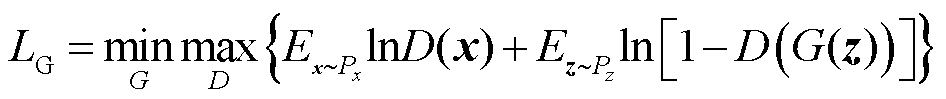 (1)
(1)
摘要 目前基于机器学习的覆冰诊断方法需要依赖大量的时间序列数据进行建模预测,在实际工作过程中,由于受到设备和工作条件的影响,收集足够多的覆冰样本监测数据非常困难,这导致数据不平衡的问题普遍存在。因此,该文提出了一种融合诊断模型,该模型结合条件表格生成对抗网络(CTGAN)和轻量梯度提升网络(LightGBM),用于生成合成样本并进行覆冰诊断。首先,基于滑动窗口算法在原有特征的基础上,进一步构建新的混合特征;其次,利用CTGAN模型学习真实样本的数据分布,通过生成器和判别器对抗训练达到纳什平衡,生成与真实样本相似的新样本;再次,将合成样本输入LightGBM中以提取有效特征进行覆冰诊断,并通过引入焦点损失函数修正LightGBM模型,提高模型区分混淆样本的能力;然后,利用沙普利加性解释(SHAP)归因理论对覆冰影响因素进行分析;最后,基于真实风机数据集设计了多组不平衡样本实验,结果表明:该文所提出的融合诊断模型即使在训练样本数量较少的情况下,其诊断准确率依然保持在0.942,优于现有多种分类诊断模型,可为提高风机安全性和运维效率提供重要的技术支持。
关键词:风机叶片 样本不平衡 生成对抗网络 覆冰诊断 可解释性
随着“碳达峰·碳中和”目标的稳步推进,我国能源结构不断优化,风电产业发展势头迅猛,资源布局从初期的“三北”(东北、西北、华北)地区逐步转移至中东部风能资源较好的高山地区。而冬季的低温和高湿环境极易造成风机叶片结冰,严重影响风力发电机的实际功率输出和安全运行[1]。为避免因覆冰导致的疲劳荷载加剧、机组零部件振动等问题,风电场需根据叶片的结冰情况及时执行停机策略。因此,叶片结冰状态的准确识别成为维护冬季风电机组安全运行的重点之一[2]。
目前风机叶片覆冰诊断方法有直接法与间接法。直接法主要通过在叶片周围安装监测装置从而采集叶片的结冰情况,包括温湿度传感器[3]、图像采集设备[4]、电容监测装置[5]、超声波传感器[6]、分布式光纤传感技术[7]、红外辐射测量技术[8]、高光谱成像设备[9]等。然而直接法往往需要高精度传感器采集特征信息,且覆冰环境下传感器设备极易出现冻结现象,从而无法准确地获取叶片覆冰情况[10]。
间接法是通过建立风机数据采集与监视控制(Supervisory Control and Data Acquisition, SCADA)系统中运行数据与结冰故障之间的非线性映射关系,从而获取叶片覆冰状态信息。该方法区别于受恶劣环境条件影响较大的直接法,被认为是一种更有应用前景的风电机组叶片结冰故障检测技术[11]。文献[12]使用递归特征消除和交叉验证方法分析了各种SCADA特征对诊断模型的影响程度,从而有效地提高了模型的分类精度。文献[13]提出了一种时空注意力模型,根据不同时空特征对叶片结冰检测的贡献程度分配权重,并基于真实风机数据集验证了诊断模型的优越性。文献[14]提出了一种基于时空对准迁移学习方法的覆冰诊断模型。该模型采用大量SCADA数据驱动,引入新的损失函数来解决不同机组数据差异性的问题,使得该覆冰诊断模型具有跨机组普适性。文献[15]通过提取叶片覆冰的短期特征和长期特征,基于集成学习算法和极端梯度提升(Extreme Gradient Boosting, XGBoost)算法,构建了叶片覆冰快速诊断模型。文献[16]基于样本分布信息构建了一种新型自适应加权策略,将自适应加权策略与传统的固定加权策略相结合,提出了自适应加权核极限学习机叶片结冰诊断模型。然而,由于受到设备和工作条件的影响,收集足够多的覆冰样本监测数据非常困难,这导致数据不平衡的问题普遍存在,给建立准确的覆冰诊断模型带来了极大的挑战。
合成少数类过采样技术(Synthetic Minority Oversampling Technique, SMOTE)作为一种再采样方法,利用随机线性插值在少数类样本与其最近邻之间创建新样本,可作为挖掘原始样本特点、扩展样本数量的一种简易手段[17-18],但该算法并不适合处理大规模样本,且生成的合成样本质量较低。相对于SMOTE算法,生成式对抗网络(Generative Adversarial Networks, GAN)通过生成器和判别器不断地对抗训练,从而生成高质量的合成样本,可有效地解决样本不平衡的问题[19]。文献[20]利用GAN和模型迁移技术,实现了对不同运行方式样本的快速生成。文献[21]结合变分自动编码器和GAN,实现了对电池退化数据的增强,提高了电池剩余寿命的预测效果。然而,传统的GAN生成模型训练时间较长且容易出现失稳等问题,因此,在GAN基础上出现了条件生成式对抗网络(Conditional GAN, CGAN)[22]、引入Wasserstein距离生成式对抗网络(Wasserstein GAN, WGAN)[23]、带梯度惩罚的 Wasserstein 生成式对抗网络(WGAN with Gradient Penalty, WGANGP)[24]等多种变体模型,在图像识别[25-26]和故障诊断[27-28]等领域被广泛应用。文献[29]将卷积注意力模块与改进生成式对抗网络相结合,提高了模型的特征提取能力,解决了样本数据不平衡导致的暂降事件辨识失效问题。文献[30]利用改进生成式对抗网络实现对风机故障样本数据的增强,有效地提升了故障诊断模型的整体分类能力。可见,GAN类模型在故障识别与诊断方面具有显著的优势。
综上所述,本文基于生成式对抗网络数据增强能力优异的特点,针对风机叶片覆冰样本监测数据缺乏导致的覆冰诊断精度较低的问题,提出了一种基于条件表格生成式对抗网络(Conditional Tabular Generative Adversarial Networks, CTGAN)和轻量梯度提升网络(Light Gradient Boosting Machine, LightGBM)的融合诊断模型。首先,通过滑动窗口算法构建混合特征;其次,利用CTGAN模型学习真实样本的分布情况,从而生成与真实样本相似的合成样本;再次,基于LightGBM模型提取样本中的有效特征信息,并引入焦点损失(Focal Loss)函数修正LightGBM模型,提高模型区分混淆样本的能力;然后,利用沙普利加性解释(SHapley Additive exPlanations, SHAP)归因理论对覆冰影响因素进行分析;最后,在多组不平衡样本实验中证明本文所提模型的有效性。
