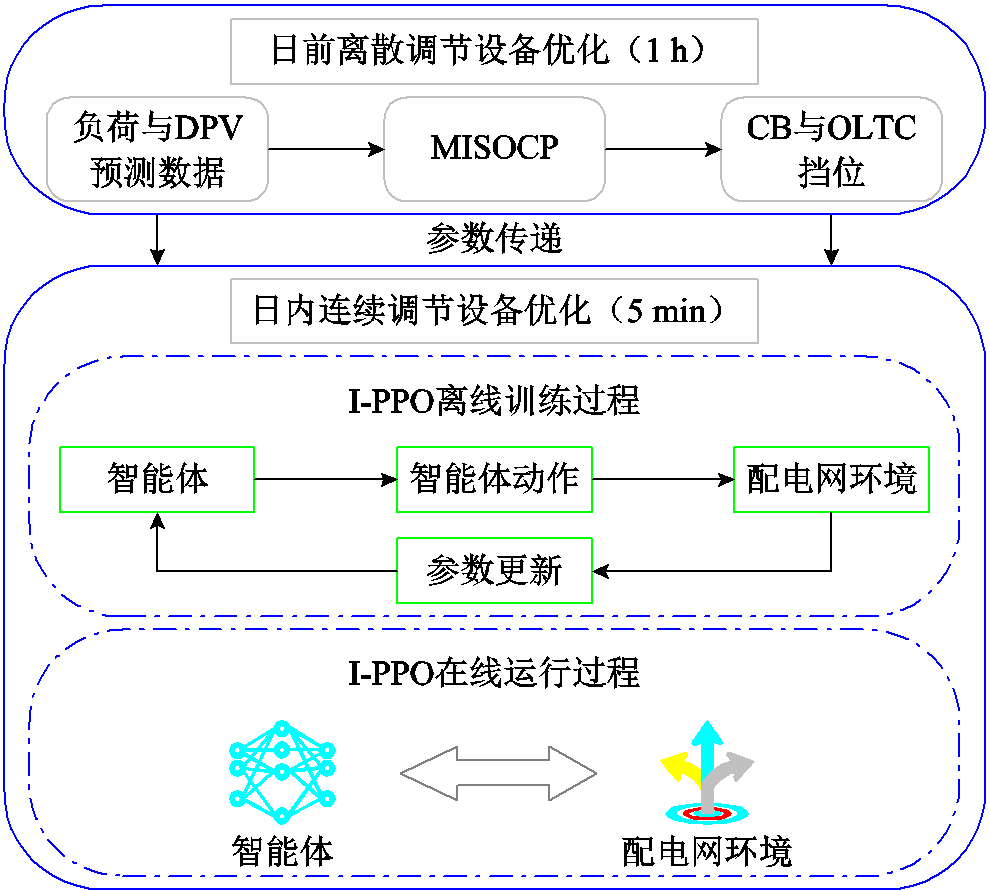
图1 “日前-日内”两阶段优化框架
Fig.1 “Day-ahead and intra-day” two-stage optimization framework
摘要 随着大规模分布式光伏和电动汽车的接入,有源配电网面临的电压越限、网损增加及三相不平衡等多重运行挑战日益凸显。传统数学规划方法因计算复杂度高难以支持在线决策,而深度强化学习算法在多时间尺度主动管理设备调节方面存在局限性。为此,该文提出一种内嵌数据驱动的三相不平衡有源配电网“日前-日内”两阶段动态最优潮流调度方法,通过结合物理机理建模与数据驱动学习的优势,实现对多类型调节资源的精细化协调控制。首先,综合考虑主动管理与需求响应约束,以调压降损为目标,建立了三相不平衡有源配电网动态最优潮流模型;其次,在日前调度的h级长时间尺度下,通过采用lift-and-project松弛方式的混合整数二阶锥规划,确定慢速离散调节设备的挡位,在日内调度的min级短时间尺度下,将动态最优潮流问题转换为马尔可夫决策过程,提出基于专家知识和层次化奖励重塑机制的改进近端策略优化算法,对快速连续调节设备进行在线调控;最后,以IEEE 33节点与123节点三相辐射状配电网为算例进行仿真分析,结果验证了所提方法的有效性和优越性。
关键词:有源配电网 调压降损 三相不平衡 两阶段动态最优潮流 混合整数二阶锥规划 改进近端策略优化
在能源转型与新型电力系统建设背景下,配电网逐步演变为支撑可再生能源消纳的关键环节[1-3]。分布式光伏(Distributed Photovoltaic, DPV)和电动汽车(Electric Vehicle, EV)的大规模接入推动了配电网从单向辐射到双向互动的结构性变革,引发了节点电压越限、网络损耗增加及三相电压不平衡等技术挑战,亟须研究适应有源配电网特征的运行方式调整策略,以确保其安全、稳定和高效运行[4-5]。
作为提升电网安全经济性的核心技术,最优潮流(Optimal Power Flow, OPF)因二次潮流等式约束的非凸特性而被证明是NP-hard问题[6-7]。为此,文献[8-9]提出了配电网支路潮流模型(Branch Flow Model, BFM),并采用二阶锥松弛技术实现模型凸化。针对传统OPF模型忽视多时段动态耦合的问题,文献[10]构建了适应有源配电网多时段动态最优潮流(Dynamic Optimal Power Flow, DOPF)的混合整数二阶锥规划(Mixed-Integer Second-Order Cone Programming, MISOCP)模型,提升了OPF凸松弛技术的适用性。然而,上述文献多基于三相平衡假设,实际配电网运行中普遍存在三相负荷、线路或元件参数不平衡的情况,而DPV与EV的单相接入进一步加剧了系统的不对称性。因此,学术界普遍认同采用三相模型对有源配电网进行分析[11-12]。如文献[13]建立了三相有源配电网无功静态优化调度模型,随后在文献[14]中将其扩展至多时段,并对储能系统(Energy Storage System, ESS)、静止无功补偿器(Static Var Compensator, SVC)、分组投切电容器组(Capacitor Bank, CB)等主动管理(Active Management, AM)元素进行线性化建模,构建了有功-无功协同的动态优化调度模型。然而,上述文献将三相潮流方程分解为独立单相处理,忽视了相间电磁耦合效应,可能导致系统不平衡工况下的优化结果出现偏差。针对这一局限,文献[15]建立了考虑相间互阻抗的三相不平衡配电网二阶锥松弛模型。文献[16]进一步将三相分布式电源、有载调压变压器(On-Load Tap-Changer, OLTC)及交直流换流器等关键设备纳入优化框架。文献[17]则提出了考虑相间耦合与三相不平衡约束的交直流配电网协同优化策略。然而,上述文献仍局限于单时段静态优化框架,未能有效整合多时段协调机制与需求响应(Demand Response, DR)潜力,制约了优化效果的提升。此外,三相不平衡有源配电网DOPF问题采用模型驱动方法求解时存在决策空间庞大与算法收敛难题,且计算资源消耗巨大,难以满足配电网调度对实时性和灵活性的高要求[18]。
相较于前述模型驱动方法,深度强化学习(Deep Reinforcement Learning, DRL)融合了深度学习的深度感知能力与强化学习的策略优化能力,在处理高维复杂DOPF问题时,展现出潜在的优势和可行性。DRL能够基于历史经验自适应学习调度策略,无需对源荷进行精确建模,以数据驱动方式应对不确定性和复杂度[19]。如文献[20]基于深度Q网络(Deep Q Network, DQN)算法求解三相不平衡配电网OPF问题,实现了分布式无功优化与电压控制;文献[21]基于深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法,从日前和日内两个阶段对有源配电网开展了多时间尺度智能优化调度。然而,DQN将动作空间离散化后从有限的动作值中选择行动,这不仅可能导致维数灾难,还会丧失优质动作的选取机会;DDPG虽然适用于高维和连续动作空间,但训练效果的好坏在很大程度上取决于超参数的选择,调参需要花费大量精力。为此,文献[22]引入了柔性执行者-评论者(Soft Actor-Critic, SAC)算法,通过双Q网络架构设计和对应的目标网络软更新机制,有效提升了训练稳定性。然而,SAC算法对超参数极为敏感,且引入的双网络可能会使最优策略趋于保守。针对这一问题,文献[23]提出了一种基于近端策略优化(Proximal Policy Optimization, PPO)的电压控制算法,旨在解决三相不平衡有源配电网节点电压越限问题。但是,现有PPO算法存在样本效率低、策略更新保守等不足,亟须改进PPO算法,以提升策略优化的稳定性和复杂动态场景下的泛化能力,从而确保实现三相不平衡有源配电网DOPF问题的高效求解。此外,DRL算法难以在不同时间尺度下对不同调节方式与调节能力的AM设备进行处理,存在一定的应用局限性[24]。
总体而言,上述文献对于解决三相不平衡有源配电网DOPF问题具有参考价值,但仍存在以下不足:①现有研究没有同时考虑相间耦合和时间耦合,三相不平衡有源配电网DOPF模型有待进一步完善;②现有研究主要集中于通过调度各类AM设备实现配电网有功-无功协同优化,忽视了DR在其中的重要作用;③传统数学规划方法依赖精确参数与模型,计算复杂度高,难以实现在线控制,且当前DRL算法在应对多时间尺度AM设备的调节任务时存在挑战。
为此,本文提出一种内嵌数据驱动的三相不平衡有源配电网“日前-日内”两阶段DOPF调度方法。首先,综合考虑AM与DR约束,以调压降损为目标,建立了三相不平衡有源配电网DOPF模型;其次,在日前调度的h级长时间尺度下,通过采用lift-and-project松弛方式的MISOCP,确定CB、OLTC等慢速离散调节设备的挡位,在日内调度的min级短时间尺度下,将DOPF问题转换为马尔可夫决策过程(Markov Decision Process, MDP),提出基于专家知识(Expert Knowledge, EK)和层次化奖励重塑(Hierarchical Reward Shaping, HRS)机制的改进近端策略优化(Improved Proximal Policy Optimization, I-PPO)算法,对DPV、EV、ESS、SVC等快速连续调节设备进行在线调控;最后,以IEEE 33节点与123节点三相辐射状配电网为算例验证了所提方法的有效性。
综上所述,本文提出的两阶段优化框架如图1所示。
图1 “日前-日内”两阶段优化框架
Fig.1 “Day-ahead and intra-day” two-stage optimization framework
在本文提出的两阶段优化框架中,日前调度与日内调度共用目标函数与约束条件,二者通过设备动作的时序衔接实现耦合。
为协同优化线路损耗与电压偏差,采用归一化方法建立目标函数,有
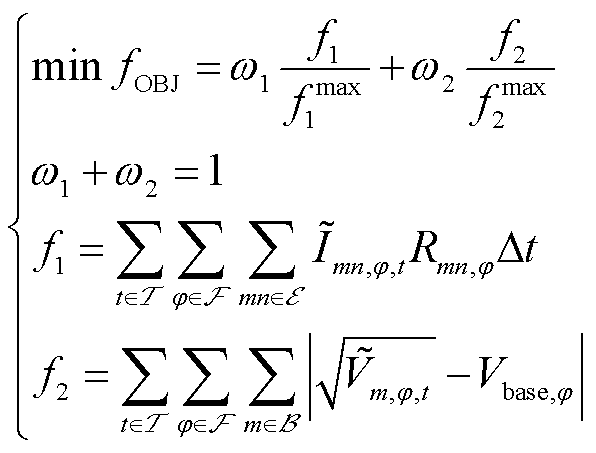 (1)
(1)
式中,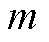 、
、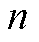 为节点编号;
为节点编号;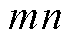 为支路;
为支路;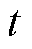 为时段;
为时段;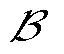 为节点集合;
为节点集合;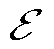 为支路集合;
为支路集合;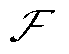 为三相集合,
为三相集合,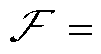
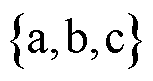 ,
,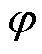 为其中一相;
为其中一相;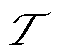 为调度周期时段集合;
为调度周期时段集合;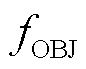 为综合目标;
为综合目标;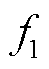 、
、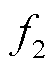 分别为线路有功损耗、节点电压偏差;
分别为线路有功损耗、节点电压偏差;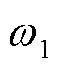 、
、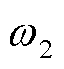 分别为、的权重;
分别为、的权重;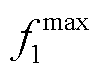 、
、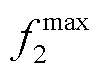 分别为、优化前的取值,通过调用Matlab中Matpower工具包进行潮流计算仿真得到;
分别为、优化前的取值,通过调用Matlab中Matpower工具包进行潮流计算仿真得到;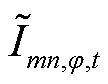 为支路的相在时段电流的二次方;
为支路的相在时段电流的二次方;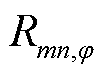 为支路的相电阻值;
为支路的相电阻值;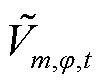 为节点的相在时段电压的二次方;
