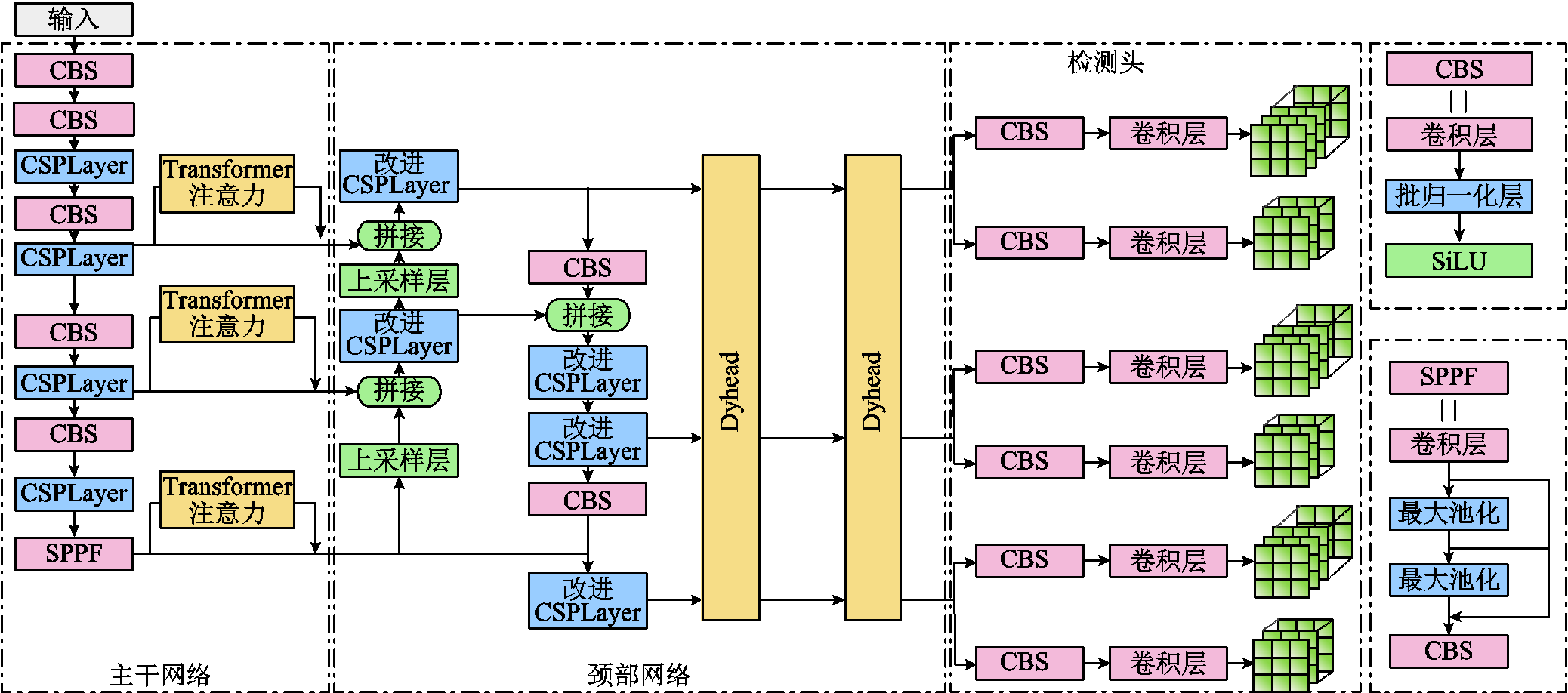
图1 ER-YOLO网络结构
Fig.1 Network architecture of ER-YOLO
摘要 为提高输电线路缺陷智能检测算法在不同环境条件下的鲁棒性,克服现有智能检测算法在不同环境下识别性能下降的问题,该文提出了跨环境鲁棒YOLO(ER-YOLO)算法。首先,基于广义注意力理论在YOLOv8的骨干网络中引入Transformer注意力机制;其次,使用大卷积核和通道注意力模块优化特征提取;最后,应用多重注意力机制检测头网络强化算法多尺度、空间位置和多任务感知能力。为获得测试数据,该文探索生成了模拟暗光、雾霾、模糊环境的虚拟数据集。经消融实验和对比分析,跨环境鲁棒YOLO算法在跨环境测试中展现了更高的缺陷识别精度和鲁棒性,各测试数据集下mAP平均值为0.726,相对改进前提升0.069,同时在实际环境下进行了验证,证明了该算法的有效性。该文提出的跨拍摄环境的输电线路缺陷识别方法,在跨环境识别中表现出卓越的性能。跨环境图像生成方法可为后续虚拟数据集生成技术提供借鉴。
关键词:输电线路 缺陷检测 深度学习 数据集生成
为确保输电线路的安全稳定运行,需要对输电线路开展定期巡检以消除潜在的故障或隐患[1]。大部分输电线路架设在人烟稀少的城市边缘区域或地形复杂的山区,采用传统的人工巡检模式实施成本及难度较高[2]。随着无人机、人工智能等技术的发展,以及智慧电网的建设,越来越多的电网单位使用无人机或固定摄像头获取输电线路巡检图像,再通过人工智能识别算法发现输电线路缺陷,已经形成了“人巡为辅,机巡为主”的自动化巡检格局[3]。
目前输电线路缺陷检测中涉及的人工智能识别算法已有较广泛的研究。李斌等[4]提出了一种基于多尺度特征融合的绝缘子缺陷检测网络,通过残差注意力网络获取不同分辨率的绝缘子缺陷特征并逐步融合,利用Focal损失和高斯非极大抑制方法提升检测效果。实验结果显示,该方法在绝缘子缺陷数据集上具有良好的性能和泛化能力。苟军年等[5]针对输电线路绝缘子缺陷检测中掩膜区域卷积神经网络(Mask Region-Convolutional Neural Networks, Mask R-CNN)模型的不足,提出了一种改进的方法。通过引入卷积注意力模块、使用全局交并比和Tversky损失计算,该方法在绝缘子照片数据集上取得了显著的检测精度提升,满足了电力巡检的要求。宋立业等[6]针对无人机电力巡检中目标检测算法的不足,提出了一种改进的EfficientDet方法。通过数据增强和特征融合等改进措施,该方法在绝缘子、防振锤等元件缺陷的检测和定位方面取得了显著的精度和速度提升。实验结果表明,该方法在准确性和快速性上优于其他先进的目标检测算法,满足了电力巡检的需求。