生成式对抗网络来源于博弈论中“零和博弈”的思想,其主要包含两个模型:生成模型和判别模型。在训练过程中,生成模型的目标是让所生成数据的分布接近真实数据分布;而判别模型的目标是尽可能地找出生成模型所生成的数据与真实数据分布之间的差异。生成模型和判别模型构成了一个动态的“博弈过程”,最终平衡点即为纳什平衡点。GAN的损失函数具体表达式为
(1)
式中,E(·)表示期望值;x为任意真实数据,x~Px表示真实数据服从Px分布;z为随机噪声数据,z~Pz表示随机噪声数据服从Pz分布;G(z)为在生成器G中基于z生成的伪数据;D(x)为判别器D在真实数据x上判断出的结果;D(G(z))为判别器D在伪数据G(z)上判断出的结果。通过先固定生成器,从判别器的角度令损失最大化,再固定判别器,从生成器的角度令损失最小化,即可让判别器和生成器在共享损失的情况下实现对抗。判别器和生成器的反馈和迭代优化,使得GAN具有较强的数据增强能力。
CTGAN是一种基于条件概率合成表格数据的生成网络,通过引入条件变量不断地训练生成器和判别器,直到生成高质量的伪数据。相比传统的GAN,CTGAN采用了条件生成器和条件判别器的方式,可有效地解决类别不平衡的问题,并通过设计一种模式特定规范化来解决梯度消失的问题。假设原始数据样本中含有Nc列连续特征和Nd列离散特征,分别记作{C1,C2,…,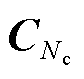 }和{D1,D2,…,
}和{D1,D2,…, 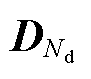 },样本数为n,则第j行样本可表示为
},样本数为n,则第j行样本可表示为
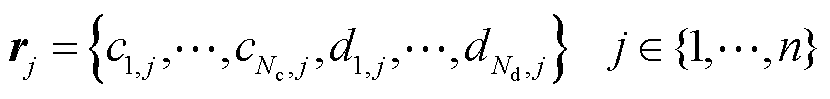 (2)
(2)
首先,对于样本中每个连续特征Ci,使用变分高斯混合模型估计其中单一模式分布的数量,模型可以表示为
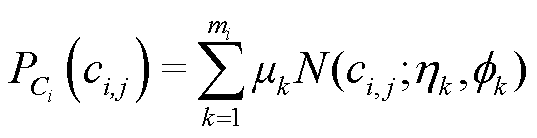 (3)
(3)
式中,N(·)为高斯混合模型;mi为第i个连续特征的模式数量;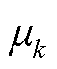 和
和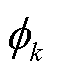 分别为第k个模式的权重与标准差波动;
分别为第k个模式的权重与标准差波动;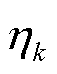 为第k个模式所发生的概率。
为第k个模式所发生的概率。
其次,对于Ci中的每个值ci,j,计算其在每个模式分布下的概率,概率密度计算式为
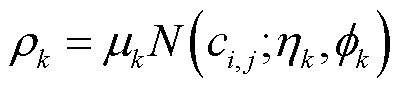 (4)
(4)
最后,从给定的概率密度中抽取一个模式并进行模式规范化,特征中的每一个值都由采样模式所属的独热向量和模式归一化值进行表示。采用αi,j和βi,j分别表示模式分布内的值与所选中模式分布的序号。例如,当模式数量mi=3时,则高斯混合模型中有三种模式,若选中第3个模式,则αi,j和βi,j计算式为
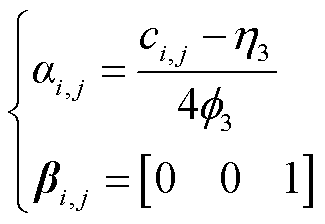 (5)
(5)
式中,βi,j为独热编码模式。则最终样本数据可表示为
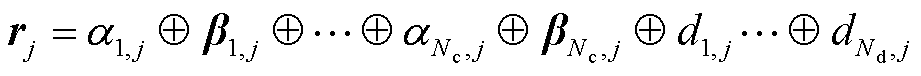 (6)
(6)
式中,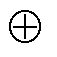 为数学定义中的拼接操作。
为数学定义中的拼接操作。
在特定模式下将数据进行规范化后,利用CTGAN的条件生成器和条件判别器合成样本数据,在生成器和判别器中均使用两个完全连接的隐藏层。条件生成器网络结构表达式为
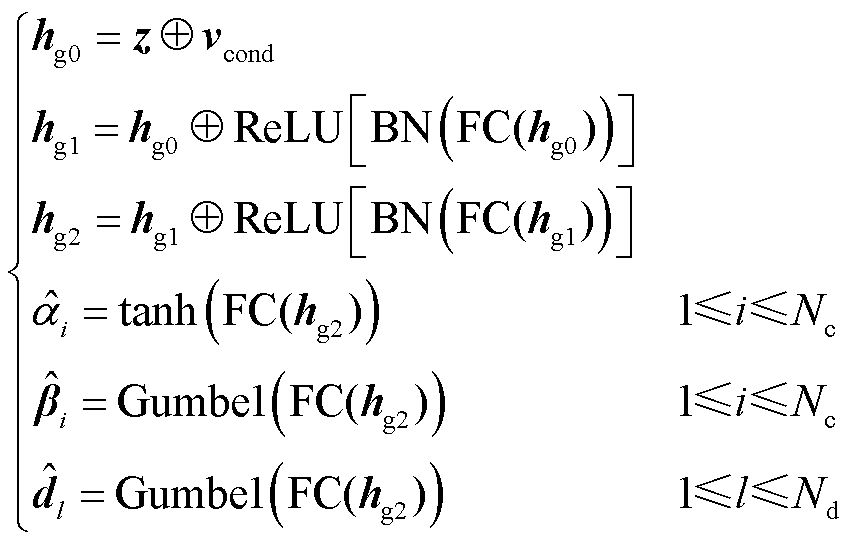 (7)
(7)
式中,vcond为条件向量;条件生成器采用两层全连接(Full Connection, FC)层,每一个连接层含批量归一化(Batch normalization, BN)层和ReLU激活层;Gumbel(·)为Gumbel Softmax函数;标量值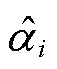 由tanh激活函数生成;模式指示符
由tanh激活函数生成;模式指示符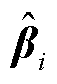 和离散数据
和离散数据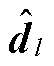 都由Gumbel Softmax激活函数生成。最终生成模型输出的值与规范化后的真实样本一同输入判别模型。条件判别器网络结构表达式为
都由Gumbel Softmax激活函数生成。最终生成模型输出的值与规范化后的真实样本一同输入判别模型。条件判别器网络结构表达式为
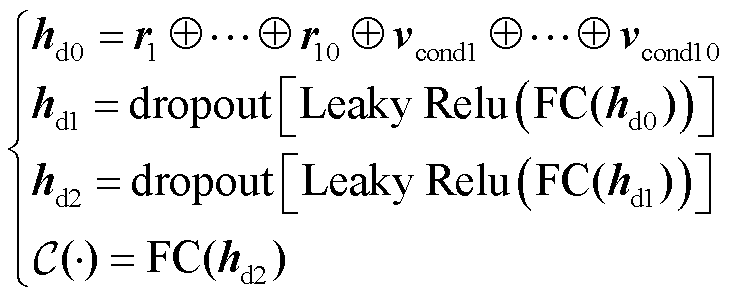 (8)
(8)
其中,为减少计算复杂度,每次取10个样本的条件向量作为输入;全连接层使用Leaky Relu作为激活函数,从而避免梯度消失现象;此外,模型还使用了dropout层,有效地缓解了过拟合现象;最后,模型输出样本为真的概率值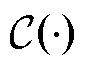 。
。
LightGBM模型由梯度提升决策树(Gradient Boosting Decision Tree, GBDT)发展而来,基于直方图算法对连续特征值进行离散化,然后对离散值进行统计并构造直方图,通过遍历直方图寻找最优分割点。直方图算法如图1所示。此外,LightGBM模型采用按叶生长策略,不同于XGBoost模型的按层生长策略,LightGBM模型在当前叶子中寻找分裂增益最大的叶子进行分裂,有效地降低了模型的复杂度,提高了训练速度。生长策略示意图如图2所示。
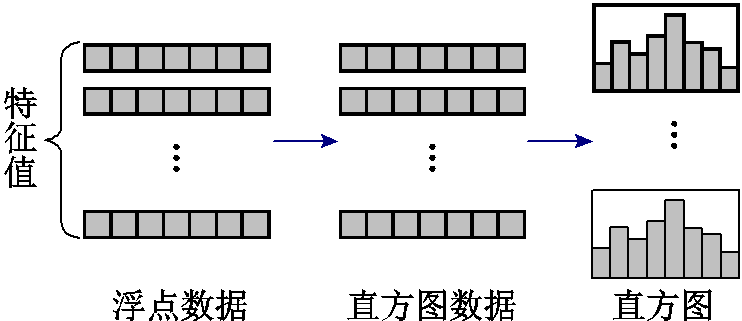
图1 直方图算法
Fig.1 The histogram algorithm
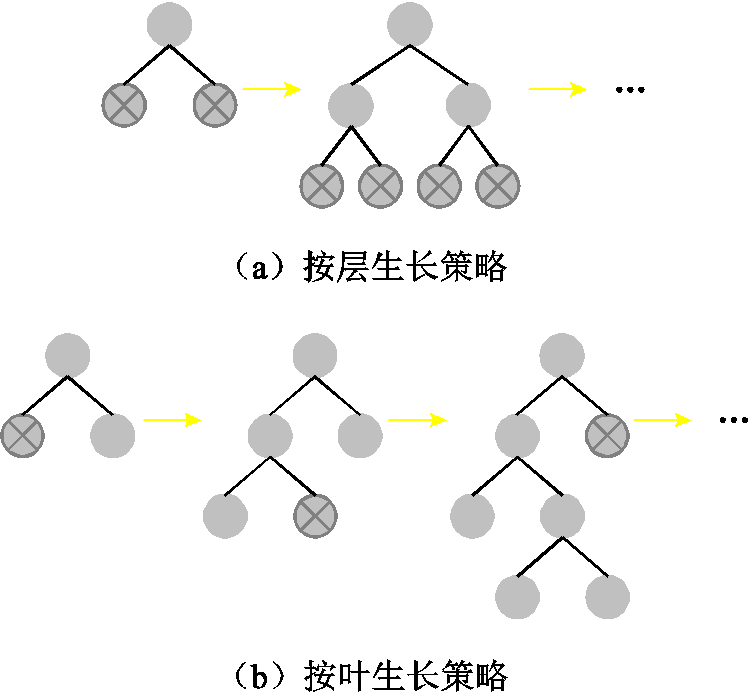
图2 生长策略示意图
Fig.2 Schematic growth strategy
假设输入模型中的训练集样本表示为X= 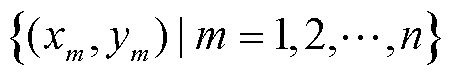 ,根据助推框架集成策略,第
,根据助推框架集成策略,第
