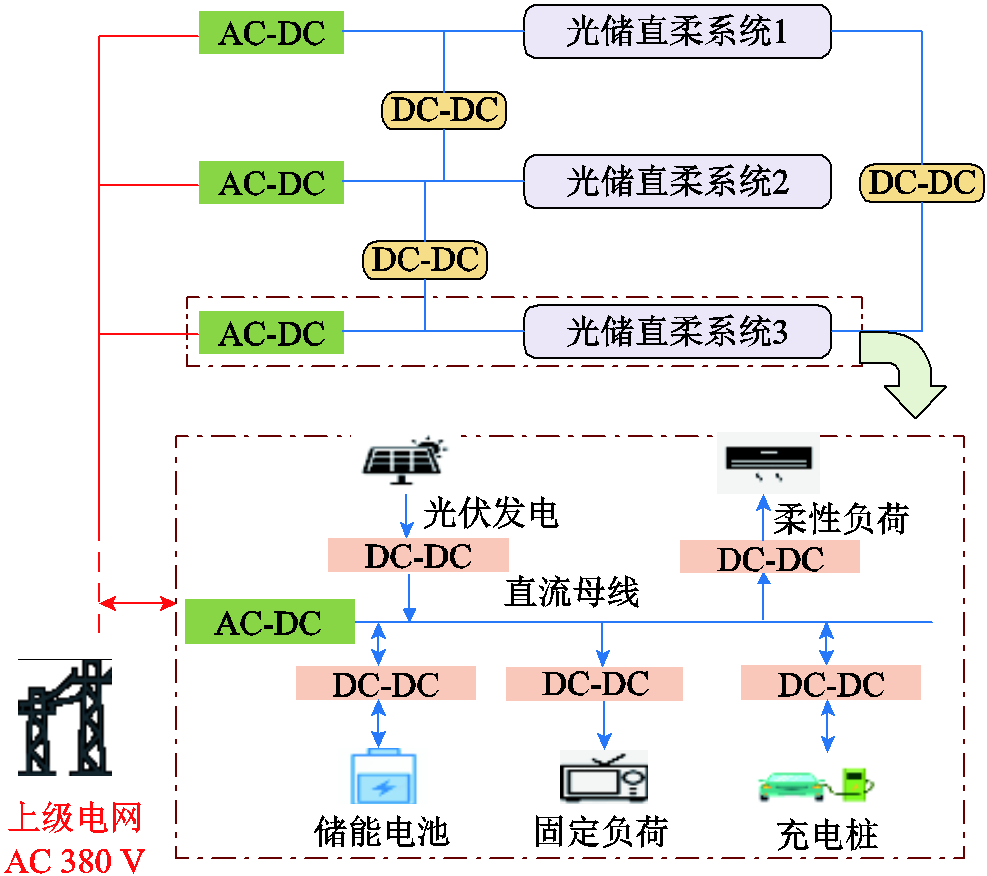
图1 MPEDF系统互联运行框架
Fig.1 Operating architecture of MPEDF System
摘要 为了提升多光储直柔(MPEDF)系统的功率互补性,降低系统运行成本,该文提出一种基于多智能体深度强化学习的MPEDF系统协同优化调度策略。首先,通过电压信号指导柔性设备进行功率调节,实现单个系统功率调度,在此基础上,利用系统间联络线两端电压差作为功率交互信号,提出MPEDF系统的功率交互策略;其次,以系统运行成本最低为目标建立MPEDF系统的优化调度模型,为满足数据隐私保护和适应各系统运行特性的能力,使用多智能体深度强化学习对模型进行求解;然后,针对多智能体系统中智能体间信息交互的延迟问题,采用延迟感知多智能体近端策略优化深度强化学习算法,该算法通过引入延迟感知马尔可夫过程,扩展状态空间,有效地降低了各智能体信息交互的延迟,提升了求解效率;最后,通过算例对比与分析检验了该文所建立模型与所用算法的有效性和优越性。
关键词:多光储直柔系统 深度强化学习 功率交互 优化调度 延迟感知多智能体
为响应“双碳”目标,我国正加速构建以新能源为核心的新型电力系统。然而分布式光伏电源的大量接入,其波动性和间歇性给新型电力系统带来许多问题[1],导致传统“源随荷动”的调节模式已无法满足调节需求。同时,在应用广泛的交流配电系统中,分布式光伏、储能电池、电动汽车(Electric Vehicle, EV)等直流设备与直流负载进行功率互动时,直-交流转换产生的电能损耗问题凸显[2]。在此背景下,新型的光储直柔系统得到快速发展。光储直柔系统集成光伏发电、储能装置、直流配电和柔性交互四项技术,通过柔性交互实现“源荷双向互动”,利用直流配电解决交直转换过程中的能源损耗问题[3]。对光储直柔系统进行优化调度是实现光储直柔系统高效运行和柔性用电的关键。
当前针对光储直柔系统优化调度的研究还处于起步阶段。文献[4]基于温度、实时用电功率提出了一种光储直柔系统能量管理策略,实现了有效的光伏消纳和源荷互动,降低系统运行成本;文献[5]设计了一种光储直柔系统运行框架,为用户提供灵活操作的意愿选择,通过深度强化学习进行用能控制,在保证用户满意度的同时有效地提高了光伏消纳,降低了对储能电池和上级电网的依赖。光储直柔系统不仅可独立运行,而且同一配电区域内还可通过多个光储直柔系统的功率互联进一步挖掘柔性资源调度潜力。文献[6]中提出一种多光储直柔(Multiple Photovoltaic, Energy storage, Direct current, Flexibility, MPEDF)系统微电网的互联互通概念,利用系统间联络线两端电压信号控制功率传输,通过功率交互在不增加系统冗余备用容量的前提下,提高供电可靠性。MPEDF系统通过功率和信息互动,可提高各系统功率互补性,减少系统对上级电网的依赖[7]。然而,目前尚未对MPEDF系统的协同优化调度开展研究。
由于需要考虑各光储直柔系统之间的功率交互和协同控制,并包含具有较强不确定性的光伏发电,使得MPEDF系统优化模型的复杂度显著增高。若采用常规的基于数学模型的鲁棒优化、随机优化或动态规划等方法求解,会面临求解效率低下或病态无解等问题[8-9]。由于深度强化学习(Deep Reinforcement Learning, DRL)具有无模型学习和可灵活响应时变环境的特点,所以非常适合解决光储直柔系统优化调度问题[5]。然而,常规单智能体DRL属于集中式优化方法,若用于处理MPEDF这类多主体系统的优化问题,则会因动作和状态空间维度过高而导致收敛性较差。鉴于多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning, MADRL)可依据特定的奖惩机制,通过智能体相互间的信息交流高效达到全局最优,目前已有较多研究将MADRL应用于解决多主体系统优化问题。文献[10]提出一种带注意力机制的可扩展MADRL算法,实现多区域商业暖通空调控制问题的高效求解;文献[11]使用多智能体深度强化学习算法对多微电网-配电网双层协同调度模型进行求解,在保护各利益主体隐私的同时降低各主体运营成本。然而,在多智能体系统中,一个智能体的动作延迟可能会对其他智能体的观察和动作产生影响,导致求解效率低下,求解结果不准确。针对上述问题,文献[12]为解决多智能体强化学习智能体间的延迟问题,提出了延迟感知马尔可夫过程;文献[13]考虑延迟感知马尔可夫过程,对多智能体近端策略优化深度强化学习算法进行改进,通过延迟动作信息扩展状态空间,并改进策略梯度公式,提出了延迟感知多智能体近端策略优化深度强化学习算法(Delay-Aware Multi-Agent Proximal Policy Optimization, DA-MAPPO)。
综上所述,为实现MPEDF系统的高效运行,本文基于直流母线电压调控方法构建MPEDF系统优化调度模型。鉴于多智能体系统中智能体信息交互延迟问题,使用DA-MAPPO算法对MPEDF系统优化调度模型进行训练。通过训练好的模型实时决策,再进行模型对比和算法对比,验证本文所构建模型和所用算法的优越性。
MPEDF系统互联运行框架如图1所示。其中,每个系统中的能源供给包括上级电网、光伏(Photovoltaic, PV),柔性设备包括电动汽车充电站、储电设备(Battery Energy Storage, BES)。各系统电压等级相同,负荷为不可调负荷和柔性负荷。上级电网通过AC-DC转换器将电能输入光储直柔系统,同时各个光储直柔系统之间通过联络线互联互通,联络线通过DC-DC转换器连接两端光储直柔系统直流母线,转换器内的调控逻辑决定能量交互机制。
图1 MPEDF系统互联运行框架
Fig.1 Operating architecture of MPEDF System
在直流系统中,柔性设备功率与直流母线电压存在直接耦合关系,当系统运行在额定电压±10%的范围内时,直流设备功率随电压响应特性呈线性关系[5]。系统中柔性可调节负荷模型对直流母线电压信号响应为
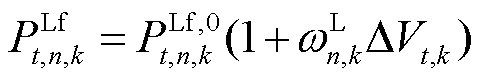 (1)
(1)
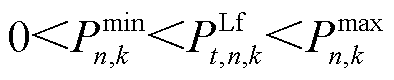 (2)
(2)
式中,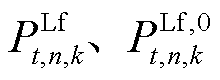 分别为光储直柔系统k在t时段第n类型负荷的调节后功率和调节前功率;
分别为光储直柔系统k在t时段第n类型负荷的调节后功率和调节前功率;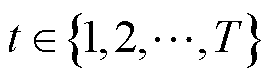 ,T为功率调整的总时段;
,T为功率调整的总时段;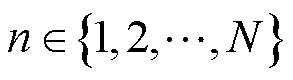 ,N为负荷类型总数;
,N为负荷类型总数;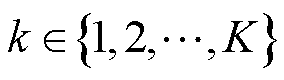 ,K为系统总数;