仲林林等[7]提出了一种基于压缩激活改进的快速异常检测生成对抗网络,针对无人机电力线路巡检图像背景复杂和正负样本不均衡的问题,通过引入压缩激活网络和优化训练策略,在电力杆塔异常检测方面取得了较高的准确性和召回率。游越等[8]提出了一种改进YOLOv5方法来解决输电线路巡检中因复杂场景遮挡以及小目标而导致误检的问题,使用数据增强与扩充、注意力机制以及改进损失函数对算法进行改进。实验结果显示,改进后算法提升了对被遮挡目标和小目标的识别准确率。郑含博等[9]针对输电线路走廊隐患目标检测的问题,构建了相应数据集,并提出了一种名为YOLO-2MCS的新模型,通过混合数据增强、卷积注意力机制、双向特征金字塔结构和SIoU损失函数等创新,该模型在复杂场景下具有检测精度高、速度快和模型简单等特点,适合在边缘计算设备上部署。
但随着当前巡检模式的推广落地,一些新的问题逐渐显现出来。例如,各种缺陷识别算法对拍摄环境变化的适应性不强。基于深度学习的各种缺陷识别算法严重依赖所使用的数据集,其学习到的缺陷特征及图像特征与所使用数据集的特征分布情况高度相关。而目前用来训练缺陷识别算法的数据集大多在单一环境下拍摄所得,导致某种特定缺陷识别算法只针对单一环境下识别效果优秀,但在不同拍摄环境(如暗光、雾霾、模糊等环境)中的泛化能力欠佳,算法鲁棒性差。针对上述问题,目前比较普遍的解决方式是缺陷识别算法在训练时使用特定拍摄条件下获得的数据集或针对某一环境下的图像特征进行预处理,使其接近正常环境下的图像。例如,张芯睿等[10]在Mask R-CNN基础上前置暗通道去雾算法,对雾天图像进行去雾处理后再进行识别,实现了雾天场景下检测效果的提升。郭克友等[11]在检测算法前使用了轻量化高动态光照渲染(High Dynamic Range, HDR)暗光增强算法,对夜间图像增强后再进行识别,提升了目标检测算法在夜间车辆识别方面的表现。但由于不同拍摄环境下的线路缺陷数据集难以获得,且预处理方法仅对某种特定环境有效,所以上述两种方法的实施具有较大局限性。如果识别算法能够在单一环境数据集中学习到适用于不同拍摄环境下的普适性图像特征与缺陷特征,可以提升算法的鲁棒性。
此外,为验证缺陷识别算法的跨环境检测效果,需要一定数量的对应环境下的输电线路缺陷数据集。但受限于环境、工程实际等因素,实地收集较大数量的特定环境下的数据集较为困难。因此,探索建设拟真度较高的虚拟数据集成为一种潜在有效的方式。在虚拟数据集生成方面,部分学者做了探索性研究。翟永杰等[12]使用3DS MAX软件绘制了绝缘子破损虚拟数据集,建立以混合样本为基础的迁移学习方法,解决样本不足的问题。刘庆臻等[13]基于域随机化数据生成方法提出了缺陷样本自动生成方法,并建立了绝缘子缺陷数据集。但目前工作仅对缺陷类型进行模拟,并未考虑对拍摄环境进行模拟。