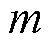 个样本的预测输出
个样本的预测输出
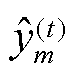 可表示为
可表示为
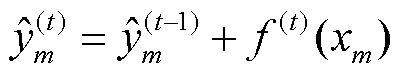 (9)
(9)
式中,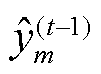 为前
为前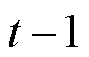 次训练出来的模型所得到的预测值;
次训练出来的模型所得到的预测值;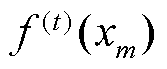 为第t次训练中抑制模型得到的预测值。
为第t次训练中抑制模型得到的预测值。
模型的目标函数可由损失函数LL与抑制模型复杂度的正则项Ω组成,其计算式为
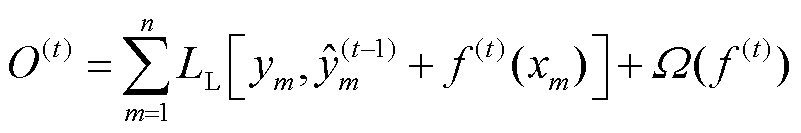 (10)
(10)
其中,模型的复杂度Ω由叶子数量T和每个叶子节点输出结果的平方和组成,即
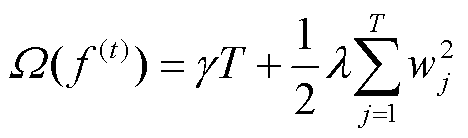 (11)
(11)
式中,γ为加入新叶子节点的代价;λ为正则化系数;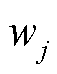 为第j个叶子节点的权重。将上述目标函数式(10)进行二阶泰勒展开可得到
为第j个叶子节点的权重。将上述目标函数式(10)进行二阶泰勒展开可得到
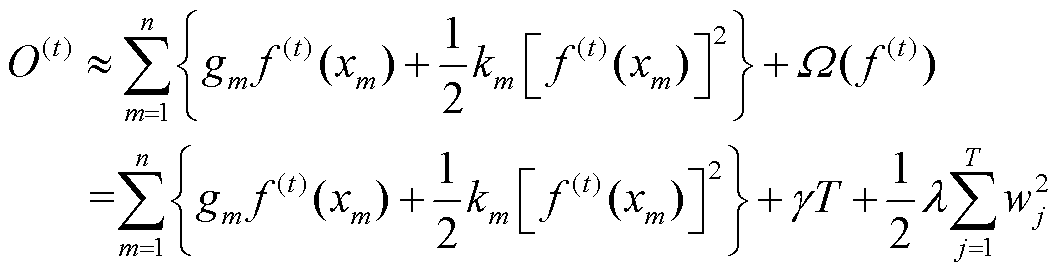 (12)
(12)
式中,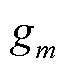 和
和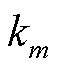 分别为损失函数的一阶导数和二阶导数,其表达式分别为
分别为损失函数的一阶导数和二阶导数,其表达式分别为
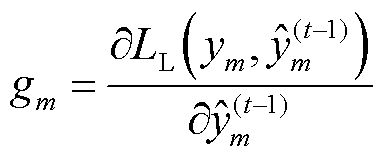 (13)
(13)
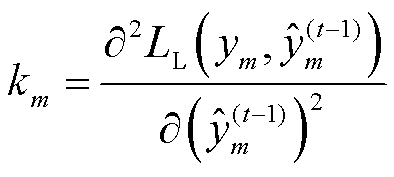 (14)
(14)
遍历所有叶子节点,得到每个叶子节点的损失值,从而得到最终目标函数为
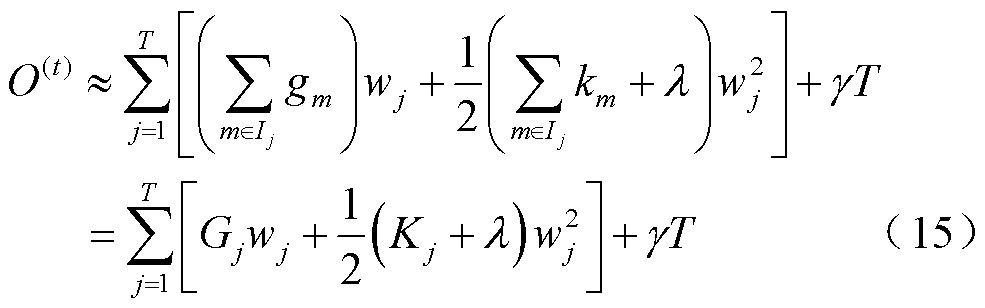
式中,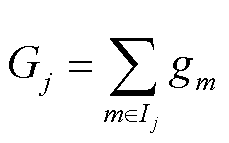 ;
;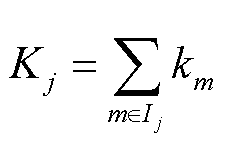 ;
;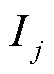 为第
为第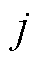 个叶子节点的样本集合。将目标函数对求一阶导数,当目标函数最小时,的取值为
个叶子节点的样本集合。将目标函数对求一阶导数,当目标函数最小时,的取值为
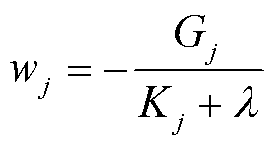 (16)
(16)
则目标函数可以简化为
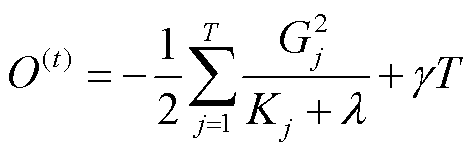 (17)
(17)
通过分裂树节点,利用增益函数计算分裂后的增益。增益值越大说明分裂效果越好,增益函数表达式为
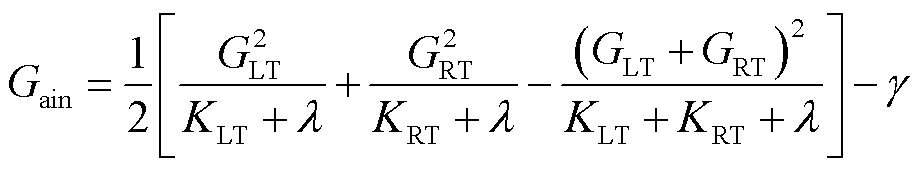 (18)
(18)
式中,下标“LT”和“RT”分别为分割后的左、右子树样本集。因此,在模型训练过程中,通过计算各个树节点损失选择增益最大的节点。
焦点损失(Focal Loss)函数是在交叉熵函数基础上演变而来,通过增加不稳定易混淆样本的权重,来提高模型的分类精度,其计算公式为
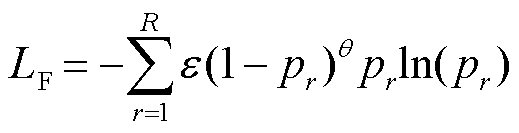 (19)
(19)
式中,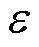 为权重参数;θ为聚焦参数,均用于平衡易混淆样本的权重;
为权重参数;θ为聚焦参数,均用于平衡易混淆样本的权重;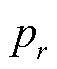 为模型对类别r的预测概率;R为总类别数量。当θ = 0时,焦点损失函数即退化为交叉熵损失函数,θ值越大,对易混淆样本的惩罚力度越大。总体而言,通过调整焦点损失函数中的和θ值,增加了易混淆样本在损失函数的权重,使模型更加关注不稳定样本,从而提高模型的分类精度。
为模型对类别r的预测概率;R为总类别数量。当θ = 0时,焦点损失函数即退化为交叉熵损失函数,θ值越大,对易混淆样本的惩罚力度越大。总体而言,通过调整焦点损失函数中的和θ值,增加了易混淆样本在损失函数的权重,使模型更加关注不稳定样本,从而提高模型的分类精度。
SHAP归因理论是一种解决模型可解释性的方法,通过计算源自合作博弈论中的SHAP值来评估各个特征值对因变量的重要程度。该方法将每个特征值视作贡献者,并聚合各个特征值的贡献值形成模型的最终预测。SHAP值计算公式为
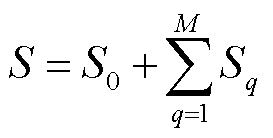 (20)
(20)
式中,S为模型输出的值;S0为模型的基线值;M为特征数量;Sq为第q个特征值的贡献程度。若Sq为正值,则表示该特征对模型预测值具有正向作用;若为负值,则其具有负向作用。
本文建立了基于CTGAN和LightGBM(Focal Loss)的融合诊断模型,以解决小样本数据下的覆冰诊断问题。风机叶片覆冰诊断流程如图3所示。主要包括数据预处理、复合特征构建、小样本数据生成以及覆冰诊断与可解释性分析,具体实施流程如下。
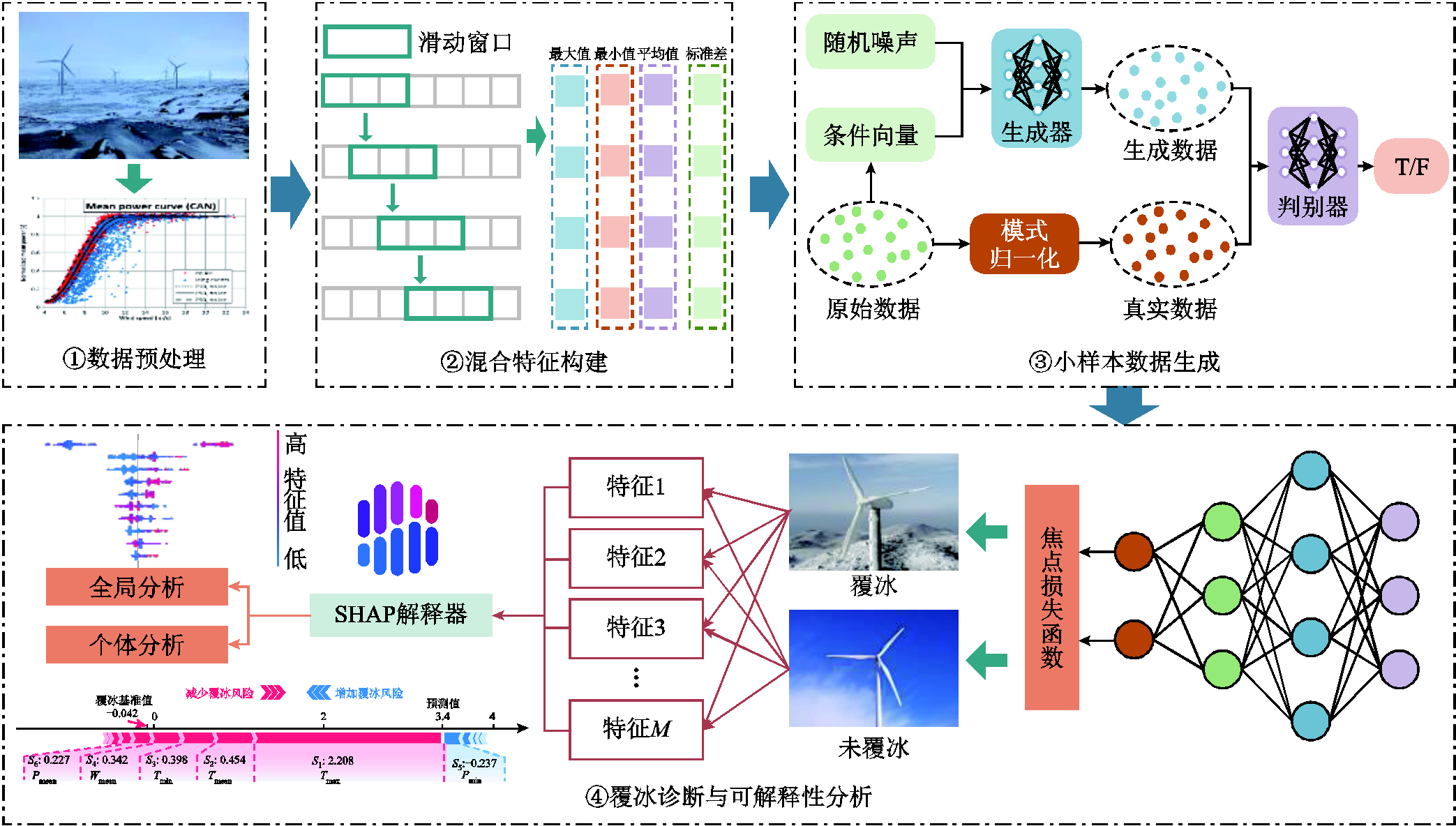
图3 风机叶片覆冰诊断流程
Fig.3 Diagnosis process for icing on wind turbine blades
1)数据预处理:收集原始风机覆冰样本作为实验数据集,并对数据集进行归一化处理,归一化使得后续的模型训练更易于收敛。
2)混合特征构建:在原有特征的基础上,基于滑动窗口算法进一步提取新的混合特征,增加了各参数在滑动窗口内的平均值、标准差、最大值以及最小值时序统计特征。
