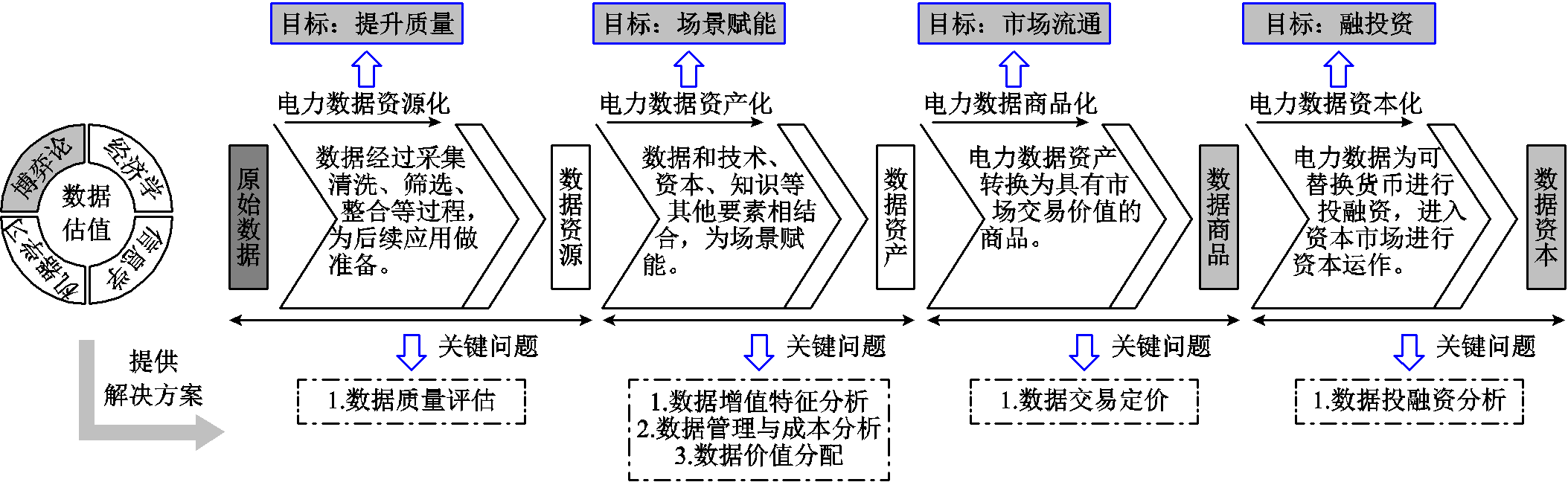
图1 电力数据资产价值全流程以及关键问题
Fig.1 The whole process of power data value and the key issues
摘要 随着新型电力系统的数字化转型,电力数据资产已成为电力系统执行决策的核心因素,其价值得到广泛认可。然而,如何对电力数据资产价值进行有效的评估已成为学术界面临的重大挑战。目前少有全面的方法来评估电力数据价值,而且由于数据资产本身的复杂性及其在特定应用场景下的依赖性,具体应用哪种方法难以达成共识,使得数据难以充分释放其价值为电力系统服务。该文首先构建了电力数据资产价值化评估的研究框架;其次从电力数据价值化全流程及关键问题着手,综述了现有估值方法以及数据估值在电力系统中的应用现状;最后展望了数据价值挖掘及评估在未来电力系统中的潜在应用,并讨论了可能存在的问题与不足,为电力数据资产价值化研究与应用提供参考,以期促进能源领域数据的高效利用与流通。
关键词:数据价值 电力系统 估值方法 价值挖掘
随着“双碳”目标的深入推进,全球能源体系正加速向绿色低碳方向转型,以新能源为主体的新型电力系统成为实现“双碳”目标的重要支撑。在智能电能表、无线通信、人工智能(Artificial Intelligence, AI)等数字技术[1]的推动下,新型电力系统不断向数字化、智能化转型,以提升能源利用率和系统运行效率。新型电力系统通过融合发电、输电、变电、配电和用电各环节的能量流、信息流及价值流,构建绿色低碳、AI赋能、高效稳定、安全经济的电力系统,为“双碳”目标的实现提供有力支撑。
在电力系统数智化转型的进程中,电力量测技术提升了数据采集的广度和深度,带来了前所未有的丰富的电力大数据资源。这些数据不仅是驱动系统优化的核心因素,其在系统中的价值属性也逐渐显现。首先,在电网内部,利用人工智能[2]、模式识别等数据挖掘技术对数据进行开发分析,并用于负荷预测[3]、优化调度[4]、故障诊断[5]等应用场景。例如,电网调度机构能够利用历史负荷数据,优化未来负荷预测和经济调度,以实现成本节约[3]。其次,电网或其他电力企业通过数据加工与打包,电力数据还能在共享、交易、投资等对外应用中产生更广泛的经济效益,如电力企业将数据产品放入数据市场进行交易,双方达成一致协议,提供方从而获得相应的经济收益,且购买方也可从数据产品中受益[6]。
电力数据资产价值属性日益受到重视,如何高效地利用和管理电力数据、释放数据价值及数据要素化[7]已成为当前研究的重点。中国信息通信研究院在2021年发布《中国数字经济发展白皮书》[8];2022年底,中共中央、国务院发布《关于构建数据基础制度更好发挥数据要素作用的意见》[9];南方电网于2021年2月发布了《中国南方电网有限责任公司数据资产定价方法(试行)》[10],说明电力数据价值得到广泛认可,相关政策促进电力数据高效利用。
然而,在“双碳”目标下,新型电力系统在电力数据价值的评估与量化方面仍缺乏公认且可信的方法,这一短板不仅严重制约电力数据的流通与深度挖掘,还可能阻碍电力系统的绿色低碳与数智化转型。例如,由于电力数据资产价值评估不够准确,电网等主体在数据挖掘与应用上的投资决策可能缺乏科学依据,影响数据在源荷预测、调度优化等关键环节的应用,进而降低新型电力系统对新能源的高效利用,导致可再生能源消纳受限以及系统运行效率下降。此外,不同类型电力数据的收集、存储、共享和交易定价等数据行为缺乏统一的数据价值评估标准,可能导致数据利用不足以及资源配置效率低,限制了新型电力系统的数智化发展以及数据高效流通。数据估值作为一种能够量化数据内在信息及应用价值的方法,目前涵盖了数据市场[11]、医疗[12-13]、供应链管理[14]、大数据管理[15]、机器学习(Machine Learning, ML)[16]等领域,文献[17]从经济学角度综述了数据估值方法,文献[18]则综述了机器学习领域中的数据估值方法。当前,电力数据资产价值评估的研究尚处于探索阶段,现有研究主要集中于电力数据质量评估、电力数据交易以及模型可解释性等相关应用分析,而针对数据合作分享、场景化以及数据隐私保护下的数据价值评估等应用仍然缺乏深入研究。而且数据估值方法涉及经济学、信息学、博弈论和计算机科学等多学科交叉融合,在新型电力系统的实际应用中存在一定的困难。
为此,本文首先构建了电力数据资产价值评估的研究框架,基于以上流程凝练数据从资源化到资本化等各阶段中存在的关键问题;其次,介绍现有电力领域相关的数据估值方法来解决上述关键问题;然后,分析了数据估值在电力场景中的应用现状,分别从估值对象、主体阶段、功能应用三方面展开论述;最后,展望数据估值在电力系统中的未来应用以及总结目前存在的问题与挑战,为后续数据估值的研究以及电力系统数字化的推行提供一些参考,从而促进“双碳”政策实施中电力数据的高效利用以及流通。
数据可被定义为以数值、符号或文本形式记录和存储的信息,其通过作为信息或洞察力的使用来创造价值。文献[19]确定了影响数据价值的关键特征,将其分为经济特征和信息特征,并分析了数据如何通过不同的使用方式创造价值。文献[20]同样梳理了电力大数据价值链及其价值创造模式,但也没有涉及数据价值评估。从经济学的角度,数据价值化贯穿数据资源化、数据资产化、数据商品化和数据资本化四个阶段[21-22],对应着潜在价值、价值创造、价值实现和价值增值的过程。电力数据特指由电力系统产生的数据信息,包含电力系统内部数据与电力系统外部数据[20]。内部数据例如调度运行数据、负荷数据、设备运行状态监测数据、市场交易信息及用户消费行为等;外部数据例如互联网数据、天气数据、地理位置数据等。这些多维数据横跨发电、输电、变电、配电和用电等各个环节,是电力系统智能化管理和优化的核心资源。本文将电力数据作为研究对象,结合经济学中上述四个阶段,并引入信息学、机器学习、博弈论等技术视角,对电力数据价值化的完整流程以及存在的关键问题进行详细分析和讨论,其流程如图1所示。
图1 电力数据资产价值全流程以及关键问题
Fig.1 The whole process of power data value and the key issues
电力系统中的电网调度自动化系统、用电信息采集系统等系统设备时刻都在采集数据,这些原始数据可能由于不同地理方位、不同采集方式、不同通信方式等方面,存在数据杂乱、缺失、冗余、异常等问题,难以直接利用。电力数据资源化就是按照需求对原始电力数据进行清洗、筛选、融合、缩减、标准化等处理,以可采、可见、互通、可信的形式进行管理、存储或是共享的过程[22]。原始电力数据能够被理解和利用时,就自然转换为数据资源。通过电力数据资源化过程,电力数据初步具备了潜在的业务价值,能够为电力系统中的各类应用提供支撑。电力数据资源化的核心目标是提升电力数据质量,数据资源质量的高低直接影响后续应用效果。在数智化转型的电网中,营销[23]、调度[24]、设备管理[25]等各个领域都离不开高质量的电力数据资源的有力支撑。在营销领域,精准的用户用电预测[26]依赖清晰、准确的用户负荷数据,以帮助电力企业合理地制定电价策略、激励政策,改善用户体验和电力供需平衡;在调度领域,高质量的新能源数据[4]能够显著提升调度策略的执行效果,有效应对负荷波动,降低供电风险;在设备管理领域,高质量的设备数据能够帮助设备管理人员有效地提高设备故障识别率[27],精准判断故障类别并采取相应措施,从而减少设备停运时间和经济损失,显著提高设备管理效率和可靠性。
在电力数据资源化阶段,关键问题为数据质量评估,便于进行高质量数据资源存储等管理操作以及使得数据的质量符合一定的预期能够更好地为后续应用服务如上述介绍的应用。数据质量评估是指为明确数据的潜在价值,需要针对数据质量进行分析与量化,该阶段的质量评估更偏向于基础、整体数据质量,使得数据真正转换为可用的数据资源以及为资产化奠定基础。
以文献[4]中澳大利亚的光伏阵列新能源实测数据质量计算为案例,分析关键问题数据质量评估。一般与新能源出力相关的数据规模庞大,若进行出力预测时选取低质量数据集作为样本来训练,会大大降低后续的预测精度,进一步使得电网调度计划无法合理运行,达不到新能源消纳的效果。数据质量通常包括完整性、准确性、一致性等维度,在本案例中,利用信息熵h及非噪声比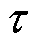 来量化其信息量和准确性,数据质量Q定义为信息熵与非噪声比的乘积即
来量化其信息量和准确性,数据质量Q定义为信息熵与非噪声比的乘积即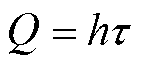 。在评估阶段中,选取多个不同天数的数据集,分别计算其数据质量,具体步骤如下:首先,数据经过初步处理,去除缺失值和异常值;其次,计算各数据集的信息熵及非噪声比,分析数据的信息丰富程度及准确性;然后,结合两个质量维度计算数据质量;最后,针对不同数据质量的数据集来训练预测模型,评估不同数据质量下的预测性能。从文献[4]可以得出,在非噪声比变化不大的情况下,数据集的信息熵对于数据质量计算起到非常重要的作用。随着信息熵的增大,数据质量越高,预测误差越小,因此高质量数据能够有效地减少预测误差。而且单独的信息熵或是非噪声比与后续的模型预测精度无明显关系,即单个质量维度评估无法说明数据质量。这可能会造成数据估值的高估或是低估,因此,针对质量评估可从多个评估维度出发,避免单个指标评估的片面性。以上案例表明,数据质量对后续场景的应用效果具有显著影响,因此必须重视数据质量评估这一关键问题。有效的数据质量评估有助于提升数据的可用性,从而为后续具体的业务应用提供坚实基础。
。在评估阶段中,选取多个不同天数的数据集,分别计算其数据质量,具体步骤如下:首先,数据经过初步处理,去除缺失值和异常值;其次,计算各数据集的信息熵及非噪声比,分析数据的信息丰富程度及准确性;然后,结合两个质量维度计算数据质量;最后,针对不同数据质量的数据集来训练预测模型,评估不同数据质量下的预测性能。从文献[4]可以得出,在非噪声比变化不大的情况下,数据集的信息熵对于数据质量计算起到非常重要的作用。随着信息熵的增大,数据质量越高,预测误差越小,因此高质量数据能够有效地减少预测误差。而且单独的信息熵或是非噪声比与后续的模型预测精度无明显关系,即单个质量维度评估无法说明数据质量。这可能会造成数据估值的高估或是低估,因此,针对质量评估可从多个评估维度出发,避免单个指标评估的片面性。以上案例表明,数据质量对后续场景的应用效果具有显著影响,因此必须重视数据质量评估这一关键问题。有效的数据质量评估有助于提升数据的可用性,从而为后续具体的业务应用提供坚实基础。
资源化阶段是将数据变为可用的资源,资源需要充分利用才能发挥其价值。电力数据资产化是将电力数据和技术、资本、知识等其他要素相结合[22],为电力营销管理、调度优化、设备管理等应用场景赋能,将可控、可量化、可收益的数据资源转换为数据资产。通过电力数据资产化过程,电力系统中的数据释放其内在价值,能够为电网或相关主体提供更加全面、准确、具有价值的决策分析,为数据转换为价值以及产生效益提供基础[28]。而且随着机器学习[2]及人工智能技术的广泛应用,电网等主体通过对电力数据进行深度挖掘来构建以电力系统中的预测、识别、控制等任务为导向的数据驱动模型,从而实现场景智能赋能。例如,电网调度机构利用历史数据构建预测模型,然后使用该模型得到未来光伏出力数据为调度机构的经济调度计划提供决策支持[4]。数据资产不仅在个体中发挥重要作用,随着数据共享[29]和跨行业合作的深入推进,其共享性与复用性在合作阶段更是释放出广泛的价值潜力,为多方协作创造了更大的可能性。这种合作模式不仅给个体带来了价值效益提升,也推动了社会效益的提升。例如,多个同类工业用户参与联邦学习共同提高负荷预测的精度[30],电、热、冷三个能源部门的数据协作提高综合能源系统的运行效率并降低成本[31]。
在电力数据资产化阶段,数据已具备明确的应用场景,例如通过在调度优化、负荷预测等具体业务中的应用,逐步实现其经济价值和决策支撑能力。
