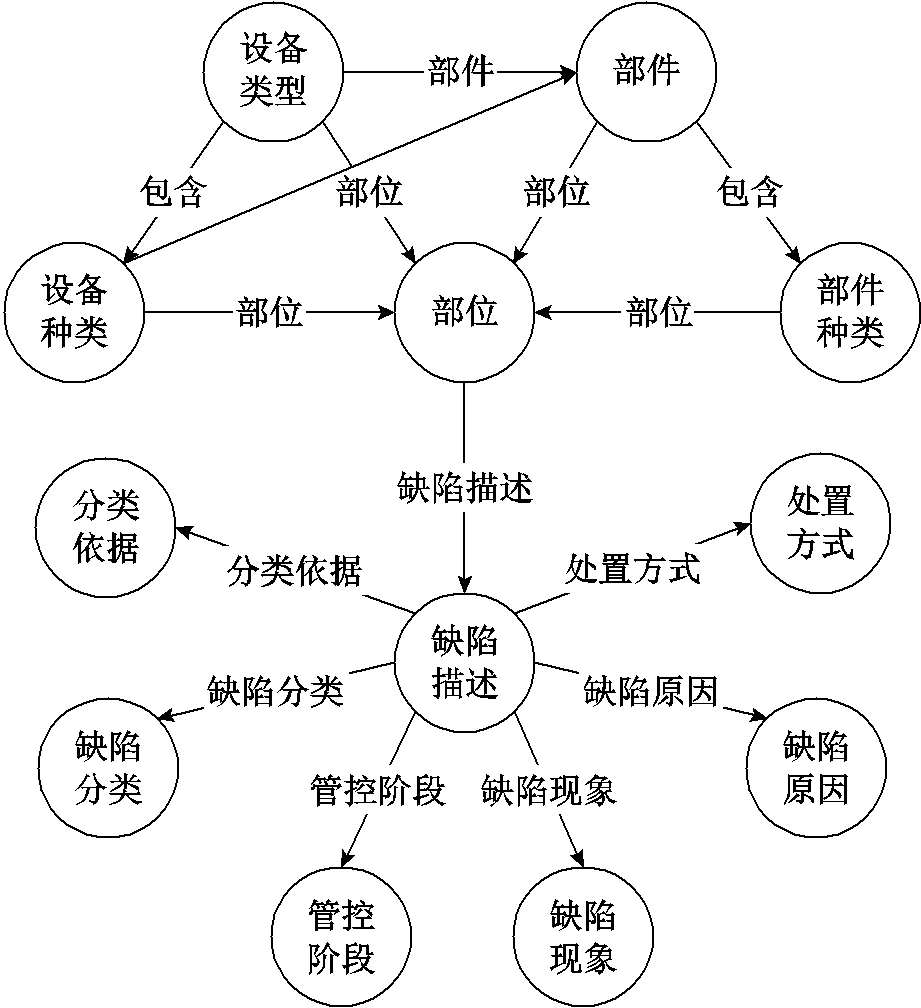
图1 输变电设备故障知识图谱本体层结构
Fig.1 The ontology layer structure of the fault knowledge graph of power transmission and transformation equipment
摘要 输变电系统作为电网的重要组成部分,其设备一旦发生故障会造成不可预计的损失。知识图谱通过存储结构化的领域知识,已成为辅助电力领域专业人员进行故障分析与决策的有力工具。实体关系抽取是知识图谱构建中的关键步骤,现有实体关系抽取方法通常忽略了三元组之间的依赖,且存在文本表征能力弱、实体定位模糊及长尾关系分类精确率不高的问题。针对以上问题,该文提出了一种基于改进集合预测网络的实体关系联合抽取模型。该模型基于集合预测网络结构对三元组进行整体建模,首先利用无监督对比学习方式增强输入文本表征,为后续实体关系抽取提供更有效的语义特征;其次利用边界回归算法对实体边界的偏移量进行建模,在网络预测的基础上进一步通过偏移量来修正实体边界,提高实体的识别准确率;最后在关系分类阶段引入代价敏感学习来平衡不同类型三元组的损失,使模型在长尾分布及高错分代价约束下有效地学习长尾关系的特征,降低长尾关系分类的错误率,并且在实际输变电设备故障数据集上进行验证,进而以此构建输变电设备故障知识图谱。在实体关系抽取实验中,精确率、召回率和F1值相较于基线模型分别提升了3.9、5.3、4.6个百分点,实验结果表明,该文所提模型在输变电设备故障数据上能够实现有效的实体关系抽取。此外,该文利用Neo4j图数据库对构建的知识图谱进行存储和可视化,构建的知识图谱能够为后续故障分析和决策提供支持。
关键词:输变电设备 知识图谱 联合抽取 对比学习 边界回归
电网智能化转型升级对电力系统运行状况的分析与维护提出了更高要求。传统电力系统的运维需要专业人员对大量文本记录进行查询和分析并结合自身经验进行判断与决策,时间及人力成本较高。对于运维有用的信息分散在大量多源异构的数据中,并未得到充分利用[1]。知识图谱(Knowledge Graph, KG)以结构化的形式描述客观世界中概念、实体及其之间的关系,提供了一种更好地组织、管理和理解不同来源和结构信息的工具[2]。因此,许多研究致力于利用知识图谱技术结构化存储电网中复杂的领域知识,并以此来辅助专业人员进行故障分析和处理,以提升运维效率和决策准确度。输变电系统作为电力系统的重要组成部分,其设备发生故障会降低电网供电的可靠性,进一步的故障还会导致大面积停电等电网事故,造成不可估量的损失[3]。输变电设备结构以及潜在故障、事故等级等知识的结构化表示有助于帮助专业人员对输变电故障进行全面和快速的认知,输变电设备故障知识的有效抽取和分析对于输变电设备故障的应急处理和电网的日常维护有着重要的指导意义。在此场景下引入知识图谱技术不仅能为专业人员的故障分析决策提供可靠的依据,还有助于进行故障检索、故障推理等下游任务。但该领域现有知识图谱的实体关系抽取算法精确率不高,导致知识图谱的可靠性不强,输变电故障相关低频知识的覆盖力不足,且对于可视化的关注较少,因此需要进一步提高和完善。
知识图谱的构建可以分为数据获取、知识抽取、知识存储、知识应用等步骤。其中知识抽取作为构建知识图谱的重要步骤,得到了广泛的研究,知识抽取的准确性对于构建高质量的领域内知识图谱至关重要。在实际应用中需要确保领域内知识图谱信息的可靠性、完整性和一致性,才能为专业人员提供有效的参考。但非结构化的输变电故障文本相较于开放领域文本的复杂程度更高,抽取难度更大,任务效果亟待进一步提升[4]。
知识抽取可以分解为两个子任务——命名实体识别(Named Entity Recognition, NER)和关系抽取(Relation Extraction, RE)。根据NER和RE任务交互程度的不同,可以将知识抽取方法分为流水线方法和联合抽取方法[5]。电力领域内许多研究使用流水线方法[6-7],但其存在的错误传播问题在很大程度上限制了模型性能的提升。因此,近年来许多研究开始关注联合抽取方法。文献[8]提出了一种基于序列到序列(Sequence to Sequence, Seq2Seq)模型结构的半指针半标注的联合抽取方法,首先使用指针网络预测头实体的起始位置和结束位置,然后抽取所有关系类别潜在的尾实体的起始位置和结束位置,实体关系通过共享编码层向量进行交互。文献[9]针对常见的序列标注方法无法解决电力领域实体关系重叠的问题,在BIESO(begin, inside, end, single, outside)标注法的基础上融合实体关系类别和重叠信息形成新的标注,并引入对抗训练,提高了电力文本知识抽取的精确率。为了更加精准地识别结构复杂的电力领域文本中的实体关系,文献[10]提出了一种基于图卷积网络(Graph Convolution Network, GCN)的联合抽取模型,利用依存关系分析建立语法依赖树,并使用GCN对文本结构信息进行编码,为联合抽取模型提供了有效的先验信息,提高了实体关系抽取的效果。
尽管以上联合抽取方法改善了流水线方法的缺陷,并从不同的角度提高了相应电力数据集的识别效果,但都只关注了同一三元组头尾实体及关系的依赖,而电力领域的文本通常存在大量的重叠实体关系,三元组之间存在紧密的联系,考虑三元组之间的相互依赖有利于整体三元组集合的预测。集合预测网络(Set Prediction Network, SPN)[11]利用非自回归解码器[12]中的多头注意力模块对三元组进行整体建模,一次生成所有三元组,在输变电设备故障数据上具有更好的表现。
