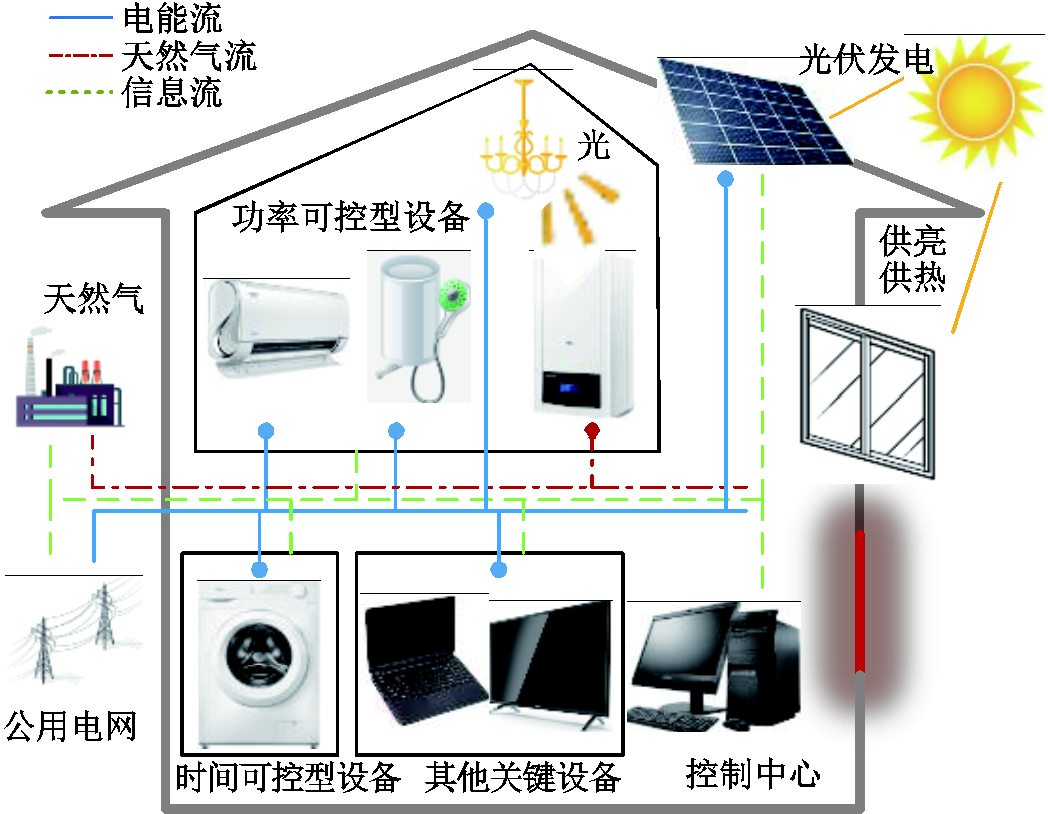
图1 住宅混合能源系统结构示意图
Fig.1 Schematic diagram of residential hybrid energy system structure
摘要 为应对住宅混合能源系统中设备运行差异性与复杂不确定性,该文提出一种领域知识嵌入深度强化学习的住宅混合能源系统能量优化管理方法。首先,构建含气/电设备的住宅混合能源系统优化运行模型,基于系统能量优化管理目标,设计住宅用能设备的优化知识规则;其次,构建领域知识嵌入深度强化学习的住宅能量优化管理框架,设计基于离散-连续混合策略的近端策略优化(PPO)方法,进行不同离散、连续类型设备的优化管理决策,并将领域知识嵌入深度强化学习的训练过程,提高住宅能量优化策略的训练效率;进而,开发一种基于指数概率函数的联动训练机制,以协调随机探索、PPO探索和基于知识规则探索的概率;最后,算例结果表明,所提方法能够自适应系统的不确定性,实时优化住宅气/电设备的运行以降低用能成本,并显著提高住宅优化策略的训练效率。
关键词:住宅混合能源系统 领域知识嵌入 深度强化学习 离散-连续混合动作 不确定性
住宅能源消耗约占社会总能源消耗的30%[1]。构建住宅混合能源系统,基于外部能源价格信号,调整住宅设备的用能模式和用能行为,能够提高能源利用效率,降低用户的用能成本[2]。住宅能量管理系统作为能量管理技术在需求侧的体现,采用不同优化方法制定负荷管理方案,实现负荷的削减和转移,满足用户对住宅经济性和舒适性的需求。
随着居民分布式资源和住宅燃气设备的普及,越来越多的家庭综合利用电能和天然气等多种能源来满足用户的多类型负荷需求[3]。这种多能耦合住宅混合能源系统,能够灵活利用异质能源,优化住宅气/电设备的运行状态,进一步降低用户的用能成本[4]。然而,住宅混合能源系统中多类型设备运行特性存在差异性,并且系统运行受可再生能源出力、外部环境温度和能源价格等随机性因素的影响,不确定性变量多且耦合关系高度复杂[5]。如何在不确定性环境下实现住宅气/电设备的联合优化管理,在保证用户舒适度的前提下降低用能成本,成为亟须解决的问题。
为应对住宅能源系统中的不确定性,文献[6]提出一种住宅日前能量调度鲁棒优化框架,实现了动态环境下住宅能源系统的能量优化调度,但调度结果往往过于保守。为避免优化决策的保守性,文献[7]采用随机规划方法,根据系统不确定性变量的分布和组合,建立多种典型场景的优化方程,优化决策精确度较高,但模型复杂度会随着不确定性场景的增加而急剧扩大。文献[8]提出一种基于模型预测控制的鲁棒方法,在保持系统能量优化鲁棒性的同时降低了决策的保守性,但计算负担较大,且优化性能依赖预测信息的准确性。上述研究虽然能够实现住宅能源系统的能量优化管理,但优化性能受系统中不确定性因素建模或预测准确性的限制。住宅能源系统中不确定性因素多,场景组合关系十分复杂,使得所提策略难以实现住宅实时能量优化管理的目标,制约了上述方法的自适应能力[9-10]。同时,上述研究仅针对住宅电器进行优化管理,缺少对住宅燃气设备的考虑。
作为一种近年来新兴的机器学习方法,强化学习能够实时感知系统状态并采取相应动作,进而学习最优策略[11-12]。深度强化学习(Deep Reinforce-ment Learning, DRL)作为无模型的决策方法,具有良好的决策和感知能力[13],无需对系统中不确定性因素进行建模或预测,能够自适应系统的随机变化,在系统实时能量优化管理中更具优势。文献[14]采用深度Q网络(Deep Q Network, DQN)算法对家庭能源系统进行优化调度,最大化需求侧效益。文献[15]提出一种基于DQN算法的住宅能源系统低碳实时优化管理方法。文献[16]提出一种无模型的深度强化学习方法实现多维连续状态和动作空间下的住宅能量实时调度。上述研究为不确定性环境下住宅的实时能量管理提供了新方案。然而,住宅混合能源系统具有离散和连续混合动作空间的复杂特性,常规深度强化学习方法通常只能处理纯离散或纯连续动作,难以同时学习离散和连续的能量优化管理策略。此外,深度强化学习面临着学习效率低的问题,需要大量的试错训练才能实现收敛,优秀样本采集代价较高,影响方法的收敛速度。
为解决上述问题,本文提出一种领域知识嵌入深度强化学习的住宅混合能源系统能量优化管理方法。该方法能够实现住宅混合能源系统中不同类型设备的联合优化管理,并将领域知识规则嵌入深度强化学习框架中,提高训练效率。首先,构建含住宅电器和燃气设备的住宅混合能源系统优化运行模型;其次,依据系统优化目标,设计住宅设备的优化知识规则;然后,构建领域知识嵌入近端策略优化(Proximal Policy Optimization, PPO)的住宅混合能源系统能量优化管理框架,以提高所提方法的训练效率;最后,通过算例仿真验证了本文所提方法能够实时优化住宅气/电设备的运行,并在保证用户舒适度的前提下降低用能成本。
本文所研究的住宅混合能源系统结构示意图如图1所示,其能源来源包括电能、天然气和分布式光伏。住宅用能设备分为功率可控型设备、时间可控型设备以及其他关键设备。功率可控型设备的运行功率可以在一定范围内调整,包括壁挂式燃气炉(Wall-hung Gas Boiler, WGB)、空调(Air Conditioner, AC)、电阻热水器(electric Resistance water Heater, RH)、照明系统(Illumination System, IS);时间可控型设备的运行时段可调,包括洗衣机(Washing Machine, WM);其他关键设备包括计算机、电视、手机和冰箱等。其中,壁挂式燃气炉包含空间制热和热水制热两个独立回路,能够同时满足用户空间制热需求和热水需求。
图1 住宅混合能源系统结构示意图
Fig.1 Schematic diagram of residential hybrid energy system structure
