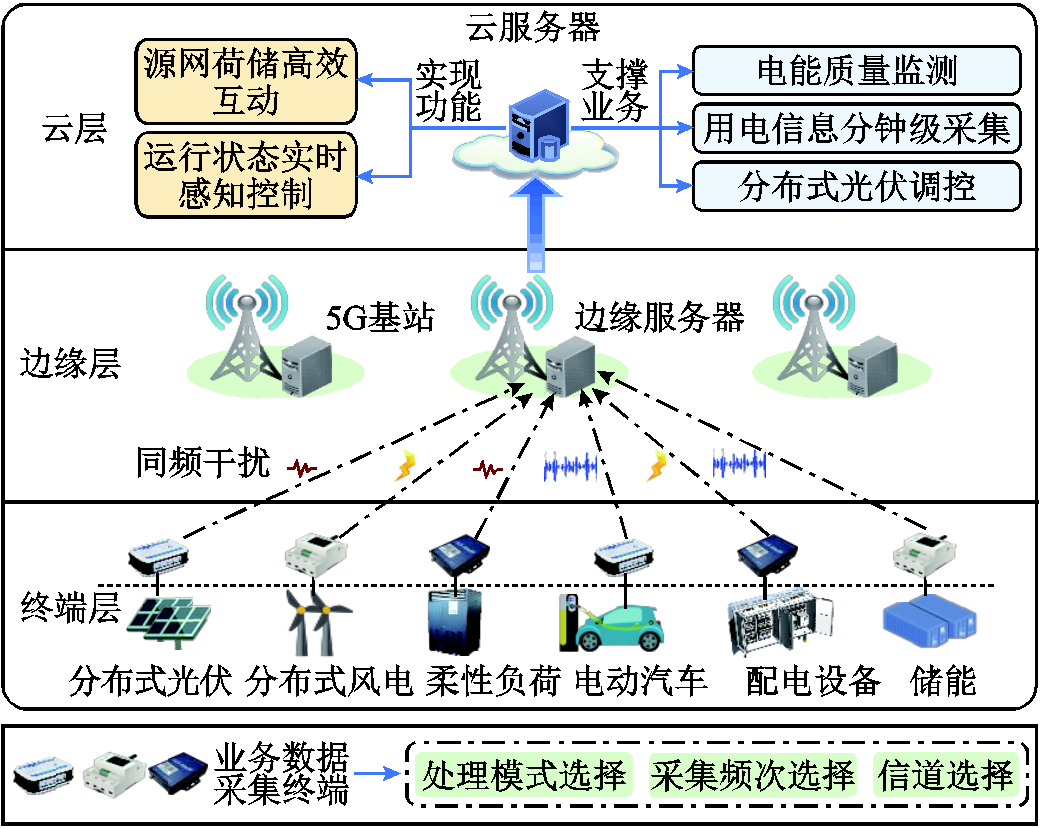
图1 云边端多级协同业务处理框架
Fig.1 Cloud-edge-end multi-level collaborative service processing framework
摘要 在新能源广泛接入背景下,配电网业务数据采集终端接入规模与信号采集频次激增,对网络的业务承载能力提出更高要求。该文首先通过整合云边端算力资源,构建以最大化云边端协同处理数据量为目标的优化问题,并引入李雅普诺夫优化理论将其转换为仅依赖当前时隙信息的在线优化问题,实现排队时延与长时平均采集数据量的协同保障;然后,提出基于改进深度Q网络(DQN)的配电网云边端协同处理算法,通过引入基于贪婪策略的Q值排序机制与双重经验回放机制,解决多终端处理决策耦合导致的资源竞争冲突,在保障样本多样性处理能力的同时提升算法的收敛性;最后,仿真结果证明所提算法能够有效适配配电网采集业务高密度、高频次的发展趋势。
关键词:配电网 高频采集 云边端协同 业务处理 深度强化学习
为支撑新型电力系统大规模分布式能源调控与源荷双向互动感知,配电网业务数据采集终端数量与采集频次激增,电压电流采集频次由1次/(15 min)向1次/min 迈进,预计到2025年,国家电网将接入超10亿台终端,实现配电网多维业务数据的全方位高频次采集[1-3]。相较于传统电力业务,分布式电源投切控制、柔性负荷调控、储能充放电管理等新兴业务对算力的需求更为庞大,使得当前配电网计算资源不足、精细化管控能力差的问题更为突出[4-5]。因此,面向配电网采集业务向高频海量、计算密集方向发展的趋势,如何有效提升业务数据的实时传输与处理能力,助力新型电力系统源网荷储的高效协同互动,已经成为行业研究的热点问题之一。
传统配电网业务主站多基于云计算框架进行建设,云端计算资源充足,可有效满足业务数据的处理需求[6]。然而,云端与配电网终端之间的长距离链路传输能力不稳定,对于信号采集频率高、业务规模增长快的高频采集场景的适应能力不足。边缘计算将部分云中心的功能下沉至本地侧附近,通过切割大型运算业务降低云中心数据处理压力,具有传输距离近、业务响应迅速的优势,可与云计算形成有效互补[7-8]。此外,具备一定算力的智能化终端在配电网中的应用越发广泛,新型智能终端兼具数据采集、接入、处理、上传等功能。在数据处理方面,其可搭载“国网芯”等智能芯片,并基于微服务架构和容器化技术实现业务应用的个性化定制,转换业务数据为业务信息,其可提供的计算资源不容忽视。综上所述,分布式智能计算正逐步打破不同层级的信息壁垒,云边端协同可有效实现跨层级、多尺度异构计算资源的统筹,通过构建面向配电网高频采集的云边端协同数据处理机制,将有助于提高配电网业务数据的传输与处理能力,支撑配电网智能决策水平的提升[9-10]。
当前国内外相关研究团队在云边端协同方面已经积累了一定的研究基础。文献[11]以最小化任务计算时延为目标,利用K-means聚类算法解决云边端任务合作卸载优化问题,在提高系统资源利用率的同时降低了时延。文献[12]提出一种权衡时延与能耗的依赖性任务卸载方法,并采用凸优化工具求最优解,有效地降低了系统总成本。文献[13]提出一种分布式计算卸载优化策略,并将其转换为基于交替方向乘法器的多目标延迟优化问题,有效地提升了卸载速率与可靠性。然而,高频采集复杂场景具有网络随机性与建模机理不确定性,且全局信息未知,上述基于确定性模型的传统求解方法并不适用。
深度强化学习(Deep Reinforcement Learning, DRL)结合了深度学习的特征感知和强化学习的决策能力,为解决全局状态信息未知情况下的协作处理优化提供了一种可行的解决方案[14-17]。文献[18]设计基于DRL的调度算法以处理云边端之间的高并发业务需求,实现网络能耗与吞吐量的联合优化。文献[19]构建移动边缘计算任务卸载模型,采用基于深度Q网络(Deep Q-Network, DQN)的多目标任务卸载算法求解,大幅提升服务器计算能力与用户体验。文献[20]针对移动设备资源受限问题,设计基于异步优势演员-评论家(Asynchronous Advantage Actor-Critic, A3C)的依赖任务卸载与资源分配算法,提高了任务的计算效率。
尽管上述研究取得了进展,但仍存在以下挑战。首先,长时约束保障与短时处理决策优化相耦合,单时隙的短期决策难以实现排队时延与长时平均采集数据量的协同保障;其次,差异化业务性能需求与受限网络资源导致多终端处理决策相互耦合,现有方法缺少协同处理机制,难以解决竞争造成的决策冲突;最后,现有方法大多采用随机抽样机制,忽略了动作经验池中不同样本的差异性,在解决资源受限场景下竞争冲突问题时的收敛性与寻优性能较差。
针对上述问题,本文提出基于改进DQN的配电网云边端协同处理算法(Improved Deep Q-Network based Cloud-Edge-End Collaborative Processing Algorithm for Distribution Network, IDCEE)。首先,引入李雅普诺夫优化理论中的虚拟队列概念将原始问题转换为仅依赖当前时隙信息的在线优化问题,实现时延与吞吐量的协同保障;其次,引入基于贪婪策略的Q值排序机制,通过边端协同解决多终端处理决策耦合导致的无线信道与边缘服务器资源选择冲突;再次,考虑不同终端业务重要度及动作样本的置信度,设计双重回放经验池,在保障样本多样性的前提下,避免数据丢失,提升算法的收敛性;最后,通过仿真分析验证所提算法的性能增益。
本文提出的面向配电网高频采集的云边端多级协同业务处理框架如图1所示,包括终端层、边缘层和云层。终端层包含多种部署在分布式光伏/风机、储能装置、充电桩等电气设备上的智能化业务数据采集终端,对配用电信息、设备状态、配电网运行环境等数据进行高频实时采集,能够进行本地计算或通过5G将数据上传至边缘层。由于低压用户侧光纤覆盖有限,采用5G作为端边通信方式。所提架构也适用于光纤、电力线载波等其他通信媒介,具有灵活性与可扩展性。边缘层由通信基站和边缘服务器组成,基站接收到的业务数据可在边缘服务器处理,或通过远程通信网进一步上传至云层处理。云层由电网公司自行建设或租用受信任的第三方云服务器实现,具有庞大的计算资源,可对配电网高频采集业务数据进行深度处理分析,支撑配电网源网荷储高效互动、运行状态实时感知等功能的实现。
图1 云边端多级协同业务处理框架