,K为系统总数;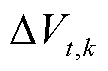 为光储直柔系统k在t时段直流母线电压偏差;
为光储直柔系统k在t时段直流母线电压偏差;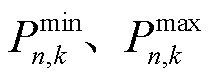 分别为第n类型负荷的功率下限、上限;
分别为第n类型负荷的功率下限、上限;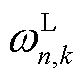 为光储直柔系统k的第n种负荷的柔性系数,有
为光储直柔系统k的第n种负荷的柔性系数,有
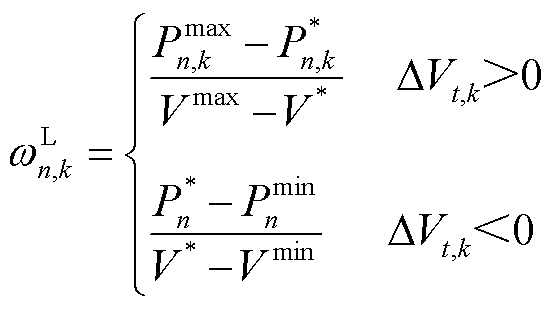 (3)
(3)
式中,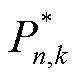 为系统k第n种柔性负荷不进行功率调节时的额定功率;
为系统k第n种柔性负荷不进行功率调节时的额定功率;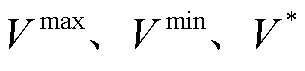 分别为直流母线电压的最大值、最小值和额定电压。
分别为直流母线电压的最大值、最小值和额定电压。
储能电池实时电量是电池充放电能力的重要指标,通常使用荷电状态(State of Charge, SOC)来描述[14],即
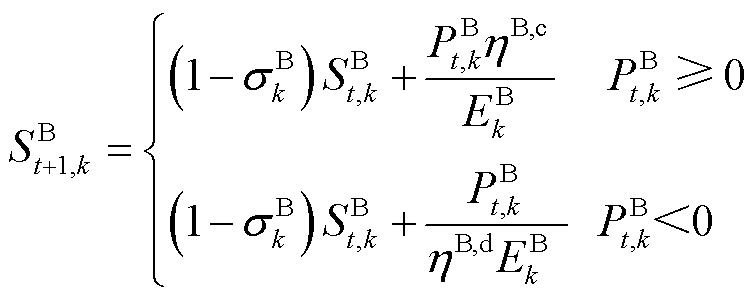 (4)
(4)
式中,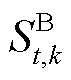 、
、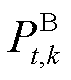 分别为系统k中BES在t时段的荷电状态、出力;
分别为系统k中BES在t时段的荷电状态、出力;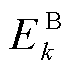 、
、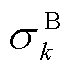 分别为系统k中BES的额定容量、自损耗系数;
分别为系统k中BES的额定容量、自损耗系数;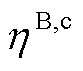 、
、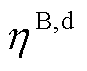 分别为BES充、放电系数。
分别为BES充、放电系数。
BES充放电功率随直流母线电压信号响应为
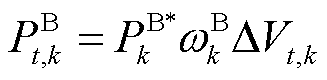 (5)
(5)
BES充放电功率约束为
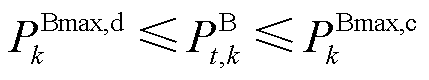 (6)
(6)
BES充放电爬坡约束为
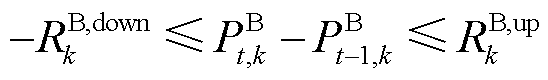 (7)
(7)
BES荷电状态约束为
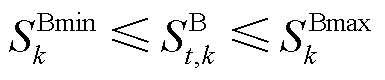 (8)
(8)
式中,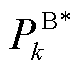 为系统k在t时段储能电池设置的额定充放电功率;
为系统k在t时段储能电池设置的额定充放电功率;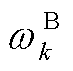 为系统k储能电池的柔性系数;
为系统k储能电池的柔性系数;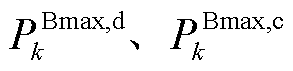 分别为系统k储能电池的最大放电功率、最大充电功率;
分别为系统k储能电池的最大放电功率、最大充电功率;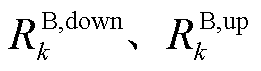 分别为系统k储能电池的滑坡限值和爬坡限值;
分别为系统k储能电池的滑坡限值和爬坡限值;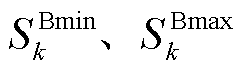 分别为系统k储能电池设定的容量下限和容量上限。
分别为系统k储能电池设定的容量下限和容量上限。
一般而言,用户会选择在一天内各时段最后一次出行的结束时刻作为起始充电时刻[15]。文献[16]通过拟合大量车辆出行数据,得到汽车最后一次出行结束时刻(可作为EV充电初始时刻)近似满足式(9)所示的正态分布。
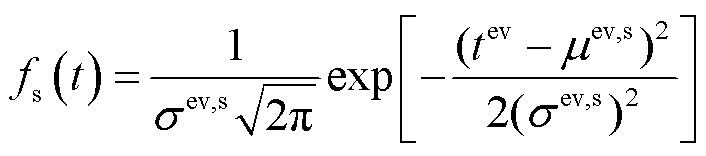 (9)
(9)
式中,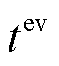 为EV到达PEDF系统的时间;
为EV到达PEDF系统的时间;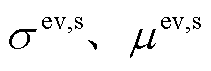 分别为EV到达时间拟合函数标准差和均值。
分别为EV到达时间拟合函数标准差和均值。
与起始充电时刻类似,EV日行驶路程符合高斯分布特征,其分布密度函数[17]为
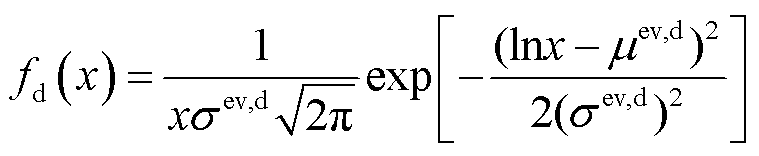 (10)
(10)
式中,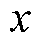 为日行驶路程;
为日行驶路程;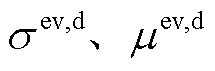 分别为日行驶路程的标准差和均值。
分别为日行驶路程的标准差和均值。
EV充电时长由起止SOC值决定,即
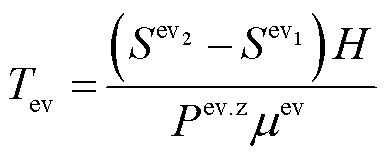 (11)
(11)
式中,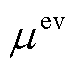 为充电效率;
为充电效率;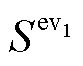 、
、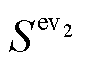 分别为EV充电前、后的SOC;H为EV的容量;
分别为EV充电前、后的SOC;H为EV的容量; 为充电桩功率。
为充电桩功率。
EV充电后的实际SOC,与初始SOC和EV日行驶里程相关,有
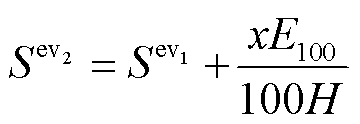 (12)
(12)
式中,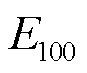 为EV每行驶100 km所需电量。
为EV每行驶100 km所需电量。
基于上述EV模型,本文应用蒙特卡洛法模拟MPEDF系统中EV无序充电负荷需求。
在光储直柔系统中,当电动汽车SOC未达到EV用户设定的最低容量时,该充电桩以额定功率对电动汽车进行充电;当EV的SOC高于设定容量时,该充电桩和电动汽车可视为一个储能电池,EV用户的设定最低容量由蒙特卡洛模拟结果决定。
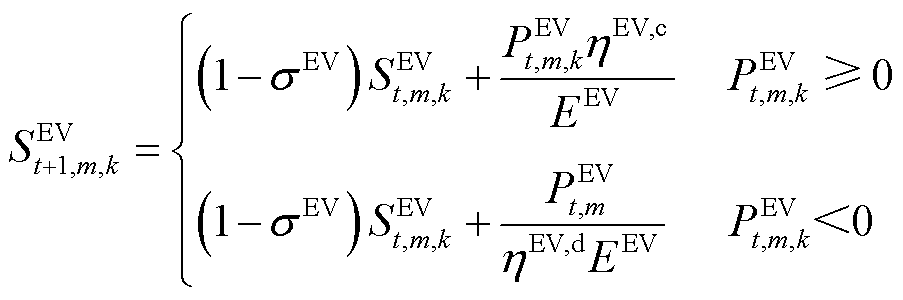 (13)
(13)
式中,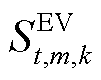 为系统k中第m辆EV在t时段的荷电状态;
为系统k中第m辆EV在t时段的荷电状态;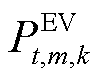 为系统k中第m辆EV在t时段的充放电功率;