气-电多能空间制热系统包括壁挂式燃气炉和空调,用户空间制热需求可以由壁挂式燃气炉消耗天然气满足,也可由空调消耗电能满足,或者两者兼有。在t时段,室内温度变化与气-电多能空间制热系统输出空间制热功率和房屋内外空气热交换相关,表示[17]为
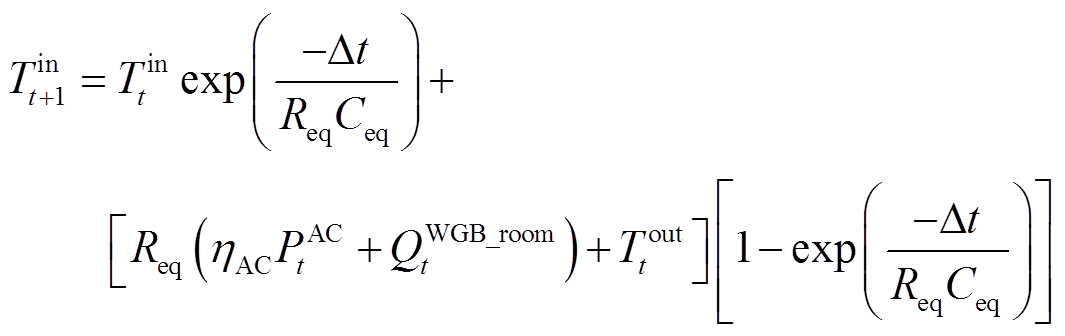 (1)
(1)
式中,Tin t为t时段室内温度;Req为房屋等效热阻;Ceq为室内空气等效热容;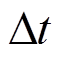 为系统能量优化管理步长;Tout t为t时段室外温度;QWGB_room t为t时段壁挂式燃气炉输出空间制热功率;hAC为空调制热/制冷效率,制热时为正,制冷时为负;PAC t为t时段空调消耗电功率。
为系统能量优化管理步长;Tout t为t时段室外温度;QWGB_room t为t时段壁挂式燃气炉输出空间制热功率;hAC为空调制热/制冷效率,制热时为正,制冷时为负;PAC t为t时段空调消耗电功率。
壁挂式燃气炉t时段输出空间制热功率和空调t时段消耗电功率需限定在一定范围内。为保证用户的热舒适度,室内温度应维持在设定范围,表示为
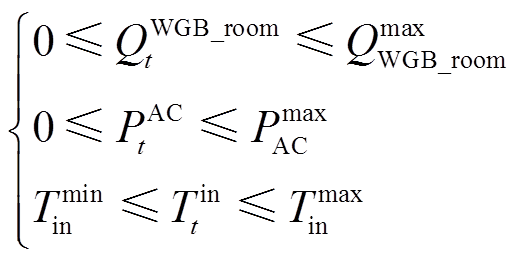 (2)
(2)
式中,QmaxWGB_room为壁挂式燃气炉输出空间制热功率最大值;Pmax AC为空调输入电功率最大值;Tminin、Tmaxin分别为室内温度舒适区间的下限值和上限值。
气-电多能供热水系统由壁挂式燃气炉和电阻热水器组成。对于壁挂式燃气炉,其通过燃烧天然气加热冷水至设定温度值后,将水储存进水箱中供用户热水需求,其输出热水制热功率QWGB_water t表示为
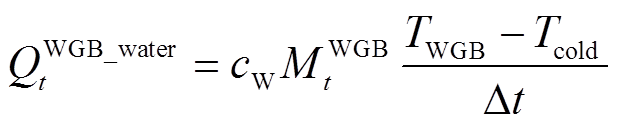 (3)
(3)
式中,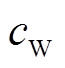 为水的比热容;MWGB t为壁挂式燃气炉t时段储存进水箱中的热水量;TWGB为用户设定的对冷水加热的目标温度值;Tcold为冷水温度。
为水的比热容;MWGB t为壁挂式燃气炉t时段储存进水箱中的热水量;TWGB为用户设定的对冷水加热的目标温度值;Tcold为冷水温度。
储水箱内水温变化与燃气炉补充热水量、电阻热水器加热功率、外部补充冷水量和用户热水需求相关。在t时段,水温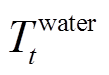 的演变过程[4]表示为
的演变过程[4]表示为
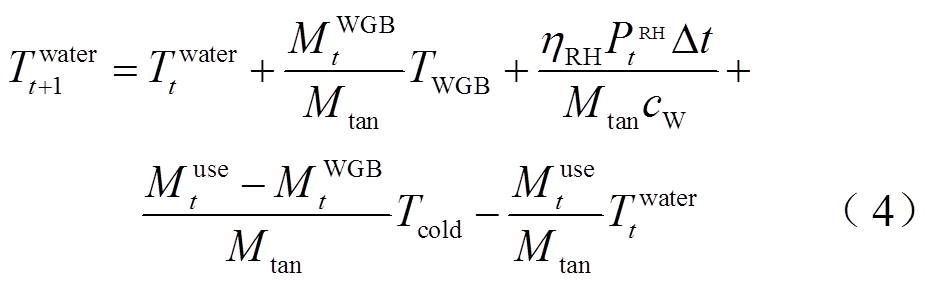
式中,Mtan为储水箱的储水质量;Muse t为t时段用户的热水需求;ηRH为电阻热水器的加热效率;PRH t为t时段电阻热水器的输入电功率。
壁挂式燃气炉t时段输出热水制热功率和电阻热水器t时段输入电功率需限定在一定范围内。考虑到用户生活用水的热舒适度,储水箱内热水温度应保持在用户设定的舒适区间范围内,表示为
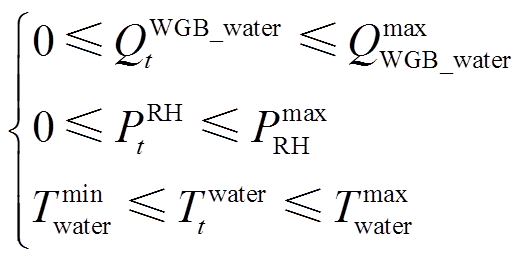 (5)
(5)
式中,Qmax WGB_water为壁挂式燃气炉输出热水制热功率的最大值;Pmax RH为电阻热水器输入电功率最大值;Tmin water、Tmaxwater分别为热水温度舒适区间的下限值和上限值。
照明系统是保障用户视觉舒适度的核心设备,其采用具有照度可调特性的发光二极管[18]。通过调节照明系统输入电功率,能够在保证用户视觉舒适度的前提下,降低用能成本。t时段室内照度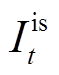 与室外太阳光照度和照明系统发出光照度相关,表示[18-19]为
与室外太阳光照度和照明系统发出光照度相关,表示[18-19]为
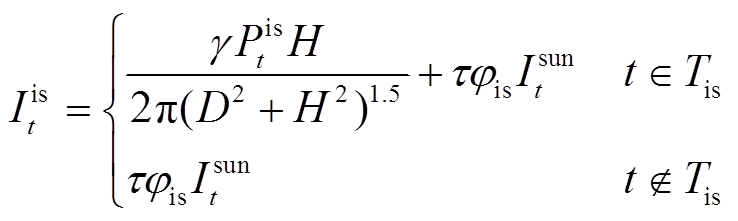 (6)
(6)
式中,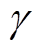 为照明系统的发光效率;
为照明系统的发光效率;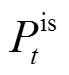 为照明系统输入电功率;D和H分别为照明设备与室内区域中心的水平距离和垂直距离;τ为窗户的净透光率;jis为太阳光照度利用系数;Isun t为太阳光照度;Tis为照明系统可控时间区间。
为照明系统输入电功率;D和H分别为照明设备与室内区域中心的水平距离和垂直距离;τ为窗户的净透光率;jis为太阳光照度利用系数;Isun t为太阳光照度;Tis为照明系统可控时间区间。
室内照度过低或过高均会降低用户视觉舒适度,为避免用户出现视觉疲劳和眩光现象,室内照度需维持在限定范围内。此外,照明系统t时段输入电功率也需维持在限定范围内,表示为
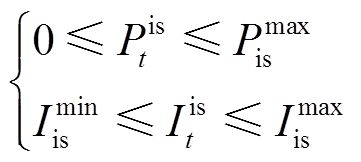 (7)
(7)
式中,Pmax is为照明系统输入电功率最大值;Imin is、Imax is分别为满足用户视觉舒适区间的照度最小值和最大值。
住宅混合能源系统中时间可控型设备为洗衣机,其模型表示为
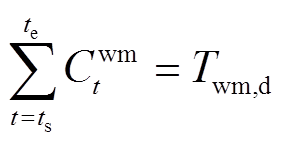 (8)
(8)
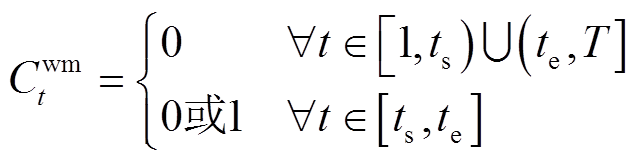 (9)
(9)
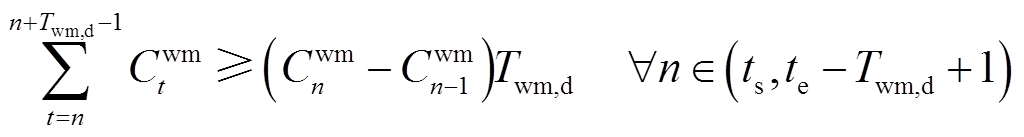 (10)
(10)
式中,Cwm t为t时段洗衣机启动/停止的二元决策变量;Twm,d为洗衣机不间断地完成工作任务所需时段数;ts和te分别为洗衣机可运行时段的起始时段和结束时段;T为总调度步长;n为洗衣机在可运行时段内的启动时段。式(8)确保设备在运行时段内完成任务;式(10)确保在任务执行过程中不中断。
此外,对于其他关键设备,其在t时段消耗的电功率为Pkey t,且不参与系统的能量优化管理过程。需要注意的是,本文对住宅中典型设备进行建模以验证所提方法的有效性,但所提方法对含有其他用能设备的住宅仍是适用的。