Fig.1 Cloud-edge-end multi-level collaborative service processing framework
云边端在数据传输与处理能力上具有各自的典型特征。边缘层相较于端层计算资源更丰富,但由于多终端对于通信与计算资源的竞争,其性能仍受限于端边之间的传输能力和端层计算能力。同时,考虑到长距离数据传输中路由转发、网络拥塞等多重因素,云边数据传输网络具有高度时变性和不确定性,是制约云层数据处理性能提升的瓶颈。因此,结合云边端层差异化特征分别构建本地计算、边缘处理和云处理模式。
参数对照见表1。考虑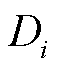 个采集终端与
个采集终端与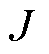 个无线信道。采用准静态时隙模型,将总优化时间划分为
个无线信道。采用准静态时隙模型,将总优化时间划分为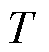 个长度为
个长度为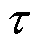 的时隙。在第
的时隙。在第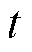 时隙,定义终端的业务处理决策变量为
时隙,定义终端的业务处理决策变量为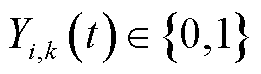 ,其中
,其中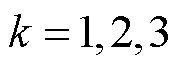 分别表示本地计算、边缘处理和云处理三种模式,
分别表示本地计算、边缘处理和云处理三种模式,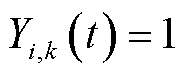 表示选择对应模式,否则
表示选择对应模式,否则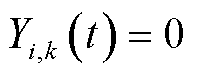 。每个终端只能选择一种模式,即
。每个终端只能选择一种模式,即
表1 参数对照表
Tab.1 Parameter comparison table

参数定义 /个业务数据采集终端 /条无线信道 /个总优化时隙数 /min时隙长度 业务处理决策变量 /个每个边缘服务器最多同时处理的业务数量 处理模式 无线信道选择变量 采集频次控制变量 n/(次/min)数据采集频次 /Mbits终端单次采集的数据量 /Mbits本地处理队列的数据积压 /(CPU cycles/Mbit)计算复杂度 /GHz终端能够提供的计算资源 /Mbits云边端协同处理数据量 /Mbits终端采集的数据量 /(Mbit/s)端边数据传输速率 /kHz传输带宽 /dB信干噪比 /W传输功率 /dBm信道增益 /dBm加性高斯白噪声功率 /dBm中高压电气设备工作产生的电磁干扰 /GHz边缘服务器能够提供的计算资源 /(Mbit/s)云边数据传输速率 /ms排队时延阈值 /Mbits长时平均采集数据量阈值 业务重要度 /个每条信道至多传输的终端业务数量 排队时延虚拟队列 长时平均采集数据量虚拟队列 长时平均采集数据量虚拟队列的权重参数 排队时延虚拟队列的权重参数 李雅普诺夫函数非负权重系数
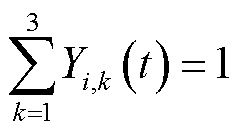 (1)
(1)
考虑边缘服务器计算资源相较云服务器仍然受限,为避免过多终端选取边缘处理模式导致业务负载分布不均衡,定义边缘服务器业务处理约束为
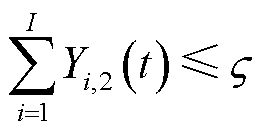 (2)
(2)
式(2)表示边缘服务器最多同时处理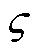 个终端的业务。
个终端的业务。
定义无线信道选择变量为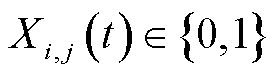 ,
,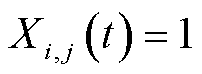 表示终端
表示终端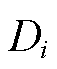 选择信道上传业务,否则
选择信道上传业务,否则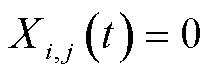 。定义采集频次控制变量为
。定义采集频次控制变量为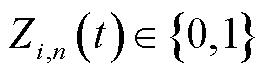 ,
,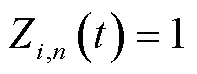 表示终端
表示终端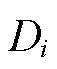 在时隙以
在时隙以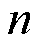 次/min的频次采集数据,否则,
次/min的频次采集数据,否则,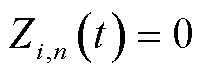 ,
,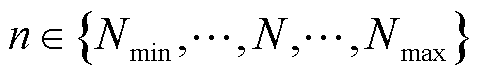 ,
,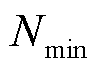 为最低采集频次,
为最低采集频次,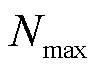 为最高采集频次。定义终端单次采集的数据量为
为最高采集频次。定义终端单次采集的数据量为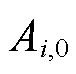 ,则不同采集频次下终端采集的数据量为
,则不同采集频次下终端采集的数据量为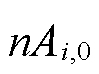 。
。
基于动态队列演进构建本地计算模型。定义本地处理队列的数据积压为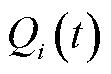 。考虑配电网不同业务终端处理能力差异性大,将数据处理过程简化为四要素模型,即数据量、计算复杂度、处理时延与计算资源。终端的本地处理数据量取决于终端计算能力与队列积压之间的较小值[7],表示为
。考虑配电网不同业务终端处理能力差异性大,将数据处理过程简化为四要素模型,即数据量、计算复杂度、处理时延与计算资源。终端的本地处理数据量取决于终端计算能力与队列积压之间的较小值[7],表示为
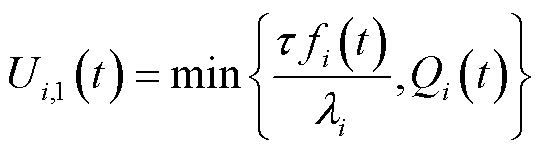 (3)
(3)