为节点的相在时段电压的二次方;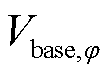 为相电压基准值,设为1(pu);
为相电压基准值,设为1(pu);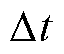 为调度步长。
为调度步长。
约束条件包括潮流约束、DPV运行约束、EV参与DR约束及ESS、SVC、CB、OLTC等各种AM设备运行约束。
1.2.1 潮流约束
计及相间耦合和时间耦合关系,三相辐射状配电网的BFM包括节点功率平衡约束、欧姆定律约束以及支路传输功率约束。
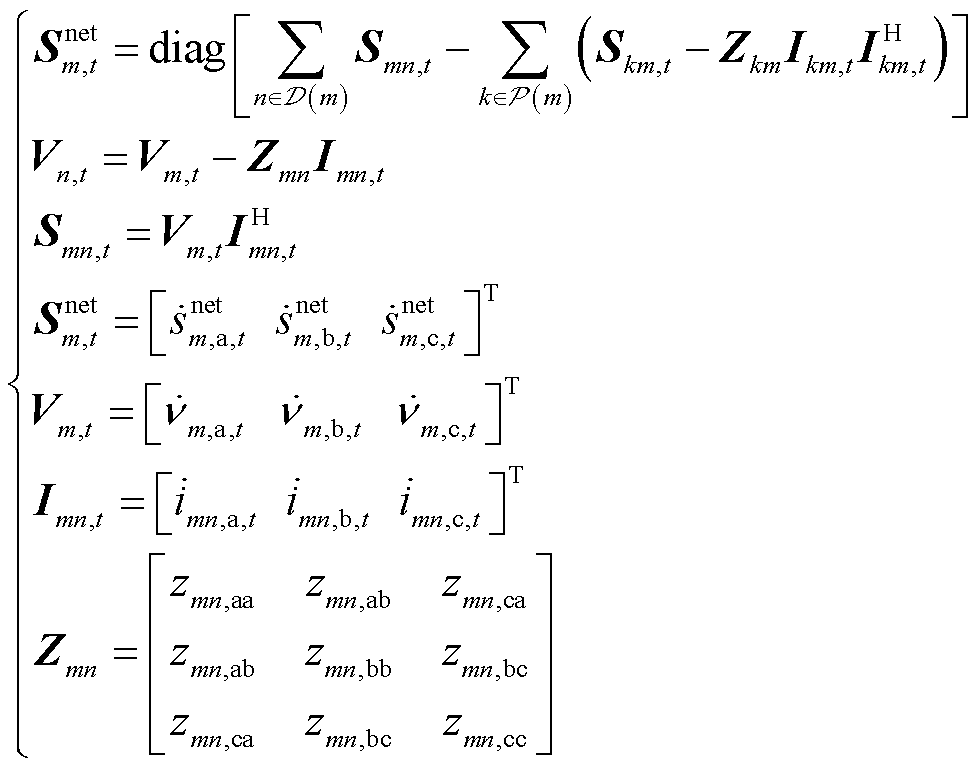 (2)
(2)
式中,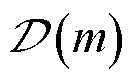 为以节点作为首端的支路末端节点集合;
为以节点作为首端的支路末端节点集合;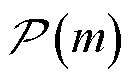 为以节点作为末端的支路首端节点集合;
为以节点作为末端的支路首端节点集合;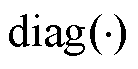 为矩阵取对角元素;上标H为矩阵共轭转置;上标T为矩阵转置;
为矩阵取对角元素;上标H为矩阵共轭转置;上标T为矩阵转置;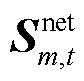 为节点在时段的注入复功率三相分量组成的列向量;
为节点在时段的注入复功率三相分量组成的列向量;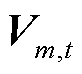 为节点在时段的电压三相分量组成的列向量;
为节点在时段的电压三相分量组成的列向量;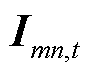 为支路在时段的电流三相分量组成的列向量;
为支路在时段的电流三相分量组成的列向量;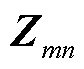 为支路的阻抗矩阵;
为支路的阻抗矩阵;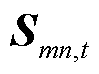 为支路在时段的传输功率矩阵;
为支路在时段的传输功率矩阵;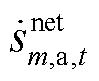 、
、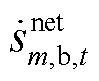 、
、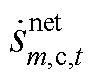 分别为节点的a、b、c相在时段的注入复功率;
分别为节点的a、b、c相在时段的注入复功率;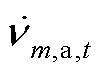 、
、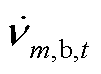 、
、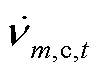 分别为节点的a、b、c相在时段的电压;
分别为节点的a、b、c相在时段的电压;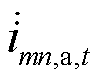 、
、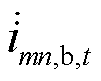 、
、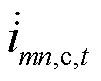 分别为支路的a、b、c相在时段的电流;
分别为支路的a、b、c相在时段的电流;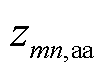 、
、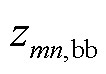 、
、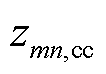 分别为支路的a、b、c相自阻抗;
分别为支路的a、b、c相自阻抗;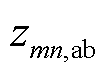 、
、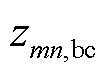 、
、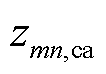 分别为支路的ab、bc、ca相间互阻抗。
分别为支路的ab、bc、ca相间互阻抗。
1.2.2 DPV运行约束
在逆变器的精准控制下,DPV能够实现有功出力与无功出力三相独立且灵活调节,有功、无功出力均不超过各自的上、下限。
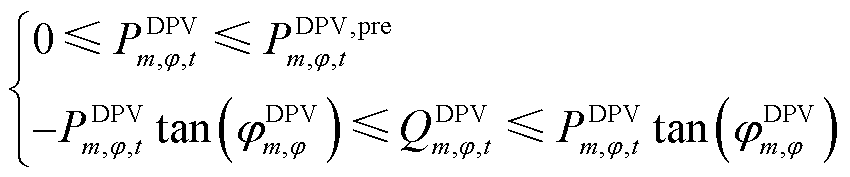 (3)
(3)
式中,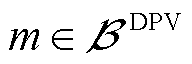 ,
,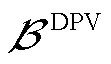 为接有DPV的节点集合;
为接有DPV的节点集合;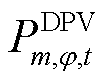 、
、 分别为节点处所连接的DPV相在时段的实际有功出力及其日前预测值;
分别为节点处所连接的DPV相在时段的实际有功出力及其日前预测值;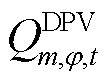 为节点处所连接的DPV相在时段的无功出力;
为节点处所连接的DPV相在时段的无功出力;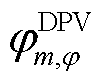 为节点处所连接的DPV相功率因数角。
为节点处所连接的DPV相功率因数角。
1.2.3 EV参与DR约束
EV能够主动参与DR,通过调整其充电时段及地点,进而有效地缓解三相电压不平衡问题。EV充电负荷的可转移量需保持在设定的上、下限内,并且实施DR前后,EV充电负荷总量应保持不变。
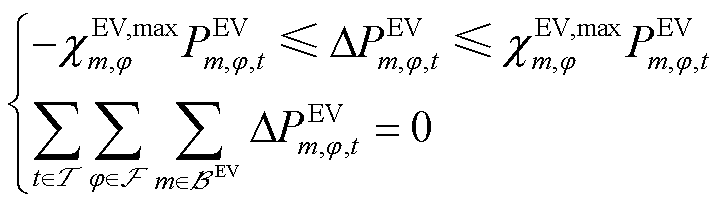 (4)
(4)
式中,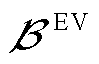 为接有EV的节点集合;
为接有EV的节点集合;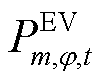 为节点处所连接的EV相在时段的充电负荷有功功率;
为节点处所连接的EV相在时段的充电负荷有功功率;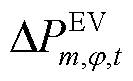 为节点处所连接的EV相在时段的充电负荷实际转移量;
为节点处所连接的EV相在时段的充电负荷实际转移量;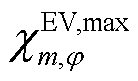 为节点处所连接的EV相充电负荷最大可转移率。
为节点处所连接的EV相充电负荷最大可转移率。
1.2.4 ESS运行约束
ESS负责有功调节,三相可独立调整。ESS的充放电功率需不超过其上限,且充放电过程不能同时进行,其荷电量变化遵循特定状态方程,并保持在规定的波动范围内。同时确保在每个调度周期的始末时刻,ESS的荷电量保持一致。
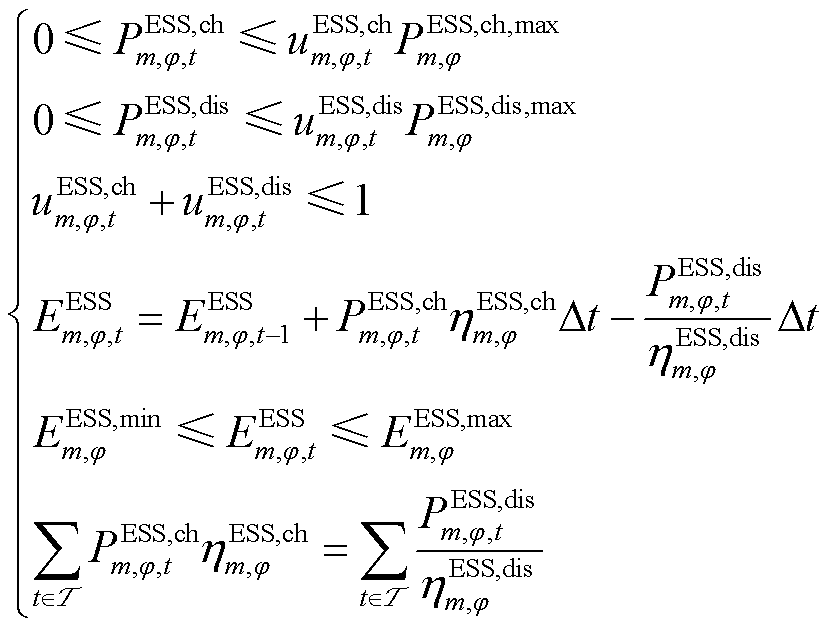 (5)
(5)
式中,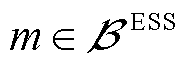 ,
, 为接有ESS的节点集合;
为接有ESS的节点集合;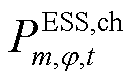 、
、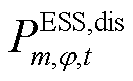 和
和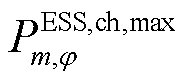 、
、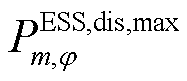 分别为节点处所连接的ESS相在时段的充、放电功率及其最大值;
分别为节点处所连接的ESS相在时段的充、放电功率及其最大值;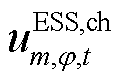 、
、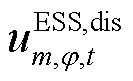 分别为节点处所连接的ESS相在时段的充、放电状态对应的0-1变量;
分别为节点处所连接的ESS相在时段的充、放电状态对应的0-1变量;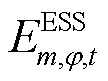 、
、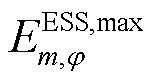 、
、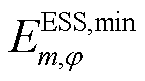 分别为节点处所连接的ESS相在时段的荷电量及其上、下限;
分别为节点处所连接的ESS相在时段的荷电量及其上、下限;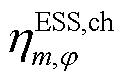 、
、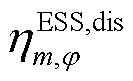 分别为节点处所连接的ESS相充、放电效率。
分别为节点处所连接的ESS相充、放电效率。
1.2.5 SVC运行约束
SVC用以进行连续无功补偿,三相可独立调整,无功补偿功率不超过设定的上、下限。
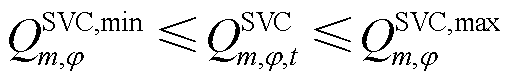 (6)
(6)
式中,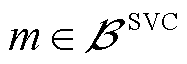 ,
,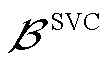 为连接SVC的节点集合;
为连接SVC的节点集合;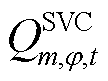 、
、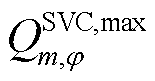 、
、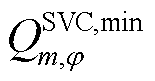 分别为节点连接SVC相在时段的无功功率及其上、下限。
分别为节点连接SVC相在时段的无功功率及其上、下限。
1.2.6 CB运行约束
CB用以进行离散无功补偿,三相可独立调整。CB的投运组数与无功补偿功率之间存在特定关系,且投运组数需不超过其上限,必须逐组投运,不能同时进行增减操作。此外,CB的投运组数调节范围及调度周期内的最大允许投切次数均有所限制。
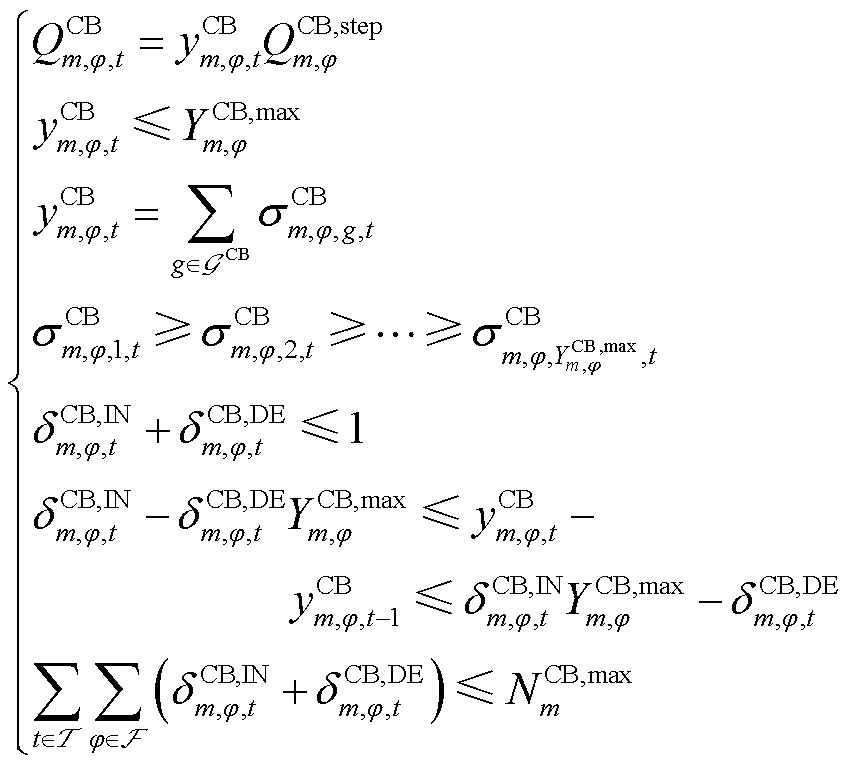 (7)
(7)
式中,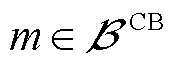 ,
,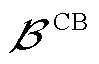 为接有CB的节点集合;
为接有CB的节点集合;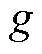 为挡位;
为挡位;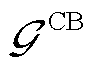 为CB投运组数集合;
为CB投运组数集合;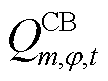 、
、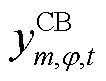 分别为节点处所连接的CB相在时段的无功功率和已投运组数;
分别为节点处所连接的CB相在时段的无功功率和已投运组数;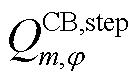 为节点处所连接的CB相单组无功补偿额定功率;
