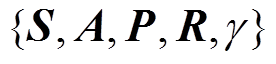 来表示。其中
来表示。其中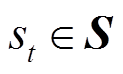 表示状态空间;
表示状态空间;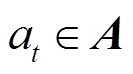 表示动作空间;
表示动作空间;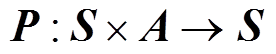 代表当前状态
代表当前状态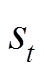 在动作
在动作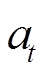 作用下转移到下一状态
作用下转移到下一状态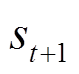 的概率;
的概率;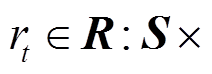
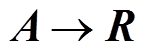 代表状态转移后获得的即时奖励;
代表状态转移后获得的即时奖励;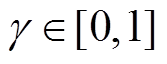 是折扣因子,代表当下奖励与未来奖励之间的相对重要程度,
是折扣因子,代表当下奖励与未来奖励之间的相对重要程度,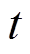 表示当前时刻。马尔科夫决策过程假设下一时刻的状态仅与当前时刻状态相关。强化学习的目标是通过反复实验来最大化预期累积奖励,其目标函数为
表示当前时刻。马尔科夫决策过程假设下一时刻的状态仅与当前时刻状态相关。强化学习的目标是通过反复实验来最大化预期累积奖励,其目标函数为摘要 在高速铁路中,弓网接触力的波动严重影响高速列车的受流质量,导致接触部件磨损,严重增加运营成本,甚至影响运行安全。受电弓主动控制是提升受流质量的有效措施,然而,现有的控制方法受限于受电弓动作时延和缺乏精确数学模型,控制器性能不佳,且缺乏对新的弓网系统运行条件和环境扰动的快速适应能力。该文提出一种基于上下文的深度元强化学习算法来解决这些限制,使得智能体能够在新环境或新任务中快速适应。首先,提出改进的分布式SAC(soft actor-critic)算法,包括分布式状态-动作价值函数和双值分布学习,来解决价值估计中的高估问题和稳定训练过程。然后,提出一种环境变化敏感的任务编码器,能够根据交互样本的上下文快速生成最优任务编码。最后,在经过验证的受电弓-接触网系统基准和主动受电弓实验平台上对所提方法的有效性和鲁棒性进行了评估,与目前最先进的受电弓主动控制方法对比,所提方法具有最低的接触力方差,并且能够快速地适应新的控制任务和环境扰动。
关键词:高速铁路 受电弓主动控制 深度强化学习 元学习
高速铁路以其显著的社会效益和经济效益,在中国和世界范围内得到了迅速发展和广泛关注。受电弓-接触网系统(简称弓网系统)是高速列车电能传输和稳定能量获取的关键子系统[1]。弓网接触力的波动会随着列车运行速度的增加而加剧,从而导致受流质量恶化和电气设备损坏。过大的接触力会加速接触部件(碳滑板和接触线)磨损,还会引起的定位器和接触线过度提升,加速零部件疲劳过程。过小的接触力会导致弓网离线,造成列车取能失败,随之产生的离线电弧会烧蚀接触部件并产生电磁干扰从而中断列车通信[2]。优化受电弓和接触网的结构参数是常见的解决方案[3-4]。然而,优化受电弓对于受流质量的提升效果有限,而优化接触网需要对原有接触网进行加固或重建,建设成本大。因此,在现有弓网系统条件下,主动受电弓控制是提升受流质量最直接有效的优化方法,包括减少取能失败、电磁污染、接触机械部件的磨损,以及降低维护成本[5]。
针对受电弓主动控制,国内外研发出了多种针对受电弓的主动控制方法。其一般以最小化接触力波动为目标,以系统物理特性为约束,建立弓网数学或有限元模型,进而通过PID控制器[6-7]、滑模控制器[8]、鲁棒控制器[9-10]、模型预测控制[11-12]、最优控制[13-14]等控制方法求解最优控制动作。尽管现有方法在应用中取得了一定突破,但仍存在以下问题。首先,这些研究大多基于简化的弓网模型,无法模拟接触力的高频分量、接触网结构非线性和波动传播现象。其次,现有方法依赖精确的系统数学模型或者精准的预测结果,受电弓的作动器-空气弹簧是具有滞后输出的执行器,通常难以建立精确的数学模型。另外,现有方法缺乏泛化能力,当系统状态发生变化时,比如弓网参数变化、列车运行版图调整,现有方法都需要再次进行完整的迭代求解,无法获得端到端的控制方案。最后,外部环境扰动(随机风、接触网不平顺等)会进一步提升控制场景的复杂化和不确定性,现有方法由于过于依赖模型、泛化能力差、计算效率低并且缺乏主动的学习能力,在环境适应性与鲁棒性方面存在较大的局限性。
近年来,以深度强化学习(Deep Reinforcement Learning, DRL)为代表的人工智能技术在优化决策和智能控制领域取得了显著的突破[14-15]。区别于传统模型驱动的优化算法,DRL是一种数据驱动的方法,通过与外部环境的直接交互学习控制策略。凭借强化学习对序贯决策问题的出色优化能力[16],以及深度学习对高维数据的强大表征能力[17],DRL方法可以不依赖系统的动态模型和环境不确定性的预测,直接获得端到端的决策控制策略,为多运行场景和复杂环境扰动的受电弓主动控制提供了新的解决思路。但这些控制策略仍然存在一些局限。首先,它们无法很好地处理各种受电弓类型、接触网运行条件、变化的运行速度和突发事件;由于缺乏对新的弓网系统运行条件和环境扰动的快速适应能力,在实际系统中实施具有挑战性。其次,这些工作大多数仅限于狭窄的任务分布和固定的环境,需要大量的训练数据并且无法快速适应新任务。最后,表征传感器精度、执行器不确定性、铁路线参数和外部激励特别困难,所有这些因素都会随着时间的推移而漂移。因此,电气化铁路系统运行条件差异大,当接触网运行工况在测试或部署阶段发生显著变化时,控制策略可能会导致性能不理想,甚至崩溃[18-19]。
为了克服以上局限,元深度强化学习(Deep Meta Reinforcement Learning, DMRL)应运而生[20-21]。元强化学习是一种学习强化学习的机器学习方法,其结合了元学习(Meta Learning)和强化学习(Reinforcement Learning, RL)的优点。元学习,即学习如何学习,旨在借助先前的经验知识来学习如何学习,利用学习所得的先前经验提高未来的学习表现,使其在未来学习中减少对样本数量的需求。元学习的目标是在训练任务数据集上训练一个元模型,使模型避免在面临新任务或新环境时从零开始,仅需少量数据就可以快速适应新任务。作为一种通过学习来迅速适应不同新任务并得到最优策略的方法,它可以提高标准DRL的效率和灵活性。元强化学习的基本假设是用于元训练的任务与元测试(适应)的新任务服从同一分布,因而不同任务之间存在一些共同特征。
现有的DMRL方法主要可以分为三类:
(1)基于递归的DMRL,其采用循环神经网络(Recurrent Neural Network, RNN),例如长短期记忆(Long Short Term Memory, LSTM)或门控循环单元(Gate Recurrent Unit, GRU)来表示行为策略。然而,基于递归的DMRL算法通常适用于平稳和非平稳环境,无法保证收敛性和泛化能力。另外,因为策略网络在每个学习时期都会更新,在线RL优化器的样本效率低下。
(2)基于策略梯度的DMRL,其尝试学习全局最优的策略初始化方法,例如与模型无关的元学习(Model-Agnostic Meta-Learning, MAML)算法[14]。MAML旨在从训练任务分布中学习全局最优策略初始化,并通过采取一些梯度步骤快速适应测试任务。由于该算法采用较小的学习率来保持稳定性和收敛性,因此它很难实现小样本自适应。
(3)基于任务推理的元强化学习,旨在识别和区分任务编码并学习编码条件策略。这需要一种学习任务表示和识别单个任务的机制,通常需要学习任务编码器和任务编码调制的元策略。文献[21]提出了一种高效的离线策略RL(Probabilistic Embeddings for Actor-critic meta-RL, PEARL)算法,将变分推理和策略梯度公式相结合来学习任务编码策略。元强化学习的总体思想是尝试训练执行各种相关任务的通用最优策略,而不是针对新任务重新训练控制策略。
鉴于此,基于上下文的深度元强化学习算法来解决这些限制,通过利用以前的任务经验更快地解决新任务,克服了自适应挑战,经过几十次实验就可以有效地学习并解决具有相似结构的任务分布并适应全新的环境。首先,提出了改进的分布式SAC(soft actor-critic),包括分布式状态-动作价值函数和双值分布学习,提高价值估计精度和稳定训练过程,以解决爆炸和消失的梯度问题。然后,提出了一种环境变化敏感的任务编码器,能够根据交互样本的上下文快速生成最优任务编码。最后,在经过验证的受电弓-接触网系统基准和主动受电弓实验平台上对所提方法的有效性和鲁棒性进行了评估,与目前最先进的受电弓主动控制方法对比,本文所提方法实现了最低的接触力方差,并且能够快速地适应新的控制任务和环境扰动。