1)数据增值关键特征分析。数据增值关键特征分析是指针对具体应用场景下的电力数据中可显著提高其价值的特征或者数据点进行分析决策,从而以较低的成本获取更高的数据资产价值提升以及理解数据如何提供价值支撑。以文献[32]中的电力负荷预测任务为案例分析数据增值关键特征分析问题,电力负荷数据经过资源化处理后,需要在负荷预测任务中具体实施。不仅需要关注整体的质量,对于内部更细粒度的特征评估同样不可忽视。因此,在训练预测模型前,首先经过数据预处理(清洗、补缺、缩放等)提高数据质量,再剔除冗余特征,以提高后续具体应用场景的预测性能。该案例首先计算电力特征与预测标签值的互信息来生成互信息指标过滤下的特征集,然后利用SHAP(Shapley Additive Explanations)方法为互信息过滤下的特征集中的各特征进一步量化特征价值来筛选最优特征,该最优的特征子集即作为后续的负荷预测模型的特征输入进行训练。文献[32]对是否进行特征评估及分析下的最终预测模型性能进行对比分析,可以得出基于特征评估及分析的XGBoost模型预测能力得到较大提高,能够更好地为短期负荷预测场景服务。通过以上案例分析可见,特征的选取直接影响后续模型的性能,因此在模型训练前,解决关键特征分析问题至关重要。数据估值为合理筛选和优化特征提供了依据,能够有效地提升模型的准确性,从而充分挖掘数据价值并优化模型表现。
2)数据管理与成本分析。数据管理与成本分析是指识别并分析其成本和应用价值,为科学合理地管理提供依据,从而实现资源的高效管理和成本的有效控制。以电网大数据中心对数据资产执行管理和维护为案例分析数据管理与成本分析问题。先进量测设备使得电力数据采集更为简单,而且目前数据采集规模达到百亿级别,导致数据管理成本不断攀升。为优化数据管理,电力公司可以根据相应的数据价值制定数据管理策略,例如数据分层存储、智能归档、精简淘汰等。具体而言,电力公司基于数据的一致性、完整性、时效性及访问频率等指标维度对不同类型的数据进行评估,以指导数据管理策略。例如,对于那些价值较低但管理与维护费用较高的数据资产,可通过精简存储、归档处理或数据淘汰等方式进行优化,提升整体管理效率和资产回报率。因此,解决数据管理与成本分析问题的关键在于精准的数据估值,它为资源优化配置和成本控制提供了科学依据。
3)数据价值分配。数据价值分配则是指由于数据资产具有多方共享性,如何进行合理公正的利益分配来匹配各方数据所带来的价值,从而制定激励相容的数据价值分配策略,促进数据流通共享。以文献[33]的电力巡检图像联邦学习的激励机制为具体案例分析数据价值分配问题。在实际的数据共享中需要考虑数据整合困难及数据隐私保护等问题,单个电力公司或是数据拥有者难以训练出高精度的检测模型,而且数据拥有者没有义务免费提供数据来合作共享从而完成需求方的任务。因此,数据需求者应当为不同的数据提供者分配相应公平且合理的任务收益,数据需求者同样也获得了高性能模型。文献[33]利用两种方式来评估各电力巡检图像数据提供者的数据价值:①直接利用各方电力图像数据的数量、类别量等指标来评估各方数据对任务的价值贡献;②利用各方电力图像数据对需求方检测精度的边际贡献来评估各方数据对任务的价值贡献。需求者可从各方提供的数据中得到提升电力巡检图像的检测能力,利用以上两种方式可制定相应的激励相容的价值分配策略,给予各方利益,并进一步激励更多的数据提供者参与任务。可见,合理的数据价值分配同样是需解决的重要问题,只有建立公平且合理的分配机制,才能激励数据供给方和需求方积极参与,促进数据的高效流通与优化配置。
电力数据商品化即为电力数据资产化的进一步升级,将电力数据资产转换为具有市场交易价值的商品,使得其在数据市场上进行流通,有需求的主体可以相对公允的价格来交换数据商品,该数据商品不一定是原本的数据资产,也可能是数据资产经过进一步加工的数据产品[34]。其中,数据交易的是原始资产,那么本质上交易的便是所有权及使用权;若是数据产品,其本质交易的是数据服务,仅交易数据使用权。通过电力数据商品化过程,数据商品打破电力数据壁垒,不仅给数据出售者带来经济效益,还能给买入者带来实际场景应用下的效益提升。例如,电力零售商可以在数据市场买入准确的用户负荷预测产品来减少自身由于用户负荷预测的不确定性所带来的利润损失[6]。
进入电力数据商品化阶段后,该阶段的关键问题是数据交易定价。类似于其他有形商品,数据交易定价是指在明确数据的获取、处理、管理等成本以及应用价值等基础上进行定价,最终促成有效交易。在定价前需要明确数据的价值量,这有助于动用市场力保证数据交易市场的良性竞争。
以文献[11]中的电力数据交易框架作为案例分析数据交易定价问题。数据交易包括数据提供者,例如可再生能源发电商和能源存储提供商等,数据需求者例如电力企业和市场运营商等,以及数据交换服务提供商,其主要作用为提供数据交易和支持相关服务,还要保证数据安全和个人隐私。数据完成交易需要对其明码标价即定价,然而数据的定价首先需要明确其价值,并基于此价值进入数据市场实现定价。文献[11]对电力数据的价值评估集中于以下三个维度:①不确定性,电力数据的不确定性会对电网稳定性构成挑战,这将导致能源浪费和储能调度的经济成本;②完整性,考虑对电力数据完整性的攻击可能会导致电网决策甚至大型电力灾害的错误,从而导致巨大的经济损失;③及时性,电力数据的及时性会影响系统的操作,高潜伏期可能会导致系统效率低下和安全事件。设定综合价值函数V,其为一个价格函数,考虑了电力数据的不确定性、完整性以及及时性三个指标,该函数指导数据交易的最终定价。完成数据估值后,交易双方基于博弈均衡实现最终定价并完成交易。因此,在数据商品化阶段,首要解决的问题是数据的交易价格设定,而合理的定价离不开精准的数据估值作为支撑,以确保数据交易的公平性和市场流通的有效性。
电力数据资本化是电力数据商品升级为电力数据资本的过程。电力主体通过资本运营使电力数据能够实现增值,数据资本化即可将电力数据视作一种可替换货币进行投融资,进入资本市场进行资本运作,电力数据可以将期货、股票、基金等金融工具相结合,然而这一阶段仍处于初步探索阶段[22]。电力数据资本化过程有利于促进电力系统中的数据要素市场化配置,提高数据要素的价值创造能力。例如,电力相关企业可以将数据资产作为抵押物[34],用于获取融资支持即数据质押融资,以激发数据的潜在价值,并推动业务发展。
数据资本化阶段的关键问题为数据投融资分析。电力数据投融资分析旨在通过评估电力数据商品或资产的经济价值、长期稳定性、可靠性、风险水平,以及在资本市场中的潜在价值,判断其是否具备作为投资、融资或抵押品的条件,为资本运作提供科学依据和决策支持。
以某新能源公司的数据资产证券化为案例分析数据投融资分析问题。数据资产证券化作为一种金融创新过程,可以将电力数据资产的未来现金流转换为可交易的金融产品,从而提升数据资产的流动性和市场价值。数据资产证券化的核心在于通过合理的资产评估、信用评级和风险分散机制,使数据资产具备可量化、可交易的特性。市场投资方或评估机构利用实物期权等方法对公司数据资产的未来收益进行价值评估,决定投资方的投资规模或贷款额度。例如,新能源公司首先将其拥有的数据资产抵押给银行,由银行来评估其价值是否有资格作为抵押物,价值合格并发放相应的贷款。贷款在纳入标准资产库后,通过结构化设计将其证券化,生成证券化产品。由此可见,电力数据资产的资本化需以明确的数据价值评估为前提,只有在确保数据具备足够的经济价值、稳定性和市场潜力的基础上,才能推动其资本化进程。因此,数据估值至关重要,它为数据投融资分析问题的解决提供了科学依据。以上介绍了电力数据资产价值化的全流程以及每个流程所存在的关键问题,下一节将深入探讨电力领域现有的数据估值方法,为解决以上关键问题或是在该问题场景下提供思路,以实现电力数据的最大价值化。
将数据估值方法引入电力系统具有重要意义,本节将介绍现阶段存在的估值方法来解决上述关键问题,并阐述其在电力系统中的应用场景。估值方法的适用阶段以及解决的关键问题如图2所示。数据估值方法主要包含三大基本法、实物期权法、指标评估法和基于影响的方法,下面进行详细介绍。
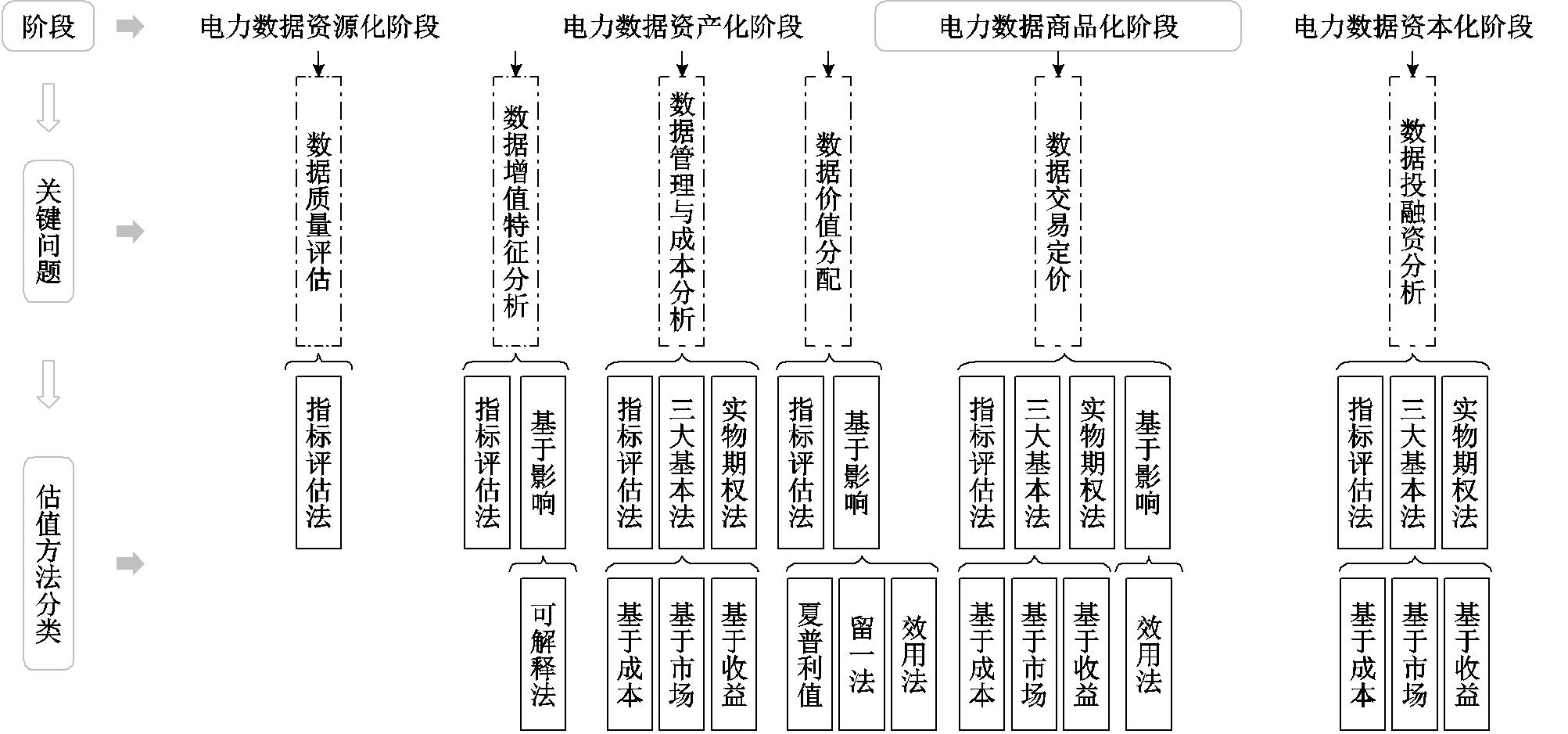
图2 数据估值方法适用阶段以及所解决关键问题
Fig.2 Stages of application of the data valuation methodology and key issues addressed
三大基本法分为基于成本的方法、基于市场的方法及基于收益的方法。基于成本的方法[35]是指考虑数据的生成、收集、存储等所涉及成本的数据估值方法,该方法较为简单,但是难以评估数据的隐性价值和应用效益,特别是在目前以大数据驱动为背景的智能电网应用场景;基于市场的方法[36]是用于市场上有同类型或是相似类型的数据资产的估值方法,需要考虑市场中的供需关系、资产类型等,若数据交易市场无类似资产或交易案例不足,则难以有效地评估其价值;基于收益的方法[37]则是通过估计数据能带来的经济效益进行数据估值的方法[4],然而收益具有不确定性,难以有效确定。三大基本法都可应用于数据资产化以及商品化阶段下,例如电网或其他企业需要对数据资产进行管理维护[38],或是将数据资产放入数据市场进行交易定价[39]等场景下评估数据价值。基于成本的方法通常适用于数据资产价值与其收集、存储或处理等成本密切相关或是数据自用的场景,帮助电力企业了解这些数据资产成本,并为后续的数据管理决策或数据交易提供指导;基于市场的方法适用于电力数据资产在数据市场中具有较高活跃性的场景,通过供需关系、历史价格等因素来评估资产价值;基于收益的方法则更适用于需要评估数据资产未来潜在价值效益的场景,侧重于数据在未来提升运营效率、降低成本或增加收益等方面的长期贡献。
实物期权法[40]是一种金融分析工具,其将数据资产看作金融衍生产品,特别适用于评估以投资为目的的数据资产价值,通过模拟不同情景下数据资产的未来收益,能够为电力企业提供更具前瞻性的投资决策依据。一般应用于数据资产化阶段电网或其他企业的数据资产管理[41]、数据交易定价[39]等场景。
指标评估法是一种设定单个或多个指标来确定数据价值的方法。通过考虑数据的完整性、一致性、隐私性、多样性、不确定性、流通性等指标[42],可利用互信息、相关系数、方差、标准差、信息熵等来量化分析。该方法适用性较强,对于电力系统中涉及数据在负荷预测、故障诊断等具体应用前的先验质量评估[27]、数据资产管理[43]、冗余信息下的特征选择[44]、电力数据交易定价[11]等场景都可适用。但该方法中指标的选取可能具有主观性,例如对于数据拥有者而言,在数据交易中更加倾向于选择对自己更有利的指标来提高其数据资产价值,可能造成交易的不公平。对于以上问题,可基于现有研究、电力行业标准或实践经验,制定一套涵盖数据多个维度的标准化指标集,包含数据一致性、完整性、应用性等,使估值能够在不同场景下具有一定的可比性,或引入独立的第三方评估机构以及专业的研究人员共同选取,充分考虑多方意见,确保这些指标的合理性与普适性,然后来具体评估价值。以上都可减少单方的主观性,提高估值的客观性和准确性。
基于影响的方法为针对数据对于应用结果影响的评估方法,因为数据的本质作用就是用来得到更好的决策。基于影响的方法通常可分为两大类:①与ML模型预测结果相关,帮助认识数据或特征如何对预测结果产生影响,例如,博弈论、效用法、留一法(Leave One Out, LOO)及可解释方法等;②与实际经济效用结果相关,帮助认识数据或特征如何对经济效益结果产生影响,例如,博弈论、效用法等。在电力系统中,基于影响的方法适用于数据事后所带来的价值评估,包括源荷预测、电网调度、电力市场优化等应用场景。
博弈论中的夏普利值(Shapley Value, SV)[45]由经济学家L. S. Shapley于1953年提出,用于量化在合作博弈中各参与者对总体收益的边际贡献,有
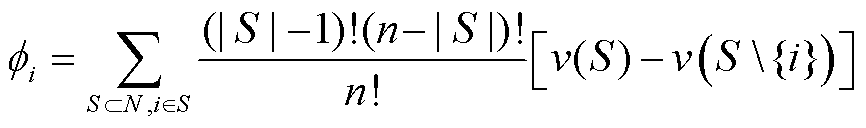 (1)
(1)
式中,N为总参与者集合;S为N的子集;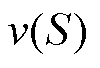 为子集S形成的联盟所能获得的收益函数;
为子集S形成的联盟所能获得的收益函数;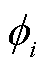 为参与者i的夏普利值,即其在整体收益中的贡献,从而为合作博弈中的利益分配提供理论依据。SV适用于以优化调度或以联邦学习为主体的负荷预测、图像检测等背景下的多个数据方合作的利益分配[31]等场景。
为参与者i的夏普利值,即其在整体收益中的贡献,从而为合作博弈中的利益分配提供理论依据。SV适用于以优化调度或以联邦学习为主体的负荷预测、图像检测等背景下的多个数据方合作的利益分配[31]等场景。