为节点处所连接的CB相单组无功补偿额定功率;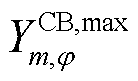 为节点处所连接的CB相最大可投运组数;
为节点处所连接的CB相最大可投运组数;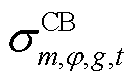 为节点处所连接的CB相在时段第g组的投运状态,=1表示第g组投运,=0表示第g组未投运;
为节点处所连接的CB相在时段第g组的投运状态,=1表示第g组投运,=0表示第g组未投运;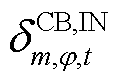 、
、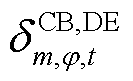 分别为节点处所连接的CB相在时段比
分别为节点处所连接的CB相在时段比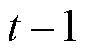 时段投运组数增、减对应的0-1变量,=1表示投运组数增加,=0表示不增加,=1表示投运组数减少,=0表示没有减少;
时段投运组数增、减对应的0-1变量,=1表示投运组数增加,=0表示不增加,=1表示投运组数减少,=0表示没有减少;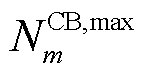 为一个调度周期内节点处所连接的CB三相最大可投切次数。
为一个调度周期内节点处所连接的CB三相最大可投切次数。
1.2.7 OLTC运行约束
OLTC负责调节主变压器低压侧母线电压,三相可独立调整。为减轻有源配电网功率波动对上级电网的影响,OLTC节点的关口交换功率受到限制,同时OLTC一、二次电压间存在特定关系,且二次电压与一次电压比的二次方需在限定范围内,OLTC挡位需逐级调节,不能同时进行升降操作。此外,OLTC的挡位调节范围及调度周期内的最大允许调节次数均有所限制。
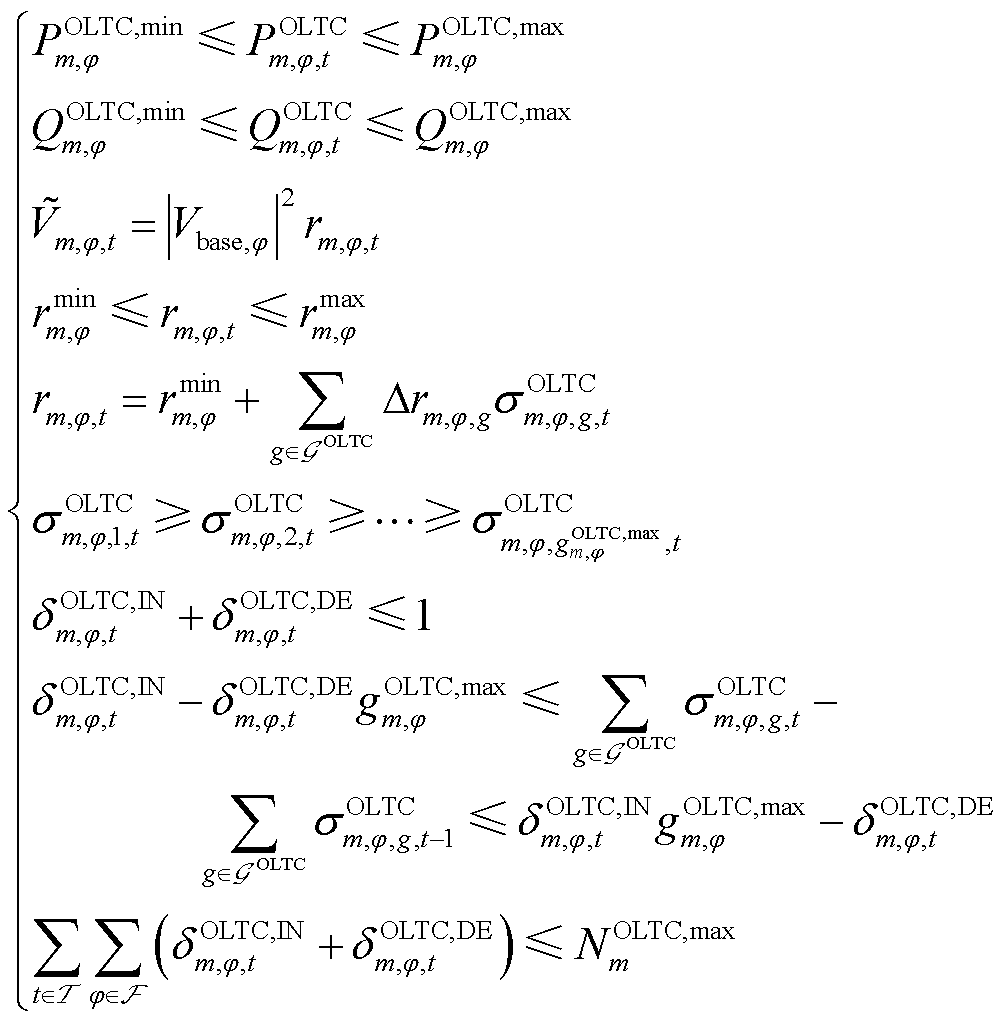 (8)
(8)
式中,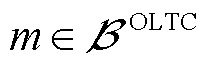 ,
,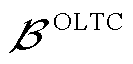 为接有OLTC的变电站节点集合;
为接有OLTC的变电站节点集合;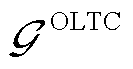 为OLTC可调挡位集合;
为OLTC可调挡位集合;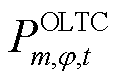 、
、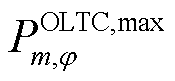 、
、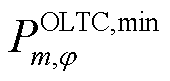 和
和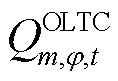 、
、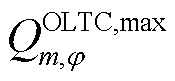 、
、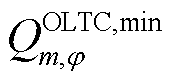 分别为上级电网注入变电站节点的相在时段的有功功率和无功功率及其上下限;
分别为上级电网注入变电站节点的相在时段的有功功率和无功功率及其上下限;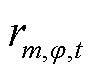 、
、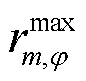 、
、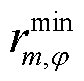 分别为节点处所连接的OLTC相在时段的二次侧与一次侧之间电压比的二次方及其上、下限;
分别为节点处所连接的OLTC相在时段的二次侧与一次侧之间电压比的二次方及其上、下限;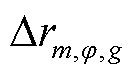 为节点处所连接的OLTC相挡位
为节点处所连接的OLTC相挡位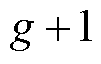 与挡位之间电压比的平方差;
与挡位之间电压比的平方差;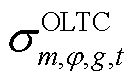 为节点处所连接的OLTC相挡位与挡位之间在时段的调节增量对应的0-1变量,=1表示由挡位g调节到挡位g+1,=0表示没有调节;
为节点处所连接的OLTC相挡位与挡位之间在时段的调节增量对应的0-1变量,=1表示由挡位g调节到挡位g+1,=0表示没有调节;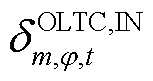 、
、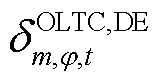 分别为节点处所连接的OLTC相在时段比时段挡位增、减对应的0-1变量,
分别为节点处所连接的OLTC相在时段比时段挡位增、减对应的0-1变量,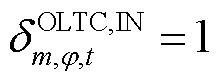 表示挡位增加,=0表示挡位没有增加,=1表示挡位降低,=0表示挡位没有降低;
表示挡位增加,=0表示挡位没有增加,=1表示挡位降低,=0表示挡位没有降低;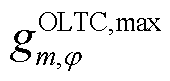 为节点处所连接的OLTC相挡位最大可调节范围;
为节点处所连接的OLTC相挡位最大可调节范围;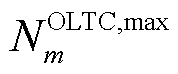 为一个调度周期内节点处所连接的OLTC三相挡位最大可调节次数。
为一个调度周期内节点处所连接的OLTC三相挡位最大可调节次数。
日前优化阶段以1 h为调度步长,共包含24个时段。通过lift-and-project的松弛方式,结合西尔维斯特准则,形成二阶锥约束;并在DOPF模型中加入三相电压不平衡度约束与系统安全运行约束;进一步将目标函数线性化,构建MISOCP模型,确定CB、OLTC等慢速离散调节设备的挡位。
针对BFM式(2)中的双线性项,采用lift-and-project的方式进行凸松弛。通过定义二次型变量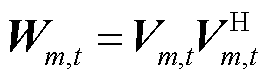 和
和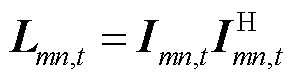 ,将和映射到高维空间。新的待求变量
,将和映射到高维空间。新的待求变量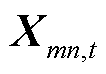 为一个厄米特矩阵,其主对角元素代表节点的a、b、c相在时段的电压二次方及支路的a、b、c相在时段的电流二次方,表达式为
为一个厄米特矩阵,其主对角元素代表节点的a、b、c相在时段的电压二次方及支路的a、b、c相在时段的电流二次方,表达式为
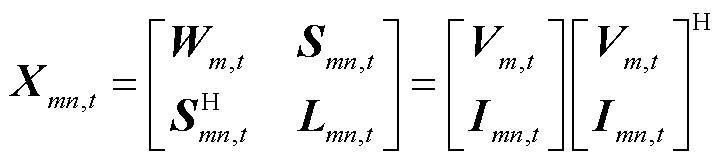 (9)
(9)
二次型变量需满足半正定性与秩约束[25],有
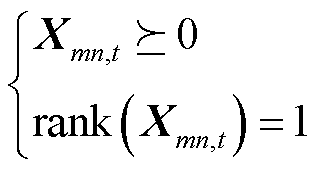 (10)
(10)
式中,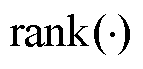 为矩阵求秩。
为矩阵求秩。
为构建凸化模型,对秩约束进行松弛处理;同时,为了减轻计算负担,依据西尔维斯特准则[26-27],将矩阵的二阶主子式全部设定为非负数,从而实现从半正定约束到二阶锥约束的有效转换,即
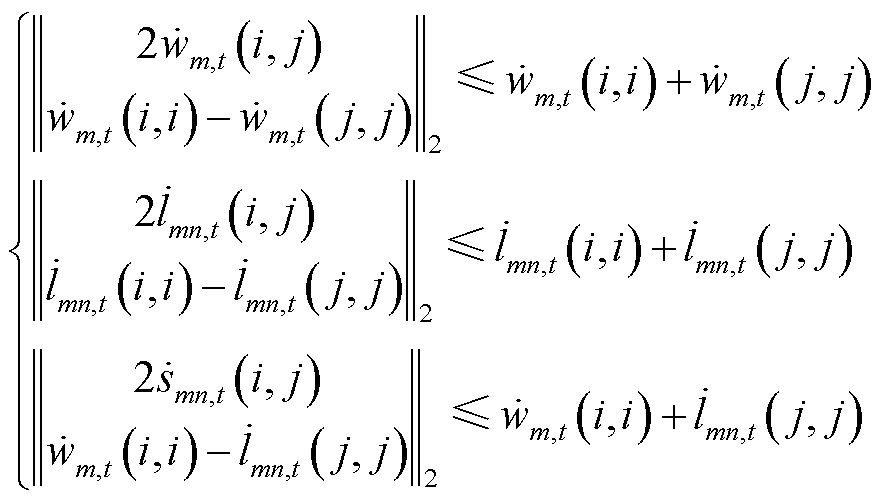 (11)
(11)
式中,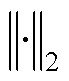 为2-范数;
为2-范数;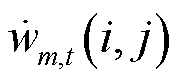 、
、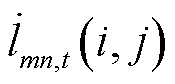 、
、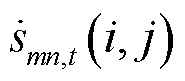 分别为矩阵
分别为矩阵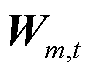 、
、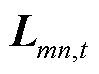 、
、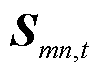 第
第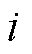 行第
行第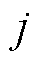 列的元素。
列的元素。
针对式(2)的第二行约束进行共轭相乘变换可得
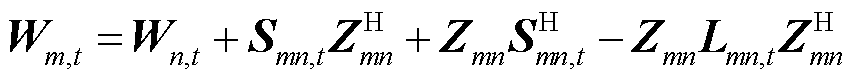 (12)
(12)
同时,式(2)的第一行约束变为
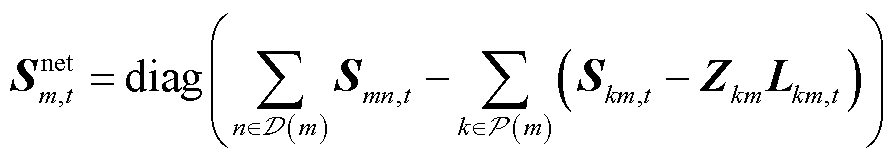 (13)
(13)
通过对称分量法实现节点电压相分量到序分量的变换,具体为
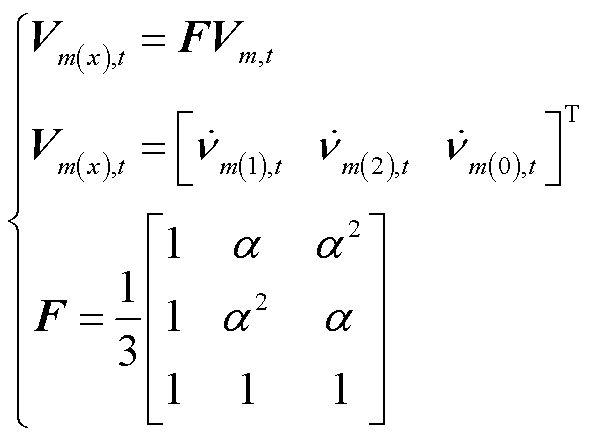 (14)
(14)
式中,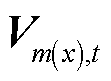 为节点在时段的电压三序分量组成的列向量;
为节点在时段的电压三序分量组成的列向量;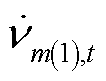 、
、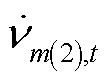 、
、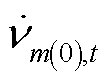 分别为节点在时段的正、负、零序电压;
分别为节点在时段的正、负、零序电压; 为相分量到序分量的变换矩阵;
为相分量到序分量的变换矩阵;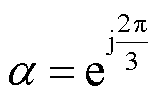 。
。
为在高维空间中计算节点电压序分量,定义新的变量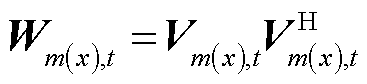 ,其主对角元素分别为节点正、负、零序在时段的电压二次方。针对式(14)的第一行约束进行共轭相乘变换可得
,其主对角元素分别为节点正、负、零序在时段的电压二次方。针对式(14)的第一行约束进行共轭相乘变换可得
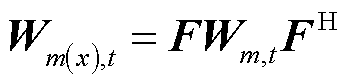 (15)
(15)
依据国标GB/T15543—2008[28],三相电压不平衡度为
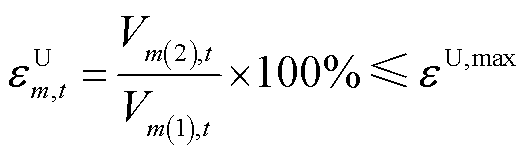 (16)
(16)
式中,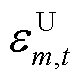 、
、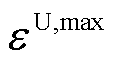 分别为节点在时段的三相电压不平衡度及其上限;
分别为节点在时段的三相电压不平衡度及其上限;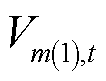 、
、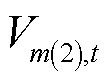 分别为节点的正、负序电压在时段的有效值。
分别为节点的正、负序电压在时段的有效值。