强化学习和元强化学习框架如图1所示,强化学习的四要素包括智能体、环境、状态、动作以及奖励。智能体与环境的交互一般建模为马尔科夫决策过程(Markov Decision Process, MDP),可以使用五元组来表示。其中表示状态空间;表示动作空间;代表当前状态在动作作用下转移到下一状态的概率;代表状态转移后获得的即时奖励;是折扣因子,代表当下奖励与未来奖励之间的相对重要程度,表示当前时刻。马尔科夫决策过程假设下一时刻的状态仅与当前时刻状态相关。强化学习的目标是通过反复实验来最大化预期累积奖励,其目标函数为
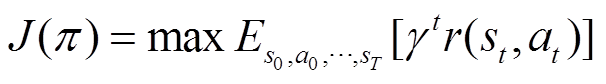 (1)
(1)
式中,T为有限时间视界或回合结束步数;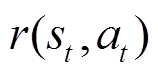 为智能体当前时刻状态
为智能体当前时刻状态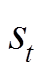 采取动作
采取动作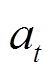 获得的奖励;
获得的奖励;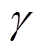 为奖励的折扣因子,
为奖励的折扣因子,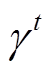 为当前t时刻的累计奖励折扣。
为当前t时刻的累计奖励折扣。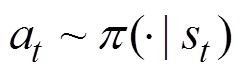 是行为策略
是行为策略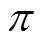 在状态
在状态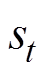 选择的动作。最优行为策略可以表示为
选择的动作。最优行为策略可以表示为
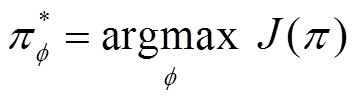 (2)
(2)
式中,argmax表示使函数取得最大值时,自变量所对应的位置;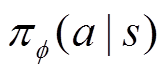 为行为策略,是智能体状态空间到动作空间的映射,通常被建模为由权重
为行为策略,是智能体状态空间到动作空间的映射,通常被建模为由权重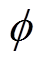 参数化的神经网络,
参数化的神经网络,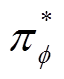 为最优策略。
为最优策略。
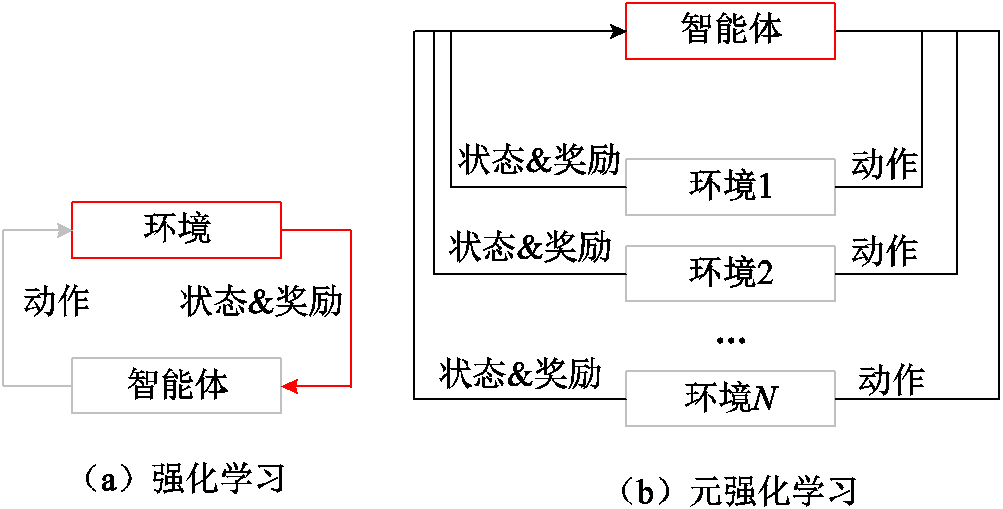
图1 强化学习和元强化学习框架
Fig.1 Reinforcement learning and meta-reinforcement learning frameworks
结合动态规划或者蒙特卡洛方法的思想,Q学习(Q-learning)使用时序差分学习(Temporal Difference Learning, TD-Learning)来学习动作价值函数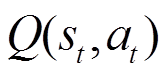 ,其表示在状态
,其表示在状态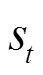 下执行动作
下执行动作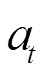 后的期望奖励,也称为Q函数[22]。贝尔曼方程描述了状态-动作对
后的期望奖励,也称为Q函数[22]。贝尔曼方程描述了状态-动作对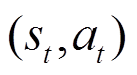 的值与后续状态-动作对
的值与后续状态-动作对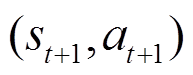 的值之间的基本关系,即
的值之间的基本关系,即
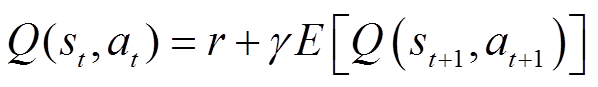 (3)
(3)
式中,E[⋅]表示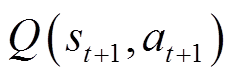 的数学期望。
的数学期望。
深度Q网络(Deep Q-learning Network, DQN)[23]引入经验回放机制,并使用神经网络参数化Q函数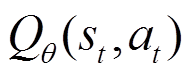 ,进一步引入一个冻结参数的目标Q函数
,进一步引入一个冻结参数的目标Q函数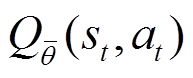 以更新贝尔曼误差。
以更新贝尔曼误差。
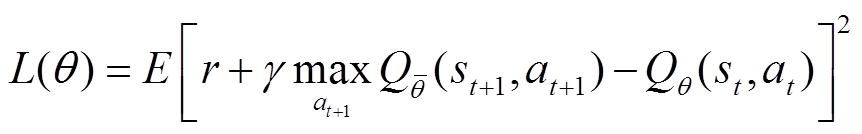 (4)
(4)
如图1b所示,与DRL方法解决单个MDP问题不同,DMRL尝试解决多MDP中的自适应问题。DMRL的训练和测试任务不同但均采样自同一任务分布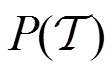 ,其中每个任务都是具有独特动力学的MDP。DMRL的目标是最大化所有任务的预期累积奖励。
,其中每个任务都是具有独特动力学的MDP。DMRL的目标是最大化所有任务的预期累积奖励。
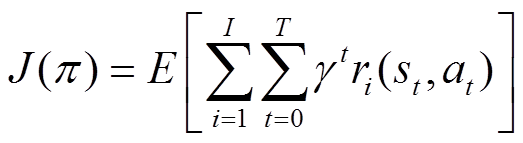 (5 )
(5 )
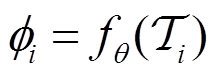 (6)
(6)
式中,下标i表示第i个任务;I为总任务数量;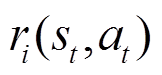 为第i个任务当前时刻的奖励;
为第i个任务当前时刻的奖励;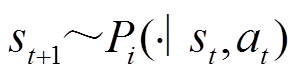 表示第i个任务的状态转移函数;
表示第i个任务的状态转移函数;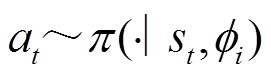 为第i个任务中动作
为第i个任务中动作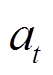 从行为策略
从行为策略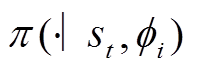 中采样;
中采样;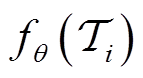 为参数为
为参数为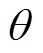 的自适应函数;
的自适应函数;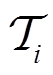 为具有特定动力学环境的第
为具有特定动力学环境的第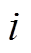 个任务。DMRL可以总结为优化学习过程中的全局参数,这一过程可以进一步总结为内循环和外循环两个步骤:作为外循环,元学习器方程式(5)根据从每个任务收集的总预期奖励来调整其参数;作为内循环,适应函数方程式(6)根据所有任务的总体奖励最大化进行优化,并根据元学习器收集的轨迹微调元策略参数。
个任务。DMRL可以总结为优化学习过程中的全局参数,这一过程可以进一步总结为内循环和外循环两个步骤:作为外循环,元学习器方程式(5)根据从每个任务收集的总预期奖励来调整其参数;作为内循环,适应函数方程式(6)根据所有任务的总体奖励最大化进行优化,并根据元学习器收集的轨迹微调元策略参数。
精确的受电弓模型是完整的弓网系统仿真的基础,本文采用基于频率响应法的受电弓三元弹簧阻尼模型[9]。受电弓三元质量弹簧阻尼模型如图2所示。值得一提的是,受电弓归算质量模型作为弓网动力学领域内应用最为广泛的模型[15-17],其已通过欧洲标准EN 50318 [24]验证,可以有效表征不同运行速度范围内受电弓动态特性。接触网系统示意图如图3所示,受电弓模型的动力学方程式为
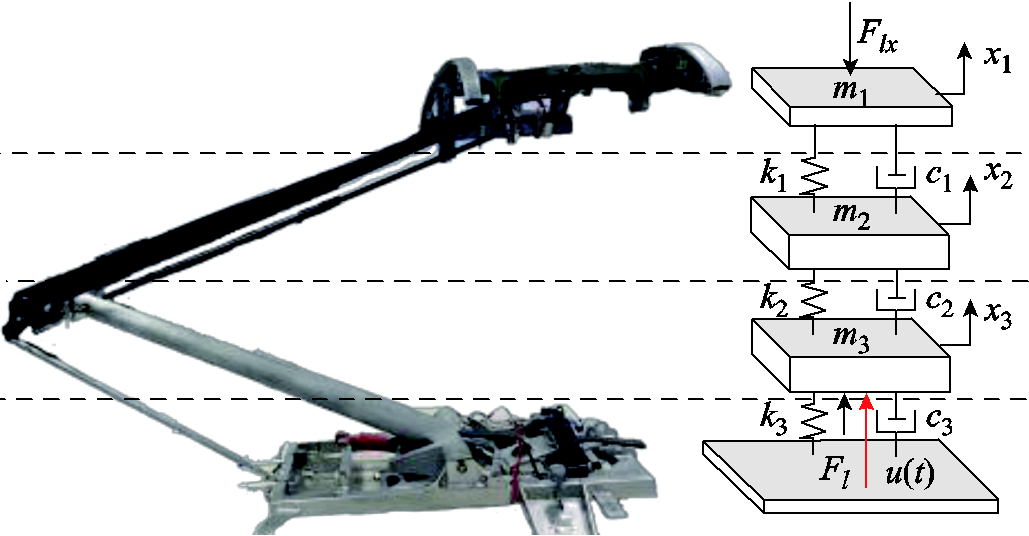
图2 受电弓三元质量弹簧阻尼模型
Fig.2 Pantograph three-element mass-spring-damping model
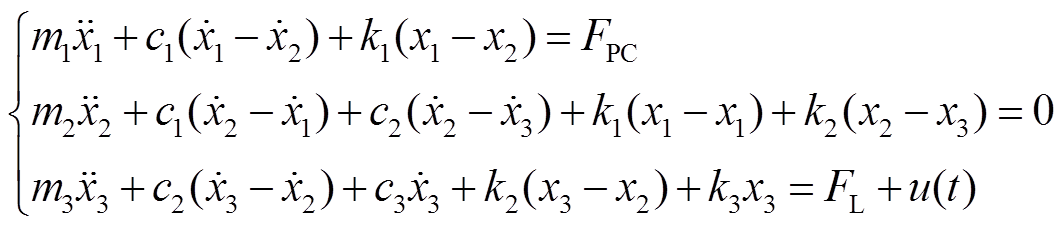 (7)
(7)
式中,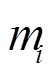 、
、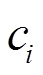 、
、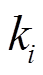 分别为受电弓弓头(i=1)、上框架(i=2)、下框架(i=3)的等效质量、等效阻尼、等效刚度;
分别为受电弓弓头(i=1)、上框架(i=2)、下框架(i=3)的等效质量、等效阻尼、等效刚度;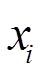 、
、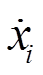 ,
,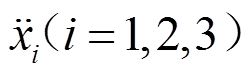 分别为每个质量块的垂直方向的位移、速度、加速度;
分别为每个质量块的垂直方向的位移、速度、加速度;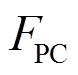 、
、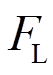 、
、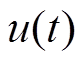 分别为接触力、基础抬升力和主动控制力。
分别为接触力、基础抬升力和主动控制力。
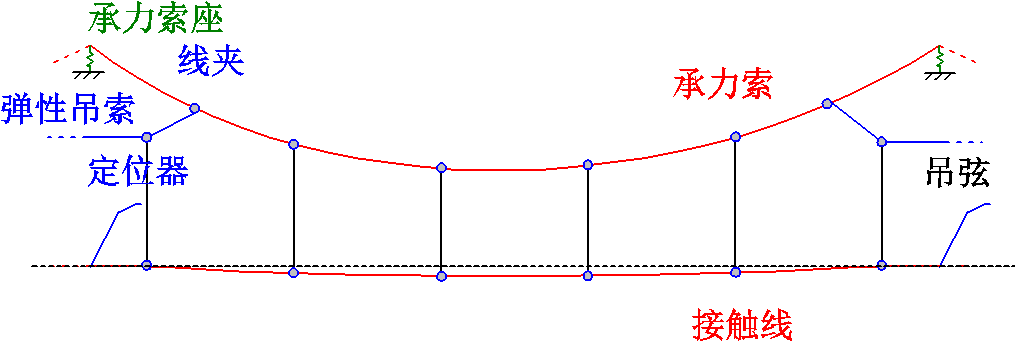
图3 接触网系统示意图