本文构建的领域知识规则是基于系统模型和能量优化管理目标设计的,用于实现住宅可控设备的近优管理决策。领域知识规则的设计考虑了系统物理约束条件和用户特征约束,但不是被动地接受限制条件,而是主动生成高质量的近优决策样本供DRL模型学习,引导智能体向着更优策略进行探索,以提升DRL的训练效率。
首先,基于系统模型计算室内温度最优时所需的热功率;然后,依据外部能源价格计算出空调和壁挂式燃气炉输出单位热功率所需成本。供热成本较低的设备在功率约束条件内优先工作,当该设备无法满足空间制热需求时,另一设备启动,弥补缺少的热功率需求。气-电多能空间制热系统中空调和壁挂式燃气炉的热功率分配优化知识规则表示为
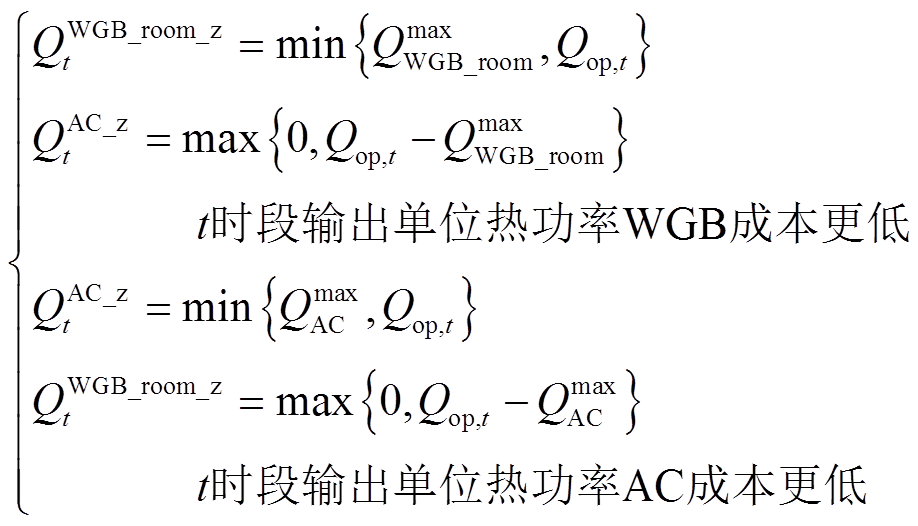 (11)
(11)
式中,QWGB_room_z t和QAC_z t分别为基于优化知识规则得到的壁挂式燃气炉和空调输出空间制热功率;Qop,t为t时段室内温度达到用户设置最优温度时所需热功率,其值可依据用户设定的最优室内温度和式(1)计算得到。
与气-电多能空间制热系统类似,先基于系统模型计算出储水箱内水温达到最优时所需热功率,再根据电阻热水器和壁挂式燃气炉热水制热成本大小与功率约束条件进行设备运行优化。气-电多能供热水系统的优化知识规则表示为
 (12)
(12)
式中,QWGB_water_z t和QRH_z t分别为基于优化知识规则得到的壁挂式燃气炉和电阻热水器输出热水制热功率;QRHX,t为t时段热水达到用户设置最优温度时所需热功率,其值可依据式(3)和式(4)计算得到。
照明系统的优化知识规则需要满足以下原则:①在照明系统可控时间区间内保证室内照度不低于用户设定的最低值;②照明系统输入功率在可控时间区间内需满足功率约束条件,在可控时间区间外为0。照明系统优化知识规则设计为
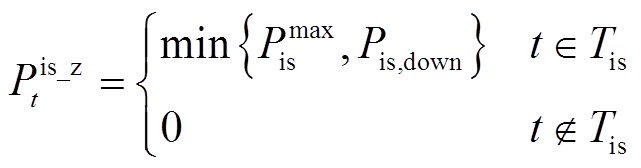 (13)
(13)
式中,Pis_z t 为基于优化知识规则得到的照明系统输入电功率;Pis,down为t时段照明系统提供最低亮度需求所需电功率,其值可依据式(6)计算得到。
洗衣机的优化知识规则需满足以下原则:①在用户设定的时段内工作;②工作过程中不可中断且连续工作的用能成本最低。因此,洗衣机的优化知识规则设计为
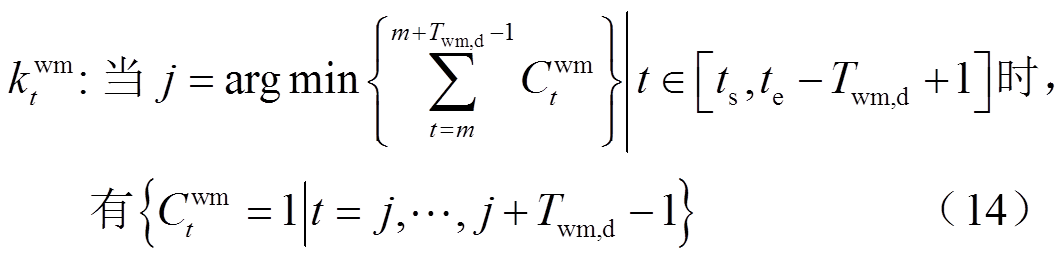
式中,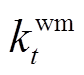 为基于优化知识规则得到的洗衣机启动/停止的二元决策变量;
为基于优化知识规则得到的洗衣机启动/停止的二元决策变量;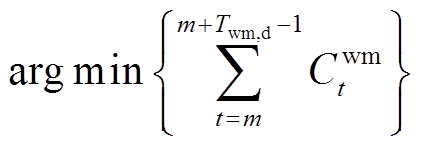 为洗衣机不中断运行Twm,d个时段耗能成本最低的起始时刻m。
为洗衣机不中断运行Twm,d个时段耗能成本最低的起始时刻m。
将住宅设备的优化知识规则集成,形成总的优化知识规则集M为
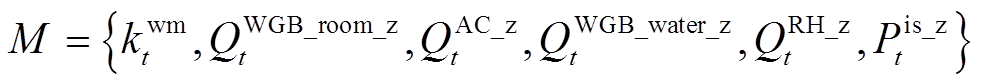 (15)
(15)
通过优化知识规则集M生成住宅能量优化管理决策的近优解,在智能体训练初期提供高质量的近优决策样本,为后续构建领域知识嵌入深度强化学习的住宅能量优化管理框架提供数据基础。
领域知识嵌入DRL的住宅混合能源系统能量优化管理框架如图2所示。“优化知识规则集M”中设计了领域知识规则,能够根据当前时刻的能源价格、用户需求和外部环境等数据,通过领域知识规则输出下一时刻住宅设备的近优决策动作。深度强化学习中内置了离散-连续混合策略,能够实现住宅离散动作设备和连续动作设备的联合优化管理,同时提取领域知识产生的近优样本来优化自身策略。“动作选择模块”按概率对优化知识规则集M和DRL输出的决策动作进行选择。其核心思路是在深度强化学习框架中嵌入“优化知识规则集M”,令领域知识规则产生的近优样本参与DRL策略的训练过程。同时,通过“动作选择模块”对领域知识规则和DRL作用概率进行动态调节,实现DRL算法快速提取优化知识规则集M产生的近优样本,同时又让智能体主动探索,快速学习住宅能量优化管理策略。
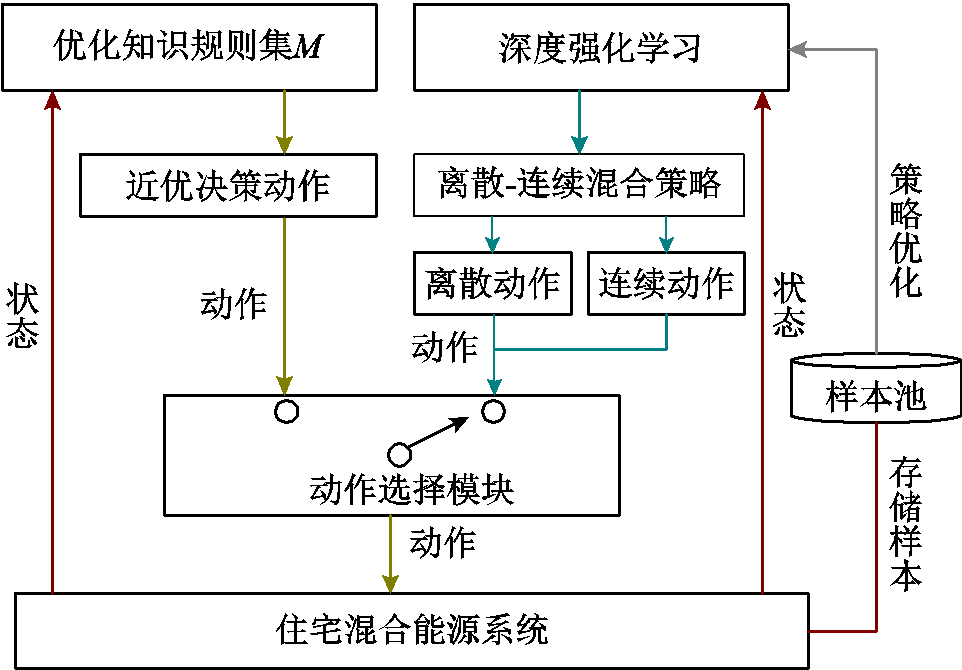
图2 领域知识嵌入DRL的住宅能量优化管理框架
Fig.2 A residential energy optimization management framework by embedding domain knowledge into DRL
住宅能量管理问题可以表述为马尔科夫决策过程(Markov Decision Process, MDP),并采用DRL方法进行系统实时能量优化管理决策。马尔科夫决策过程通常由状态集S、动作集A、奖励函数R和状态转移函数P组成,分别描述如下。
1)状态空间
智能体t时段观测的状态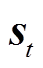 表示为
表示为
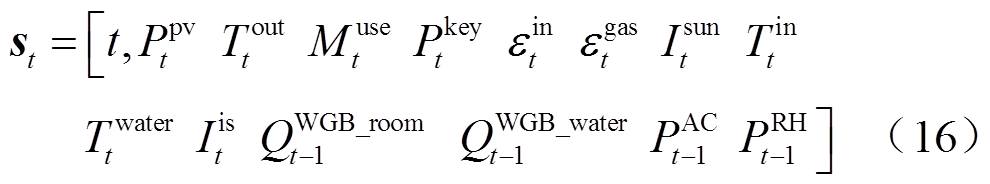
式中,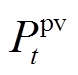 为t时段光伏发电功率;
为t时段光伏发电功率;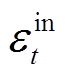 为t时段购电价格;
为t时段购电价格;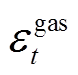 为t时段天然气价格。
为t时段天然气价格。
2)动作空间
智能体在t时段依据策略采取的动作包含离散和连续两种类型,动作空间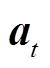 表示为
表示为
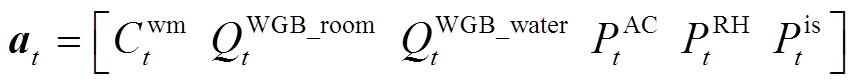 (17)
(17)
式中,Cwm t为系统中时间可控型设备的离散型动作;QWGB_room t、QWGB_water t、PAC t、PRH t和Pis t为系统中功率可控型设备的连续型动作。
3)奖励函数
(1)用能成本
在t时段,系统的用能成本包括购电成本和购气成本,分别表示为
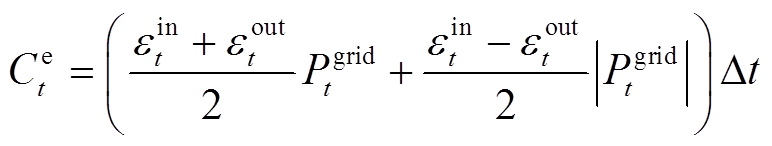 (18)