3)小样本数据生成:将特征升维后的数据集划分为训练集和测试集。首先通过改变不平衡率选取不同数量的真实覆冰样本数据进行实验验证,其中训练集由真实样本和生成样本组成,测试集均由真实样本组成;然后将随机噪声向量输入生成器中,经过对抗训练生成与覆冰样本相似的数据,并将生成数据与真实数据输入判别器中进行判别,直到训练过程达到纳什平衡,生成与原始样本具有相似分布的伪样本;最后将原始样本与生成的伪样本组合形成新的混合样本。
4)覆冰诊断与可解释性分析:将数据增强后的合成样本输入分类器模型中进行训练,提取混合样本中有效的特征信息;然后用训练完成的模型对测试集数据进行覆冰诊断;最后利用SHAP理论对模型诊断结果进行分析。
采用中国重庆某实际风电场覆冰数据集进行相关实验验证,时间分辨率为1 min。同时,为了证明本文所提样本生成模型的数据增强效果,利用多种先进样本生成模型进行对比分析,包括GAN、CGAN、WGANGP以及Copula GAN。在模型诊断阶段,采用逻辑回归(Logistic regression)、 K近邻算法(K-Nearest Neighbor, KNN)、支持向量机(Support Vector Machine, SVM)、GBDT以及XGBoost等模型进行对比实验。为了保证实验的一致性,所有模型都采用相同的样本集和实验环境。本文分类模型的超参数均采用默认值,经过多次实验测试,将时间滑动窗口设置为30,焦点损失函数中和θ分别设置为0.15和2.0。
原始数据中仅包含环境温度、风速及有功功率三个维度的特征信息,特征信息过少,容易造成模型训练效果较差。由于叶片结冰是缓慢累积的时序过程,因此,同一特征存在明显的时序相关性。为了提高模型的整体诊断效果,本文在原有特征的基础上,基于滑动窗口算法进一步提取新的混合特征,增加了各参数在滑动窗口内的平均值、标准差、最大值以及最小值时序统计特征。各模型基于原始特征和混合特征覆冰诊断对比结果如图4所示。
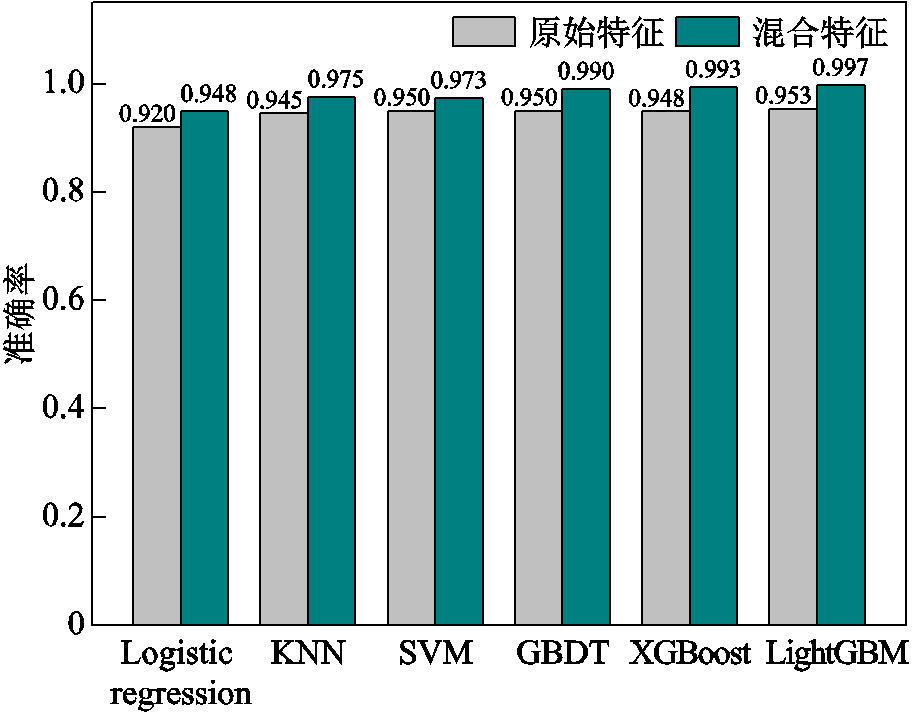
图4 原始特征和混合特征覆冰诊断对比结果
Fig.4 Comparison results of ice diagnosis between original and hybrid features
由图4可知,在采用混合特征后,所有算法的诊断准确率均有一定的提升效果,各个模型的诊断准确率较原始特征分别提升了3.04%、3.17%、2.42%、4.21%、4.75%和4.62%。从最终分类效果可以看出,本文所提出的LightGBM算法在采用混合特征后,相较于其他算法具有优异的分类效果,覆冰诊断准确率为0.997。结果表明,本文所构造的混合特征与LightGBM模型在覆冰诊断问题上具有明显的优势。
采用Wasserstein距离和最大均值差异距离以评估真实样本与生成样本的相似性,用于检验所提模型拟合真实数据分布的能力,评价指标计算公式为
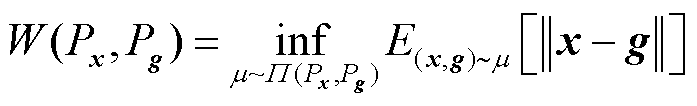 (21)
(21)
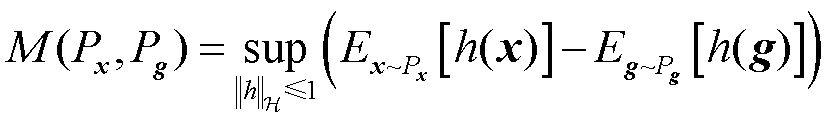 (22)
(22)
式中,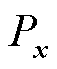 为真实样本x的分布;Pg为生成样本g的分布;
为真实样本x的分布;Pg为生成样本g的分布;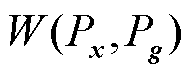 和
和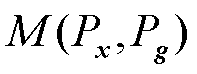 分别为真实样本与生成样本的Wasserstein距离和最大均值差异距离;
分别为真实样本与生成样本的Wasserstein距离和最大均值差异距离;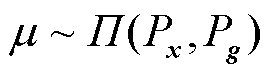 为由Px和Pg组合得到的联合分布;h(·)为映射函数;
为由Px和Pg组合得到的联合分布;h(·)为映射函数;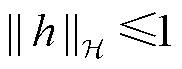 表示函数h的范数限制在1以内;
表示函数h的范数限制在1以内;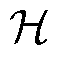 为希尔伯特空间。
为希尔伯特空间。
图5展示了生成数据的评价指标箱线图。箱线图的中位数表示生成数据的平均水平,整体高度表示生成数据的波动程度,上线和下线分别表示统计指标的最大值和最小值。从图5中可以看出,对比模型所生成的样本与真实样本之间的距离较大,样本相似性较小,所提出的生成模型在各统计指标下的波动程度更小,表明其具有良好的稳定性,且在各统计指标下的中位数均是最小的,证明本文所提模型具有更好的数据生成能力,在数据增强任务中取得了比其他方法更好的性能。
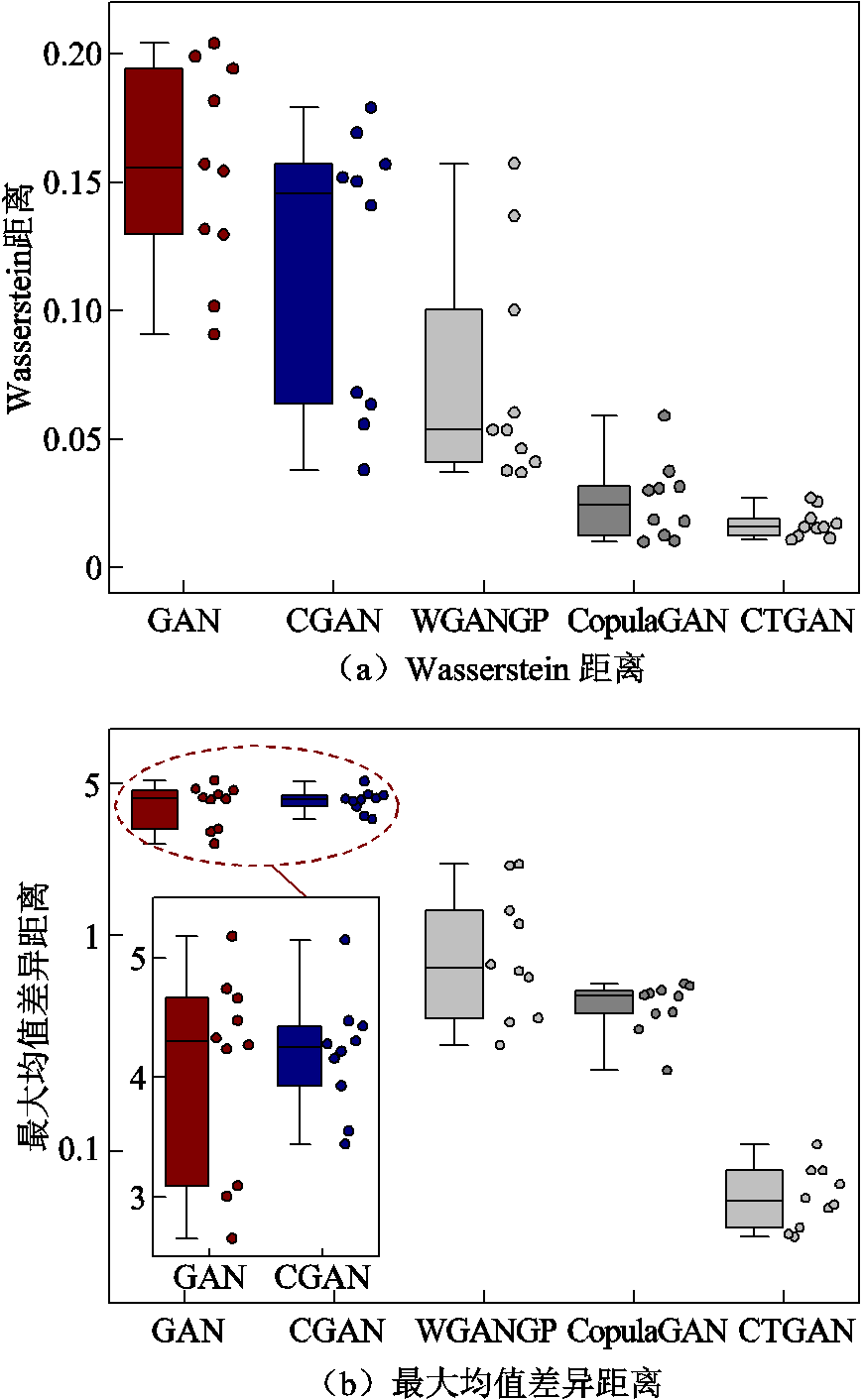
图5 评价指标箱线图
Fig.5 Box plots of statistical indicators
在风力发电机实际运行中,由于受到设备和工作条件的影响,安装在风机上的传感器所采集到的样本数据是极不平衡的,即风机处在非覆冰状态下的数据远远多于处在覆冰状态下的数据,这对覆冰诊断精度的提高产生了影响。为了进一步验证所提出的样本生成模型在不同训练样本下的数据增强能力以及引入焦点损失函数修正LightGBM模型(LightGBM(Focal Loss))的分类能力,本文设定了多种正常样本和覆冰样本的不平衡率,各不平衡率和样本数量的具体信息见表1。
2.4.1 未添加合成样本的不平衡实验
结合表1中覆冰样本与正常样本的不平衡率,设置多种不平衡样本对比实验,在相同的测试集样本下测试了不同模型在各不平衡率情况下的样本分
类效果,分析样本不平衡情况下的各模型的覆冰诊断能力。未添加合成样本各模型的分类准确率对比结果见表2。
表1 覆冰样本与正常样本比例
Tab.1 Ratio of faulty samples to normal samples
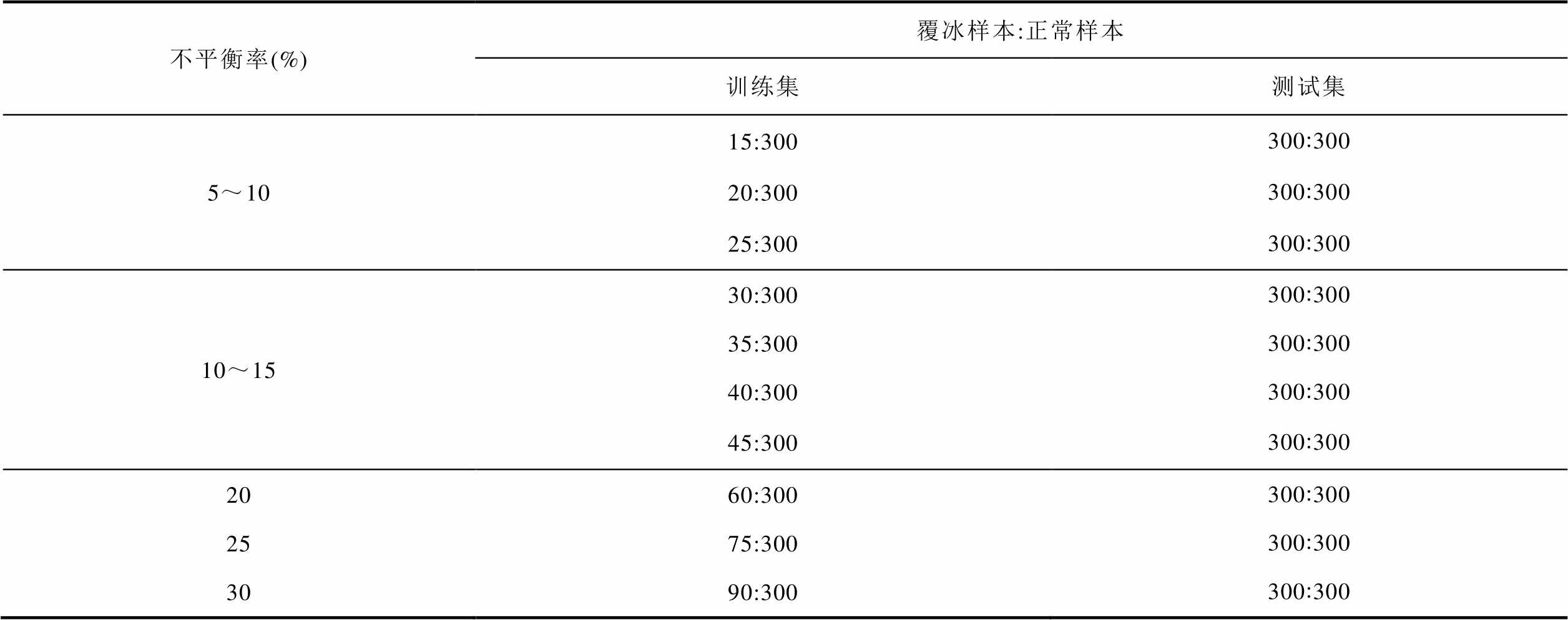
不平衡率(%)覆冰样本:正常样本 训练集测试集 5~1015:300300:300 20:300300:300 25:300300:300 10~1530:300300:300 35:300300:300 40:300300:300 45:300300:300 2060:300300:300 2575:300300:300 3090:300300:300
由表2可知:
1)当覆冰样本数量为90个,即样本不平衡率为30%时,样本不平衡问题并不显著,各个模型的分类准确率均在0.85以上,Logistic regression传统分类模型的准确率为0.862,主要是由于其特征提取能力较弱,因此分类效果较差;而KNN、SVM、GBDT、XGBoost、LightGBM以及LightGBM(Focal Loss)各个模型的分类准确率均在0.9以上。其中,LightGBM(Focal Loss)模型的分类效果最好,分类准确率达0.977。
表2 未添加合成样本各模型的分类准确率对比
Tab.2 Comparison of classification accuracy of each models without added synthetic samples
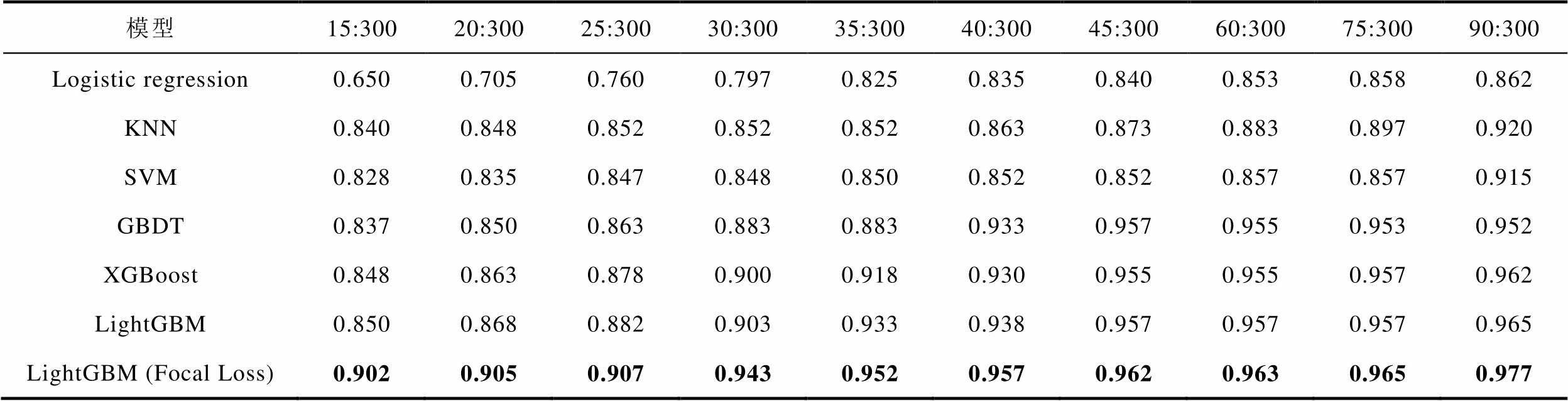
模型15:30020:30025:30030:30035:30040:30045:30060:30075:30090:300 Logistic regression0.6500.7050.7600.7970.8250.8350.8400.8530.8580.862 KNN0.8400.8480.8520.8520.8520.8630.8730.8830.8970.920 SVM0.8280.8350.8470.8480.8500.8520.8520.8570.8570.915 GBDT0.8370.8500.8630.8830.8830.9330.9570.9550.9530.952 XGBoost0.8480.8630.8780.9000.9180.9300.9550.9550.9570.962 LightGBM0.8500.8680.8820.9030.9330.9380.9570.9570.9570.965 LightGBM (Focal Loss)0.9020.9050.9070.9430.9520.9570.9620.9630.9650.977
2)随着真实覆冰样本数量的降低,各个模型的分类准确率也降低,当样本不平衡率从30%下降到10%时,Logistic regression、KNN、SVM、GBDT、XGBoost以及LightGBM分类模型的准确率分别降低了7.54%、7.39%、7.32%、7.25%、6.44%和6.42%,而LightGBM(Focal Loss)模型的准确率仅降低了3.48%,分类准确率达0.943。
3)随着真实覆冰样本数量的进一步减少,当样本的不平衡率仅为5%时,各个模型的准确率进一步下降。Logistic regression、XGBoost以及LightGBM模型的分类准确率仅为0.650、0.848和0.850,而LightGBM(Focal Loss)模型的分类效果仍然是最优的,分类准确率达0.902,相比于表现较好的LightGBM模型,分类准确率提高了6.12%,这表明所提出的LightGBM(Focal Loss)模型在样本量较少时,仍有较好的分类效果和较强的适应能力。
2.4.2 添加合成样本的不平衡实验
从2.4.1节结果可以看出,随着真实覆冰样本数量的减少,各个模型的分类准确率也逐渐降低,说明实际工况下的数据不平衡现象将严重影响分类结果的准确性,因此扩充小样本数据十分必要。通过利用CTGAN模型分别平衡上述各个不均衡数据集,将生成的样本添加到真实的覆冰样本中,使训练集的覆冰样本数量和正常状态样本数量一致(均为300个),然后将扩充后的合成样本输入各个模型中进行训练测试,添加合成样本各模型的分类准确率对比结果见表3。同时,利用t-SNE(t-distributed Stochastic Neighbor Embedding)分布对CTGAN生成数据进行可视化分析,生成数据与原始数据的t-SNE降维结果如图6所示。
由表3和图6可知:
1)由于样本扩充算法的引入,各个模型的分类准确率相较于数据缺乏时均有不同程度的提高,从t-SNE结果可以看出,生成数据和原始数据的融合程度较高。当真实覆冰样本量为90个、生成样本数量为210个时,Logistic regression传统分类模型的准确率提高了11.02%,同时,LightGBM(Focal Loss)的准确率为0.982,接近于样本充足时的准确率。
表3 添加合成样本各模型的分类准确率对比
Tab.3 Comparison of classification accuracy of each models with added synthetic samples
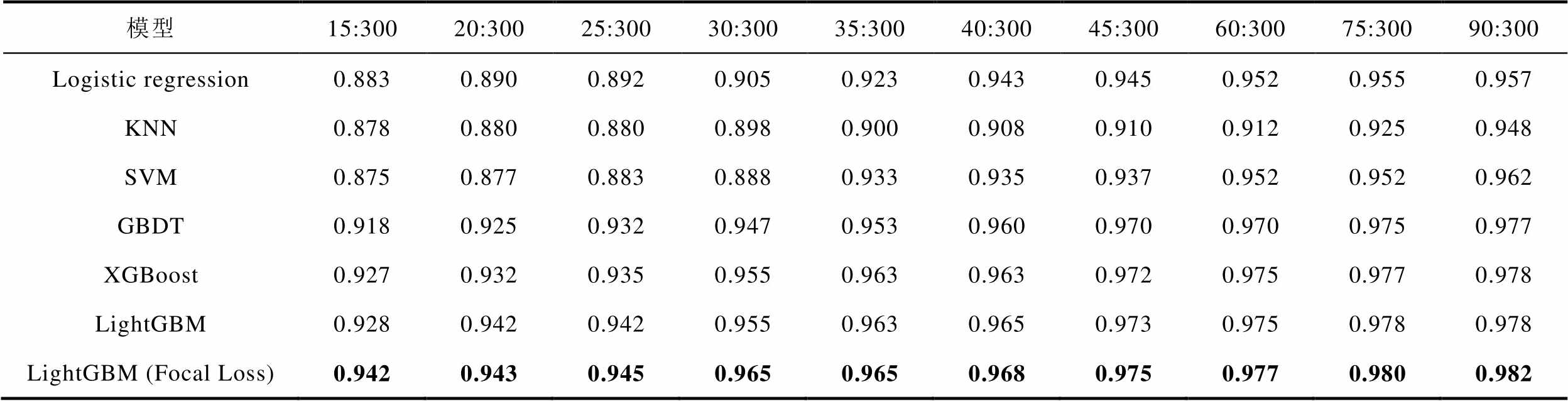
模型15:30020:30025:30030:30035:30040:30045:30060:30075:30090:300 Logistic regression0.8830.8900.8920.9050.9230.9430.9450.9520.9550.957 KNN0.8780.8800.8800.8980.9000.9080.9100.9120.9250.948 SVM0.8750.8770.8830.8880.9330.9350.9370.9520.9520.962 GBDT0.9180.9250.9320.9470.9530.9600.9700.9700.9750.977 XGBoost0.9270.9320.9350.9550.9630.9630.9720.9750.9770.978 LightGBM0.9280.9420.9420.9550.9630.9650.9730.9750.9780.978 LightGBM (Focal Loss)0.9420.9430.9450.9650.9650.9680.9750.9770.9800.982
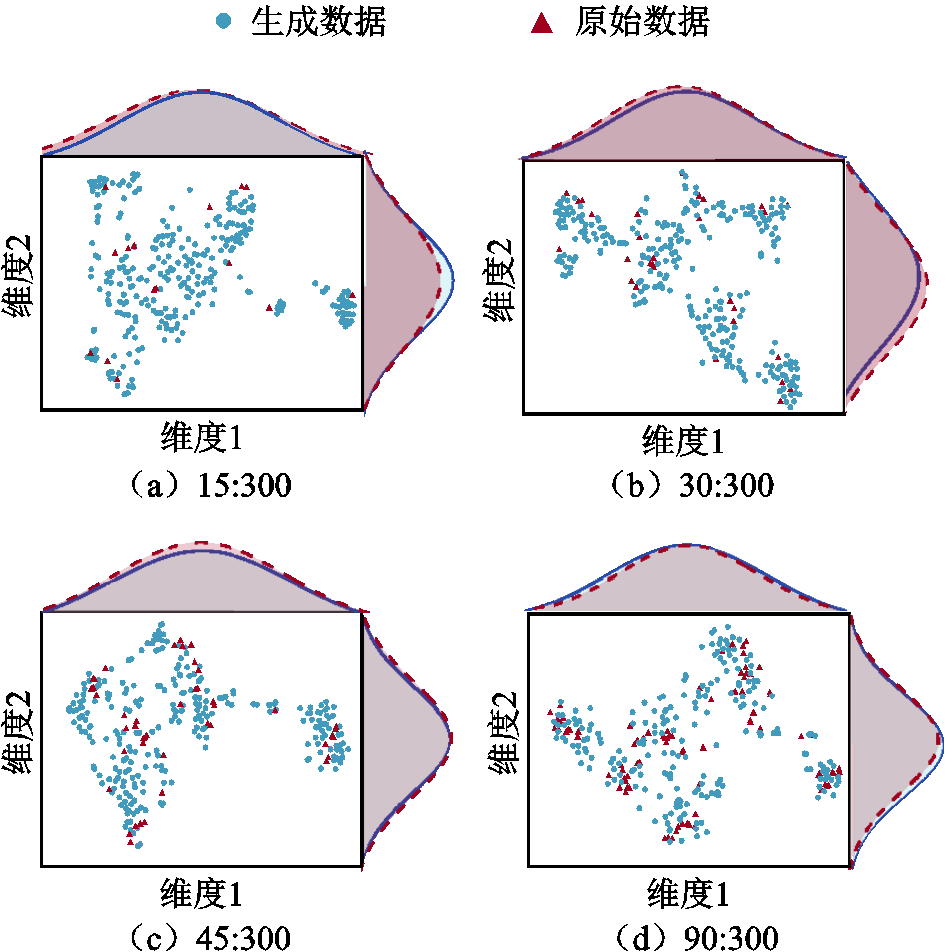
图6 生成数据与原始数据的t-SNE降维结果
Fig.6 t-SNE dimensionality reduction results of generated data and raw data
2)随着样本不平衡率的降低,真实覆冰样本数量进一步减少,此时,样本扩充算法的优势逐渐明显。当样本不平衡率为10%时,相较于未扩充样本测试结果,Logistic regression、KNN、SVM、GBDT、XGBoost以及LightGBM模型的准确率分别提高了13.55%、5.40%、4.72%、7.25%、6.11%和5.76%,此时,LightGBM(Focal Loss)的准确率为0.965。