为系统k中第m辆EV在t时段的充放电功率;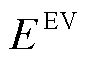 为EV的额定容量;
为EV的额定容量;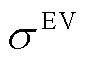 为EV的自损耗系数;
为EV的自损耗系数;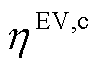 、
、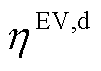 分别为EV充、放电系数;
分别为EV充、放电系数;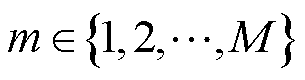 ,M为电动汽车总数。
,M为电动汽车总数。
电动汽车充放电功率随直流母线电压信号变化的响应为
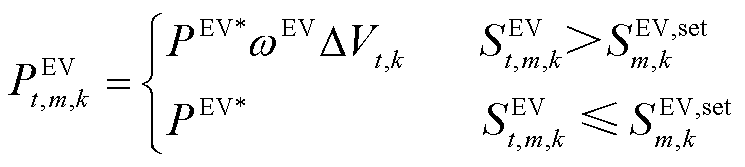 (14)
(14)
式中,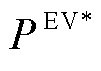 为EV的额定充放电功率;
为EV的额定充放电功率;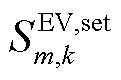 为系统k第m辆电动汽车用户设定的最低需求荷电状态。
为系统k第m辆电动汽车用户设定的最低需求荷电状态。
EV充放电功率约束为
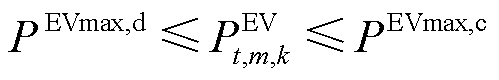 (15)
(15)
EV充放电爬坡约束为
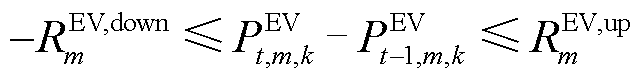 (16)
(16)
EV荷电状态约束为
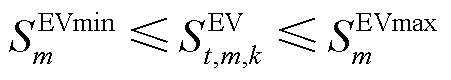 (17)
(17)
式中,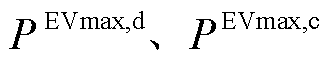 分别为EV的最大放电、充电功率;
分别为EV的最大放电、充电功率;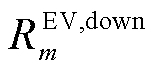 、
、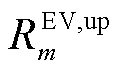 分别为第m辆电动汽车电池的滑坡限值和爬坡限值;
分别为第m辆电动汽车电池的滑坡限值和爬坡限值;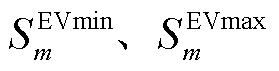 分别为第m辆车的最低、最高荷电状态。
分别为第m辆车的最低、最高荷电状态。
直流母线电压偏差作为可调节设备功率的调节信号:当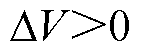 时,能源供给侧功率大于需求侧功率,适当增大各设备用电功率;当
时,能源供给侧功率大于需求侧功率,适当增大各设备用电功率;当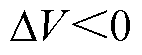 时,供给侧功率不足,适当降低各设备用电功率。各类型负载功率、蓄电池和电动汽车充放电功率根据直流母线信号与对应的设备运行策略调节自身功率。
时,供给侧功率不足,适当降低各设备用电功率。各类型负载功率、蓄电池和电动汽车充放电功率根据直流母线信号与对应的设备运行策略调节自身功率。
系统k功率平衡方程为
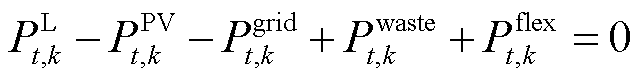 (18)
(18)
式中,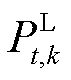 为t时段所有负荷总和;
为t时段所有负荷总和;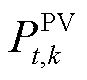 为t时段光伏功率;
为t时段光伏功率;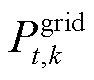 为t时段系统从电网取电功率;
为t时段系统从电网取电功率;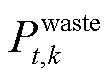 为t时段弃光功率;
为t时段弃光功率;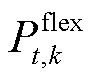 为柔性设备调节功率。
为柔性设备调节功率。
柔性设备的可调功率为
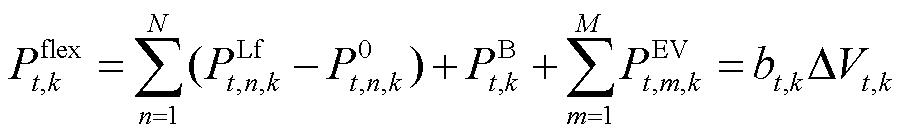 (19)
(19)
由式(1)、式(5)和式(14)可知式(19)中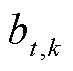 为t时段系统k直流母线所连接负载决定的参数。
为t时段系统k直流母线所连接负载决定的参数。
为提高光伏消纳,降低对外部电网取电的依赖,本文尽可能使调节功率等于系统需求功率,即
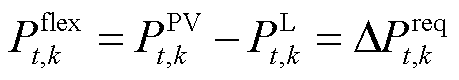 (20)
(20)
式中,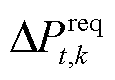 为系统k在t时段所需功率。
为系统k在t时段所需功率。
当系统运行条件满足式(20),即刚性负荷和柔性设备的调节总功率等于系统需求调节功率时,联立式(19)和式(20)得
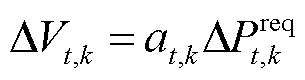 (21)
(21)
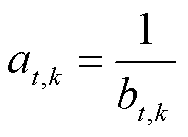 (22)
(22)
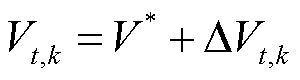 (23)
(23)
式中,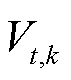 为t时段光储直柔系统k的直流母线电压;
为t时段光储直柔系统k的直流母线电压;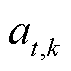 为t时段系统k电压增益系数。该时段的光储直柔系统视为零碳系统,且弃光为0。
为t时段系统k电压增益系数。该时段的光储直柔系统视为零碳系统,且弃光为0。
当系统调节功率无法满足式(20)时,式(22)将不成立,此时通过式(17)计算电压差信号,利用该信号对系统柔性设备进行功率调节。因此,本文通过优化每个调度时刻的,得到光储直柔系统柔性设备的功率调整方案,实现系统经济运行。
上述电压信号控制功率过程如图2所示。
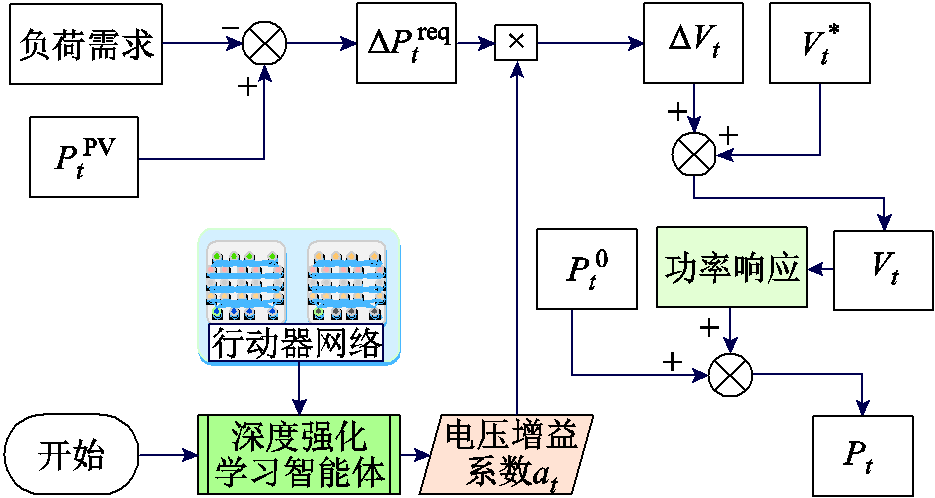
图2 电压信号控制功率过程
Fig.2 Voltage signal controls power process
如图1所示,该区域内各光储直柔系统通过AC-DC接入上级电网。当系统间电压差超过预定设定值时,则开通联络线的DC-DC开关,从高电压系统向低电压系统传输功率。传输功率由两端的电压差决定,电压差值越高,传输功率越大。当发生功率交互时,令提供功率系统为k1,接收功率系统为k2,如果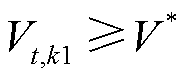 、
、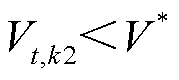 且
且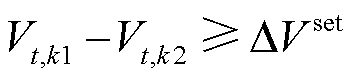 ,则功率传输模型为
,则功率传输模型为