Fig.3 Schematic diagram of catenary
如图3所示,接触网系统主要零部件有接触线、承力索、吊弦等,均为细长结构。接触线、承力索和弹链型悬挂中的弹性吊索在弓网系统运行过程中,表现出明显的波动传播行为,通常采用梁单元进行模拟。本文基于绝对节点坐标法(Absolute Nodal Coordinate Formulation, ANCF),结合静负载目标配置(Target Configuration Under Dead Load, TCUD)找形方法,建立了接触网的精确非线性模型[8]。绝对节点坐标法采用全局坐标对单元进行定义,避免了传统有限元中局部坐标系与全局坐标系之间互相转换的问题。引入接触网质量矩阵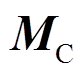 、阻尼矩阵
、阻尼矩阵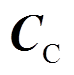 以及刚度矩阵
以及刚度矩阵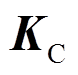 ,接触网的运动方程为
,接触网的运动方程为
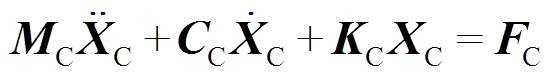 (8)
(8)
式中,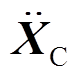 、
、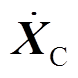 、
、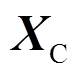 分别为每个节点的全局加速度、速度和位移矢量;
分别为每个节点的全局加速度、速度和位移矢量;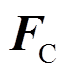 为接触网系统的外力矩阵。
为接触网系统的外力矩阵。
罚函数法模拟弓网接触示意图如图4所示,受电弓与接触网间一般采用罚函数法进行耦合。受电弓弓头与接触线之间设置具有一定的接触刚度为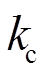 的虚拟接触弹簧[8-10],接触力的计算公式为
的虚拟接触弹簧[8-10],接触力的计算公式为
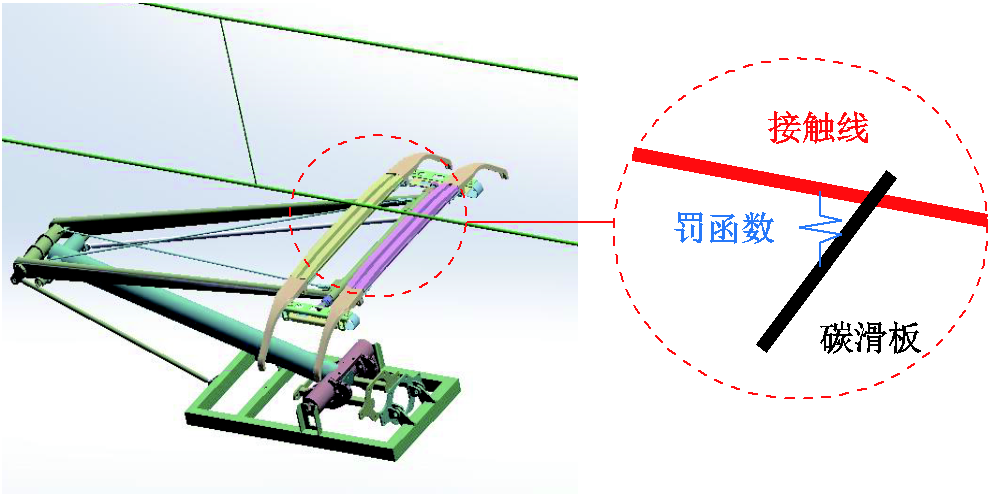
图4 罚函数法模拟弓网接触示意图
Fig.4 Schematic diagram of the penalty function method for simulating pantograph-catenary contact
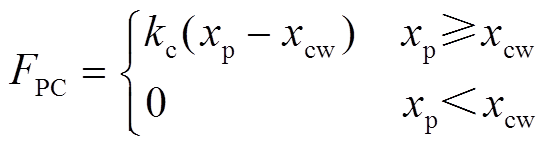 (9)
(9)
式中,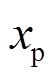 和
和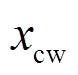 分别为受电弓弓头和接触点的坐标。结合式(7)~式(9),弓网耦合模型可以表示为
分别为受电弓弓头和接触点的坐标。结合式(7)~式(9),弓网耦合模型可以表示为
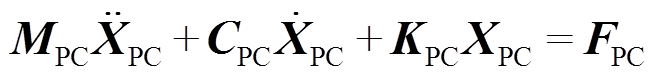 (10)
(10)
式中,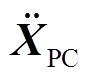 、
、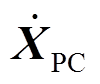 、
、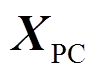 分别为弓网系统整体的全局加速度、速度和位移矢量;
分别为弓网系统整体的全局加速度、速度和位移矢量;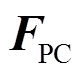 为弓网系统整体的受力矩阵;
为弓网系统整体的受力矩阵;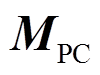 、
、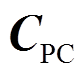 和
和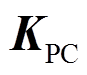 分别为弓网系统整体的质量矩阵、阻尼矩阵以及刚度矩阵。
分别为弓网系统整体的质量矩阵、阻尼矩阵以及刚度矩阵。
基于上下文的深度元强化学习框架如图5所示,本节提出了一种基于上下文的深度元强化学习(Context-Based Deep Meta Reinforcement Learning, CB-DMRL)算法,其结合了改进的离线DRL算法和环境敏感任务编码器。其中改进的离线DRL算法采用了分布式SAC(soft actor critic)算法[22]作为元控制策略,任务编码器接收历史交互数据和当前状态以推断环境的潜在上下文分布(任务编码),然后元策略将生成一个以增强状态向量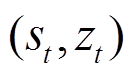 为条件的动作。因此,元策略、状态动作值函数和任务编码器可以表示为
为条件的动作。因此,元策略、状态动作值函数和任务编码器可以表示为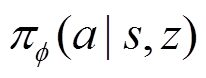 、
、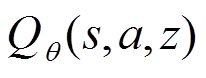 和
和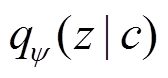 ,其分别采用参数为
,其分别采用参数为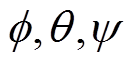 的神经网络参数化。元策略
的神经网络参数化。元策略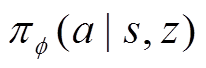 以环境状态
以环境状态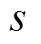 和任务上下文
和任务上下文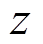 为条件来生成行为策略,编码器从交互数据
为条件来生成行为策略,编码器从交互数据 的上下文中提取潜在信息并确定任务编码。
的上下文中提取潜在信息并确定任务编码。
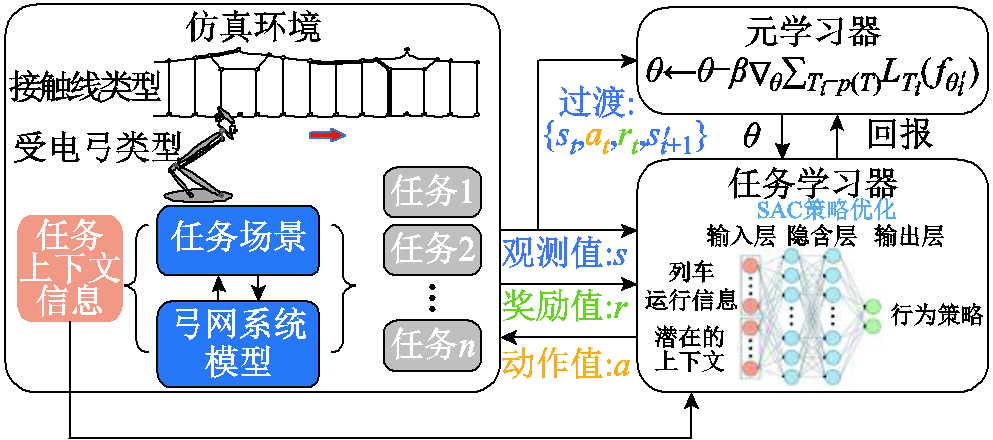
图5 基于上下文的深度元强化学习框架
Fig.5 Context-based deep meta-reinforcement learning framework
CB-DMRL方法学习弓网系统运行条件的任务分布并学习基于上下文的元策略,使其能够快速适应新的目标任务。通过上下文变量进行在线任务推理,元智能体能够快速有效地适应新任务。假设潜在上下文空间 可以表征任务分布,CB-DMRL训练以上下文为条件的元策略,它将任务编码
可以表征任务分布,CB-DMRL训练以上下文为条件的元策略,它将任务编码 视为观测值的一部分。具有任务上下文
视为观测值的一部分。具有任务上下文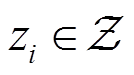 的元控制策略可以被认为是目标任务
的元控制策略可以被认为是目标任务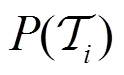 的最优控制策略。考虑到需要确定每个训练任务相应的任务编码,一种直接的方法是使用训练任务的累积奖励作为搜索最优策略的指标。通过重写式(5)可以解决元训练阶段的策略优化问题,有
的最优控制策略。考虑到需要确定每个训练任务相应的任务编码,一种直接的方法是使用训练任务的累积奖励作为搜索最优策略的指标。通过重写式(5)可以解决元训练阶段的策略优化问题,有
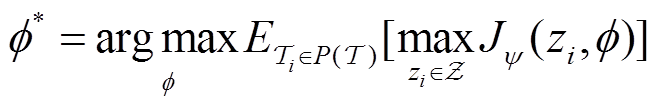 (11)
(11)
式中,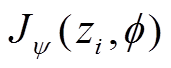 为任务策略
为任务策略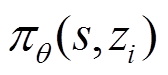 在特定任务
在特定任务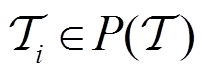 上的累计奖励,表示任务
上的累计奖励,表示任务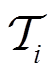 是从任务分布
是从任务分布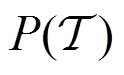 中采样获得;表示弓网系统运行条件任务的任务编码。因为在联合优化策略
中采样获得;表示弓网系统运行条件任务的任务编码。因为在联合优化策略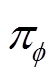 和任务编码时很难直接计算策略参数梯度,直接求解方程式(11)很困难。为了解决这个问题,将式(11)重写为
和任务编码时很难直接计算策略参数梯度,直接求解方程式(11)很困难。为了解决这个问题,将式(11)重写为
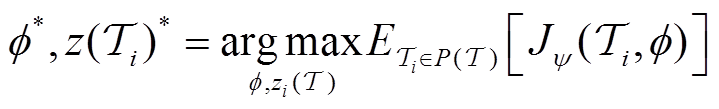 (12)
(12)
式中,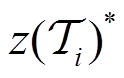 为特定训练任务的最佳任务编码;
为特定训练任务的最佳任务编码;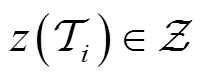 表示任务的任务编码属于潜在空间
表示任务的任务编码属于潜在空间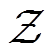 。式(12)的联合优化问题可以通过进一步解耦为两个相关的优化问题来解决,包括优化任务编码
。式(12)的联合优化问题可以通过进一步解耦为两个相关的优化问题来解决,包括优化任务编码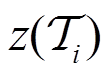 和策略网络参数