(18)
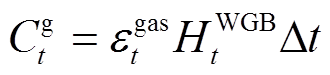 (19)
(19)
式中,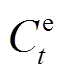 为t时段系统与电网交互功率的成本;Cg t为t时段购买天然气成本;eout t为t时段售电价格;HWGB t为t时段壁挂式燃气炉因空间制热和热水制热消耗天然气总量,由于壁挂式燃气炉热效率高[20],忽略燃气炉启停导致的损耗;Pgrid t为t时段系统与电网的交互功率。HWGB t和Pgrid t分别表示为
为t时段系统与电网交互功率的成本;Cg t为t时段购买天然气成本;eout t为t时段售电价格;HWGB t为t时段壁挂式燃气炉因空间制热和热水制热消耗天然气总量,由于壁挂式燃气炉热效率高[20],忽略燃气炉启停导致的损耗;Pgrid t为t时段系统与电网的交互功率。HWGB t和Pgrid t分别表示为
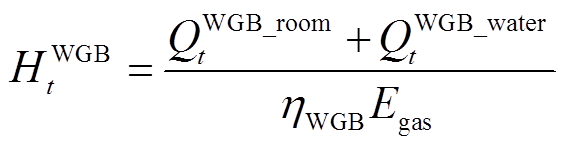 (20)
(20)
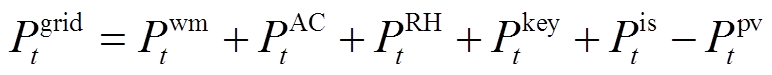 (21)
(21)
式中,ηWGB为壁挂式燃气炉的效率;Egas为单位体积天然气所含能量。
(2)舒适度惩罚项
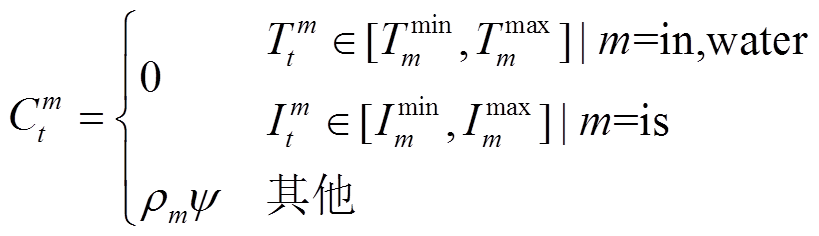 (22)
(22)
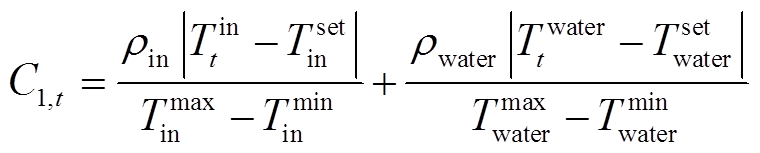 (23)
(23)
式中,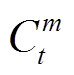 为t时段系统m违反舒适度指标导致的惩罚项;C1,t为t时段因室内温度和热水温度与用户设定最优值相差而导致的惩罚项;rm为系统m的舒适度惩罚系数,用户依据对不同舒适度的耐受程度设定;y为正常数;Tset in和Tset water分别为最优室内温度和最优热水温度。
为t时段系统m违反舒适度指标导致的惩罚项;C1,t为t时段因室内温度和热水温度与用户设定最优值相差而导致的惩罚项;rm为系统m的舒适度惩罚系数,用户依据对不同舒适度的耐受程度设定;y为正常数;Tset in和Tset water分别为最优室内温度和最优热水温度。
系统能量优化管理的目标是在满足用户热舒适度和视觉舒适度的前提下,优化住宅气/电设备的运行以降低用能成本。因此,t时段奖励函数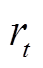 定义为
定义为
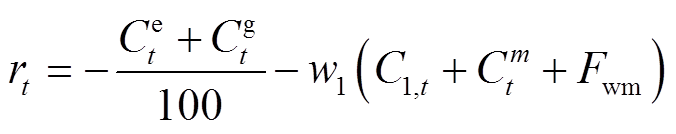 (24)
(24)
式中,w1为惩罚因子,用以控制惩罚项权重;Fwm为时间可控型设备违反约束的惩罚项。
4)状态转移函数
住宅混合能源系统转移到下一状态st+1的过程会受到决策动作at和系统内不确定性因素的影响,包括新能源出力的随机性以及用户需求和环境状况的未知。状态转移函数表示为
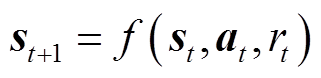 (25)
(25)
系统状态转移受不确定性影响,且难以为不确定性因素建立一个精确的模型。因此,采用DRL方法进行住宅能量管理决策,从历史数据中学习状态转移,可避免对系统中不确定性因素的建模。
住宅混合能源系统中不同类型设备的运行差异性会导致智能体观测信息的多元化,进而形成高维度的状态空间和具有离散、连续两种类型决策变量的动作空间。近端策略优化算法收敛稳定性好、调参相对简单[21],具备同时处理连续动作和离散动作的能力,适合求解本文所研究的住宅实时能量优化管理问题。
首先,设计一种离散-连续混合策略函数,允许智能体能够同时处理时间可控型设备的离散动作和功率可控型设备的连续动作,实现住宅电器和燃气设备的联合优化管理。其中,离散动作采用伯努利分布B(·)逼近能量优化管理策略π,连续动作采用高斯分布N(·)逼近能量优化管理策略π。在t时段,依据混合概率分布分别取样离散动作和连续动作。离散-连续混合策略函数表示为
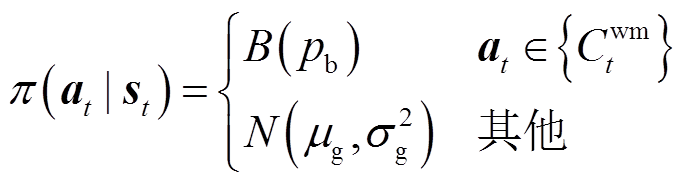 (26)
(26)
式中,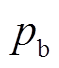 为执行时间可控型设备的概率;μg和
为执行时间可控型设备的概率;μg和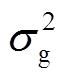 分别为功率可控型设备功率调节动作的均值和方差。
分别为功率可控型设备功率调节动作的均值和方差。
然后,采用基于Actor-Critic架构的近端策略优化(PPO)算法对所提住宅能量优化管理策略进行优化。Actor网络分为旧策略网络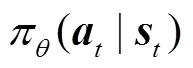 和新策略网络
和新策略网络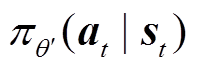 ,分别用于输出动作和学习新数据。Critic网络为价值网络,其通过优势函数评价输出动作价值来指导策略网络动作择优。
,分别用于输出动作和学习新数据。Critic网络为价值网络,其通过优势函数评价输出动作价值来指导策略网络动作择优。
构造价值网络损失函数Lc(f),表示为
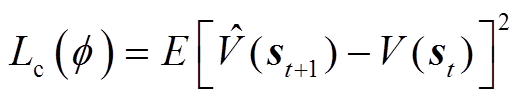 (27)
(27)
式中,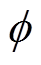 为价值网络权重参数;E[·]为期望运算;V(st)为t时段状态值函数;
为价值网络权重参数;E[·]为期望运算;V(st)为t时段状态值函数;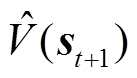 为t+1时段V(st)的估计值,表示为
为t+1时段V(st)的估计值,表示为
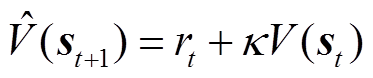 (28)
(28)
式中,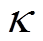 为折扣因子。