效用法通常是指通过衡量数据在实际应用场景下的实际效益提升评估数据价值。例如,在光伏预测场景[4]下,将评估数据集给光伏负荷预测精度的提升效果作为该数据集的效用价值,并构建质量与预测精度提升之间的效用函数,为不同质量数据提供不同效用的直观展示。对于电力系统中涉及数据源荷预测等任务应用场景下的数据集选择[4]以及电力市场优化中多方合作下的利益分配[46]等场景都可适用。
留一法[18]在机器学习中被广泛应用于交叉验证,通过排除某个估值对象,计算整体的价值和没有该估值对象下的整体价值之差作为该估值对象的贡献价值量化,即
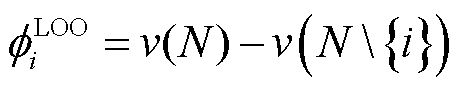 (2)
(2)
该方法类似于SV方法,适用于资产化阶段中解决多方协作场景[47]下的利益分配等场景。
可解释方法主要包括线性模型、树模型[48]、LIME(Local Interpretable Model-agnostic Explan-ations)[49]、PI(Permutation Importance)[50]及SHAP[51]。以上方法主要应用于数据资产化阶段中数据存有冗余信息下的特征选择,以及黑箱ML模型决策难以理解场景下的数据增值关键特征分析关键问题。线性模型为最简单的自解释模型,特征前的系数权重直接体现了特征对于预测结果的影响,但是对于非线性问题,其权重难以体现特征的真实价值贡献;树模型是一种具有可解释性的学习方法,通过在根节点及各内部节点处计算信息熵,寻找并确定最优分割特征,从而进行节点分裂,这一过程使得决策树能够有效地识别各个特征对模型决策的相对贡献,例如电网运维部门将电力系统的故障状态特征(如电压、电流信号)与故障类型相结合[52],确定对故障分类的决策贡献最大特征;LIME为一种可解释任意模型的局部可解释方法,主要用于负荷预测[53]、稳定性评估[54]等应用场景下的ML模型解释;PI是一种传统的无偏全局解释方法,通过随机扰动某一特征的取值,比较扰动前后的模型表现以评估特征的重要性,主要应用于能源价格预测[55]下的模型解释;SHAP方法为SV在可解释ML中的变体方法,该方法可应用在大部分监督学习领域,且在电力系统中表现出显著优势,例如在新能源预测中,光伏发电商利用SHAP来计算每个特征对于光伏发电功率模型决策结果的边际贡献来解释模型以及识别影响光伏发电的最重要特征[56]。可解释方法在电力系统中的适用场景广泛,涵盖源荷预测、稳定性评估、电价预测以及故障诊断等多个领域。通过引入可解释性分析,可以提升以数据驱动的复杂ML模型的可信度,并增强决策的透明性和可靠性,其中SHAP方法还能实现特征筛选,从而促进新型电力系统的数智化发展。目前电力系统中的数据价值评估方法对比见表1。
表1 电力数据资产估值方法对比
Tab.1 Comparison of valuation methods for power data assets
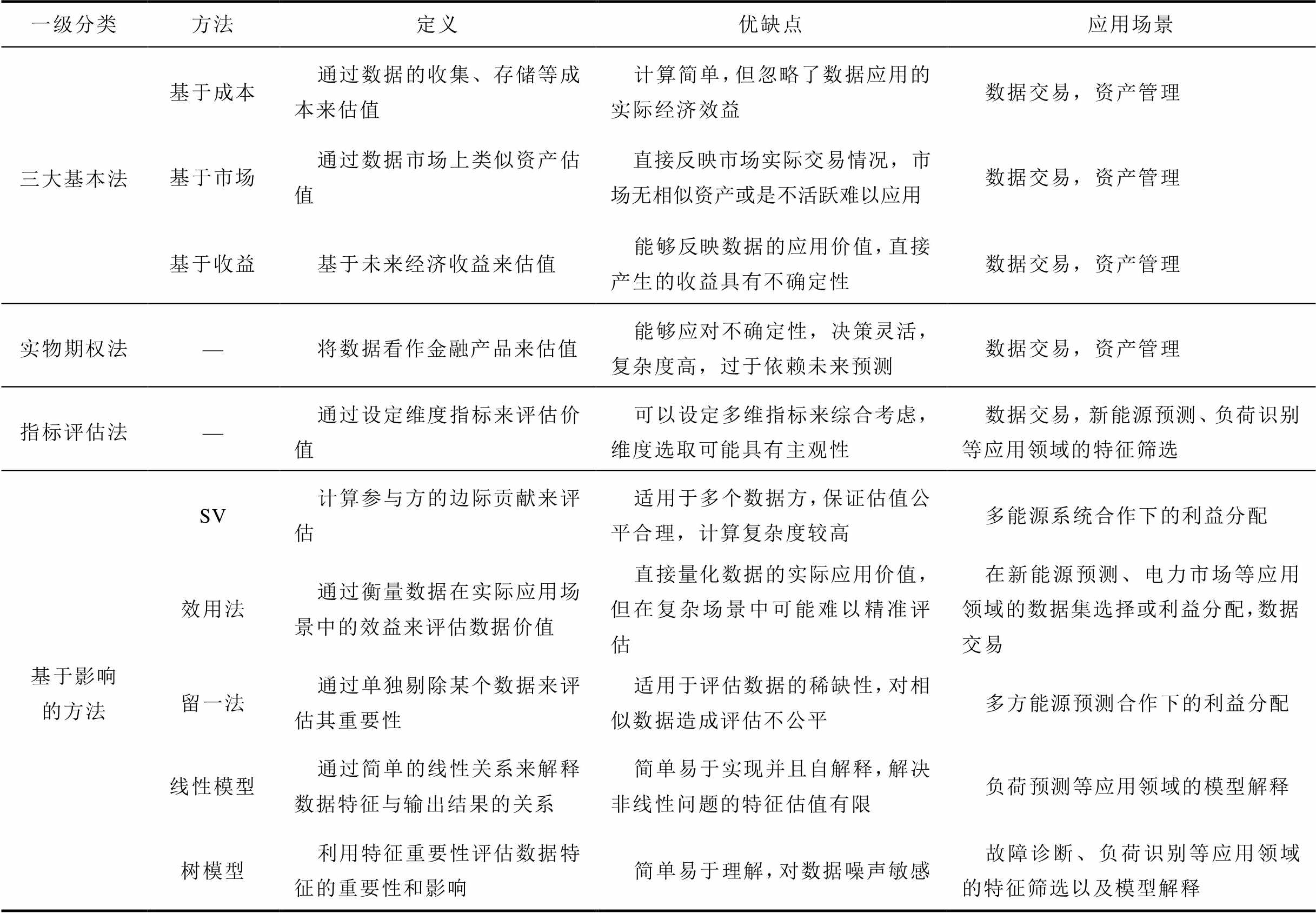
一级分类方法定义优缺点应用场景 三大基本法基于成本通过数据的收集、存储等成本来估值计算简单,但忽略了数据应用的实际经济效益数据交易,资产管理 基于市场通过数据市场上类似资产估值直接反映市场实际交易情况,市场无相似资产或是不活跃难以应用数据交易,资产管理 基于收益基于未来经济收益来估值能够反映数据的应用价值,直接产生的收益具有不确定性数据交易,资产管理 实物期权法—将数据看作金融产品来估值能够应对不确定性,决策灵活,复杂度高,过于依赖未来预测数据交易,资产管理 指标评估法—通过设定维度指标来评估价值可以设定多维指标来综合考虑,维度选取可能具有主观性数据交易,新能源预测、负荷识别等应用领域的特征筛选 基于影响的方法SV计算参与方的边际贡献来评估适用于多个数据方,保证估值公平合理,计算复杂度较高多能源系统合作下的利益分配 效用法通过衡量数据在实际应用场景中的效益来评估数据价值直接量化数据的实际应用价值,但在复杂场景中可能难以精准评估在新能源预测、电力市场等应用领域的数据集选择或利益分配,数据交易 留一法通过单独剔除某个数据来评估其重要性适用于评估数据的稀缺性,对相似数据造成评估不公平多方能源预测合作下的利益分配 线性模型通过简单的线性关系来解释数据特征与输出结果的关系简单易于实现并且自解释,解决非线性问题的特征估值有限负荷预测等应用领域的模型解释 树模型利用特征重要性评估数据特征的重要性和影响简单易于理解,对数据噪声敏感故障诊断、负荷识别等应用领域的特征筛选以及模型解释
(续)

一级分类方法定义优缺点应用场景 基于影响的方法LIME通过局部解释方法来解释ML模型,分析特征对预测的贡献简单而且可解释任意ML模型,对全局特征贡献计算有限负荷预测、稳定性评估等应用领域的局部模型解释 PI通过置换重要性方法评估特征对模型预测的影响简单而且全局无偏解释,需要多次置换并计算,计算开销大新能源价格预测应用领域的模型解释 SHAP通过Shapley值公平地评估各特征对模型输出的贡献适用广泛,公平估值,计算复杂度较高新能源预测、稳态控制等应用领域的特征筛选以及模型解释
在数字化、智能化的背景下,对电力系统中的数据进行有效的数据估值能够为电网或其他电力企业提高数据利用率、增强决策性能及促进数据流通等奠定基础。不同的电力业务对于数据估值的需求是不同的,因此,本节对当前数据估值在电力系统中的应用现状进行总结,结果见表2。目前电力数据资本化阶段处于初级阶段,还未有文献具体展开。本文从估值对象、主体阶段及功能应用三方面对数据估值在电力系统中的具体应用进行阐述分析,如图3所示。主体阶段分为个体阶段[4]和交互阶段[6];估值对象即为数据集[4,11]、特征[53-56]及数据产品[6];应用功能包括决策指导[57]、信息辨识[4,44]、模型解释[52-56]、利益分配[31,46-47]及数据交易[11,39]。
表2 数据估值在电力系统中应用的文献梳理
Tab.2 Literature related to data valuation in power systems

典型场景描述可用估值方法估值对象及目的主体阶段应用功能文献 1. 电网或其他主体对其数据资产下的相关业务管理或投资分析。如电网中存储了大量的数据资产,但是其中部分数据资产有可能过时或价值量低,需要进行有效判别,进行数据精简减少存储成本。三大基本法、实物期权法、指标评估法估值对象主要为数据集,为管理、投资决策提供指导个体阶段决策指导[41, 43, 57] 2. 原始数据经过初步数据处理即将用于实际场景,需要进一步识别数据质量。如电网在进行设备故障识别前需要判别该数据集质量满足预期质量来完成后续故障识别模型的训练或存储。指标评估法,效用法估值对象主要为数据集,应用前判别数据集质量个体阶段信息辨识[4, 27] 3. 数据已经具有明确场景导向,但数据中还存有冗余信息可能对后续造成不良影响。如电网在进行负荷预测前进行关键特征抽取从而甄别出对于预测精度具有决定作用的关键特征。指标评估法、可解释法估值对象主要为特征,剔除冗余信息提高数据利用率个体阶段信息辨识[32, 44, 58-61] 4. 数据已经实际应用,然而黑箱ML模型的决策难以理解,阻碍电网人员信任。如在电网的新能源预测中利用复杂模型例如LSTM来预测未来功率,对模型进行解释分析来说明各特征对于模型决策的贡献,提高模型的可信度。可解释法估值对象主要为特征,提供模型解释能力,增强模型信任度个体阶段模型解释[62-64] 5. 数据已经进行处理和加工,电网或其他主体将其放入市场进行交易。例如电力企业需求方可以从数据市场中交易新能源数据,数据提供者需要先对数据进行估值以便为后续的数据定价提供指导意见。三大基本法、指标评估法,效用法估值对象主要为数据集以及数据产品,为其提供定价依据促成有效交易交互阶段数据交易[6, 11] 6. 电网或其他多个主体将数据共享从而提高社会效益或获得私人利益。例如电、热、冷各能源部门将本地的预测数据共享给调度中心实现总体的成本降低,然后调度中心制定分配策略来激励各部门共享数据。SV、留一法,效用法估值对象主要为数据集以及数据产品,执行合理公平分配策略从而激励数据方积极共享数据交互阶段收益分配[31, 46-47]
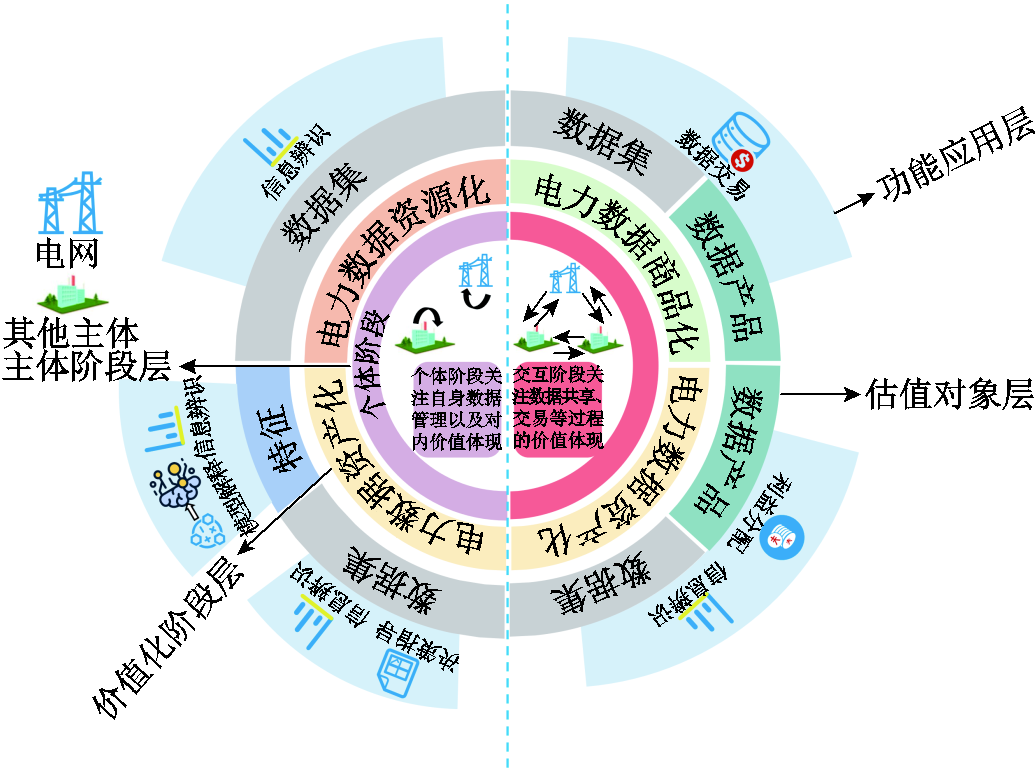
图3 电力数据资产估值应用分析
Fig.3 Data valuation application analysis
估值对象可分为数据集、数据特征及数据产品,它们在不同的应用场景中具有不同的目的。在数据集估值中,例如电网公司的大数据管理部门在管理和维护企业数据集资产时,需要对数据集进行价值评估,从而降低从专业部门获取数据的冗余度,实现高效管理的目的;在数据特征估值方面,比如电网调度部门使用ML模型实现对负荷预测[53]、故障诊断[52]等应用场景的赋能,通过特征估值来评估其对模型的决策影响,以达到剔除冗余特征信息及提高模型决策可信度的目的;在数据产品估值方面,通过评估数据产品给需求方带来的经济效益来估值定价,从而实现数据交易或共享[6,46]。因此,需要根据不同场景及目的来确定合适的估值对象,有针对性地满足业务需求,下面具体展开论述。
3.1.1 数据集估值及其目的
数据集估值即评估数据整体的价值量。数据集估值在资源化、资产化以及商品化阶段中都有体现。首先在资源化阶段,高质量的数据集往往会给后续电力系统的决策和应用带来更多效益,其目的在于事前判别数据质量。例如,电网调度机构可通过信息熵、非噪声比、数据量等数据指标评估数据集质量,为后续相关预测[4]等任务做事前准备。其次在资产化阶段,数据集估值的目的在于实现高效经营决策、制定合理的利益分配及激励机制来促进数据共享。例如,电力公司通过计算各电力巡检图像数据集提供者对于联邦模型的边际贡献来制定合理、公平的激励机制,从而激励更多用户参与图像识别的联邦任务[33]。最后在商品化阶段,数据集通常作为交易的核心对象进行市场交换,数据集估值的目的是为数据交易中的定价提供基础依据。在这一过程中,电力数据集的价值评估通常利用数据指标包括不确定性、完整性、时效性等来综合评估[11],为数据交易及定价提供指导基础。
3.1.2 数据特征估值及其目的
特征在电力系统中的ML模型决策中扮演至关重要的角色。特征估值主要发生在数据资产化阶段,为电网或其他主体内部服务,解决数据增值特征分析问题。特征估值在电力系统中的主要目的有两个:一是剔除冗余特征信息,提升模型效率;二是增强模型决策的可信度与可解释性。
1)在剔除冗余特征信息方面,通常利用指标评估中的统计指标包括Fisher评分、皮尔逊相关系数、互信息等量化特征与预测标签之间的相关性,为新能源预测[58]、负荷预测[32,59]、故障诊断[60]等任务中的特征筛选提供理论依据,并有助于提高ML模型的性能和训练效率。
2)在提高模型决策可信度方面,通过LIME、SHAP等可解释方法计算特征与模型输出之间的关系,进一步揭示模型的决策过程。这些可解释方法已经广泛应用于稳定控制[61]、负荷预测[51,62-63]、优化运行[64]等与ML相关的任务。通过特征估值有助于理解模型对各特征的依赖性,进而提高模型的可解释性与可信度。
3.1.3 数据产品估值及其目的
数据产品是数据经过ML模型或其他数据技术加工开发后生成的洞察或见解,主要体现在资产化以及商品化阶段,其目的为促进数据交易和共享。在资产化阶段,共享数据产品是为了合作性质的内部优化而不是为了提供数据服务,通过对其提供的数据产品估值进行利益分配,促进数据共享[31];在商品化阶段,数据产品是为了提供数据服务,可以将该数据产品对购买者的效益提升作为评估准则即利用效用法来评估价值,为后续购买者支付相关费用提供指导。例如,文献[65]研究了调度方在信息交易市场上交易风力功率预测数据产品的场景,其中数据产品由数据提供商提供,并从理论上推导数据价值公式,将其定义为风力功率预测数据的不确定性降低所带来的经济调度最优成本的下降。
在数据估值中,主体阶段可以分为个体阶段和交互阶段。个体阶段主要关注电网与其他主体自身的数据特性来评估数据价值,不需要考虑外部主体的影响;交互阶段则强调电网与其他主体或其他主体之间的数据交易、合作或共享等场景,不仅需要关注自身数据价值,还需要考虑数据需求方的要求和各方的博弈关系[31]。通过分析个体阶段和交互阶段,电力行业的相关主体能够更全面地理解和发掘数据在不同情境中的多元作用,从而推动数据的高效利用和增值。下面将分别对这两方面进行详细分析。
3.2.1 个体阶段