将式(16)不等式两边二次方,转换为
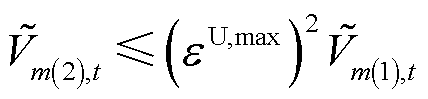 (17)
(17)
式中,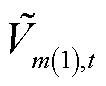 、
、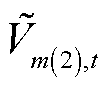 分别为节点在时段的正、负序电压二次方。
分别为节点在时段的正、负序电压二次方。
在日前调度阶段,需确保节点电压、支路电流、支路传输功率及节点注入功率均不超过其各自的上、下限。
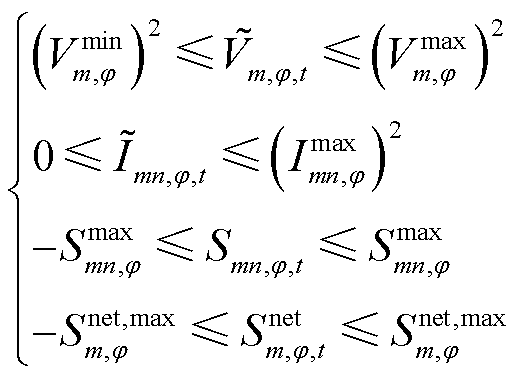 (18)
(18)
式中,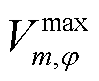 、
、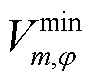 分别为节点的相电压有效值的上、下限;
分别为节点的相电压有效值的上、下限;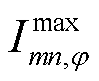 为支路
为支路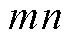 的相电流有效值的上限;
的相电流有效值的上限;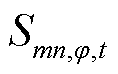 、
、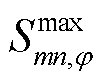 分别为支路的相在时段的传输视在功率及其上限;
分别为支路的相在时段的传输视在功率及其上限;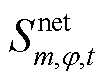 、
、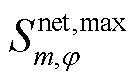 分别为节点的相在时段的注入视在功率及其上限。
分别为节点的相在时段的注入视在功率及其上限。
针对式(1)中节点电压偏差的非线性项,由于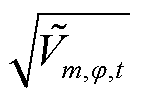 接近基准值1(pu),故在1(pu)附近对进行一阶泰勒展开,可得
接近基准值1(pu),故在1(pu)附近对进行一阶泰勒展开,可得
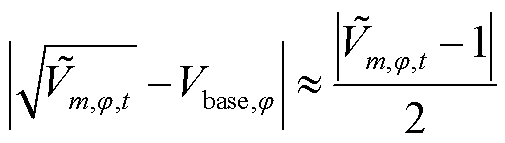 (19)
(19)
式(19)中的绝对值项可通过引入非负辅助变量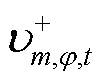 、
、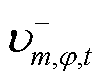 及0-1变量
及0-1变量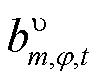 ,并应用big-M法线性化,从而将转换为
,并应用big-M法线性化,从而将转换为
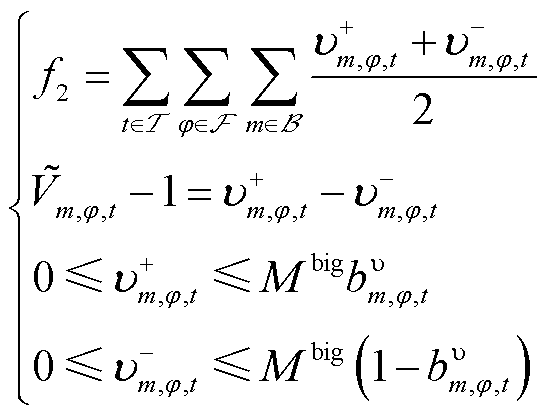 (20)
(20)
式中,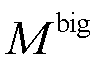 为一个极大的正实数。
为一个极大的正实数。
日内优化阶段以5 min为调度步长,共包含288个时段。对有源配电网运行规则和调度目标进行编码,将EK转换为可微分的正则项,并嵌入Actor网络的梯度更新过程中,以增强智能体在三相电压不平衡度约束上的执行力,同时引导其有效地减少DPV的有功削减;在将DOPF模型的数学表述形式转换为DRL框架下的MDP时,通过HRS机制优化奖励函数构造,综合评估智能体的实时与最终性能,对系统安全运行约束的满足行为给予正向引导。在强化学习过程中,将日前阶段确定的CB与OLTC挡位作为智能体控制器的输入,对DPV、EV、ESS、SVC等快速连续调节设备进行在线调控。
3.1.1 Actor网络训练
引入优势函数衡量在特定状态下执行当前动作相对于其他动作的好坏程度,如果所选动作优于平均值,则优势函数为正,否则为负。
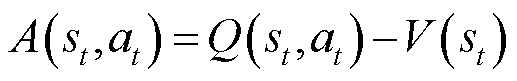 (21)
(21)
式中,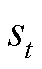 为时段的状态;
为时段的状态;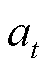 为时段的动作;
为时段的动作;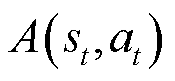 为优势函数;
为优势函数;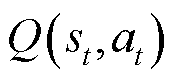 为动作价值函数;
为动作价值函数;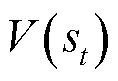 为状态价值函数。
为状态价值函数。
为平衡方差与偏差,采用截断形式的通用优势估计计算优势函数,即
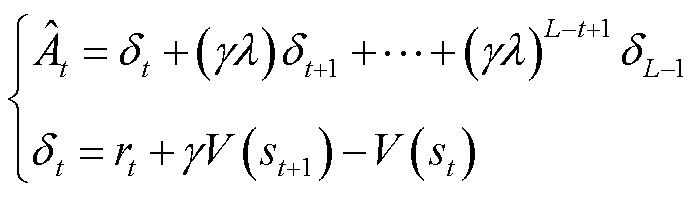 (22)
(22)
式中,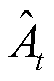 为对优势函数在时段的估计;
为对优势函数在时段的估计;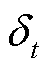 为时段的单步优势;
为时段的单步优势;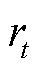 为时段的奖励;
为时段的奖励;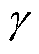 为折扣因子,用于控制未来回报在当前决策中的重要性,越大表示智能体更倾向于考虑长远的利益,越小表示智能体更倾向于即时回报;
为折扣因子,用于控制未来回报在当前决策中的重要性,越大表示智能体更倾向于考虑长远的利益,越小表示智能体更倾向于即时回报;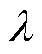 为衰减因子;
为衰减因子;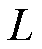 为一幕轨迹的长度,用于截断。
为一幕轨迹的长度,用于截断。
Actor网络通过优化其损失函数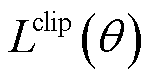 来更新网络参数
来更新网络参数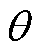 ,即
,即
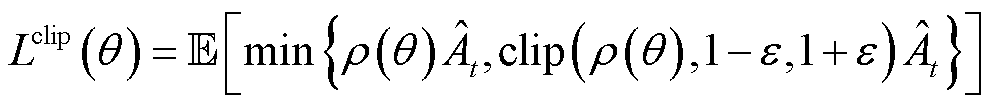 (23)
(23)
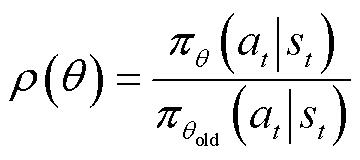 (24)
(24)
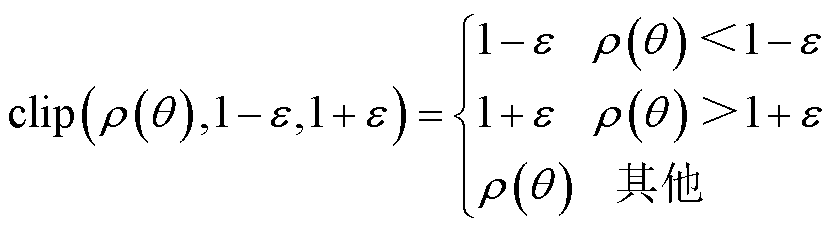 (25)
(25)
式中,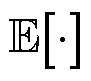 为期望函数;
为期望函数;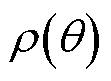 为重要性采样比;
为重要性采样比;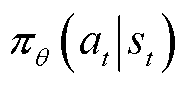 、
、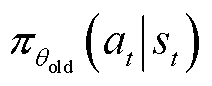 分别为新、旧策略分布函数;
分别为新、旧策略分布函数;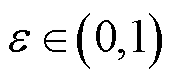 为裁剪因子;
为裁剪因子;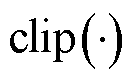 为裁剪函数,用于限制处于区间
为裁剪函数,用于限制处于区间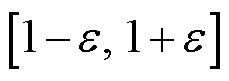 内,防止新、旧策略之间的差异过大。
内,防止新、旧策略之间的差异过大。
为增强智能体在强化学习过程中对三相电压不平衡度约束的执行能力,并有效降低DPV有功削减,引入基于EK的正则项至Actor网络的损失函数中。
专家经验表明,三相电压不平衡会导致电力设备运行效率降低、损耗增加,甚至引发设备过热、绝缘损坏等严重故障。因此将式(17)转换为三相电压不平衡度约束正则项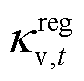 ,引导智能体在训练过程中优先满足这一电能质量约束。表达式为
,引导智能体在训练过程中优先满足这一电能质量约束。表达式为
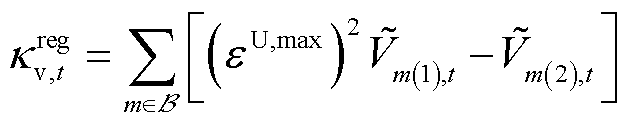 (26)
(26)
此外,基于专家对DPV波动性、经济性及环保需求的权衡经验,将此类经验编码为DPV消纳率正则项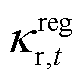 ,通过降低DPV有功削减,引导智能体在训练过程中优先消纳可再生能源。表达式为
,通过降低DPV有功削减,引导智能体在训练过程中优先消纳可再生能源。表达式为
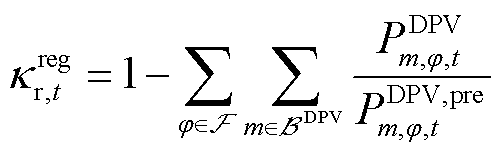 (27)
(27)
综上所述,改进后的Actor网络损失函数为
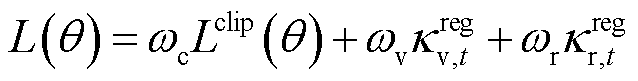 (28)
(28)
式中,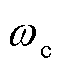 、
、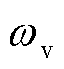 、
、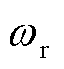 为改进后的Actor网络损失函数正则项权重。
为改进后的Actor网络损失函数正则项权重。
采用梯度上升法更新Actor网络参数,即
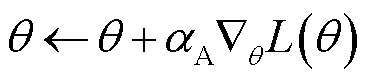 (29)
(29)
式中,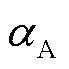 为Actor网络的学习率。
为Actor网络的学习率。
3.1.2 Critic网络训练
Critic网络通过优化其损失函数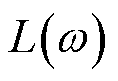 来更新网络参数
来更新网络参数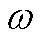 ,即
,即
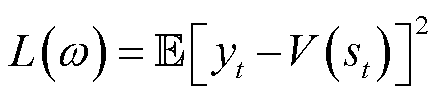 (30)
(30)
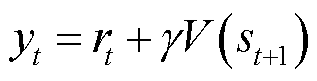 (31)
(31)
式中,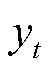 为
为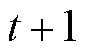 时段对的估计值。
时段对的估计值。
采用梯度下降法更新Critic网络参数,即
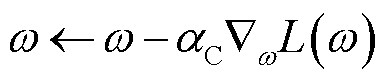 (32)
(32)
式中,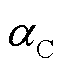 为Critic网络的学习率。
为Critic网络的学习率。