然而,输变电设备故障实体关系抽取中仍存在以下问题。首先,在文本特征向量获取上,BERT(bidirectional encoder representations from Transformers)等基于Transformer结构的模型是在大量通用数据集上训练得到的,直接作为电力领域内文本编码器不能很好地表示句子的语义特征,进而影响后续实体关系的抽取效果;其次,现有方法存在实体边界定位不够精准的问题;最后,输变电设备故障文本中不同关系类型三元组的数量占比差异较大,而现有研究未考虑此类不平衡性[13-14],导致长尾关系的分类准确度较差。
为了解决以上问题,提高输变电设备故障文本的抽取效果,本文在集合预测网络(SPN)的基础上提出了基于改进集合预测网络(Improved Set Prediction Network, ISPN)的实体关系联合抽取模型。首先利用无监督的对比学习方法增强编码器抽取的文本语义特征,使解码器能够结合更好的句子表示来学习建模三元组;其次,提出基于边界回归(Bounding Regression, BR)算法来建模预测实体边界和真实实体边界的偏移,结合偏移量对实体边界进行修正,并通过边界损失约束实体的定位,使其更接近真实值;然后,在关系分类时,引入代价敏感学习(Cost Sensitive Learning, CSL)来平衡不同类别关系对于模型参数更新的影响,根据代价矩阵增大长尾关系损失的权重,使模型能够更关注学习长尾关系特征,降低长尾关系分类的错误率;最后,面向输变电设备故障场景,基于所提出的联合抽取模型构建输变电设备故障知识图谱,将构建的知识图谱存储至Neo4j数据库,并利用Neo4j的可视化功能展示查询后的结果。
本文使用自顶向下方法[4]构建输变电设备故障知识图谱,参考Q/GDW 1906—2013、Q/GDW 1904.1—2013、Q/GDW 1904.2—2013、DL/T 741—2019等输变电相关标准规范手册进行本体设计。输变电设备故障知识图谱本体层结构如图1所示。
输变电设备故障知识图谱构建流程如图2所示。本文首先从电子版标准规范手册中利用光学字符识别算法提取结构化和非结构化数据。结构化数据根据设计的本体层进行数据层的映射,形成初步的知识图谱框架;非结构化数据与某地区实际输变电设备故障巡检文本经过数据清洗后的文本相结合,形成非结构化输变电设备故障数据集。其次基于ISPN模型抽取故障相关实体和关系。最后将二者进行融合形成最终的输变电设备故障知识图谱。
图1 输变电设备故障知识图谱本体层结构
Fig.1 The ontology layer structure of the fault knowledge graph of power transmission and transformation equipment
集合预测网络将三元组的预测看作一个相关的过程,即每个三元组的预测都依赖其他三元组的学习,因此SPN更适合抽取输变电设备故障数据这种具有大量重叠实体关系的文本。本文基于SPN进行改进,改进联合抽取模型ISPN整体结构如图3所示。
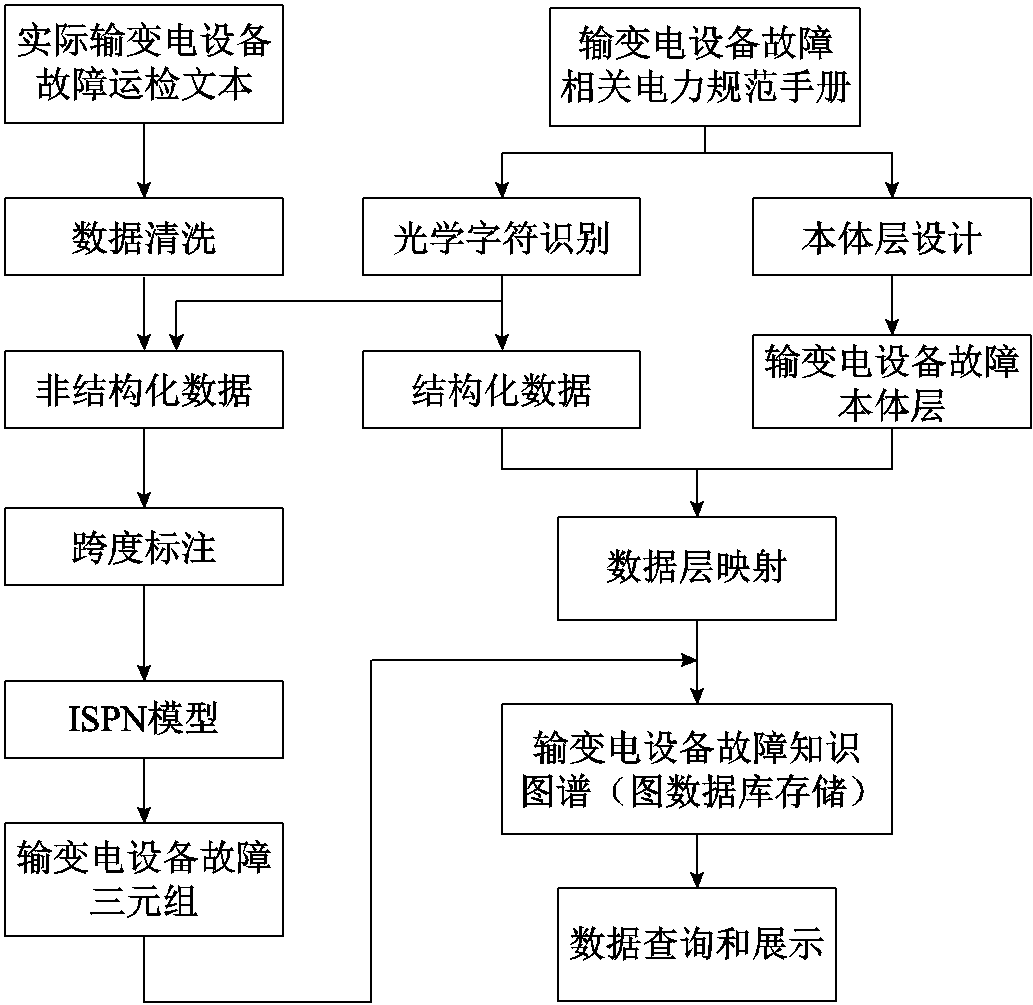
图2 输变电设备故障知识图谱构建流程
Fig.2 Construction process of fault knowledge graph of power transmission and transformation equipment
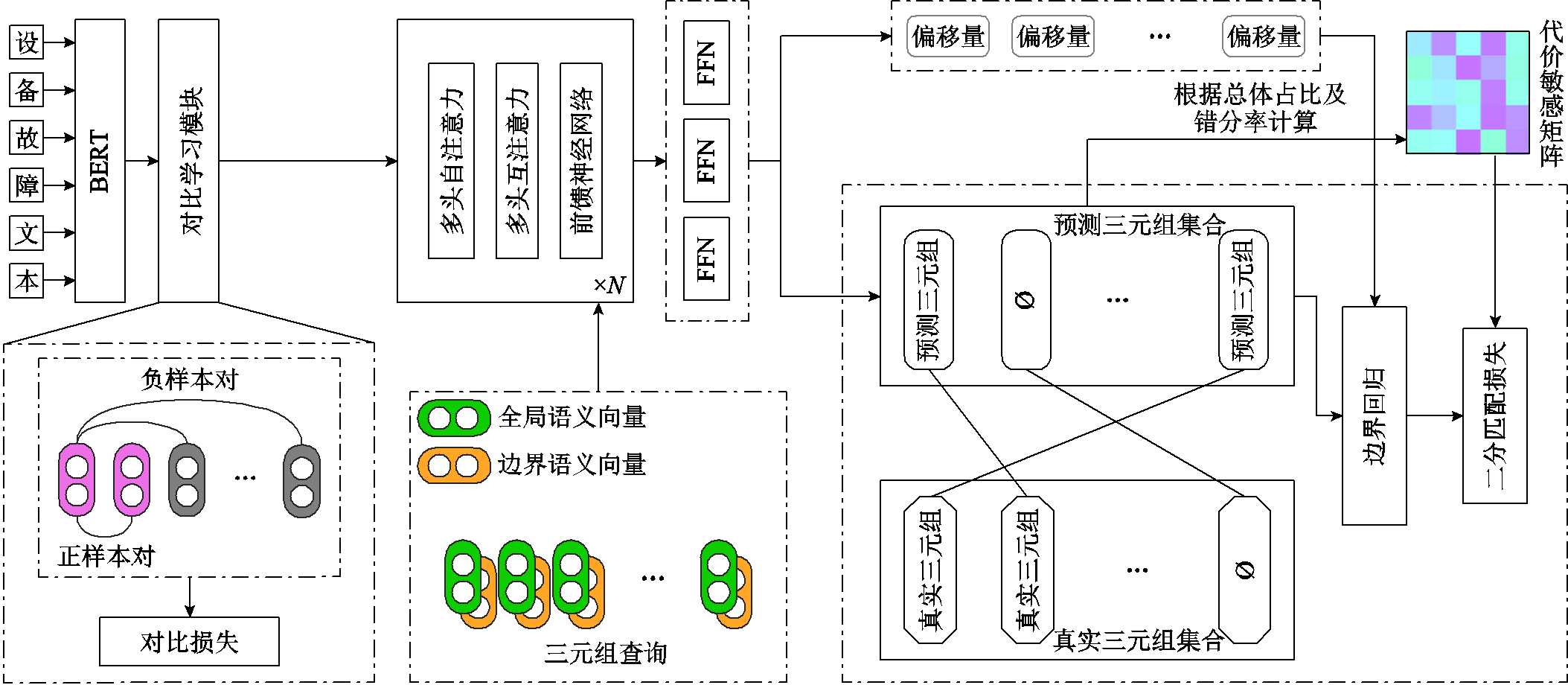
图3 联合抽取模型ISPN整体结构
Fig.3 The overall structure of the joint extraction model ISPN
本文针对输变电设备故障的三元组抽取中存在的三个问题分别进行了改进,对应模型的特征抽取、命名实体识别以及关系分类过程。图3中,点画线部分为算法改进的部分,具体为:
1)在特征抽取阶段,相较于先前直接使用预训练模型抽取文本特征的方法,本文利用对比学习来提高文本嵌入的质量,作为增强的全局信息输入解码器。在解码器模块中,利用全局语义向量和边界语义向量并结合编码器得到的文本特征分别学习不同尺度的信息以进行实体关系的预测。
2)在命名实体识别任务中,本文基于目标检测中边界回归的思想提出利用边界回归的方法来约束实体边界预测,在以往方法直接进行实体边界预测的基础上增加了对候选实体和真实实体之间的差值的建模,通过偏移量对实体边界进行微调,以达到更接近真实实体的目的。
3)在关系分类任务中,本文考虑输变电设备故障数据中存在的长尾关系错分率较高的问题,引入代价敏感学习来平衡数据集中不同类型关系的损失大小,提升错分率较大的长尾关系类型占损失的比例,引导模型学习更多关于长尾关系的特征,从而提升长尾关系分类的准确度。
SPN是编码器-解码器结构,基于Transformer变体的BERT模型[15]在自然语言处理领域实现了优越的性能,SPN也采用BERT作为文本的编码器。但输变电设备故障场景文本相对于通用文本语义更加复杂,因此本文引入了对比学习框架来提升文本特征表示能力。增强的文本表示输入解码器的多头互注意力模块中用以对三元组整体建模,具体算法将在第3节进行介绍。
SPN的解码器由N个非自回归模块组成,每个模块中的多头自注意力模块用于建模不同三元组之间的依赖关系,多头互注意力模块用于融合增强的文本表征信息。解码器的输入为M个三元组查询,为了更好地学习输入句子的语义信息,解码器的每个查询输入包含1个全局语义向量和4个边界语义向量。训练过程中M个三元组查询分别学习三元组不同尺度的特征,利用全局语义特征预测关系类型,边界语义特征预测实体边界,并通过前馈神经网络(Feed Forward Network, FFN)一次生成三元组集合。
为了提高实体的识别准确率,本文提出一种边界回归算法,首先根据解码器输出特征预测三元组头尾实体的下标和起始偏移,然后利用二分图匹配算法得到真实三元组集合与预测三元组集合的最佳匹配,最后利用边界回归公式得到新的下标并计算损失。