目前个体阶段主要体现在数据的资源化与资产化两个关键阶段。在资源化阶段,通过对数据的潜在价值进行前期的判断和筛选,为后续提高个体的应用价值水平奠定基础;在资产化阶段,主要涉及个体数据应用的特征价值分析,重点挖掘数据集中特征对ML模型性能的影响,提供事前特征选择和事后模型解释功能,从而优化模型决策并提升其性能。例如,在配电网拓扑信息[42]识别任务中,通过特征重要性排序先提取重要特征,然后训练识别模型,这有助于降低训练复杂度以及提高电网对拓扑信息的识别能力。新能源发电商应用LIME、SHAP和ELI5[66]对特征贡献度进行分析,其中LIME用来解释原始特征值,ELI5用来检查单个样本预测情况,SHAP用于分析光伏预测的全局特征重要性以及特征之间的交互影响,并得出“表面太阳能辐射”在光伏出力预测中是最重要的特征[54]。此外,还涉及自身的运营或管理决策。其中,指标评估法通常被用来评估数据资产价值,指导运营决策。如电网公司可利用数据量、数据质量、数据管理等指标来量化数据资产,评估是否值得进一步开发以及发展业务[55]。以上都为对自身内部的数据特性进行评估,无需考虑其他主体对其影响。
3.2.2 交互阶段
交互阶段主要体现在数据的资产化与商品化两个关键阶段。首先,在资产化阶段,多个主体之间的数据共享与协作是核心体现。在此过程中,数据资产的所有权归属于各主体,而价值评估的重点在于数据共享所带来的协同效应及实际贡献,同时为各主体提供经济激励。多数据方下的数据估值流程如图4所示,电网作为需求方发布任务,需要新能源数据训练ML预测模型或优化调度模型。各风电场作为数据提供方,响应任务请求,并基于隐私计算或联邦学习等技术,提供各自的隐私发电数据,共同参与完成电网任务。电网不仅需要对汇聚的数据进行处理与分析,还需构建合理的数据估值体系,以评估各风电场对预测模型性能提升或调度优化效果的贡献。基于数据估值结果,电网制定公平透明的利益分配策略,以激励各风电场持续共享高质量数据,从而形成可持续的数据协同与优化机制。例如,文献[31]着重探讨了多方协作执行多能源调度的应用场景。各方独立训练负荷预测模型,然后将电、热、冷负荷未来预测数据即数据产品共享至能源调度中心。文献还采用SV方法,量化每个数据方在优化决策中的边际贡献,将调度成本的降低作为价值度量,直观体现数据协作带来的增值效益,并据此进行合理的收益分配。
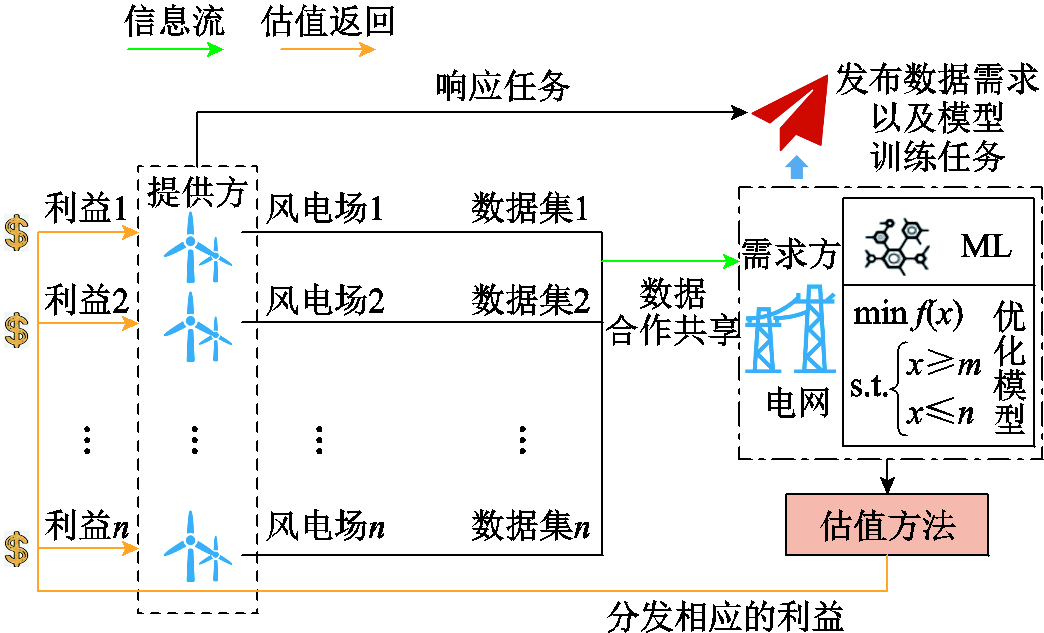
图4 多数据方下的数据估值流程
Fig.4 Data valuation process under multiple data parties
其次,在商品化阶段,交互表现为主体间的数据交易,数据估值可提供一个基础数据定价。类似于文献[65],文献[67]探讨了数据交易场景中调度方与数据提供商之间的数据价值评估问题。其中使用标准差拟合不同分布下的数据产品预测误差,在此基础上,推导出数据价值率公式,量化数据不确定性与经济收益之间的关系,可为后续进一步的实际数据交易定价设定基准。
3.3.1 决策指导
数据估值为电力企业在相关数据业务下提供了科学量化数据资产价值的手段,为企业在相关业务下做出更合理的运营决策提供相关依据[41,55]。如在数字经济背景下,电网企业在低碳环保业务和金融服务业务中,利用实物期权法评估数据资产价值,并充分考虑资产的不确定性及未来经济效益,可在面临不确定环境时为做出更加灵活和理性的投资决策[39]提供依据。
3.3.2 信息辨识
数据估值能够为电网或其他主体提供信息辨识功能,从而实现特征选择以及判别数据质量等目的,主要应用于数据资源化及资产化阶段。具体应用场景以及方法总结见表3。
表3 信息辨识功能在电力系统中的应用
Tab.3 Application of information recognition functions in power systems
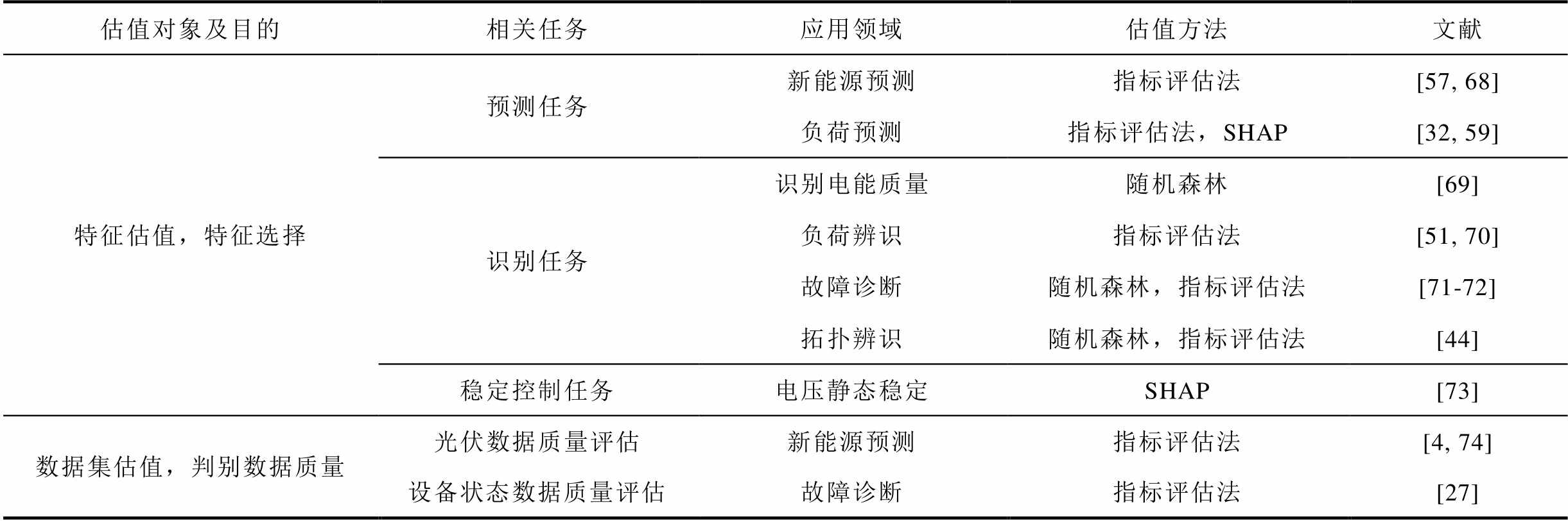
估值对象及目的相关任务应用领域估值方法文献 特征估值,特征选择预测任务新能源预测指标评估法[57, 68] 负荷预测指标评估法,SHAP[32, 59] 识别任务识别电能质量随机森林[69] 负荷辨识指标评估法[51, 70] 故障诊断随机森林,指标评估法[71-72] 拓扑辨识随机森林,指标评估法[44] 稳定控制任务电压静态稳定SHAP[73] 数据集估值,判别数据质量光伏数据质量评估新能源预测指标评估法[4, 74] 设备状态数据质量评估故障诊断指标评估法[27]
1)特征选择
特征选择为电力系统的数据消除冗余信息,为后续的预测、识别、稳定控制等任务质量提高提供有力支持。
(1)预测任务
在光伏新能源和电力负荷预测任务中,特征选择是提升模型性能的关键步骤。在新能源预测中,皮尔逊相关系数[57]、互信息[68]等指标通常被用来判断所选取的特征是否为影响新能源发电的核心特征并剔除冗余信息,从而提高预测效果;在负荷预测中,不仅用统计指标[59]来度量特征价值,还用可解释方法例如SHAP等,通常与互信息[58]等指标法相结合,从众多特征中筛选对预测贡献最大的特征,显著提高了预测模型的准确性和效率。
(2)识别任务
在电能质量识别[69]、负荷辨识[49,70]及故障诊断[71-72]等任务中,最大互信息系数、Fisher、峭度因子等指标以及可解释方法中的随机森林能够有效量化特征价值,去除冗余特征信息,从而显著提升模型的辨识能力,还能满足实际应用中量测装置有限的需求。
(3)稳定控制任务
在静态电压稳定裕度估计中,SHAP方法[73]通过依据特征贡献值对特征进行排序,首先对特征按贡献值降序排列,然后通过循环优化过程剔除冗余特征,从而提高模型的稳定性和准确性。尽管SHAP是一种事后解释方法,但在此场景中,它主要用于特征筛选,为后续的ML模型提供更合适的特征,而非解释模型的决策过程。
以上任务展示了指标法和可解释方法在特征选择中的应用潜力,这不仅降低了后续模型的训练复杂度,还提高了模型的准确性和效率,进而提升了数据的实际价值。
2)判别数据质量
数据的质量直接影响其在电力系统中的实际应用价值,特别是在机器学习训练任务中,一般数据集质量越高,模型的性能越好。因此,事前判别数据质量能够为后续的应用提供坚实的基础。例如,通过构建数据质量计算模型[74],可以帮助系统评估数据的质量,为后续光伏负荷预测模型的构建提供可靠的数据支撑。此外,利用数据的完整性、准确性、唯一性、一致性和及时性等评估指标维度[27],结合模糊层次分析法和熵权法确定权重,也能有效地评估电力设备数据的质量。
3.3.3 模型解释
随着机器学习在电力系统的广泛应用,模型解释对于确保安全性、合规性以及增强决策者对模型输出的信任至关重要[75],主要用于资产化阶段解决数据增值特征分析问题从而达到增强模型可信度的目的。模型解释还可在数据商品化阶段提高由数据训练的ML模型的透明性和可解释性,使其在数据或模型市场上更具竞争性。通过提高模型的可解释性,数据的价值得以充分理解。模型解释为电力系统的各场景任务提供了更为清晰的解释能力,包括预测、识别、优化运行、稳定控制等任务,任务应用如图5所示。
1)预测任务
该部分的内容相当丰富,包含电价预测、负荷预测、新能源预测等应用。在电力市场中的电价预测[76]中,电价预测能够帮助市场参与者做出更为准确的决策以应对能源价格变化。SHAP[77]、PI[53]等可解释法已经被广泛应用于分析各特征对电价预测结果的影响,以加强模型的可解释性。负荷预测[78]在电力系统中起着至关重要的作用,它为电网的规划、调度、供需平衡以及市场交易提供了重要的依据。模型解释功能在交通能源消耗预测[79]、建筑负荷预测[80]等负荷预测中已初具潜力,以挖掘影响负荷预测的重要特征。新能源预测在电力系统中起到平衡供需、优化调度和保障系统稳定的关键作用。数据估值通过提供模型解释功能来分析例如风力[81-82]、光伏[54,83-84]等新能源出力预测模型的内在机制,以及发现未知因素,针对黑箱模型做出相关校正并提高其解释能力。
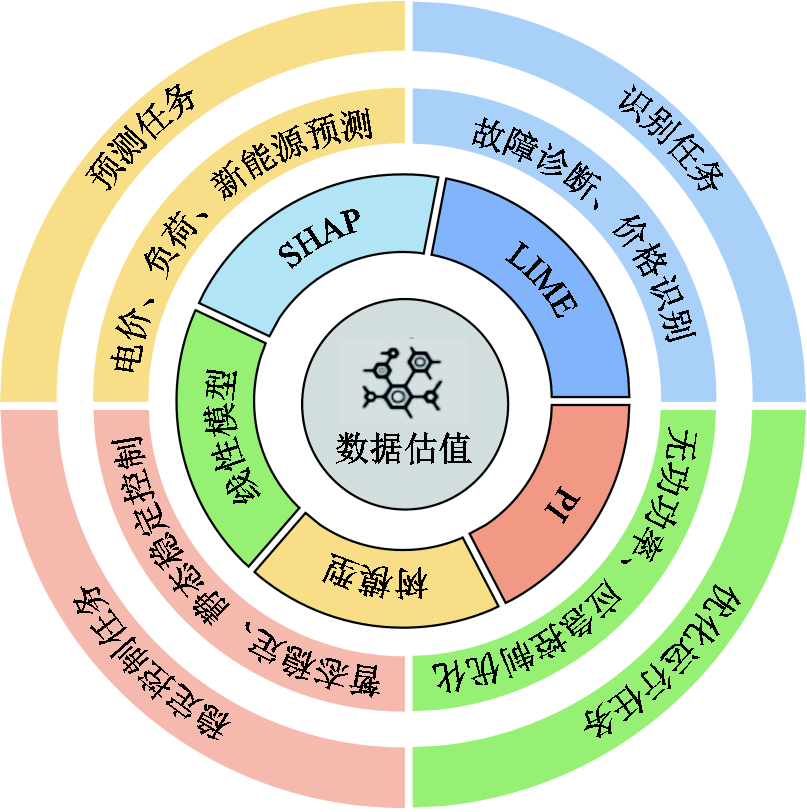
图5 模型解释的任务应用
Fig.5 Task application of model interpretation
2)识别任务
模型解释主要应用于识别任务中的故障诊断识别以及电力市场的价格识别。在故障诊断识别中,模型解释可提供诊断辅助信息来帮助运维工作人员理解模型诊断结果,目前包括电力系统级事件故障诊断解释[85]、设备级故障诊断解释[86-87]以及储能系统诊断解释[88]。在电力市场的价格识别中,模型解释可为深入理解电力市场异常价格现象提供重要参考。例如,文献[89]采用孤立森林算法识别电力市场中的非典型价格,该研究结合机组受限状态的解释性分析,探讨了机组起停、机组受限状态、断面阻塞及非典型价格成因等关键因素的影响。
3)优化运行任务
随着电力系统的复杂化,传统方法无法解决大规模控制或无法利用数学模型建模问题,深度学习和深度强化学习(Deep Reinforcement Learning, DRL)[90]这种数据驱动方法被研究者关注,并在电力系统中被广泛用于优化运行,但这些方法的决策过程往往较难解释。利用基于影响的方法可以有效地解释模型决策原因。例如,文献[91]利用SV量化有功功率和负荷对无功功率控制输出的影响程度。文献[92]提出利用SHAP解释基于DRL的电力系统应急控制模型,并计算所有输入特征对所有输出动作的贡献度来识别关键特征。
4)稳定控制任务
在稳定控制任务中,ML主要用于判别系统在受到扰动后能否在正常阈值内运行。在暂态稳定控制中,SHAP[93]通常被用来对暂态电压稳定控制模型进行解释,可以明确揭示各特征对控制结果的影响;在静态稳定性分析中,XGBoost通常与LIME、SHAP相结合计算特征的贡献率以及分析它们如何影响预测结果[94-95]。这些方法在提供决策支持的同时,也为电力系统稳定性评估提供了量化依据。
3.3.4 利益分配
在电力系统中,各主体之间存在紧密耦合,多方合作的重要性日益凸显[96]。在数据协作过程中,利益分配与数据资产化阶段中的数据价值分配关键问题密不可分。数据估值通过量化各方数据对模型性能或决策结果的具体贡献,并将其作为数据所带来的价值,为利益公平分配提供客观依据。例如,新型电力系统背景下电网调度为提高新能源和负荷预测精度可在数据市场上购买高质量的负荷预测服务。该负荷预测可由多个数据提供者发布(融合气象信息、地区经济发展、其他能源市场交易信息等多元数据),调度机构可以综合多个负荷预测服务,将其组合到一个集成模型中,以进一步提高最终预测的质量,然后利用估值方法例如SV、LOO来评估各方预测数据对于集成预测的贡献[44]。目前,利益分配在电力系统中的能源预测[44,97]、优化调度决策[31]、电力市场[45]以及图像目标检测[56]任务中有所研究。通过制定相应的激励相容策略来实现公平、合理的经济分配,以鼓励各数据方积极参与数据共享。
3.3.5 数据交易
数据交易指的是个人、组织或公司依据特定规则进行各类数据的买卖,用于市场分析、研究或决策支持。随着数据量的急剧增长,以及对数据驱动解决方案需求的不断增加,数据交易已经成为近年来备受关注的研究领域,为企业通过数据交换实现经济效益提供了新途径。为此,国内外研究者已提出了数据交易方案和机制。例如,文献[98]提出了一种基于优化单价编码的数据交易机制,利用OUE(Optimized Unary Encoding)协议,在保证公平交易和隐私保护的同时,实现数据提供者和购买者双方的利润最大化。文献[99]探讨了国内实现能源互联网数据交易市场的架构以及关键技术。目前已有的国内外数据交易市场运营管理案例见表4。国内数据交易市场的特点包括政府主导、平台多元化和强调合规性,例如上海数据交易所、贵阳大数据交易所以及西部数据交易中心。截至2024年7月31日,贵阳大数据交易所累计入驻交易市场的主体1 424家,累计交易额47.87亿元。由此可见,数据市场已经逐步走向成熟,且数据交易正成为一种新的经济形式。国外的数据市场发展较早,例如,微软的Azure在线数据市场于2010年便已成立,但是其在2017年关闭;成立于2017年的Ocean Market由Ocean Protocol创建,其类似于一个竞争市场,该市场是一个去中心化的数据交易平台,旨在保护用户隐私。
表4 数据市场案例
Tab.4 The case for a data marketplace