MDP框架涉及状态空间、动作空间、状态转移概率、奖励函数和折扣因子五元组。在优化调度过程中,智能体首先依据初始状态选择执行一个动作。在动作的影响下,当前状态依据策略函数转变为下一时段的状态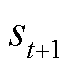 。同时,系统根据奖励值函数计算出对应的奖励值
。同时,系统根据奖励值函数计算出对应的奖励值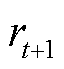 。随后,智能体接收这个新的状态和奖励值作为输入,基于当前的策略函数输出一个新的动作
。随后,智能体接收这个新的状态和奖励值作为输入,基于当前的策略函数输出一个新的动作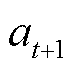 。智能体通过与动态环境试错互动,不断学习并改进序列策略,最大限度地提高累积奖励。
。智能体通过与动态环境试错互动,不断学习并改进序列策略,最大限度地提高累积奖励。
3.2.1 状态空间
状态空间表示智能体从当前环境中所能获取的所有信息,包括负荷与DPV预测功率、ESS的荷电量、CB挡位、OLTC挡位以及时段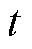 。故状态空间S定义为
。故状态空间S定义为
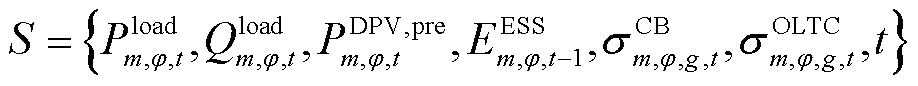 (33)
(33)
式中,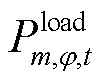 、
、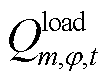 分别为节点
分别为节点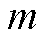 的
的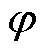 相在时段的有功、无功负荷预测功率。
相在时段的有功、无功负荷预测功率。
3.2.2 动作空间
智能体以降低日内线路有功损耗与节点电压偏差为目标,优化连续调节设备出力。故智能体的动作空间A定义为
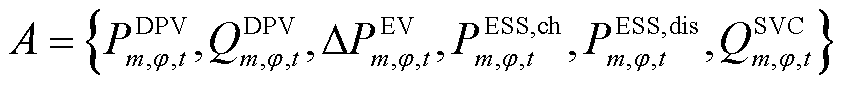 (34)
(34)
3.2.3 奖励函数
传统奖励函数设计(见附录)常采用单一惩罚机制,仅通过负向成本函数与惩罚项引导智能体学习优势策略,虽能惩罚约束违反行为,却未对约束满足行为给予正向引导。鉴于三相不平衡有源配电网DOPF问题存在大量的高维复杂约束,导致各时段状态-动作空间庞大,智能体训练时难以获得积极奖励,学习进程缓慢甚至停滞,出现稀疏奖励问题,仍会偶尔违反约束,影响系统的安全运行。
为此,引入融合了即时奖励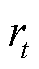 与最终奖励
与最终奖励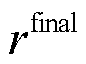 的HRS机制,辅助智能体获取最优策略。该机制下的奖励函数
的HRS机制,辅助智能体获取最优策略。该机制下的奖励函数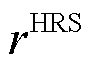 为
为
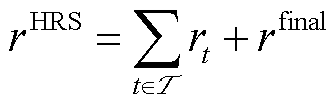 (35)
(35)
即时奖励反映当前时段的动作效果,表达式为
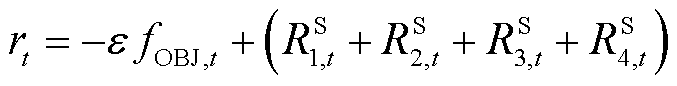 (36)
(36)
式中,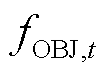 为时段优化目标的取值;
为时段优化目标的取值;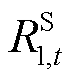 、
、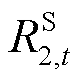 、
、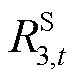 、
、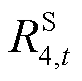 分别为与节点电压、支路电流、支路传输功率及节点注入功率安全约束相对应的单步奖励;
分别为与节点电压、支路电流、支路传输功率及节点注入功率安全约束相对应的单步奖励;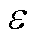 为用于将优化目标和单步奖励置于同一数量级的系数。
为用于将优化目标和单步奖励置于同一数量级的系数。
其中各类单步奖励均采用分段惩罚函数形式,且分段惩罚函数针对约束违反程度进行设计:当约束满足时,HRS赋予正向激励,以加速策略优化。具体表达式为
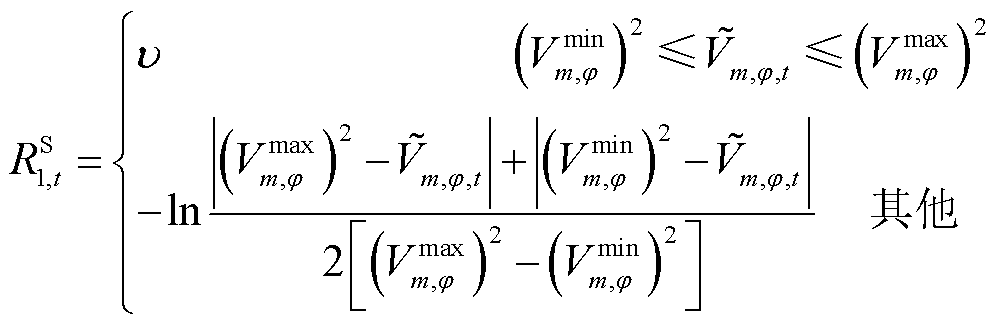 (37)
(37)
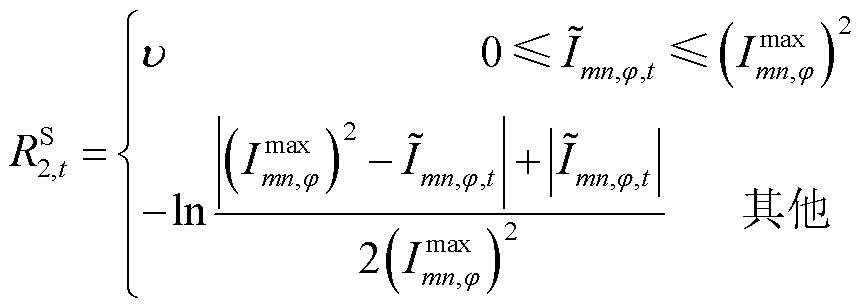 (38)
(38)
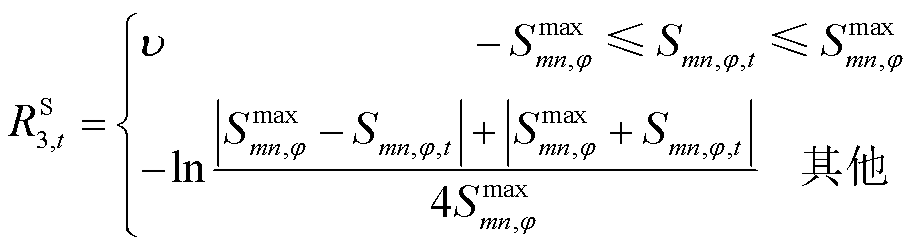 (39)
(39)
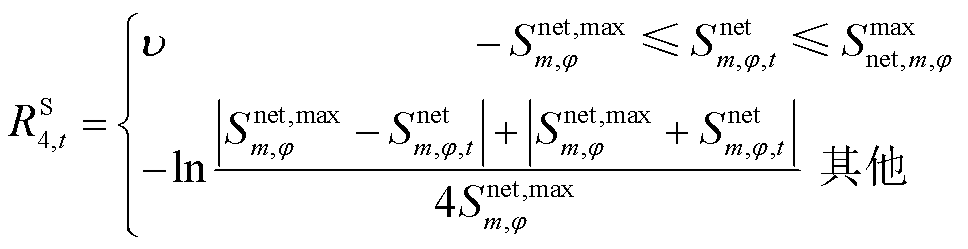 (40)
(40)
式中,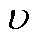 为激励系数。
为激励系数。
最终奖励用于在训练周期结束时全面评估智能体在本轮次中执行动作的性能:若全时段约束满足,则赋予高额奖励,以显著提升智能体对硬约束的敏感性。具体表达式为
 (41)
(41)
式中,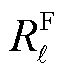 为第
为第 个安全约束对应的最终奖励;
个安全约束对应的最终奖励;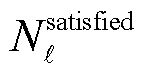 为一个回合内满足第个安全约束的步数之和;
为一个回合内满足第个安全约束的步数之和;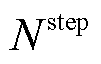 为一个回合内包含的总步数;
为一个回合内包含的总步数;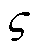 为激励系数。
为激励系数。
分别在IEEE 33节点和IEEE 123节点配电网验证所提方法的有效性。本文仿真测试在配置有AMD Ryzen 9 7900X3D CPU和32 GB RAM的PC机上进行。日前阶段仿真测试程序基于Matlab 2018b调用商业优化软件Gurobi 10.0.3完成求解;日内阶段DRL算法基于Python 3.10和Pytorch 1.13.1框架训练实现。在I-PPO算法中,Actor网络设4层隐藏层,每层含120个神经元;Critic网络设4层隐藏层,每层含100个神经元。网络激活函数选用ReLU,权重更新采用Adam优化器。
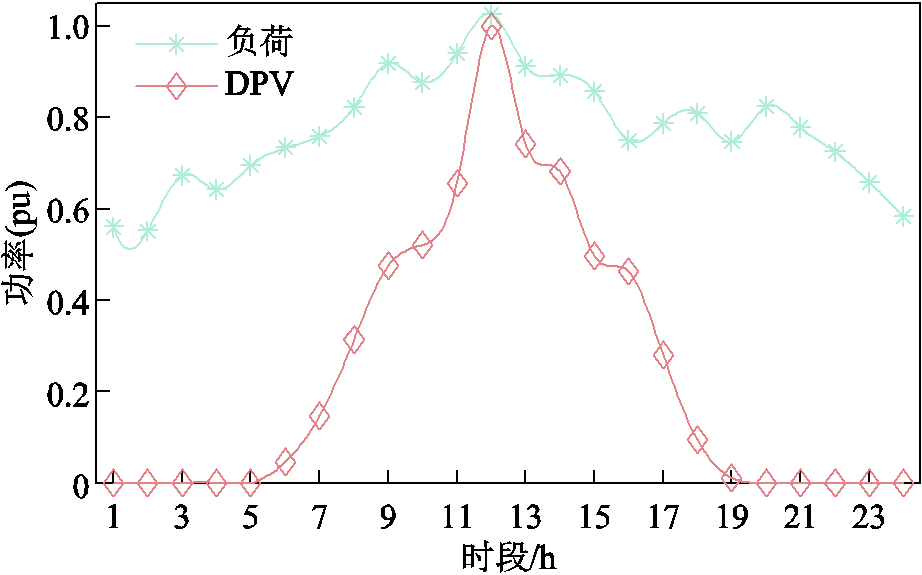
采用河南省某县域配电网6月的负荷与DPV实际数据进行分析。在日内优化调度阶段,按7:3的比例划分训练集与测试集(21天训练/9天测试),选取测试集中DPV出力峰值日作为测试基准日。
IEEE33节点配电网由37条支路构成,包含5条联络开关支路,集成了DPV、EV、ESS、SVC、CB、OLTC。基准电压为12.66 kV,基准容量为10 MV·A,总负荷功率为3 635 kW有功功率及2 265 kvar无功功率,存在三相不平衡问题。设各节点三相电压不平衡度不超过2%,DPV最小功率因数为0.95,EV充电负荷可转移率不超过15%。鉴于县域配电网覆盖区域较小且结构紧凑,为简化分析,各节点采用负荷设定值为基准的归一化功率预测曲线,而连接DPV的节点则采用DPV装机容量为基准的归一化功率预测曲线。系统结构如附图1所示,负荷与DPV归一化功率预测曲线如附图2所示,AM设备配置参数见附表1,网络参数见文献[13]。
4.1.1 日前优化调度结果分析
为探究权重系数对日前优化综合目标的影响,分别对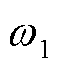 和
和 的不同取值进行敏感性测试。文献[8]严格证明了当目标函数为支路电流的增函数时,二阶锥松弛确切;反之则松弛失败。因此设定本文目标函数中线路有功损耗
的不同取值进行敏感性测试。文献[8]严格证明了当目标函数为支路电流的增函数时,二阶锥松弛确切;反之则松弛失败。因此设定本文目标函数中线路有功损耗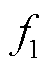 的权重最小为0.1。所得敏感性分析结果见表1。从表1中可见,组合1目标函数仅考虑网损,三相OLTC始终处于最高挡,此时有功损耗最小,电压偏差最大。组合2~5以有功损耗和电压偏差综合最小为目标,三相OLTC挡位处于1.02~1.04,电压偏差显著改善。进一步分析可知,随着由0.75降低至0.25,有功损耗增加11.80%,电压偏差降低65.08%,综合目标由0.157(pu)减少至0.138(pu),表明电压偏差相较于有功损耗对权重系数在该区间内的变化更为敏感;当由0.25降低至0.1时,有功损耗进一步增加,电压偏差进一步降低,但综合目标由0.138(pu)增加至0.141(pu)。综上所述,为确保有功损耗和电压偏差综合最小,选取组合4为最优权重。
的权重最小为0.1。所得敏感性分析结果见表1。从表1中可见,组合1目标函数仅考虑网损,三相OLTC始终处于最高挡,此时有功损耗最小,电压偏差最大。组合2~5以有功损耗和电压偏差综合最小为目标,三相OLTC挡位处于1.02~1.04,电压偏差显著改善。进一步分析可知,随着由0.75降低至0.25,有功损耗增加11.80%,电压偏差降低65.08%,综合目标由0.157(pu)减少至0.138(pu),表明电压偏差相较于有功损耗对权重系数在该区间内的变化更为敏感;当由0.25降低至0.1时,有功损耗进一步增加,电压偏差进一步降低,但综合目标由0.138(pu)增加至0.141(pu)。综上所述,为确保有功损耗和电压偏差综合最小,选取组合4为最优权重。
表1 不同权重系数对日前优化目标的影响
Tab.1 Influence of different weight coefficients on day-ahead optimization objectives
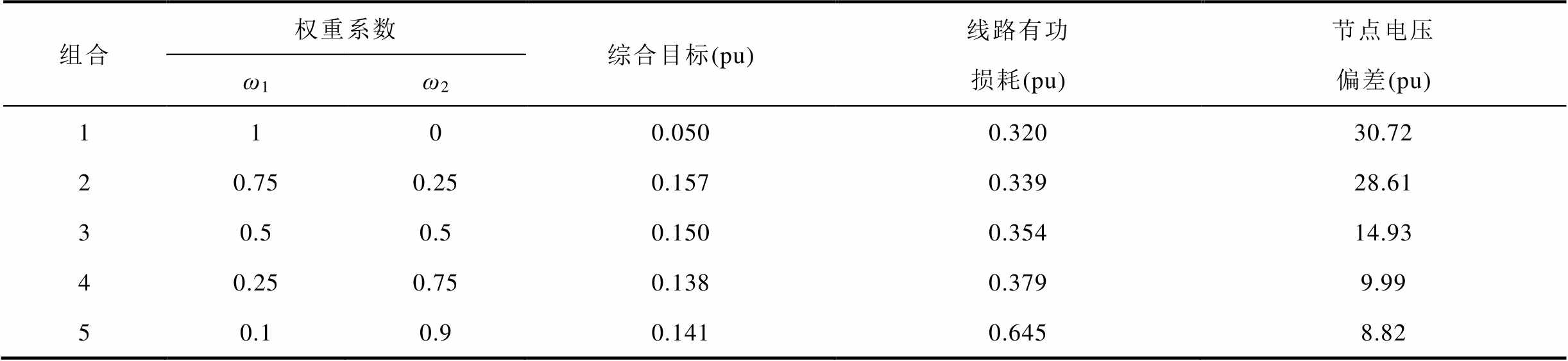
组合权重系数综合目标(pu)线路有功损耗(pu)节点电压偏差(pu) ω1ω2 1100.0500.32030.72 20.750.250.1570.33928.61 30.50.50.1500.35414.93 40.250.750.1380.3799.99 50.10.90.1410.6458.82
此时,OLTC和CB的日前优化调度结果如图2所示。OLTC电压比介于1.01~1.03之间,三相分接头共动作5次,未超每日最大调节次数。节点18所连CB在午间时段进行投切,各相补偿功率略有差异,三相共动作4次,严格遵循操作次数限制;而节点33则仅需投入1组CB,即满足多时段需求。在日前优化阶段,通过OLTC电压比调节与CB离散无功功率补偿,有助于降低网络有功功率损耗,缓解电压越限问题。
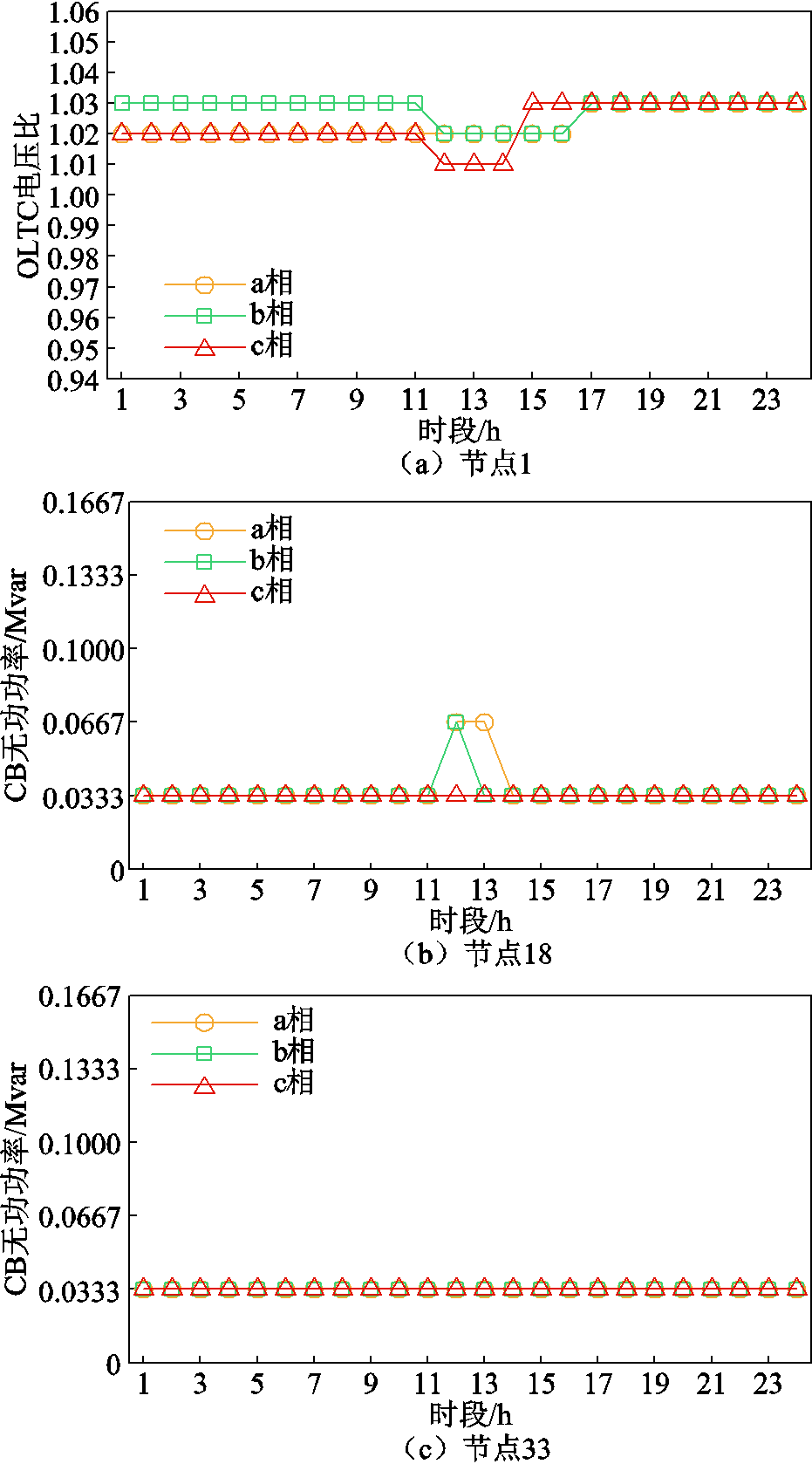