本文针对上述问题,为满足输电线路缺陷检测任务对算法泛化性的需求,提出了跨环境鲁棒YOLO(cross-Environment Robust YOLO, ER-YOLO)算法。本文首先在YOLOv8算法的基础上,基于广义注意力理论使用Transformer注意力机制,加强了算法长距离建模能力;其次,通过增大卷积核尺寸、引入高效注意力机制改进路径聚合网络(Path Aggregation Network, PANet)中的跨阶段局部层(Cross Stage Partial Layer, CSPLayer),提升了网络对目标的检测能力;最后,使用多重注意力机制检测头网络,强化算法多尺度、空间位置和多任务感知能力,使网络聚焦于目标关键信息。经测试,本文方法可有效提升缺陷识别算法在跨拍摄环境下的识别效果。同时,为解决测试数据集问题,本文提出了输电线路缺陷识别常见的不利环境数据生成方法,基于正常环境数据生成了高拟真度的测试数据集。探索了基于曝光融合算法与亮度降低方法的暗光环境模拟方法、基于生成对抗网络的雾霾环境生成方法以及基于均值滤波的成像模糊环境生成方法,评估了各方法的有效性,并与其他方法进行对比,为测试缺陷识别算法跨环境鲁棒性提供了条件。
YOLOv8算法是由YOLOv5改进而来,其建立在先前YOLO算法[14]的基础上,引入新功能和改进措施,以进一步提升性能和灵活性。YOLOv8算法不仅拥有轻量、快速的特点,还可以在多种硬件平台上部署,适用于输电线路缺陷巡检场景,但其未对鲁棒性做相应的提升,其跨环境缺陷检测能力较差,不同拍摄环境下的检测效果差异性大,不能适用于与训练数据集差异较大的输电线路巡检场景。因此,本文选择以此算法为基础,进行针对性的改进。
YOLOv8算法结构由主干网络(Backbone)、颈部网络(Neck)和检测头(Head)组成。主干网络基于Darknet-53改进而成。将其中的三次卷积模块转换为两次卷积的CSPLayer模块,相对于三次卷积模块添加了更多的跳层连接,可在保证轻量化的同时获得更加丰富的梯度流信息。
颈部网络由空间金字塔池化结构(Spatial Pyramid Pooling, SPP)组成,有效地避免了对图像区域进行裁剪、缩放操作而导致的图像失真,解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