和策略网络参数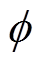 ,分别为
,分别为
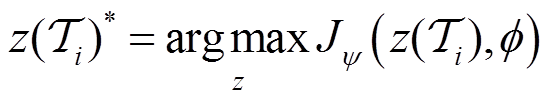 (13)
(13)
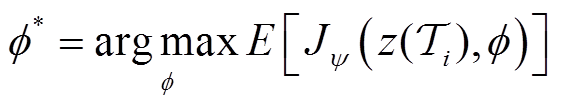 (14)
(14)
方程式(13)定义了任务编码器优化问题,用于优化策略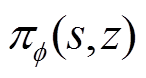 的任务编码,由3.3节中的环境敏感任务编码器求解。等式(14)定义了训练策略网络的策略优化问题,由3.2节中描述的改进分布式SAC算法求解。
的任务编码,由3.3节中的环境敏感任务编码器求解。等式(14)定义了训练策略网络的策略优化问题,由3.2节中描述的改进分布式SAC算法求解。
SAC算法是一种基于最大熵RL框架的动作-评价算法,旨在解决深度强化学习方法的高样本复杂性和稳定性问题[18],其通过熵正则化平衡预期收益和策略熵。熵是策略随机性的度量,增加策略熵会导致更多的探索,加快学习速度并防止策略过早收敛到局部最优。相较于其他包括深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG)[25]、双延迟深度确定性策略梯度算法(Twin Delayed Deep Deterministic Policy Gradient, TD3)[26]、近端策略优化算法(Proximal Policy Optimization, PPO)[27]等在内的深度强化学习算法,SAC利用离线更新和最大熵框架的优势,控制性能更为优越。许多研究结果都表明SAC算法的采样效率和鲁棒性均优于其他深度强化学习算法。对于标准的RL算法而言,控制目标是最大化公式(1)的折扣奖励期望值。SAC采用最大熵RL框架来改善探索效率,在原来的基础上增加了策略的熵值,目标函数为
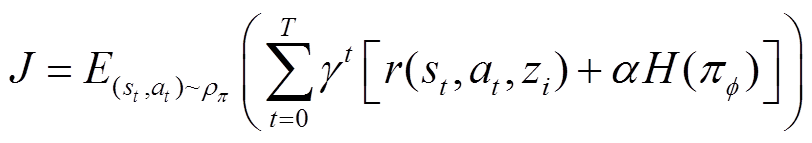 (15)
(15)
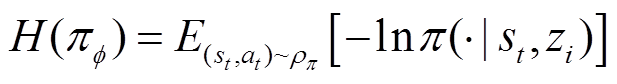 (16)
(16)
式中,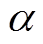 为温度因子,用于表征策略熵值和奖励期望值之间的权衡;
为温度因子,用于表征策略熵值和奖励期望值之间的权衡;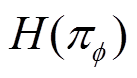 为策略
为策略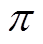 的熵值,当策略随机性越高时,策略中抽样的概率越平均,熵值也就越大。进一步地将状态的熵增累积增益或软回报表示为
的熵值,当策略随机性越高时,策略中抽样的概率越平均,熵值也就越大。进一步地将状态的熵增累积增益或软回报表示为
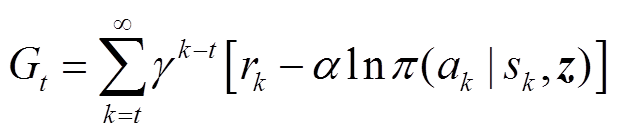 (17)
(17)
式中,k为未来时间步。
行为策略的软Q值描述了状态和策略的预期软收益,可以表示为
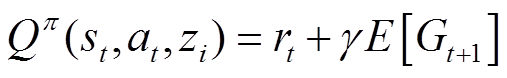 (18)
(18)
3.2.1 分布式状态-动作价值函数
首先定义一个行为策略从状态-动作对开始的分布式状态-动作价值函数(分布式Q函数)为
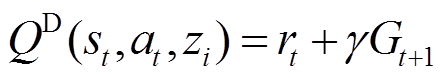 (19)
(19)
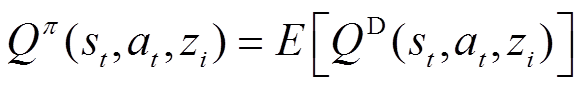 (20)
(20)
分布式状态-动作价值函数的贝尔曼方程可以表示为
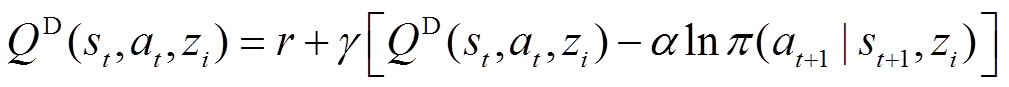 (21)
(21)
神经网络参数化的分布式状态-动作价值函数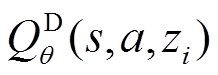 和随机行为策略
和随机行为策略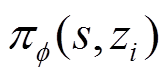 被建模为高斯函数,均值和协方差由神经网络给出。
被建模为高斯函数,均值和协方差由神经网络给出。
3.2.2 双值分布学习
改进分布式SAC算法框架如图6所示,本文引入目标分布式Q函数网络来解决价值估计中的高估问题和稳定训练过程[31-34]。分布式状态-动作价值函数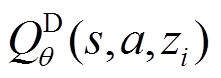 通过下式更新:
通过下式更新:
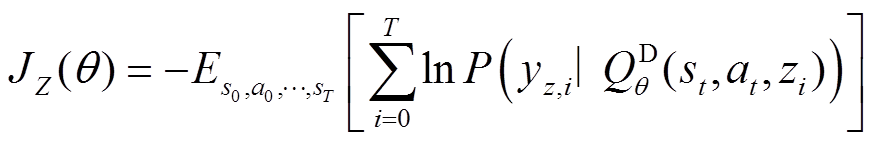 (22)
(22)
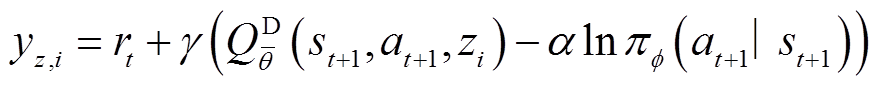 (23)
(23)
式中,为当前Q网络参数;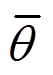 为目标Q网络参数。
为目标Q网络参数。
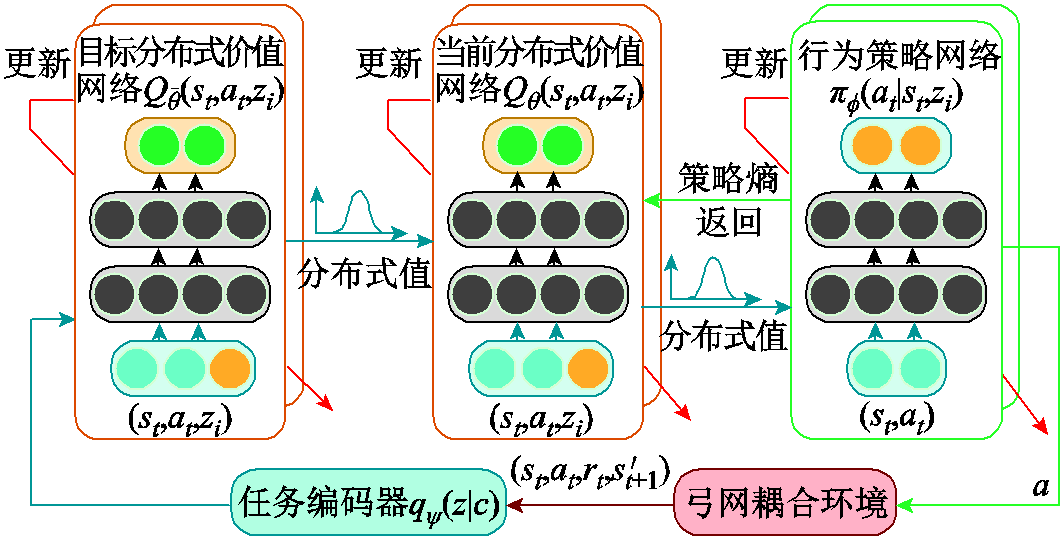
图6 改进分布式SAC算法框架
Fig.6 Improved distributed SAC algorithm framework
进一步参数化两个独立的分布式Q函数,在计算梯度时选择其中均值较小的一个,并以此作为值函数更新时的目标分布。这样可以引入适度的低估偏差,并进一步抑制过估计问题,获得更加稳定的学习过程。
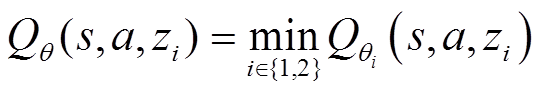 (24)
(24)
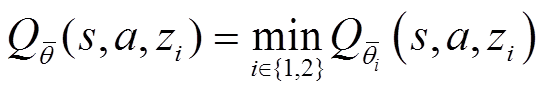 (25)
(25)
行为策略网络通式更新为
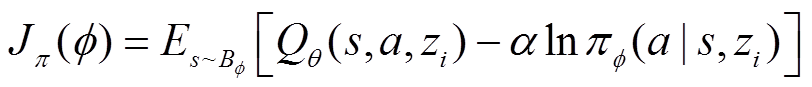 (26)
(26)
温度参数更新为
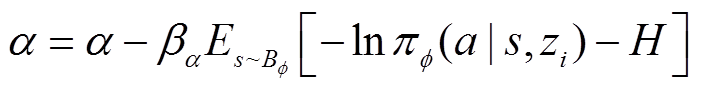 (27)
(27)
式中,H为设定的最小策略熵值;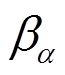 为学习率。目标分布式Q函数网络通过当前分布式Q函数网络和当前行为策略网络定期指数移动平均获得,即
为学习率。目标分布式Q函数网络通过当前分布式Q函数网络和当前行为策略网络定期指数移动平均获得,即
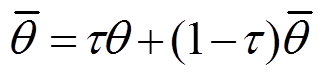 (28)
(28)
式中,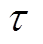 为目标网络给当前网络复制参数的相对软度。
为目标网络给当前网络复制参数的相对软度。
上节定义了由任务编码调制的元行为策略,如果任务编码器能够快速识别和跟踪环境的突然变化,那么元策略也能快速适应环境[35-38]。假设环境或任务的编码信息表示为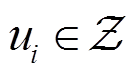 。本文目标是编码器预测的任务上下文接近真实编码信息
。本文目标是编码器预测的任务上下文接近真实编码信息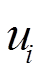 ,迫使任务编码器准确快速地预测。本文使用L2损失来约束和之间的距离,计算公式为
,迫使任务编码器准确快速地预测。本文使用L2损失来约束和之间的距离,计算公式为
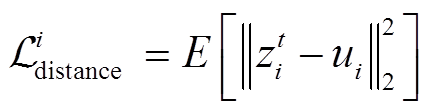 (29)
(29)
式中,真实的任务上下文是未知的,可以使用移动平均任务编码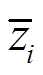 来估计。实际应用时可以通过在环境经验样本库
来估计。实际应用时可以通过在环境经验样本库 中采样一批交互数据计算移动平均任务编码,计算公式为
中采样一批交互数据计算移动平均任务编码,计算公式为
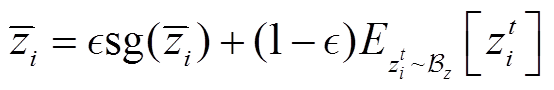 (30)
(30)
式中,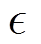 为移动平均水平,
为移动平均水平,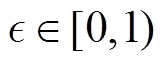 。因此,环境敏感的任务编码器损失函数可以写为
。因此,环境敏感的任务编码器损失函数可以写为
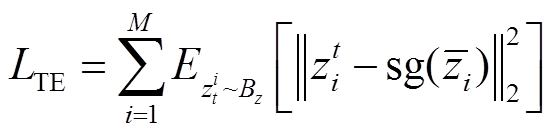 (31)
(31)
式中,M为训练任务的数量;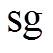 为梯度停止,自动梯度工具将丢弃关于任务编码器参数的梯度。
为梯度停止,自动梯度工具将丢弃关于任务编码器参数的梯度。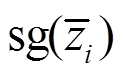 相对于任务编码器参数的梯度始终为零,而
相对于任务编码器参数的梯度始终为零,而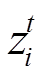 则继续求梯度。
则继续求梯度。
在实际应用时,本文使用循环神经网络实例化环境敏感任务编码器从在线轨迹中提取任务上下文信息,并使用最近的H步交互数据来避免太旧的交互数据误导上下文编码。任务编码器预测的潜在上下文可以写为
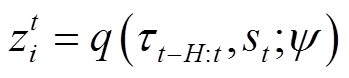 (32)
(32)
式中,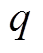 为参数为