为折扣因子。
通过价值网络损失函数Lc(f)对价值网络参数f进行更新,有
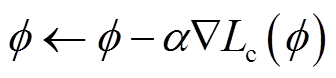 (29)
(29)
式中,a为价值网络的学习率。
策略网络损失函数表示为
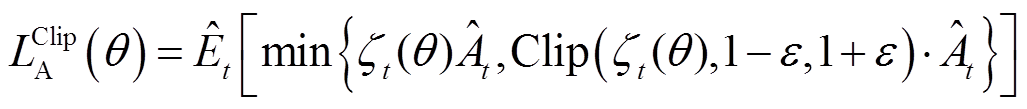 (30)
(30)
式中,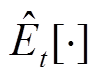 为在样本上的经验平均;
为在样本上的经验平均;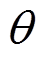 为策略网络的参数;函数Clip
为策略网络的参数;函数Clip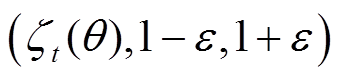 表示将新旧策略比
表示将新旧策略比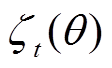 限定到[1-e, 1+e],其中e为裁剪率;
限定到[1-e, 1+e],其中e为裁剪率;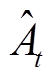 为优势函数的估计,用来表征在状态st时采取动作at的优势。和分别表示为
为优势函数的估计,用来表征在状态st时采取动作at的优势。和分别表示为
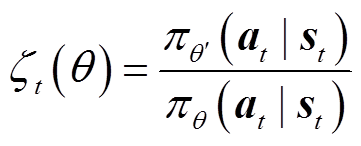 (31)
(31)
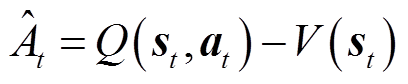 (32)
(32)
式中,Q(st,at)为动作-价值函数。
引入广义优势估计(Generalized Advantage Estimation, GAE)[22]对优势函数进行估计。GAE是一种平衡偏差与方差的优势函数估计方法,通过对不同步数的优势估计进行加权平均,得到一个更稳定的估计值,表示为
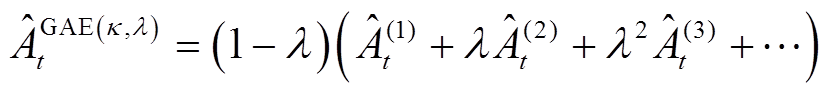 (33)
(33)
式中,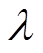 为用于调整偏差-方差权衡的参数。
为用于调整偏差-方差权衡的参数。
最后,通过策略网络损失函数对策略网络参数进行更新,表示为
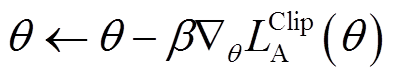 (34)
(34)
式中,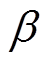 为Actor网络的学习率。
为Actor网络的学习率。
由于PPO学习网络的随机初始化,其在训练初期输出的决策动作水平较低,应令优化知识规则集M以更高的概率输出住宅设备的近优决策动作。随着PPO策略的不断优化,其决策能力不断提高,应逐步提高PPO输出决策动作的概率。根据指数概率函数的单调递减性可知,智能体能够在训练初始阶段偏向选择知识规则产生的决策动作,并且随着训练回合数的增加,选择PPO输出决策动作的概率逐渐增加,进而使智能体自主探索到优于领域知识的优化策略。
在t时段,智能体选择PPO策略动作的概率为1-a1,选择优化知识规则探索近优动作的概率为a1,设计a1为
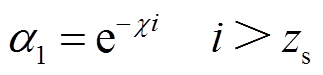 (35)
(35)
式中,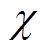 为优化知识与PPO策略动作选择概率控制因子;i为智能体与系统交互次数;zs为领域知识作用的起始回合数。
为优化知识与PPO策略动作选择概率控制因子;i为智能体与系统交互次数;zs为领域知识作用的起始回合数。
领域知识嵌入深度强化学习的住宅能量优化管理方法训练过程如图3所示。首先,初始化Actor和Critic网络参数,并随机选取一天数据作为初始状态。在t时段,智能体观测当前环境状态st,通过动作选择模块从策略π或优化知识规则集M中选取动作at并执行,环境会转移到下一个状态st+1并向智能体返回奖励rt,随后将经验元组(st, at, rt, st+1)存储到经验回放池中。最后,从经验回放池中随机小批量抽取N个经验样本更新Actor和Critic网络参数。
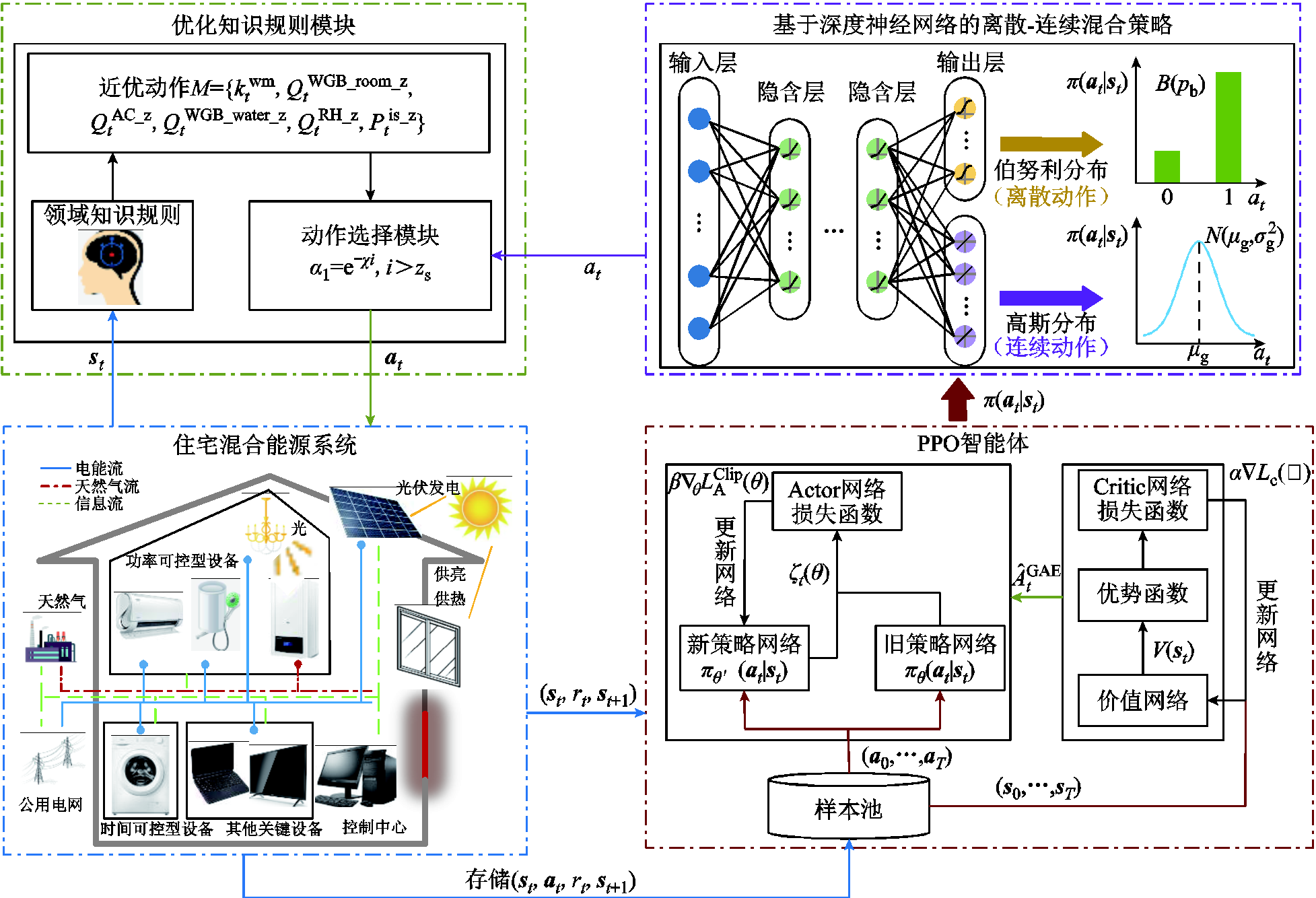
图3 领域知识嵌入深度强化学习的住宅能量优化管理方法训练过程
Fig.3 The training process of optimal residential energy management by embedding domain knowledge into DRL
本文采用图1所示的住宅混合能源系统开展仿真研究,光伏发电和用户热水需求数据来自开源CREST模型[23],室外温度数据取自文献[24],其他关键设备消耗功率参考文献[25],太阳光照度参考文献[18]。本文采用分时电价,0:00—6:00和22:00—23:00为低谷时段,价格为3.53美分/(kW·h);7:00—9:00和18:00—19:00为峰时段,价格为10.582美分/ (kW·h);其他时段为平时段,价格为6美分/(kW·h)。售电价格为分时电价的一半,天然气价格为33.81美分/m3。住宅用能设备参数[4]和其他参数分别见表1和表2。冬季、夏季用户室内温度舒适区间分别为20~24℃、22~26℃,最优室内温度分别为22℃和24℃。热水温度舒适区间为45~65℃,最优热水温度为55℃。用户视觉舒适区间为320~500 lx,照明系统可控时间区间为8:00—22:00。洗衣机的可运行时段为8:00—21:00。
仿真基于Pytorch平台,Actor网络和Critic网络均含有3个隐含层,每层有125个神经元。折扣因子为0.99,Clip参数为0.2,学习率为0.001,Adam优化器更新网络权重。系统能量优化调度步长Dt= 1 h,总调度步长T =24 h。
表1 住宅用能设备参数
Tab.1 Parameters of residential energy equipment
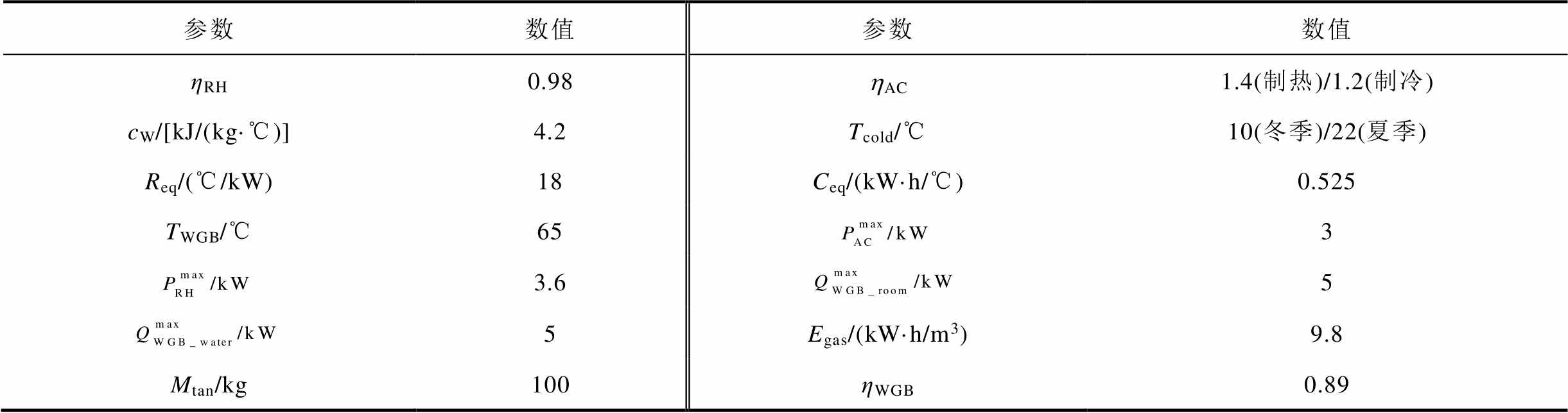