在模型训练过程中,本文通过代价敏感矩阵赋予关系三元组不同的错分代价,并根据错分代价调整损失大小。
对比学习[16]原本用于图像处理领域,通过提高同类图像的特征相似性,并降低不同类图像的特征相似性来学习更多的数据语义特征,从而提升图像特征提取器的性能。随着自然语言处理领域的发展,也逐渐将对比学习作为增强文本特征提取的方法。在对比学习框架中有两个主要问题:正负样本对的生成和样本之间对比损失的计算。为了提升BERT编码器在输变电设备故障场景中的语义表示能力,本文采用无监督的对比学习方法增强文本特征提取模块。
本文利用BERT模型中dropout层的随机丢弃掩码,将同一个句子输入BERT模型中两次得到语义相似的特征向量。在一个大小为B的训练批次内,正样本为同一个句子经过不同随机丢弃掩码得到的特征向量,负样本则为其他B-1个句子的特征向量。
在编码阶段加入对比学习的目的是通过拉近语义上接近的正样本之间的特征距离,将语义不同的负样本的距离推远,从而学习有效的表征。本文遵循文献[17]所提出的对比学习框架,采用批量内交叉熵目标函数作为损失,对比损失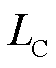 计算式为
计算式为
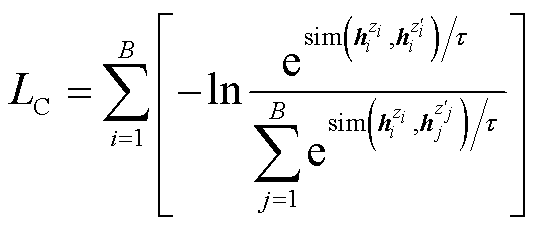 (1)
(1)
式中,τ为温度超参数;z和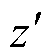 为同一个句子两次输入BERT编码器的随机丢弃掩码;
为同一个句子两次输入BERT编码器的随机丢弃掩码;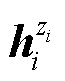 和
和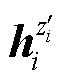 为一个训练批次内当前句子通过具有随机丢弃掩码的编码器生成的正样本对的特征向量;
为一个训练批次内当前句子通过具有随机丢弃掩码的编码器生成的正样本对的特征向量;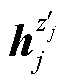 为其他句子生成的负样本特征向量;sim函数用来度量不同句子特征向量之间的距离,具体方法是基于L2范数计算余弦相似度。训练时,基于对比损失反向传播更新编码器参数。
为其他句子生成的负样本特征向量;sim函数用来度量不同句子特征向量之间的距离,具体方法是基于L2范数计算余弦相似度。训练时,基于对比损失反向传播更新编码器参数。
边界回归(BR)[18-19]是目标检测领域内用于提升候选框的定位准确度的一个重要方法,旨在对候选框和真实框坐标之间的差异进行回归建模,通过预测回归参数对候选框的坐标进行缩放和位移,从而使回归后的预测坐标与真实坐标间的差距缩小。输变电设备故障文本会因其语义复杂性而导致抽取过程中存在实体边界识别不准确的问题,为了解决该问题,本文提出一种基于边界回归算法的实体定位方法。类比目标检测中的二维检测框,一维文本序列的检测输出为句子中实体跨度的边界下标,因此需要建模的回归参数为跨度的开始和结束下标的偏移量。本文所提算法通过对候选实体跨度的偏移量进行建模,使候选实体跨度修正后的结果更接近真实实体边界的位置,从而达到准确定位的目的。以“冷却器”实体为例,输变电设备故障文本中的边界回归如图4所示。图4中,实线代表实体跨度,虚线代表预测实体和真实实体的起始偏移量ΔS和结束偏移量ΔE。从图4中可以看出,原本不准确的边界识别可以经过边界回归算法的修正与真实跨度的边界更接近。本文利用边界语义向量进行候选实体边界偏移量的预测,与全局语义向量不同,边界语义向量更关注实体的边界特征。
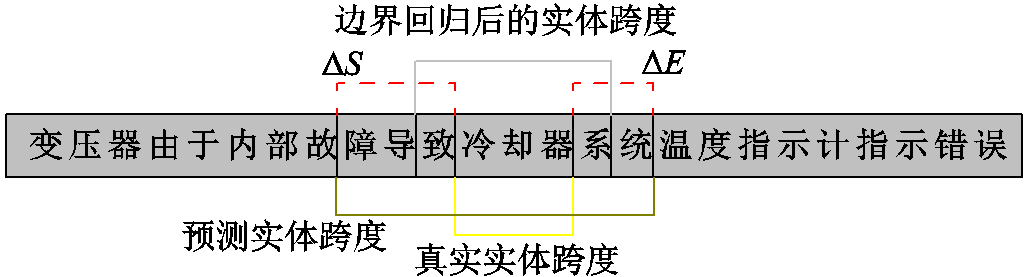
图4 输变电设备故障文本中“冷却器”实体的边界回归
Fig.4 Boundary regression of “Cooler” in fault text of power transmission and transformation equipment
在进行边界回归之前,需要得到初步的边界预测结果,解码器的M个三元组查询经过非自回归建模转换为M个长度为d的全局语义向量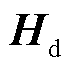 以及4M个长度为d的边界语义向量
以及4M个长度为d的边界语义向量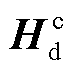 。
。
关系类型的预测概率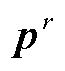 可以通过softmax激活函数得到,表示为
可以通过softmax激活函数得到,表示为
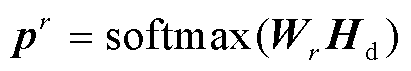 (2)
(2)
式中,r为关系类型;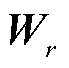 为对应关系类型的网络权重。
为对应关系类型的网络权重。
实体头尾实体的起始下标及结束下标的预测概率表示为
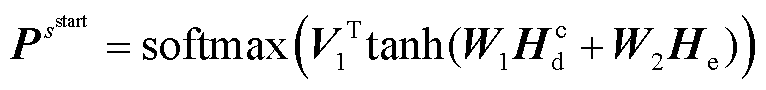 (3)
(3)
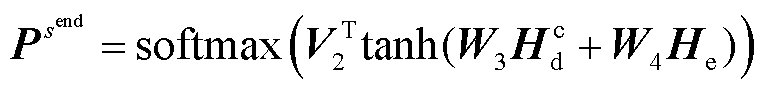 (4)
(4)
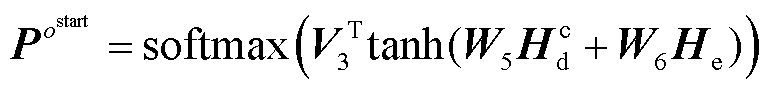 (5)
(5)
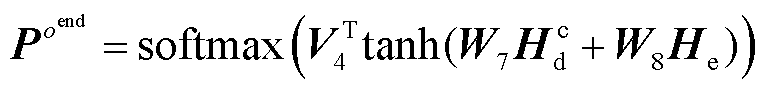 (6)
(6)
式中,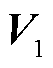 ~
~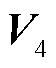 和
和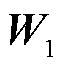 ~
~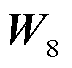 为解码器的可学习参数;