式中,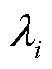 为计算复杂度,用处理单位比特业务数据所需的中央处理器(Central Processing Unit, CPU)频率表示;
为计算复杂度,用处理单位比特业务数据所需的中央处理器(Central Processing Unit, CPU)频率表示;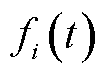 为能够提供的计算资源。每一时隙数据处理完毕后,本地处理队列数据积压的时隙间动态演进表示为
为能够提供的计算资源。每一时隙数据处理完毕后,本地处理队列数据积压的时隙间动态演进表示为
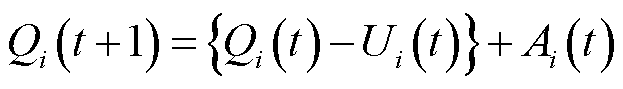 (4)
(4)
式中,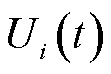 为云边端协同处理数据量;
为云边端协同处理数据量;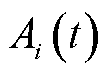 为在时隙内采集的数据量。
为在时隙内采集的数据量。
第时隙终端采用信道j进行端边数据传输的速率表示为
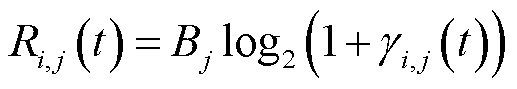 (5)
(5)
式中,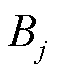 为传输带宽;
为传输带宽;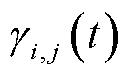 为信干噪比,表示为
为信干噪比,表示为
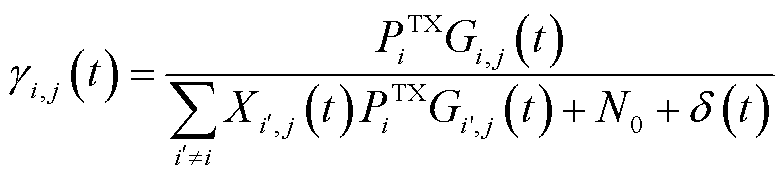 (6)
(6)
式中,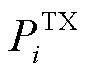 和
和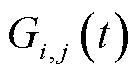 分别为传输功率和信道增益;
分别为传输功率和信道增益; 数据时产生的同频干扰;
数据时产生的同频干扰;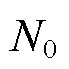 为加性高斯白噪声功率;
为加性高斯白噪声功率;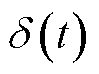 为中高压电气设备工作产生的电磁干扰,具有显著脉冲特性。采用Alpha稳态分布对其进行量化,其特征函数表示为
为中高压电气设备工作产生的电磁干扰,具有显著脉冲特性。采用Alpha稳态分布对其进行量化,其特征函数表示为
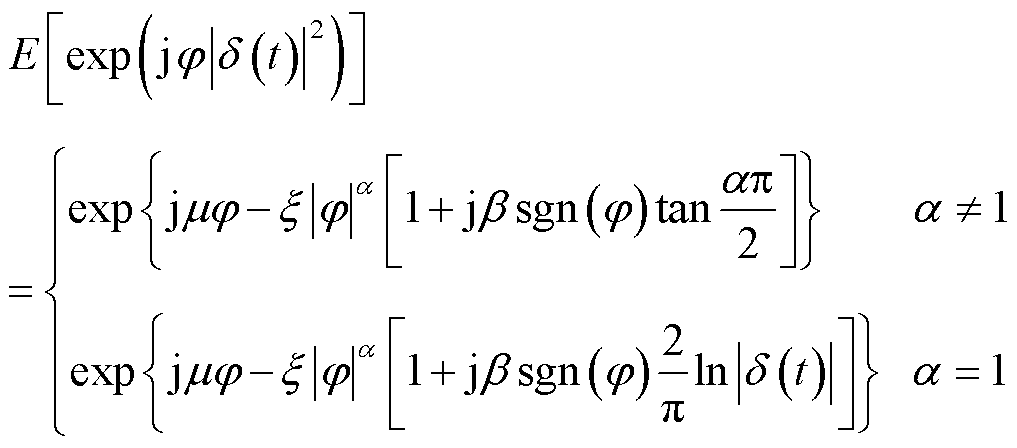 (7)
(7)
式中,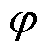 为常数;
为常数;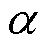 、
、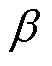 、
、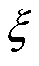 和
和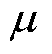 分别为电磁干扰的特征因子、偏斜参数、尺度参数和位置参数。
分别为电磁干扰的特征因子、偏斜参数、尺度参数和位置参数。
边缘处理模式下,边缘服务器可以处理的数据量取决于边端间无线信道传输能力、边缘服务器计算能力以及本地业务数据队列积压的较小值,即
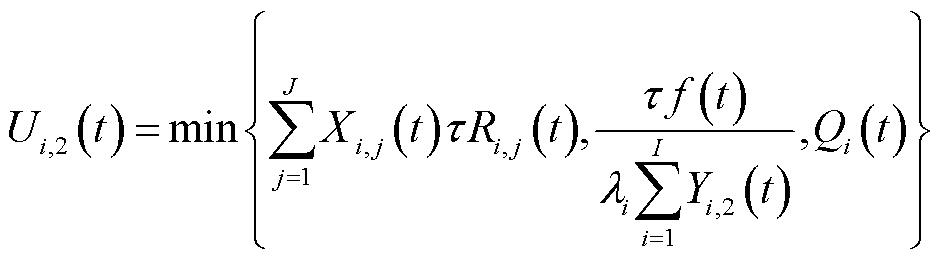 (8)
(8)
式中, 为边缘服务器能够提供的计算资源;
为边缘服务器能够提供的计算资源;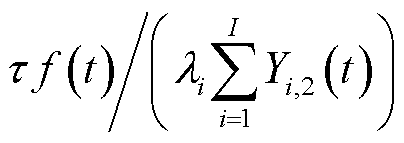 为边缘服务器用于处理终端数据所分配的计算资源。
为边缘服务器用于处理终端数据所分配的计算资源。
由式(8)可以看出,终端业务数据处理量不仅与自身处理决策相关,还受其他终端处理决策的影响,例如,当复用某一较好信道的终端较多时,所获得的性能可能不如独享某一较差信道。
云端具有充足的存储、计算资源,可通过数据挖掘、高性能存储等技术对边/端上传的电力数据进行分析与管理,因此,假设上传至云端的业务数据均可在规定时间内处理完成。在云处理模式下,可以处理的数据量取决于端边之间无线信道传输能力、云边之间通信链路传输能力以及本地业务数据队列积压的较小值,即
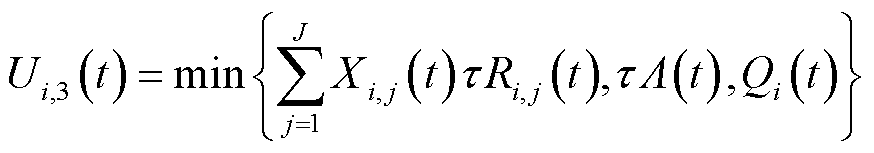 (9)
(9)
式中,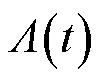 为云边通信链路可提供的传输速率,受路由转发、网络拥塞等多重因素影响,具有高度时变性和不确定性。
为云边通信链路可提供的传输速率,受路由转发、网络拥塞等多重因素影响,具有高度时变性和不确定性。
考虑本地计算、边缘处理和云处理的差异化模型构建,云边端协同处理数据量表示为
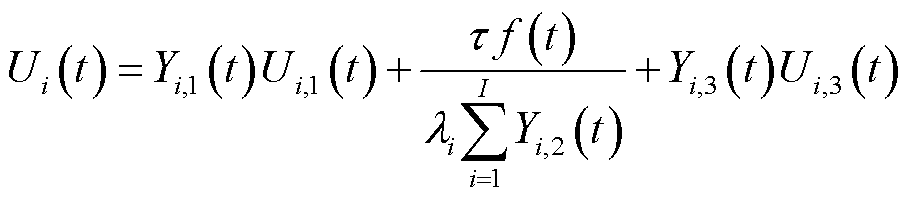 (10)
(10)
高频采集场景下业务数据量激增易导致终端层业务数据队列排队时延过长,对配电网运行决策准确性造成的影响不可忽视。此外,配电网高频采集业务,如用电信息采集、电能质量监测、配电自动化、精准负荷控制等,对采集数据量都有最小要求。因此,面向高频采集的云边端协同处理数据量还需考虑终端侧本地处理排队时延约束[20],以及长时平均采集数据量约束,分别表示为
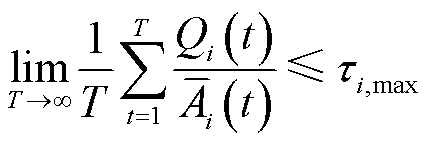 (11)
(11)
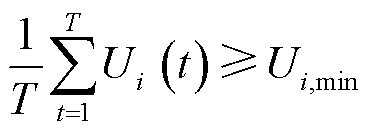 (12)
(12)
式中,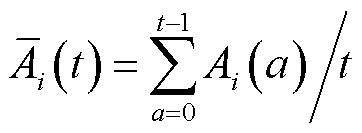 ;
;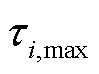 为排队时延阈值;
为排队时延阈值;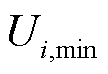 为终端在整体优化时间中配电网高频采集业务正常运行所需的最小数据量。
为终端在整体优化时间中配电网高频采集业务正常运行所需的最小数据量。
综上所述,本文在保障排队时延和长时平均采集数据量约束前提下,以最大化云边端协同处理数据量为优化目标,能够在保障有足够底层数据支撑新型电力业务正常开展的同时,降低排队时延,具体表示为
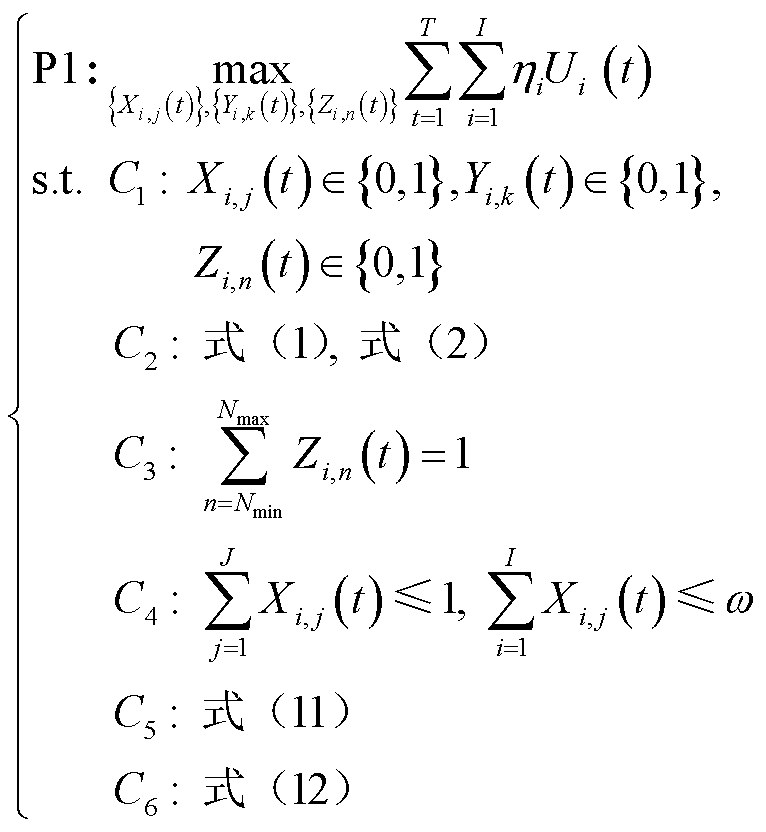 (13)
(13)