参数数值参数数值 ηRH0.98hAC1.4(制热)/1.2(制冷) cW/[kJ/(kg·℃)]4.2Tcold/℃10(冬季)/22(夏季) Req/(℃/kW)18Ceq/(kW·h/℃)0.525 TWGB/℃653 3.65 5Egas/(kW·h/m3)9.8 Mtan/kg100ηWGB0.89
表2 其他参数
Tab.2 Other parameters
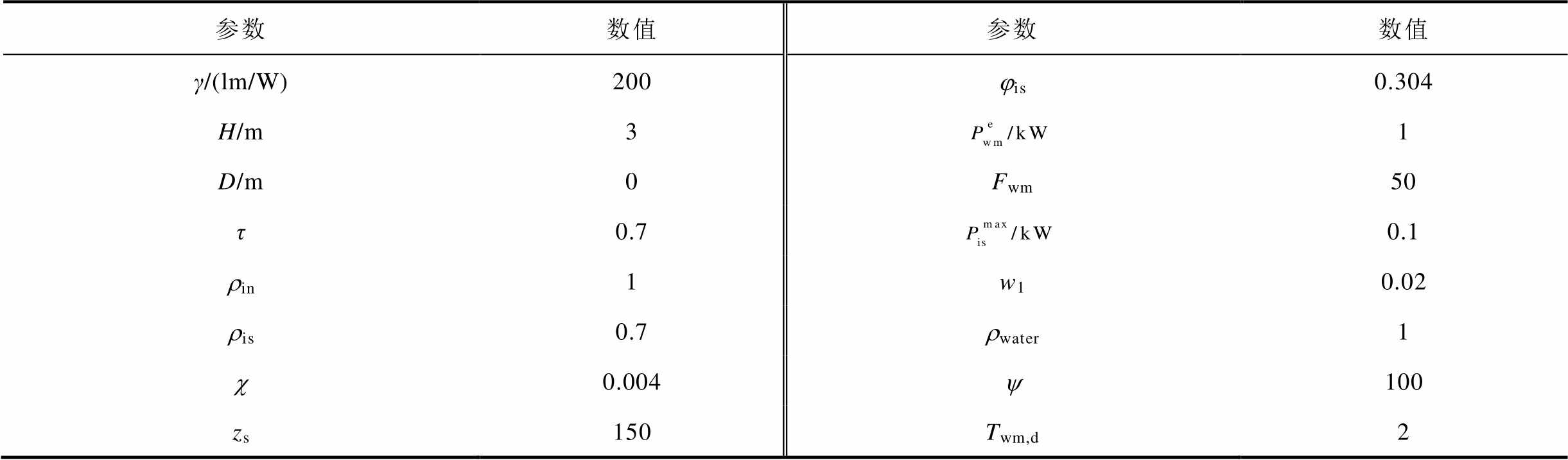
参数数值参数数值 γ/(lm/W)200jis0.304 H/m31 D/m0Fwm50 τ0.70.1 rin1w10.02 ris0.7rwater1 c0.004y100 zs150Twm,d2
注:Pe wm为洗衣机额定运行功率。
本文所提方法与基于近端策略优化方法的训练收敛曲线如图4所示。本文所提方法训练880回合收敛,收敛时间为16.2 min。近端策略优化方法训练3 200回合收敛,收敛时间为110.3 min。本文所提领域知识嵌入PPO方法较PPO方法训练效率提升72.5%,训练时间减少94.1 min。
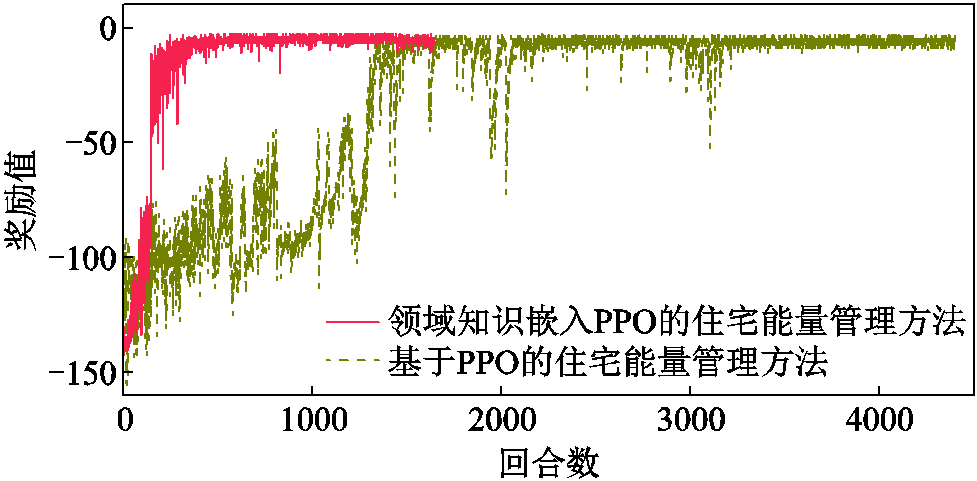
图4 领域知识嵌入PPO方法与PPO方法收敛情况
Fig.4 Convergence of domain knowledge embedded in PPO method and PPO method
上述方法训练效果对比分析表明,与常规近端策略优化方法相比,本文所提领域知识嵌入PPO方法的训练效率得到显著提升。究其原因,本文所构建的领域知识嵌入DRL的住宅能量优化管理框架在训练前期能够高效提取优化知识规则产生的优质样本,加速住宅能量优化策略的学习过程。
为验证所提方法的有效性,随机选取三个典型日(冬季非工作日1(晴天)、冬季非工作日2(阴天)和冬季工作日)进行分析。冬季非工作日1(晴天)的光伏发电功率、其他关键负荷和室外温度曲线如图5a所示,用户热水需求和太阳光照度如图5b所示。
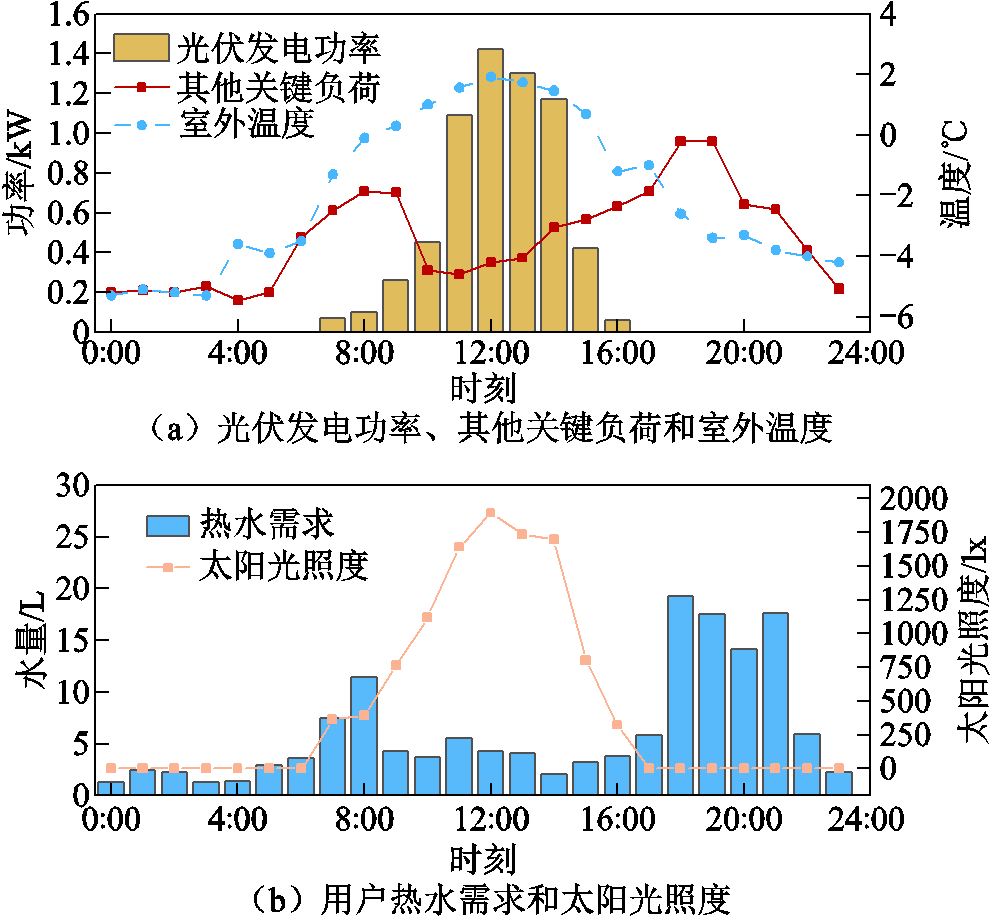
图5 冬季非工作日1(晴天)概况
Fig.5 Overview of winter weekend 1 (sunny day)
冬季非工作日1(晴天)的住宅设备能量优化管理情况如图6所示。根据图6a和图6b可知,在分时电价低谷时段,空调和电阻热水器处于工作状态。在其他时段,壁挂式燃气炉处于工作状态。在11:00—14:00时段,光伏发电量较大,在满足其他关键负荷需求后,剩余电量供空调工作。室内温度和热水温度一直处于用户设定的舒适区间范围内。照明系统和洗衣机能量优化管理情况如图6c所示,照明系统在太阳光照度难以满足用户视觉舒适需求时开启并调节输入功率,以维持室内照度始终在用户设定的舒适区间范围内;洗衣机运行在用户设定运行时段。所测试非工作日1(晴天)的总用能成本为209.6美分,完成决策所需时间为52.3 ms,能够满足实时优化需求。
冬季非工作日2(阴天)概况如图7所示,相比于冬季非工作日1(晴天),所测试阴天的室外温度、光伏发电功率和太阳光照度更低。
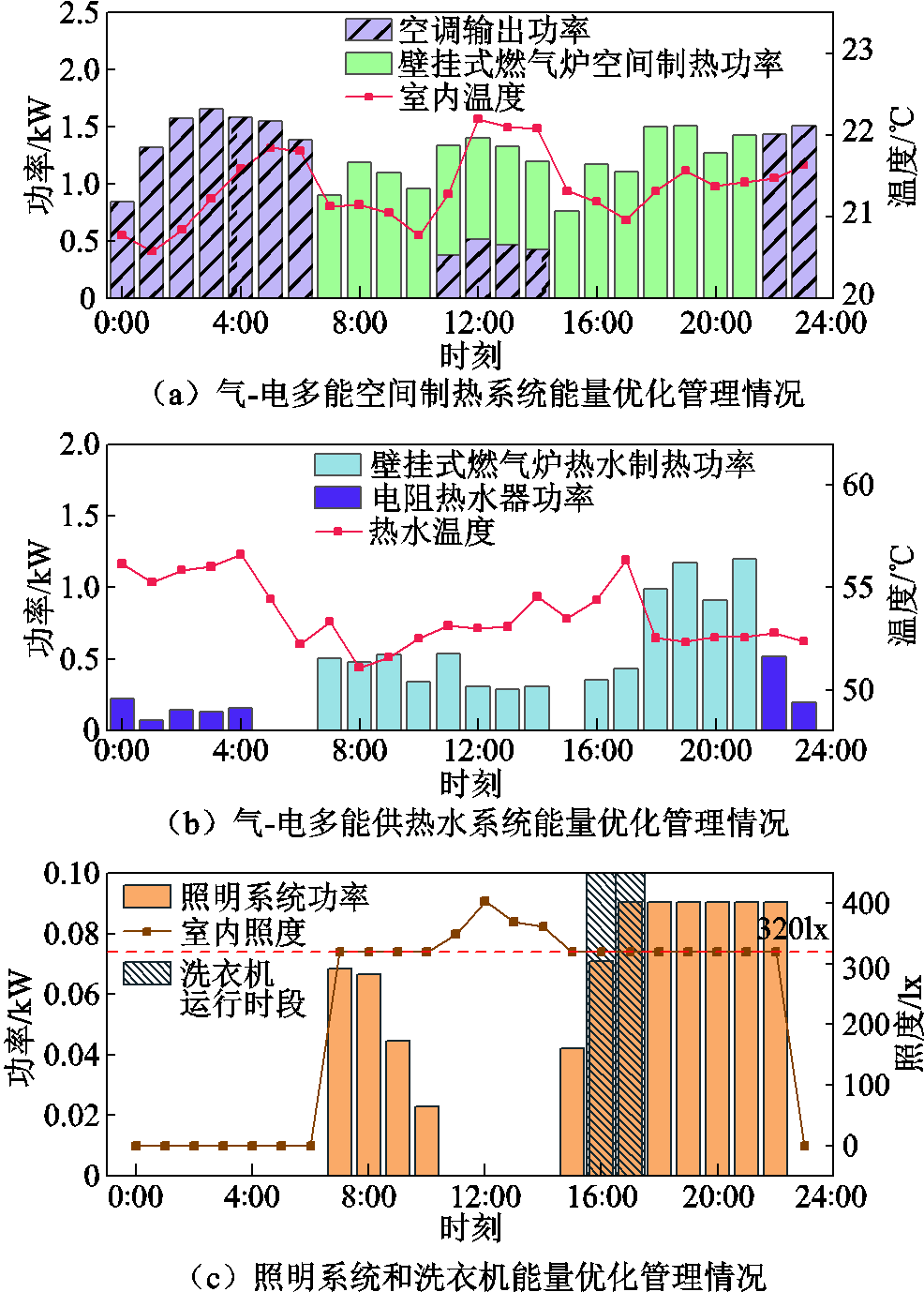
图6 冬季非工作日1(晴天)住宅设备能量优化管理情况
Fig.6 Optimal energy management of residential equipment on winter weekend 1 (sunny day)
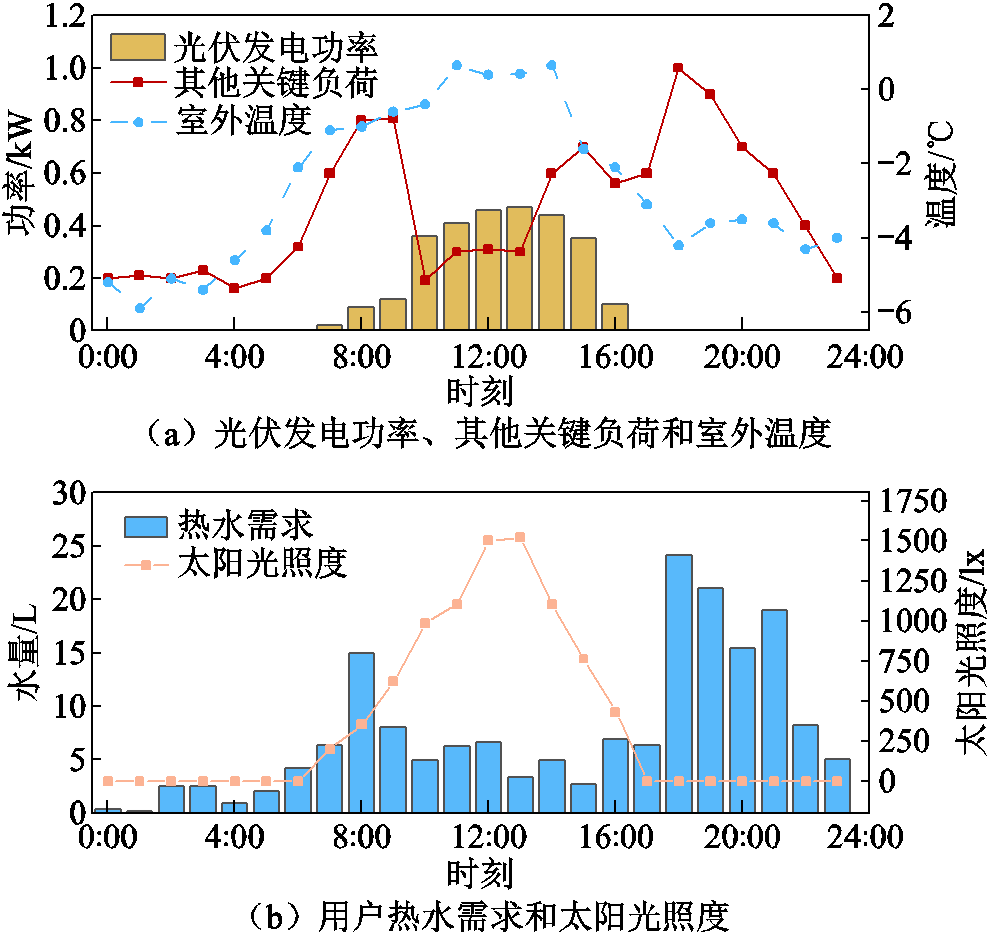
图7 冬季非工作日2(阴天)概况
Fig.7 Overview of winter weekend 2 (cloudy day)
冬季非工作日2(阴天)的住宅设备能量优化管理情况如图8所示。在分时电价低谷时段,住宅电器制热成本更低,壁挂式燃气炉关闭,空调和电阻热水器工作;在其他时段,住宅燃气设备制热成本更低,空调和电阻热水器关闭,壁挂式燃气炉消耗天然气提供热能。由于所测试冬季非工作日2(阴天)的室外太阳光照度较低,照明系统大部分时间处于开启状态,来维持室内照度始终在用户舒适区间范围内,满足用户的照度需求。洗衣机运行在用户设定运行时段。在整个能量优化管理周期内,室内温度、热水温度和室内照度一直处于用户设定区间内,保证了用户的舒适度。所测试冬季非工作日2(阴天)的室外温度、光伏发电功率和太阳光照度更低,导致该场景下住宅设备出力更大,用户用能成本更高。所测试冬季非工作日2(阴天)的住宅总用能成本为223.8美分,完成全部决策所需要的时间为52.1 ms,能够满足实时优化需求。
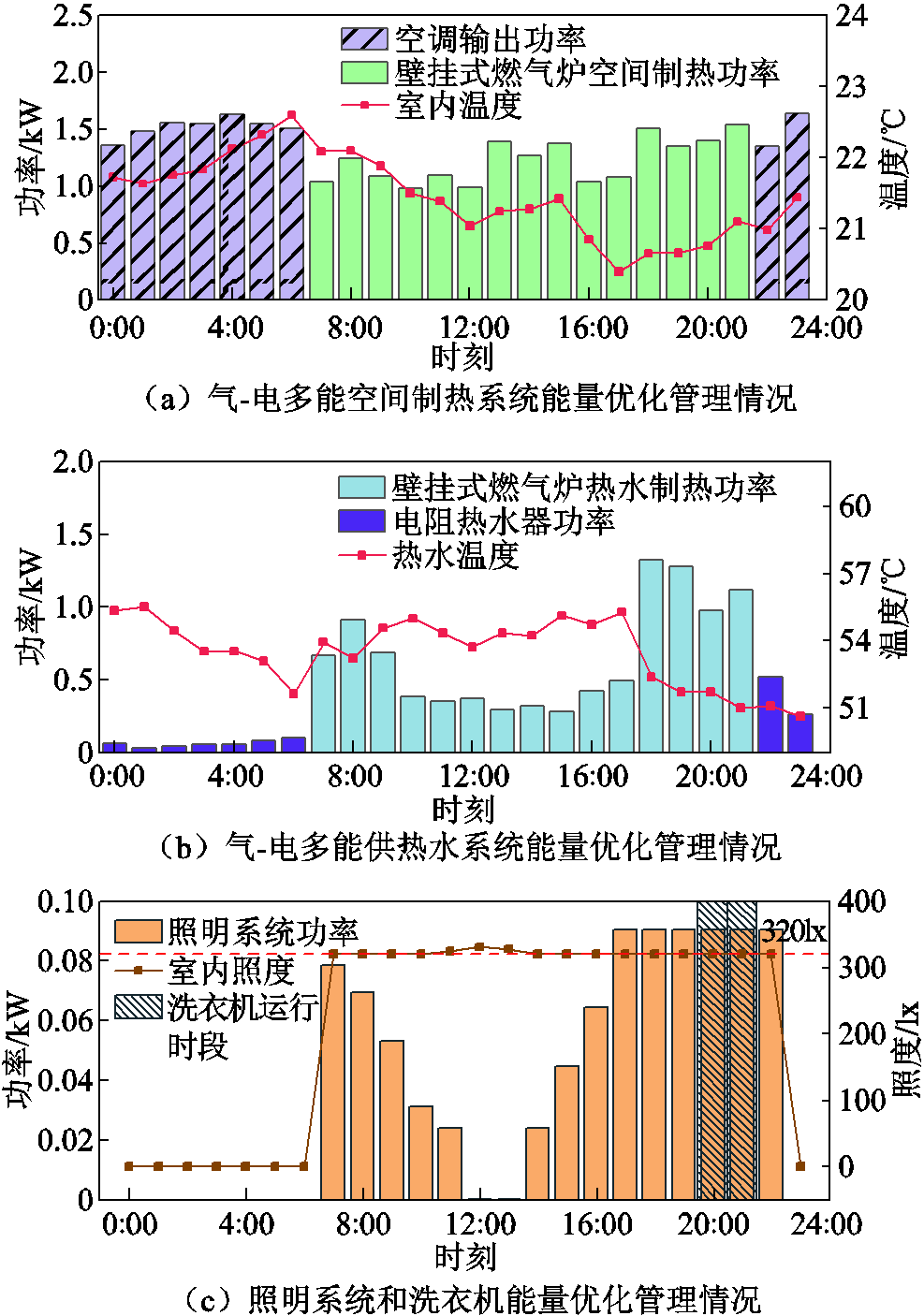
图8 冬季非工作日2(阴天)住宅设备能量优化管理情况
Fig.8 Optimal energy management of residential equipment on winter weekend 2 (cloudy day)
冬季工作日的概况如图9所示,所测试冬季工作日的其他关键负荷和热水需求较低。
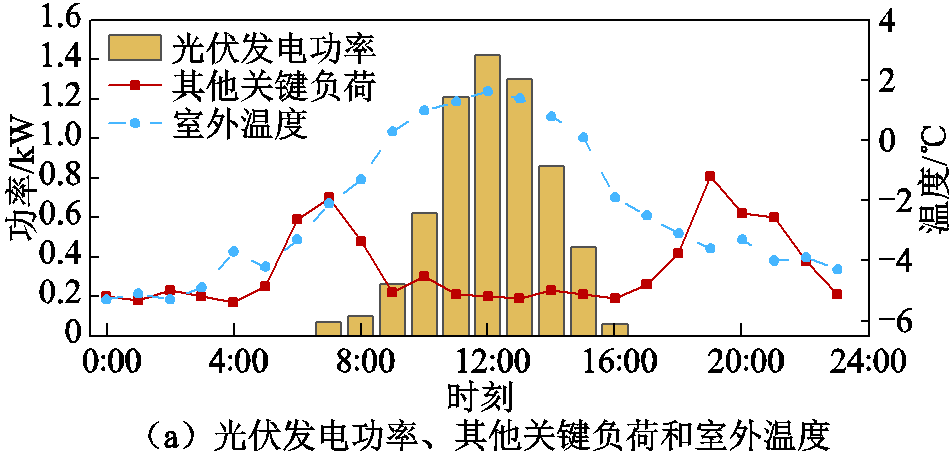
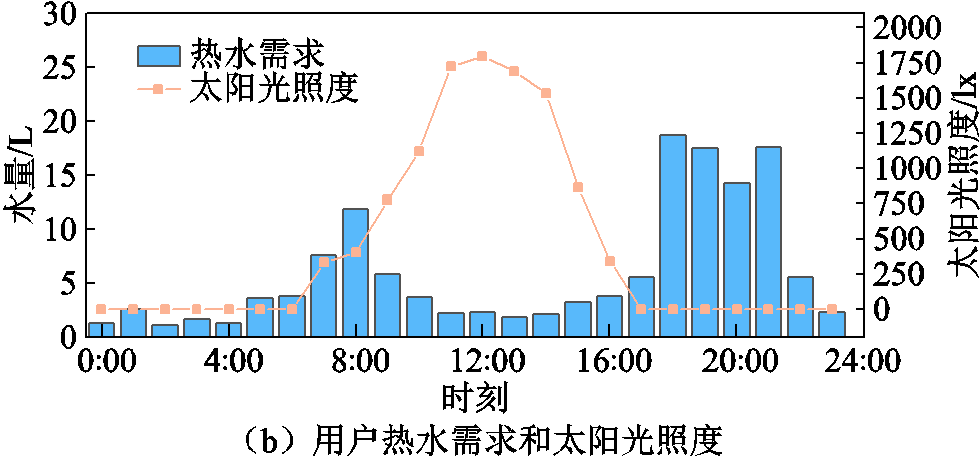
图9 冬季工作日概况
Fig.9 Overview of winter weekday
冬季工作日的住宅设备能量优化管理情况如图10所示。由于工作日其他关键负荷较低,光伏发电在满足其他关键负荷需求后的电量供空调工作。用户热水需求较低,在10:00—16:00时段内燃气炉输出热水制热功率较非工作日低,其余时段住宅设备运行情况与前述分析类似。所测试工作日的总用能成本为195.8美分,完成全部决策所需要的时间为51.2 ms。
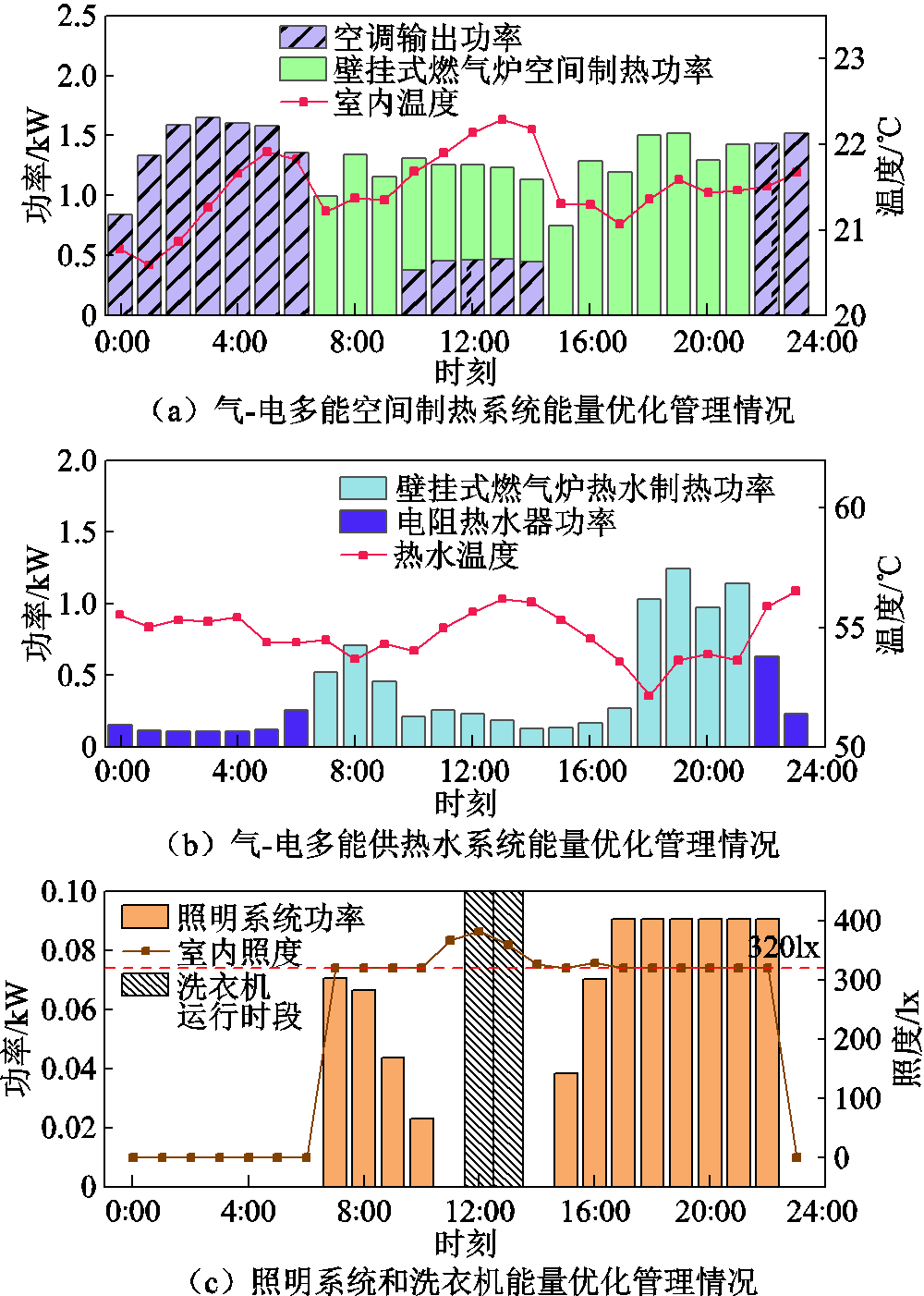
图10 冬季工作日住宅设备能量优化管理情况