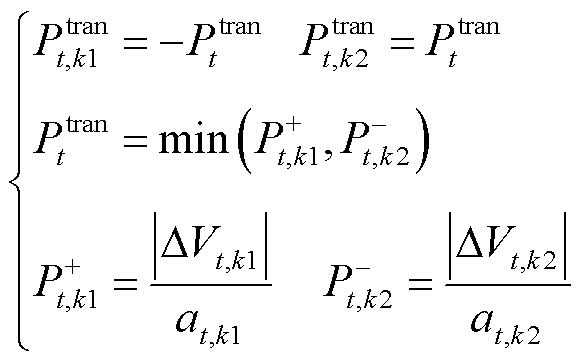 (24)
(24)
式中,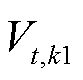 、
、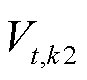 分别为t时段光储直柔系统k1和k2的直流母线电压;
分别为t时段光储直柔系统k1和k2的直流母线电压;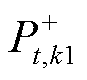 为系统k1可提供的功率余量;
为系统k1可提供的功率余量;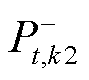 为系统k2所需求的功率;
为系统k2所需求的功率;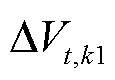 、
、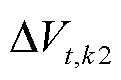 分别为系统k1、k2的直流母线电压偏差;
分别为系统k1、k2的直流母线电压偏差;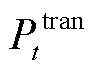 为光储直柔系统k1向系统k2的供电功率;
为光储直柔系统k1向系统k2的供电功率;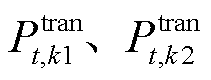 分别为系统k1、k2互联后功率变化。
分别为系统k1、k2互联后功率变化。
当功率交互完成后,系统互相独立,再进行设备功率调节,此时的系统功率需求为
 (25)
(25)
式中,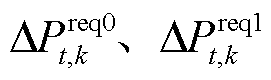 分别为t时段发生功率交互前后系统k的功率调节需求;
分别为t时段发生功率交互前后系统k的功率调节需求;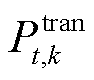 为系统k与其他系统功率交互总和。
为系统k与其他系统功率交互总和。
用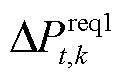 替换式(21)中的
替换式(21)中的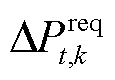 ,此时柔性设备的功率调节的电压差信号为
,此时柔性设备的功率调节的电压差信号为
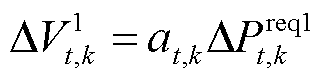 (26)
(26)
本文以MPEDF系统运行成本最低为目标,建立优化调度目标函数,有
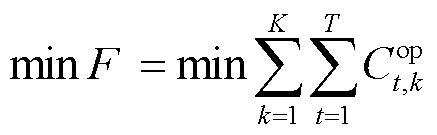 (27)
(27)
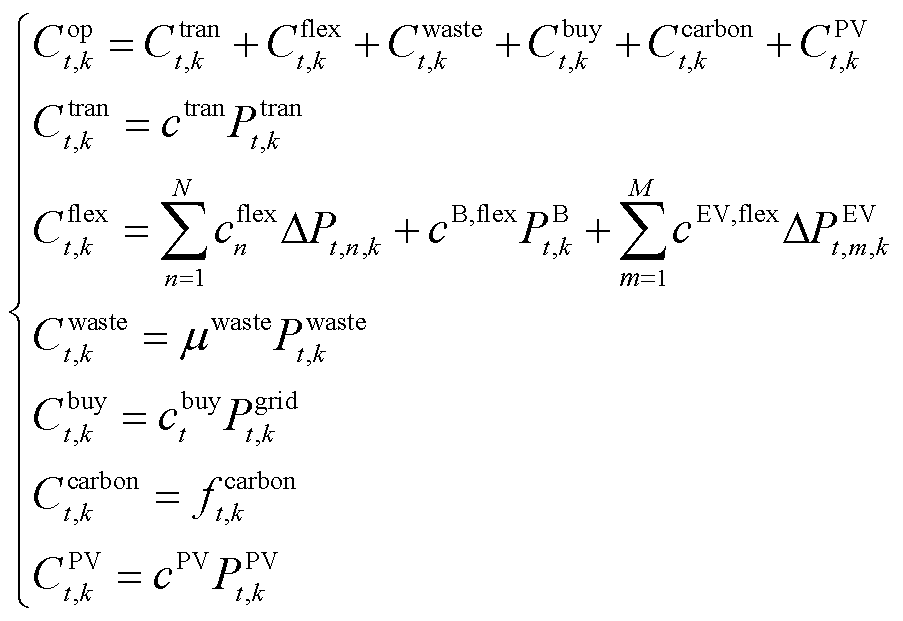 (28)
(28)
式中,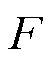 为MPEDF系统总运行成本;
为MPEDF系统总运行成本;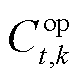 为系统k在t时段运行成本;
为系统k在t时段运行成本;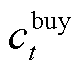 为t时段购电电价;
为t时段购电电价;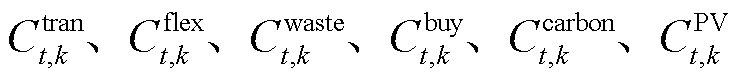 分别为系统k在t时段功率传输成本、柔性设备功率调度成本、弃光惩罚成本、购电成本、碳排放成本、光伏发电成本;
分别为系统k在t时段功率传输成本、柔性设备功率调度成本、弃光惩罚成本、购电成本、碳排放成本、光伏发电成本;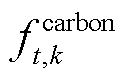 为系统k在时段碳交易成本;
为系统k在时段碳交易成本;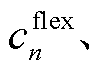
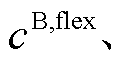
 分别为第n类型负荷的调度成本系数、储能电池调度成本系数、电动汽车调度成本系数、弃光惩罚系数、光伏单位发电维护成本、功率交互电价。
分别为第n类型负荷的调度成本系数、储能电池调度成本系数、电动汽车调度成本系数、弃光惩罚系数、光伏单位发电维护成本、功率交互电价。
本文中碳配额采取无偿分配,碳配额分配对象为上级电网购电。当系统实际排放量与配额差值超过设定阈值时,碳交易成本将按阶梯电价原理递增,详细建模方法参照文献[18]。
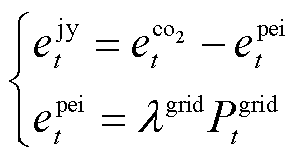 (29)
(29)
式中,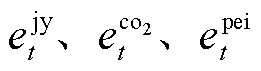 分别为t时段系统的总碳配额、总碳排放量、碳配额;
分别为t时段系统的总碳配额、总碳排放量、碳配额;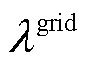 为上级电网购电的单位供电碳配额。
为上级电网购电的单位供电碳配额。
MAPPO算法是在PPO算法的基础上,对其中涉及的行动器-评判器框架进行改进。该算法使用集中式训练、分布式执行(Centralized Training and Decentralized Execution, CTDE)的机制,解决了行动器-评判器单独工作带来的潜在不稳定性和恶性竞争,避免了通信负担过大和隐私泄露的问题,减少了通信开销和计算负载。在训练阶段,集中式训练利用一个中心化的神经网络收集所有智能体的经验数据,并更新全局策略。训练完成后,每个智能体仅依据本地信息做出最优决策。而在多智能体强化学习中,经常存在动作执行延迟产生的时延问题,可能会导致策略失稳与系统发散,降低系统整体性能。为解决上述问题,本文采用延迟感知的多智能体近端策略优化算法对模型进行求解。
现有的马尔可夫决策模型在存在延迟的环境下经常出现系统不协调等问题。T. J. Walsh等采用一种扩展状态空间的方法重新定义了马尔可夫决策过程[12]。这种具有动作延迟的马尔可夫过程可通过扩展状态空间的方法转换为普通马尔可夫决策过程,则t时段扩展状态空间为
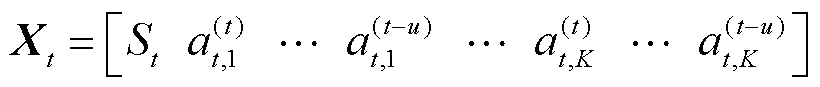 (30)
(30)
式中,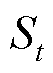 为普通状态空间;
为普通状态空间;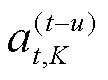 为t时段第K个智能体动作考虑延迟u步动作信息。
为t时段第K个智能体动作考虑延迟u步动作信息。
第t时段的智能体动作空间为
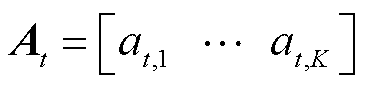 (31)
(31)
式中,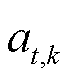 为系统k在t时段的电压增益系数,用以表示t时段第k个智能体的动作,本文模型中对应的为统一值。
为系统k在t时段的电压增益系数,用以表示t时段第k个智能体的动作,本文模型中对应的为统一值。
根据上述扩展状态空间和动作空间集合,修正状态转移概率分布为