图2 OLTC和CB的日前优化调度结果
Fig.2 Day-ahead optimal dispatch results of OLTC and CBs
4.1.2 日前优化计算性能分析
为探究三相耦合互阻抗对日前优化结果的影响,设置两种方法进行对比分析:
方法1(传统方法):采用三相解耦形式的二阶锥松弛进行建模,调用Gurobi求解器进行求解。
方法2(本文方法):采用三相耦合形式的二阶锥松弛进行建模,调用Gurobi求解器进行求解。
首先,考虑到节点功率平衡与欧姆定律约束中均包含三相耦合互阻抗,故定义拟合误差指标以衡量不同建模方法所得解对上述等式约束的拟合程度,即
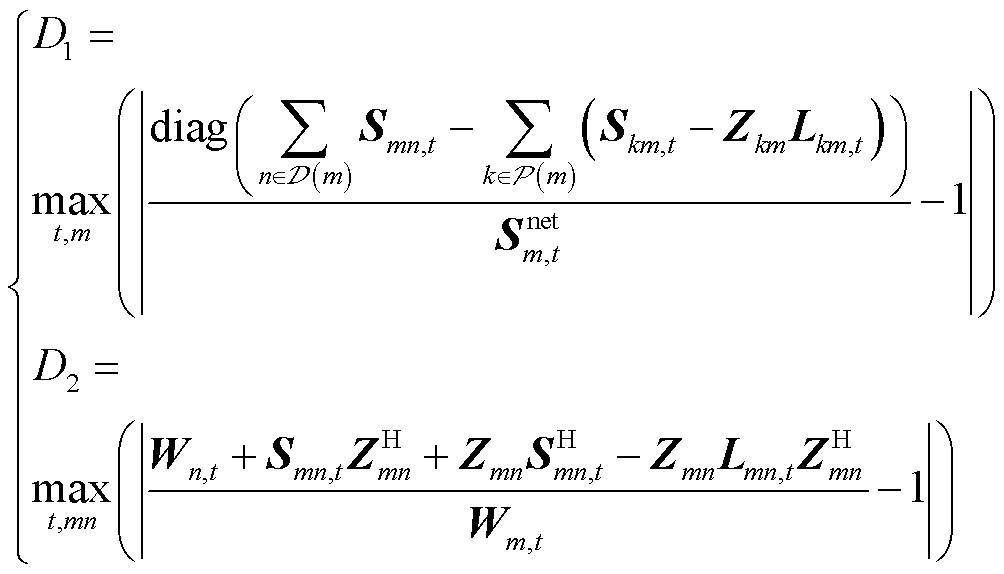 (42)
(42)
其次,为衡量二阶锥松弛的准确性,定义松弛偏差度指标为
 (43)
(43)
不同建模方法下拟合误差与松弛偏差度见表2。从中可见,在三相不平衡有源配电网中,方法1由于未考虑三相耦合关系,存在较大计算误差;方法2由于计及三相耦合关系,拟合误差与松弛偏差度均在10-3以下,且结果均满足秩约束,表明松弛后的最优解仍在原始非凸可行域内,验证了日前优化阶段二阶锥松弛的准确性。
表2 不同建模方法计算结果对比
Tab.2 Comparison of calculation results of different modeling methods

方法D1D2DWDLDS 11.7×10-11.5×10-3——1.5×10-2 23.6×10-58.9×10-91.7×10-48.5×10-42.9×10-4
4.1.3 日内优化离线训练过程
在将DRL网络应用于求解三相不平衡有源配电网DOPF问题前,需先利用历史数据进行离线训练;参考深度学习全球交流社区[29]的推荐做法,初步确定超参数取值。同时,结合文献[30-31]中的思路,根据实际训练数据进行多次试错、调整。随后,将训练完成的模型应用于测试集进行性能评估,最终确定一组效果较优的超参数(见附表2)。
I-PPO算法离线训练过程如图3所示,该过程可分为三个阶段:0~2 000回合为探索阶段,智能体对环境还不太熟悉,主要以“探索试错”的方式进行初期自适应学习,随机选择动作,导致训练初期奖励值波动较大;2 000~15 000回合为学习阶段,智能体与环境不断交互并将获取的经验存入经验回放缓冲区,同时基于获取到的即时奖励指导模型参数的更新,通过持续性学习以获得最大化的累积奖励;15 000~20 000回合为收敛阶段,由于不同训练回合中DPV出力的波动性导致奖励值仍有小幅波动,随着过程推进,奖励值的波动逐渐趋于平稳,并最终收敛于目标值。
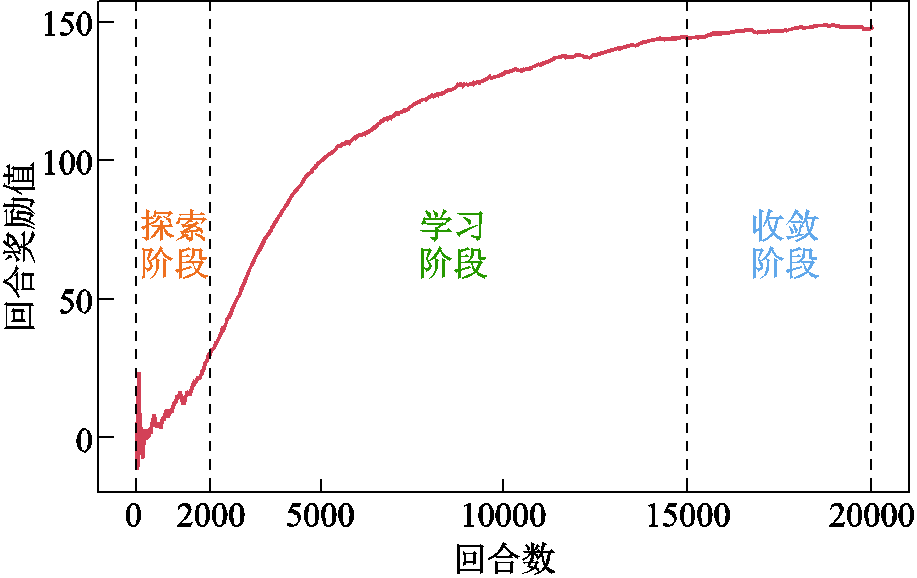
图3 I-PPO算法离线训练过程
Fig.3 Offline training process of I-PPO algorithm
智能体借助感知-行动-评价-学习的模式,在与环境的交互中持续积累经验,不断优化改进采取的动作行为以更好地适应环境,从而形成一套较优的策略,应用到日内在线优化调度过程中。
4.1.4 日内优化调度结果分析
为分析引入AM和DR约束对线路有功损耗与节点电压偏差的影响,选取以下四个情景进行比较:情景1——不引入AM和DR约束;情景2——仅考虑AM约束;情景3——仅考虑DR约束;情景4——同时采用AM和DR约束。各情景下在线优化调度结果对比见表3。
表3 不同情景下在线优化调度结果对比
Tab.3 Comparison of online optimal dispatch results under different scenarios
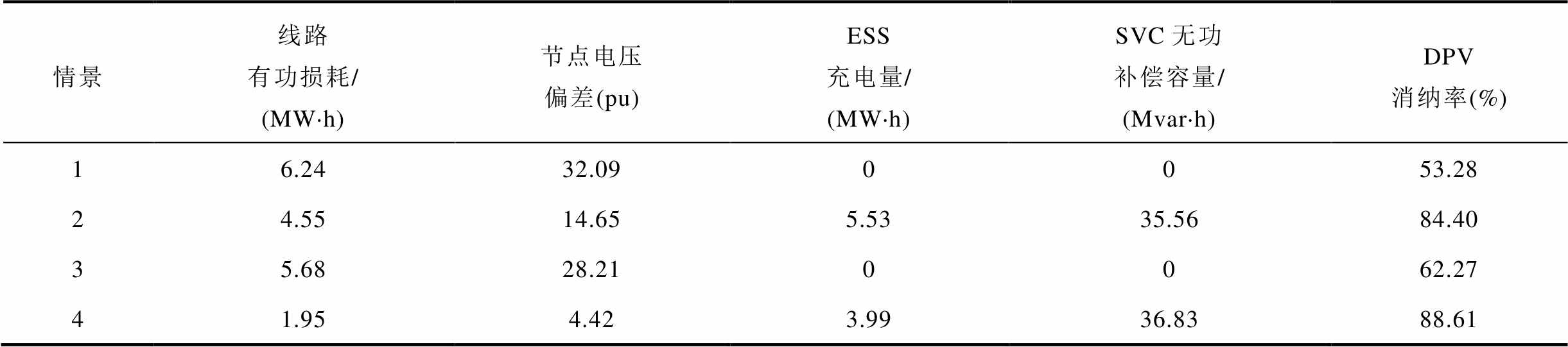
情景线路有功损耗/(MW·h)节点电压偏差(pu)ESS充电量/(MW·h)SVC无功补偿容量/(Mvar·h)DPV消纳率(%) 16.2432.090053.28 24.5514.655.5335.5684.40 35.6828.210062.27 41.954.423.9936.8388.61
从表3可见,情景1下线路有功损耗和节点电压偏差均为最高,情景4下线路有功损耗和节点电压偏差均为最低。情景4由于采用AM和DR约束,线路有功损耗和节点电压偏差分别为1.95 MW·h和4.42(pu),与情景1相比分别减少68.75%和86.23%。情景2与情景3由于考虑了AM或DR约束,线路有功损耗和节点电压偏差相比情景1均有降低。同时,情景2线路有功损耗和节点电压偏差相比于情景3分别降低19.89%和48.07%,表明AM相较于DR约束在降低线路有功损耗和节点电压偏差方面具有更好的效果。综上所述,将AM和DR约束应用于三相不平衡有源配电网DOPF中,可实现有功-无功协同优化调度,有效降低线路有功损耗,并缓解三相电压不平衡问题。
此外,情景2、3、4下DPV消纳率均优于情景1。这是因为情景2下ESS在DPV大发时段进行充电,情景3下EV参与DR进行时空转移,均可有效促进DPV消纳。进一步对比发现,情景2下的DPV消纳率优于情景3,表明AM约束效果优于DR。情景4综合考虑AM与DR约束,实现了DPV消纳率最大化。
图4展示了情景4下11:25—12:35时段DPV规模化消纳能力的评估结果。从中可见,除节点24和25之外,其余接有DPV的节点均能有效实现DPV的就地消纳,且消纳比例达到88%以上。在综合考虑AM与DR约束后,尽管节点24和25仍存在弃光现象,但其DPV消纳比例仍保持在36%以上,系统DPV整体消纳水平较高。节点24和25所出现的弃光现象揭示了这两个台区DPV的承载能力已经达到了极限。基于此,可以在配电网系统中对各节点的DPV消纳潜力进行评估。
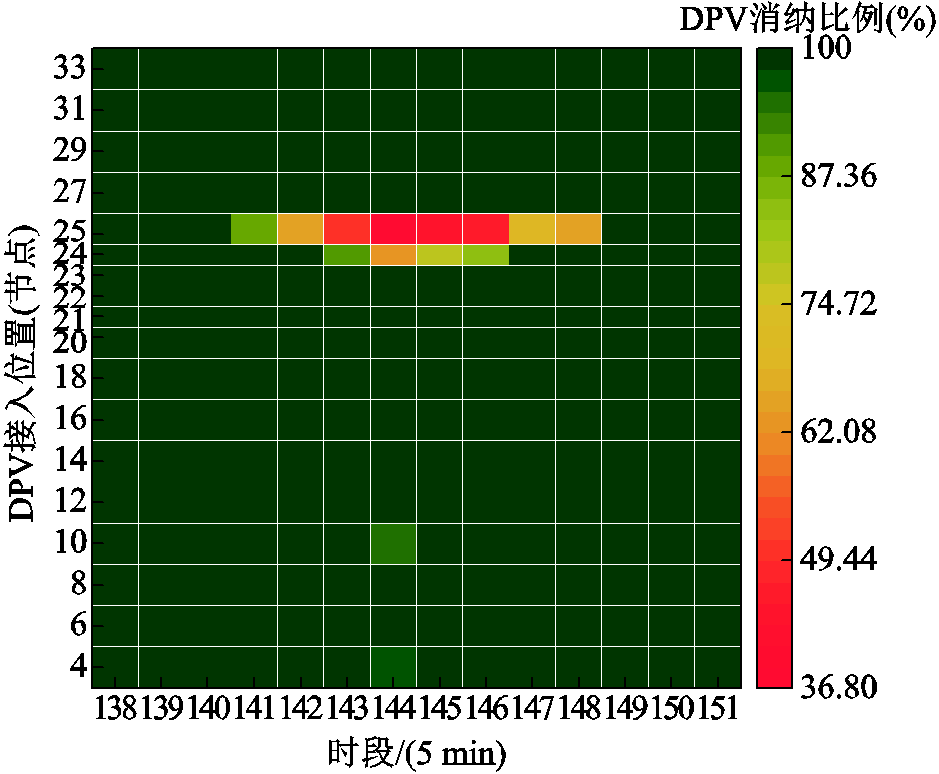
图4 情景4下DPV规模化消纳能力的评估结果
Fig.4 Assessment results of DPVs’ large-scale consumption capacity under scenario 4
情景4下11:00—13:00时段EV参与DR的评估结果如图5所示,其中正值表示移出,负值表示移入。通过将EV充电负荷从高负荷节点及时段向低负荷节点及时段转移,有效地缩小了配电网的负荷峰谷差,平稳了DPV出力波动。同时,确保了各节点EV参与DR的比例控制在预设的合理区间内。利用EV这一灵活资源,实现了充电负荷在时空上的灵活调度,提升了可再生能源的消纳能力。
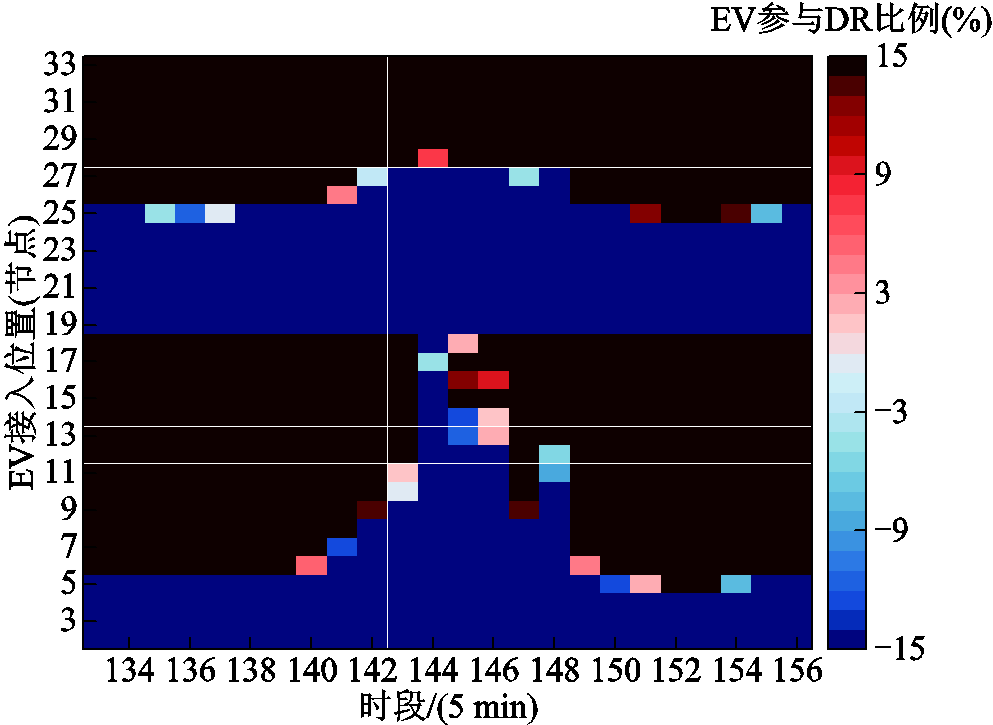
图5 情景4下EV参与DR的评估结果
Fig.5 Results of EVs participating in DR under scenario 4
图6展示了情景4下11:00—13:00时段各节点电压。此时段内,各节点各相电压分布相似,幅值均在0.98(pu)~1.02(pu)范围内。这表明,实施有功与无功协同优化调度策略后,电压分布得到优化,电压质量提升,偏移度减小,满足安全约束。
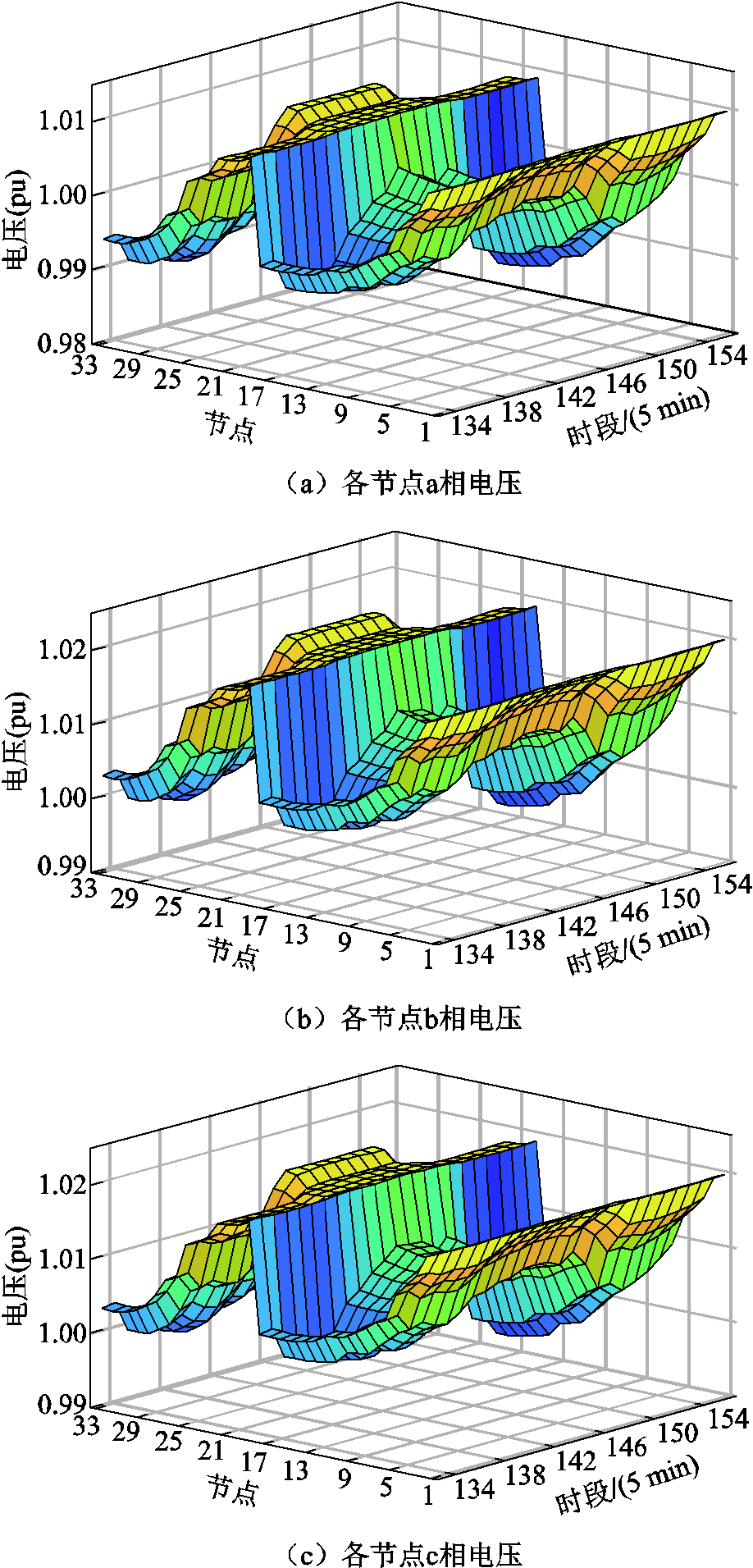
图6 情景4下各节点电压的计算结果
Fig.6 Calculation results of each bus voltage under scenario 4
图7对比了情景4下11:00—13:00时段三相电压不平衡度优化前后结果。采用AM和DR约束后,配电网各节点三相电压不平衡度从初始的100%大幅下降至2%以下,符合国家相关标准,验证了本文所提方法的有效性。
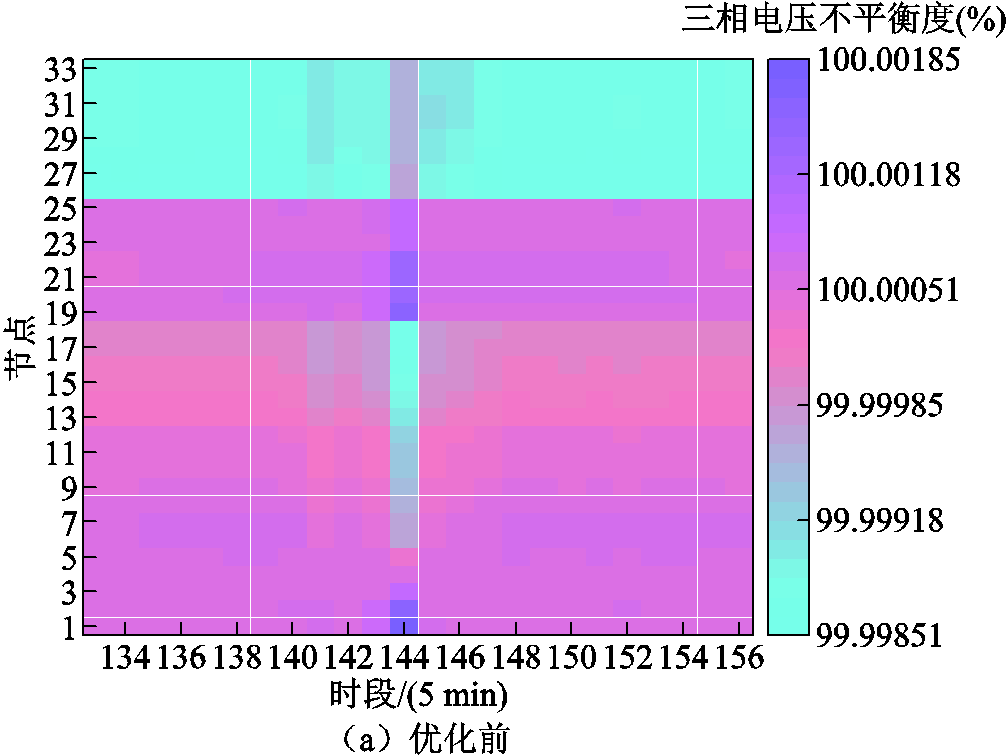
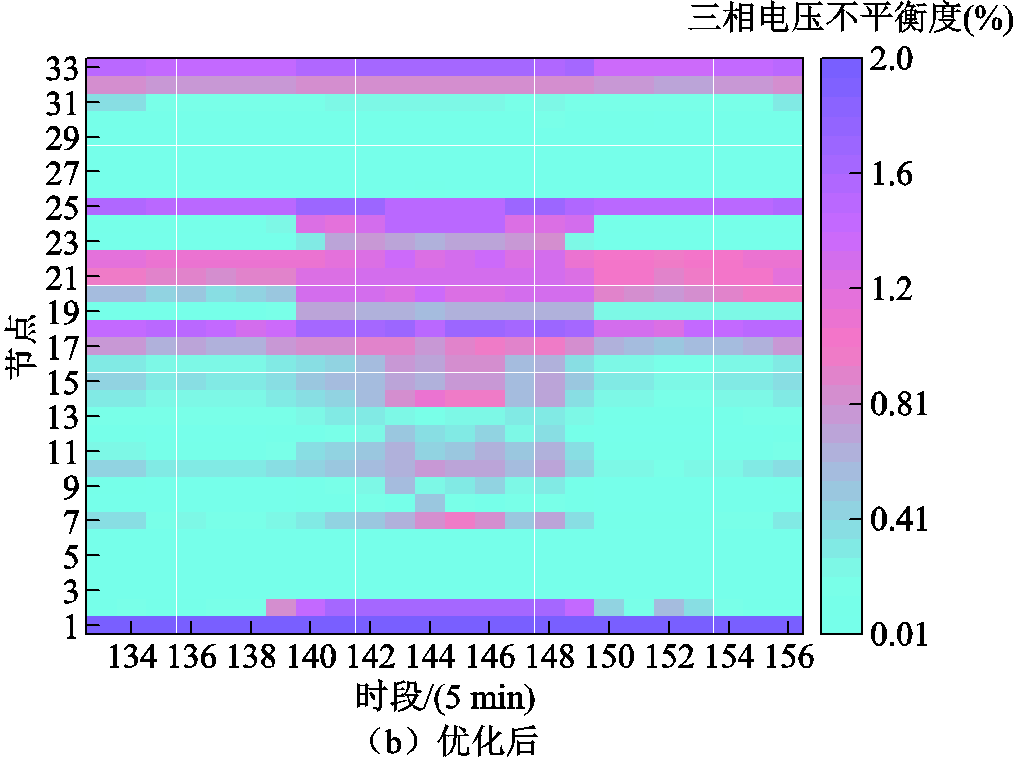
图7 情景4下三相电压不平衡度优化结果对比
Fig.7 Comparison of three-phase voltage unbalance degrees before and after optimization under scenario 4
4.1.5 日内优化计算性能分析
在情景4下,分别采用Gurobi求解器与I-PPO算法进行日内调度,对其优化结果展开分析。基于测试日的优化数据,对比两种求解方式下的线路有功损耗、节点电压偏差及平均决策时间,结果见表4。
表4 不同求解方式下优化结果对比
Tab.4 Comparison of optimization results under different solution methods

求解方式线路有功损耗/(MW·h)节点电压偏差(pu)平均决策时间/s Gurobi1.944.39120.1 I-PPO1.954.424.1
从表4中可见,在日内优化调度结果方面,商业求解器Gurobi因能获取MISOCP问题的全局最优解,线路有功损耗和节点电压偏差更小,但I-PPO算法所得结果与之相近,差异均在1%以内,说明I-PPO算法在获取最优解质量上表现良好;在日内平均决策时间方面,I-PPO算法明显低于Gurobi求解器,这是因为I-PPO算法借助神经网络直接输出决策结果,跳过了复杂的迭代过程,极大地缩减了决策时间。这既体现了I-PPO算法求解两阶段DOPF问题的有效性,凸显了其在调压降损方面的潜力,也证明了其相较于传统商业求解器具备s级在线决策优势。
进一步在更大规模的IEEE 123节点配电网上进行测试。该系统含121条支路,集成了DPV、EV、ESS、SVC、CB、OLTC。基准电压为4.16 kV,总负荷功率为3 490 kW有功功率及1 920 kvar无功功率。该系统存在大量不平衡供电负荷及非对称参数支路,且各相有功负荷相较于IEEE 33节点系统差异更为显著,可达几十kW。此外,为深入测试本文方法在更复杂数值条件下的效果,研究基于文献[13]的网络参数,对节点负荷和支路参数进行了适当调整。具体包括:将部分节点负荷设置为单相供电,并模拟了支路自阻抗和互阻抗为零的极端情况(尽管实际运行中配电线路的自阻抗和互阻抗通常非零)。这些人为设定的复杂因素显著提升了测试的挑战性。系统结构如附图3所示,基本配置参数同算例1。
4.2.1 算法性能分析
将本文所提I-PPO算法与HRS-PPO、EK-PPO、PPO、SAC、DDPG、DQN六种DRL算法进行对比,训练曲线如图8所示。
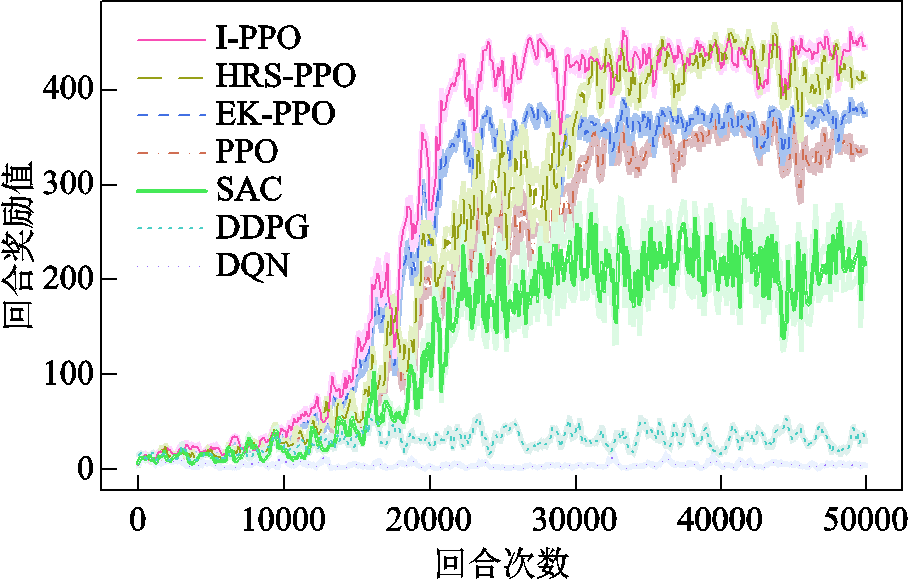
图8 不同DRL算法下训练过程奖励曲线
Fig.8 Training process reward curves under different DRL algorithms