为解码器的可学习参数;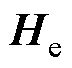 为编码器的输出;s和o分别为头实体和尾实体;start和end分别为实体的起始和结束。本文预测的三元组表示为含有(r,
为编码器的输出;s和o分别为头实体和尾实体;start和end分别为实体的起始和结束。本文预测的三元组表示为含有(r, 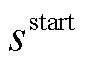 ,
, 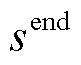 ,
, 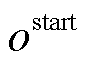 ,
, 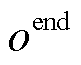 )五个元素的元组,分别代表关系类型、头尾实体的起始和结束位置下标。这五个元素的值为预测概率最大值对应的标签。
)五个元素的元组,分别代表关系类型、头尾实体的起始和结束位置下标。这五个元素的值为预测概率最大值对应的标签。
本文提出的边界回归算法可以分为边界回归和边界损失计算两步。边界回归是对候选实体跨度的偏移量进行预测,并根据预测偏移量修正候选实体跨度位置。预测偏移量通过网络对头尾实体的边界语义向量进行线性映射来预测。候选实体跨度的新的起始位置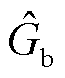 和结束位置
和结束位置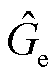 计算式分别为
计算式分别为
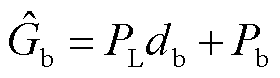 (7)
(7)
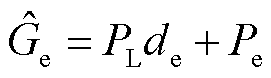 (8)
(8)
式中,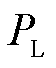 为候选实体跨度的长度;
为候选实体跨度的长度;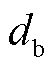 和
和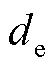 分别为候选实体起始和结束位置下标的预测偏移量;
分别为候选实体起始和结束位置下标的预测偏移量;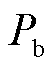 和
和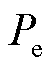 分别为候选实体起始和结束位置的下标。
分别为候选实体起始和结束位置的下标。
本文使用边界回归损失约束模型对实体边界进行学习,边界回归损失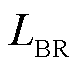 计算式为
计算式为
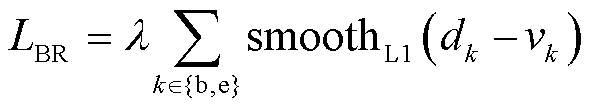 (9)
(9)
式中,λ为平衡分类损失和边界回归损失的系数;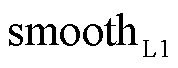 损失函数结合了
损失函数结合了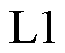 损失和
损失和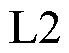 损失的优点,函数曲线较为平滑,能够减少对异常值的敏感性,故本文采用损失来衡量预测偏移量和真实偏移量的差距;起始位置和结束位置真实偏移量
损失的优点,函数曲线较为平滑,能够减少对异常值的敏感性,故本文采用损失来衡量预测偏移量和真实偏移量的差距;起始位置和结束位置真实偏移量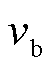 和
和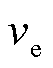 由真实实体跨度与候选实体跨度计算得出,计算公式分别为
由真实实体跨度与候选实体跨度计算得出,计算公式分别为
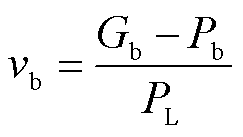 (10)
(10)
 (11)
(11)
式中,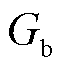 和
和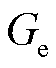 分别为实体起始位置和结束位置的真实下标。
分别为实体起始位置和结束位置的真实下标。
关系分类作为三元组抽取的关键步骤之一,决定了三元组最终抽取的质量。对输变电设备故障数据集中不同类型关系三元组占比统计和预测错误占比统计分别如图5和图6所示。
从图5的统计结果可以看出,数据集中“缺陷描述/管控阶段/管控阶段”“缺陷描述/缺陷分类/缺陷分类”“缺陷描述/分类依据/分类依据”这三种关系三元组的占比仅有8.5%,但在图6的预测错误占比中高达38.9%,这是由于数据量的占比分布不均衡导致少数长尾关系三元组的预测准确度较低。由于长尾三元组和其他类型三元组在知识层面有着同样的重要性,因此长尾三元组关系的准确分类至关重要。
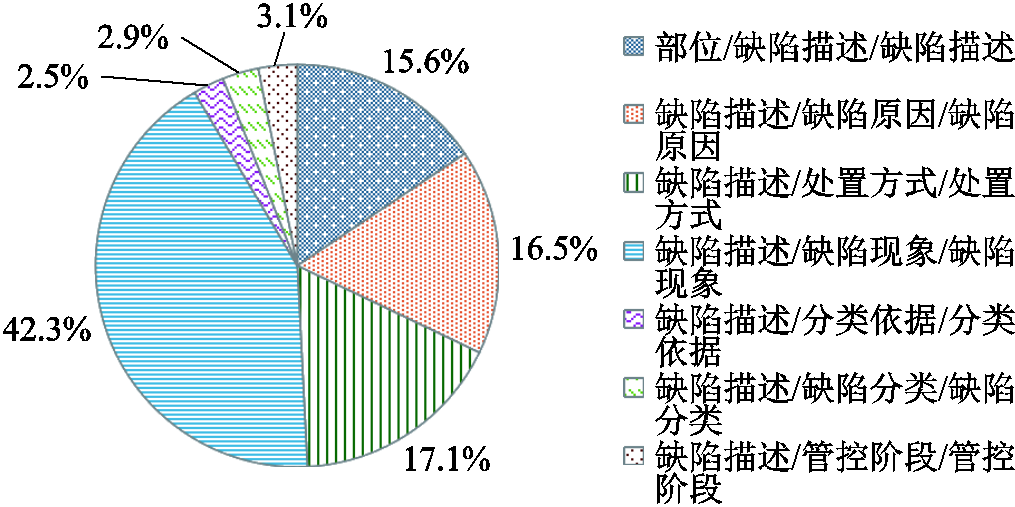
图5 不同类型关系三元组占比统计
Fig.5 Statistics on the proportion of triples in various types of relationships
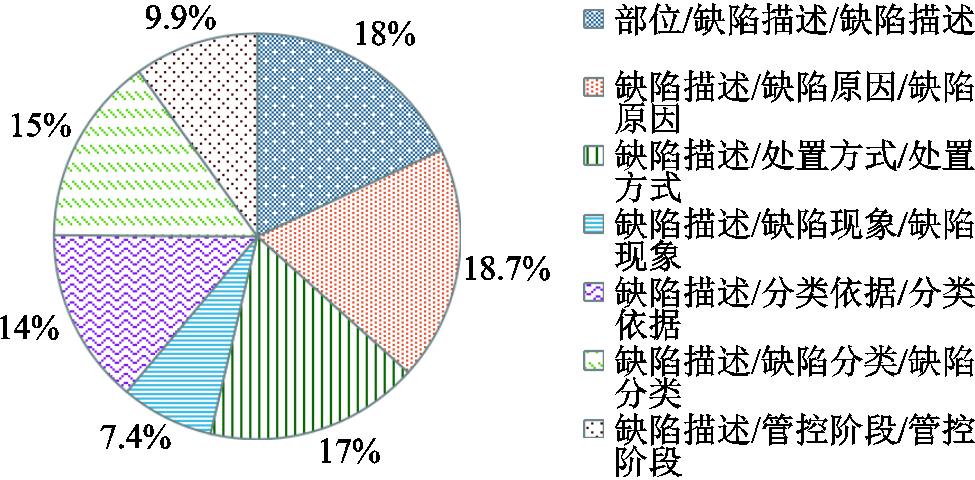
图6 不同类型关系三元组预测错误占比统计
Fig.6 Statistics on the proportion of prediction errors in triplets of various types of relationships
以往的模型在进行关系分类时对每一个类别的错分代价是相等的,这就导致模型很难从长尾关系三元组这类少量数据学习到足够多的特征,从而使得这部分数据的分类准确度下降。