检测头网络采用解耦头(Decoupled-Head)结构将分类和检测头分离。同时相对于YOLOv5算法,从基于锚框方法(Anchor-Based)改为无锚框(Anchor-Free)方法,在损失函数(Loss Function)方面抛弃了交并比(Intersection over Union, IoU)匹配或单边比例的分配方式,使用了Task Aligned- Assigner[15]正负样本匹配的方式。分类和回归分支的损失值计算分别采用二值交叉熵损失(Binary Cross Entropy Loss, BCE Loss)和分布聚焦损失(Distribution Focal Loss, DFL)加权完整交并比损失(Complete-IoU Loss, CIoU Loss)[16]的方式。
为提高目标检测网络的鲁棒性,提升其对不同拍摄环境的适应能力,本文以YOLOv8算法为基准,对其骨干网络与颈部网络进行针对性改进,形成了ER-YOLO算法,其整体结构如图1所示。
图1 ER-YOLO网络结构
Fig.1 Network architecture of ER-YOLO
骨干网络(Backbone)作为提取图像特征的主要网络,其提取的图像特征供后续网络使用,所以其提取特征能力的强弱对模型的整体检测效果影响较大。本文在YOLOv8原有骨干网络基础上以残差注意力模块的形式使用了基于广义注意力机制的Transformer模块,从而更好地捕捉长距离依赖关系,建模时考虑全局上下文信息,实现多尺度特征融合。
颈部网络(Neck)及检测头(Head)基于骨干网络输出的特征进行预测框生成及类别预测。在颈部网络部分,本文对PANet的CSPLayer模块进行改进,并引入多重注意力机制检测头(Dynamic Head, Dyhead)复合结构,有效地提高了算法对目标特征的提取能力以及目标与周围环境关系的学习能力。检测头仍采用YOLOv8无锚框(Anchor Free)结构。
Transformer是由A. Vaswani等[17]在2017年提出的神经网络架构,在自然语言处理领域取得了巨大成功。Transformer的设计主要基于自注意力(self-attention)机制,它能够捕捉输入序列中不同位置之间的依赖关系。在目标检测领域,Transformer得到了广泛的应用并取得了显著的成果,如N. Carion等[18]在2020年提出的Detection Transformer模型,就是将Transformer引入目标检测任务中。
在目标检测领域,使用Transformer结构具有以下优势。Transformer结构通过自注意力机制可以直接建模序列中任意两个位置之间的依赖关系,能够更好地捕捉目标之间的长距离关系,提高目标检测的准确性。同时可以对输入序列中的不同位置进行全局的上下文建模,有助于理解目标与其周围环境之间的关系,提高目标检测的准确性。其多头注意力机制允许模型同时关注不同层次和不同角度的特征表示,有助于有效地融合多尺度的特征信息,提高目标检测的性能。多头注意力机制的输出特征[19]表示为