从图8中可见,DQN算法对动作进行离散化,从有限的动作值中选择行动,降低了优化决策精度,易引发“维数灾难”,使智能体收敛失败;DDPG算法则因不能进行有效的梯度训练,存在Actor网络对Q值过估计的问题,从而学习到错误信息,影响系统的最终性能,同样导致收敛失败;SAC算法虽能收敛,但调度效果波动幅度大,智能体输出的动作易违反系统安全运行约束,使回合提前结束;PPO算法因其对超参数的低敏感度,可以避免大量的策略更新和不理想的动作选择,调度效果逐步提升;EK-PPO算法借助EK引导智能体学习优质调度策略,收敛速度明显快于PPO算法,但最终奖励值低于HRS-PPO算法和I-PPO算法;HRS-PPO算法动态耦合即时奖励与长期性能指标,能为智能体提供积极正向奖励,最终奖励值显著优于EK-PPO算法和PPO算法,但因缺乏EK引导,收敛速度不及EK-PPO算法;I-PPO算法融合了EK-PPO算法与HRS-PPO算法的优势,利用EK强化智能体对三相电压不平衡度约束的执行能力,引导其减少DPV有功削减,同时借助HRS机制优化奖励函数,综合评估智能体的实时与最终性能,对满足系统安全运行约束的行为给予正向激励,计算性能最佳。
4.2.2 灵敏度分析
针对本文所提I-PPO算法超参数进行灵敏度分析,分析过程中每次仅改变一个参数值,其余参数保持不变,结果如图9所示。
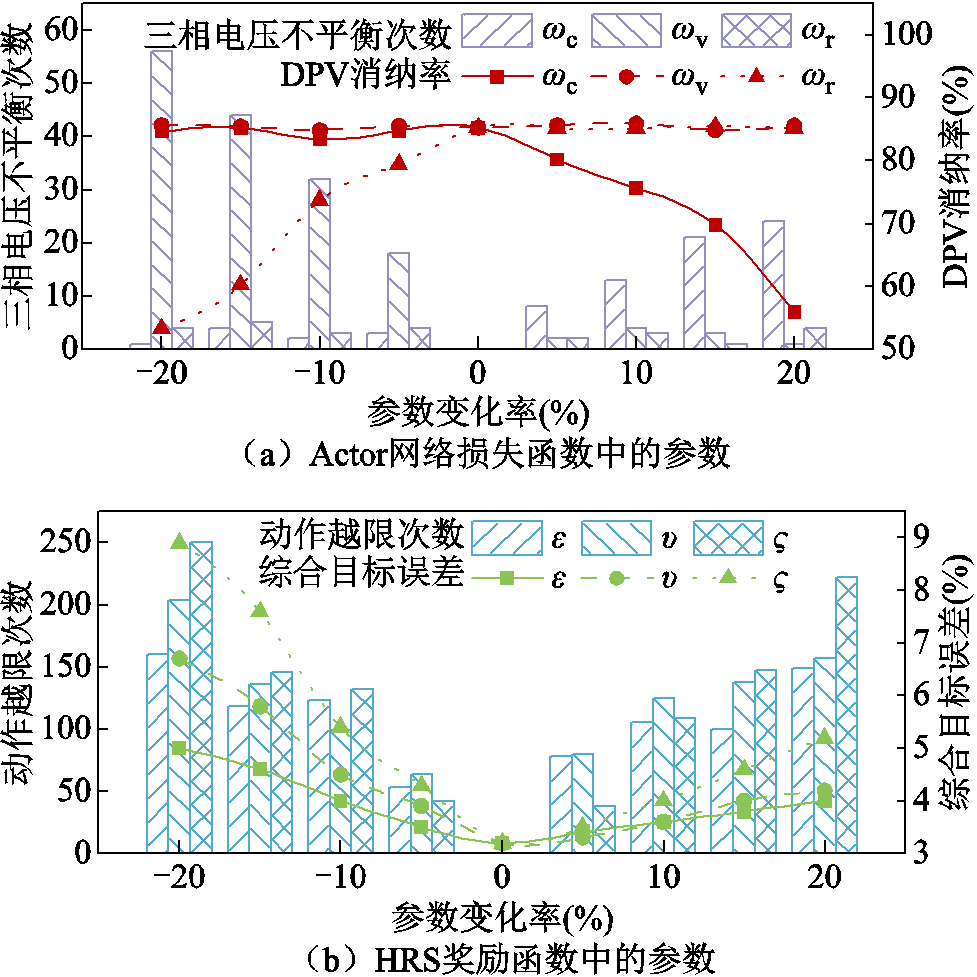
图9 超参数灵敏度分析结果
Fig.9 Sensitivity analysis of hyper-parameters
从图9a可知,当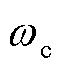 变化率自0增至20%时,因的增大削弱了EK对智能体的精细化引导,三相电压不平衡次数从0上升至24次,DPV消纳率由85.3%下降至59.9%;而当
变化率自0增至20%时,因的增大削弱了EK对智能体的精细化引导,三相电压不平衡次数从0上升至24次,DPV消纳率由85.3%下降至59.9%;而当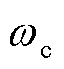 变化率从0降至-20%时,由于EK的引导作用已趋于饱和,三相电压不平衡次数和DPV消纳率均基本稳定。当
变化率从0降至-20%时,由于EK的引导作用已趋于饱和,三相电压不平衡次数和DPV消纳率均基本稳定。当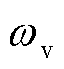 变化率从0降至-20%时,因的减小削弱了三相电压不平衡度约束正则项的引导,三相电压不平衡次数激增至56次;当变化率从0增至20%时,由于该正则项引导作用趋于饱和,三相电压不平衡次数保持稳定,且在-20%~20%的变化率区间内,DPV消纳率几乎不受影响,这归因于不同正则项间耦合关系微弱。当
变化率从0降至-20%时,因的减小削弱了三相电压不平衡度约束正则项的引导,三相电压不平衡次数激增至56次;当变化率从0增至20%时,由于该正则项引导作用趋于饱和,三相电压不平衡次数保持稳定,且在-20%~20%的变化率区间内,DPV消纳率几乎不受影响,这归因于不同正则项间耦合关系微弱。当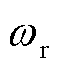 变化率从0降至-20%时,因的减小削弱了DPV消纳率正则项的引导,DPV消纳率锐减至53.3%;当变化率从0增至20%时,由于该正则项引导作用趋于饱和,DPV消纳率基本不变,同时在变化率区间内,三相电压不平衡次数保持稳定,这同样源于不同正则项间的弱耦合关系。
变化率从0降至-20%时,因的减小削弱了DPV消纳率正则项的引导,DPV消纳率锐减至53.3%;当变化率从0增至20%时,由于该正则项引导作用趋于饱和,DPV消纳率基本不变,同时在变化率区间内,三相电压不平衡次数保持稳定,这同样源于不同正则项间的弱耦合关系。
由图9b可知,在参数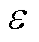 、
、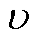 、
、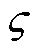 分别于-20%~20%范围内变动时,智能体动作越限次数与综合目标误差均呈现先降后升的趋势。具体而言,当变动时,智能体动作越限次数由160次降至0次再增至149次,综合目标误差由5%降至3.2%再增至4%;当变动时,智能体动作越限次数由204次降至0次再增至157次,综合目标误差由6.7%降至3.2%再增至4.2%;当变动时,智能体动作越限次数由250次降至0次再增至222次,综合目标误差由8.9%降至3.2%再增至5.2%。综合对比,智能体动作越限次数和综合目标误差对的变化最为敏感,对的敏感性次之,对的敏感性最低。究其原因,是与最终奖励相关的激励参数,而最终奖励用于全面评估智能体执行动作的性能,反映了全时段高额奖励的累计过程,因此对硬约束的敏感性最高;是与即时奖励相关的激励参数,则是用于将优化目标和单步奖励置于同一数量级的系数,二者主要反映当前时段的动作效果,故对硬约束的敏感性不如。
分别于-20%~20%范围内变动时,智能体动作越限次数与综合目标误差均呈现先降后升的趋势。具体而言,当变动时,智能体动作越限次数由160次降至0次再增至149次,综合目标误差由5%降至3.2%再增至4%;当变动时,智能体动作越限次数由204次降至0次再增至157次,综合目标误差由6.7%降至3.2%再增至4.2%;当变动时,智能体动作越限次数由250次降至0次再增至222次,综合目标误差由8.9%降至3.2%再增至5.2%。综合对比,智能体动作越限次数和综合目标误差对的变化最为敏感,对的敏感性次之,对的敏感性最低。究其原因,是与最终奖励相关的激励参数,而最终奖励用于全面评估智能体执行动作的性能,反映了全时段高额奖励的累计过程,因此对硬约束的敏感性最高;是与即时奖励相关的激励参数,则是用于将优化目标和单步奖励置于同一数量级的系数,二者主要反映当前时段的动作效果,故对硬约束的敏感性不如。
针对传统数学规划方法在线决策的计算瓶颈及DRL算法在多时间尺度AM设备调节中的局限性,本文提出一种内嵌数据驱动的三相不平衡有源配电网“日前-日内”两阶段DOPF调度方法。以IEEE 33节点与123节点三相辐射状配电网为算例对所提方法进行验证,得到如下结论:
1)在日前优化阶段,计及相间耦合和时间耦合关系,通过采用lift-and-project松弛方式的MISOCP,确定CB、OLTC等慢速离散调节设备的挡位。算例分析表明,本文所提方法的拟合误差与松弛偏差度均小于10-3,相较传统方法提高了计算精度。
2)在日内优化阶段,将DOPF问题转换为MDP,基于I-PPO算法对DPV、EV、ESS、SVC等快速连续调节设备进行在线调控。通过综合考虑AM与DR约束,实现了有源配电网调压降损协同优化,并确保三相电压不平衡度满足国标2%的限值要求。
3)本文所提I-PPO算法,一方面通过引入EK,不仅增强了三相电压不平衡度约束的执行能力,还有效地引导智能体减少了DPV有功削减;另一方面,采用动态耦合即时奖励与长期性能指标的HRS机制,以适应日前-日内两阶段多时间尺度的调度需求。算例分析表明,该算法可以兼顾求解效率和精度,具备更优的计算性能。
后续研究将考虑有源配电网中不同种类新型储能对调度策略产生的影响,以进一步完善所提方法。
附 录
1. 传统奖励函数设计
奖励函数的核心作用是引导智能体寻求最优调度策略,代表当前时段环境反馈给智能体的动作评价。它通常与优化目标一致,因此首要考虑将优化目标转换为奖励函数最大化的一部分,即
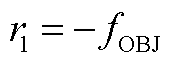 (A1)
(A1)
为提升强化学习算法的收敛速度并优化控制效果,环境会对智能体采取的不合理动作施加惩罚措施。因此,在奖励函数中引入动作越限惩罚项。动作越限惩罚项包括节点电压越限惩罚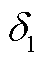 、支路电流越限惩罚
、支路电流越限惩罚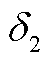 、支路传输功率越限惩罚
、支路传输功率越限惩罚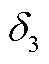 、节点注入功率越限惩罚
、节点注入功率越限惩罚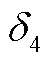 ,即
,即
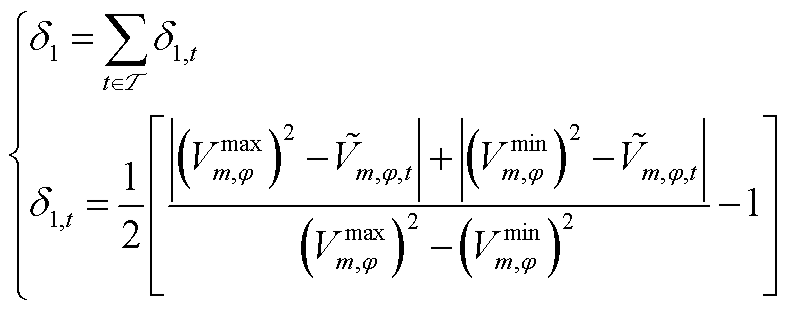 (A2)
(A2)
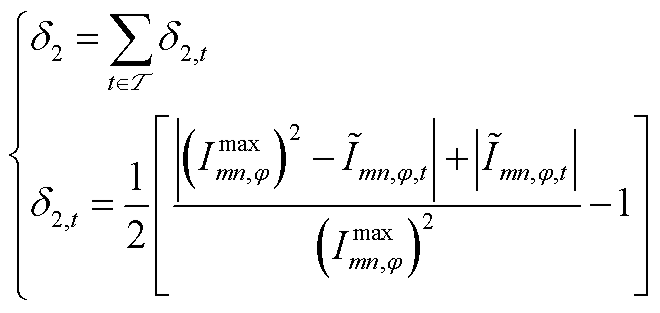 (A3)
(A3)
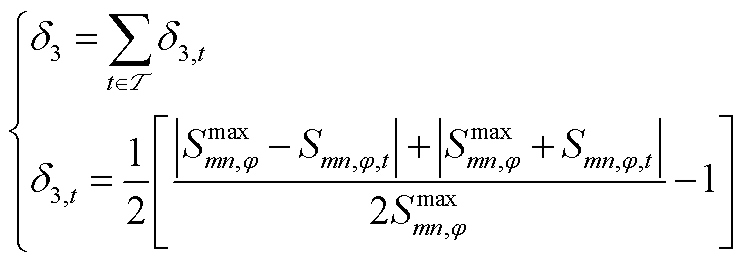 (A4)
(A4)
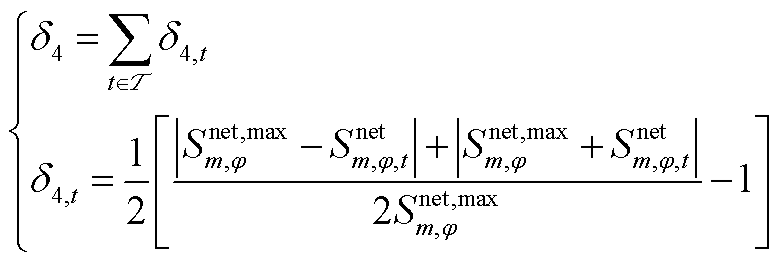 (A5)
(A5)
将各类惩罚项求和取负转换为奖励函数形式,有
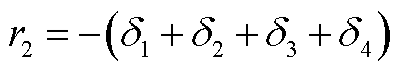 (A6)
(A6)
综上所述,传统奖励函数为
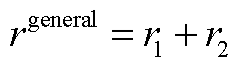 (A7)
(A7)
2. 算例相关参数
附图1 IEEE 33节点配电网结构
App.Fig.1 IEEE 33-bus distribution network structure
附图2 负荷与DPV归一化功率预测曲线
App.Fig.2 Load and DPV normalized power prediction curves
附表1 AM设备配置参数
App.Tab.1 AM device configuration parameters
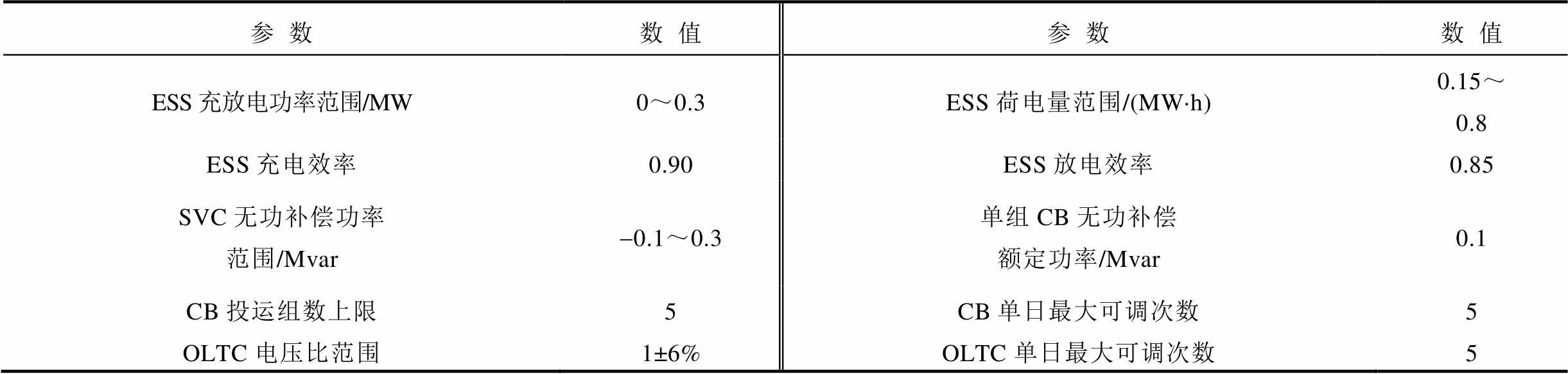
参数数值参数数值 ESS充放电功率范围/MW0~0.3ESS荷电量范围/(MW·h)0.15~0.8 ESS充电效率0.90ESS放电效率0.85 SVC无功补偿功率范围/Mvar-0.1~0.3单组CB无功补偿额定功率/Mvar0.1 CB投运组数上限5CB单日最大可调次数5 OLTC电压比范围1±6%OLTC单日最大可调次数5
附表2 I-PPO算法超参数
App.Tab.2 Hyper-parameters of I-PPO algorithm
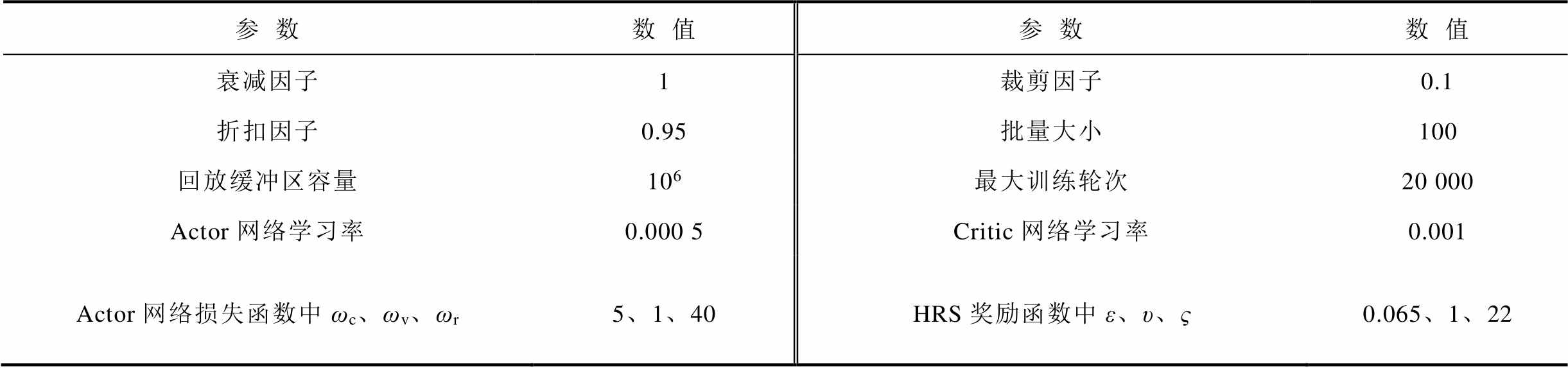
参数数值参数数值 衰减因子1裁剪因子0.1 折扣因子0.95批量大小100 回放缓冲区容量106最大训练轮次20 000 Actor网络学习率0.000 5Critic网络学习率0.001 Actor网络损失函数中ωc、ωv、ωr5、1、40HRS奖励函数中ε、υ、ς0.065、1、22
附图3 IEEE 123节点配电网结构
App.Fig.3 IEEE 123-bus distribution network structure
参考文献
[1] 国家发展改革委, 国家能源局, 国家数据局. 关于印发《加快构建新型电力系统行动方案(2024—2027年)》的通知[EB/OL]. (2024-07-25)[2025-04-06]. https://www.gov.cn/zhengce/zhengceku/202408/ content_6966863.htm.