式中,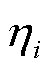 为不同终端的业务重要度,
为不同终端的业务重要度,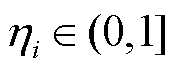 ,越大表示该终端业务对配电网稳定运行更重要;
,越大表示该终端业务对配电网稳定运行更重要;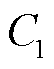 为无线信道选择变量、业务处理决策变量和采集频次控制变量取值范围约束;
为无线信道选择变量、业务处理决策变量和采集频次控制变量取值范围约束;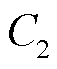 为模式约束与边缘服务器业务处理约束;
为模式约束与边缘服务器业务处理约束;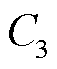 、
、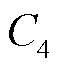 分别为每个终端在每个时隙内只能选择一个频次采集数据,至多只能选择一个信道上传业务,且每条信道至多被
分别为每个终端在每个时隙内只能选择一个频次采集数据,至多只能选择一个信道上传业务,且每条信道至多被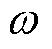 个终端所选择;
个终端所选择;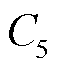 、
、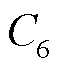 分别为排队时延约束与长时平均采集数据量约束。
分别为排队时延约束与长时平均采集数据量约束。
由于每时隙业务处理决策与排队时延和长时平均采集数据量约束相互耦合,难以直接求解优化问题P1。因此,引入李雅普诺夫优化中的虚拟队列[21],将排队时延约束和长时平均采集数据量约束转换为队列稳定性约束,从而将长期优化问题解耦为单时隙确定性优化问题。定义排队时延虚拟队列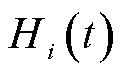 、长时平均采集数据量虚拟队列
、长时平均采集数据量虚拟队列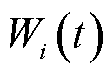 ,时隙间更新公式分别为
,时隙间更新公式分别为
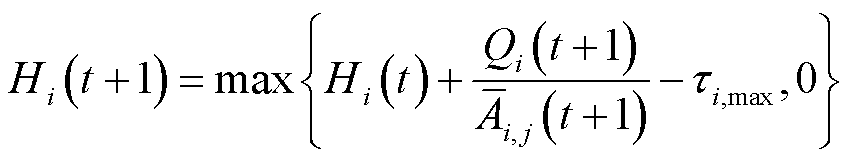 (14)
(14)
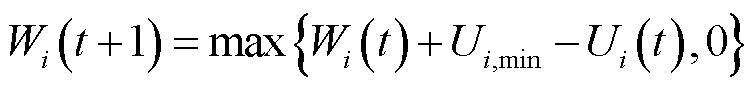 (15)
(15)
式中,为第个时隙后本地处理数据队列的排队时延与排队时延阈值之间的偏差;为当前时隙平均采集数据量与长时平均采集数据量阈值之间的偏差。基于李雅普诺夫优化理论,当虚拟队列和稳定时,所对应的长时约束和得到满足[21]。
定义向量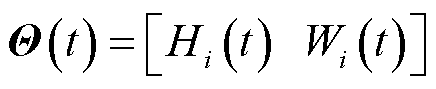 ,则李雅普诺夫函数可表示为
,则李雅普诺夫函数可表示为
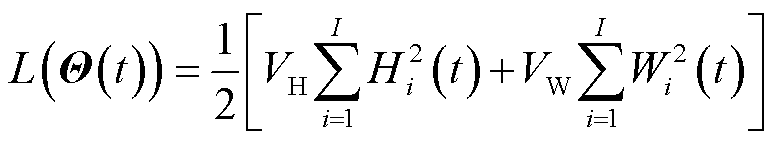 (16)
(16)
式中,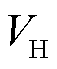 和
和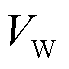 分别为排队时延和长时平均采集数据量虚拟队列的权重参数,用来平衡优先级。
分别为排队时延和长时平均采集数据量虚拟队列的权重参数,用来平衡优先级。
进一步引入李雅普诺夫漂移理论,化简原优化问题,为后续算法提供支撑。李雅普诺夫漂移定义为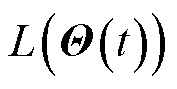 在时隙间期望值的差值,通过最小化李雅普诺夫漂移可有效保障队列积压处于较小状态,同时结合本文优化目标,构造李雅普诺夫漂移加惩罚函数,即
在时隙间期望值的差值,通过最小化李雅普诺夫漂移可有效保障队列积压处于较小状态,同时结合本文优化目标,构造李雅普诺夫漂移加惩罚函数,即
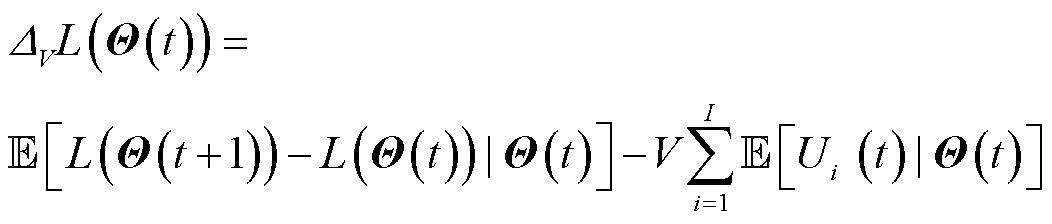 (17)
(17)
式中,V为非负的权重系数,用来实现最小化队列漂移与最大化云边端协同处理数据量之间的权衡。
将式(16)代入式(17)并简化可以得到漂移加惩罚的上界为
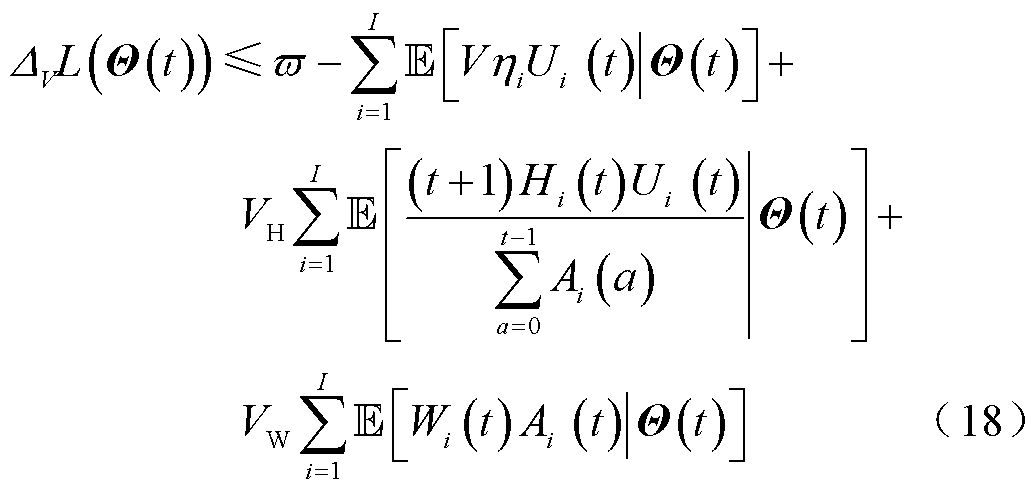
式中,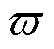 为不影响李雅普诺夫优化的正常数。因此,将P1转换为最大化漂移加惩罚上界的相反数,表示为
为不影响李雅普诺夫优化的正常数。因此,将P1转换为最大化漂移加惩罚上界的相反数,表示为
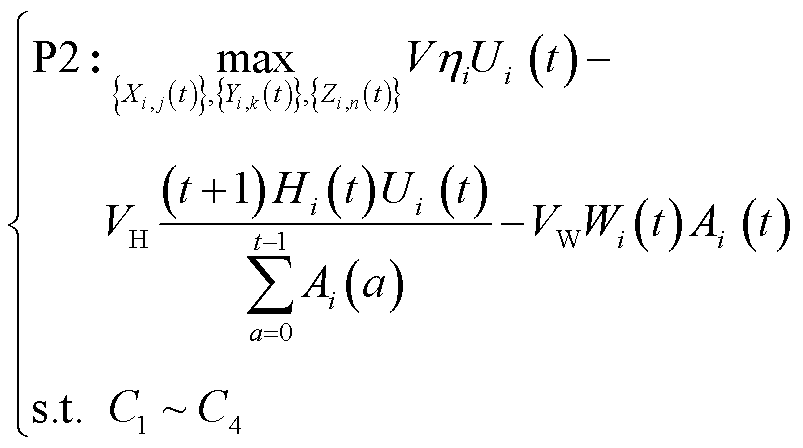 (19)
(19)
尽管原始优化问题已经被转换为仅依赖当前时隙信息便可在线优化的新问题,但由于配电网信道传输能力的波动性,以及多终端处理决策耦合带来的信息不确定性,优化问题P2仍难以被直接求解。因此,本文进一步将P2建模为一个经典的马尔可夫决策(Markov Decision Process, MDP)优化问题,包括状态空间、动作空间和奖励三个元素,具体介绍如下。
1)状态空间:时隙内的状态包括的业务队列积压、新采集的数据量、终端处理数据量,以及排队时延和长时平均采集数据量的虚拟队列积压,即
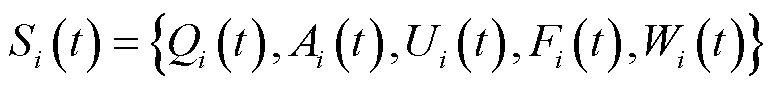 (20)
(20)
2)动作空间:定义为变量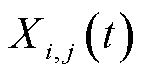 、
、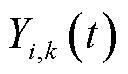 和
和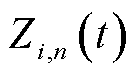 组成的集合,即
组成的集合,即
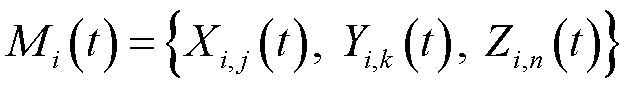 (21)
(21)
3)奖励:定义为P2的优化目标值,表示为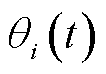 。
。
深度强化学习算法,例如DQN,通过引入经验回放机制使智能体在与环境交互中学习最优策略,具有自适应特性,能够高效处理复杂高维状态空间问题,在收敛性更佳的同时还具有轻量化的特点,可以作为一个应用嵌入边缘层,不会影响配电网本身的业务数据处理。然而,传统DQN算法在解决资源受限场景下的竞争冲突问题时存在迭代较慢、寻优性能差的劣势。针对上述问题,本文提出IDCEE算法,原理如图2所示。IDCEE算法通过引入基于贪婪策略的Q值排序机制以及双重回放机制对传统DQN方法加以改进,从而提升算法的收敛性,保障配电网高频采集业务的有序运行。