国家和地区交易机构或平台名称简介 中国上海上海数据交易所成立于2021年,专注于数据流通交易与数据权益保护,推动数据合规流通,助力数据要素市场化配置。该交易所销售20种数据产品。 中国贵阳贵阳大数据交易所成立于2015年,是全国首个大数据交易所,通过采用隐私计算、联邦学习、区块链等先进技术,打造数据、算力、算法等多元的数据产品体系。 中国重庆西部数据交易中心以服务西部地区为核心,致力于推动跨区域数据交易与共享,支持能源、交通及工业数据交易,促进区域经济数字化转型。 新西兰Data RepublicSenator 平台澳大利亚及新西兰银行使用该平台能够简单地进行数据交换、控制数据访问和用户权限、流量治理、共享分析和审计,即扮演做市商的角色。 新加坡Ocean Market该市场最初源自新加坡,是一个利用区块链技术构建的去中心化数据市场,其利用Automated Market Maker生成数据价格。 美国Azure在线数据市场由微软在2010年成立,该案例目标是成为“高级数据和应用程序的一站式商店”,但是由于缺乏市场厚度于2017年关闭。
数据交易下的数据估值如图6所示。数据交易的过程通常包括以下几个步骤:首先,数据提供者单独(例如使用指标法)或交易双方(例如使用效用法)对其进行预期价值评估,为数据定价提供基础;其次,数据提供者与数据购买者在数据市场中进行博弈定价、拍卖定价或采用其他定价策略,其中数据权属以及隐私需要得到保障;最后,双方达成一致,确定数据的最终价格并完成交易。例如,文献[100]以数据大小、完整性以及多样性作为标准来评估物联网(Internet of Things, IoT)数据质量,然后将其作为后续最优数据交易博弈模型的考虑因素,最后双方达到博弈均衡,实现数据最终定价并完成交易。在文献[6]中,电力零售商需要在一个两阶段的电力批发市场模型中实现决策优化,零售商可通过与数据供应商实现数据交易得到准确的负荷预测数据来提高效益,充分考虑了数据产品对零售商的收益影响。该预测数据越准确,其不确定性越小,零售商能得到的经济效益越高。文献[6]推导出数据价值率公式,该公式表明数据带来的单位不确定性降低所对应的利润增加,为后续数据交易的费用界定提供基础。
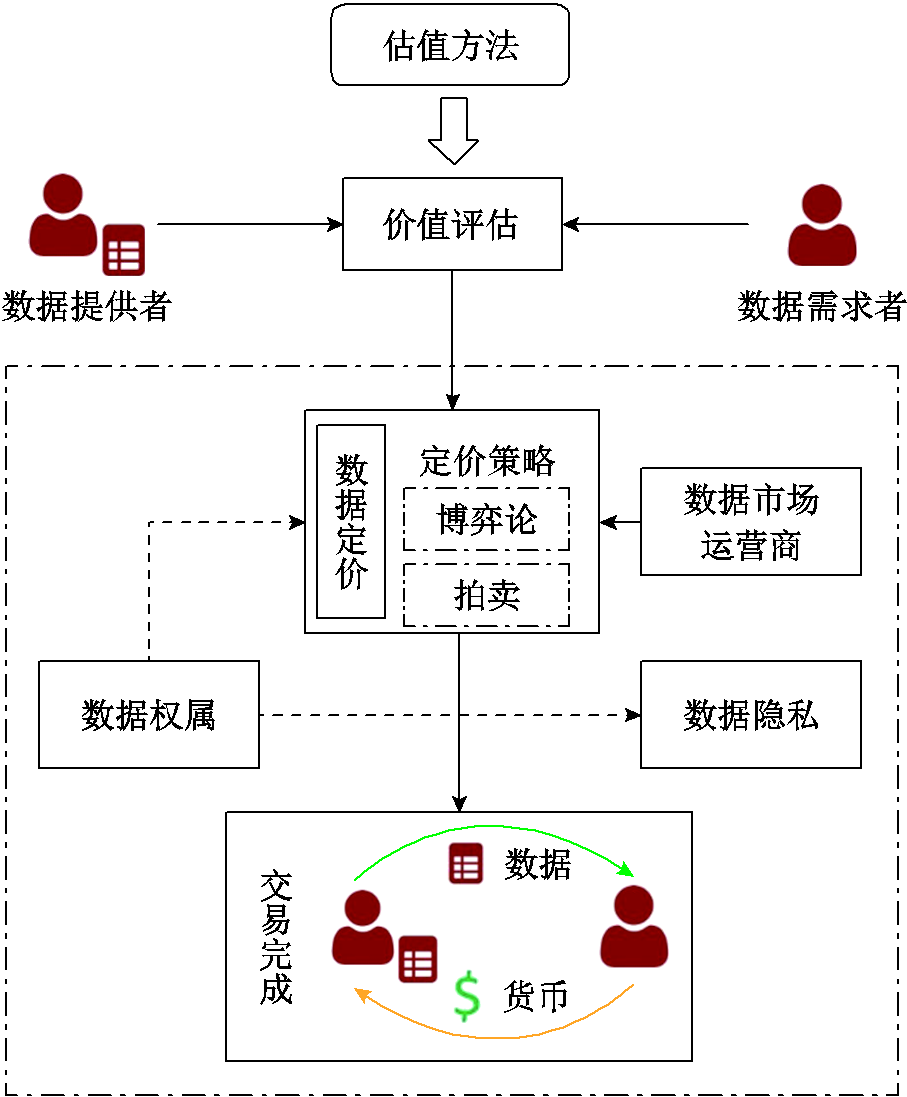
图6 数据交易下的数据估值
Fig.6 Data valuation under data trading
如第3节所述,从估值对象、主体阶段以及功能应用来阐述数据估值在电力系统中的应用,为电力数据释放其价值提供支撑和保障。基于以上分析,本节探讨数据价值的挖掘方法,并分析其在电力系统中的评估应用、未来发展前景以及面临的挑战。
在实际电力数据共享协作的应用场景中,数据拥有者通常需要考虑隐私保护问题,因此不会直接分享原始电力数据。在文献[31]中,各能源部门将本地数据明文共享给调度中心,调度中心将这些预测数据嵌入优化模型以降低成本。然而,以上做法会泄露终端用户的敏感数据,从而可能影响其继续分享数据的意愿。为进一步加强数据价值的挖掘以及保护数据传输过程免受窃听或恶意方的反向推断,数据拥有者可以利用现有的联邦学习[101]、差分隐私[102]、同态加密[103]、安全多方计算[104]、零知识证明[105]等隐私计算技术[106]实现隐私保护下的数据“可用不可见”,打破数据壁垒,提高电力系统的整体运行效率。
以上隐私计算方法虽然能够有效地提高数据的安全性以及在隐私下深度挖掘数据价值,但可能需要考虑以下问题:
1)隐私与价值之间的权衡。在隐私计算中,通常需要对电力数据进行加密操作,在某些情况下可能会导致数据精度问题,例如,在电动汽车出行链的充放电需求交互时往往使用差分隐私等技术进行用户充放电需求或者位置隐私保护,由于加密会导致加密数据和源数据不一致,进而会影响后续的数据分析、预测结果或决策指令的准确性。因此,未来需要研究在数据效益和数据隐私之间找到平衡点,能够在数据隐私得到保护的前提下,不会显著降低数据分析以及价值挖掘。第一,可以根据隐私保护级别动态调整隐私保护参数。例如在差分隐私下根据实际隐私强度需求来自适应隐私预算分配,最大程度地保持数据的可用性。第二,可以利用生成对抗网络来生成与源数据统计特性相符合的数据而不是在原始数据上添加噪声,然后对该生成数据实现共享,可以在数据隐私保护下保证一定程度的数据可用性。第三,可以利用密码学,例如零知识证明,同态加密等,能够保证数据的可用性,但是计算效率将会降低,而且对于机器学习中的非线性计算同态加密等加密算法同样可能存在精度损失问题,由于非线性需要线性近似,需要根据实际场景需求来选择。
2)隐私计算的效率问题。同态加密、SMPC和零知识证明等技术需要进行大量加解密操作和计算电路构建,增加了计算成本。在多方参与的数据处理场景中,数据传输延迟也是一个不容忽视的问题。这些因素会导致隐私计算在处理效率上的瓶颈,尤其是在复杂的电力系统中,面对大规模数据挖掘时,低效的计算方式显然难以满足实际需求。因此,首先,需要根据电力系统中的具体应用场景和业务需求,选择合适的数据挖掘算法和隐私计算技术,从而优化计算性能,如调度运行相关业务以及综合能源网状态估计就需要较高效和快速的计算方式,但发策规划相关业务就对求解效率要求不高;其次,可以通过探索硬件设施的加速方案,降低计算成本;最后,在多方参与的环境下,优化通信协议,降低数据延迟和传输成本,以提升整体计算效率。
3)数据滥用问题。虽然隐私计算可以保证数据共享的安全计算,但是部分参与方可能会利用技术漏洞或不当行为获取本应受保护的数据,导致数据滥用的风险,如电动汽车充放电位置信息可能会造成用户出行链隐私数据泄露,进而暴露用户的生活习惯、出行路线等敏感信息。某些不法分子对以上隐私数据进行非法分析,推测用户的出行行为,甚至进行精准的定位跟踪。这种滥用不仅侵犯用户隐私,还可能引发法律和道德上的问题。因此,隐私计算过程中需要加强监管机制和审计功能,确保数据提供方的隐私得到保护。此外,透明的计算流程和明确的数据使用边界也是至关重要的,避免数据在未授权的情况下被扩展至其他领域或目的。
联邦学习,作为一种分布式机器学习范式,允许多个参与方在本地数据不出本地的情况下协同训练全局模型,其在电力系统中已经得到了广泛研究,例如负荷预测[30]、异常识别[107]、能源管理[108]等领域,能够在数据隐私保护下实现数据合作共同提高效益,从而进一步发挥数据价值。然而,在电力系统的研究中,研究者更多关注数据隐私下的合作,很少关注价值分配问题。由于数据合作中的参与者没有义务提供数据,因此,如何在隐私保护下实现数据联邦的同时进行数据估值中的价值分配及制定激励相容策略工作至关重要。
联邦学习下的激励相容分配策略如图7所示。例如电网或其他任务需求者发起负荷预测、新能源预测以及能源优化等联邦训练服务需求,参与者可以响应并加入联邦任务(指在联邦学习框架下设定的具体任务,如分类、回归或其他数据建模任务),但参与者并不是无偿执行联邦任务,任务需求者需要给予参与者相应的经济利益来促使参与者积极参与数据协作任务,而且各方数据对于相关任务的贡献程度不一即数据价值是不同的,需求方更需要制定合理、公平的分配以及激励机制保证参与者的积极性。可利用基于各参与方数据量和数据成本等数据指标来评估数据价值,或是利用留一法、SV来评估各方对模型的边际贡献。
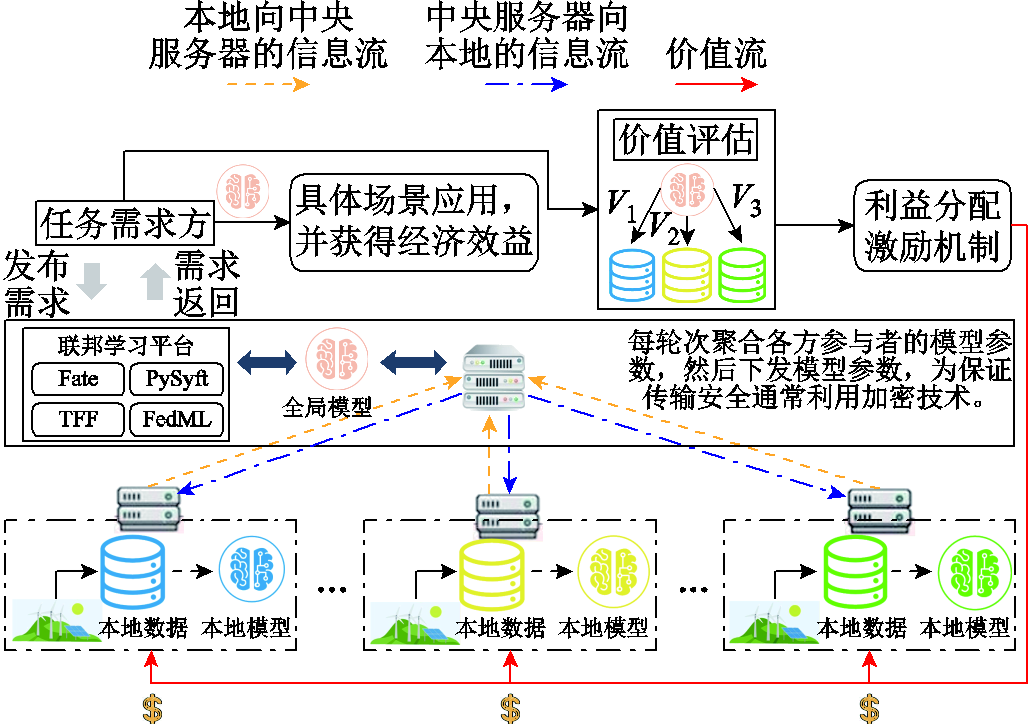
图7 联邦学习下的激励相容分配策略
Fig.7 Incentive-compatible allocation strategies under federal learning
联邦学习促进了数据共享并提高整体的数据利用率,也有一些数据估值方法能够实现利益分配来激励共享,但目前还需考虑以下问题:
1)估值方法的计算效率问题。在数据估值中,计算效率是一个关键问题,尤其是在处理大规模参与者的场景下。例如,在新能源预测的联邦学习中,假设有5个参与者,如果其中以准确率为性能指标,利用SV法执行评估,可能需要训练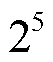 个新能源发电商或数据拥有者数据组合下的新能源预测模型来计算边际贡献,这会随着参与方增加而指数增加,大大增加了计算成本。此外,为了进一步增强数据安全,估值计算往往还需要涉及加密计算[109],进一步提高了计算的复杂性。因此,如何在保证估值准确性的前提下提高计算效率,是当前面临的主要挑战。为此,针对复杂的估值方法,如SV等,以上述负荷预测的联邦学习利益分配为案例,可采用以下实施步骤:首先,可以选择不依赖复杂模型的评估指标[110-111](例如准确率等评估指标依赖模型,互信息评估指标不依赖模型,互信息即通过计算各方负荷数据给负荷预测结果降低的不确定性而无需经过模型输出来计算),将显著减少计算时间;然后,在多方参与下,SV还需要排列组合计算各方数据贡献,可采用近似计算方法(如蒙特卡洛采样、梯度近似)降低计算复杂度,以减少计算成本,同时确保估值的合理性;最后,算法程序可利用python等该类易于处理的编程语言,其中集成了分布式计算或并行处理技术的方法库,可快速调用。
个新能源发电商或数据拥有者数据组合下的新能源预测模型来计算边际贡献,这会随着参与方增加而指数增加,大大增加了计算成本。此外,为了进一步增强数据安全,估值计算往往还需要涉及加密计算[109],进一步提高了计算的复杂性。因此,如何在保证估值准确性的前提下提高计算效率,是当前面临的主要挑战。为此,针对复杂的估值方法,如SV等,以上述负荷预测的联邦学习利益分配为案例,可采用以下实施步骤:首先,可以选择不依赖复杂模型的评估指标[110-111](例如准确率等评估指标依赖模型,互信息评估指标不依赖模型,互信息即通过计算各方负荷数据给负荷预测结果降低的不确定性而无需经过模型输出来计算),将显著减少计算时间;然后,在多方参与下,SV还需要排列组合计算各方数据贡献,可采用近似计算方法(如蒙特卡洛采样、梯度近似)降低计算复杂度,以减少计算成本,同时确保估值的合理性;最后,算法程序可利用python等该类易于处理的编程语言,其中集成了分布式计算或并行处理技术的方法库,可快速调用。
2)评估指标合理设计问题。目前,已有研究探讨了数据指标以及一些性能指标来度量数据价值[112],这些指标在不同应用场景中具有各自的优势和局限。例如,在电网负荷预测联邦任务中,基于历史负荷数据准确性和完整性的评估指标可能无法公平地衡量所有参与方的数据价值,虽然这种方法计算简单快速,但高质量数据不一定带来高质量模型,还需要评估对模型的效用影响。因此,在联邦学习下,未来的指标设计需要综合考虑多个方面,确保其全面性。此外,评估指标还需具备公平性和抗恶意性,防止恶意数据方通过提供噪声数据或低质量数据获得不合理的高收益[18]。这要求评估指标具备较强的鲁棒性,能够识别并排除低质量或恶意数据,从而确保合作过程中数据的公正性和可靠性。
3)利益分配的合理性和公平性问题。在数据合作场景中,尽管SV等方法可以用于利益分配,但这些方法如何在复杂的电力系统中准确评估每个数据方对整体的贡献仍然面临挑战。例如,某工业用户发起负荷预测联邦任务,该需求方同样拥有负荷数据,简单地利用SV来评估可能存在未将其与其他参与方进行实际区分,而是将需求方和提供方同等对待的问题,从而忽略了需求方拥有的内部数据和提供方拥有的外部数据之间的替代效应。而且,在一体化的框架下不仅需要考虑数据对需求方的效用价值,还需要平衡数据提供方的成本[45]和风险。因此,需要根据实际需求方是否有内部数据参与训练,以及综合考虑数据提供方和数据需求方双方的数据价值,来设计更加精确、公平的利益分配机制,促进各方数据共享和协作。
数据合作不仅需要关注模型预测性能的提升,在电力系统的实际数据应用中更加需要关注数据协同对于其优化决策的影响[3]。例如,在负荷预测中,某负荷数据拥有方对于联合训练负荷预测模型精度的提高贡献大,但不意味着该方的数据对于后续电网调度机构利用该预测结果执行优化调度所降低的运行成本的贡献大,以上可能会导致后续的利益分配出现不公平的问题,而且预测精度高不一定带来系统运行成本的降低[113]。因此,需要将预测-决策实现一体化建模执行数据估值来促进各方数据共享。例如,在电网的负荷预测-调度决策一体化的数据合作场景中,各方利用隐私计算技术,可以在保证数据隐私安全的前提下共享数据,其中不再是先训练负荷预测模型然后执行经济调度决策,而是同时考虑负荷预测模型训练和经济调度决策模型,利用决策模型得到的结果更新负荷预测模型参数,最后利用估值方法实现利益分配来激励各方数据共享。