为了提升长尾关系分类的准确度,本文在关系分类模块中引入代价敏感学习(CSL)[20]。代价通常为一个预定义的矩阵,本文将分类结果看作分类正确和分类错误两种情况,在这种情况下,代价矩阵为一维矩阵,表示为W=[wr],r∈R,其中R为关系的集合。代价敏感矩阵所有元素初始时为零,随后根据模型的迭代结果进行代价敏感矩阵的动态计算更新。代价的定义遵循数量占比较少、分类错误率高的关系类型的代价大于数量占比较多、分类错误率低的关系类型的原则。设预测关系类型为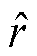 ,对应真实关系类型为r,其代价
,对应真实关系类型为r,其代价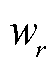 的计算式为
的计算式为
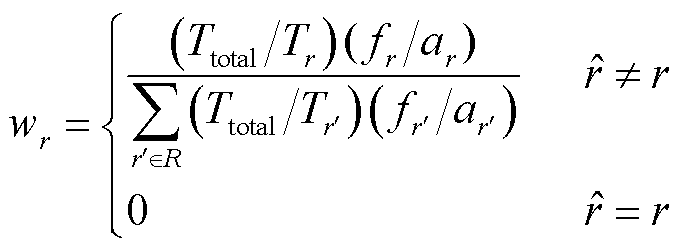 (12)
(12)
式中,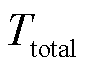 为数据集中三元组的数量;
为数据集中三元组的数量;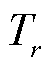 为关系类型为r的三元组数量;
为关系类型为r的三元组数量;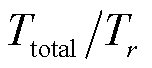 与关系三元组数量占总体的比例呈负相关;
与关系三元组数量占总体的比例呈负相关;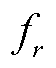 为关系r的错误分类数量;
为关系r的错误分类数量;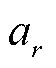 为预测为关系r的总数;
为预测为关系r的总数;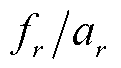 为预测为关系r的错误分类比例。从式(12)可以看出,某一关系类型三元组的代价由三元组所占比例以及错误分类率决定,错误分类率随着网络的训练结果每轮迭代。
为预测为关系r的错误分类比例。从式(12)可以看出,某一关系类型三元组的代价由三元组所占比例以及错误分类率决定,错误分类率随着网络的训练结果每轮迭代。
ISPN的输出为预测三元组集合,二分匹配[21]常用于寻找两个不相交集合的最大匹配,在电力领域中也被用于调度策略的制定[22]。为了得到边界回归算法中的候选实体,本文使用二分匹配为真实三元组找到最佳候选三元组,由最佳候选三元组与真实三元组组成的三元组对集合为最佳匹配。
本文基于提出的改进算法重新设计了基于二分匹配的损失。模型总体损失的计算具体可以分为两个步骤:最佳匹配查找和损失计算。
假设真实三元组集合Y大小为n,预测三元组集合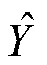 大小为m,最佳匹配查找旨在找到一个Y和的匹配,使得匹配代价最小,即找到使两个集合损失最小的匹配作为最佳匹配。计算最佳匹配时需要两个集合大小相等,由于m>n,在查找最佳匹配前需使用空集
大小为m,最佳匹配查找旨在找到一个Y和的匹配,使得匹配代价最小,即找到使两个集合损失最小的匹配作为最佳匹配。计算最佳匹配时需要两个集合大小相等,由于m>n,在查找最佳匹配前需使用空集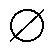 (表示非三元组)来填充真实三元组使其大小为m。
(表示非三元组)来填充真实三元组使其大小为m。
匹配结果可以通过匈牙利算法[23]得到,其形式为(预测三元组,真实三元组)的匹配对集合。图7为输变电设备故障数据的一个二分图匹配示例,得到匹配结果后计算预测三元组集合和真实三元组集
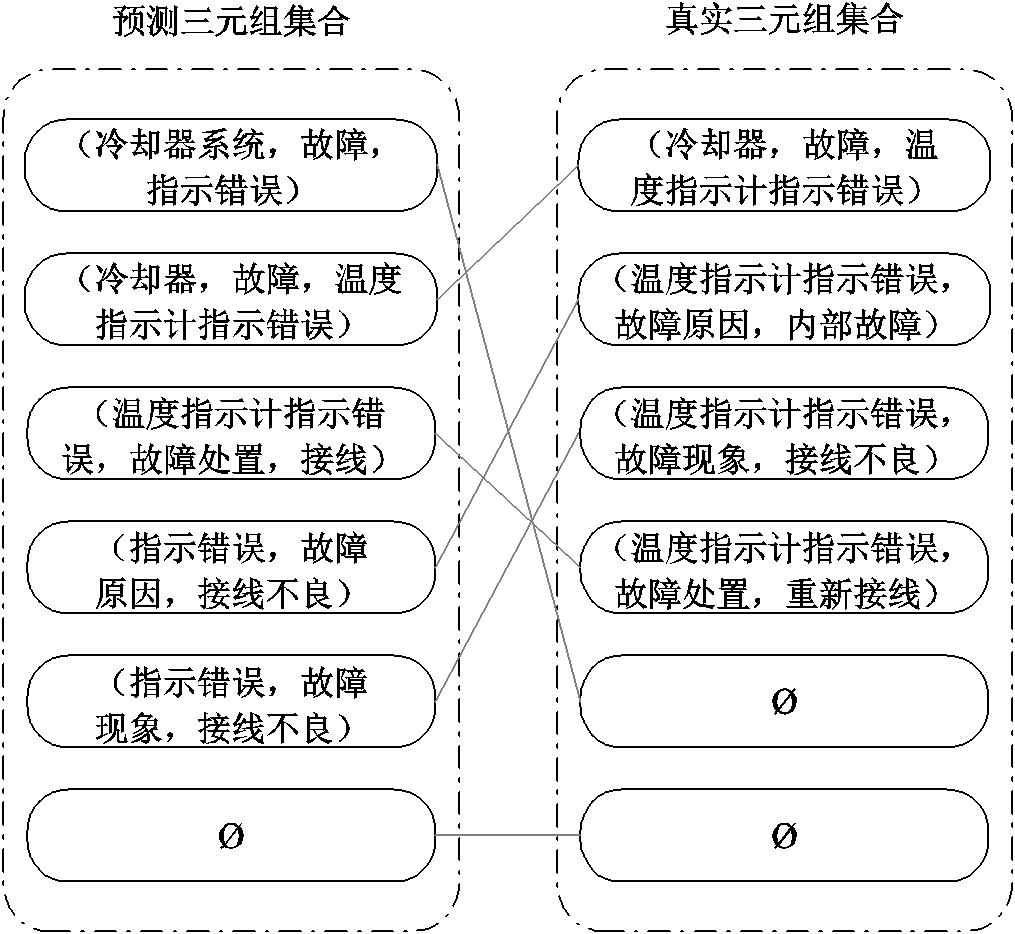
图7 输变电设备故障数据的二分图匹配示例
Fig.7 An example of bipartite graph matching fault data of transmission and transformation equipment
合之间的损失。设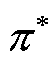 为最佳匹配,ISPN模型的损失计算公式为
为最佳匹配,ISPN模型的损失计算公式为
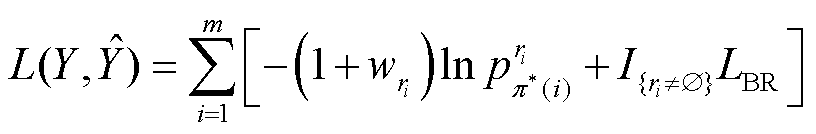 (13)
(13)
式中,模型的总体损失由关系分类损失和边界回归损失组成;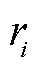 为预测集合第i个匹配对中关系的真实标签;
为预测集合第i个匹配对中关系的真实标签;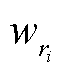 为关系类别的错误分类代价;
为关系类别的错误分类代价;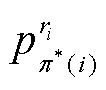 为最佳匹配中第i个匹配对
为最佳匹配中第i个匹配对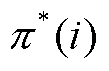 中的预测三元组对应的真实关系类型的置信度;I为指示函数,表示当关系
中的预测三元组对应的真实关系类型的置信度;I为指示函数,表示当关系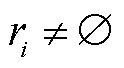 时,边界回归损失不为0。
时,边界回归损失不为0。
本文面向输变电设备故障场景进行了实验,以实际输变电设备故障巡检记录共8 626条作为联合抽取的数据集。实验时需要先对数据集进行标注,跨度标注解码简单高效且能很好地解决实体嵌套的问题,因此本文采用跨度标注生成数据集标签。跨度的结构如图4所示,仅需给出实体起始位置的索引。关系的标注格式为“头实体类型/关系类型/尾实体类型”,以三元组(冷却器,缺陷描述,温度指示器指示错误)为例,关系的标注为“部位/缺陷描述/缺陷描述”,可以看出在关系抽取的过程中包含了对实体类型的判断,无需单独设置实体类型分类模块。实验按照8:2的比例划分训练集和测试集。