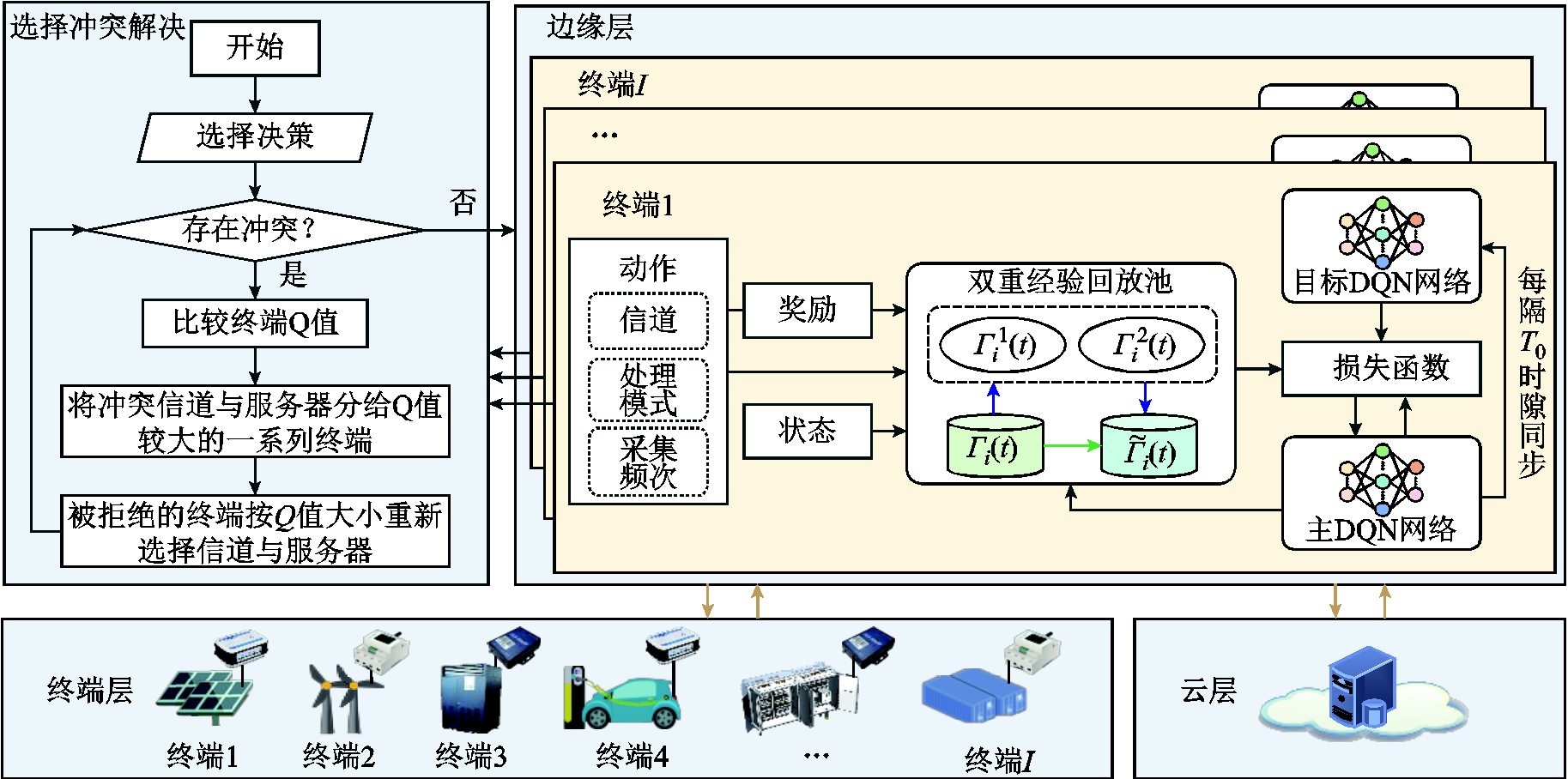
图2 IDCEE算法原理
Fig.2 IDCEE algorithm schematic diagram
所提IDCEE算法部署于边缘层,作为云边端协同与跨层级信息交互的中间环节,边缘层可向下感知终端层业务数据采集与处理情况及边端之间传输性能,也可向上获取云边之间传输性能及云层聚合信息。边缘服务器为每个终端维护主DQN和目标DQN两个网络,以及两个回放经验池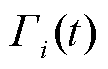 与
与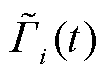 。主网络和目标网络结构的参数可分别表示为
。主网络和目标网络结构的参数可分别表示为 和
和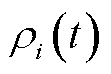 。目标网络和经验池能够通过削弱连续时隙内数据之间的联系而优化主网络的性能。边缘层通过主网络在每个时隙学习业务处理决策并下发至终端,终端执行决策并更新信息反馈给边缘服务器。IDCEE算法主要包含初始化、动作选择、冲突解决、学习和更新共五个阶段。
。目标网络和经验池能够通过削弱连续时隙内数据之间的联系而优化主网络的性能。边缘层通过主网络在每个时隙学习业务处理决策并下发至终端,终端执行决策并更新信息反馈给边缘服务器。IDCEE算法主要包含初始化、动作选择、冲突解决、学习和更新共五个阶段。
1)初始化阶段:初始化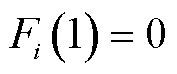 ,
,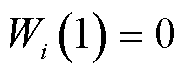 。
。
2)动作选择阶段:在第时隙初,将当前时隙的状态空间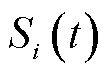 输入主网络中,得到动作Q值
输入主网络中,得到动作Q值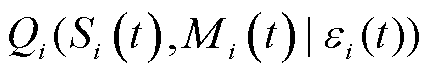 ,并根据贪婪策略选择当前时隙内Q值最大的动作作为本时隙的处理策略,即选择相应的处理模式、信道与采集频次。选择本地计算的终端直接执行动作
,并根据贪婪策略选择当前时隙内Q值最大的动作作为本时隙的处理策略,即选择相应的处理模式、信道与采集频次。选择本地计算的终端直接执行动作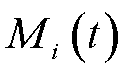 ,并计算本时隙的奖励。需要上传至边缘和云层的业务由终端向其发出处理请求。
,并计算本时隙的奖励。需要上传至边缘和云层的业务由终端向其发出处理请求。
3)冲突解决阶段:由于不同终端之间的决策相互耦合,当选择同一信道或边缘服务器的终端数量超过其配额约束时,会产生决策冲突。在配额允许的范围内,将资源分配给Q值排序靠前的终端,并拒绝其他终端的处理请求。被驳回的终端将Q值最大的动作剔除后,根据Q值排列顺序重新执行其他动作。重复上述过程,直到所有终端的处理请求被接收。接下来各终端执行所选取的动作,并计算奖励值。
4)学习阶段:传统DQN方法由于采用随机抽样机制,忽略了动作经验池中不同样本的差异性,导致收敛性较差。因此,本文结合不同终端业务重要度,设计了一种双重回放机制来提升算法收敛性。
首先,设置动作样本经验池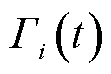 的最大容量为
的最大容量为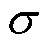 ,每个时隙末,转移至下一个状态
,每个时隙末,转移至下一个状态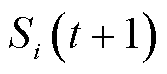 ,主网络生成本时隙的动作样本
,主网络生成本时隙的动作样本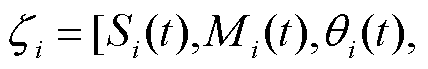
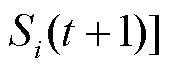 并放入经验池。经验池中所有动作样本的实时奖励均值为
并放入经验池。经验池中所有动作样本的实时奖励均值为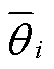 ,当经验池满额时,按照先入先出原则对最早存入的动作样本进行判定,若其奖励值大于或等于,则将其移至经验池
,当经验池满额时,按照先入先出原则对最早存入的动作样本进行判定,若其奖励值大于或等于,则将其移至经验池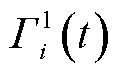 ,否则移至经验池
,否则移至经验池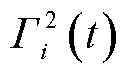 ,然后继续存入动作样本至经验池。
,然后继续存入动作样本至经验池。
然后,当前期经验池中样本数不足时,主网络从经验池中随机抽取动作样本数据构成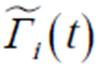 ,当经验池和中动作样本数据充足时,分别以和
,当经验池和中动作样本数据充足时,分别以和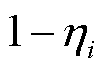 的概率从和中抽取样本数据构成,这样既保证了样本的多样性,同时对于高重要度终端而言,有效地避免了“激进”策略可能导致的数据损失。进一步计算当前时隙内的损失函数,即
的概率从和中抽取样本数据构成,这样既保证了样本的多样性,同时对于高重要度终端而言,有效地避免了“激进”策略可能导致的数据损失。进一步计算当前时隙内的损失函数,即
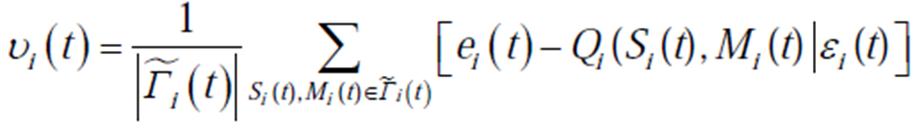 (22)
(22)
式中,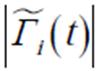 为中的样本数量;
为中的样本数量;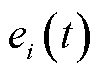 表示为
表示为
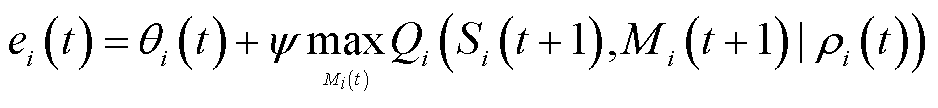 (23)
(23)
式中,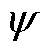 为折扣因子。
为折扣因子。
5)更新阶段:基于损失函数更新主网络的参数,且每隔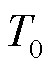 个时隙将目标网络与主网络同步。而后进入下一时隙,迭代执行上述步骤,直到优化结束。