[2] 国家能源局. 关于印发《配电网高质量发展行动实施方案(2024—2027年)》的通知[EB/OL]. (2024-08-02) [2025-04-06]. https://www.gov.cn/zhengce/zhengceku/ 202408/content_6969919.htm.
[3] 国家发展改革委, 国家能源局. 关于新形势下配电网高质量发展的指导意见[EB/OL]. (2024-02-06) [2025-04-06]. https://www.gov.cn/zhengce/zhengceku/ 202403/content_6935790.htm.
[4] 李宗晟, 张璐, 张志刚, 等. 考虑柔性资源多维价值标签的交直流配电网灵活调度[J]. 电工技术学报, 2024, 39(9): 2621-2634.
Li Zongsheng, Zhang Lu, Zhang Zhigang, et al. A flexible scheduling method of AC/DC hybrid distribution network considering the multi-dimensional value tags of flexible resources[J]. Transactions of China Electrotechnical Society, 2024, 39(9): 2621-2634.
[5] 王守相, 尹孜阳, 赵倩宇. 考虑多供电层级耦合的中低压配电网分布式光伏承载力一体化精细评估方法[J]. 电工技术学报, 2025, 40(6): 1930-1944.
Wang Shouxiang, Yin Ziyang, Zhao Qianyu. A precise distributed PV hosting capability evaluation method for MV and LV distribution network considering the coupling of multiple power supply layers[J]. Transactions of China Electrotechnical Society, 2025, 40(6): 1930-1944.
[6] 张剑, 崔明建, 何怡刚. 结合数据驱动与物理模型的主动配电网双时间尺度电压协调优化控制[J]. 电工技术学报, 2024, 39(5): 1327-1339.
Zhang Jian, Cui Mingjian, He Yigang. Dual timescales coordinated and optimal voltages control in distribution systems using data-driven and physical optimization[J]. Transactions of China Electrotechnical Society, 2024, 39(5): 1327-1339.
[7] 于惠钧, 马凡烁, 陈刚, 等. 基于改进灰狼优化算法的含光伏配电网动态无功优化[J]. 电气技术, 2024, 25(4): 7-15, 58.
Yu Huijun, Ma Fanshuo, Chen Gang, et al. Dynamic reactive power optimization of photovoltaic distribution network based on improved gray wolf optimization algorithm[J]. Electrical Engineering, 2024, 25(4): 7-15, 58.
[8] Farivar M, Low S H. Branch flow model: relaxations and convexification: part I[J]. IEEE Transactions on Power Systems, 2013, 28(3): 2554-2564.
[9] Farivar M, Low S H. Branch flow model: relaxations and convexification: part II[J]. IEEE Transactions on Power Systems, 2013, 28(3): 2565-2572.
[10] 高红均, 刘俊勇, 沈晓东, 等. 主动配电网最优潮流研究及其应用实例[J]. 中国电机工程学报, 2017, 37(6): 1634-1645.
Gao Hongjun, Liu Junyong, Shen Xiaodong, et al. Optimal power flow research in active distribution network and its application examples[J]. Proceedings of the CSEE, 2017, 37(6): 1634-1645.
[11] 姚良忠, 徐箭, 赵大伟, 等. 高比例可再生能源电力系统优化运行[M]. 北京: 科学出版社, 2022.
[12] 陈艳波, 张智, 徐井强, 等. 广义快速分解潮流计算方法[J]. 电力系统自动化, 2019, 43(6): 85-91.
Chen Yanbo, Zhang Zhi, Xu Jingqiang, et al. Generalized fast decoupled load flow algorithm[J]. Automation of Electric Power Systems, 2019, 43(6): 85-91.
[13] 刘一兵, 吴文传, 张伯明, 等. 基于混合整数二阶锥规划的三相有源配电网无功优化[J]. 电力系统自动化, 2014, 38(15): 58-64.
Liu Yibing, Wu Wenchuan, Zhang Boming, et al. Reactive power optimization for three-phase distribution networks with distributed generators based on mixed integer second-order cone programming [J]. Automation of Electric Power Systems, 2014, 38(15): 58-64.
[14] 刘一兵, 吴文传, 张伯明, 等. 基于混合整数二阶锥规划的主动配电网有功–无功协调多时段优化运行[J]. 中国电机工程学报, 2014, 34(16): 2575-2583.
Liu Yibing, Wu Wenchuan, Zhang Boming, et al. A mixed integer second-order cone programming based active and reactive power coordinated multi-period optimization for active distribution network[J]. Proceedings of the CSEE, 2014, 34(16): 2575-2583.
[15] 徐添锐, 丁涛, 李立, 等. 适应三相不平衡主动配电网无功优化的二阶锥松弛模型[J]. 电力系统自动化, 2021, 45(24): 81-88.
Xu Tianrui, Ding Tao, Li Li, et al. Second-order cone relaxation model adapting to reactive power optimization for three-phase unbalanced active distribution network[J]. Automation of Electric Power Systems, 2021, 45(24): 81-88.
[16] 巨云涛, 黄炎, 张若思. 基于二阶锥规划凸松弛的三相交直流混合主动配电网最优潮流[J]. 电工技术学报, 2021, 36(9): 1866-1875.
Ju Yuntao, Huang Yan, Zhang Ruosi. Optimal power flow of three-phase hybrid AC-DC in active distribution network based on second order cone programming[J]. Transactions of China Electrotechnical Society, 2021, 36(9): 1866-1875.
[17] 孙乾皓, 张耀, 周一丹, 等. 基于半正定规划的交直流主动配电网三相有功无功联合优化[J]. 电工技术学报, 2024, 39(9): 2608-2620.
Sun Qianhao, Zhang Yao, Zhou Yidan, et al. Three-phase active-reactive power optimization of AC-DC active distribution network based on semi-definite programming[J]. Transactions of China Electrotechnical Society, 2024, 39(9): 2608-2620.
[18] Jacob R A, Paul S, Chowdhury S, et al. Real-time outage management in active distribution networks using reinforcement learning over graphs[J]. Nature Communications, 2024, 15: 4766.
[19] 冯斌, 胡轶婕, 黄刚, 等. 基于深度强化学习的新型电力系统调度优化方法综述[J]. 电力系统自动化, 2023, 47(17): 187-199.
Feng Bin, Hu Yijie, Huang Gang, et al. Review on optimization methods for new power system dispatch based on deep reinforcement learning[J]. Automation of Electric Power Systems, 2023, 47(17): 187-199.
[20] Zhang Ying, Wang Xinan, Wang Jianhui, et al. Deep reinforcement learning based volt-VAR optimization in smart distribution systems[J]. IEEE Transactions on Smart Grid, 2021, 12(1): 361-371.
[21] 李鹏, 钟瀚明, 马红伟, 等. 基于深度强化学习的有源配电网多时间尺度源荷储协同优化调控[J]. 电工技术学报, 2025, 40(5): 1487-1502.
Li Peng, Zhong Hanming, Ma Hongwei, et al. Multi-timescale optimal dispatch of source-load-storage coordination in active distribution network based on deep reinforcement learning[J]. Transactions of China Electrotechnical Society, 2025, 40(5): 1487-1502.
[22] Liang Tao, Zhang Xiaochan, Tan Jianxin, et al. Deep reinforcement learning-based optimal scheduling of integrated energy systems for electricity, heat, and hydrogen storage[J]. Electric Power Systems Research, 2024, 233: 110480.
[23] El Helou R, Kalathil D, Xie Le. Fully decentralized reinforcement learning-based control of photovoltaics in distribution grids for joint provision of real and reactive power[J]. IEEE Open Access Journal of Power and Energy, 2021, 8: 175-185.
[24] 毕刚. 基于深度强化学习的有源配电网协同调压控制方法研究[D]. 南京: 南京邮电大学, 2022.
Bi Gang. Research on coordinated voltage regulation methods of active distribution networks based on deep reinforcement learning[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2022.
[25] Gan Lingwen, Low S H. Convex relaxations and linear approximation for optimal power flow in multiphase radial networks[C]//2014 Power Systems Computation Conference, Wroclaw, Poland, 2014: 1-9.
[26] Horn R A, Johnson C R. Matrix Analysis[M]. Cambridge: Cambridge University Press, 2012.
[27] Kocuk B, Dey S S, Sun X A. Strong SOCP relaxations for the optimal power flow problem[J]. Operations Research, 2016, 64(6): 1177-1196.
[28] 国家质量监督检验检疫总局, 中国国家标准化管理委员会. 电能质量三相电压不平衡: GB/T 15543—2008[S]. 北京: 中国标准出版社, 2008.
[29] Goodfellow I, Bengio Y, Courville A. Deep Learning [M]. Cambridge: MIT Press, 2016.
[30] Wang Yi, Qiu Dawei, Sun Mingyang, et al. Secure energy management of multi-energy microgrid: a physical-informed safe reinforcement learning approach [J]. Applied Energy, 2023, 335: 120759.
[31] 杨志学, 任洲洋, 孙志媛, 等. 基于近端策略优化算法的新能源电力系统安全约束经济调度方法[J]. 电网技术, 2023, 47(3): 988-998.
Yang Zhixue, Ren Zhouyang, Sun Zhiyuan, et al. Security-constrained economic dispatch of renewable energy integrated power systems based on proximal policy optimization algorithm[J]. Power System Technology, 2023, 47(3): 988-998.
A Two-Stage Dynamic Optimal Power Flow Dispatch Method for Three-Phase Unbalanced Active Distribution Networks Incorporating Data-Driven Approaches
Abstract In the context of energy transition and the construction of new type power systems, distribution networks are gradually evolving into a critical link for supporting the consumption of renewable energy. The large-scale integration of distributed photovoltaic systems and electric vehicles has driven a structural transformation of distribution networks from a unidirectional radial topology to a bidirectional interactive one, leading to technical challenges such as bus voltage violations, increased network losses, and three-phase voltage unbalance. Traditional mathematical programming methods face challenges due to their high computational complexity, which makes online decision-making difficult to implement. Meanwhile, deep reinforcement learning algorithms exhibit limitations in managing the regulation of multi-timescale active management devices. There is an urgent need to research operational adjustment strategies tailored to the characteristics of active distribution networks to ensure their safe, stable, and efficient operation.
To address these issues, a “day-ahead and intra-day” two-stage dynamic optimal power flow dispatch method for three-phase unbalanced active distribution networks is proposed, incorporating data-driven approaches. This method leverages the advantages of both physical mechanism modeling and data-driven learning to achieve refined coordinated control of multiple types of regulation resources.Firstly, considering the constraints of active management and demand response, a dynamic optimal power flow model for three-phase unbalanced active distribution networks is established, with the objectives of voltage regulation and loss reduction. Then, at the hour-level long timescale of day-ahead dispatch, the tap positions of slow discrete regulating devices are determined using mixed-integer second-order cone programming with lift-and-project relaxation. At the minute-level short timescale of intra-day dispatch, the dynamic optimal power flow problem is formulated as a Markov decision process, and an improved proximal policy optimization algorithm based on expert knowledge and a hierarchical reward shaping mechanism is proposed for online dispatch of fast continuous regulating devices.
Simulation analyses are conducted using the IEEE 33-bus and 123-bus three-phase radial distribution networks as case studies, drawing the following conclusions: (1) During the day-ahead optimization stage, considering the inter-phase and temporal coupling relationships, the tap positions of slow discrete regulating devices such as capacitor banks and on-load tap-changers are determined by using mixed-integer second-order cone programming with lift-and-project relaxation. Both the fitting error and the relaxation deviation degree of the proposed method are less than 10-3, indicating an improvement in computational accuracy compared to traditional methods. (2) During the intra-day optimization stage, the dynamic optimal power flow problem is transformed into a Markov decision process, and online control of fast continuous regulating devices such as distributed photovoltaic systems, electric vehicles, energy storage systems, and static var compensators is carried out based on the improved proximal policy optimization algorithm. By comprehensively considering the constraints of active management and demand response, a collaborative optimization of voltage regulation and loss reduction in active distribution networks is achieved, while ensuring that the three-phase voltage unbalance degree meets the national standard limit of 2%. (3)The proposed improved proximal policy optimization algorithm, on one hand, enhances the enforcement capability of the three-phase voltage unbalance degree constraint and effectively guides the agent to reduce active power curtailment of distributed photovoltaic systems by introducing expert knowledge. On the other hand, it adopts a hierarchical reward shaping mechanism that dynamically couples the immediate reward with long-term performance indicators to adapt to the multi-timescale dispatch requirements of the day-ahead and intra-day stages. The algorithm can balance both solution efficiency and accuracy, exhibiting superior computational performance.
keywords:Active distribution network, voltage regulation and loss reduction, three-phase unbalance, two-stage dynamic optimal power flow, mixed-integer second-order cone programming, improved proximal policy optimization
中图分类号:TM732
DOI: 10.19595/j.cnki.1000-6753.tces.250556
国家自然科学基金(U24B2083, 52407098)和国家资助博士后研究人员计划(GZC20240463)资助项目。
收稿日期 2025-04-08
改稿日期 2025-05-14
陈艳波 男,1982年生,教授,博士生导师,研究方向为新能源电力系统优化与分析。
E-mail:chenyanbo@ncepu.edu.cn(通信作者)
张 智 男,1994年生,博士,讲师,研究方向为新能源电力系统规划和运行。
(编辑 赫 蕾)