为参数为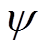 的RNN编码器网络,
的RNN编码器网络,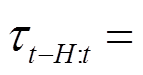
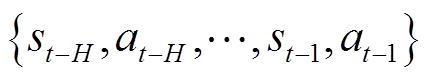 。
。
环境敏感任务编码器训练的总体步骤是首先收集每个任务的交互轨迹并将其保存到重播缓冲区。编码器网络编码当前轨迹上下文来执行任务自适应,生成的潜在任务编码封装了当前任务信息;然后元策略网络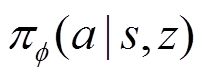 根据任务编码信息生成行为策略。
根据任务编码信息生成行为策略。
本文开发的CB-DMRL算法具有两阶段更新器来训练具有良好泛化性的元控制策略。在元学习阶段,学习一种对所有任务都表现良好的元控制策略;在元适应阶段,学习的元策略通过几个步骤快速适应新任务或未知运营情况。如图5所示,CB-DMRL算法由两个循环组成:外部任务编码器优化和内部元策略优化。表1给出了所提出的CB-DMRL算法的训练框架和过程。本节将详细描述所提出的算法。
表1 CB-DMRL算法伪代码
Tab.1 CB-DMRL algorithm pseudocode

算法:基于深度元强化学习的自适应控制策略 输入:元策略网络,分布式Q函数网络,任务编码器,任务分布。输出:元策略网络1 初始化环境经验重放缓冲区和环境。2 随机初始化策略、Q函数和编码器3 使用参数复制初始化目标Q函数网络4 元策略训练5 采样个任务 6 使用收集交互样本并添加到任务重播缓冲区7 采样一批上下文,根据式(33)优化任务编码器8 根据式(22)优化分布式Q函数网络9 根据式(26)优化策略网络10 根据式(27)和式(28)更新温度参数和目标分布式Q函数11 元策略测试12 对于新/未知的控制任务或环境:13 使用收集交互样本并添加到任务重播缓冲区14 实用任务编码器生成最优任务编码15 使用元策略解决控制任务16 结束返回:元策略网络
(1)模型初始化。
首先随机初始化元策略网络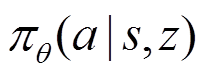 和分布式Q函数网络
和分布式Q函数网络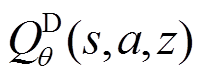 ,并采样一批来自任务分布
,并采样一批来自任务分布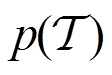 的训练任务
的训练任务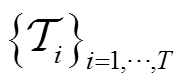 ,然后为每个任务初始化空任务重播缓冲区
,然后为每个任务初始化空任务重播缓冲区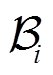 。
。
(2)任务交互样本收集。在每回合开始时重置训练任务环境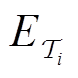 ,每个环境从初始状态
,每个环境从初始状态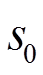 开始并传输到元智能体;然后元策略网络输出高斯策略并采样一个动作,智能体执行动作后环境移动到下一个状态
开始并传输到元智能体;然后元策略网络输出高斯策略并采样一个动作,智能体执行动作后环境移动到下一个状态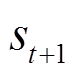 并生成奖励
并生成奖励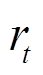 ;交互样本存储在体验重放缓冲区中。
;交互样本存储在体验重放缓冲区中。
(3)元策略训练。元策略训练包含两个优化步骤。在任务编码器优化循环中,首先固定元策略权重,其中任务编码器用于计算最优任务编码;在元策略内循环优化中,首先固定每个训练任务的任务编码,然后改进的分布式SAC算法用于更新元策略和分布式Q函数网络。
(4)元策略适应。适应阶段利用训练有素的元策略来快速适应目标任务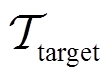 ,环境敏感任务编码器根据目标任务的交互经验快速生成任务编码。首先对目标任务进行采样并优化任务编码
,环境敏感任务编码器根据目标任务的交互经验快速生成任务编码。首先对目标任务进行采样并优化任务编码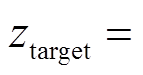
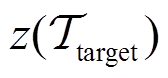 ,该过程产生对应于特定目标任务的最优任务编码
,该过程产生对应于特定目标任务的最优任务编码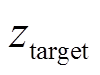 和元策略
和元策略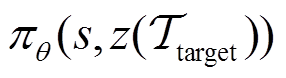 。
。
为了将CB-DMRL算法应用到受电弓主动控制中,本节设计了状态空间、动作空间、奖励函数。
3.5.1 状态空间
状态是智能体对环境的感知,并作为受电弓主动控制策略的输入。在本文中,受电弓的状态由受电弓-接触网混合模拟实验台的状态监测系统采集。利用受电弓垂向位移、速度、加速度和列车行驶速度来构造状态向量,表示为
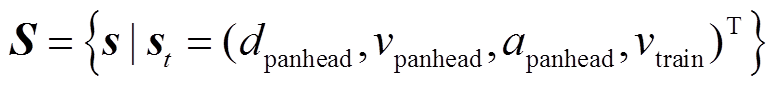 (33)
(33)
式中,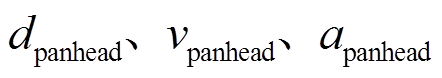 分别为受电弓滑块在时间步
分别为受电弓滑块在时间步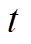 的垂向位移、速度和加速度;
的垂向位移、速度和加速度;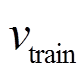 为列车的列车行驶速度。
为列车的列车行驶速度。
为了约束智能体的行为模式,使其尽可能保持平滑性和周期性。本文使用平滑滤波器来约束动作空间中的动作噪声,动作空间可以表示为
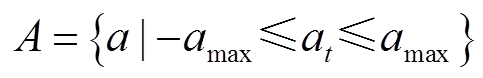 (34)
(34)
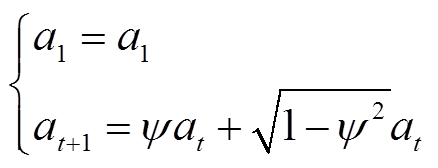 (35)
(35)
式中,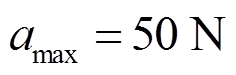 ;
;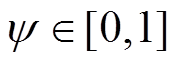 为滤波系数,约束了动作随时间步长的变化率。
为滤波系数,约束了动作随时间步长的变化率。
奖励函数的作用是使得智能体能够感知到决策的好坏,从而调整自身的控制策略以向更好的方向发展。控制器的主要目的是减少弓网接触力波动,使接触力时程足够平滑流畅,减少受电弓离线率。另外,控制力的剧烈变化会对受电弓和气动执行器的关节造成永久性损害,需要约束小的控制力和少的控制调整次数。奖励函数设置为
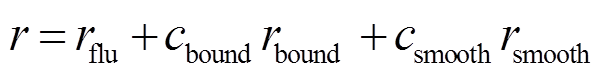 (36)
(36)
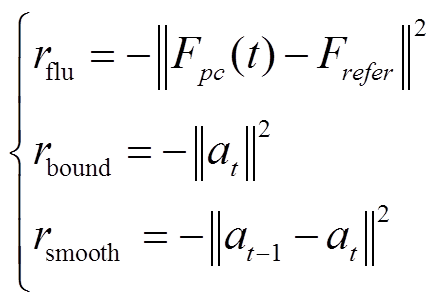 (37)
(37)
式中,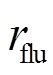 为接触力波动损失,其目标是惩罚弓网接触力波动;
为接触力波动损失,其目标是惩罚弓网接触力波动;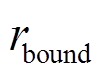 为有限动作幅度的边界损失,其目标是惩罚幅值过大的控制动作,节约制动器能量消耗;
为有限动作幅度的边界损失,其目标是惩罚幅值过大的控制动作,节约制动器能量消耗;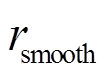 为平滑度损失,其目标是惩罚振荡的控制力导致受电弓关节上的额外磨损;
为平滑度损失,其目标是惩罚振荡的控制力导致受电弓关节上的额外磨损;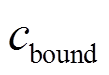 和
和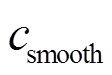 为权重系数,用于平衡损失。
为权重系数,用于平衡损失。
本节将展示仿真和硬件在环结果以验证所提出的主动受电弓控制算法的性能。
本文所有实验都是在配备Intel(R) Xeon(R) CPU E5-2640 v4运行(主频4.40 GHz)和NVIDIA GeForce RTX 3090显卡的服务器上进行的。核心算法是在Ubuntu 20.04.3服务器系统上使用PyTorch 1.5架构创建的。
4.1.1 参数设置
本文使用两个包含3层隐含层的多层感知机(Multilayer Perceptron, MLP)参数化元策略网络、分布式Q函数网络和任务编码器网络。并且使用ReLu激活函数和自适应矩估计方法(Adaptive moment estimation, Adam)进行训练。为了系统性地确定最优参数组合,本文采用了一种结合自动化搜索和稳定性验证的两阶段优化策略。首先,利用自动化超参数优化框架Optuna[28]对关键参数(如学习率、网络神经元数量、折扣因子等)在预设的范围内进行高效搜索,其优化目标为最大化训练任务的平均累积奖励,从而筛选出若干组高性能的候选参数。随后,为应对深度强化学习训练过程中的不确定性,对这些候选参数集进行了严格的鲁棒性测试。具体而言,每组参数都在5~8个不同的随机种子下进行完整的重复训练。最终的选择标准是综合性的,不仅要求其在所有种子实验中取得最高的平均性能,同时还要求其性能方差最小且奖励曲线收敛平稳。所提控制算法中的神经网络结构算法参数设置见表2。