本文模型基于Pytorch框架实现,选取基于中文预训练的BERT模型作为编码器。本文设置不同的dropout值进行实验,实验结果表明,当dropout值取0.2时,模型效果最好,因此后续的实验中将dropout值统一设置为0.2。训练时的批次大小设置为8,训练轮数epoch设置为50。为了简化训练,解码器的查询数量M设置为远大于文本中典型三元组数量的固定值。
本文对数据集每条数据的三元组数量进行了统计,最大三元组数量为22个,因此将输入三元组查询M的值设置为22。模型训练利用NVIDIA GeForce RTX 4060 Ti 8 G显卡进行加速,采用AdamW优化器进行梯度更新。
在实体关系抽取任务中,通常采用精确率、召回率以及综合精确率和召回率的F1值指标来衡量三元组抽取的效果。本文采用以上三个指标作为输变电设备故障数据集的评价指标。
实验中,预测三元组为正例的判定方式采用精确匹配,即该三元组的所有元素都预测正确才算一个正确的三元组。精确率为预测正确的三元组数量与预测出的三元组数量的比值,召回率为预测正确的三元组数量与真实三元组数量的比值,F1值为精确率和召回率的调和平均数。
6.3.1 消融实验
为了验证本文所提不同改进的有效性,本节在基线模型SPN上分别加入对比学习模块、边界回归算法以及代价敏感算法进行训练和测试。由于本文分别针对实体和关系进行改进,在消融实验中,同样计算实体的F1值和关系的F1值来说明改进的有效性,消融实验结果见表1。表1中,CL、BR、CSL分别代表模型加入对比学习算法、边界回归算法和代价敏感学习的改进。
表1 消融实验结果
Tab.1 Results of ablation experiment
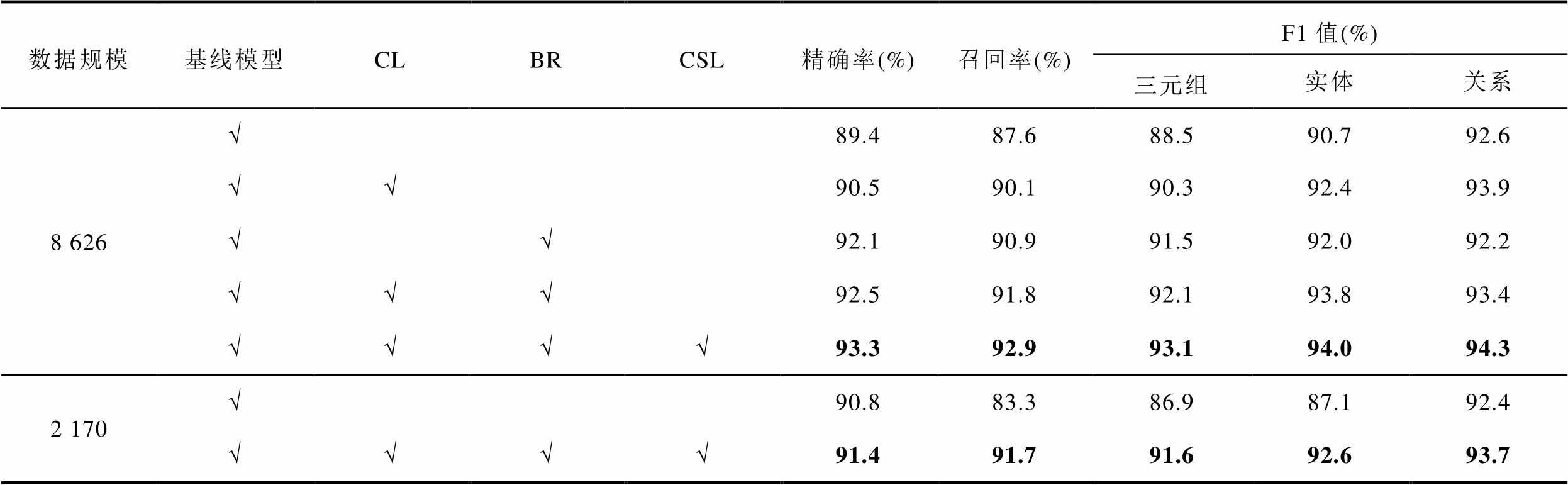
数据规模基线模型CLBRCSL精确率(%)召回率(%)F1值(%) 三元组实体关系 8 626√89.487.688.590.792.6 √√90.590.190.392.493.9 √√92.190.991.592.092.2 √√√92.591.892.193.893.4 √√√√93.392.993.194.094.3 2 170√90.883.386.987.192.4 √√√√91.491.791.692.693.7
从表1可以看出,在基线模型SPN的基础上分别加入不同的算法后,改进结果均有所提升。单独加入对比学习模块之后整体的精确率、召回率、F1值均高于SPN,说明该模块能够学习到比BERT更有效的特征用于下游抽取任务。单独加入边界回归算法后,实体的F1值相较于基线模型提升了1.3个百分点,精确率也有所提高,说明边界回归算法能够更准确地识别实体。
为了评估ISPN在与故障相关的不同关系类型上的分类性能,图8展示了ISPN和基线模型关系分类F1值的柱状图对比。结果显示,ISPN在提升长尾关系分类性能的同时并不会过多地影响其他三元组的分类效果,验证了本文模型对于解决长尾问题的有效性。
由于电力领域内数据收集较为困难,研究普遍基于较少的数据量,因此本文在小规模数据集上也进行了实验,结果见表1。从结果来看,在更小规模的数据集上,ISPN的性能仍然优于基线模型,且与大规模数据集的结果相比的降低幅度较小。
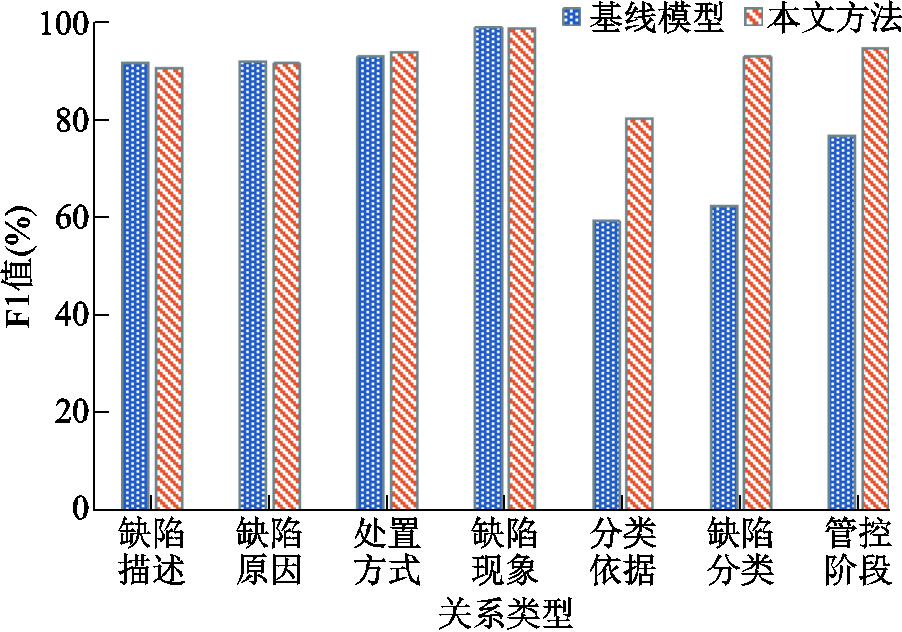
图8 不同关系类型的抽取性能对比
Fig.8 Comparison of extraction performance for different relationship types
6.3.2 对比实验
本节选取了以往联合抽取中具有良好表现的模型与本文模型进行对比,模型的参数设置为各个模型的原始参数。不同模型在本文数据集上的抽取性能对比见表2。
表2 不同模型在本文数据集上的抽取性能对比
Tab.2 Comparison of extraction performance of different models on the dataset
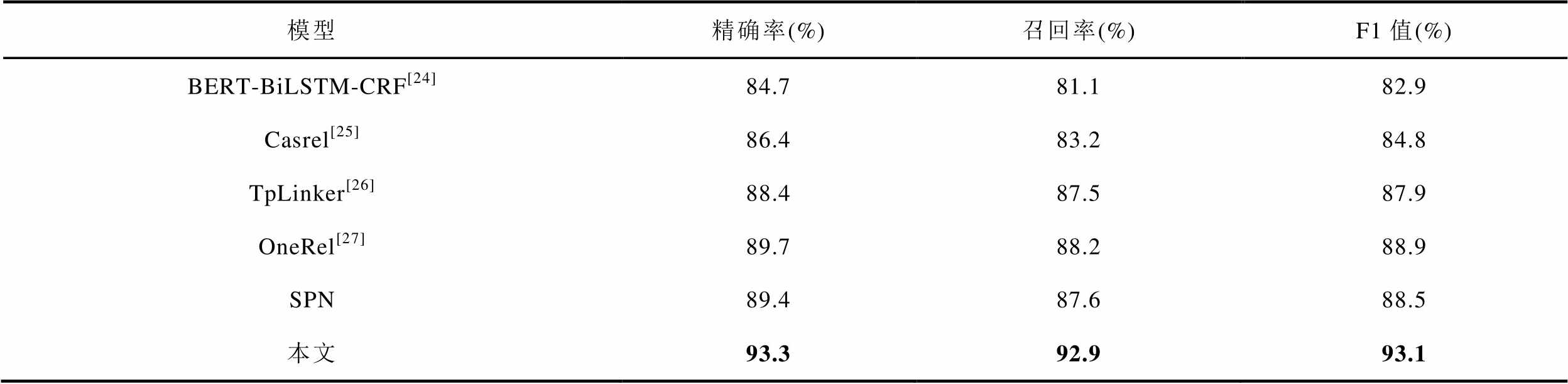
模型精确率(%)召回率(%)F1值(%) BERT-BiLSTM-CRF[24]84.781.182.9 Casrel[25]86.483.284.8 TpLinker[26]88.487.587.9 OneRel[27]89.788.288.9 SPN89.487.688.5 本文93.392.993.1
从评价指标来看,除了OneRel模型以外,本文所选基线模型SPN在输变电设备故障数据集上的表现相较于其他模型的表现更好。本文之所以选取SPN而不是OneRel作为基线模型的原因是,OneRel模型的训练速度和批量选择对于文本长度比较敏感,模型表现相对不稳定。
在本文数据集上的实验中,当文本长度大于50时,SPN的训练速度和OneRel没有明显区别,但SPN的性能更好,且SPN能够同时考虑到三元组集合大小和不同三元组之间的依赖。因此SPN更适合于电力领域这类长文本较多且重叠实体较多的场景。
此外,为了进一步评估本文模型在关系分类中的性能,绘制了基线模型与ISPN的精确率-召回率曲线进行对比,如图9所示。由图9可知,本文模型的精确率-召回率曲线基本在基线模型的上方,且平均精度(Average Precision, AP)值(曲线所包围的面积)更大,说明本文模型的关系分类效果较基线模型有所提升。
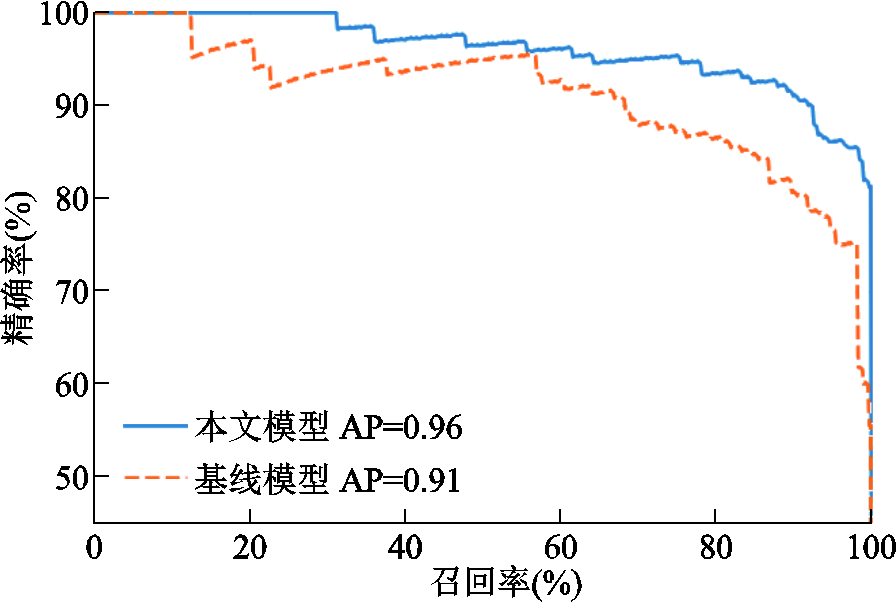
图9 基线模型和本文模型的精确率-召回率曲线
Fig.9 The precision-recall curves of baseline and the model
日常运维中产生的文本数据可能会包含一些噪声以及异常值和缺失值,为了评估模型的鲁棒性,本文人为地构建了包含噪声、头尾实体缺失、数值异常的文本进行测试,测试结果见表3。