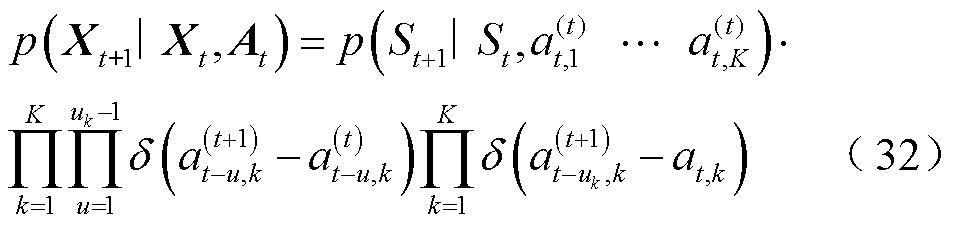
式中,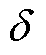 为二元函数;
为二元函数;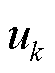 为第k个智能体的延迟步数;
为第k个智能体的延迟步数;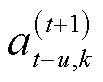 为第t+1时刻第k个智能体延迟u步动作,当k=u时,函数值为1,k≠u时,函数值为0;p为概率分布。
为第t+1时刻第k个智能体延迟u步动作,当k=u时,函数值为1,k≠u时,函数值为0;p为概率分布。
通过改进状态转移概率分布得到考虑延迟信息时下一时刻的状态,从而构建延迟感知马尔可夫过程。本文利用上述方法改进MAPPO算法,提出了DA-MAPPO算法。DA-MAPPO在CTDE框架内采用中心化的价值函数方法,允许单个PPO智能体通过全局价值函数进行协作。DA-MAPPO策略梯度更新公式为
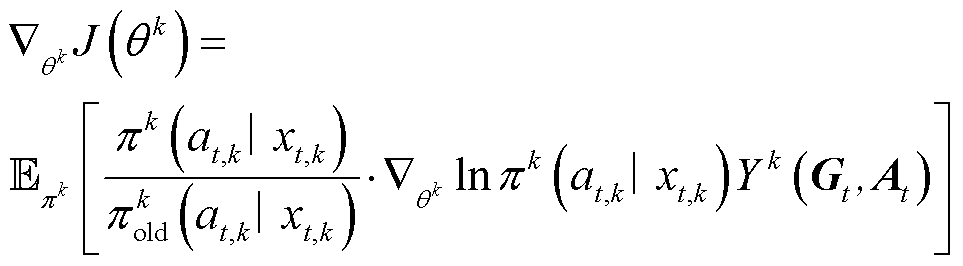 (33)
(33)
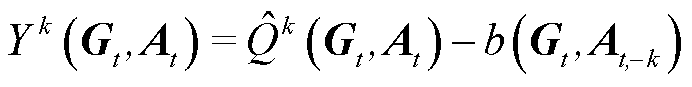 (34)
(34)
式中,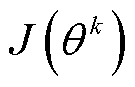 为智能体k策略参数
为智能体k策略参数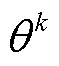 的梯度;
的梯度;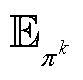 为在当前
为在当前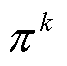 策略下,对所有样本的期望;
策略下,对所有样本的期望;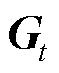 为全局状态空间,
为全局状态空间,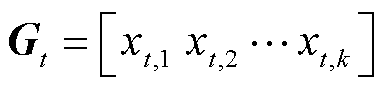 ;
;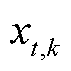 为智能体k在t时段的扩展空间;
为智能体k在t时段的扩展空间;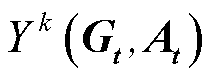 为基于目标价值函数的最优策略函数;
为基于目标价值函数的最优策略函数;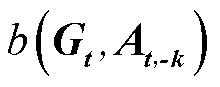 为估值基准,通常为状态值函数或其他智能体动作的依赖项,用于减少方差;
为估值基准,通常为状态值函数或其他智能体动作的依赖项,用于减少方差;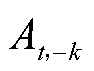 为除k外其他智能体的动作;
为除k外其他智能体的动作;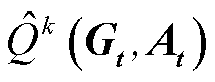 为
为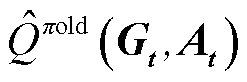 的估计值,
的估计值,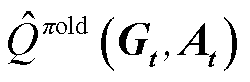 为在上一策略下的期望累计回报;
为在上一策略下的期望累计回报;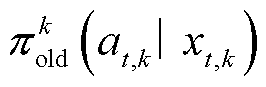 为智能体k上一策略在考虑延迟信息的扩展状态空间
为智能体k上一策略在考虑延迟信息的扩展状态空间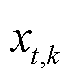 下选择动作的概率;
下选择动作的概率;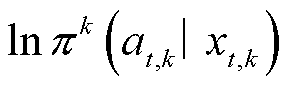 为智能体k策略在考虑延迟信息的扩展状态空间下选择动作的对数概率。
为智能体k策略在考虑延迟信息的扩展状态空间下选择动作的对数概率。
通过式(33)更新智能体的策略参数,使其在延迟环境中选择的动作更有利于最大化长期奖励。
评判网络(Critic Network)和行动网络(Actor Network)损失函数分别更新为
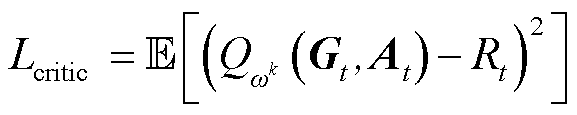 (35)
(35)
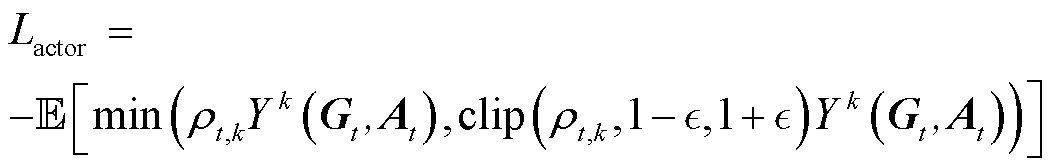 (36)
(36)
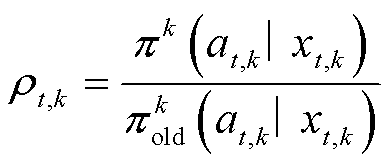 (37)
(37)
式中,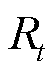 为从时间步长t开始的奖励;
为从时间步长t开始的奖励;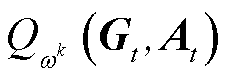 为评判器网络对动作价值函数的估计;
为评判器网络对动作价值函数的估计;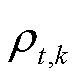 为策略更新的重要抽样比;
为策略更新的重要抽样比;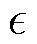 为裁剪参数;
为裁剪参数;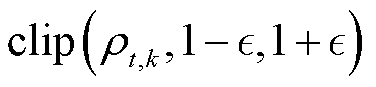 为裁断函数,限制重要性采样比率在
为裁断函数,限制重要性采样比率在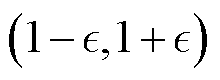 内。
内。
结合MPEDF系统优化调度环境的DA-MAPPO算法具体更新过程如图3所示。
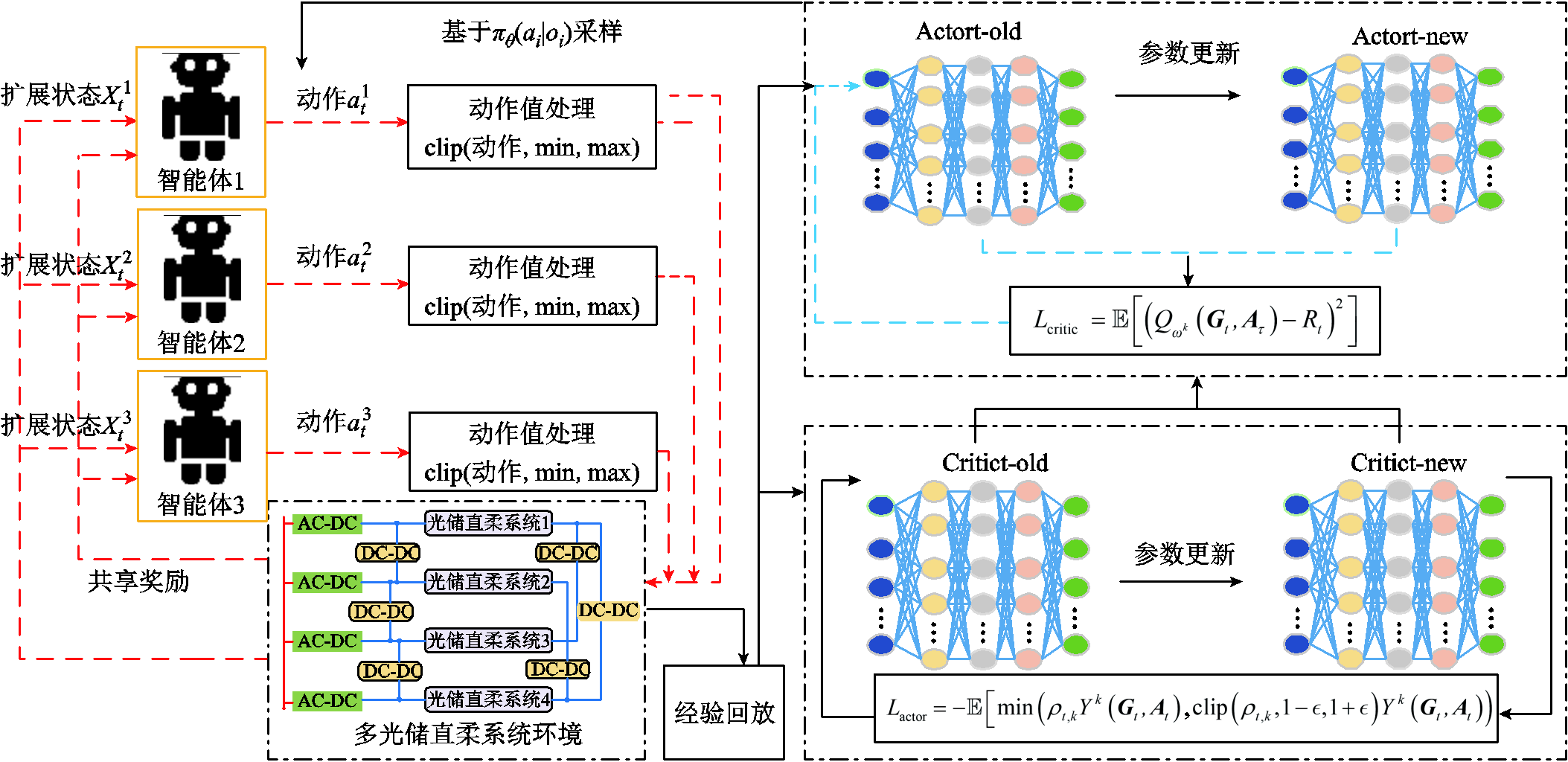
图3 基于DA-MAPPO算法的MPEDF系统优化调度策略框架
Fig.3 Economic dispatch strategy framework for MPEDF system based on DA-MAPPO
鉴于优化调度模型以各系统运行成本最小化为优化目标,而智能体通过环境交互获取奖励信号,实现回报最大化,强化学习的奖励函数构建为
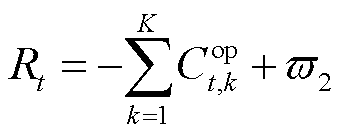 (38)
(38)
式中,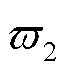 为对奖励函数回归正值的参数。
为对奖励函数回归正值的参数。
在实际运行阶段,每个智能体只能基于本地局部观测产生动作。单个系统中状态空间包括下一时刻的总负荷、光伏功率、储能充放电功率、电动汽车充放电功率、储能荷电状态、电动汽车荷电状态、电价、取电功率。
考虑延迟动作信息的扩展状态空间设计为
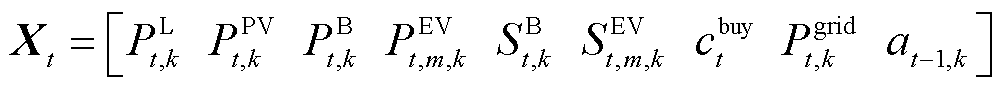 (39)
(39)
以上状态空间为各系统隐私空间,不参与信息共享,而参与信息共享决定联络线开关的仅有各系统直流母线电压数据。
本文使用DA-MAPPO对MPEDF系统优化调度模型进行训练,训练过程见表1。
表1 训练过程
Tab.1 Training process