表2 算法参数设置
Tab.2 Algorithm parameter settings
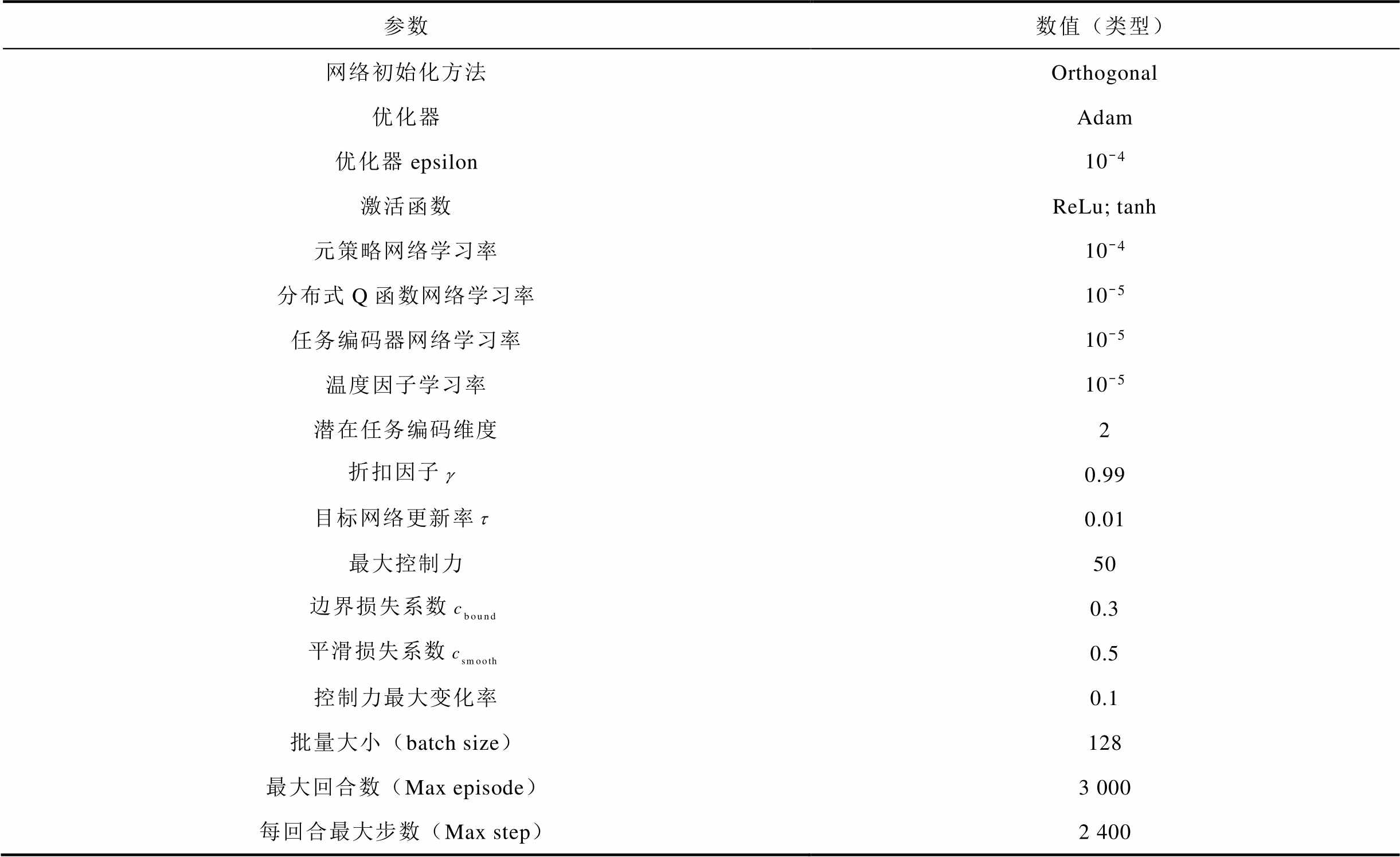
参数数值(类型) 网络初始化方法Orthogonal 优化器Adam 优化器epsilon10-4 激活函数ReLu; tanh 元策略网络学习率10-4 分布式Q函数网络学习率10-5 任务编码器网络学习率10-5 温度因子学习率10-5 潜在任务编码维度2 折扣因子0.99 目标网络更新率0.01 最大控制力50 边界损失系数0.3 平滑损失系数0.5 控制力最大变化率0.1 批量大小(batch size)128 最大回合数(Max episode)3 000 每回合最大步数(Max step)2 400
为模拟真实场景的交互场景,本文采用了国内广泛采用的真实受电弓和接触网参数, DSA380型受电弓参数见表3,京津线、京沪线和京广线接触网结构参数见表4。根据欧洲电工标准化委员会标准EN50318,接触力通过0~20 Hz进行滤波[8,19]。如无特殊说明,本文的接触力均是指20Hz滤波后的接触力。
表3 DSA380型受电弓参数
Tab.3 DSA380 pantograph parameters

参数标称值 等效质量m1, m2, m37.12, 6, 5.8 等效阻尼c1, c2, c30, 0, 70 等效刚度k1, k2, k39 340, 14 100, 0.1
表4 接触网结构参数
Tab.4 Catenary structural parameters

参数京津线京沪线京广线 跨距/m485050 结构高度/m1.61.61.6 拉出值/m±0.2±0.2±0.2 吊弦数/个555 承力索张力/kN212021
(续)
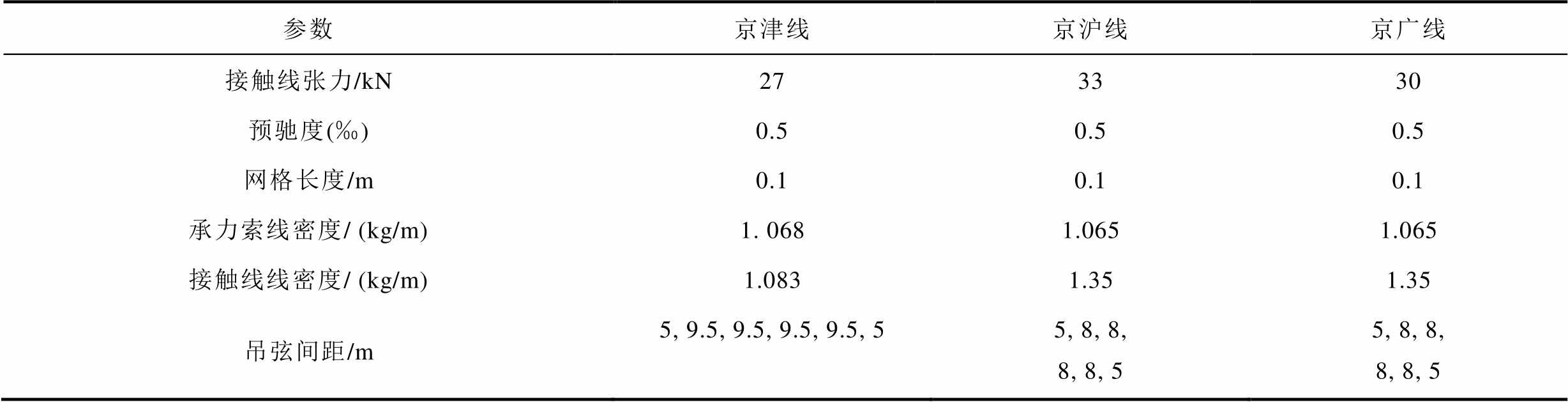
参数京津线京沪线京广线 接触线张力/kN273330 预驰度(‰)0.50.50.5 网格长度/m0.10.10.1 承力索线密度/ (kg/m)1. 0681.0651.065 接触线线密度/ (kg/m)1.0831.351.35 吊弦间距/m5, 9.5, 9.5, 9.5, 9.5, 55, 8, 8, 8, 8, 55, 8, 8, 8, 8, 5
接触线的不平顺是影响弓网动力学特性的重要因素。在电气化铁路线路中,接触线的不平顺是由架空线的位置、本身的形状以及架空线表面的磨损程度决定的。在接触网有限元模型中,架空线路的不均匀方程可描述为[8]
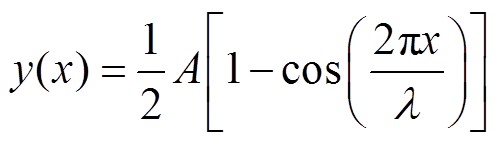 (38)
(38)
式中,A为不平顺幅值;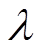 为不平顺波长;
为不平顺波长;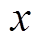 为沿接触线的坐标。本文使用不同的线路不规则参数来验证所提出的控制策略的鲁棒性。本文考虑以下20种情况:A=1, 2, 3, 4 mm,=2, 3, 4, 5, 6 m,其中不平顺幅值A和不平顺波长任一组合为一种不平顺扰动案例。
为沿接触线的坐标。本文使用不同的线路不规则参数来验证所提出的控制策略的鲁棒性。本文考虑以下20种情况:A=1, 2, 3, 4 mm,=2, 3, 4, 5, 6 m,其中不平顺幅值A和不平顺波长任一组合为一种不平顺扰动案例。
随机风场也是弓网系统受到的外界扰动之一,本文利用风谱通过时域反演方式获得随机风时程,建立风场模型。当风吹过接触线时,根据流体引发结构振动理论[28],作用在接触线上的气动力可以表示为
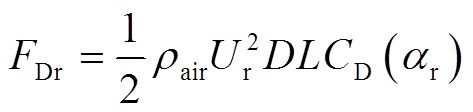 (39)
(39)
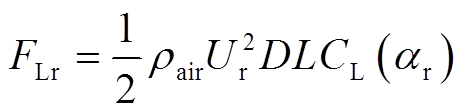 (40)
(40)
式中,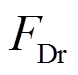 和
和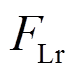 分别为横向的阻力和纵向的升力;
分别为横向的阻力和纵向的升力;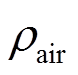 为空气密度;
为空气密度;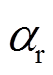 为实际风攻角;
为实际风攻角;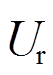 为相对风速;D和L分别为接触线的长度和截面直径;
为相对风速;D和L分别为接触线的长度和截面直径;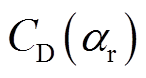 和
和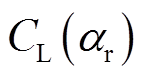 分别为在攻角处的阻力和升力系数,可以通过流伴动力学计算计算得到。本文考虑以下20种情况:
分别为在攻角处的阻力和升力系数,可以通过流伴动力学计算计算得到。本文考虑以下20种情况: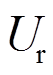 = 10, 20, 30, 40 m/s,=15°, 30°, 45°, 60°, 75°,其中不实际风攻角和相对风速
= 10, 20, 30, 40 m/s,=15°, 30°, 45°, 60°, 75°,其中不实际风攻角和相对风速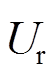 的任一组合为一种随即风扰动案例。
的任一组合为一种随即风扰动案例。
4.1.2 对比方法和指标
为了验证所提算法的性能,在仿真分析中与现有受电弓控制方法进行了比较:
(1)现有的DMRL方法。文献[21]提出了一种高效的离线策略RL算法(Probabilistic Embeddings for Actor-critic meta-RL, PEARL),将变分推理和策略梯度公式相结合来学习任务编码策略,它代表了最先进的DMRL算法。
(2)现有的DRL方法。本文对比了一种DRL方法-近端策略优化算法(PPO)[27],它代表了最先进的DRL算法。
(3)传统方法。本文对比了基于先验信息的有限频域控制方法(PFH∞)[9],其将接触网的周期性结构特征先验知识融入控制器设计中,通过接触力频域分析或时频域分析,例如傅里叶变化或功率谱密度函数得到接触力的主导频率或接触网结构信息,在计算控制增益矩阵时从频域角度减少接触力的主导频率成分。
本文选择以下指标来评估训练和测试阶段的性能:①接触力标准差(Standard Deviation, STD),描述了接触力波动的幅度;②最终奖励和适应速度。元强化学习的目标是快速收敛于训练任务和快速适应未知任务,因此比较了训练任务中的最终奖励和适应速度。
本节设置了3×20×20个控制任务(三种接触网类型,不平顺和随机风扰动各20种),训练任务∶测试任务设置为8∶2用于评估元智能体的适应能力。并与其他控制方法进行对比,其中预训练的PPO使用微调方法来适应测试任务。不同控制方法在测试任务中的总奖励如图7所示。每个实验使用随机种子重复8次,图中的实线表示平均奖励,阴影区域表示奖励标准差。
图7a表明所提出的CB-DMRL算法能够以最高的数据效率快速适应新环境。提出的元智能体优于预训练的智能体,并且奖励的快速增加表明提出的元智能体可以比预训练的智能体更快地适应新环境。CB-DMRL方法在4×104交互样本上实现了良好的性能收敛,而PEARL和PPO方法需要超过4×106的交互样本互数据才能收敛。图7b给出了适应过程中不同方法的奖励曲线,其表明所提出的CB-DMRL算法能够快速适应测试任务并获得最高的奖励,其在两次迭代后快速适应并获得高回报。预训练的PPO在新任务上完全崩溃,需要重新收集数据来学习控制策略。PEARL作为DMRL算法,适应新任务的速度很慢,甚至有时适应失败,在训练结束时仍然频繁崩溃。
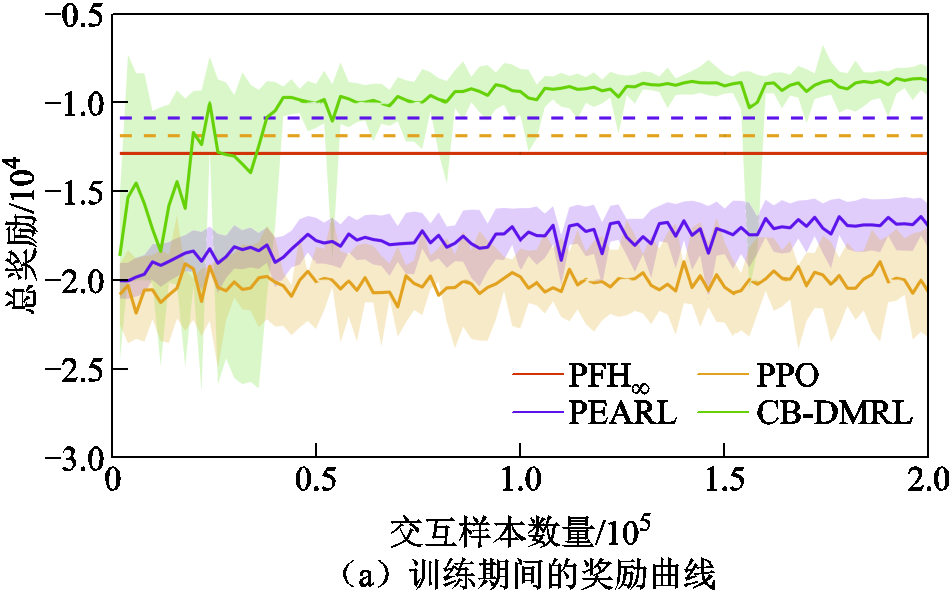
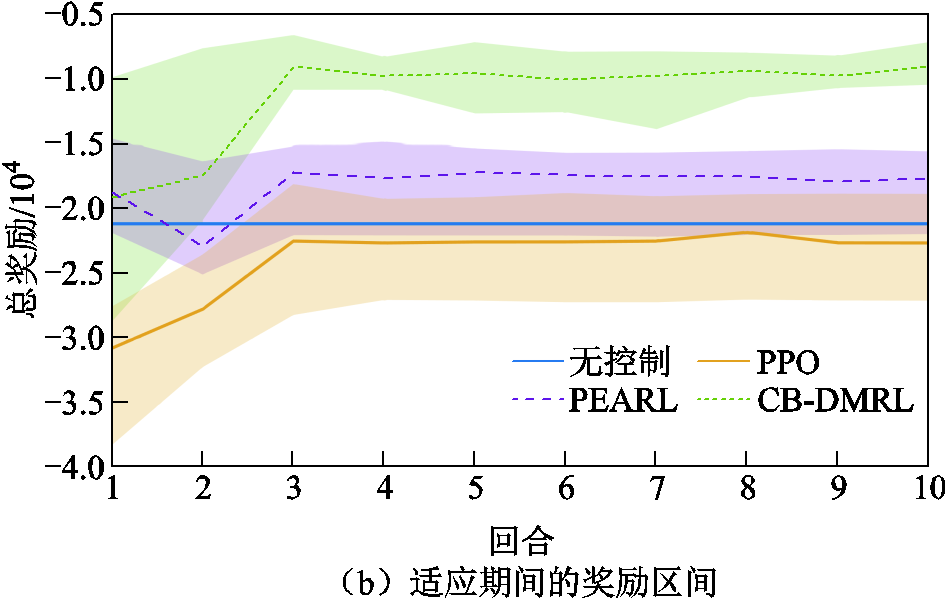
图7 不同控制器的性能对比
Fig.7 Performance comparison of different controller
为了证明本文所提方法在具体案例中的实际性能,本节选择一组弓网系统运行环境(DSA380受电弓和京津线接触网参数)以测试不同控制器在实际运行中的实际性能。不同运行速度下的综合比较结果见表5。结果表明本文提出的方法在不同的运行速度下均实现了最小的接触力标准差,证明了本文方法的有效性和优越性。
表5 不同控制器性能对比
Tab.5 Performance comparison of different controllers
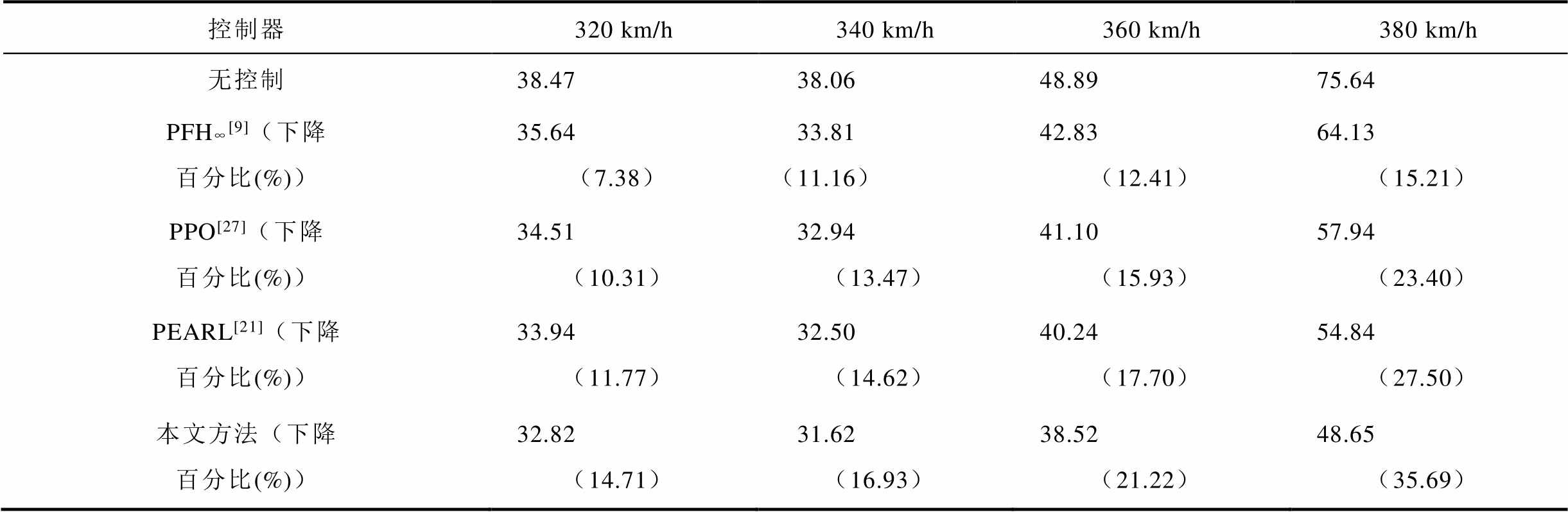
控制器320 km/h340 km/h360 km/h380 km/h 无控制38.4738.0648.8975.64 PFH∞[9](下降百分比(%))35.64(7.38)33.81(11.16)42.83(12.41)64.13(15.21) PPO[27](下降百分比(%))34.51(10.31)32.94(13.47)41.10(15.93)57.94(23.40) PEARL[21](下降百分比(%))33.94(11.77)32.50(14.62)40.24(17.70)54.84(27.50) 本文方法(下降百分比(%))32.82(14.71)31.62(16.93)38.52(21.22)48.65(35.69)