虽然数据合作下的预测决策一体化能够更好地为电力系统服务,但可能面临以下问题。首先是复杂环境的预测-决策一体化建模困难问题。目前,预测和决策为两个独立环节,即“先预测、后决策”。将预测模型与决策优化模型相互耦合,在实际应用中需要考虑模型的稳定性和准确性。此外,必须考虑不同主体之间的相互影响关系。如在电力市场环境中,市场成员例如新能源发电商等决策行为可能受到功率预测、市场价格、供需波动、政策调整等多方面因素的影响,而且市场成员之间可能还存在合作或竞争的关系影响其他成员的决策行为,这些因素使得预测模型和决策模型之间的关系更加复杂,且难以单独优化,并影响训练和优化的效率。因此,可以将预测模型和优化决策模型一起嵌入优化过程,共同训练,通过双向反馈机制实现模型间的互动与调整。分布式计算可以将复杂计算分解为多个子问题,提高计算效率,进而提高系统的灵活性和实时性。
随着隐私计算技术的发展,各方可以在保证数据隐私的前提下,实现数据的“可用不可见”。例如在联邦学习框架下,各方能够安全共享数据,保护各自的数据不被直接访问。然而,在在执行利益分配或数据交易时,可能存在篡改风险——某些数据方可能试图通过篡改数据或计算结果来增加自身的收益。区块链技术[114]作为一种不可篡改、可追溯的分布式账本,能够对整个数据价值流过程进行有效的监管。区块链中的智能合约技术[115]作为一种能够自动执行合约而且流程可追溯的工具,可确保交易以及利益分配过程的自动化、透明性和可靠性。能源数据市场中的交易以及利益分配监管如图8所示。以负荷预测联邦任务中的利益分配为例,其中电网可能为需求方,其他用电企业为数据提供者,需求方需要给各数据提供者提供相关利益。首先,在数据共享挖掘前,需要明确智能合约(如利益分配合约利用SV来评估各方贡献)、确认数据参与方以及计算执行方式(如在模型训练时利用联邦学习和同态加密的隐私计算);然后,各方上传电子签名达成共识。在模型训练过程,各方需要按照约定方式执行训练,随时校验合约。区块链中记录了各方的计算流程,包括每轮次的模型参数、计算日志以及计算结果等,防止各方伪造训练贡献。需求方可对数据提供者的计算流程以及预测计算结果的存证进行利益分配,可以有效地防止篡改行为,确保分配的公正性与透明性。
图8 能源数据市场中的交易以及利益分配监管
Fig.8 Transactions in energy data markets and regulation of the distribution of benefits
类似的篡改风险同样可能发生在数据交易过程中,交易中的一方可能尝试通过篡改交易价格获取非法收益。某些数据提供方可能试图篡改其提供的电力负荷数据、设备运行数据或环境监测数据等电力数据,通过伪造更有利的数据提高其数据的市场价值;或者人为操纵交易平台的定价机制,从而在数据市场中获得更高的收益。以数据市场中的新能源数据交易为例,其中新能源发电商可能为数据提供方,提供光伏、风电等新能源出力数据;能源市场运营商或其他发电商可能为数据购买方,用于市场预测或发电功率预测。基于区块链的智能合约的安全数据交易如下:在数据交易前,首先,提供者需要明确售卖数据的价值及初始数据的定价,并上传至链上,购买方上传其需求以及期望的数据价格,然后交易双方利用电子签名对智能合约(如博弈定价)达成共识。在交易开始时,授权节点会触发智能合约,数据提供方和购买方可以在市场上展开交易。交易双方会根据智能合约中博弈均衡的结果在链上进行交易,并锁定交易价格。交易价格及相关信息随后会被上传至链上,确保其透明和不可篡改。数据交易后,双方进行交易资金结算以及数据版权转移,数据版权转移存证记录在链上防止二次售卖。通过这种方式,数据交易不仅能够实现自动化,还能通过区块链技术确保交易价格的公正性,防止人为干预或篡改行为。
区块链提供了数据交易以及利益分配的可监管、可信环境,但还需考虑以下问题:数据权属、监管以及法律问题。在电力系统中,随着主体的多样化以及数据的合作共享和交易日益频繁,明确数据的权属[116],以及考虑数据相关的监管与法律规定对数据估值尤其是在数据交易、利益分配等场景下至关重要。首先针对数据权属问题,电力数据主体有发电企业、电网公司、配电运营商、用户,以及第三方数据提供商,这种多样化的来源导致数据所有权难以界定。如果没有明确的数据权属,不仅存在潜在的法律争议和纠纷,并且使得某些数据方未能从数据的价值中获得应有的回报。例如在需求响应刻画中,可能涉及用户数据如用电行为和响应量、发电数据、电网数据等,用户数据的所有权属于用户,而电网公司若使用该数据进行需求响应优化以及开发数据产品获利,必须确保获得用户的授权或许可,否则可能会引发数据隐私和所有权的法律争议。其次,无论是个人、企业、监管机构还是政府对数据交易监管、隐私保护及数据合法合规要求的关注都逐渐增强。针对数据监管以及法律问题,目前欧洲出台了通用数据保护条例(General Data Protection Regulation,GDPR),我国也出台了《中华人民共和国数据安全法》等相关的数据法律法规,其中对数据隐私以及合规性都有明确的要求,这可能会影响相应的数据交易或合作共享模式,数据方可能需要先对数据进行相应处理,使得其符合相应的法律法规,这可能会给后续的数据估值额外增加了风险考量以及处理成本,估值过程中无法忽略该部分,否则可能导致数据交易失败或利益分配不合理,阻碍数据流通。因此,必须在区块链技术的基础上,充分考虑相应法律和监管环境的影响及行业标准,明确数据权属、遵守数据隐私及合规性,避免后续发生法律纠纷,确保各方的合法权益得到充分保障,以实现合理的数据估值,保证数据市场健康发展,提高数据合作共享意愿。
随着电网大数据技术的进步和数据流通主体的多样化,需要开发更加通用且具备扩展性的估值平台,能够自适应用户需求,例如满足不同估值对象、单方和多方场景、经济价值评估、信息价值评估及隐私保护等多重需求。具体而言,通过设计人性化、通用化的估值平台,将不同需求的程序封装成库,设计不同接口供相关人员能够简单调用,无须相关人员掌握例如经济学、机器学习、密码学等知识,这样有助于降低使用数据估值技术的难度,并提高其接受度。例如,电网公司可以利用该平台进行多方数据共享和利益分配,评估来自不同发电商、用电用户及分布式能源系统的数据价值,同时还能确保各方的数据隐私。平台可以根据电力需求预测、负荷调度和可再生能源预测等场景、估值对象以及目的,提供不同的估值模型,帮助电网公司精准评估各方对电力系统优化的贡献。此外,平台还可以通过区块链技术记录每次电力数据交易和利益分配的全过程,确保公平和安全。
数据是电力系统发展的重要资源,为其数智化发展奠定了坚实的基础。数据为电力系统中的场景业务带来价值,然而具体能带来了多少价值的认知尚且缺乏,这种缺乏会导致数据难以在电力系统中充分释放其价值,阻碍相关人员更清晰地理解电力数据如何为经济和系统运行提供价值支持,并且限制了数据共享和流通,不能满足未来新型电力系统的实际需求。
在我国加快建设数字化电力系统的背景下,本文旨在推动数据估值在新型电力系统中数据管理、数据市场交易、数据共享、模型可解释性等场景应用,释放数据潜力与价值,促进电力数据的高效流通,推动电力系统的高效运行。
参考文献
[1] 樊强, 刘东, 王宇飞, 等. 电力信息物理系统形态演进关键技术及其进展[J]. 中国电机工程学报, 2024, 44(21): 8341-8353. Fan Qiang, Liu Dong, Wang Yufei, et al. Key technologies and trends of cyber physical power system morphology evolution[J]. Proceedings of the CSEE, 2024, 44(21): 8341-8352.
[2] 韩笑, 郭剑波, 蒲天骄, 等. 电力人工智能技术理论基础与发展展望(一): 假设分析与应用范式[J]. 中国电机工程学报, 2023, 43(8): 2877-2891. Han Xiao, Guo Jianbo, Pu Tianjiao, et al. Theoretical foundation and directions of electric power artificial intelligence(Ⅰ): hypothesis analysis and application paradigm[J]. Proceedings of the CSEE, 2023, 43(8): 2877-2891.
[3] 左宇, 秦大林, 杜尔顺, 等. 交互式负荷预测:研究框架与展望[J/OL]. 中国电机工程学报, 2024: 1-13[2025-01-22]. https://doi.org/10.13334/j.0258-8013.pcsee. 242224. Zuo Yu,Zuo Yu, Qin Dalin, DU Ershun, et al. Inter active load forecasting: research framework and outlook[J/OL]. Proceedings of the CSEE, 2024: 1-13[2025-01-22]. https://doi.org/10.13334/j.0258-8013.pcsee. 242224.
[4] 于明凯. 数据价值驱动的新能源电力系统优化运行方法研究[D]. 北京: 华北电力大学, 2023. Yu Mingkai. Research on optimal operation method of new energy power system driven by data value[D]. Beijing: North China Electric Power University, 2023.
[5] 文沛先. 基于数据信息技术驱动的光伏发电系统智能化故障诊断[J]. 太阳能学报, 2024, 45(12): 688.Wen Peixian. Intelligent fault diagnosis of photovoltaic power generation system driven by data information technology[J]. Acta Energiae Solaris Sinica, 2024, 45(12): 688.
[6] Wang Bohong, Guo Qinglai, Yang Tianyu, et al. Data valuation for decision-making with uncertainty in energy transactions: a case of the two-settlement market system[J]. Applied Energy, 2021, 288: 116643.
[7] 刘桂锋, 吴雅琪, 韩牧哲, 等. 面向数据要素价值化的数据资源应用场景创新研究[J]. 情报理论与实践, 2025, 48(1): 53-62. Liu Guifeng, Wu Yaqi, Han Muzhe, et al. Research on the innovation of data resource application scenarios for the valorization of data elements[J]. Intelligence Theory and Practice, 2025, 48(1): 53-62
[8] 中共中央国务院关于构建数据基础制度更好发挥数据要素作用的意见. [EB/OL]. (2022-12-19)[2025-01-22]. https://www.gov.cn/zhengce/2022-12/19/content_5732695.htm.
[9] 国家能源局关于加快推进能源数字化智能化发展的若干意见[EB/OL]. (2023-03-28)[2025-01-22]. https://www.gov.cn/zhengce/zhengceku/2023-04/02/content_ 5749758. htm.
[10] 中国南方电网有限责任公司. 中国南方电网有限责任公司数据资产定价方法(试行)[R/OL]. (2022-08-30) [2025-01-22]. https://power.in-en.com/html/power- 2385119. shtml.