步骤内容 1)根据建立MPEDF系统环境。 2)离线训练: (1)初始化环境模型X0,初始化神经网络参数,设置迭代次数O,经验池最大样本数I,给定所需训练数据。 (2)for o=1to O do从MPEDF环境中获取初始状态X0。for i=1 to I dofor t=1 to T do①将扩展状态Xt输入到DA-MAPPO算法智能体中。②智能体基于MPEDF环境状态,给定动作At。③动作At输入环境,环境基于At更新下一时刻状态Xt+1,并给出t时段奖励值Rt。④将(Xt,At, Xt+1, Rt)存入经验池中。End End 智能体通过经验池采样,获取(Xt,At,Xt+1, Rt)更新神经网络参数。End
在离线训练阶段完成后,部署DRL框架至实时调度系统。在线运行时,通过预测得到系统t时段光伏、负荷和系统的状态,随后将该信息输入训练完成的决策网络,通过Q值函数最大化策略,生成最优调度方案。
在此应用本文所提方法针对如图1所建立的MPEDF系统进行仿真分析。MPEDF系统内各单元参数见表2,系统从上级电网购电的分时电价格见表3。其中三个光储直柔系统的EV数量分别设为180、60和90辆,各系统的EV充电模型参数(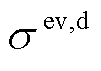 ,
, 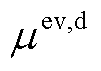 )分别为(12.05, 5.26)、(18.82, 3.61)和(10.23, 6.07)。各系统三类柔性负荷参与优化调度,充电桩充电功率上限为2 kW。系统直流母线电压上限为800 V,下限为670 V,额定电压为750 V;联络线两端电压差
)分别为(12.05, 5.26)、(18.82, 3.61)和(10.23, 6.07)。各系统三类柔性负荷参与优化调度,充电桩充电功率上限为2 kW。系统直流母线电压上限为800 V,下限为670 V,额定电压为750 V;联络线两端电压差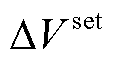 设置不宜过大(会导致各系统间功率互济功能降低而增加系统运行成本),也不宜过小(会导致联络线动作过于频繁而功率交互总成本增加),通过对比不同设置下的优化结果,本文最终设=10 V。强化学习奖励折扣因子、神经网络隐藏层数和学习率分别设置为0.9、3和0.000 3。算例仿真硬件为Intel i7-12700H处理器。本文算法和训练基于百度飞桨平台进行搭建。
设置不宜过大(会导致各系统间功率互济功能降低而增加系统运行成本),也不宜过小(会导致联络线动作过于频繁而功率交互总成本增加),通过对比不同设置下的优化结果,本文最终设=10 V。强化学习奖励折扣因子、神经网络隐藏层数和学习率分别设置为0.9、3和0.000 3。算例仿真硬件为Intel i7-12700H处理器。本文算法和训练基于百度飞桨平台进行搭建。
表2 各单元参数
Tab.2 The unit parameters
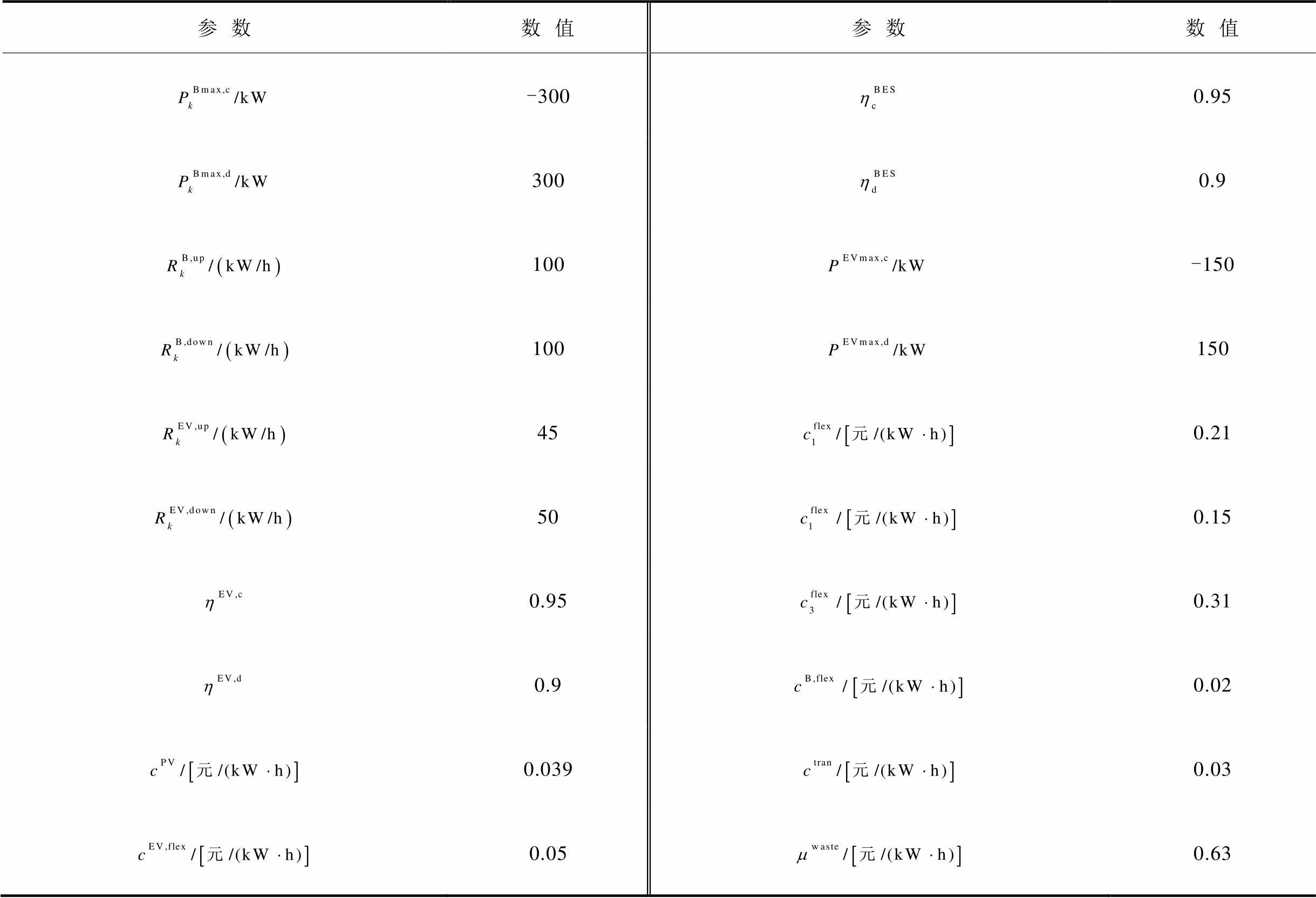
参数数值参数数值 -3000.95 3000.9 100-150 100150 450.21 500.15 0.950.31 0.90.02 0.0390.03 0.050.63
表3 分时电价
Tab.3 Time of use electricity prices

时段时刻电价/[元/(kW·h)] 峰时段8:00—12:00,18:00—22:000.97 平时段7:00,13:00—17:000.63 谷时段1:00—6:00,23:00—24:000.295
各系统光伏、负荷预测数据如图4所示。各系统电动汽车功率需求如图5所示。
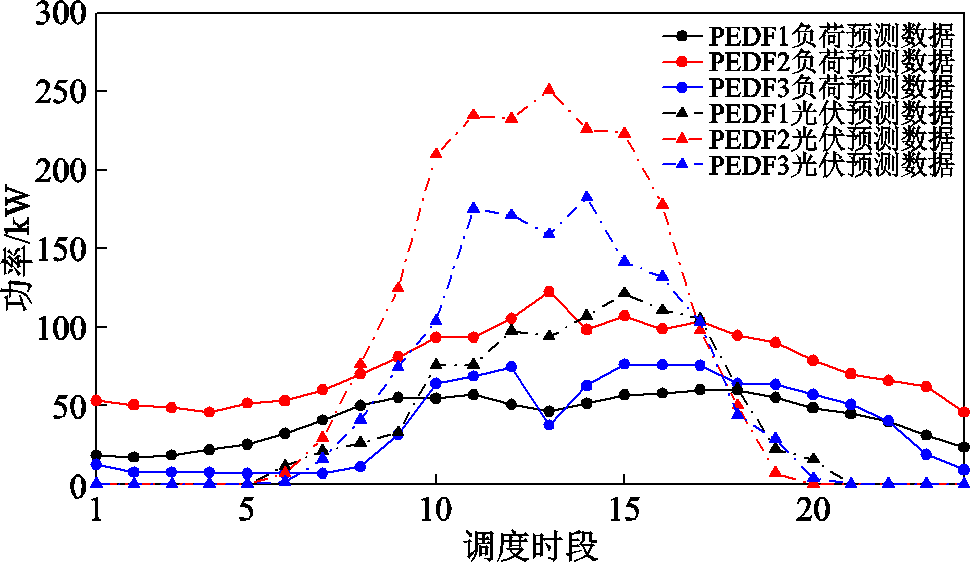
图4 PEDF光伏、负荷预测曲线
Fig.4 PEDF photovoltaic and load forecasting curves
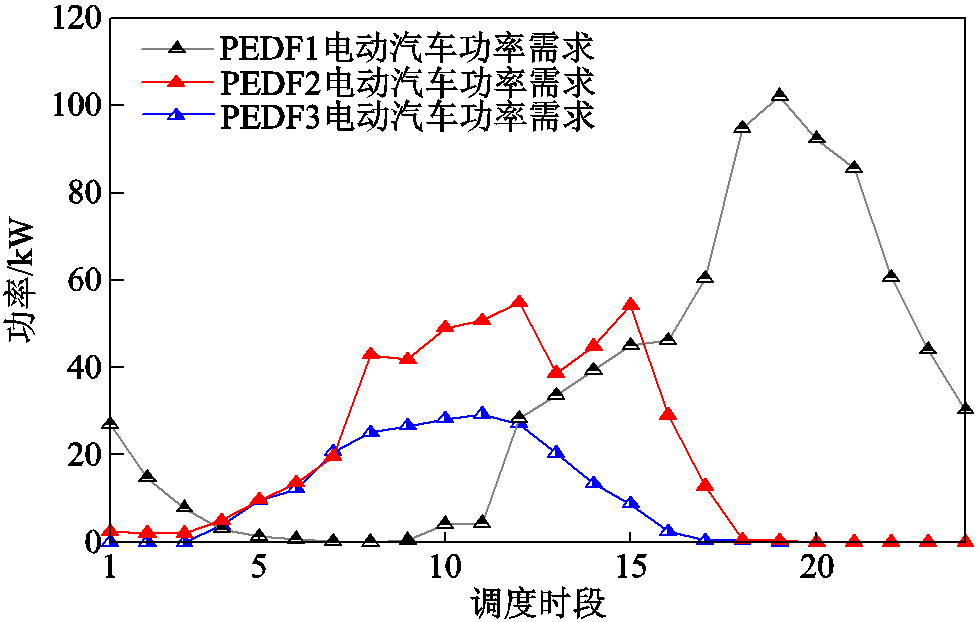
图5 各系统电动汽车功率需求曲线
Fig.5 Power demand curves of EVs for each system
本文通过训练上述场景,得到以下调度结果。其中直流母线电压调度结果如图6所示,各系统在光伏出力不足时电压低于额定电压,光伏出力过剩时电压高于额定电压。各系统中源侧出力只有光伏发电,仿真结果符合源-荷功率差指导直流母线电压的规律,低电压信号表示系统处于缺电状态,各设备进行功率调节降低用能需求。此外,因各系统负荷曲线变化,光伏出力较高时发生电压波动。
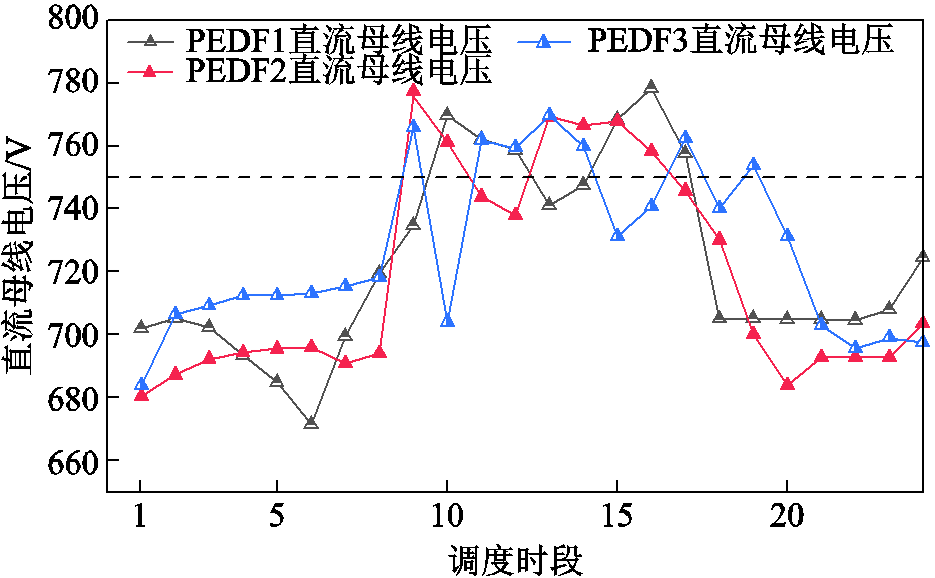
图6 系统直流母线电压变化曲线
Fig.6 DC Bus voltage variation curves
负荷和设备的优化出力结果如图7~图9所示。可见三个光储直柔系统在光伏出力和负荷波动场景下,不同时段的调度结果存在相似规律和差异化。整体而言,各系统在0:00—5:00及20:00—24:00光伏出力不足时段,均通过直流母线电压动态调节指导电动汽车和储能电池进行放电、降低柔性负荷运行功率,同时从上级电网进行购电维持系统功率平衡。
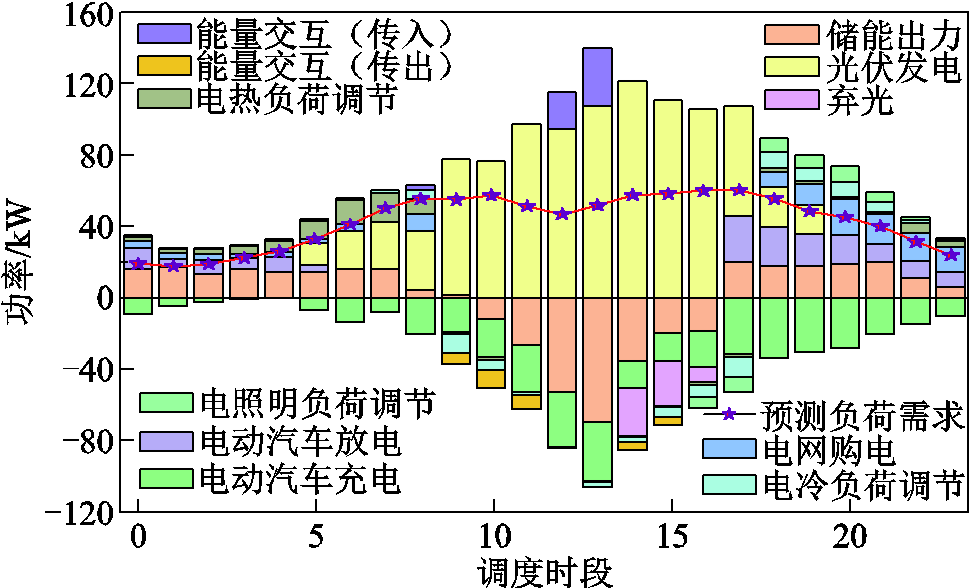
图7 PEDF1电功率优化结果
Fig.7 Optimization results of electric power for PEDF1
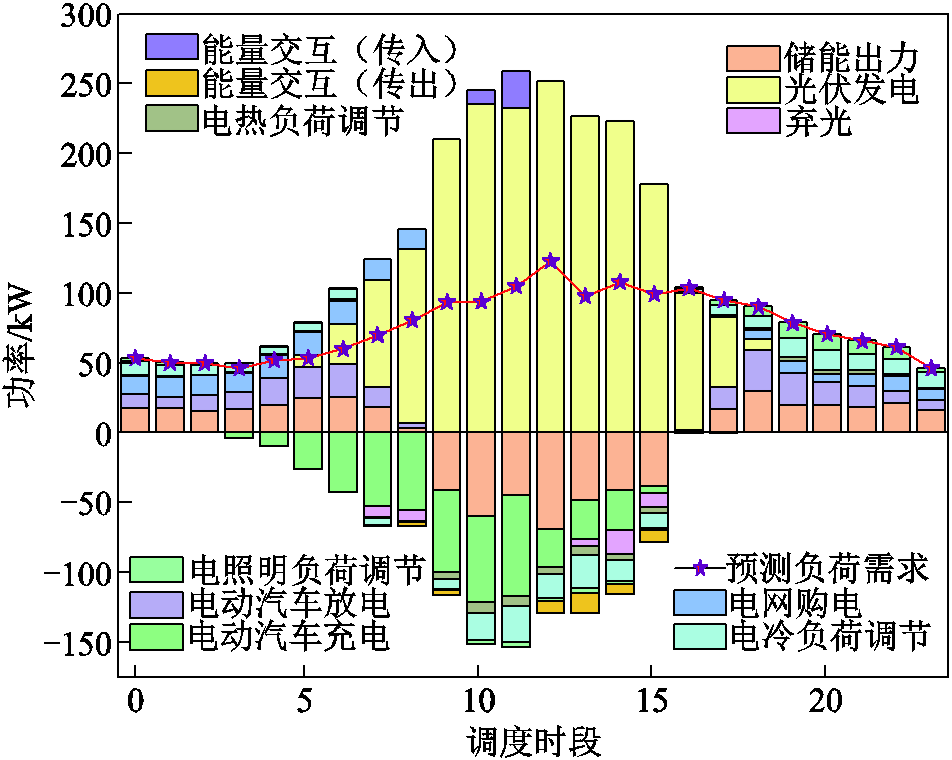
图8 PEDF2电功率优化结果
Fig.8 Optimization results of electric power for PEDF2
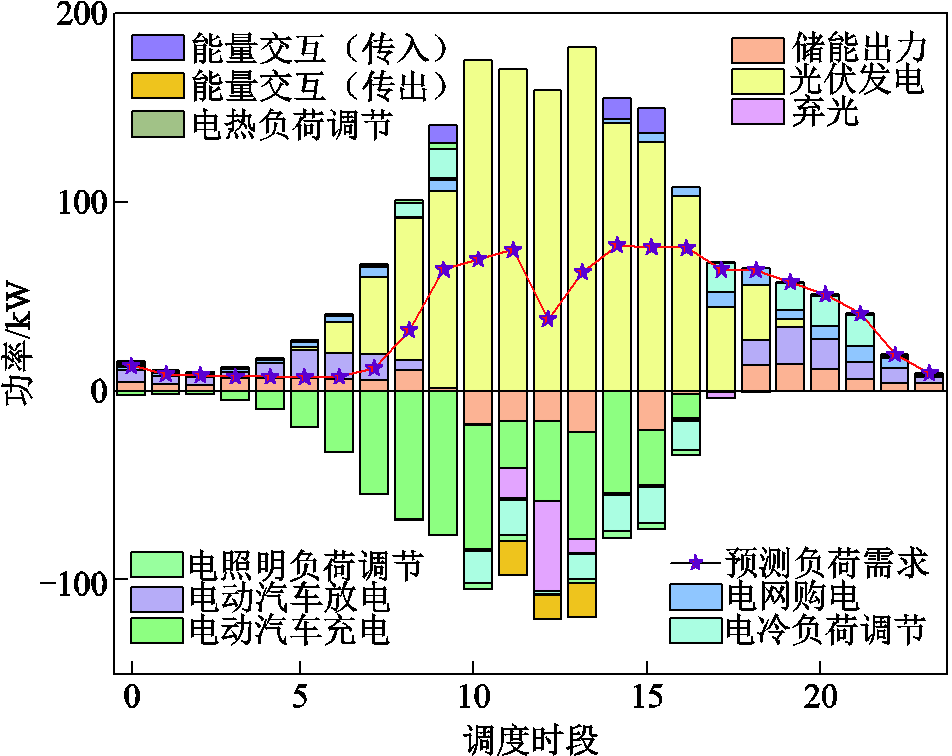
图9 PEDF3电功率优化结果
Fig.9 Optimization results of electric power for PEDF3
当光伏出力进入过渡阶段时(系统1、3为6:00—9:00,系统2为6:00—8:00),各系统虽具备光伏发电能力,但仍存在功率缺口。此时系统中光伏优先供电,柔性负荷降低,电压信号引导储能与电动汽车放电,电网购电作为补充。其中系统1在9:00通过跨系统能量传输接收外部电力,系统3则在此阶段接收其他系统14:00—15:00的功率。
在光伏出力充沛的10:00—17:00区间,各系统均通过提升电压指导储能电池和电动汽车提升充电功率、增加柔性负荷,提高工作效率。在调度的同时对储能设备实施动态SOC管理,保证储能电池拥有充足的容量进行夜间放电。同时,系统1在13:00—14:00出现储能与电动汽车充电功率峰值,同时其他系统光伏出力富余,调用其他系统进行供电;系统2的充电负荷高峰则集中于11:00—12:00,并在9:00率先实现余电外送;系统3在11:00—13:00持续高功率充电期间仍产生弃光现象。弃光时段分布呈现系统差异性,系统1集中于15:00—17:00,系统2发生于9:00及14:00—16:00,系统3则在11:00—13:00。这些时段的弃光现象主要由跨系统能量交互需求与本地调节能力饱和等因素导致。