值得注意的是,当面临全新的测试环境时,本文方法可以通过环境编码器快速推理出任务编码从而适应新环境,相比之下PEARL则需要更多的环境交互数据,从而逐渐适应环境。PPO方法在面对新环境时表现崩溃,需要重新训练智能体。表6给出了CB-DMRL、PEARL、PPO和PFH∞方法在测试场景中的计算时间对比。表中的“推理时间”表示测试场景中每个控制步骤的平均计算时间,所有方法平均需要不到0.1 s的时间来计算控制动作,都满足“实时性”要求。表6还证明CB-DMRL方法可以快速适应新的环境或扰动,原因是环境敏感的任务编码器可以根据新任务的交互经验(上下文)快速推断任务编码,实现原策略的有效泛化。
表6 不同控制器时间消耗对比
Tab.6 Comparison of time consumption of different controllers

参数CB-DMRLPEARL[21]PPO[27][9] 训练时间24 h10 h20 d 适应时间10 min25.61 h2 d 推理时间/ms3.63.72.71.5
为了评估智能体在面对未知环境时的自适应性能,本节在训练任务分布的测试环境中(A=6 mm,=8 m,=60 m/s,=45°)评估了所有控制方法的泛化性,通常称之为不可见任务或未知任务。图8给出了所有方法在不同测试场景上的最终奖励,每组实验使用随机种子重复10次,图中的实线表示平均奖励,阴影区域表示奖励标准差。图8a表明,CB-DMRL方法可以快速适应新环境,同时在扰动条件下表现良好,进一步证明DRL算法缺乏泛化能力,导致难以适应新的或未知的弓网系统环境。图8b给出了各种场景的奖励分布箱图,其显示CB-DMRL方法以较小的波动范围产生最高的奖励。综上所述,即使与训练任务的差异很大,CB-DMRL算法也可以快速适应未知的弓网系统运行环境。
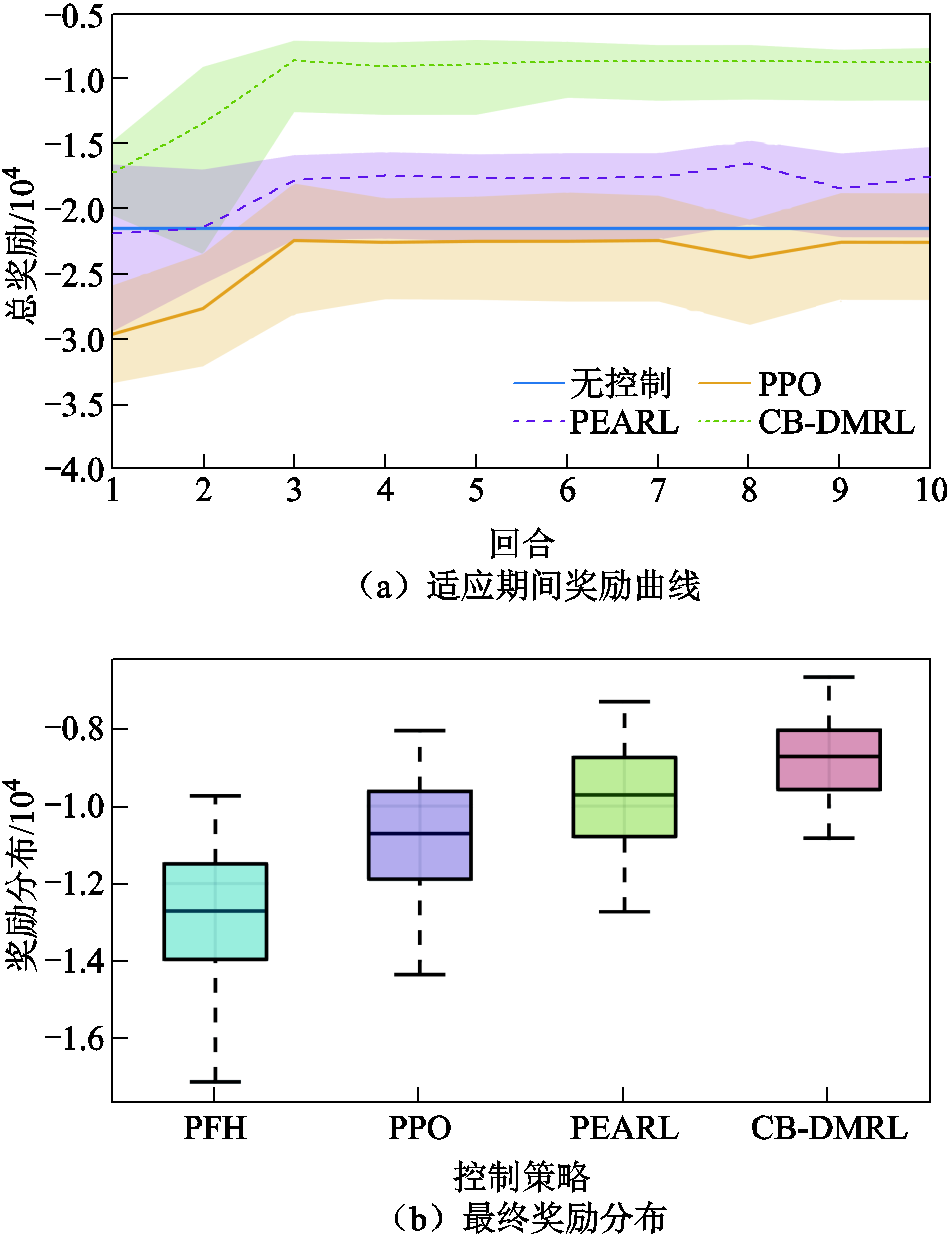
图8 未知环境条件的不同控制器性能对比
Fig.8 Performance comparison of different controller under unknown environmental conditions
为评估任务编码器能否快速识别和跟踪环境的突然变化,本小节将任务上下文编码为二维向量。图9给出了分布内和分布外任务的上下文编码可视化结果,并用颜色条可视化任务的潜在上下文,图中实际任务上下文是环境中随机风速。实验结果表明,环境敏感任务编码器成功地从在线轨迹中推断出高质量的特定于任务的上下文信息,动力学相似的任务在任务上下文编码空间中很接近。此外任务上下文编码可以泛化到训练任务分布外的环境,这表明任务编码器甚至可以为元策略提供足够多的任务上下文信息。
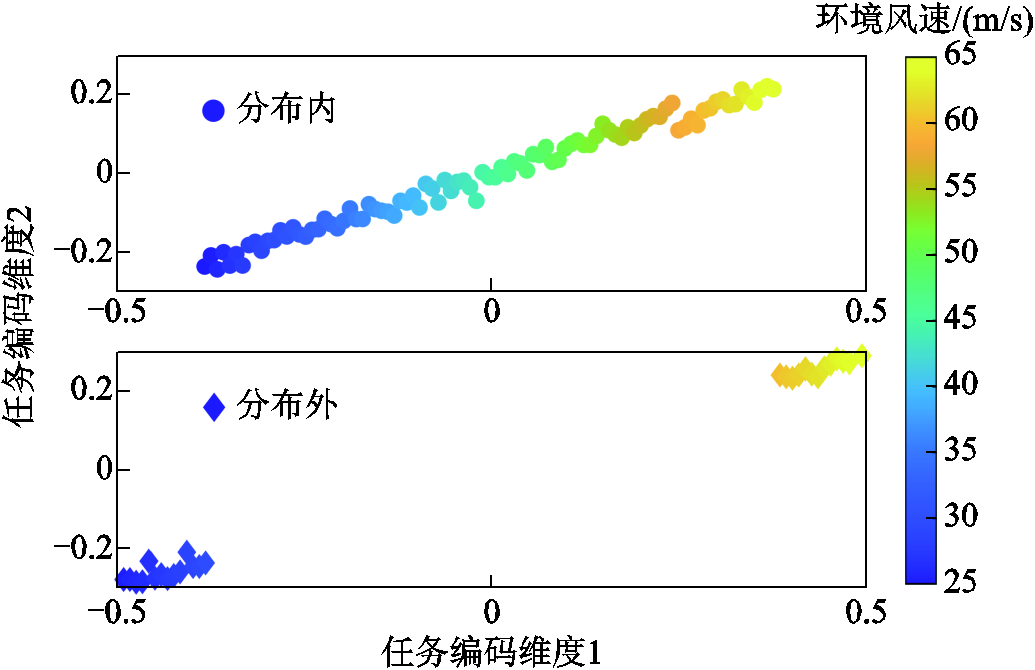
图9 任务上下文编码可视化
Fig.9 Visualization of task context encoding
图10给出了非平稳环境中任务上下文编码的变化,图中,“real”曲线表示环境随机风信息的标准化值。本节将环境扰动设置为每100步突然变化,因此实际任务上下文将与100步中的变化相同,值得注意的是,本文的任务上下文编码只是用于表征不同的环境信息,并不等于实际环境上下文信息。实验结果表明,任务编码器可以快速检测和跟踪环境变化。如果任务动力学发生变化,任务编码会立即响应并在10步内收敛,使得元策略能够快速适应任务信息和环境动力学的变化。
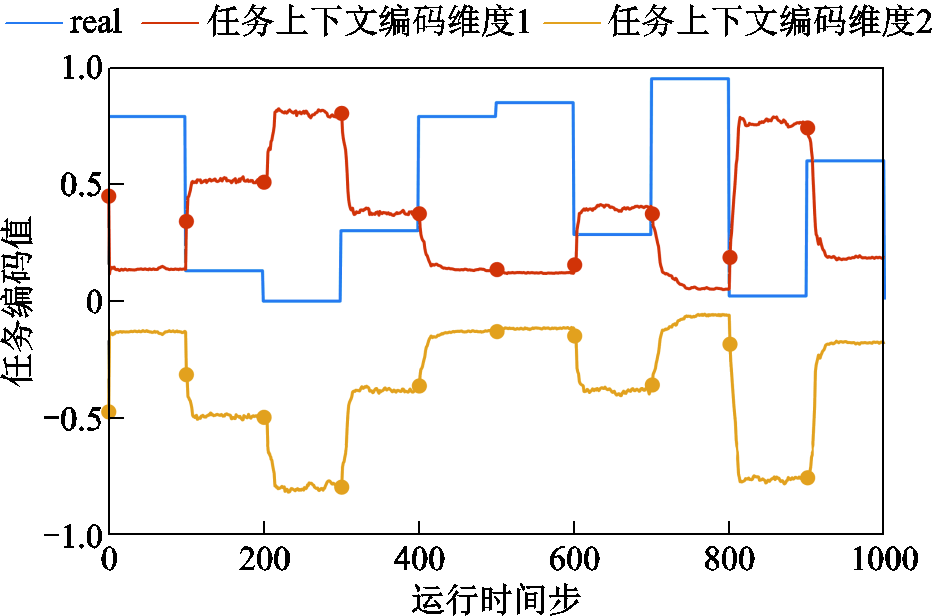
图10 非平稳环境下任务上下文编码可视化
Fig.10 Visualization of task context encoding in non-stationary environments
本节在主动受电弓硬件在环实验台上测试了所有控制器在复杂多样的运行环境下的实际性能。受电弓-接触网混合模拟实验台如图11所示。考虑以下系统特性变化和环境扰动的情况,扰动接入时标记为扰动点。
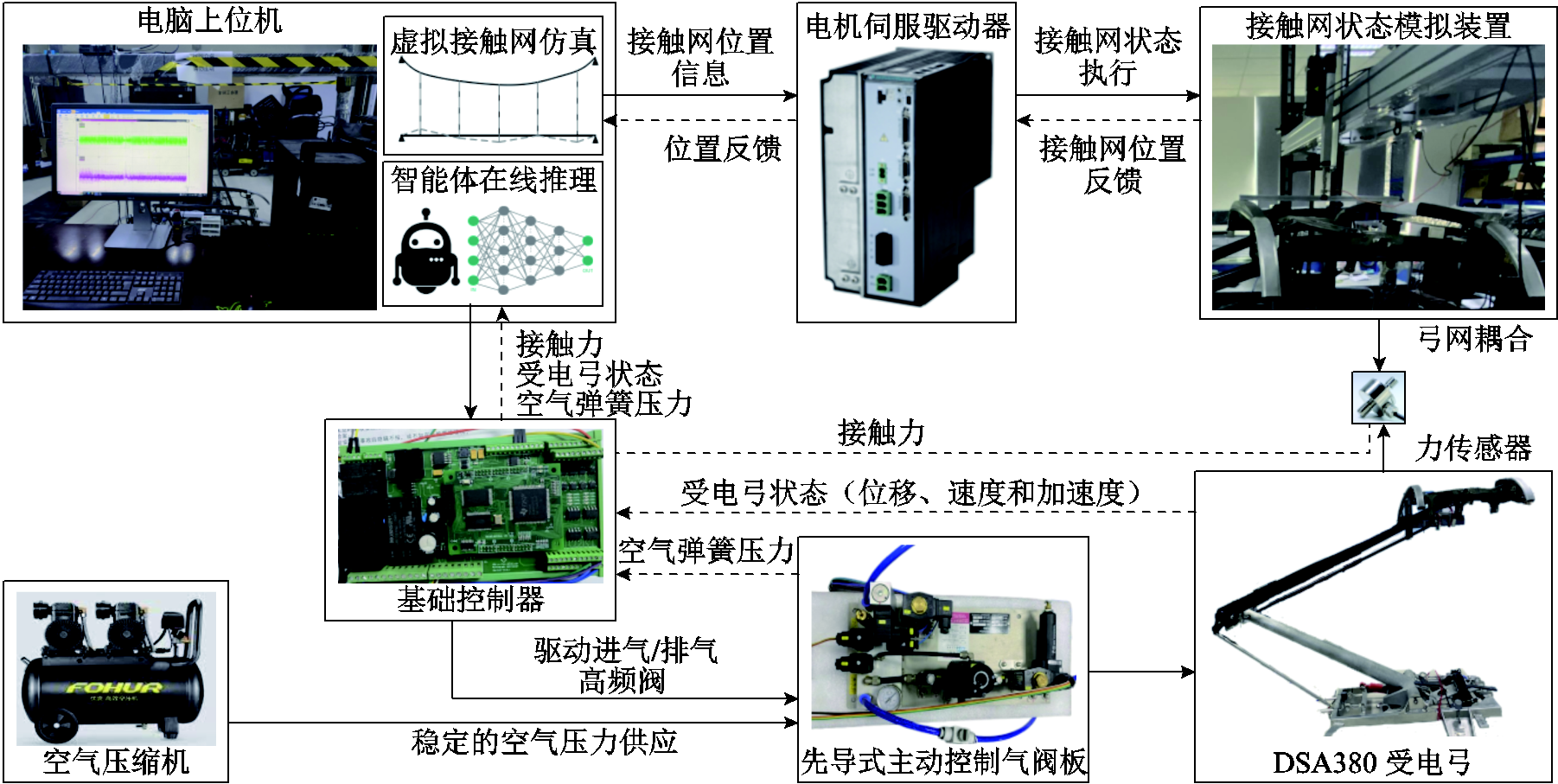
图11 受电弓-接触网混合模拟实验台
Fig.11 Pantograph-catenary hybrid simulation test bench
案例1:新运营场景。虚拟接触网在线仿真参数由京津线变更为沪昆线。
案例2:接触线不平顺场景,参数设置为 。
。
图12a和图12b中,上边子图给出了不同控制策略在不同环境扰动场景下的接触力曲线。实验结果表明,所提CB-DMRL方法通过10 m距离内的元适应实现了最佳性能,证明了对环境扰动的鲁棒性泛化性。由于缺乏对外部环境变化的适应性,对比控制器的性能则明显下降。注意到CB-DMRL方法在所有情况下都避免了弓网离线,这对于确保列车稳定的受流质量至关重要。下边子图证明了环境敏感的任务编码器可以快速适应新环境,并在环境改变后生成适当的任务编码。
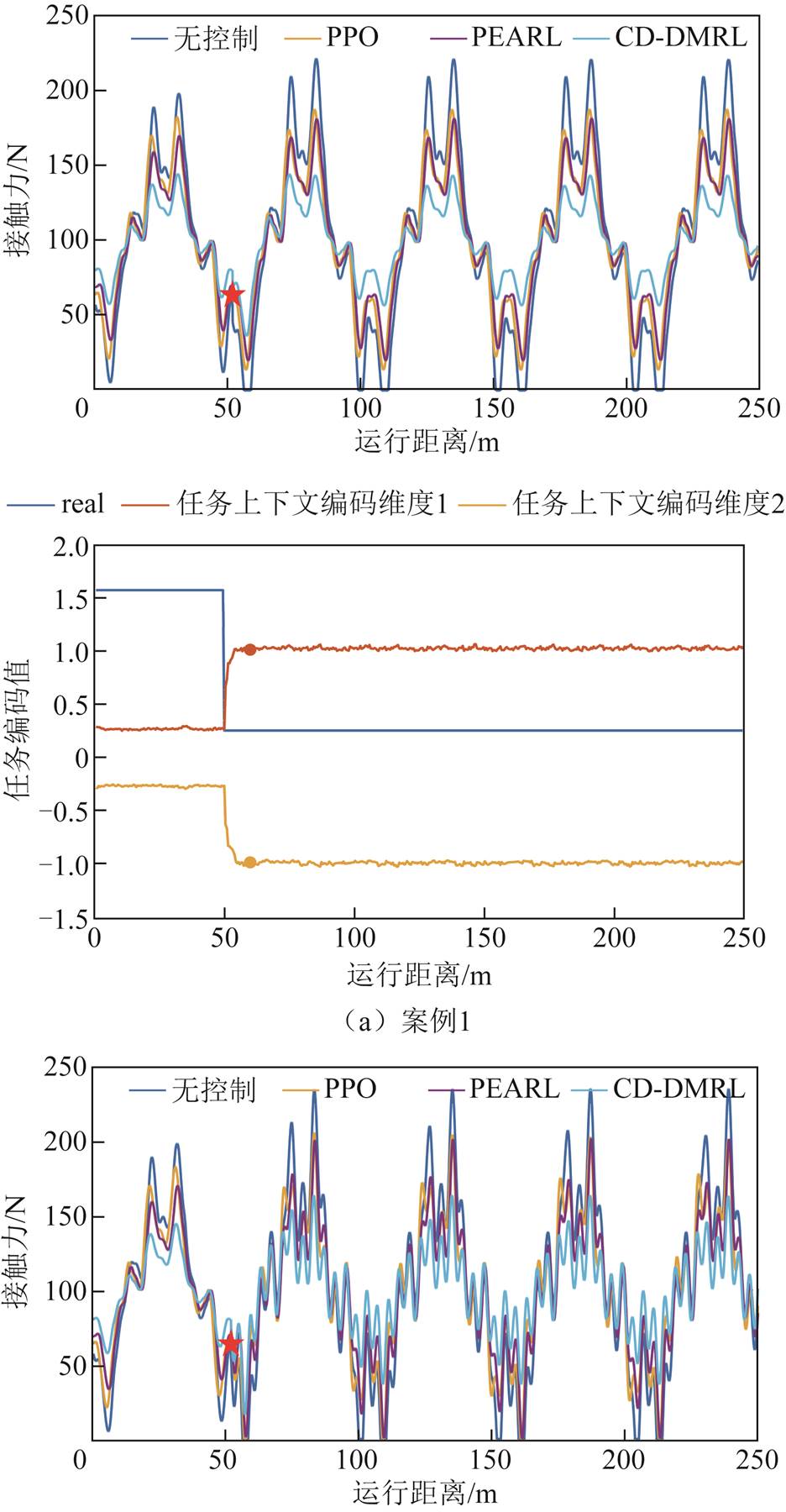
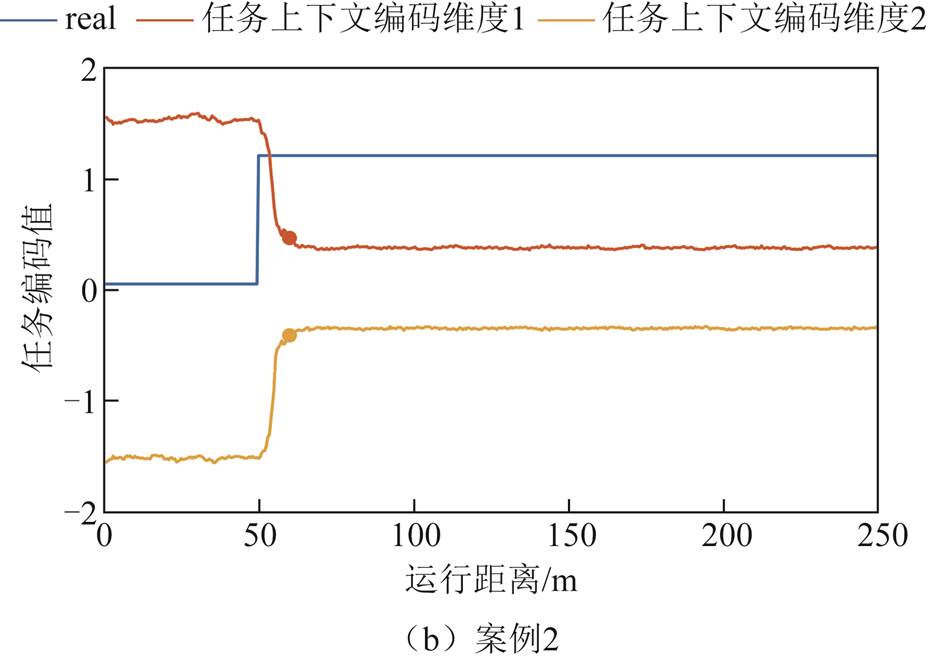
图12 不同控制器的性能对比
Fig.12 Performance comparison of different controllers
针对在不同运行场景和条件的受电弓主动控制问题,本文提出了一种基于上下文的深度元强化学习算法。该方法利用训练期间的任务经验快速地适应了测试任务,经过几十次实验就可以有效地学习并解决具有相似结构的任务分布并适应全新的环境。通过仿真和主动受电弓硬件在环实验对比分析,可以得出以下结论:
1)本文算法组件中,改进的分布式SAC算法能够有效提高价值估计精度和稳定训练过程,以解决爆炸和消失的梯度问题。环境变化敏感的任务编码器能够根据交互样本的上下文快速生成最优任务编码。
2)与目前最先进的受电弓主动控制方法对比,本文所提方法实现了最低的接触力方差,并且能够快速地适应新的控制任务和环境扰动。
本文采用的深度元强化学习算法在多场景受电弓主动控制方面取得较好效果,但在运行车辆等有限算力场景如何科学有效地更新元策略参数有待下一步的探索。
参考文献
[1] Wang Hongrui, Liu Zhigang, Song Yang, et al. Detection of contact wire irregularities using a quadratictime-frequency representation of the pantograph-catenary contact force[J]. IEEE Transactions on Instru-mentation and Measurement, 2016, 65(6): 1385-1397.
[2] 赵娜, 韦晓广, 高仕斌. 基于可靠性和维修成本的高铁接触网维修策略优化[J]. 电气化铁道, 2024, 35(6): 1-6. Zhao Na, Wei Xiaoguang, Gao Shibin. Optimization of maintenance strategy of OCS of high-speed railway based on reliability and maintenance costs[J]. Electric Railway, 2024, 35(6): 1-6.
[3] 程肥肥. 高速受电弓结构参数设计优化研究[D]. 成都: 西南交通大学, 2020. Cheng Feifei. Research on structure parameters design optimization of high speedpantograph[D]. Chengdu: Southwest Jiaotong University, 2020.
[4] 谢松霖, 张静, 宋宝林, 等. 计及作动器时滞的高速铁路受电弓最优控制[J]. 电工技术学报, 2022, 37(2): 505-514.Xie Songlin, Zhang Jing, Song Baolin, et al. Optimal control of pantograph for high-speed railway considering actuator time delay[J]. Transactions of China Electrotechnical Society, 2022, 37(2): 505-514.
[5] 吴延波, 韩志伟, 王惠, 等. 基于双延迟深度确定性策略梯度的受电弓主动控制[J]. 电工技术学报, 2024, 39(14): 4547-4556. Wu Yanbo, Han Zhiwei, Wang Hui, et al. Active pantograph control of deep reinforcement learning based on double delay depth deterministic strategy gradient[J]. Transactions of China Electrotechnical Society, 2024, 39(14): 4547-4556.