Fig.10 Optimal energy management of residential equipment on winter weekday
为进一步验证本文所提方法的泛化性能,随机选取一个夏季典型日进行分析。夏季典型日的概况如图11所示,相比于冬季典型日,其光伏发电功率、室外温度和太阳光照度较高、用户热水需求较低。
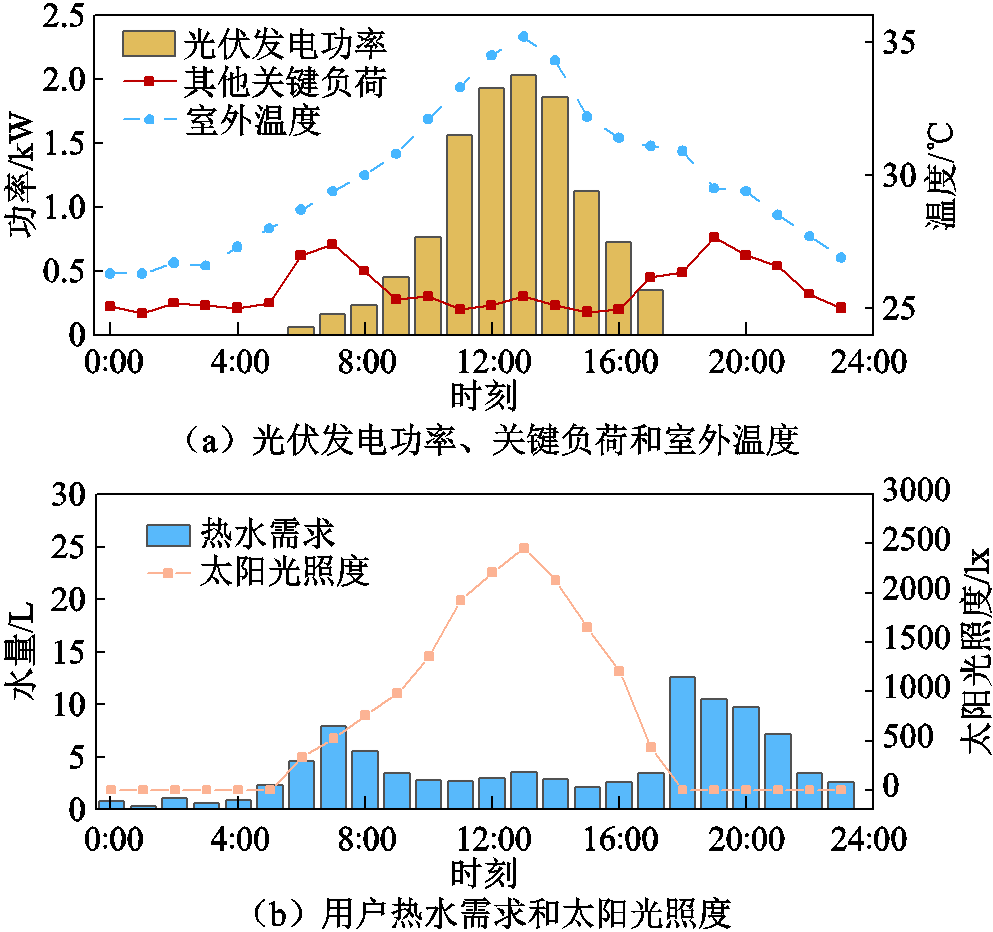
图11 夏季典型日概况
Fig.11 Overview of typical summer day
夏季典型日的住宅能量优化管理情况如图12所示。用户空间制冷需求由空调消耗电能满足,在11:00—14:00时段内,系统光伏发电功率大,空调输出制冷功率大,室内温度低。电阻热水器也在光伏出力较大时刻工作,满足用户的热水需求。壁挂式燃气炉在电价较高且光伏出力较小的时段输出热水,制热功率较大,洗衣机则运行在光伏出力较大时段。夏季典型日的住宅总用能成本为92.4美分,完成全部决策所需要的时间为48.3 ms。
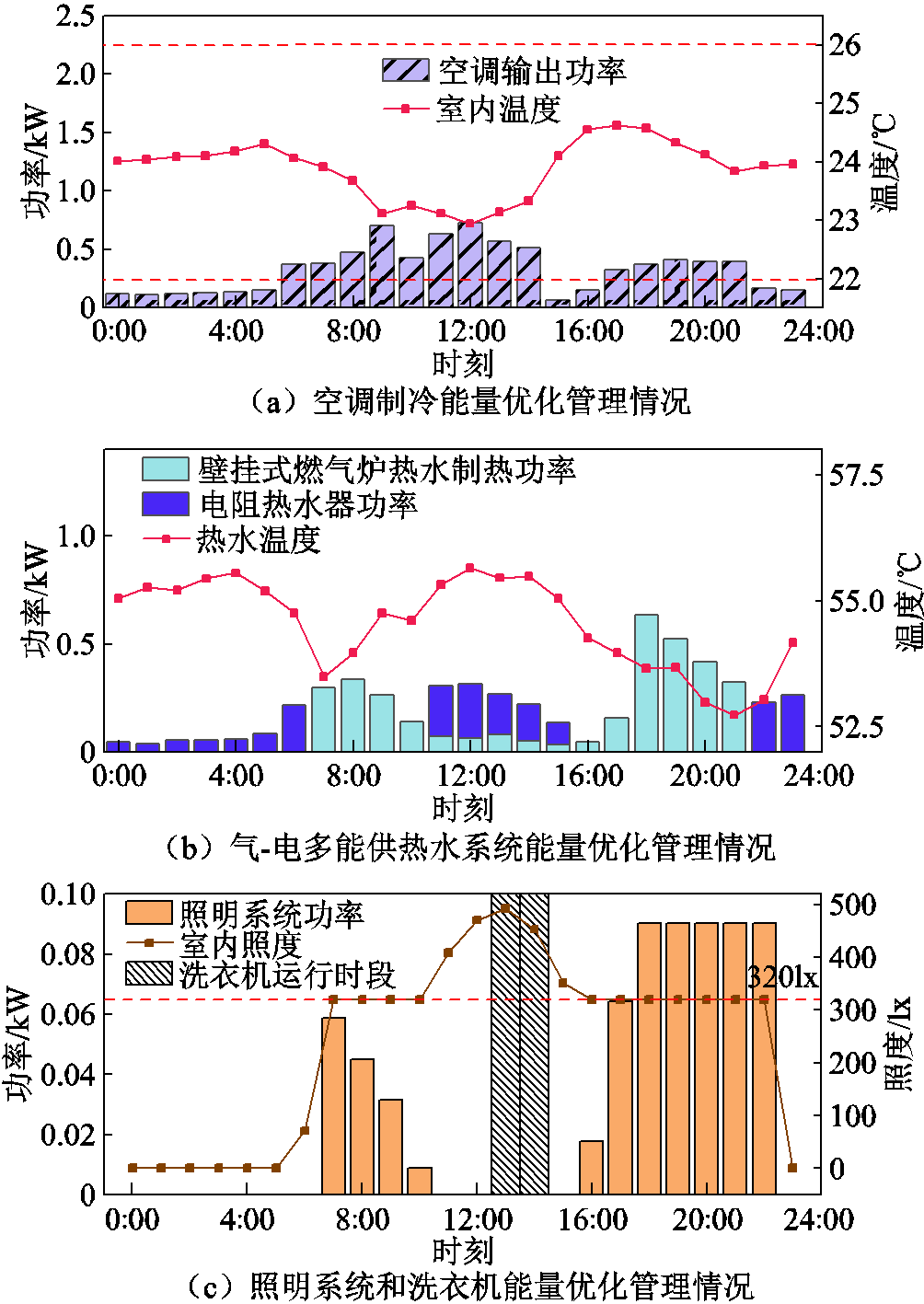
图12 夏季典型日住宅设备能量优化管理情况
Fig.12 Optimal energy management of residential equipment on typical summer day
通过对上述住宅能量优化管理结果分析可知,所提方法在不同测试日的决策时间为ms级,能够满足实时优化需求。此外,该方法能够自适应系统的随机变化,通过对住宅气/电设备进行实时能量优化管理决策,在保证用户热舒适度和视觉舒适度的前提下降低用户用能成本。
为验证本文所提方法在多类型设备联合优化管理和应对不确定性方面的优越性,随机选取15个测试日,在相同优化目标和约束下对不同方法进行对比分析。采用四种方法在测试集上得到的平均用能成本、舒适度惩罚成本和决策时间见表3。其中,方法1:本文所提领域知识嵌入PPO方法;方法2:基于PPO的住宅能量管理方法;方法3:基于DQN的住宅能量管理方法,该方法将系统中每个连续动作离散为3个整数值,折扣因子为0.99,学习率为0.0001;方法4:通过粒子群优化算法(Particle Swarm Optimization, PSO)进行求解,采用长短期记忆(Long Short-Term Memory, LSTM)神经网络对光伏发电功率等不确定因素进行预测。
表3 不同方法能量优化管理结果
Tab.3 Energy management results of different methods

方法用能成本/美分舒适度惩罚成本/美分决策时间/s 1214.37.650.0524 2221.88.120.0563 3250.110.230.0623 4252.310.6520.03
根据表3中数据可知,本文所提方法的总成本为221.95美分,分别较方法2、方法3和方法4降低了3.47%、14.74%和15.59%。通过不同方法能量管理结果对比分析可知,所提方法能够同时处理系统中的离散动作和连续动作,实现不同类型设备的联合优化管理。所提方法在决策时间和优化效果上均优于传统基于预测的方法。究其原因,所提方法通过智能体实时感知系统状态进行决策,能够在ms级时间内完成决策,快速实现住宅气/电设备的实时能量优化管理。此外,该方法无需对系统中的不确定性因素进行精准预测,增强了对系统随机变化的自适应能力,这是传统优化方法难以实现的。
为进一步验证本文所提出的住宅混合能源系统能量优化管理方法在降低用户用能成本方面的优越性,将本文所提方法与基于DQN的住宅能量管理方法在纯电力驱动和气/电混合驱动两个场景下进行对比分析。在测试集中随机挑选15个测试日,两种方法在不同场景下得到的累计能源成本如图13所示。
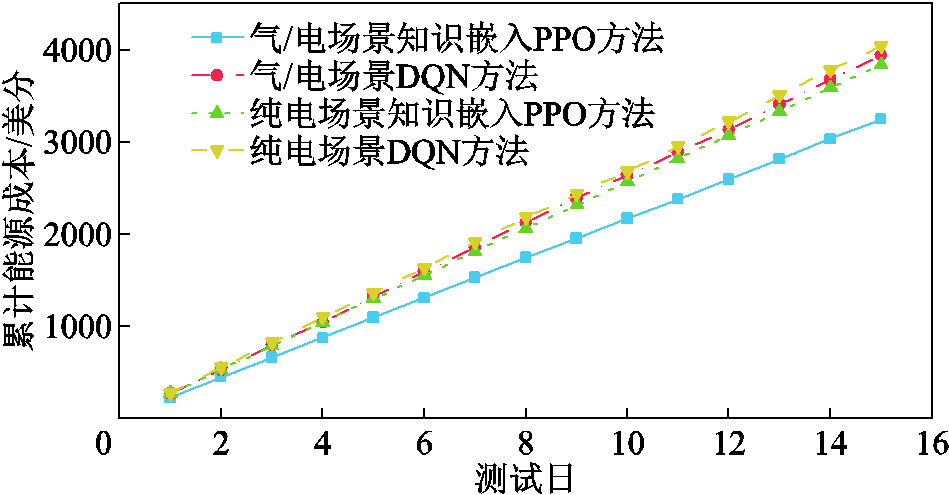
图13 不同场景不同方法累计能源成本
Fig.13 Cumulative energy costs of different methods in different scenarios
由图13可知,气/电场景知识嵌入PPO方法、气/电场景DQN方法、纯电场景知识嵌入PPO方法和纯电场景DQN方法在测试日上的平均能源成本分别为216.4、259.3、255.8和269.9美分。本文所提方法的平均能源成本最低,分别较气/电场景DQN方法、纯电场景知识嵌入PPO方法和纯电场景DQN方法降低了16.54%、15.40%和19.82%。
本文提出了一种领域知识嵌入深度强化学习的住宅混合能源系统能量优化管理方法,该方法能够同时处理系统中时间可控型设备的离散动作和功率可控型设备的连续动作,实现了住宅电器和燃气设备的联合优化管理。通过算例仿真得出以下结论:
1)本文所提领域知识嵌入PPO的住宅混合能源系统能量优化管理方法,通过将领域知识嵌入PPO框架的开发和训练中,来提高住宅优化策略的训练效率。与常规PPO算法相比,所提方法的训练效率提升了72.5%。
2)与基于DQN和基于PSO-LSTM的住宅能量管理方法相比,所提方法避免了对系统中连续动作的离散化处理和不确定性因素的预测,进一步提升了住宅能量实时优化性能。所提方法在15个测试日上的平均总成本较基于DQN和基于PSO-LSTM的住宅能量管理方法分别降低了14.74%和15.59%。
3)与纯电力设备驱动场景相比,所提方法能够依据外部能源价格信号,灵活使用异质能源来满足住宅用户的多类型负荷需求,进一步降低了用户的用能成本。与纯电场景知识嵌入PPO方法和纯电场景DQN方法相比,所提方法在测试日上的平均用能成本分别降低了15.40%和19.82%。
参考文献
[1] Wang Zixuan, Xiao Fu, Ran Yi, et al. Scalable energy management approach of residential hybrid energy system using multi-agent deep reinforcement learning [J]. Applied Energy, 2024, 367: 123414.