系统间进行功率交互结果如图10所示,其中功率正为接收、负为传输。可见,系统1在10:00—12:00及15:00—16:00对外供电,9:00、13:00—14:00接收功率;系统2在9:00—16:00持续参与余电调配,形成双向能量流动;系统3则在14:00—15:00接收外部供电,其余光伏充足时段对外供电。各系统通过直流母线电压偏差阈值触发能量传输,在消纳本地光伏与支援邻域系统之间实现动态平衡。这种协同运行机制使各系统有效地降低了弃光率和上级电网的购电量。
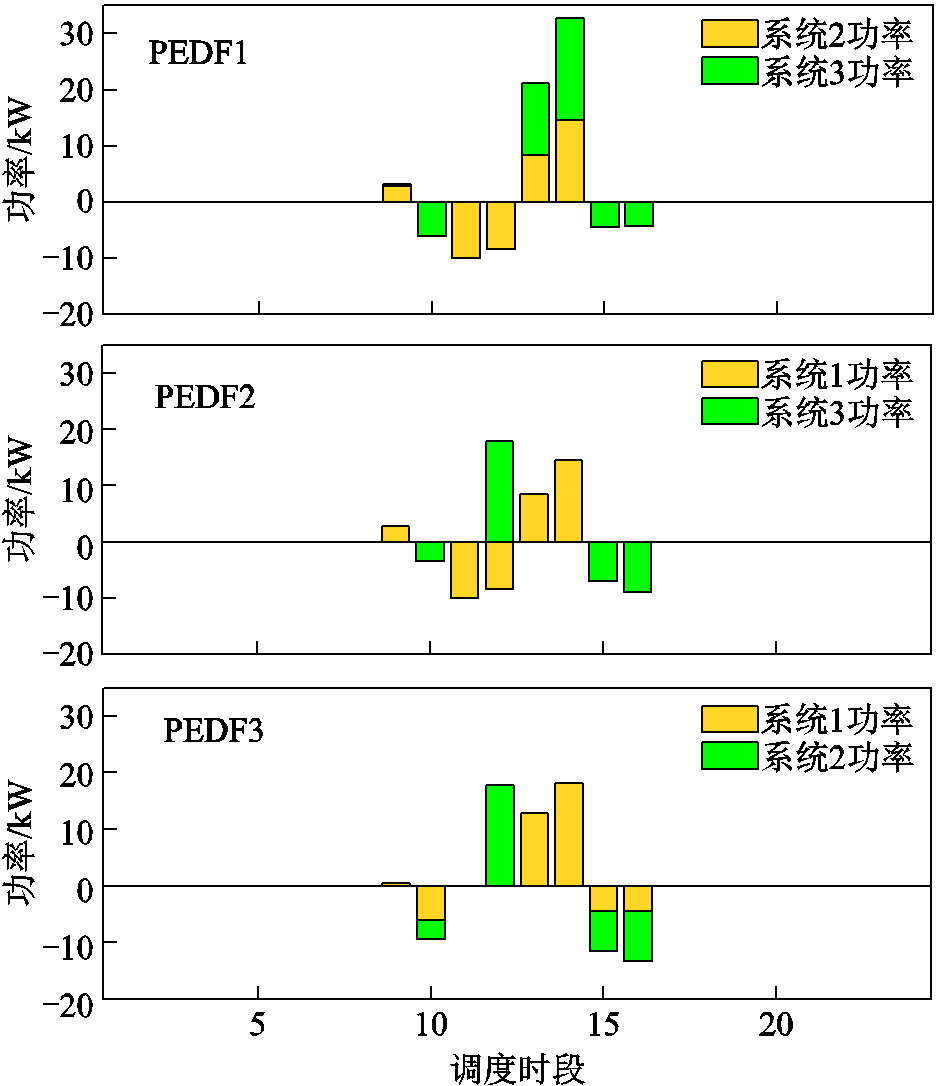
图10 各系统的功率交互
Fig.10 Power interaction of each system
5.3.1 模型对比
通过以下场景对比,验证本文模型的优越性。
场景1:不考虑价格EV参与放电调度和各系统能量交互。
场景2:考虑EV参与调度但不考虑各系统能量交互。
场景3:考虑各系统能量交互但不考虑EV参与调度。
场景4:考虑EV参与调度和各系统能量交互;各场景均通过DA-MAPPO算法完成离线训练,采用统一历史数据集的训练流程后,使用典型调度日数据进行模型验证。
其中场景2和场景3中各时段购电量和弃光量相对于场景1的减少量分别如图11和图12所示。
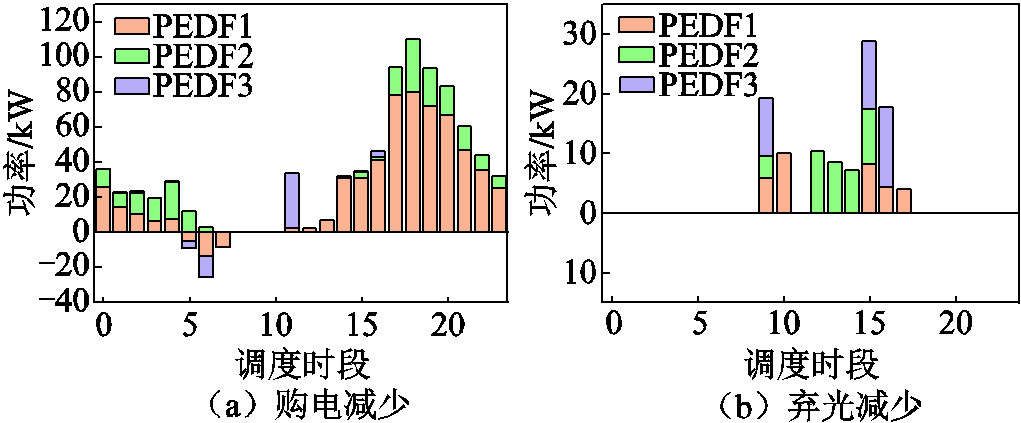
图11 场景2中购电及弃光减少量
Fig.11 Reductions of purchased electricity and abandoned solar power in Scenario 2
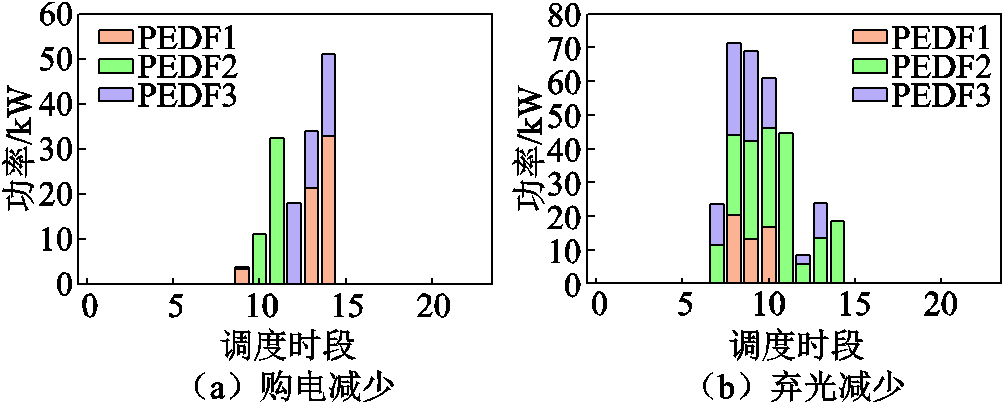
图12 场景3中购电及弃光减少量
Fig.12 Reductions of purchased electricity and abandoned solar power in Scenario 3
由图11和图12可见,EV参与调度后购电在大部分时段都有降低,少部分时段需要给参与调度的EV充电增加购电量。在各系统光伏出力盈余时才存在功率交互,因此系统功率交互购电减少时段集中在中午等光照充足时段,弃光减少同理。
不同场景下优化调度结果对比见表4。相较于场景1,场景2最终的调度成本和购电量都有所降低,这是由于场景2中的电动汽车参与调度时可在夜间光伏出力不足的时段进行放电,降低电网购电量,在光伏出力过高时对光伏进行消纳,降低弃光成本。而场景3相较于场景1,能在电量富余的同时向其他系统供电获得收益,降低弃光成本,但运行成本和购电量高于场景2。场景4同时采用两种措施协同优化系统运行成本,使得系统调节能力和光伏消纳能力显著提升。
表4 优化调度结果对比
Tab.4 Comparison of optimal scheduling results

场景成本/元购电成本/元 13 465.611 867.46 22 904.231 334.81 33 301.231 683.62 42 640.211 070.22
5.3.2 算法对比
为评估优化性能,利用本文算法与典型求解方法对本文模型进行求解,并进行对比分析。对比方法包括商用数学规划工具(CPLEX)、粒子群优化算法(Particle Swarm Optimization, PSO)、深度强化学习(SAC(soft actor critic))及多智能体深度强化学习(MAPPO)。各算法在相同参数配置下的优化求解性能对比详见表5。
表5 不同优化方法对比
Tab.5 Comparison of different optimization methods

优化方法成本/元优化时间/s DA-MAPPO2 640.211 MAPPO2 811.731 SAC2 933.461 CPLEX3 192.2246 PSO3 043.41267
从表5中可知,粒子群优化算法易陷入局部最优,最终的成本相比本文深度强化学习算法高出15.3%,且其寻优速度为267 s,远超深度强化学习所需求解时间长;单智能体SAC算法和多智能体深度强化学习算法相比,多智能深度强化学习在处理多主体系统时更具优势。深度强化学习算法可通过大量训练避免陷入局部最优解,因此最终调度结果更优;CPLEX在面对大规模、时变性强的实际场景时,不可避免地会遇到“维度灾难”。而强化学习通过与环境交互自主学习和适应策略,能够有效地处理系统的非线性和不确定性,捕捉复杂动态特性,不依赖精确的全局模型,在求解可行性、成本优化效果和实际适用性上均展现出显著优势。
对比MAPPO和DA-MAPPO在不同延迟步数的情况下求解本文模型奖励值曲线如图13所示。
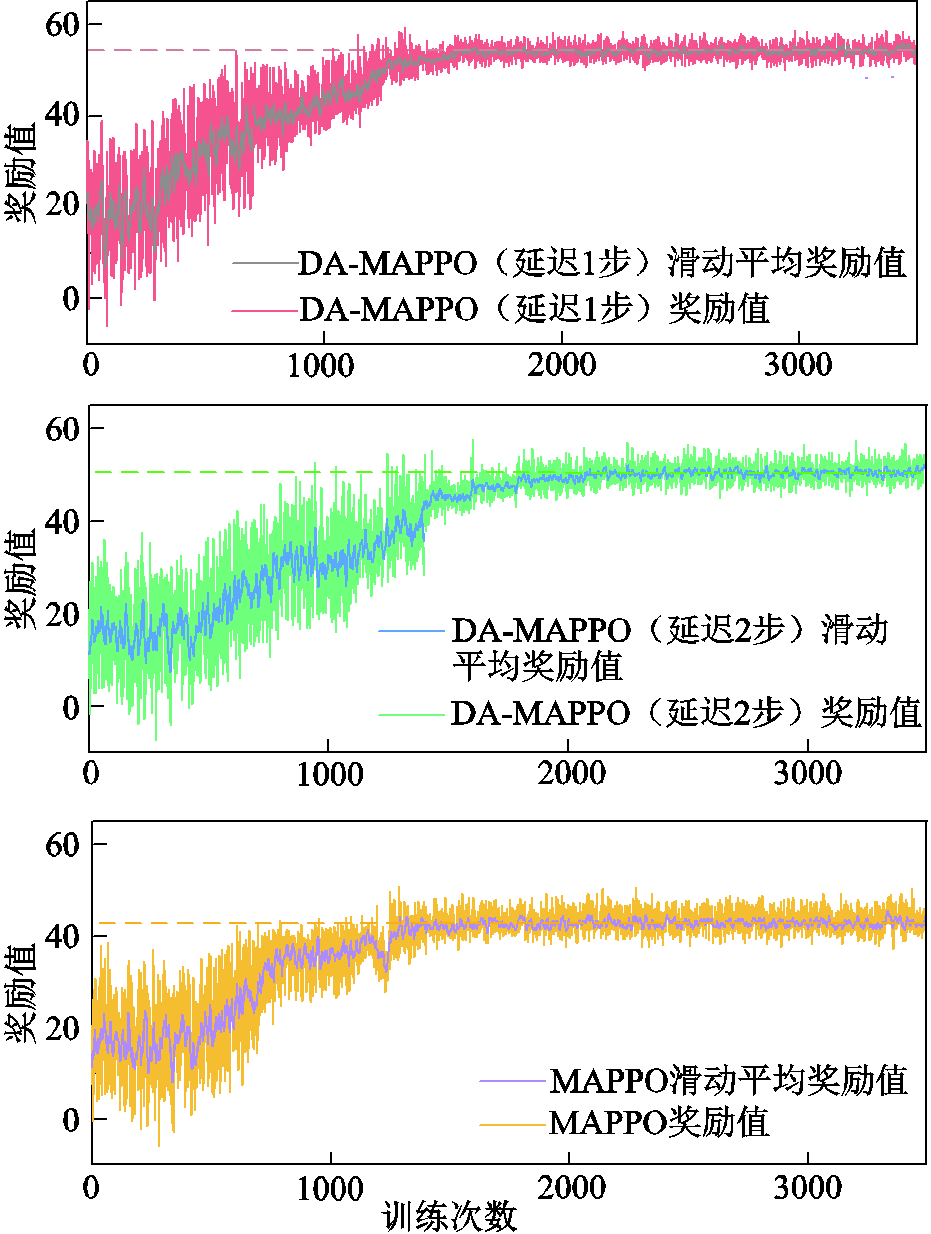
图13 训练过程奖励变化曲线对比
Fig.13 Comparison of reward variation curves during training process
在图13中引入滑动平均奖励值,演示奖励值整体变化。对比MAPPO算法,本文所用DA-MAPPO在延迟1步情况下的奖励值和收敛速度效果都强于MAPPO;延迟2步情况下奖励值较高,但收敛速度低于MAPPO算法。这是由于智能体数量和延迟步数的增加,导致智能体增强状态空间的维度扩大。这使得智能体决策依赖的信息更加复杂,在一定程度上影响了收敛的稳定性。因此本文算例分析使用考虑延迟1步的DA-MAPPO算法对本文所建立的模型进行训练求解。
本文基于直流电压信号调控策略,建立光储直柔系统运行架构,该架构通过直流母线电压信号调整柔性设备功率,并实现系统间功率交互;然后以各系统运行成本最小为目标,建立MPEDF系统优化调度模型,通过DA-MAPPO算法对该模型进行仿真求解。对算例结果进行分析,得到以下结论:
1)本文所提光储直柔系统直流母线电压调节柔性设备功率的运行框架,可根据电压信号有效地调节柔性设备、柔性负荷的运行功率,为后续优化调度模型提供了理论依据。
2)对于MPEDF系统功率交互策略,通过提升各系统的功率互补性,提高了光伏消纳,有效降低了系统运行成本。
3)相较于一些常用算法,本文所使用的DA-MAPPO算法使优化后的MPEDF系统最终运行成本更低,求解效率更高,有效地提升了MPEDF系统的经济性。
参考文献
[1] 马庆, 邓长虹. 基于单/多智能体简化强化学习的电力系统无功电压控制[J]. 电工技术学报, 2024, 39(5): 1300-1312. Ma Qing, Deng Changhong. Single/multi agent simplified deep reinforcement learning based volt-var control of power system[J]. Transactions of China Electrotechnical Society, 2024, 39(5): 1300-1312.