[11] Liu Ziming, Huang Bonan, Li Yushuai, et al. Pricing game and blockchain for electricity data trading in low-carbon smart energy systems[J]. IEEE Transactions on Industrial Informatics, 2024, 20(4): 6446-6456.
[12] 胥婷, 吴丹麦, 魏明月, 等. 开放数据视角下健康医疗数据价值评估指标体系研究[J]. 医学信息学杂志, 2022, 43(1): 16-22. Xu Ting, Wu Danmai, Wei Mingyue, et al. Study on the index system of healthcare data value evaluation from the perspective of open data[J]. Journal of Medical Informatics, 2022, 43(1): 16-22.
[13] Xu Anran, Zheng Zhenzhe, Wu Fan, et al. Online data valuation and pricing for machine learning tasks in mobile health[C]//IEEE INFOCOM 2022 - IEEE Conference on Computer Communications, London, United Kingdom, 2022: 850-859.
[14] Brinch M. Understanding the value of big data in supply chain management and its business processes[J]. International Journal of Operations & Production Management, 2018, 38(7): 1589-1614.
[15] Ghasemaghaei M, Calic G. Does big data enhance firm innovation competency? The mediating role of data-driven insights[J]. Journal of Business Research, California, 2019, 104: 69-84.
[16] Ghorbani A, Zou J. Data shapley: equitable valuation of data for machine learning[C]//International Conference on Machine Learning, Long Beach, California, 2019: 2242-2251.
[17] Coyle D, Manley A. What is the value of data? A review of empirical methods[J]. Journal of Economic Surveys, 2024, 38(4): 1317-1337.
[18] Sim R H L, Xu X, Low B K H. Data valuation in machine learning: “ingredients”, strategies, and open challenges[C]//International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022: 5607-5614.
[19] Coyle D, Diepeveen S, Wdowin J. The value of data summary report[EB/OL]. https://www.bennettinstitute. cam.ac.uk/publications/value-data-summary-report/.
[20] 高骞, 胡广伟, 林辉, 等. 电力大数据价值链及其价值创造模式研究[J]. 中国科技资源导刊, 2020, 52(1): 6-13, 34. Gao Qian, Hu Guangwei, Lin Hui, et al. Analysis on the value chain and value creation models of power big data[J]. China Science & Technology Resources Review, 2020, 52(1): 6-13, 34.
[21] 李海舰, 赵丽. 数据成为生产要素: 特征、机制与价值形态演进[J]. 上海经济研究, 2021, 33(8): 48-59. Li Haijian, Zhao Li. Data becomes a factor of production: characteristics, mechanisms, and the evolution of value form[J]. Shanghai Journal of Economics, 2021, 33(8): 48-59.
[22] 朱秀梅, 林晓玥, 王天东, 等. 数据价值化: 研究评述与展望[J]. 外国经济与管理, 2023, 45(12): 3-17. Zhu Xiumei, Lin Xiaoyue, Wang Tiandong, et al. Data valued process: a review and prospects[J]. Foreign Economics & Management, 2023, 45(12): 3-17.
[23] 魏帅, 马芳. 浅谈如何提高电力营销系统基础数据质量[J]. 科技风, 2018(34): 194. Wei Shuai, Ma Fang. Discussion on how to improve the quality of basic data of electric power marketing system[J]. Technology Wind, 2018(34): 194.
[24] 谢琳, 陶蕾, 叶瑞丽, 等. 基于多源量测信息的数据质量诊断方法研究与分析[J]. 电器与能效管理技术, 2024(5): 36-45. Xie Lin, Tao Lei, Ye Ruili, et al. Research and analysis on data quality diagnosis method based on multi-source measuring information[J]. Electrical & Energy Management Technology, 2024(5): 36-45.
[25] 计蓉, 侯慧娟, 盛戈皞, 等. 基于粒子群优化堆叠降噪自编码器的电力设备状态数据质量提升[J]. 上海交通大学学报, 2025, 59(6): 780-788. Ji Rong, Hou Huijuan, Sheng Gehao, et al. Quality improvement of power equipment condition data based on particle swarm optimization stacked noise reduction self-encoder[J]. Journal of Shanghai Jiao Tong University, 2025, 59(6): 780-788.
[26] 孔祥玉, 马玉莹, 艾芊, 等. 新型电力系统多元用户的用电特征建模与用电负荷预测综述[J]. 电力系统自动化, 2023, 47(13): 2-17. Kong Xiangyu, Ma Yuying, Ai Qian, et al. Review on electricity consumption characteristic modeling and load forecasting for diverse users in new power system[J]. Automation of Electric Power Systems, 2023, 47(13): 2-17.
[27] 计蓉, 侯慧娟, 盛戈皞, 等. 基于组合赋权法和模糊综合评价的电力设备状态数据质量评估[J]. 高电压技术, 2024, 50(1): 274-281. Ji Rong, Hou Huijuan, Sheng Gehao, et al. Quality assessment of power equipment condition data based on combined assignment method and fuzzy comprehensive evaluation[J]. High Voltage Engineering, 2024, 50(1): 274-281.
[28] 李锦狄, 刘建戈, 张鹏宇, 等. 关于电网数据资产化与价值评估的探索[J]. 中国信息化, 2020(12): 67-68. Li Jindi, Liu Jiange, Zhang Pengyu, et al. Exploration on capitalization and value evaluation of power grid data[J]. China Informatization, 2020(12): 67-68.
[29] 邢汇笛, 龚钢军, 翟明岳, 等. 电力数据共享安全防护与隐私保护综述[J]. 综合智慧能源, 2024, 46(5): 30-40. Xing Huidi, Gong Gangjun, Zhai Mingyue, et al. Research on security and privacy protection of electric power data sharing[J]. Integrated Intelligent Energy, 2024, 46(5): 30-40.
[30] 王蓓蓓, 朱竞, 王嘉乐, 等. 电表数据隐私保护下的联邦学习行业电力负荷预测框架[J]. 电力系统自动化, 2023, 47(13): 86-93. Wang Beibei, Zhu Jing, Wang Jiale, et al. Federated-learning based industry load forecasting framework under privacy protection of meter data[J]. Automation of Electric Power Systems, 2023, 47(13): 86-93.
[31] Zhou Yangze, Wen Qingsong, Song Jie, et al. Load data valuation in multi-energy systems: an end-to-end approach[J]. IEEE Transactions on Smart Grid, 2024, 15(5): 4564-4575.
[32] 谷云东, 刘浩. 基于最优特征组合改进极限梯度提升的负荷预测[J]. 计算机应用研究, 2021, 38(9): 2767-2772. Gu Yundong, Liu Hao. Load forecasting based on optimal feature combination improved XGBoost[J]. Application Research of Computers, 2021, 38(9): 2767-2772.
[33] 仲林林, 刘柯妤. 面向电力巡检图像目标检测的联邦学习激励机制[J]. 电工技术学报, 2024, 39(17): 5434-5449. Zhong Linlin, Liu Keyu. Federated-learning incentive mechanism for object detection in power inspection images[J]. Transactions of China Electrotechnical Society, 2024, 39(17): 5434-5449.
[34] 数据价值化与数据要素市场发展报告[EB/OL]. (2024-09-09)[2025-01-22]. http://www.caict.ac.cn/ kxyj/qwfb/ztbg/202409/P020240926365684089988.pdf.
[35] 徐漪. 大数据的资产属性与价值评估[J]. 产业与科技论坛, 2017, 16(2): 97-99. Xu Yi. Asset attribute and value evaluation of big data[J]. Industrial & Science Tribune, 2017, 16(2): 97-99.
[36] 李永红, 张淑雯. 数据资产价值评估模型构建[J]. 财会月刊, 2018(9): 30-35. Li Yonghong, Zhang Shuwen. Establishment of the value evaluation model of data assets[J]. Finance and Accounting Monthly, 2018(9): 30-35.
[37] 陈芳, 余谦. 数据资产价值评估模型构建: 基于多期超额收益法[J]. 财会月刊, 2021(23): 21-27. Chen Fang, Yu Qian. Construction of data asset value evaluation model-based on multi-period excess return method[J]. Finance and Accounting Monthly, 2021(23): 21-27.
[38] 周艳秋. 数字经济驱动下数据资产价值评估研究[D]. 北京: 首都经济贸易大学, 2022. Zhou Yanqiu. Research on value evaluation of data assets driven by digital economy[D]. Beijing: Capital University of Economics and Business, 2022.
[39] 邹贵林, 陈雯, 吴良峥, 等. 电网数据资产定价方法研究: 基于两阶段修正成本法的分析[J]. 价格理论与实践, 2022(3): 89-93, 204. Zou Guilin, Chen Wen, Wu Liangzheng, et al. Research on grid power data asset pricing method: Analysis based on two-stage modified costing[J]. Price (Theory & Practice), 2022(3): 89-93, 204.
[40] Myers S C. Determinants of corporate borrowing[J]. Journal of Financial Economics, 1977, 5(2): 147-175.
[41] 刘国磊. 典型应用场景下电网企业数据资产价值测度研究[D]. 北京: 华北电力大学, 2023. Liu Guolei. Research on value measurement of data assets of power grid enterprises in typical application scenarios[D]. Beijing: North China Electric Power University, 2023.
[42] Batini C, Cappiello C, Francalanci C, et al. Methodologies for data quality assessment and improvement[J]. ACM Computing Surveys, 2009, 41(3): 1-52.
[43] 孙俊烨. 电网企业数据资产价值评估研究: 以国家电网为例[D]. 保定: 河北大学, 2023. Sun Junye. Research on value evaluation of data assets of power grid enterprises: taking state grid as an example[D]. Baoding: Hebei University, 2023.
[44] 沈赋, 张微, 徐潇源, 等. 基于随机森林和最大互信息系数关键特征选择的配电网拓扑辨识研究[J]. 电力系统保护与控制, 2024, 52(17): 1-11. Shen Fu, Zhang Wei, Xu Xiaoyuan, et al. Topological identification of distribution networks based on key feature selection using RF and MIC[J]. Power System Protection and Control, 2024, 52(17): 1-11.
[45] Shapley L S. A value for n-person games[J]. Contributions to the Theory of Games, 1953, 2(28): 307-317.
[46] Wang Bohong, Guo Qinglai, Yu Yang. Mechanism design for data sharing: an electricity retail perspective[J]. Applied Energy, 2022, 314: 118871.
[47] Sun Zelin, Von Krannichfeldt L, Wang Yi. Trading and valuation of day-ahead load forecasts in an ensemble model[J]. IEEE Transactions on Industry Applications, 2023, 59(3): 2686-2695.
[48] Quinlan J R. C4. 5: programs for machine learning [M]. Elsevier, 2014.
[49] Ribeiro M T, Singh S, Guestrin C. “Why should I trust you?”: explaining the predictions of any classifier [C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, California, USA, 2016: 1135-1144.
[50] Fisher A, Rudin C, Dominici F. All models are wrong, but Many are useful: learning a variable’s importance by studying an entire class of prediction models simultaneously[J]. Journal of Machine Learning Research, 2019, 20: 177.
[51] Lundberg S, Lee S I. A unified approach to interpreting model predictions[J/OL]. ArXiv, 2017: 1705.07874. https://arxiv.org/abs/1705.07874v2.
[52] 刘雁文, 胡炎, 邰能灵. 基于决策树的智能变电站运维专家系统规则提取方法[J]. 电力科学与技术学报, 2019, 34(1): 123-128. Liu Yanwen, Hu Yan, Tai Nengling. Rule extraction method of operation and maintenance expert system for an intelligent substation based on the decision tree[J]. Journal of Electric Power Science and Technology, 2019, 34(1): 123-128.
[53] Kim M, Jun J A, Song Yujin, et al. Explanation for building energy prediction[C]//2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea (South), 2020: 1168-1170.
[54] An Jun, Yu Jiachen, Li Zonghan, et al. A data-driven method for transient stability margin prediction based on security region[J]. Journal of Modern Power Systems and Clean Energy, 2020, 8(6): 1060-1069.
[55] Ma Hongnan, McAreavey K, McConville R, et al. Explainable AI for non-experts: energy tariff forecasting[C]//2022 27th International Conference on Automation and Computing (ICAC), Bristol, United Kingdom, 2022: 1-6.
[56] Kuzlu M, Cali U, Sharma V, et al. Gaining insight into solar photovoltaic power generation forecasting utilizing explainable artificial intelligence tools[J]. IEEE Access, 2020, 8: 187814-187823.
[57] 吴泽方. 电网企业数据资产价值评估及价值实现研究[D]. 长沙: 长沙理工大学, 2021. Wu Zefang. Research on value evaluation and value realization of data assets in power grid enterprises[D]. Changsha: Changsha University of Science & Technology, 2021.
[58] 王瑶, 吴云来, 俞铁铭, 等. 基于特征选择和XGBoost算法考虑极端天文、气象事件影响的光伏性能预测方法[J]. 太阳能学报, 2024, 45(5): 547-555. Wang Yao, Wu Yunlai, Yu Tieming, et al. Forecasting method of photovoltaic power generation based on feature selection and XGBoost algorithm considering influence of extreme astronomical and meteorological events[J]. Acta Energiae Solaris Sinica, 2024, 45(5): 547-555.
[59] 商立群, 李洪波, 侯亚东, 等. 基于特征选择和优化极限学习机的短期电力负荷预测[J]. 西安交通大学学报, 2022, 56(4): 165-175. Shang Liqun, Li Hongbo, Hou Yadong, et al. Short-term power load forecasting based on feature selection and optimized extreme learning machine[J]. Journal of Xi’an Jiaotong University, 2022, 56(4): 165-175.
[60] 马良玉, 程东炎, 梁书源, 等.基于LightGBM-VIF-MIC-SFS的风电机组故障诊断输入特征选择方法[J]. 热力发电, 2024, 53(1): 154-164. Ma Liangyu, Cheng Dongyan, Liang Shuyuan, et al. Input feature selection method for wind turbine fault diagnosis based on LightGBM-VIF-MIC-SFS[J]. Thermal Power Generation, 2024, 53(1): 154-164.
[61] 甄永赞, 阮程. 基于强化学习的混合元启发式暂态电压稳定特征选择方法及可解释性研究[J]. 电网技术, 2024, 48(4): 1519-1532. Zhen Yongzan, Ruan Cheng. Reinforcement learning-based hybrid element heuristic transient voltage stability feature selection and its interpretability[J]. Power System Technology, 2024, 48(4): 1519-1532.
[62] Moon J, Rho S, Baik S W. Toward explainable electrical load forecasting of buildings: a comparative study of tree-based ensemble methods with Shapley values[J]. Sustainable Energy Technologies and Assessments, 2022, 54: 102888.
[63] 章超波, 刘永政, 李宏波, 等. 基于加权残差聚类的建筑负荷预测区间估计[J]. 浙江大学学报(工学版), 2022, 56(5): 930-937. Zhang Chaobo, Liu Yongzheng, Li Hongbo, et al. Weighted residual clustering-based building load prediction interval estimation[J]. Journal of Zhejiang University (Engineering Science), 2022, 56(5): 930-937.
[64] Dai X, Cheng S, Chong A. Deciphering optimal mixed-mode ventilation in the tropics using reinforcement learning with explainable artificial intelligence[J]. Energy and Buildings, 2023, 278: 112629.
[65] Wang Bohong, Xia Tian, Guo Qinglai, et al. Data valuation in electricity transactions with uncertainty considering risk preferences[C]//2022 IEEE 5th International Electrical and Energy Conference (CIEEC), Nanjing, China, 2022: 917-921.
[66] ELI5. A library for debugging_inspecting machine learning classifiers and explaining their predictions. [EB/OL]. (2023-11-06)[2025-01-22]. https://github. com/eli5-org/ eli5.
[67] Wang Bohong, Guo Qinglai, Yang Tianyu, et al. Evaluation of information value for solar power plants in market environment[C]//2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 2020: 3574-3580.
[68] 刘嘉诚, 刘俊, 赵宏炎, 等. 基于DKDE与改进mRMR特征选择的短期光伏出力预测[J]. 电力系统自动化, 2021, 45(14): 13-21. Liu Jiacheng, Liu Jun, Zhao Hongyan, et al. Short-term photovoltaic output forecasting based on diffusion kernel density estimation and improved max-relevance and Min-redundancy feature selection [J]. Automation of Electric Power Systems, 2021, 45(14): 13-21.
[69] 杨晓梅, 郭林明, 肖先勇, 等. 基于可调品质因子小波变换和随机森林特征选择算法的电能质量复合扰动分类[J]. 电网技术, 2020, 44(8): 3014-3020. Yang Xiaomei, Guo Linming, Xiao Xianyong, et al. Classification of multiple power quality disturbances based on TQWT and random forest feature selection algorithm[J]. Power System Technology, 2020, 44(8): 3014-3020.