3)当样本不平衡率为5%,真实覆冰样本数量仅为15时,相较于未扩充样本,Logistic regression、KNN、XGBoost以及LightGBM模型的准确率分别提高了35.85%、4.52%、9.32%和9.18%,说明CTGAN具有较好的样本生成能力,在样本数据量较少时仍能有效地学习到真实样本的分布情况。
同时,表4统计了不同模型的耗时对比。从表4中可以看出,由于各个模型都采用了相同的样本生成方法,样本生成时间相同,且模型主要耗时在于样本生成阶段。因此,在时间要求比较高的场合可以考虑对样本生成模型提前进行离线训练,而各模型运行时间都非常短,在实际模型应用时影响较小。
表4 不同模型耗时对比
Tab.4 Comparison of time consumption between different models

模型样本生成时间/s模型运行时间/s Logistic regression2520.004 KNN0.014 SVM0.005 GBDT0.541 XGBoost0.026 LightGBM0.031 LightGBM (Focal Loss)0.082
机器学习模型虽然具有高效率和高精度等特点,但由于其黑箱性质的限制,使得模型的可解释性较弱,因此,本文采用SHAP方法对覆冰的影响因素进行量化分析。图7根据SHAP值大小展示了前10个覆冰特征的SHAP值。图中,横轴为SHAP值,表示每个特征量对模型最终结果的影响;纵轴按重要程度从上到下列出了每个特征量,每一个散点代表一个样本,样本特征值大小用不同颜色表示,红色表示较高的特征值,蓝色表示较低的特征值。
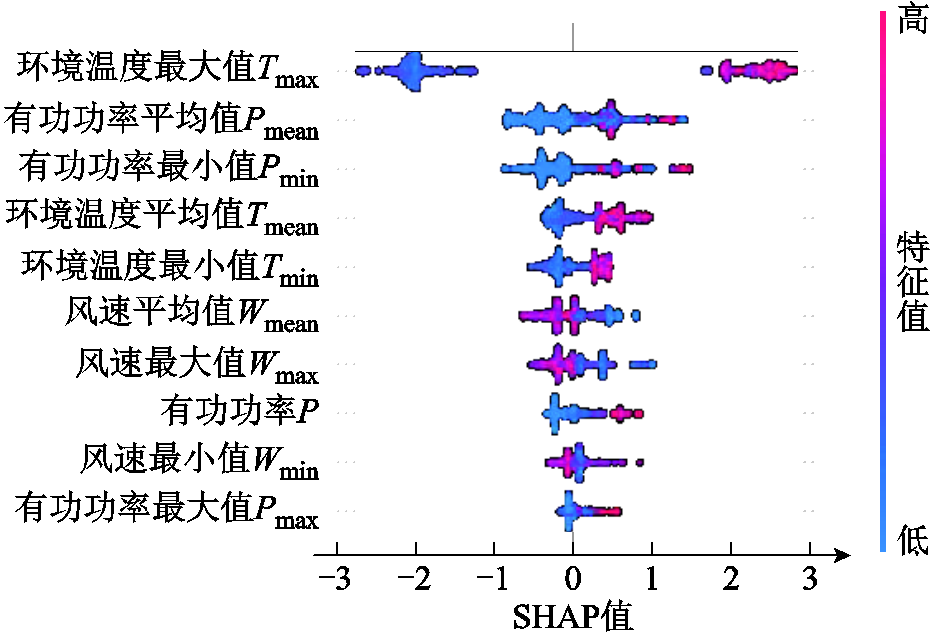
图7 覆冰特征SHAP值
Fig.7 Summary of Shapley values for icing characteristics
从图7中可以看出,在一定时间内,环境温度最大值对覆冰结果的影响最大。环境温度主要影响水滴冻结过程中的对流换热平衡,环境温度越低,叶片表面与空气间表面传热系数越大,过冷却水滴在叶片表面释放潜热速率越快,从而使水滴更易冻结。其次,风力发电机的有功功率也是表征叶片覆冰的重要因素,覆冰会改变风机叶片的气动性能,降低风能利用率,从而导致叶片的输出功率下降。另外,自然风作为过冷却水滴碰撞叶片表面的驱动力,随着风速的不断增加,过冷却水滴撞击叶片表面的概率越高。同时,风速的增大可提高水滴冻结过程中潜热的释放效率,加速其对流换热过程,进而提高覆冰速率。
随机选取测试集中模型测试结果为“覆冰”和“非覆冰”的样本各一个,利用SHAP理论对两个样本的预测结果进行分析。覆冰样本和非覆冰样本的SHAP特征力图如图8所示,图中Si表示各特征量的SHAP值,用于表示各特征量对诊断结果的贡献程度,红色表示正向贡献程度,蓝色表示负向贡献程度,箭头越长表示贡献程度越大。由图8a可以看出,环境温度最大值、环境温度平均值所对应的SHAP值均为正值,且环境温度最大值的贡献程度最大,促使评估结果向非覆冰过程移动,而有功功率所对应的SHAP值为负值,促使评估结果向覆冰状态移动,模型最终输出值为3.4,大于覆冰的基准值-0.042,则诊断结果为非覆冰。同理,由图8b可知,环境温度最大值、有功功率平均值所对应的SHAP值均为负值,促使模型向覆冰状态移动,模型的输出值为-3.7,小于覆冰的基准值-0.042,最终诊断结果为覆冰。
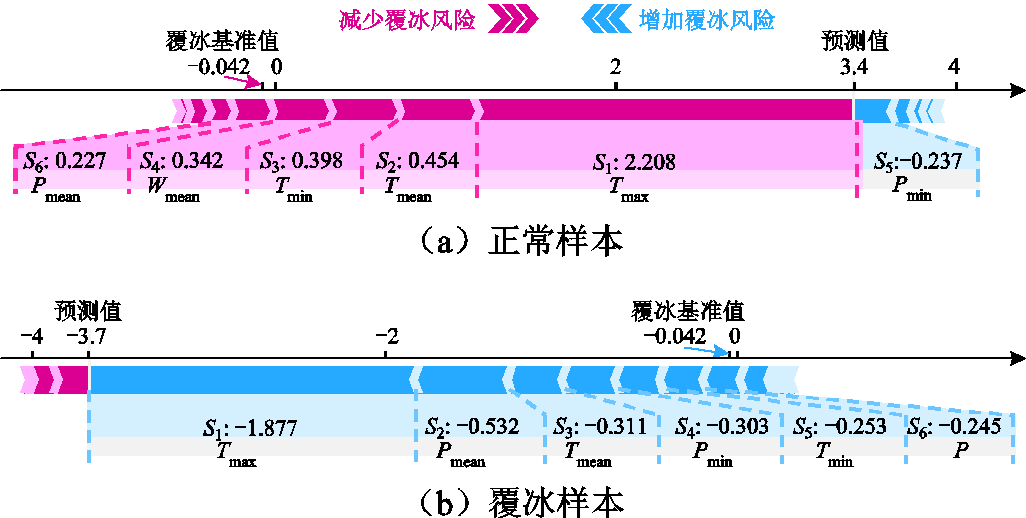
图8 覆冰样本和非覆冰样本的SHAP特征力图
Fig.8 SHAP feature force diagram of iced and non-iced samples
综上所述,通过对“覆冰”样本和“非覆冰”样本进行可解释性分析,量化了各覆冰影响因素的贡献程度,有助于对覆冰诊断结果进行归因分析,提高了诊断模型的可信度,为后续风电场根据叶片的覆冰情况及时执行停机策略提供参考依据。
针对风机叶片覆冰样本监测数据不平衡、诊断模型难以解释等问题,本文提出了一种基于CTGAN和LightGBM(Focal Loss)的融合诊断模型,旨在利用少量的训练样本实现高性能的风机叶片覆冰诊断,主要结论如下:
1)本文基于滑动窗口算法所构造的混合特征能明显提升各模型的分类能力,相较于原始特征信息,使用混合特征后,各模型的平均诊断准确率可达0.979。同时,结合混合特征信息的LightGBM模型相较于其他算法具有明显的优势,覆冰诊断准确率可达0.997。
2)样本生成模型CTGAN能够有效地学习真实样本的分布情况,相比于其他数据增强方法,可以生成与真实样本更为相似的新样本。当真实覆冰样本数量仅为15个时,相较于原始数量样本,样本扩充后各个模型的平均诊断准确率提高了11.24%。
3)利用Focal Loss损失函数修正LightGBM模型,增加了模型区分易混淆样本的能力。在真实覆冰样本数量仅为15个时,模型的准确率依然保持在0.942。此外,基于SHAP归因理论分析了各覆冰因素的重要程度,并量化了关键特征对诊断结果的定量影响,提高了模型诊断结果的可信度。本文可为风电场的运营提供优化维护策略的信息,确保风机在寒冷天气条件下安全高效地运行。
需要注意的是,本文中模型参数的确定是采用人工调参的方式。在未来的工作中,为了简化参数调整流程,将探索先进的超参数优化算法,以降低人工调参的成本。同时,融合诊断模型的主要耗时在于样本生成阶段。因此,后续将进一步研究轻量化的网络模型,以优化训练过程并提高模型运行效率。
参考文献
[1] 于周, 舒立春, 胡琴, 等. 风机叶片气动脉冲除冰结构脱冰计算模型及试验验证[J]. 电工技术学报, 2023, 38(13): 3630-3639.
Yu Zhou, Shu Lichun, Hu Qin, et al. De-icing calculation model of pneumatic impulse de-icing structure for wind turbine blades and experiment verification[J]. Transactions of China Electrotechnical Society, 2023, 38(13): 3630-3639.
[2] Hu Liangquan, Zhu Xiaocheng, Hu Chenxing, et al. Wind turbines ice distribution and load response under icing conditions[J]. Renewable Energy, 2017, 113: 608-619.