个时隙将目标网络与主网络同步。而后进入下一时隙,迭代执行上述步骤,直到优化结束。
所提IDCEE算法的复杂度分析如下。在动作选择阶段,每个终端需要对Q值进行排序选取,采用快速排序法的复杂度为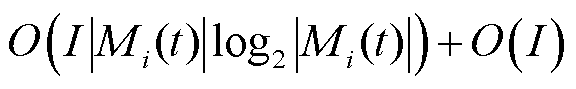 ,其中动作空间
,其中动作空间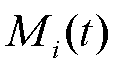 大小为
大小为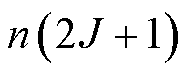 ;在冲突解决阶段,冲突发生的最大可能次数为
;在冲突解决阶段,冲突发生的最大可能次数为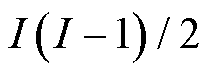 ,则对应的复杂度为
,则对应的复杂度为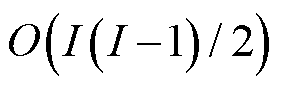 ;在学习阶段,每个动作样本至多经历存入、均值计算、比较、转存四个环节,其复杂度为
;在学习阶段,每个动作样本至多经历存入、均值计算、比较、转存四个环节,其复杂度为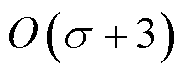 ,并在之后抽取一定数量样本数据构成
,并在之后抽取一定数量样本数据构成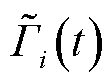 ,其复杂度为
,其复杂度为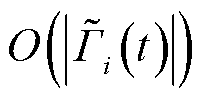 ;在更新阶段,假设所构建神经网络层数为
;在更新阶段,假设所构建神经网络层数为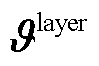 ,每层至多有
,每层至多有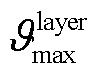 个神经元,网络更新的复杂度为
个神经元,网络更新的复杂度为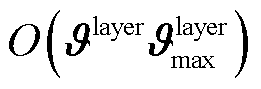 。
。
本文考虑的场景为一个300 m×2 km的条带状区域,终端按照局部集中、整体分散的方式随机分布,从而模拟实际的配电线路与配电房场景,基站位于条带区域中心。结合目前配电网实际业务及发展趋势,终端部署密度设置为500个/km2,根据实际电表性能与差异化业务需求,将业务数据采集周期设置为0.1、0.25、0.5、1 min四种时间尺度,单次采集数据量为1.50~3.00 Mbits。基站和终端之间的路径损耗(dB)服从正态分布[22],信道增益(dB)的数值大小为路径损耗的相反数;电磁干扰(dBm)服从Alpha稳定分布[23],其余仿真参数设置见表2。
表2 仿真参数
Tab.2 Simulation parameters
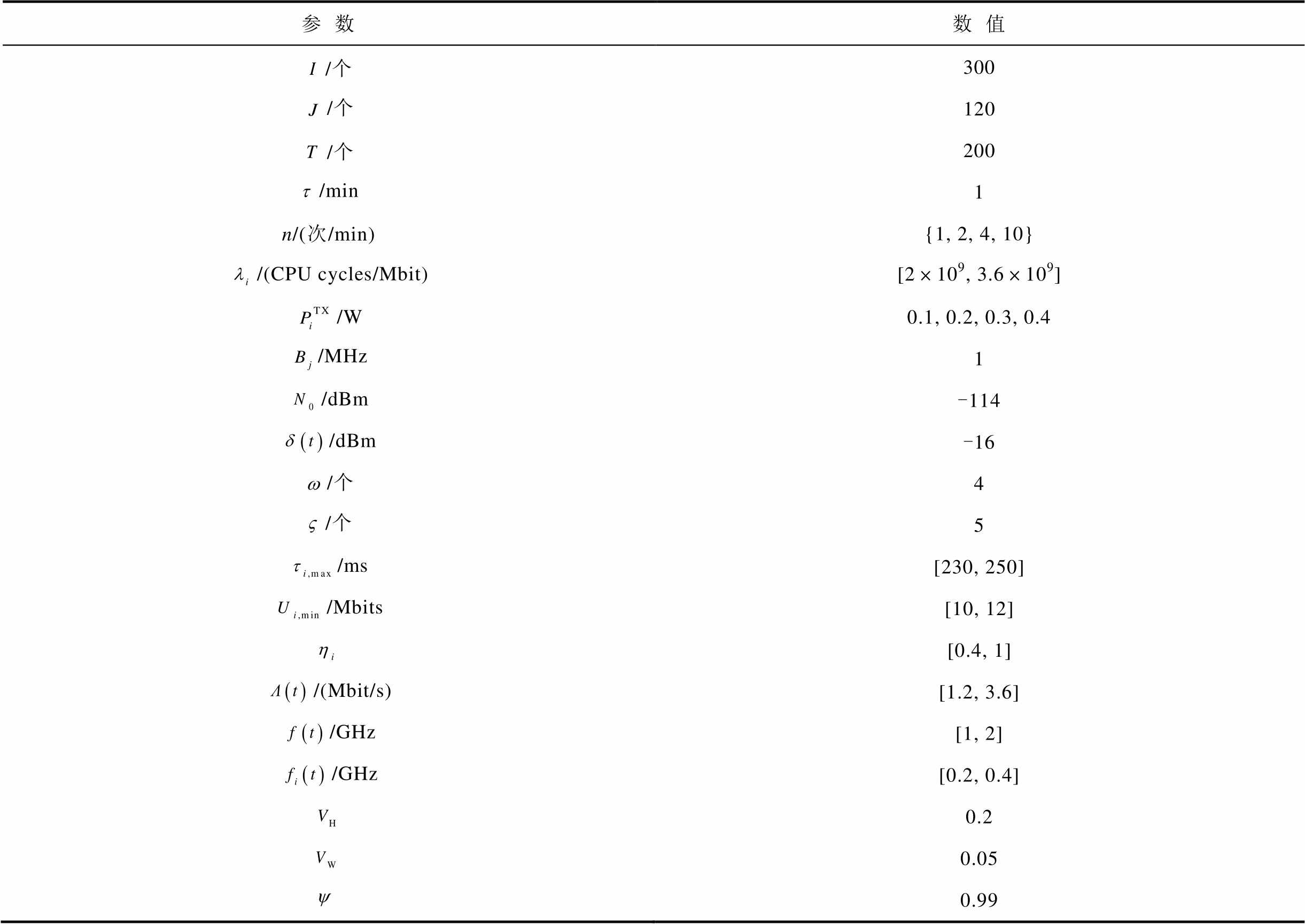
参数数值 /个300 /个120 /个200 /min1 n/(次/min){1, 2, 4, 10} /(CPU cycles/Mbit)[2×109, 3.6×109] /W0.1, 0.2, 0.3, 0.4 /MHz1 /dBm-114 /dBm-16 /个4 /个5 /ms[230, 250] /Mbits[10, 12] [0.4, 1] /(Mbit/s)[1.2, 3.6] /GHz[1, 2] /GHz[0.2, 0.4] 0.2 0.05 0.99
本文将所提算法与两种传统深度强化学习算法进行比较,分别是传统DQN算法[17]与A3C算法[18],对比算法优化目标与本文一致,两种对比算法均未考虑排队时延与长时平均采集数据量约束。
图3为云边端协同处理数据量随时隙的变化情况对比。截至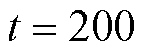 ,相较于A3C和传统DQN算法,IDCEE算法的云边端协同处理数据量分别提升11.71%和14.86%。因为所提算法通过设置排队时延和长时平均采集数据量约束,在保障自身时延的基础上,采集尽可能多的数据以提高终端处理数据总量,并利用IDCEE强大的数据拟合能力实时感知虚拟队列状态,在考虑上述约束前提下联合优化云边端协同处理数据量。A3C与传统DQN未考虑上述约束,导致云边端协同处理数据量较低。
,相较于A3C和传统DQN算法,IDCEE算法的云边端协同处理数据量分别提升11.71%和14.86%。因为所提算法通过设置排队时延和长时平均采集数据量约束,在保障自身时延的基础上,采集尽可能多的数据以提高终端处理数据总量,并利用IDCEE强大的数据拟合能力实时感知虚拟队列状态,在考虑上述约束前提下联合优化云边端协同处理数据量。A3C与传统DQN未考虑上述约束,导致云边端协同处理数据量较低。
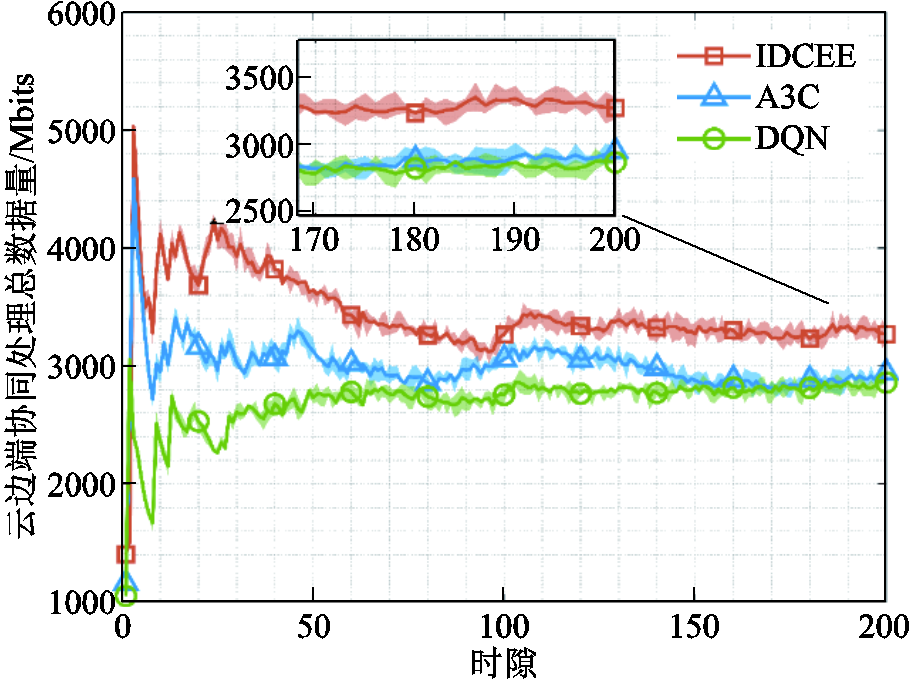
图3 云边端协同处理总数据量随时隙的变化情况对比
Fig.3 Contrast of total amount of cloud-edge-end collaborative processed data versus time slot
图4为排队时延随时隙的变化情况对比。由于未考虑长时排队时延约束,A3C和传统DQN的排队时延在优化初期相比所提算法明显增加。所提IDCEE算法通过优先传输数据排队时延长的终端的高频采集数据,实现了最低平均排队时延,截至,相较于A3C和传统DQN,所提IDCEE算法能够降低排队时延24.68%和26.09%。A3C和传统DQN算法在解决资源受限场景下的竞争冲突问题时存在复杂度较高、迭代较慢的劣势,优化效果较差。
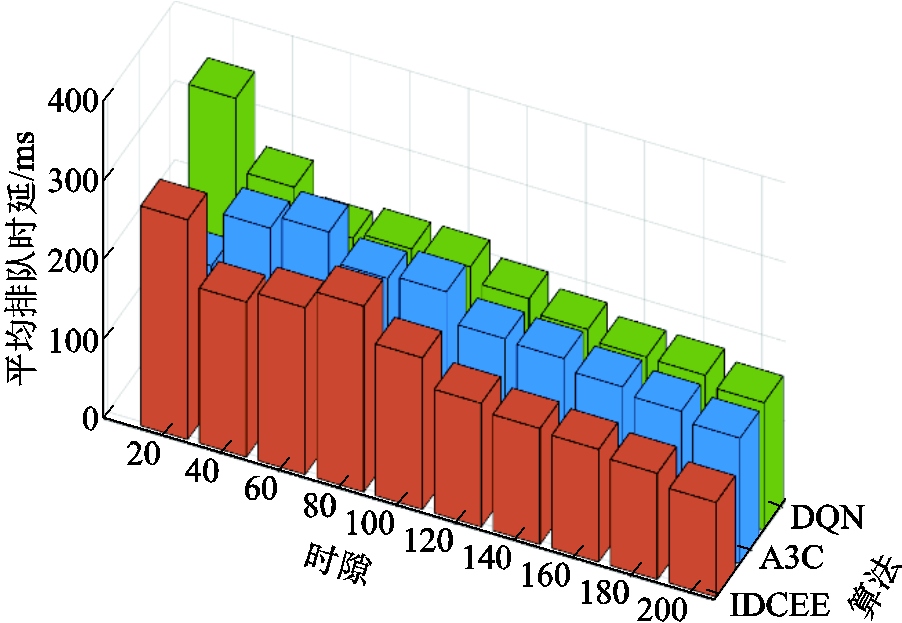
图4 排队时延随时隙的变化情况对比
Fig.4 Contrast of queuing delay versus time slot
图5为终端总采集数据量随时隙的变化情况对比。截至,相较于A3C和传统DQN,所提IDCEE算法的平均采集数据量分别提升8.87%和7.44%。在优化初期,DQN的总采集数据量较小,之后随着时隙快速增加,其总采集数据量达到最大,但很快降低。所提算法因为设置长时平均采集数据量约束,从优化初期便始终保持较高的采集数据量,满足配电网高频采集业务对采集数据量的要求。
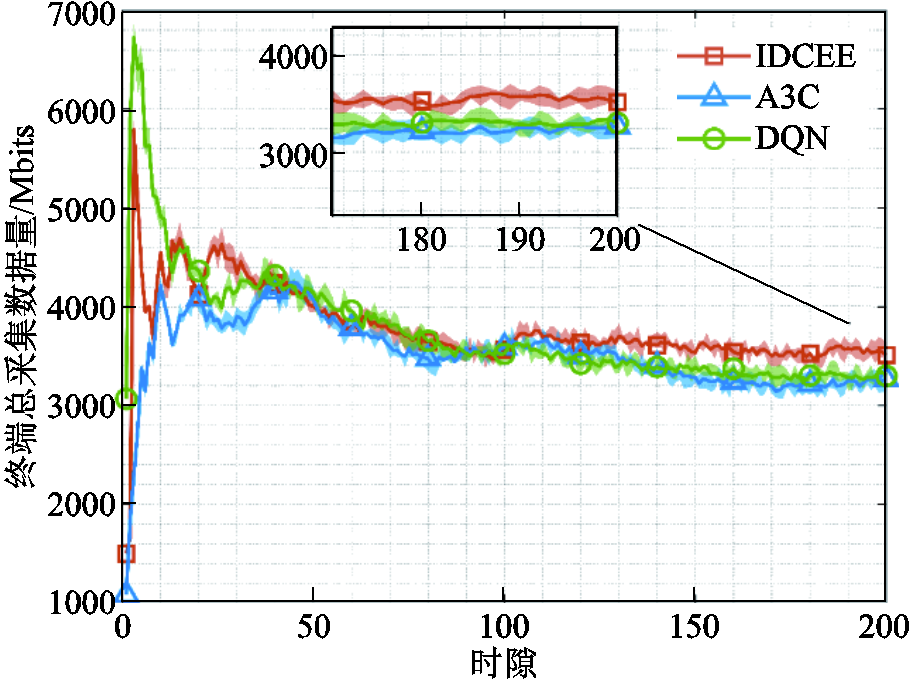
图5 终端总采集数据量随时隙的变化情况对比