[6] Song Yongduan, Li Luyuan. Robust adaptive contact force control of pantograph–catenary system: an accelerated output feedback approach[J]. IEEE Transactions on Industrial Electronics, 2021, 68(8): 7391-7399.
[7] Duan Huayu, Dixon R, Stewart E. A disturbance observer based lumped-mass catenary model for active pantograph design and validation[J]. Vehicle System Dynamics, 2023, 61(6): 1565-1582.
[8] Song Yang, Ouyang Huajiang, Liu Zhigang, et al. Active control of contact force for high-speed railway pantograph-catenary based on multi-body pantograph model[J]. Mechanism and Machine Theory, 2017, 115: 35-59.
[9] Lu Xiaobing, Liu Zhigang, Zhang Jing, et al. Prior-information-based finite-frequency control for active double pantograph in high-speed railway[J]. IEEE Transactions on Vehicular Technology, 2017, 66(10): 8723-8733.
[10] 张静, 宋宝林, 谢松霖,等. 基于状态估计的高速受电弓鲁棒预测控制[J].电工技术学报, 2021, 36(5): 1075-1083. Zhang Jing, Song Baolin, Xie Songlin, et al. Robust predictive control of high-speed pantograph based on state estimation[J]. Transactions of China Electro-technical Society, 2021, 36(5): 1075-1083
[11] Zhang Jing, Zhang Hantao, Song Baolin, et al. A new active control strategy for pantograph in high-speed electrified railways based on multi-objective robust control[J]. IEEE Access, 2019, 7: 173719-173730.
[12] Schirrer A, Aschauer G, Talic E, et al. Catenary emulation for hardware-in-the-loop pantograph testing with a model predictive energy-conserving control algorithm[J]. Mechatronics, 2017, 41: 17-28.
[13] Yu Pan, Liu Kangzhi, Li Xiaoli, et al. Robust control of pantograph-catenary system: comparison of 1-DOF-based and 2-DOF-based control systems[J]. IET Control Theory & Applications, 2021, 15(18): 2258-2270.
[14] 杨鹏, 张静, 金伟, 等.考虑气动系统的高速受电弓分层控制[J]. 电工技术学报, 2022, 37(10): 2644-2655. Yang Peng, Zhang Jing, Jin Wei, et al. Hierarchical control of high-speed pantograph considering pneumatic system[J]. Transactions of China Electrotechnical Society, 2022, 37(10): 2644-2655.
[15] 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019, 42(6): 1406-1438. Liu Jianwei, Gao Feng, Luo Xionglin. Survey of deep reinforcement learning based on value function and policy gradient[J]. Chinese Journal of Computers, 2019, 42(6): 1406-1438.
[16] 陈荣亮, 梁海燕, 刘艺涛. 基于人工神经网络的差模EMI滤波器插入损耗预测[J]. 电源学报, 2024, 22(5): 67-73. Chen Rongliang, Liang Haiyan, Liu Yitao. Insertion loss prediction of differential-mode EMI filter based on artificial neural networks[J]. Journal of Power Supply, 2024, 22(5): 67-73.
[17] Zhang Hailong, Peng Jiankun, Tan Huachun, et al. A deep reinforcement learning-based energy management framework with Lagrangian relaxation for plug-in hybrid electric vehicle[J]. IEEE Transactions on Transportation Electrification, 2021, 7(3): 1146-1160.
[18] Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//International Conference on Machine Learning, PMLR, Stockholm, Sweden, 2018: 1861-1870.
[19] Duan Jingliang, Guan Yang, Li S E, et al. Distributional soft actor-critic: off-policy reinforcement learning for addressing value estimation errors[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(11): 6584-6598.
[20] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// International Conference on Machine Learning, PMLR, Sydney, Australia, 2017: 1126-1135.
[21] Rakelly K, Zhou A, Finn C, et al. Efficient off-policy meta-reinforcement learning via probabilistic context variables[C]//International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 2019: 5331-5340.
[22] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[23] Van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 2016, 2094-2100.
[24] CENELEC. Railway applications-current collection systems-validation of simulation of the dynamic interaction between pantograph and overhead contact line: BS EN 50318: 2018+A1: 2022[S]. London: BSI Standards Limited, 2022.
[25] 王殿元, 赵兴东, 豆飞, 等. 基于深度Q网络的城市轨道交通协同限流方法[J]. 都市快轨交通, 2024, 37(3): 97-102. Wang Dianyuan, Zhao Xingdong, Dou Fei, et al. Cooperative passenger flow control method for urban rail transit utilizing deep Q-network[J]. Urban Rapid Rail Transit, 2024, 37(3): 97-102
[26] Fujimoto S, Hoof H, Meger D. Addressing function approximation error in actor-critic methods[C]// International conference on machine learning, PMLR, Stockholm, Sweden, 2018: 1587-1596.
[27] 张华强, 牟晨东, 赵玫, 等. 基于强化学习的多光储虚拟同步机频率协调控制策略[J]. 电气传动, 2021, 51(19): 36-42. Zhang Huaqiang, Mu Chendong, Zhao Mei, et al. Frequency coordination control strategy of multiple photovoltaic-battery virtual synchronous generators based on reinforcement learning[J]. Electric Drive, 2021, 51(19): 36-42.
[28] Akiba T, Sano S, Yanase T, et al. Optuna: a next-generation hyperparameter optimization framework[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 2019: 2623-2631.
[29] 宋洋. 环境风下高速铁路弓网动态受流特性研究[D]. 成都: 西南交通大学, 2018. Song Yang. Study on high-speed railway pantograph-catenary current collection quality under environmental wind load[D]. Chengdu: Southwest Jiaotong University, 2018.
[30] 赵洪山, 钱亚楠, 李西备, 等. 基于振动信号特征预测与张量融合的真空断路器机械性能退化动态评估方法[J/OL]. 电工技术学报, 2025: 1-14. (2025-10-17).https://doi/10.19595/j.cnki.1000-6753.tces. 250438.Zhao Hongshan, QianYanan, Li Xibei, et al. Dynamic evaluation method of mechanical performance degradation of vacuum circuit breaker based on vibration signal feature prediction and tensor fusion [J/OL]. Transactions of China Electrotechnical Society, 2025: 1-14. (2025-10-17). https://link.cnki. net/doi/ 10.19595/j.cnki.1000-6753.tces.250438.
[31] 刘阳, 姚宇昊, 裴川东, 等. 基于模糊融合的锂电池深度强化学习充电策略[J]. 电力电子技术, 2025, 59(12): 94-102. Liu Yang, Yao Yuhao, Pei Chuandong, et al. Fuzzy fusion-based deep reinforcement learning charging strategy for lithium-ion batteries[J]. Power Electronics, 2025, 59(12): 94-102.
[32] 张振龙, 聂达文, 张新生, 等. 融合特征筛选与信号分解协同优化的xLSTM-Informer风电功率预测研究[J/OL]. 电工技术学报, 2025: 1-14. (2025-10-17). https://doi/10.19595/j.cnki.1000-6753. tces.251380. Zhang Zhenlong, Nie Dawen, Zhang Xinsheng, et al. Research on xLSTM-Informer wind power prediction with synergistic optimization of feature selection and signal decomposition[J/OL]. Transactions of China Electrotechnical Society, 2025: 1-14. (2025-10-17). https://link.cnki.net/doi/10.19595/j.cnki.1000-6753. tces.251380.
[33] 彭春华, 张浩旗, 孙惠娟, 等. 基于延迟感知多智能体深度强化学习的多光储直柔系统优化调度[J/OL]. 电工技术学报, 2025: 1-12. (2025-10-10). https: //doi/ 10.19595/j.cnki.1000-6753.tces. 250960. Peng Chunhua, Zhang Haoqi, Sun Huijuan, et al. Optimized scheduling of multi photovoltaics and energy storage integrated flexible direct current distribution systems based on delay-aware multi-agent deep reinforcement learning[J/OL]. Transactions of China Electrotechnical Society, 2025: 1-12. (2025-10-10). https://doi/10.19595/j.cnki.1000-6753.tces.250960.
[34] 王允祥, 刘友波, 廖红兵, 等. 基于双层强化学习的有源配电网中低压协同趋优运行策略[J]. 电力系统自动化, 2025, 49(24): 41-50. Wang Yunxiang, Liu Youbo, Liao Hongbing, et al. Medium-and low-voltage collaborative optimal operation strategy in active distribution network based on double-layer reinforcement learning[J]. Automation of Electric Power Systems, 2025, 49(24): 41-50.
[35] 彭自然, 王顺豪, 肖伸平, 等. 基于KA Informer的电动汽车动力电池荷电状态和健康状态估算[J]. 电工技术学报, 2025, 40(19): 6378-6394. Peng Ziran, Wang Shunhao, Xiao Shenping, et al. State of charge and state of health estimation of electric vehicle power battery based on KA Informer model[J]. Transactions of China Electrotechnical Society, 2025, 40(19): 6378-6394.
[36] 李寅生, 王冰, 陈玉全, 等. 基于积分强化学习的构网型VSC综合频率控制[J/OL]. 电工技术学报, 2025: 1-15. (2025-09-28). https://link.cnki.net/doi/10. 19595/j.cnki.1000-6753.tces.250670. Li Yinsheng, Wang Bing, Chen Yuquan, et al. Integrated frequency control for grid-forming VSC based on integral reinforcement learning[J/OL]. Transactions of China Electrotechnical Society, 2025: 1-15. (2025-09-28). https://doi/10.19595/j.cnki.1000-6753.tces.250670.
[37] 刘润龙, 李亦言, 周正昊, 等. 基于扩散模型考虑用户行为的电动汽车充电场景生成[J/OL]. 电力系统自动化, 2025: 1-17. (2025-10-22). https://kcms/ detail/32.1180.TP.20251021.1434.004.html. Liu Runlong, Li Yiyan, Zhou Zhenghao, et al. Diffusion model-based electric vehicle charging scenario generation considering user behavior[J/OL]. Automation of Electric Power Systems, 2025: 1-17. (2025-10-22). https://kcms/detail/32.1180.TP.20251021. 1434.004.html.
[38] 罗培恩, 尹忠刚, 原东昇, 等. 基于自适应和弦变换旋转蒸发策略的电机轴承未知故障诊断[J]. 电工技术学报, 2026, 41(2): 499-451. Luo Peien, Yin Zhonggang, Yuan Dongsheng, et al. Unknown fault diagnosis of motor bearings based on adaptive chord transformation rotation evaporation strategy[J]. Transactions of China ElectrotechnicalSociety, 2026, 41(2): 499-451.
Abstract Active pantograph control is the most promising technique for reducing contact force (CF) fluctuation and improving the train’s current collection quality. The train’s high-speed operation causes wave propagation and nonlinearity dynamics, making it challenging to maintain a suitable and stable contact force. Scholars have proposed numerous control strategies for the PCS in recent years, including proportional-integral-derivative (PID) control, sliding mode control, feedback control, optimal control, robust control, etc. Thesecontrol strategies often achieve good results on single simulation scenes. Existing solutions, however, suffer from three significant limitations: (1) they are incapable of dealing with the various pantograph types, catenary line operating conditions, changing operating speeds, and contingencies well. (2) It is challenging to implement in practical systems due to the lack of rapid adaptability to new PCS operating conditions and environmental disturbances; (3)It is particularly difficult to characterize the sensor accuracy, actuator uncertainty, railway line parameters, and external excitations because all of these factors can drift over time. The high-speed railway systems with widely varying operating conditions will increase uncertainty.
In this paper, we improve the current collection quality by developing and applying a context-based deep meta-reinforcement learning (CB-DMRL) approach to learn and finetune the control strategy. It combines improved distributed soft actor-critic algorithm with environment-sensitive task encoder to train a meta-policy, which can quickly adapt to different PCS operating conditions and environmental disturbances. Firstly, an improved distributed soft actor-critic algorithm, including distributed state-action value function and dual-value distribution learning, is proposed to solve the overestimation problem in value estimation and stabilize the training process. Secondly, the proposed method allows the environment-sensitive task encoder and well-trained agent to adapt to new tasks quickly and efficiently, even in unseen tasks and non-stationary environments. Finally, a validated non-linear pantograph-catenary system model is established based on the finite element and multi-body dynamics theory as the simulation environment in DRL. The state space, action space, and reward in are redesigned to train the meta-agent.
We evaluated the CB-DMRL algorithm’s performance on a proven PCS model and active pantograph HIL experiment platform. The experimental results demonstrate that meta-training DRL policies with latent space swiftly adapt to new operating conditions and unknown perturbations. The meta-agent adapts quickly after two iterations with a high reward, which require only 10 steps. The standard deviation of contact force is reduced by 14.71%, 16.93%, 21.22%, and 35.69% at 320 km/h, 340 km/h, 360 km/h, and 380 km/h respectively. The faster the train runs, the better the control effect is. Because the high-speed train has caused strong pantograph-catenary system vibration, our method can effectively improve the current collection quality. Even in unknown scenarios, the proposed approach can adapt the well-trained behavior policy to the new task using environment-sensitive task encoder. Given the rapidly changing PCS operating conditions and unknown environmental disturbances, we believe this research is a significant advance in applying DRL to PCS control.
The following conclusions can be drawn from the simulation analysis: (1) In the algorithm components of this paper, the improved distributed SAC algorithm can effectively improve the value estimation accuracy and stabilize the training process to solve the problem of exploding and vanishing gradients. The task encoder sensitive to environmental changes can quickly generate the optimal task encoding based on the context of the interaction sample. (2) Compared with the most advanced pantograph active control method, the method proposed in this paper achieves the lowest contact force variance and can quickly adapt to new control tasks and environmental disturbances. The deep meta-reinforcement learning algorithm used in this paper has achieved good results in multi-scenario pantograph active control. However, how to scientifically and effectively update the meta-strategy parameters in limited computing power scenarios such as running vehicles needs to be explored in the future.
keywords:High-speed railway, active pantograph control, deep reinforcement learning, meta-learning
DOI: 10.19595/j.cnki.1000-6753.tces.250116
中图分类号:TM614
收稿日期 2025-01-15
改稿日期 2025-07-26
王 惠 男,1998年生,助理研究员,硕士生导师,研究方向为深度学习及其在铁路弓网系统中的应用等。E-mail: wanghui163@my.swjtu.edu.cn
刘志刚 男,1975年生,教授,博士生生导师,研究方向为现代信号处理、计算机视觉及其在铁路和电力系统中的应用等。E-mail:liuzg_cd@126.com(通信作者)
(编辑 郭丽军)