[3] Gao Linyue, Hong Jiarong. Wind turbine performance in natural icing environments: a field characterization[J]. Cold Regions Science and Technology, 2021, 181: 103193.
[4] 林刚, 王波, 彭辉, 等. 基于强泛化卷积神经网络的输电线路图像覆冰厚度辨识[J]. 中国电机工程学报, 2018, 38(11): 3393-3401.
Lin Gang, Wang Bo, Peng Hui, et al. Identification of icing thickness of transmission line based on strongly generalized convolutional neural network[J]. Proceedings of the CSEE, 2018, 38(11): 3393-3401.
[5] 蒋兴良, 周文轩, 董莉娜, 等. 基于旋转圆柱三电极阵列的覆冰测量方法[J]. 电工技术学报, 2024, 39(5): 1524-1535.
Jiang Xingliang, Zhou Wenxuan, Dong Lina, et al. Research on icing measurement method based on rotating cylindrical three-electrode array[J]. Transactions of China Electrotechnical Society, 2024, 39(5): 1524-1535.
[6] Gómez Muñoz C Q, Arcos Jiménez A, García Márquez F P. Wavelet transforms and pattern recognition on ultrasonic guides waves for frozen surface state diagnosis[J]. Renewable Energy, 2018, 116: 42-54.
[7] 王敏学, 李黎, 周达明, 等. 分布式光纤传感技术在输电线路在线监测中的应用研究综述[J]. 电网技术, 2021, 45(9): 3591-3600.
Wang Minxue, Li Li, Zhou Daming, et al. Overview of studies on application of distributed optical fiber sensing technology in online monitoring of transmission lines[J]. Power System Technology, 2021, 45(9): 3591-3600.
[8] Gómez Muñoz C Q, García Márquez F P, Sánchez Tomás J M. Ice detection using thermal infrared radiometry on wind turbine blades[J]. Measurement, 2016, 93: 157-163.
[9] Rizk P, Al Saleh N, Younes R, et al. Hyperspectral imaging applied for the detection of wind turbine blade damage and icing[J]. Remote Sensing Applications: Society and Environment, 2020, 18: 100291.
[10] Guo Peng, Infield D. Wind turbine blade icing detection with multi-model collaborative monitoring method[J]. Renewable Energy, 2021, 179: 1098-1105.
[11] Cheng Xu, Shi Fan, Liu Yongping, et al. Wind turbine blade icing detection: a federated learning approach[J]. Energy, 2022, 254: 124441.
[12] Bai Xinjian, Tao Tao, Gao Linyue, et al. Wind turbine blade icing diagnosis using RFECV-TSVM pseudo-sample processing[J]. Renewable Energy, 2023, 211: 412-419.
[13] Jiang Guoqian, Yue Ruxu, He Qun, et al. Imbalanced learning for wind turbine blade icing detection via spatio-temporal attention model with a self-adaptive weight loss function[J]. Expert Systems with Applications, 2023, 229: 120428.
[14] Yue Ruxue, Jiang Guoqian, Jin Xiaohang, et al. Spatio-temporal feature alignment transfer learning for cross-turbine blade icing detection of wind turbines[J]. IEEE Transactions on Instrumentation Measurement, 2024, 73: 3350147.
[15] Tao Tao, Liu Yongqian, Qiao Yanhui, et al. Wind turbine blade icing diagnosis using hybrid features and Stacked-XGBoost algorithm[J]. Renewable Energy, 2021, 180: 1004-1013.