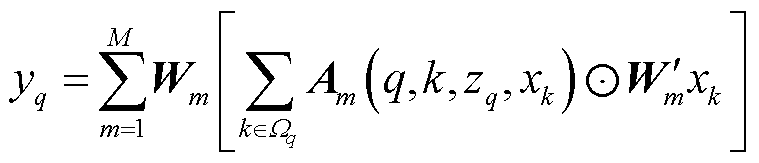 (1)
(1)
式中,q为查询(query)元素;zq为查询元素q的内容;k为键值(key)元素;xk为键值元素k的内容,在目标检测领域,q和k为图像中的一组像素;Wq为查询元素q对应的简直元素区域;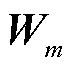 和
和 为第m头注意力机制的可学习权重;Am(q,k,zq,xk)为第m头注意力机制的权重;M为多头注意力机制中注意力头总数量;
为第m头注意力机制的可学习权重;Am(q,k,zq,xk)为第m头注意力机制的权重;M为多头注意力机制中注意力头总数量; 为逐元素相乘。根据Zhu Xizhou等[20]的研究,多头注意力机制作用原理可解耦为四个单独项:查询内容及键值内容、查询内容及查询内容到键值内容的相对位置、仅键值内容、仅查询内容到键值内容的相对位置。同时该文献实验结论显示,在Transformer注意力机制中只使用“查询内容及查询内容到键值内容的相对位置”项最为高效。因此,本文使用的Transformer注意力机制网络结构如图2所示。
为逐元素相乘。根据Zhu Xizhou等[20]的研究,多头注意力机制作用原理可解耦为四个单独项:查询内容及键值内容、查询内容及查询内容到键值内容的相对位置、仅键值内容、仅查询内容到键值内容的相对位置。同时该文献实验结论显示,在Transformer注意力机制中只使用“查询内容及查询内容到键值内容的相对位置”项最为高效。因此,本文使用的Transformer注意力机制网络结构如图2所示。
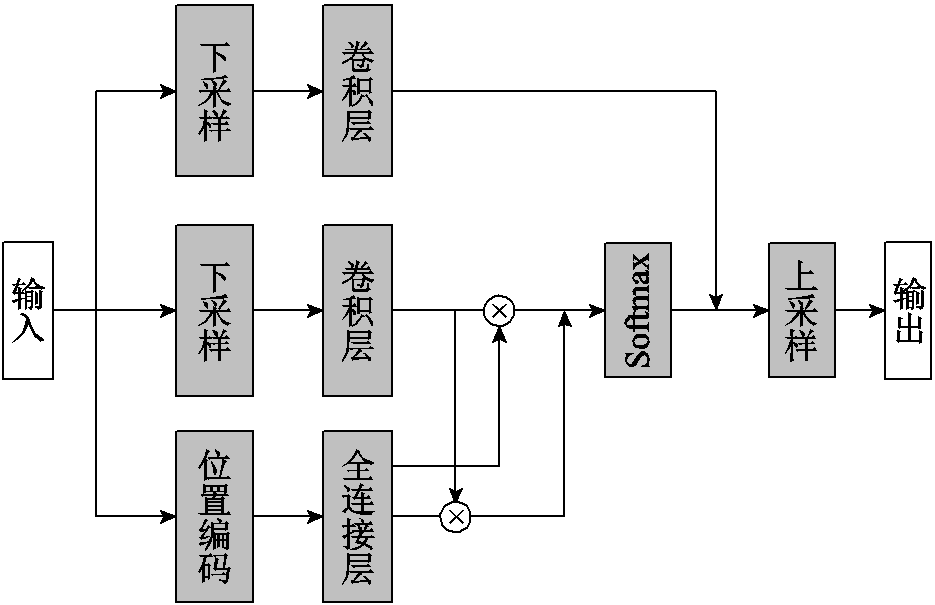
图2 Transformer注意力机制网络
Fig.2 Transformer attention network
在其与骨干网络结合方式上,根据文献[20]结论,将Transformer注意力机制串联到骨干网络与将其并联到骨干网络带来的效果几乎一致,所以本文选择将其作为注意力残差块(Attended Residual Block)并联到骨干网络中,如图1所示。
YOLOv8网络中的颈部网络使用了PANet,对骨干网络的表征能力进行了加强。在骨干网络输出的浅层特征图中,通常分辨率较高、定位信息准确,但语义信息不丰富;而在骨干网络输出的深层特征图中,通常分辨率较低、语义信息丰富,但定位信息不准确。PANet通过融合自底向上和自顶向下两条路径的方式用低层特征融合高层特征,增强高层特征的定位信息,进而增强了骨干网络输出特征图的标准能力。