[70] 向颖, 严慧峰, 余旭阳, 等. 基于特征优选及改进自组织神经网络的非侵入式负荷辨识[J]. 中国电机工程学报, 2022, 42(增刊1): 106-114. Xiang Ying, Yan Huifeng, Yu Xuyang, et al. Non-invasive load identification based on feature optimization and improved self-organizing neural network[J]. Proceedings of the CSEE, 2022, 42(S1): 106-114.
[71] 池程芝, 潘震, 徐钊, 等. 基于多特征选择算法的功率变换器故障分类方法[J]. 西北工业大学学报, 2022, 40(3): 645-650. Chi Chengzhi, Pan Zhen, Xu Zhao, et al. Power converter fault classification method based on multi-feature selection algorithm[J]. Journal of Northwestern Polytechnical University, 2022, 40(3): 645-650.
[72] 赵耀, 沈翀, 李东东, 等. 极端条件下基于特征层面信号融合的电励磁双凸极电机匝间短路故障诊断[J]. 电工技术学报, 2023, 38(10): 2661-2674. Zhao Yao, Shen Chong, Li Dongdong, et al. Inter-turn short circuit diagnosis of wound-field doubly salient machine based on multi-signal fusion on feature level under extreme conditions[J]. Transactions of China Electrotechnical Society, 2023, 38(10): 2661-2674.
[73] 高晗, 蔡国伟, 杨德友, 等. 基于累积贡献率和可解释人工智能的静态电压稳定裕度估计特征量筛选方法[J]. 电力自动化设备, 2023, 43(4): 168-176. Gao Han, Cai Guowei, Yang Deyou, et al. Feature selection approach based on FCC-eAI in static voltage stability margin estimation[J]. Electric Power Automation Equipment, 2023, 43(4): 168-176.
[74] Yu Mingkai, Wang Jianxiao, Yan Jie, et al. Pricing information in smart grids: a quality-based data valuation paradigm[J]. IEEE Transactions on Smart Grid, 2022, 13(5): 3735-3747.
[75] 王小君, 窦嘉铭, 刘曌, 等. 可解释人工智能在电力系统中的应用综述与展望[J]. 电力系统自动化, 2024, 48(4): 169-191. Wang Xiaojun, Dou Jiaming, Liu Zhao, et al. Review and prospect of explainable artificial intelligence and its application in power systems[J]. Automation of Electric Power Systems, 2024, 48(4): 169-191.
[76] Beltrán S, Castro A, Irizar I, et al. Framework for collaborative intelligence in forecasting day-ahead electricity price[J]. Applied Energy, 2022, 306: 118049.
[77] Shen Xiaodong, Liu Huixin, Qiu Gao, et al. Interpretable interval prediction-based outlier-adaptive day-ahead electricity price forecasting involving cross-market features[J]. IEEE Transactions on Industrial Informatics, 2024, 20(5): 7124-7137.
[78] 杨佳泽, 王灿, 王增平. 新型电力系统背景下的智能负荷预测算法研究综述[J]. 华北电力大学学报(自然科学版), 2025, 52(3): 54-67. Yang Jiaze, Wang Can, Wang Zengping. A review of research on intelligent load forecasting algorithms in the context of new power systems[J]. Journal of North China Electric Power University (Natural Science Edition), , 2025, 52(3): 54-67.
[79] Shams Amiri S, Mottahedi S, Lee E R, et al. Peeking inside the black-box: explainable machine learning applied to household transportation energy consumption [J]. Computers, Environment and Urban Systems, 2021, 88: 101647.
[80] Chung W J, Liu Chunde. Analysis of input parameters for deep learning-based load prediction for office buildings in different climate zones using eXplainable Artificial Intelligence[J]. Energy and Buildings, 2022, 276: 112521.
[81] 余长青. 基于人工智能方法的风电消纳能力预测及消纳措施优化[D]. 重庆: 重庆大学, 2020. Yu Changqing. Prediction of wind power absorptive capacity and optimization of absorptive measures based on artificial intelligence method[D]. Chongqing: Chongqing University, 2020.
[82] 白玉莹. 计及风资源时空特征的风电功率超短期预测研究[D]. 吉林: 东北电力大学, 2021. Bai Yuying. Study on ultra-short-term forecast of wind power considering the temporal and spatial characteristics of wind resources[D]. Jilin: Northeast Dianli University, 2021.
[83] Chang Xiaomin, Li Wei, Ma Jin, et al. Interpretable machine learning in sustainable edge computing: a case study of short-term photovoltaic power output prediction[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 8981-8985.
[84] 蒋莹莹, 田建艳, 姬政雄, 等. 可解释性验证的光伏出力实时纠偏概率预测模型[J]. 高电压技术, 2024, 50(9): 3944-3954. Jiang Yingying, Tian Jianyan, Ji Zhengxiong, et al. Interpretability verification of real-time deviation correction probability prediction model of photovoltaic output[J]. High Voltage Engineering, 2024, 50(9): 3944-3954.
[85] Santos O L D, Dotta D, Wang Meng, et al. Performance analysis of a DNN classifier for power system events using an interpretability method[J]. International Journal of Electrical Power & Energy Systems, 2022, 136: 107594.
[86] Sairam S, Seshadhri S, Marafioti G, et al. Edge-based explainable fault detection systems for photovoltaic panels on edge nodes[J]. Renewable Energy, 2022, 185: 1425-1440.
[87] 吕云龙, 胡琴, 胡紫园, 等. 考虑样本不平衡条件下风机叶片覆冰诊断及其可解释性研究 [J]. 电工技术学报, 2025, 40(11): 3667-3679. Lü Yunlong, Hu Qin, Hu Ziyuan, et al. Diagnosis of wind turbine blade ice cover and its interpretability under sample imbalance[J]. Transactions of China Electrotechnical Society, 2025, 40(11): 3667-3679.
[88] 许格健. 电池储能系统典型单元运行状态参数预测方法研究[D]. 吉林: 东北电力大学, 2020. Xu Gejian. Study on prediction method of operating state parameters of typical cells in battery energy storage system[D]. Jilin: Northeast Dianli University, 2020.
[89] 吴洋, 辛茹, 邹文滔, 等. 提升电力现货市场出清结果可解释性的综合分析方法[J]. 南方电网技术, 2022, 16(6): 113-123. Wu Yang, Xin Ru, Zou Wentao, et al. Comprehensive analysis method for enhancing the explainability of electricity spot market clearing results[J]. Southern Power System Technology, 2022, 16(6): 113-123.
[90] 陈明昊, 朱月瑶, 孙毅, 等. 计及高渗透率光伏消纳与深度强化学习的综合能源系统预测调控[J]. 电工技术学报, 2024, 39(19): 6054-6071, 6103. Chen Minghao, Zhu Yueyao, Sun Yi, et al. The predictive-control optimization method for park integrated energy system considering the high penetration of photovoltaics and deep reinforcement learning[J]. Transactions of China Electrotechnical Society, 2024, 39(19): 6054-6071, 6103.
[91] Utama C, Meske C, Schneider J, et al. Reactive power control in photovoltaic systems through (explainable) artificial intelligence[J]. Applied Energy, 2022, 328: 120004.
[92] Zhang Ke, Zhang Jun, Xu Peidong, et al. Explainable AI in deep reinforcement learning models for power system emergency control[J]. IEEE Transactions on Computational Social Systems, 2022, 9(2): 419-427.
[93] 周挺, 杨军, 詹祥澎, 等. 一种数据驱动的暂态电压稳定评估方法及其可解释性研究[J]. 电网技术, 2021, 45(11): 4416-4425. Zhou Ting, Yang Jun, Zhan Xiangpeng, et al. Data-driven method and interpretability analysis for transient voltage stability assessment[J]. Power System Technology, 2021, 45(11): 4416-4425.
[94] 陈明华, 刘群英, 张家枢, 等. 基于XGBoost的电力系统暂态稳定预测方法[J]. 电网技术, 2020, 44(3): 1026-1034. Chen Minghua, Liu Qunying, Zhang Jiashu, et al. XGBoost-based algorithm for post-fault transient stability status prediction[J]. Power System Technology, 2020, 44(3): 1026-1034.
[95] 陈明华. 电力系统暂态稳定性智能评估方法研究[D]. 成都: 电子科技大学, 2019. Chen Minghua. Research on intelligent evaluation method of power system transient stability[D]. Chengdu: University of Electronic Science and Technology of China, 2019.
[96] Wang Jianxiao, Gao Feng, Zhou Yangze, et al. Data sharing in energy systems[J]. Advances in Applied Energy, 2023, 10: 100132.
[97] Pinson P, Han Liyang, Kazempour J. Regression markets and application to energy forecasting[J]. TOP, 2022, 30(3): 533-573.
[98] Li Chuang, He Aoli, Wen Yanhua, et al. Optimal trading mechanism based on differential privacy protection and Stackelberg game in big data market[J]. IEEE Transactions on Services Computing, 2023, 16(5): 3550-3563.
[99] 郭庆来, 王博弘, 田年丰, 等. 能源互联网数据交易: 架构与关键技术[J]. 电工技术学报, 2020, 35(11): 2285-2295. Guo Qinglai, Wang Bohong, Tian Nianfeng, et al. Data transactions in energy Internet: architecture and key technologies[J]. Transactions of China Electro-technical Society, 2020, 35(11): 2285-2295.
[100] Oh H, Park S, Lee G M, et al. Personal data trading scheme for data brokers in IoT data marketplaces[J]. IEEE Access, 2019, 7: 40120-40132.
[101] McMahan H B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[J/OL]. ArXiv, 2016: 1602. 05629. https://arxiv.org/abs/1602.05629v4.
[102] Dwork C. Differential privacy: a survey of results[C] //2008 International Conference on Theory and Applications of Models of Computation, Berlin, Heidelberg, 2008: 1-19.
[103] Bos J W, Castryck W, Iliashenko I, et al. Privacy-friendly forecasting for the smart grid using homomorphic encryption and the group method of datahandling[C]//International Conference on Cryptology in Africa, Dakar, Senegal, 2017: 184-201.
[104] Yao A C. Protocols for secure computations[C]//23rd Annual Symposium on Foundations of Computer Science, Chicago, IL, USA, 1982: 160-164.
[105] 许伦, 刘文杰, 李昀, 等. 零知识证明在新型电力系统中的应用分析及展望[J]. 中国电机工程学报, 2024, 44(增刊1): 114-130. Xu Lun, Liu Wenjie, Li Yun, et al. Application analysis and prospect of zero-knowledge proof in new power system[J]. Proceedings of the CSEE, 2024, 44(S1): 114-130.
[106] 凡航, 徐葳, 范晓昱, 等. 隐私计算在新型电力系统中的应用分析与展望[J]. 电力系统自动化, 2023, 47(19): 187-199. Fan Hang, Xu Wei, Fan Xiaoyu, et al. Application analysis and prospect of privacy-preserving computation in new power system[J]. Automation of Electric Power Systems, 2023, 47(19): 187-199.
[107] 陆俊, 肖琦, 龚钢军, 等. 基于动态差分隐私的联邦学习配电台区数据异常识别[J]. 电网技术, 2025, 49(8): 3512-3521.Lu Jun, Xiao Qi, Gong Gangjun, et al. Federated learning distribution station data anomaly identification based on dynamic differential privacy[J]. Power System Technology, 2025, 49(8): 3512-3521.
[108] 黎海涛, 刘伊然, 杨艳红, 等. 基于改进联邦竞争深度Q网络的多微网能量管理策略[J]. 电力系统自动化, 2024, 48(8): 174-184. Li Haitao, Liu Yiran, Yang Yanhong, et al. Energy management strategy for multi-microgrid based on improved federated dueling deep Q network[J]. Automation of Electric Power Systems, 2024, 48(8): 174-184.
[109] Wang Guan, Dang C X, Zhou Ziye. Measure contribution of participants in federated learning[C]// 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 2019: 2597-2604.
[110] Yoon J, Arik S O, Pfister T. Data valuation using reinforcement learning[EB/OL]. 2019: 1909.11671. https://arxiv.org/abs/1909.11671v1.
[111] Han Xiao, Wang Leye, Wu Junjie, et al. Data valuation for vertical federated learning: a model-free and privacy-preserving method[J/OL]. ArXiv, 2021: 2112. 08364. https://arxiv.org/abs/2112.08364v3.
[112] 王勇, 李国良, 李开宇. 联邦学习贡献评估综述[J]. 软件学报, 2023, 34(3): 1168-1192. Wang Yong, Li Guoliang, Li Kaiyu. Survey on contribution evaluation for federated learning[J]. Journal of Software, 2023, 34(3): 1168-1192.
[113] Zhang Jialun, Wang Yi, Hug G. Cost-oriented load forecasting[J]. Electric Power Systems Research, 2022, 205: 107723.
[114] 李达, 郭庆雷, 冯景丽. 基于区块链的分布式电力交易隐私结算模型[J]. 电网技术, 2023, 47(9): 3608-3624. Li Da, Guo Qinglei, Feng Jingli. Private settlement model of distributed power transactions based on blockchains[J]. Power System Technology, 2023, 47(9): 3608-3624.
[115] 凡航, 徐葳, 王倩雯, 等. 多方安全计算框架下的智能合约方法研究[J]. 信息安全研究, 2022, 8(10): 956-963. Fan Hang, Xu Wei, Wang Qianwen, et al. Research on smart contract method in the framework of secure multi-party computation[J]. Journal of Information Security Research, 2022, 8(10): 956-963.
[116] 李凤华, 李晖, 牛犇, 等. 数据要素流通与安全的研究范畴与未来发展趋势[J]. 通信学报, 2024, 45(5): 1-11. Li Fenghua, Li Hui, Niu Ben, et al. Research category and future development trend of data elements circulation and security[J]. Journal on Communications, 2024, 45(5): 1-11.
Abstract With the deep implementation of the “dual carbon” policy and the advancement of intelligent measurement technologies, the new power system is undergoing a transformation toward digital intelligence and low-carbon development. Power data assets play a pivotal role in this transition. For example, power grids leverage artificial intelligence and other advanced technologies to utilize load data for future load forecasting and economic dispatch, enabling cost savings. Additionally, power enterprises can package and trade data assets in data markets, where data providers obtain economic benefits, and data purchasers derive value from data products. However, despite the widespread recognition of data value in the power system, the inherent complexity of data assets and their dependency on specific application scenarios have hindered the development of universally accepted and reliable evaluation methods. The challenges restrict the circulation and deep utilization of power data, potentially impeding the green, low-carbon, and intelligent transformation of power systems.
To address these challenges, this paper constructs a research framework for evaluating the value realization of power data assets, structured around four key stages: data resourceization, assetization, commoditization, and capitalization. The paper systematically explores the critical issues at each stage and their relationship with data valuation. Furthermore, it reviews and analyzes existing valuation methodologies in power systems, including the three fundamental approaches, real options analysis, indicator-based evaluation, and impact-based methods, to provide solutions to key valuation challenges. The study also compares these methods in terms of their advantages, limitations, applicability, and practical application scenarios. Additionally, it categorizes data valuation applications in power systems from three perspectives: valuation objects, valuation stages, and functional applications. Specifically, the valuation stages include the individual and interaction stages; the valuation objects encompass datasets, features, and data products; and the functional applications cover decision support, information identification, model interpretability, profit distribution, and data transactions.
Based on the analysis of valuation methods and their current applications, this study further explores future directions and challenges in power data valuation. Key areas of focus include privacy-aware data value extraction, value distribution in federated learning, integrated valuation under predictive decision-making frameworks, data market pricing and transaction mechanisms, benefit distribution and regulatory oversight, and the development of data valuation platforms. By advancing the application of data valuation in data management, market transactions, data sharing, and model interpretability, this paper aims to unlock the full potential of power data, facilitate its efficient circulation, and promote the high-efficiency operation of power systems.
keywords:Data value, power systems, valuation methods, value mining
DOI: 10.19595/j.cnki.1000-6753.tces.250205
中图分类号:TM76
教育部人文社科基金资助项目(21YJAZH083)。
收稿日期 2025-02-11
改稿日期 2025-03-30
丁正凯 男,1996年生,博士研究生,研究方向为智能电网安全、大数据价值挖掘等。E-mail:15895190157@163.com
王蓓蓓 女,1979年生,副教授,博士生导师,研究方向为电力市场、需求侧管理等。E-mail:wangbeibei@seu.edu.cn(通信作者)
(编辑 赫 蕾)