[2] 杨雪莹, 祁琪, 李启明, 等. 奖励机制与用户意愿结合的高峰期负荷博弈调度策略[J]. 电工技术学报, 2024, 39(16): 5060-5074. Yang Xueying, Qi Qi, Li Qiming, et al. Peak load game scheduling strategy combining reward mechanism and user willingness[J]. Transactions of China Electrotechnical Society, 2024, 39(16): 5060-5074.
[3] Zhao Liyuan, Yang Ting, Li Wei, et al. Deep reinforcement learning-based joint load scheduling for household multi-energy system[J]. Applied Energy, 2022, 324: 119346.
[4] Wang Jidong, Liu Jianxin, Li Chenghao, et al. Optimal scheduling of gas and electricity consumption in a smart home with a hybrid gas boiler and electric heating system[J]. Energy, 2020, 204: 117951.
[5] 李延珍, 王海鑫, 杨子豪, 等. 基于非侵入式负荷分解的家庭负荷两阶段超短期负荷预测模型[J]. 电工技术学报, 2024, 39(11): 3379-3391. Li Yanzhen, Wang Haixin, Yang Zihao, et al. Two-stage ultra-short-term load forecasting model of household appliances based on non-intrusive load disaggregation[J]. Transactions of China Electrotech-nical Society, 2024, 39(11): 3379-3391.
[6] Hosseini S M, Carli R, Dotoli M. Robust optimal energy management of a residential microgrid under uncertainties on demand and renewable power generation[J]. IEEE Transactions on Automation Science and Engineering, 2021, 18(2): 618-637.
[7] Javadi M S, Gough M, Lotfi M, et al. Optimal self-scheduling of home energy management system in the presence of photovoltaic power generation and batteries[J]. Energy, 2020, 210: 118568.
[8] Yamamoto S, Furukakoi M, Uehara A, et al. MPC-based robust optimization of smart apartment building considering uncertainty for conservative reduction[J]. Energy and Buildings, 2024, 318: 114461.
[9] Xiong Shengtao, Liu Dehong, Chen Yuan, et al. A deep reinforcement learning approach based energy management strategy for home energy system considering the time-of-use price and real-time control of energy storage system[J]. Energy Reports, 2024, 11: 3501-3508.
[10] Zhang Yiwen, Lin Rui, Mei Zhen, et al. Interior-point policy optimization based multi-agent deep reinfo-rcement learning method for secure home energy management under various uncertainties[J]. Applied Energy, 2024, 376: 124155.
[11] 张薇, 王浚宇, 杨茂, 等. 基于分布式双层强化学习的区域综合能源系统多时间尺度优化调度[J]. 电工技术学报, 2025, 40(11): 3529-3544. Zhang Wei, Wang Junyu, Yang Mao, et al. The multi-time-scale optimal scheduling for regional integrated energy system based on the distributed bi-layer reinforcement learning[J]. Transactions of China Electrotechnical Society, 2025, 40(11): 3529-3544.
[12] 李鹏, 钟瀚明, 马红伟, 等. 基于深度强化学习的有源配电网多时间尺度源荷储协同优化调控[J]. 电工技术学报, 2025, 40(5): 1487-1502. Li Peng, Zhong Hanming, Ma Hongwei, et al. Multi-timescale optimal dispatch of source-load-storage coordination in active distribution network based on deep reinforcement learning[J]. Transactions of China Electrotechnical Society, 2025, 40(5): 1487-1502.
[13] 张磊, 吴红斌, 何叶, 等. 基于深度强化学习的氢能综合能源系统优化调度方法[J]. 电力系统自动化, 2024, 48(16): 132-141. Zhang Lei, Wu Hongbin, He Ye, et al. Optimal scheduling method for integrated energy systems with hydrogen based on deep reinforcement learning[J]. Automation of Electric Power Systems, 2024, 48(16): 132-141.
[14] 张甜, 赵奇, 陈中, 等. 基于深度强化学习的家庭能量管理分层优化策略[J]. 电力系统自动化, 2021, 45(21): 149-158. Zhang Tian, Zhao Qi, Chen Zhong, et al. Hierarchical optimization strategy for home energy management based on deep reinforcement learning[J]. Automation of Electric Power Systems, 2021, 45(21): 149-158.
[15] 侯慧, 陈跃, 吴细秀, 等. 非预测机制下计及碳交易的家庭能量低碳优化实时管理[J]. 电网技术, 2023, 47(3): 1066-1078. Hou Hui, Chen Yue, Wu Xixiu, et al. Low-carbon optimal real-time management strategy for home energy considering carbon trading under non-prediction mechanisms[J]. Power System Technology, 2023, 47(3): 1066-1078.
[16] Ye Yujian, Qiu Dawei, Wu Xiaodong, et al. Model-free real-time autonomous control for a residential multi-energy system using deep reinforcement learning [J]. IEEE Transactions on Smart Grid, 2020, 11(4): 3068-3082.
[17] Li Hepeng, Wan Zhiqiang, He Haibo. Real-time residential demand response[J]. IEEE Transactions on Smart Grid, 2020, 11(5): 4144-4154.
[18] Lu Qing, Lü Shuaikang, Leng Yajun, et al. Optimal household energy management based on smart residential energy hub considering uncertain behaviors [J]. Energy, 2020, 195: 117052.
[19] 程晨, 张永熙, 邓友均, 等. 考虑多重舒适度的分时间尺度家庭能量管理策略[J]. 电力建设, 2024, 45(3): 160-172. Cheng Chen, Zhang Yongxi, Deng Youjun, et al. Different time-scale optimization strategy for home energy management considering multiple comforts[J]. Electric Power Construction, 2024, 45(3): 160-172.
[20] Bennett G, Elwell C. Effect of boiler oversizing on efficiency: a dynamic simulation study[J]. Building Services Engineering Research & Technology, 2020, 41(6): 709-726.
[21] 潘玺安, 艾欣, 胡俊杰, 等. 考虑网络安全约束的分布式智能电网边云协同优化调度方法[J]. 电工技术学报, 2024, 39(19): 6104-6118. Pan Xi’an, Ai Xin, Hu Junjie, et al. Network security constrained distributed smart grid edge-cloud collaborative optimization scheduling[J]. Transactions of China Electrotechnical Society, 2024, 39(19): 6104-6118.
[22] Chen Yurou, Zhang Fengyi, Liu Zhiyong. Adaptive bias-variance trade-off in advantage estimator for Actor-Critic algorithms[J]. Neural Networks, 2024, 169: 764-777.
[23] McKenna E, Thomson M. High-resolution stochastic integrated thermal-electrical domestic demand model [J]. Applied Energy, 2016, 165: 445-461.
[24] Open Power System Data[DB/OL]. [2025-04-30]. https://data.open-power-system-data.org.
[25] Xu Xu, Jia Youwei, Xu Yan, et al. A multi-agent reinforcement learning-based data-driven method for home energy management[J]. IEEE Transactions on Smart Grid, 2020, 11(4): 3201-3211.
Abstract To cope with the operational differences of equipment and complex uncertainties in residential hybrid energy system, this paper proposes a residential energy optimization management method by embedding domain knowledge into deep reinforcement learning (DRL). The method can achieve joint optimization management of different types of equipment in residential hybrid energy system, and embed domain knowledge rules into the deep reinforcement learning framework to improve training efficiency.
Firstly, an optimal operation model of residential hybrid energy system including residential electrical appliances and gas equipment was constructed, and optimal knowledge rules for residential equipment were designed based on system energy management objectives. Then, to cope with the uncertainties of renewable energy output and user demand in the system, a deep reinforcement learning optimization model of residential hybrid energy system was constructed, and the proximal policy optimization (PPO) method based on discrete-continuous hybrid strategy was used to make system energy management decisions. Furthermore, a residential hybrid energy system energy optimization management framework that embeds domain knowledge into deep reinforcement learning was constructed. By embedding domain knowledge into the training process of deep reinforcement learning, the advantage of deep reinforcement learning method in efficiently extracting domain optimization knowledge was fully utilized, improving the training efficiency of residential energy optimization strategy. Accordingly, a linkage training mechanism based on exponential probability function was developed to coordinate the probabilities of the random exploration, PPO exploration and knowledge-based exploration. Finally, the effectiveness and superiority of the proposed method were verified through simulation results.
Simulation results show that the domain knowledge embedded PPO method improves the training efficiency by 72.5% and reduces the training time by 94.1 minutes compared with the conventional proximal policy optimization method, which verifies the effectiveness of the proposed method in improving the training efficiency of residential optimization strategy. The residential energy optimization management results under different test days are analyzed to verify that the proposed method can adapt to system uncertainties. By making real-time energy optimization management decisions for residential gas/electricity equipment, users’ energy cost can be reduced while ensuring their thermal and visual comfort. The energy optimization management results of different methods show that the total cost of the proposed method is reduced by 3.47%, 14.74% and 15.59% compared with the PPO method, DQN method and PSO-LSTM method, respectively.
The simulation analysis draws the following conclusions: (1) By embedding domain knowledge into the development and training of the PPO framework, the training efficiency of the residential optimization strategy can be improved. (2) The proposed method avoids the discretization of continuous actions in the system and the prediction of uncertainty factors, further improving the real-time optimization performance of residential hybrid energy system. (3) The proposed method can flexibly use heterogeneous energy to meet the multi-type load demands of residential users based on external energy price signals, further reducing the energy cost of users.
keywords:Residential hybrid energy system, domain knowledge embedding, deep reinforcement learning, discrete-continuous hybrid action, uncertainty
DOI: 10.19595/j.cnki.1000-6753.tces.250945
中图分类号:TM73
河北省自然科学基金项目(E2025202270, F2024202005)、河北省教育厅科学研究项目(BJK2024151)、天津市自然科学基金项目(23JCQNJC01060)、国家自然科学基金面上项目(52477005)、河北省燕赵青年科学家项目(E2024202109)和河北省省级科技计划项目(21567605H)资助。
收稿日期 2025-06-03
改稿日期 2025-08-29
赵黎媛 女,1992年生,博士,讲师,研究方向为综合能源系统、人工智能在电力领域的应用。E-mail:yuanerzhao@hebut.edu.cn
张 献 男,1983年生,教授,博士生导师,研究方向为电动汽车、无线电能传输技术等。E-mail:zhangxian@hebut.edu.cn(通信作者)
(编辑 李 冰)