YOLOv8中使用CSPLayer模块作为PANet的基本模块。ConvNeXt[21]、RepLKNet[22]、RTMDet[23]的相关研究表明,大卷积具有更大的感受野,可以使模型获取更多全局信息,在卷积层中使用更大的卷积核可提升网络对不同任务(目标识别、实例分割)的表现效果。因此,本文在YOLOv8的CSPLayer模块基础上进行改进,引入大卷积核的卷积层。同时考虑尽可能地减小模型体积,在大卷积核卷积层具体形式的选择上,使用逐通道分离卷积(Depthwise Convolution, DWConv)[24]。为提升算法对物体特征的提取能力,同时使用高效通道注意力机制对逐通道分离卷积的输出结果进行处理。改进前后的CSPLayer结构对比如图3所示。
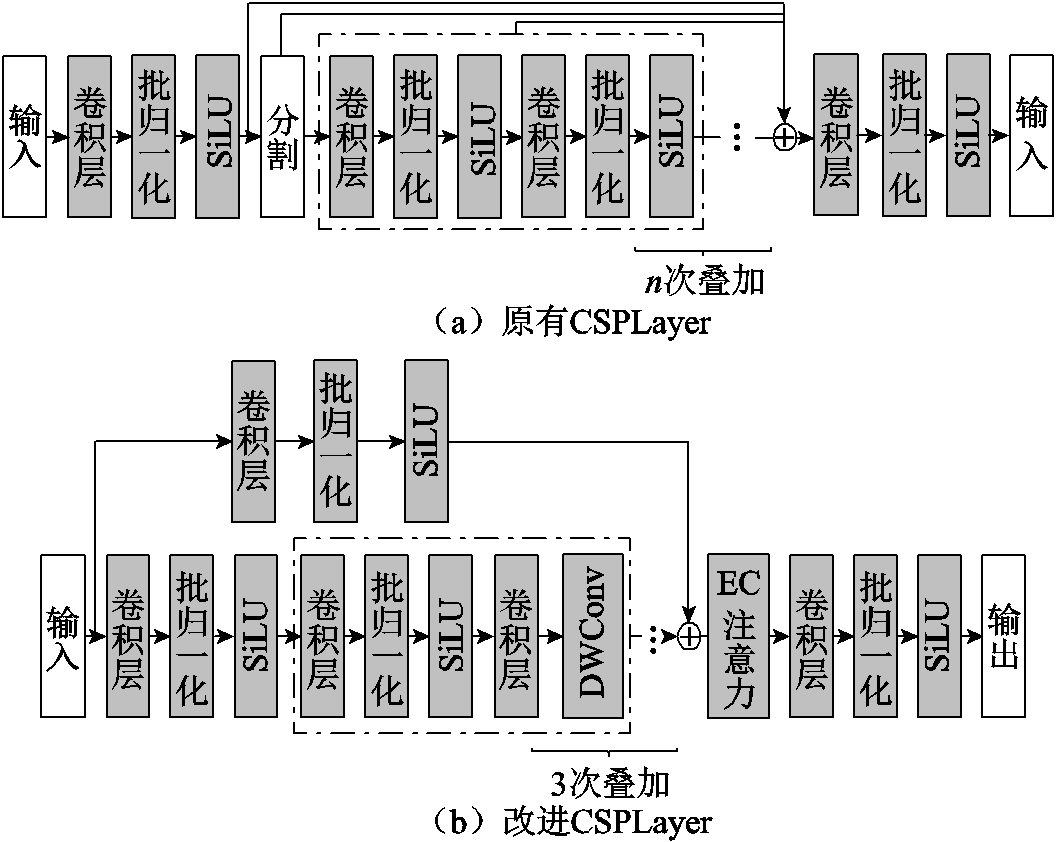
图3 改进前后CSPLayer结构对比
Fig.3 Comparison of the CSPLayer before and after improvement
逐通道分离卷积使用一个卷积核处理一个通道,即一个通道只被一个卷积核卷积。该过程产生的特征图通道数与输入的通道数完全一致,本文中取各卷积核大小为7´7。将CSPLayer中所使用的通道注意力机制方法改进为高效通道注意力机制(Efficient Channel Attention, ECA)[25],其结构如图4所示。高效通道注意力机制对输入的特征图进行不降低维数的通道级全局平均池化之后,使用卷积核大小为ks的一维卷积对每个通道及其ks个相邻通道进行卷积运算,以此捕获局部跨通道交互信息。ks与输入通道数相关,其值表示为
 (2)
(2)
式中,C为通道数;γ和b均为参数,取γ=2, b=1;odd表示取最相近的奇数。学习到的通道注意力ω可表示为

图4 高效通道注意力机制结构
Fig.4 Structure of efficient channel attention
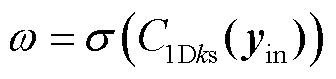 (3)
(3)
式中,σ为Sigmoid激活函数;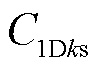 为卷积核大小为ks的一维卷积;
为卷积核大小为ks的一维卷积;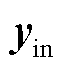 为ECA输入张量。
为ECA输入张量。
由于拍摄环境的变化,特别是处于不利环境时,会导致图片中线路缺陷目标的有效像素信息减少。深度学习算法在识别线路缺陷时,容易受复杂背景及环境因素的影响,致使算法对缺陷的有效特征的提取能力不足。
为了将算法资源尽可能地集中于对线路缺陷更为关键的信息提取中,可使用注意力机制在不增加计算量的情况下显著提升模型颈部网络的表达能力。多重注意力机制检测头方法(Dyhead)[26]通过从三个不同的角度(尺度感知、空间位置和多任务)分别运用注意力机制,提高了算法对尺度、空间位置和多任务的感知能力。这些注意力机制分别应用于特征张量的不同维度,不但可以实现性能的互补,而且能够高效地学习目标特征。