表3 包含噪声、缺失值及异常值的测试结果
Tab.3 Test results containing noise, missing values and outliers

异常文本类型F1值(三元组)(%) 噪声91.2 缺失值92.9 异常值93.5
从测试结果来看,加入噪声后的测试结果有所下降,但下降幅度较小,而缺失值和异常值的结果和表1中的实验结果比较接近,说明本文模型在有缺失值和异常值的文本中仍然具有较好的性能。
本文面向输变电设备故障场景构建了知识图谱,并利用Neo4j数据库进行知识图谱的存储。Neo4j数据库遵循属性图模型来存储和管理数据,具有高效的节点和边存储以及查询能力。本文利用py2neo库进行知识图谱的存储,存储过程分为节点创建和关系创建,节点存储三元组中的实体名称及其类型,关系存储关系类型以及所关联的头尾实体对应的编号。
与关系数据库不同,Neo4j不仅能够以JSON的格式返回查询结果,还能够展示“节点-关系-节点”的可视化图结构,便于快速厘清数据之间的关系。
在Neo4j Browser中还可以插入自定义的CSS代码修改节点和关系的展示效果。返回结果中的节点和关系也可以通过点击进行交互,修改相关设置来优化知识图谱的可视化效果。
Neo4j数据查询使用Cypher语句,例如使用“MATCH (n)-[r]-(m) RETURN n, r, m”能够查询知识图谱的所有节点。图10展示了以上Cypher语句对输变电设备故障知识图谱进行查询的结果。

图10 输变电设备故障知识图谱的可视化展示
Fig.10 Visual display of fault knowledge graph for power transmission and transformation equipment
通过检索输变电设备故障知识图谱的相关数据能够认识输变电系统的整体结构,检索标签为“设备类型”的节点得到的层级结构如图11所示,图11中不同颜色代表设备的不同层级。通过设置灵活的查询条件,用户能够进行进一步的故障分析。
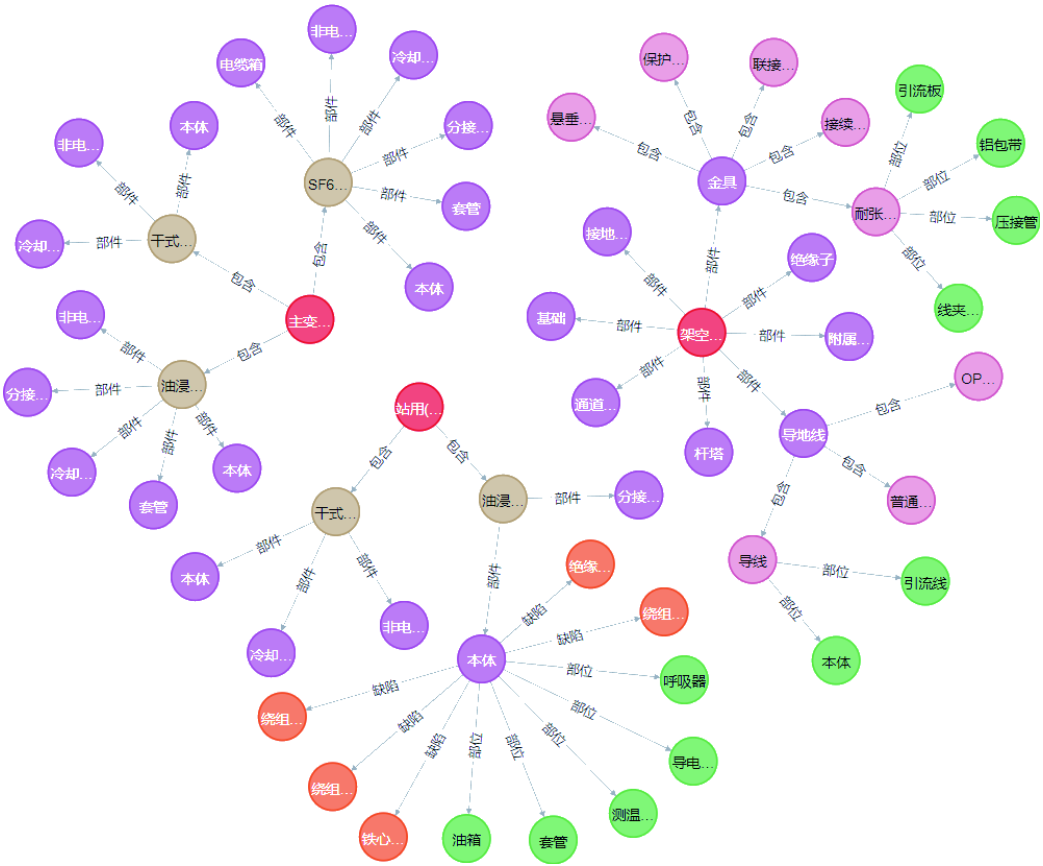
图11 检索标签为“设备类型”的节点得到的层级结构
Fig.11 Hierarchical structure obtained by searching nodes with the tag “device type”
本文面向输变电设备故障场景,对实体关系抽取算法进行了改进,提升了三元组抽取的准确度,并结合结构化数据和抽取结果构建了输变电设备故障知识图谱,进而利用Neo4j数据库对知识图谱进行了存储和可视化展示。
未来的工作将进一步提升实体关系抽取的效果并增强模型的泛化性,也将考虑研究可视化效果优化以及基于构建知识图谱的下游应用。
参考文献
[1] 田嘉鹏, 宋辉, 陈立帆, 等. 面向知识图谱构建的设备故障文本实体识别方法[J]. 电网技术, 2022, 46(10): 3913-3922.
Tian Jiapeng, Song Hui, Chen Lifan, et al. Entity recognition approach of equipment failure text for knowledge graph construction[J]. Power System Technology, 2022, 46(10): 3913-3922.
[2] Zhu Xiangru, Li Zhixu, Wang Xiaodan, et al. Multi-modal knowledge graph construction and application: a survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(2): 715-735.
[3] 卢奥煊, 季天瑶, 李梦诗, 等. 基于数学形态学和Pearson相关系数的风电变流器开路故障识别方法[J]. 电工技术学报, 2025, 40(11): 3446-3459.
Lu Aoxuan, Ji Tianyao, Li Mengshi, et al. Identification of open-circuit fault in wind power converter based on mathematical morphology and Pearson correlation coefficient[J]. Transactions of China Electrotech-nical Society, 2025, 40(11): 3446-3459.
[4] 蒲天骄, 谈元鹏, 彭国政, 等. 电力领域知识图谱的构建与应用[J]. 电网技术, 2021, 45(6): 2080-2091.
Pu Tianjiao, Tan Yuanpeng, Peng Guozheng, et al. Construction and application of knowledge graph in the electric power field[J]. Power System Technology, 2021, 45(6): 2080-2091.
[5] 张仰森, 刘帅康, 刘洋, 等. 基于深度学习的实体关系联合抽取研究综述[J]. 电子学报, 2023, 51(4): 1093-1116.
Zhang Yangsen, Liu Shuaikang, Liu Yang, et al. Joint extraction of entities and relations based on deep learning: a survey[J]. Acta Electronica Sinica, 2023, 51(4): 1093-1116.