[16] Tong Ruining, Li Peng, Lang Xun, et al. A novel adaptive weighted kernel extreme learning machine algorithm and its application in wind turbine blade icing fault detection[J]. Measurement, 2021, 185: 110009.
[17] 汤健, 侯慧娟, 盛戈皞, 等. 变压器不平衡样本故障诊断的过采样和代价敏感算法[J]. 高压电器, 2023, 59(6): 93-102.
Tang Jian, Hou Huijuan, Sheng Gehao, et al. Oversampling and cost-sensitive algorithm for transformer fault diagnosis with unbalanced samples [J]. High Voltage Apparatus, 2023, 59(6): 93-102.
[18] 游文霞, 李清清, 杨楠, 等. 基于多异学习器融合Stacking集成学习的窃电检测[J]. 电力系统自动化, 2022, 46(24): 178-186.
You Wenxia, Li Qingqing, Yang Nan, et al. Electricity theft detection based on multiple different learner fusion by stacking ensemble learning[J]. Automation of Electric Power Systems, 2022, 46(24): 178-186.
[19] 裴少通, 张行远, 胡晨龙, 等. 基于ER-YOLO算法的跨环境输电线路缺陷识别方法[J]. 电工技术学报, 2024, 39(9): 2825-2840.
Pei Shaotong, Zhang Hangyuan, Hu Chenlong, et al. The defect detection method for cross-environment power transmission line based on ER-YOLO algorithm [J]. Transactions of China Electrotechnical Society, 2024, 39(9): 2825-2840.
[20] 兰健, 郭庆来, 周艳真, 等. 基于生成对抗网络和模型迁移的电力系统典型运行方式样本生成[J]. 中国电机工程学报, 2022, 42(8): 2889-2900.
Lan Jian, Guo Qinglai, Zhou Yanzhen, et al. Generation of power system typical operation mode samples: a generation adversarial network and model-based transfer learning approach[J]. Proceedings of the CSEE, 2022, 42(8): 2889-2900.
[21] 尹杰, 刘博, 孙国兵, 等. 基于迁移学习和降噪自编码器-长短时间记忆的锂离子电池剩余寿命预测[J]. 电工技术学报, 2024, 39(1): 289-302.
Yin Jie, Liu Bo, Sun Guobing, et al. Transfer learning denoising autoencoder-long short term memory for remaining useful life prediction of Li-ion batteries[J]. Transactions of China Electrotechnical Society, 2024, 39(1): 289-302.
[22] 金亮, 宋居恒, 马天赐, 等. 电磁轨道发射器高速下电流密度场预测[J]. 电工技术学报, 2024, 39(19): 5914-5928, 5936.
Jin Liang, Song Juheng, Ma Tianci, et al. Current density field prediction method for electromagnetic rail launcher at high speed[J]. Transactions of China Electrotechnical Society, 2024, 39(19): 5914-5928, 5936.
[23] 王守相, 陈海文, 潘志新, 等. 采用改进生成式对抗网络的电力系统量测缺失数据重建方法[J]. 中国电机工程学报, 2019, 39(1): 56-64, 320.
Wang Shouxiang, Chen Haiwen, Pan Zhixin, et al. A reconstruction method for missing data in power system measurement using an improved generative adversarial network[J]. Proceedings of the CSEE, 2019, 39(1): 56-64, 320.
[24] 李弈, 张金龙, 漆汉宏, 等. 基于VaDE-WGANGP的锂离子电池老化特性建模[J]. 电工技术学报, 2024, 39(13): 4226-4239.
Li Yi, Zhang Jinlong, Qi Hanhong, et al. Modeling of aging characteristics of lithium-ion batteries based on VaDE WGANGP[J]. Transactions of China Electro-technical Society, 2024, 39(13): 4226-4239.
[25] 赵洪山, 彭轶灏, 刘秉聪, 等. 基于边缘注意力生成对抗网络的电力设备热成像超分辨率重建[J]. 中国电机工程学报, 2022, 42(10): 3564-3573.
Zhao Hongshan, Peng Yihao, Liu Bingcong, et al. Super-resolution reconstruction of electric equipment’s thermal imaging based on generative adversarial network with edge-attention[J]. Proceedings of the CSEE, 2022, 42(10): 3564-3573.
[26] 仲林林, 胡霞, 刘柯妤. 基于改进生成对抗网络的无人机电力杆塔巡检图像异常检测[J]. 电工技术学报, 2022, 37(9): 2230-2240, 2262.
Zhong Linlin, Hu Xia, Liu Keyu. Power tower anomaly detection from unmanned aerial vehicles inspection images based on improved generative adversarial network[J]. Transactions of China Electro-technical Society, 2022, 37(9): 2230-2240, 2262.
[27] Huang Nantian, Chen Qingzhu, Cai Guowei, et al. Fault diagnosis of bearing in wind turbine gearbox under actual operating conditions driven by limited data with noise labels[J]. IEEE Transactions on Instrumentation Measurement, 2021, 70: 3025396.
[28] Zhang Liang, Zhang Hao, Cai Guowei. The multiclass fault diagnosis of wind turbine bearing based on multisource signal fusion and deep learning generative model[J]. IEEE Transactions on Instrumentation Measurement, 2022, 71: 3178483.
[29] 沙浩源, 梅飞, 李丹奇, 等. 基于改进生成对抗网络的电压暂降事件类型辨识研究[J]. 中国电机工程学报, 2021, 41(22): 7648-7660.
Sha Haoyuan, Mei Fei, Li Danqi, et al. Research on voltage sag event type identification based on improved generative adversarial networks[J]. Procee-dings of the CSEE, 2021, 41(22): 7648-7660.
[30] 李东东, 刘宇航, 赵阳, 等. 基于改进生成对抗网络的风机行星齿轮箱故障诊断方法[J]. 中国电机工程学报, 2021, 41(21): 7496-7507.
Li Dongdong, Liu Yuhang, Zhao Yang, et al. Fault diagnosis method of wind turbine planetary gearbox based on improved generative adversarial network[J]. Proceedings of the CSEE, 2021, 41(21): 7496-7507.
Diagnosis and Interpretability Study of Wind Turbine Blade Icing under Consideration of Sample Imbalance Conditions
Abstract The low temperature and high humidity environment in winter can easily cause wind turbine blades to freeze, seriously affecting the actual power output and safe operation of wind turbines. To avoid problems such as increased fatigue load and vibration of unit components caused by icing, wind farms need to implement shutdown strategies in a timely manner based on the icing situation of the blades. Therefore, accurate identification of blade icing status has become one of the key points in maintaining the safe operation of winter wind turbines. However, current ice diagnosis methods rely on a large amount of time series data for modeling and prediction. In practical work, due to equipment and working conditions, it is difficult to collect sufficient ice sample monitoring data, which leads to the widespread problem of data imbalance and has a continuous impact on the improvement of ice diagnosis accuracy. To solve this problem, this paper proposes a fusion diagnostic model based on conditional generative adversarial network (CTGAN) and light gradient boosting machine (LightGBM), aiming to achieve high-performance wind turbine blade ice diagnosis using a small number of training samples.
Firstly, based on the sliding window algorithm, new mixed features are further constructed on the basis of the original features. Secondly, the CTGAN model is used to learn the data distribution of real samples, and Nash equilibrium is achieved through adversarial training with generators and discriminators, generating new samples that are similar to real samples. Then, the synthesized samples are input into LightGBM to extract effective features and diagnose icing, and the LightGBM model is modified by introducing a focus loss function to improve its ability to distinguish confusing samples. Finally, the attribution theory based on shapley additive explanetions (SHAP) was used to analyze the factors affecting icing.
The simulation results on actual wind farm data show that the diagnostic accuracy of all algorithms has a certain improvement effect after using mixed features, and the average diagnostic accuracy of each model can reach 0.979. Due to the introduction of sample expansion algorithms, the accuracy of each model has improved to varying degrees compared to when data is lacking. When the sample imbalance rate is 30%, the accuracy of the traditional Logistic regression classification model is improved by 11.02%. At the same time, the accuracy of LightGBM (Focal Loss) is 0.982, which is close to the accuracy when the sample is sufficient. As the sample imbalance rate decreases and the actual number of ice-covered samples further decreases, the advantages of the sample expansion algorithm gradually become apparent. When the sample imbalance rate is 10%, compared to the unexpanded samples, the accuracy of Logistic regression model is improved by 13.55%. When the sample imbalance rate is 5% and the actual number of ice-covered samples is only 15, compared to the unexpanded samples, the accuracy of Logistic regression, KNN, XGBoost, and LightGBM models has improved by 35.85%, 4.52%, 9.32%, and 9.18%, respectively. This indicates that CTGAN has good sample generation ability and can effectively learn the distribution of real samples even when the sample data is small.
From the simulation analysis, the following conclusions can be drawn: (1) The mixed features constructed based on the sliding window algorithm in this paper can significantly improve the classification ability of each model. At the same time, the LightGBM model combined with mixed feature information has obvious advantages compared to other models. (2) The sample generation model CTGAN can effectively learn the distribution of real samples, and compared to other data augmentation methods, it can generate new samples that are more similar to real samples. (3) By using the Focal loss function to modify the LightGBM model, the model's ability to distinguish easily confused samples has been increased. In addition, based on the SHAP attribution theory, the importance of each icing factor was analyzed, and the quantitative impact of key features on the diagnostic results was quantified, improving the credibility of the model's diagnostic results.
Keywords:Wind turbine blade, sample imbalance, generative adversarial networks, icing diagnosis, interpretability
中图分类号:TM614
DOI: 10.19595/j.cnki.1000-6753.tces.240795
中央高校基本科研业务费(2023CDJYXTD-005)和国家资助博士后研究人员计划(GZC20242120)资助项目。
收稿日期 2024-05-16
改稿日期 2024-07-01
吕云龙 男,1997年生,博士研究生,研究方向为风力发电机覆冰及防护。
E-mail:lvyunlongcqu@163.com
胡 琴 男,1981年生,教授,博士生导师,研究方向为电网防冰减灾等。
E-mail:huqin@cqu.edu.cn(通信作者)
(编辑 李 冰)