Dyhead的结构如图5所示,分别由尺度注意力模块、空间注意力模块和多任务注意力模块构成。尺度注意力模块处理过程表示为
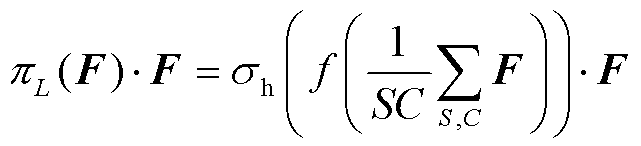 (4)
(4)
式中,F为尺度注意力模块输入;f为二维卷积操作,卷积核尺寸为1´1;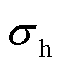 为hard sigmoid函数;S为F的宽度与高度的乘积。尺度注意力模块的作用是改进不同级的表达能力以有效提升目标检测器的尺度感知能力。
为hard sigmoid函数;S为F的宽度与高度的乘积。尺度注意力模块的作用是改进不同级的表达能力以有效提升目标检测器的尺度感知能力。
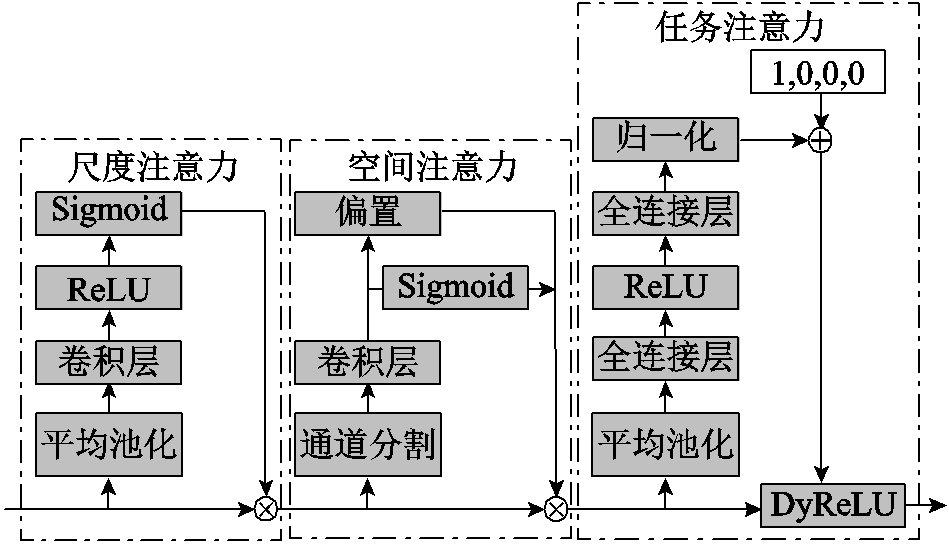
图5 Dyhead结构
Fig.5 Structure of Dyhead
空间注意力机制采用第二代可变形卷积网络,使用带偏置的可变形卷积层对输入的特征图进行卷积运算。此过程中更新各个可变形卷积层的偏置量,改变感受野的形状,以拟合不同目标的尺寸和形状。同时更新可变形卷积各个采样点的权重值,适当降低部分区域权重,以减小无关区域的干扰。空间注意力模块的计算过程为
 (5)
(5)
式中,I为卷积核采样点总数;L为输入特征图层级数;w为可变卷积层权重;pi第i个采样点预设中心;Dpi为该采样点相对中心位置偏置量;c为特征图各通道;Dmi为可变卷积层第i个采样点权重。
多任务注意力模块使用Dynamic ReLU(DyReLU)函数[27]对输入的特征图按通道激活,其计算公式为
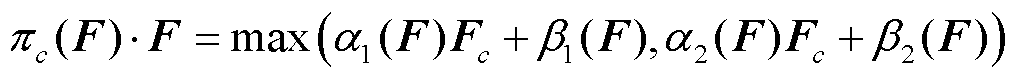 (6)
(6)
该模块根据输入特征图动态调整特征图各通道使用的DyReLU激活函数的四个参数α1、β1、α2、β2,各参数得出方法如图5所示,即对输入特征图进行平均池化后使用全连接层与ReLU激活函数处理,最后归一化到[0,1]区间。
本文将Dyhead模块置于改进PANet与三个检测头之间,嵌入方式如图6所示,并按此方式将Dyhead模块叠加放置两次。
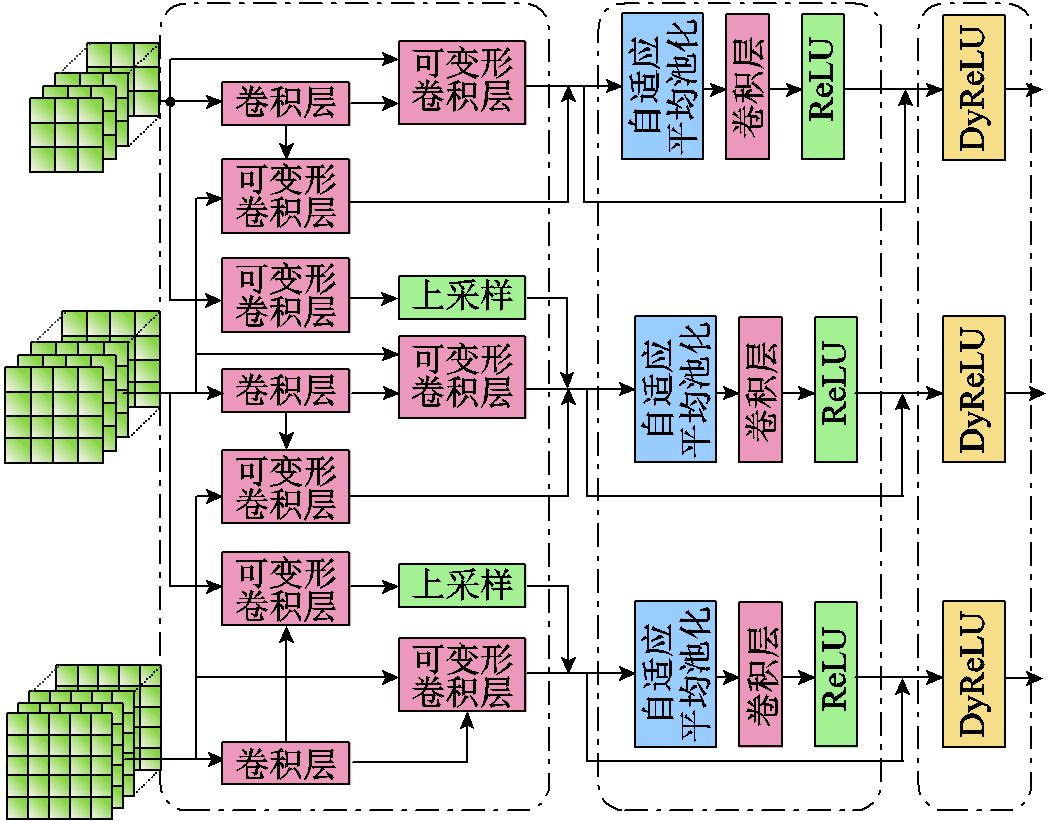
图6 Dyhead在颈部网络中应用
Fig.6 Dyhead is applied in neck networks