[6] 郭榕, 杨群, 刘绍翰, 等. 电网故障处置知识图谱构建研究与应用[J]. 电网技术, 2021, 45(6): 2092-2100.
Guo Rong, Yang Qun, Liu Shaohan, et al. Constructionand application of power grid fault handing knowledge graph[J]. Power System Technology, 2021, 45(6): 2092-2100.
[7] 谢庆, 蔡扬, 谢军, 等. 基于ALBERT的电力变压器运维知识图谱构建方法与应用研究[J]. 电工技术学报, 2023, 38(1): 95-106.
Xie Qing, Cai Yang, Xie Jun, et al. Research on construction method and application of knowledge graph for power transformer operation and maintenance based on ALBERT[J]. Transactions of China Electro-technical Society, 2023, 38(1): 95-106.
[8] 何俊, 刘鹏, 聂勇, 等. 基于Seq2seq实体关系联合抽取的电力知识图谱构建[J]. 实验室研究与探索, 2022, 41(7): 1-5, 17.
He Jun, Liu Peng, Nie Yong, et al. Construction of knowledge graph of transmission regulation documents based on Seq2seq jonit extraction of entity relation[J]. Research and Exploration in Laboratory, 2022, 41(7): 1-5, 17.
[9] 束嘉伟, 杨挺, 耿毅男, 等. 面向电力知识图谱构建的重叠实体关系联合抽取方法[J]. 高电压技术, 2024, 50(11): 4912-4922.
Shu Jiawei, Yang Ting, Geng Yinan, et al. Joint extraction method for overlapping entity relationships in the construction of electric power knowledge graph [J]. High Voltage Engineering, 2024, 50(11): 4912-4922.
[10] Zhang Yingqiang, He Kejia, Xu Huifang, et al. Joint extraction of entity relations in electric power industry standard based on GCN[C]//2023 IEEE 6th International Electrical and Energy Conference (CIEEC), Hefei, China, 2023: 1249-1254.
[11] Sui Dianbo, Zeng Xiangrong, Chen Yubo, et al. Joint entity and relation extraction with set prediction networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 35(9): 12784-12795.
[12] Ziv A, Gat I, Le Lan G, et al. Masked audio generation using a single non-autoregressive transformer[J/OL]. ArXiv, 2024: 2401.04577[2024-10-30]. https://arxiv. org/abs/2401.04577v2.
[13] 汤健, 侯慧娟, 盛戈皞, 等. 变压器不平衡样本故障诊断的过采样和代价敏感算法[J]. 高压电器, 2023, 59(6): 93-102.
Tang Jian, Hou Huijuan, Sheng Gehao, et al. Oversampling and cost-sensitive algorithm for transformer fault diagnosis with unbalanced samples [J]. High Voltage Apparatus, 2023, 59(6): 93-102.
[14] 雷蕾潇, 何怡刚, 姚其新, 等. 基于变权属性矩阵的变压器零样本故障诊断技术[J]. 电工技术学报, 2024, 39(20): 6577-6590.
Lei Leixiao, He Yigang, Yao Qixin, et al. Zero-shot fault diagnosis technique of transformer based on weighted attribute matrix[J]. Transactions of China Electrotechnical Society, 2024, 39(20): 6577-6590.
[15] Wang Jiajia, Huang J X, Tu Xinhui, et al. Utilizing BERT for information retrieval: survey, applications, resources, and challenges[J]. ACM Computing Surveys, 2024, 56(7): 1-33.
[16] Tang Shunpu, Yang Qianqian, Fan Lisheng, et al. Contrastive learning-based semantic communications [J]. IEEE Transactions on Communications, 2024, 72(10): 6328-6343.
[17] Gao Tianyu, Yao Xingcheng, Chen Danqi. SimCSE: simple contrastive learning of sentence embeddings [C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 2021: 6894-6910.
[18] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//Computer Vision - ECCV 2020, Glasgow, UK, 2020: 213-229.
[19] 刘传洋, 吴一全, 刘景景. 无人机航拍图像中绝缘子缺陷检测的深度学习方法研究进展[J]. 电工技术学报, 2025, 40(9): 2897-2916.
Liu Chuanyang, Wu Yiquan, Liu Jingjing. Research progress of deep learning methods for insulator defect detection in UAV based aerial images[J]. Transactions of China Electrotechnical Society, 2025, 40(9): 2897-2916.
[20] Benítez-Peña S, Blanquero R, Carrizosa E, et al. Cost-sensitive probabilistic predictions for support vector machines[J]. European Journal of Operational Research, 2024, 314(1): 268-279.
[21] Asratian A S, Denley T M J, Häggkvist R. Bipartite Graphs and Their Applications[M]. Cambridge: Cambridge University Press, 1998.
[22] 万海洋, 刘文霞, 石庆鑫, 等. 城市电网灾后应急资源的集中匹配-分布调度策略[J]. 电工技术学报, 2024, 39(23): 7463-7480.
Wan Haiyang, Liu Wenxia, Shi Qingxin, et al. A post-disaster centralized matching and decentralized dispatch strategy for emergency resources in urban power network[J]. Transactions of China Electro-technical Society, 2024, 39(23): 7463-7480.
[23] 梁喻, 陈明明, 刘凡. 利用改进匈牙利算法求解旅行商问题[J]. 科学技术与工程, 2024, 24(14): 5920-5927.
Liang Yu, Chen Mingming, Liu Fan. Improvd Hungarian algorithm for solving problem of travel providers[J]. Science Technology and Engineering, 2024, 24(14): 5920-5927.
[24] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, California, 2016: 260-270.
[25] Wei Zhepei, Su Jianlin, Wang Yue, et al. A novel cascade binary tagging framework for relational triple extraction[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 2020: 1476-1488.
[26] Wang Yucheng, Yu Bowen, Zhang Yueyang, et al. TPLinker: single-stage joint extraction of entities and relations through token pair linking[C]//Proceedings of the 28th International Conference on Computational Linguistics, Online, 2020: 1572-1582.
[27] Shang Yuming, Huang Heyan, Mao Xianling. OneRel: joint entity and relation extraction with one module in one step[C]//Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2022: 11285-11293.
Abstract With the intelligent transformation and upgrading of power grids, higher requirements have been put forward for the analysis and maintenance of power system operation status. As an important part of the power grid, power transmission and transformation equipment may cause unpredictable losses in case of failure. Knowledge Graph describes concepts, entities and their relationships in the objective world in a structured form, providing a tool for better organizing, managing and understanding information from different sources and structures, so the introduction of knowledge in transmission and transformation equipment management and troubleshooting is conducive for professionals to quickly locate fault information and make effective decisions.
To effectively integrate the scattered knowledge related to power transmission and transformation and improve the quality of knowledge graph construction of power transmission and transformation equipment faults, this paper carried out the knowledge graph construction based on the relevant specification manuals of power transmission and transformation, and further improves the entity-relationship extraction algorithm. Existing entity-relationship extraction methods in the power field ignore the connection between triples and have problems of weak text representation, vague entity localization, and low accuracy of classification of long-tail relationships. In response to the above, this paper proposed a joint entity-relationship extraction model based on the improved set prediction network (ISPN). The set prediction network (SPN) is used to model the overall triples, which introduces unsupervisSed contrast learning to BERT encoder for enhanced text representation. The enhanced text representation is then fed into a decoder to guide triple queries to learn potential triple features in the text. The triple queries contain global and boundary features to capture information at different scales. The prediction triples are obtained by the feed forward neural network. In order to improve the performance of entity boundary identification, this paper proposes to use boundary regression algorithm to model the boundary offset of entities, which uses decoder output features to predict the start and end index offset of head and tail entities firstly, then the candidate triples are obtained according to the binary matching algorithm, finally correct the entity boundaries according to the boundary regression formulae, and also use the boundary loss instead of the cross-entropy loss in total loss. In the relationship classification stage, cost-sensitive learning is introduced to balance the losses of different types of triples, and the classification accuracy of long-tail relationships is improved by assigning larger loss weights to long-tail relationships as well as those with high misclassification rates to facilitate the model to effectively learn the features of long-tailed relationships. The redesigned binary matching loss is used to model the difference between the predicted set and the true set and optimize the model training.
A knowledge graph was constructed based on the proposed model ISPN on a real transmission and substation equipment fault dataset. The precision, recall and F1 score of the entity-relationship extraction experiments are improved by 3.9, 5.3 and 4.6 percentage points over the model, respectively. The constructed knowledge graph is stored and visualized using the Neo4j graph database, in which the structured stored fault information can provide support for subsequent fault processing and decision analysis.
Keywords:Power transmission and transformation equipment, knowledge graph, joint extraction, contrastive learning, bounding regression
中图分类号:TM72; TP391.1
DOI: 10.19595/j.cnki.1000-6753.tces.241362
国家自然科学基金(62373148)和中央高校基本科研业务费专项资金(2022JG004)资助项目。
收稿日期 2024-08-01
改稿日期 2024-11-04
阎光伟 男,1971年生,副教授,硕士生导师,研究方向为计算机图形/图像技术在电力系统中的应用。
E-mail:yan_guang_wei@126.com(通信作者)
张云馨 女,2000年生,硕士研究生,研究方向为知识图谱在电力系统中的应用。
E-mail:yunxinzhang@ncepu.edu.cn
(编辑 李 冰)