Fig.5 Contrast of total amount of data collected by device versus time slot
图6为本地计算资源对排队时延与云边端协同处理数据量的影响。随着本地计算资源的增加,三种算法均逐步降低排队时延、增加云边端协同处理数据量。这是因为本地计算资源的增加使得终端可在本地进行处理的数据量增加,传输数据量减小,从而降低了排队时延。A3C和传统DQN算法由于未考虑排队时延约束,排队时延较高。当本地计算资源为0.1 GHz时,相较于A3C和传统DQN,所提算法的排队时延分别降低了13.73%和22.64%,云边端协同处理数据量分别提高了21.96%和34.58%。所提算法基于改进DQN强大的数据拟合能力在保障低排队时延的前提下实现了处理数据量的快速提升。
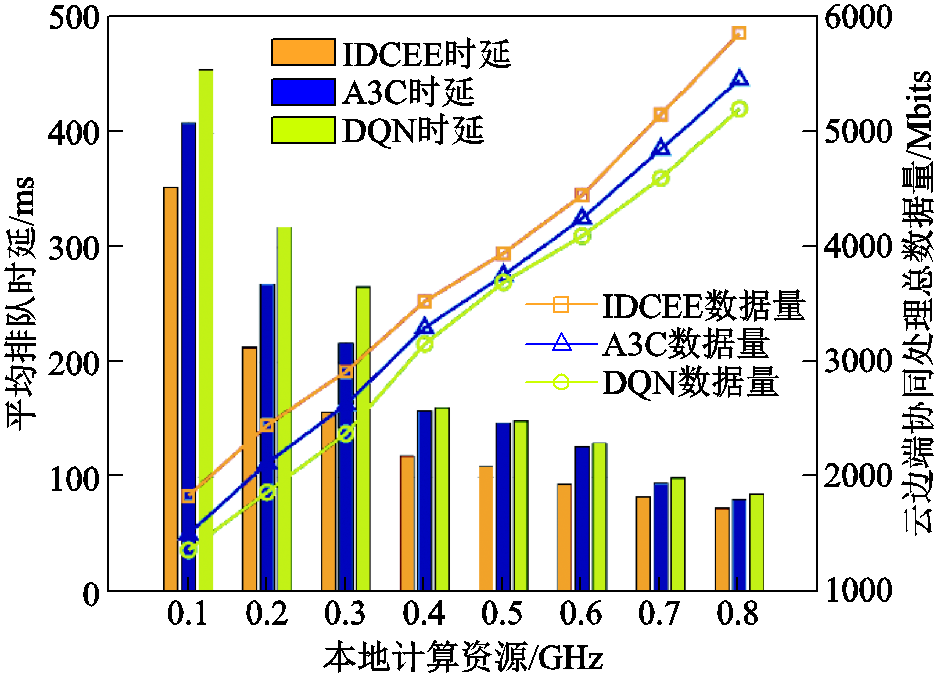
图6 本地计算资源对排队时延与处理数据量的影响
Fig.6 Impact of local computing resource on queuing delay and amount of processed data
图7为三种算法的平均采集数据量虚拟赤字和排队时延虚拟赤字情况对比。仿真结果表明,相较于A3C和传统DQN,所提IDCEE算法的平均采集数据量虚拟赤字中位数分别降低39.15%和40.37%,排队时延虚拟赤字平均值分别降低80.79%和43.15%。因为所提算法引入李雅普诺夫优化理论,并对平均采集数据量和排队时延约束加以考虑,结合深度学习的特征感知和强化学习的决策能力,拟合提取环境特征信息,实时感知队列稳定性。A3C无法有效协调多终端对于有限资源的竞争,难以保障终端平均采集数据量和排队时延赤字的优化性能;而传统DQN缺乏终端虚拟队列赤字感知能力,终端虚拟队列赤字优化效果最差。
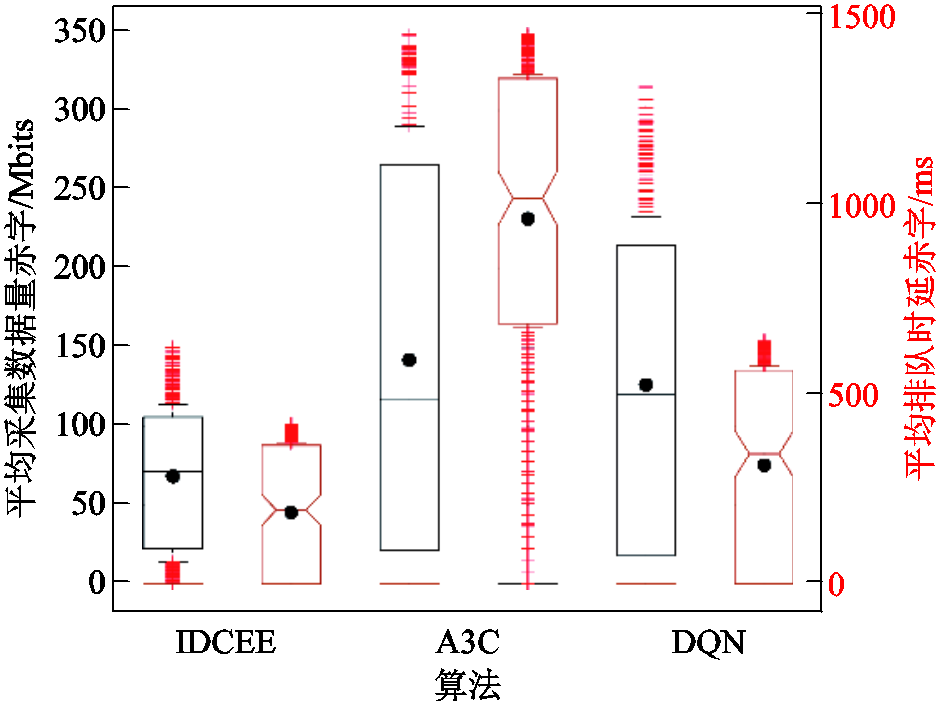
图7 平均采集数据量和排队时延虚拟赤字情况对比
Fig.7 Contrast of average data acquisition and queuing delay virtual deficit situation
图8为终端层队列积压情况对比。相较于A3C和传统DQN,所提算法终端层队列积压波动最小,且终端层队列积压中位数分别降低66.39%和77.93%。其原因在于所提算法考虑长时平均采集数据量约束,通过构建虚拟队列对其解耦,同时通过IDCEE在考虑长时排队时延前提下优化云边端协同处理数据量。而A3C未考虑长时稳定性约束,传统DQN缺乏大状态空间下队列积压感知能力,因此数据队列持续积压。
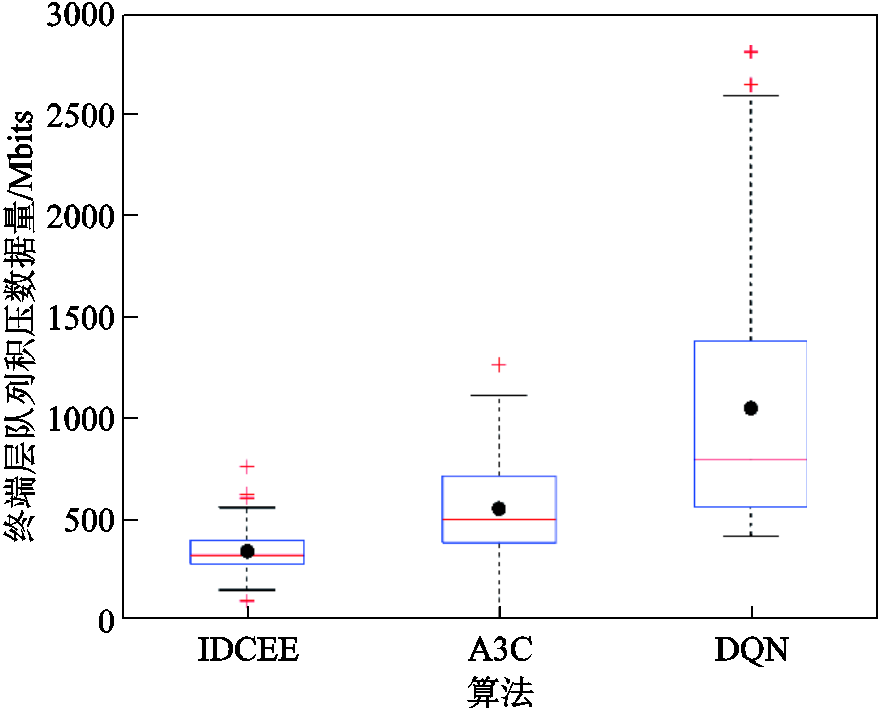
图8 终端层队列积压情况对比
Fig.8 Contrast of device layer queue backlog situation
图9为损失函数值随时隙的变化情况对比。相较于A3C和传统DQN,所提算法分别降低了损失函数最终收敛值16.97%和33.04%。其原因在于所提算法引入了基于贪婪策略的Q值排序机制以及双重回放机制,其收敛的速度更快,收敛到的数值结果更优。传统DQN算法在解决资源受限场景下的竞争冲突问题时复杂度高,导致收敛最慢,收敛效果最差。A3C算法尽管采用了策略梯度和异步更新机制,但无法有效协调多终端对于有限资源的竞争,因而性能相较于所提算法较差。
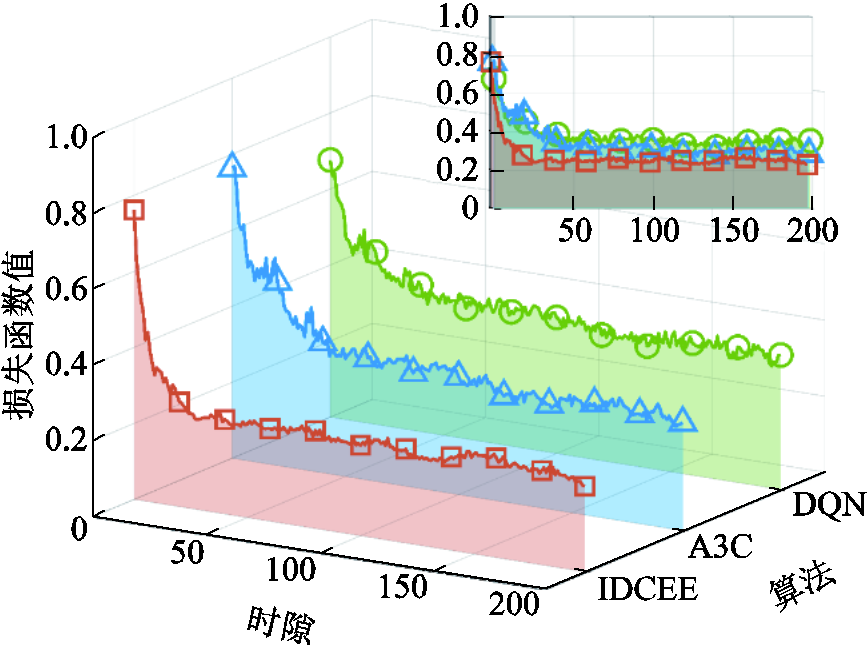
图9 损失函数值随时隙的变化情况对比
Fig.9 Contrast of loss function value versus time slot
在面向新能源广泛接入背景下配电网业务数据采集终端接入规模与采集频次激增问题,本文提出了一种面向配电网高频采集的云边端协同业务处理机制,通过整合云边端算力资源,解决业务排队时延和长时平均采集数据量约束下最大化云边端协同处理数据量优化问题,为高频采集通信容量不足、多业务通道复用不足、本地通道与远程通道协同等卡脖子问题提供技术支撑,保障配电网高频采集业务处理时效性与可靠性,为新型电力系统建设及双碳目标实现贡献力量。仿真结果表明,相较于A3C与传统DQN算法,所提算法在云边端协同处理数据量、排队时延、平均采集数据量、损失函数收敛等方面具有性能优势,其中云边端协同处理数据量提升11.71%和14.86%,排队时延降低24.68%和26.09%,平均采集数据量提升8.87%和7.44%,终端层队列积压数据量降低66.39%和77.93%,降低损失函数最终收敛值16.97%和33.04%。接下来,作者团队将进一步考虑数据传输及处理过程中的信息同步与安全问题,结合异步更新机制及联邦平均等先进思想,继续开发更为安全高效的业务数据采集终端数据处理方法。
参考文献
[1] 陈亚鹏, 刘朋矩, 周振宇, 等. 面向业务可靠承载的电力弹性光网络自主协同决策[J]. 电工技术学报, 2023, 38(21): 5821-5831, 5877.
Chen Yapeng, Liu Pengju, Zhou Zhenyu, et al. Autonomous collaborative decision-making for power elastic optical network oriented to service reliable bearing[J]. Transactions of China Electrotechnical Society, 2023, 38(21): 5821-5831, 5877.
[2] 谢可, 郭文静, 祝文军, 等. 面向电力物联网海量终端接入技术研究综述[J]. 电力信息与通信技术, 2021, 19(9): 57-69.
Xie Ke, Guo Wenjing, Zhu Wenjun, et al. Review on access technology of massive terminals of power Internet of Things[J]. Electric Power Information and Communication Technology, 2021, 19(9): 57-69.
[3] 姜云鹏, 任洲洋, 李秋燕, 等. 考虑多灵活性资源协调调度的配电网新能源消纳策略[J]. 电工技术学报, 2022, 37(7): 1820-1835.