[2] 高艺宁, 胡海涛, 葛银波, 等. 电气化铁路沿线光伏分布式并网方案及其电气特性研究[J]. 电工技术学报, 2025, 40(21): 7062-7075. Gao Yining, Hu Haitao, Ge Yinbo, et al. Research on distributed photovoltaic integration scheme along electrified railways and its electrical characteristics [J]. Transactions of China Electrotechnical Society, 2025, 40(21): 7062-7075.
[3] 李叶茂, 李雨桐, 郝斌, 等. 低碳发展背景下的建筑“光储直柔”配用电系统关键技术分析[J]. 供用电, 2021, 38(1): 32-38. Li Yemao, Li Yutong, Hao Bin, et al. Key technologies of building power supply and distribution system towards carbon neutral development[J]. Distribution & Utilization, 2021, 38(1): 32-38.
[4] 余梦凡, 周建新, 韩四维, 等. 光储直柔建筑整体特性建模与仿真研究[J]. 建筑科学, 2024, 40(4): 142-149. Yu Mengfan, Zhou Jianxin, Han Siwei, et al. Modeling and simulation research on the overall characteristics of photovoltaics, energy storage, direct current and flexibility buildings[J]. Building Science, 2024, 40(4): 142-149.
[5] Deng Xiangtian, Zhang Yi, Jiang Yi, et al. A novel operation method for renewable building by combining distributed DC energy system and deep reinforcement learning[J]. Applied Energy, 2024, 353: 122188.
[6] 江亿. 光储直柔: 助力实现零碳电力的新型建筑配电系统[J]. 暖通空调, 2021, 51(10): 1-12. Jiang Yi. PSDF(photovoltaic, storage, DC, flexible): a new type of building power distribution system for zero carbon power system[J]. Heating Ventilating & Air Conditioning, 2021, 51(10): 1-12.
[7] Liu Xiaochen, Liu Xiaohua, Jiang Yi, et al. Photovoltaics and energy storage integrated flexible direct current distribution systems of buildings: definition, technology review, and application[J]. CSEE Journal of Power and Energy Systems, 2023, 9(3): 829-845.
[8] 李鹏, 钟瀚明, 马红伟, 等. 基于深度强化学习的有源配电网多时间尺度源荷储协同优化调控[J]. 电工技术学报, 2025, 40(5): 1487-1502. Li Peng, Zhong Hanming, Ma Hongwei, et al. Multi-timescale optimal dispatch of source-load-storage coordination in active distribution network based on deep reinforcement learning[J]. Transactions of China Electrotechnical Society, 2025, 40(5): 1487-1502.
[9] 董雷, 杨子民, 乔骥, 等. 基于分层约束强化学习的综合能源多微网系统优化调度[J]. 电工技术学报, 2024, 39(5): 1436-1453. Dong Lei, Yang Zimin, Qiao Ji, et al. Optimal scheduling of integrated energy multi-microgrid system based on hierarchical constraint reinforcement learning[J]. Transactions of China Electrotechnical Society, 2024, 39(5): 1436-1453.
[10] Yu Liang, Sun Yi, Xu Zhanbo, et al. Multi-agent deep reinforcement learning for HVAC control in commercial buildings[J]. IEEE Transactions on Smart Grid, 2021, 12(1): 407-419.
[11] 陈池瑶, 苗世洪, 姚福星, 等. 基于多智能体算法的多微电网-配电网分层协同调度策略[J]. 电力系统自动化, 2023, 47(10): 57-65. Chen Chiyao, Miao Shihong, Yao Fuxing, et al. Hierarchical cooperative dispatching strategy of multi-microgrid and distribution networks based on multi-agent algorithm[J]. Automation of Electric Power Systems, 2023, 47(10): 57-65.
[12] Walsh T J, Nouri A, Li Lihong, et al. Learning and planning in environments with delayed feedback[J]. Autonomous Agents and Multi-Agent Systems, 2009, 18(1): 83-105.
[13] Liu Mingyu, Zhang Hui, Zhang Ya. Delay-aware MAPPO algorithm for cooperative environments[C]// 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 2023: 8497-8502.
[14] 侯慧, 何梓姻, 陈跃, 等. 基于深度强化学习区间多目标优化的智能建筑低碳优化调度[J]. 电力系统自动化, 2023, 47(21): 47-57. Hou Hui, He Ziyin, Chen Yue, et al. Low-carbon optimal dispatch of smart building based on interval multi-objective optimization with deep reinforcement learning[J]. Automation of Electric Power Systems, 2023, 47(21): 47-57.
[15] 文欣, 黄学良, 高山, 等. 考虑区域差异性的电动私家车网格化充电需求预测[J]. 电力系统自动化, 2025, 49(7): 158-168. Wen Xin, Huang Xueliang, Gao Shan, et al. Grid charging demand forecasting for private electric vehicles considering regional differences[J]. Automation of Electric Power Systems, 2025, 49(7): 158-168.
[16] 田立亭, 史双龙, 贾卓. 电动汽车充电功率需求的统计学建模方法[J]. 电网技术, 2010, 34(11): 126-130. Tian Liting, Shi Shuanglong, Jia Zhuo. A statistical model for charging power demand of electric vehicles[J]. Power System Technology, 2010, 34(11): 126-130.
[17] 韩丽, 陈硕, 王施琪, 等. 考虑风光消纳与电动汽车灵活性的调度策略[J]. 电工技术学报, 2024, 39(21): 6793-6803. Han Li, Chen Shuo, Wang Shiqi, et al. Scheduling strategy considering wind and photovoltaic power consumption and the flexibility of electric vehicles[J]. Transactions of China Electrotechnical Society, 2024, 39(21): 6793-6803.
[18] 陈登勇, 刘方, 刘帅. 基于阶梯碳交易的含P2G-CCS耦合和燃气掺氢的虚拟电厂优化调度[J]. 电网技术, 2022, 46(6): 2042-2054. Chen Dengyong, Liu Fang, Liu Shuai. Optimization of virtual power plant scheduling coupling with P2G-CCS and doped with gas hydrogen based on stepped carbon trading[J]. Power System Technology, 2022, 46(6): 2042-2054.
Abstract In the context of developing a new power system dominated by new energy, large-scale integration of distributed photovoltaics has exacerbated spatiotemporal mismatches. DC-AC conversion losses in prevalent AC distribution systems have also grown more prominent. These issues drove rapid advancement of the photovoltaic, energy storage, direct current, flexibility (PEDF) system. Most existing studies, however, focus on single-system optimization and neglect collaborative scheduling in multiple photovoltaic, energy storage, direct current, flexibility (MPEDF) systems. To enhance MPEDF power complementarity and cut operational costs, this study proposed a collaborative optimal scheduling strategy based on multi-agent deep reinforcement learning.
First, the study established an interconnected operation framework for the MPEDF system. Multiple independent PEDF systems integrated PV, grid access, battery energy storage (BES), electric vehicles (EVs), and flexible loads via DC-DC converters and interconnection lines. The power response of flexible loads, BES, and EVs correlates linearly with DC bus voltage deviation. EV charging behavior was simulated using the Monte Carlo method. Next, the study developed a power control method. It dynamically guides the charging and discharging power of flexible devices and EVs based on DC bus voltage deviation signals, enabling power scheduling. By optimizing the voltage gain coefficient at each scheduling moment, the study obtained a power adjustment plan for flexible devices in PEDF systems to achieve economic operation. Finally, the study constructed a complete MPEDF system optimization scheduling model with a power interaction strategy. Its power transmission mechanism coordinates inter-system power differences to minimize operational costs. The model considers various costs, including power transmission, device scheduling, and curtailment penalties, aiming to maximize economic and environmental benefits.
To address data privacy and system-specific operational traits, the study employed multi-agent deep reinforcement learning for model solving. For information interaction delays among agents, it adopted a delay-aware multi-agent proximal policy optimization (DA-MAPPO) algorithm. The algorithm introduces a delay-aware Markov process and expands the state space, effectively reducing interaction delays and boosting solving efficiency. Simulations on three interconnected MPEDF systems show that enhanced power complementarity increases photovoltaic absorption and cuts operating costs. Compared with scenarios without electric vehicle participation or inter-system power interaction, electricity purchase costs drop by 42.7% and curtailment decreases by 38.5%. DA-MAPPO yields a total operating cost of 2 640.21 yuan, 17.3% lower than CPLEX, 13.2% lower than PSO, 9.9% lower than SAC, and 6.1% lower than MAPPO. It also has the fastest solving speed (1 second), making it suitable for real-time scheduling.
In conclusion, this study develops an operation framework for the PEDF system based on DC bus voltage control strategies. This framework adjusts the power of flexible devices and facilitates inter-system power interaction through voltage signals. The strategy contributes to balancing renewable energy supply and demand, supporting the stable and low-carbon operation of urban power grids, and provides new insights for future optimization scheduling models. Future research will explore the integration of MPEDF with shared energy storage to address spatial and temporal differences in PV output and load demand, as well as to solve issues of energy storage redundancy in some systems and capacity insufficiency in others.
Keywords:Multiple photovoltaic, energy storage, direct current, flexibility (MPEDF) system, deep reinforcement learning, power interaction, optimization scheduling, delay-aware multi-agent
DOI: 10.19595/j.cnki.1000-6753.tces.250960
中图分类号:TM61
国家自然科学基金(52267007, 52167009, 52567008)和江西省自然科学基金(20242BAB26070)资助项目。
收稿日期 2025-06-04
改稿日期 2025-08-10
彭春华 男,1973年生,博士,教授,博士生导师,研究方向为电力系统规划与运行、智慧能源系统优化调控。E-mail:chinapch@163.com(通信作者)
张浩旗 男,2001年生,硕士研究生,研究方向为智能电网优化调度。E-mail:1625957875@qq.com
(编辑 赫 蕾)