Jiang Yunpeng, Ren Zhouyang, Li Qiuyan, et al. An accommodation strategy for renewable energy in distribution network considering coordinated dispatching of multi-flexible resources[J]. Transactions of China Electrotechnical Society, 2022, 37(7): 1820-1835.
[4] 潘玺安, 艾欣, 胡俊杰, 等. 考虑网络安全约束的分布式智能电网边云协同优化调度方法[J]. 电工技术学报, 2024, 39(19): 6104-6118.
Pan Xian, Ai Xin, Hu Junjie, et al. Network security constrained distributed smart grid edge-cloud collaborative optimization scheduling[J]. Transactions of China Electrotechnical Society, 2024, 39(19): 6104-6118.
[5] 陈亚鹏, 周振宇, 韩东升, 等. 电力+5G前传网中融合时延敏感网络技术的流量调度方法[J]. 电子学报, 2023, 51(5): 1141-1147.
Chen Yapeng, Zhou Zhenyu, Han Dongsheng, et al. TSN-integrated flow scheduling method in Power+5G fronthaul network[J]. Acta Electronica Sinica, 2023, 51(5): 1141-1147.
[6] 倪利, 吕湛, 沈正, 等. 基于云计算的电力系统突发性数据处理任务调度方法[J]. 自动化与仪器仪表, 2021(8): 56-59.
Ni Li, Lü Zhan, Shen Zheng, et al. Cloud computing based scheduling method for sudden data processing in power system[J]. Automation & Instrumentation, 2021(8): 56-59.
[7] Liao Haijun, Jia Zehan, Zhou Zhenyu, et al. Cloud-edge-end collaboration in air–ground integrated power IoT: a semidistributed learning approach[J]. IEEE Transactions on Industrial Informatics, 2022, 18(11): 8047-8057.
[8] 李鹏, 习伟, 李鹏, 等. 基于边缘计算的配电网数字化转型关键问题分析与展望[J]. 电力系统自动化, 2024, 48(6): 29-41.
Li Peng, Xi Wei, Li Peng, et al. Analysis of key issues and prospect for digital transformation of distribution networks based on edge computing[J]. Automation of Electric Power Systems, 2024, 48(6): 29-41.
[9] 文祥宇, 李帅, 刘文彬, 等. 面向配电网的云边端协同技术研究[J]. 山东电力技术, 2022, 49(7): 8-11.
Wen Xiangyu, Li Shuai, Liu Wenbin, et al. Research on cloud-edge-user collaboration technology for distribution network[J]. Shandong Electric Power, 2022, 49(7): 8-11.
[10] Kai Caihong, Zhou Hao, Yi Yibo, et al. Collaborative cloud-edge-end task offloading in mobile-edge computing networks with limited communication capability[J]. IEEE Transactions on Cognitive Communications and Networking, 2021, 7(2): 624-634.
[11] 鲁蔚锋, 印文徐, 王菁, 等. 面向车辆边缘计算的任务合作卸载[J]. 工程科学与技术, 2024, 56(1): 89-98.
Lu Weifeng, Yin Wenxu, Wang Jing, et al. Task cooperative offloading for vehicle edge computing[J]. Advanced Engineering Sciences, 2024, 56(1): 89-98.
[12] 张俊娜, 鲍想, 陈家伟, 等. 一种联合时延和能耗的依赖性任务卸载方法[J]. 计算机研究与发展, 2023, 60(12): 2770-2782.
Zhang Junna, Bao Xiang, Chen Jiawei, et al. A dependent task offloading method for joint time delay and energy consumption[J]. Journal of Computer Research and Development, 2023, 60(12): 2770-2782.
[13] Wang Zhong, Xue Guangtao, Qian Shiyou, et al. CampEdge: distributed computation offloading strategy under large-scale AP-based edge computing system for IoT applications[J]. IEEE Internet of Things Journal, 2021, 8(8): 6733-6745.
[14] Li Haiyuan, Assis K D R, Yan Shuangyi, et al. DRL-based long-term resource planning for task offloading policies in multiserver edge computing networks[J]. IEEE Transactions on Network and Service Management, 2022, 19(4): 4151-4164.
[15] 陈泽宇, 方志远, 杨瑞鑫, 等. 基于深度强化学习的混合动力汽车能量管理策略[J]. 电工技术学报, 2022, 37(23): 6157-6168.
Chen Zeyu, Fang Zhiyuan, Yang Ruixin, et al. Energy management strategy for hybrid electric vehicle based on the deep reinforcement learning method[J]. Transactions of China Electrotechnical Society, 2022, 37(23): 6157-6168.
[16] Huang Yakun, Qiao Xiuquan, Tang Jian, et al. An integrated cloud-edge-device adaptive deep learning service for cross-platform web[J]. IEEE Transactions on Mobile Computing, 2023, 22(4): 1950-1967.
[17] 麻秀范, 冯晓瑜. 考虑5G网络用电需求及可靠性的变电站双Q规划法[J]. 电工技术学报, 2023, 38(11): 2962-2976.
Ma Xiufan, Feng Xiaoyu. Double Q planning method for substation considering power demand of 5G network and reliability[J]. Transactions of China Electrotechnical Society, 2023, 38(11): 2962-2976.
[18] 邓世权, 叶绪国. 基于深度Q网络的多目标任务卸载算法[J]. 计算机应用, 2022, 42(6): 1668-1674.
Deng Shiquan, Ye Xuguo. Multi-objective task offloading algorithm based on deep Q-network[J]. Journal of Computer Applications, 2022, 42(6): 1668-1674.
[19] 李强, 仪晋辉, 杜婷婷, 等. 移动边缘计算中基于A3C的依赖任务卸载与资源分配[J]. 计算机工程, 2023, 49(6): 42-52.
Li Qiang, Yi Jinhui, Du Tingting, et al. Dependent task offloading and resource allocation based on A3C in mobile edge computing[J]. Computer Engineering, 2023, 49(6): 42-52.
[20] Liao Haijun, Zhou Zhenyu, Zhao Xiongwen, et al. Learning-based queue-aware task offloading and resource allocation for space air ground-integrated power IoT[J]. IEEE Internet of Things Journal, 2021, 8(7): 5250-5263.
[21] Guo Mian, Guan Quansheng, Chen Weiqi, et al. Delay-optimal scheduling of VMs in a queueing cloud computing system with heterogeneous workloads[J]. IEEE Transactions on Services Computing, 2022, 15(1): 110-123.
[22] Ding Ming, López-Pérez D, Chen Youjia, et al. Ultra-dense networks: a holistic analysis of multi-piece path loss, antenna heights, finite users and BS idle modes[J]. IEEE Transactions on Mobile Computing, 2021, 20(4): 1702-1713.
[23] 周振宇, 陈亚鹏, 潘超, 等. 面向智能电力巡检的高可靠低时延移动边缘计算技术[J]. 高电压技术, 2020, 46(6): 1895-1902.
Zhou Zhenyu, Chen Yapeng, Pan Chao, et al. Ultra-reliable and low-latency mobile edge computing technology for intelligent power inspection[J]. High Voltage Engineering, 2020, 46(6): 1895-1902.
Cloud-Edge-End Collaborative Service Processing Mechanism for High Frequency Acquisition in Distribution Network
Abstract With the widespread access of renewable energy, the access scale of distribution network service data acquisition devices and data acquisition frequency have surged. The distribution network acquisition services are rapidly developing towards high-frequency, massive, and computationally intensive directions. It is significant to fully utilize the potential of cloud-edge-end collaboration to enhance the service carrying capacity of the network. Recently, service processing methods based on cloud-edge-end collaboration have been proposed. However, these methods still face several challenges. First, the coupling of long-term constraint guarantees and short-term processing decision optimization makes it difficult for single-slot short-term decisions to achieve long-term constraint coordination. Second, the differentiated performance requirements of services and limited network resources lead to interdependence among multi-device processing decisions. Existing methods lack a collaborative processing mechanism, making it challenging to resolve decision conflicts caused by competition. Finally, most current methods adopt random sampling mechanisms, overlooking the differences among samples in the action experience pool, resulting in poor convergence and optimization performance in resolving competition conflicts under resource-constrained scenarios. To address these challenges, this paper proposes a cloud-edge-end collaborative service processing mechanism for high-frequency data acquisition in distribution network.
Firstly, a cloud-edge-end multi-level collaborative service processing framework for high-frequency acquisition in the distribution network is designed. It constructs differentiated models for local computing, edge processing, and cloud processing to meet the varied computing requirements of data acquisition services. Further, under the premise of ensuring queuing delay and long-term average data collection constraints, the objective of maximizing the amount of cloud-edge-end collaborative processed data is set, which ensures sufficient underlying data support for the normal operation of new power services while reducing queuing delay.
Subsequently, the concept of virtual queues from Lyapunov optimization theory is introduced to transform the original problem into an online optimization problem that only depends on current slot information. It plays an important role in achieving the coordinated guarantee of delay and throughput.
Then, an improved deep Q-network based cloud-edge-end collaborative processing algorithm for distribution network is proposed, which includes five stages of initialization, action selection, conflict resolution, learning, and updating. Specifically, in the action selection and conflict resolution stages, a greedy strategy-based Q-value sorting mechanism is introduced. It selects the action with the highest Q-value as the processing decision of the device for the current slot, and resolves wireless channel and edge server resource selection conflicts caused by multi-device processing decision coupling through edge-end collaboration. In the learning stage, considering the importance of different device services and the confidence of action samples, a dual replay experience pool is designed to ensure sample diversity, effectively avoiding data loss potentially caused by aggressive strategies. This greatly improves the convergence of the algorithm. The proposed algorithm ensures the orderly operation of cloud-edge-end services in distribution networks.
Finally, the effectiveness and rationality of the proposed algorithm are verified through simulation examples. The simulation results show that the proposed algorithm can increase the amount of cloud-edge-end collaborative processed data by 11.71% and 14.86%, reduce queuing delay by 24.68% and 26.09%. It can also increase the average data acquisition volume by 8.87% and 7.44%. At the same time, it significantly reduces the backlog of device layer queue backlog and greatly improves the convergence speed of the algorithm. The author team will further consider information synchronization and security issues during data transmission and processing.
Keywords:Distribution network, high frequency acquisition, cloud-edge-end collaboration, service processing, deep reinforcement learning
中图分类号:TM73
DOI: 10.19595/j.cnki.1000-6753.tces.240627
国家电网公司总部科技项目资助(No.52094021N010(5400-202199534A-0-5-ZN))。
收稿日期 2024-04-23
改稿日期 2024-07-11
于子淇 女,2000年生,硕士研究生,研究方向为配电网高频采集、云边端协同、电力物联网等。
E-mail:ziqi_yu@ncepu.edu.cn
周振宇 男,1983年生,教授,博士生导师,研究方向为新型电力系统与虚拟电厂、无线通信网络与新技术、能源互联网信息通信技术等。
E-mail:zhenyu_zhou@ncepu.edu.cn(通信作者)
(编辑 赫 蕾)