Dyhead模块接受算法网络上级输出的不同尺度特征图后,首先,不同尺度的空间注意力模块使用本尺度特征图作为输入进行空间注意力处理,将其作为本尺度空间注意力模块输出之一;同时使用本尺度特征图与高一级尺度特征图作为输入进行空间注意力处理,将其作为本尺度空间注意力模块输出之二;并对小尺度特征图进行上采样处理,将其作为高一级尺度空间注意力模块输出之一。其次,不同尺度的尺度注意力模块对本尺度的空间注意力模块的输入进行拼接后作尺度注意力处理。最后,多任务注意力模块对本尺度的尺度注意力模型输出进行多任务注意力处理。按上述过程处理两次后输入三个检测头。
输电线路缺陷包括自身部件缺陷,如绝缘子破损、防振锤锈蚀等,以及外破物缺陷,如异物入侵、鸟类入侵等。本文以输电线路外破物缺陷为研究对象,构建外破物缺陷数据集,并根据此数据集设计数据生成方法生成测试数据集。输电线路外破物缺陷数据集通过实地拍摄与爬取网络资源构成,共涵盖有效样本照片4 517张,涉及鸟巢、垃圾、风筝、气球四种异物缺陷。其中,鸟巢缺陷2 960处,垃圾缺陷553处,风筝缺陷545处,气球缺陷521处。使用Labelme软件对样本照片中的异物位置及种类进行标注,并根据8:1:1的比例随机划分为训练集、验证集、测试集。
为测试算法在不利条件下获得缺陷样本的识别能力,需要对原始的测试集使用图像处理方法生成不利条件下缺陷样本测试集。
在输电线路实时监控场景中会面临在光线不足(暗光)的情况下(如清晨、傍晚或阴天)监测输电线路状态的需要。如果缺陷识别算法在光线不足的情况下识别准确度低,则可能导致无法及时发现线路缺陷。为测试缺陷识别算法在暗光条件下的识别效果,需要生成一组暗光环境下的测试数据集。
原始图像如图7a所示,常用的降低图像光照强度的方法为直接降低图像的亮度,具体方法为:对图片各个通道矩阵进行线性变换以降低各个像素值。利用该方法处理后的效果如图7b所示,图片亮部与暗部的亮度均匀降低,不符合实际情况。由于光源角度以及物体遮挡的原因,实际暗光条件下图片中不同部位的亮度值降低程度应当存在差异。Ying Zhenqiang等[28]提出的曝光融合算法实现了准确对比度下的暗光图片亮度增强方法。本文基于此方法反向实现了亮光图像暗化方法。将多个多重曝光图像融合为一张图像,以获得更好的低光照条件下的图像,计算方法为
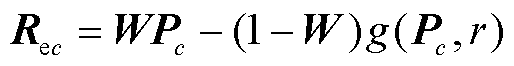 (7)
(7)
式中,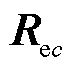 为通道c处理结束后的图像;c为图像RGB各通道;W为权重矩阵;g(·)为亮度转换函数;
为通道c处理结束后的图像;c为图像RGB各通道;W为权重矩阵;g(·)为亮度转换函数;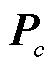 为通道c的原图像;r为曝光率。权重矩阵用于评估输入图像中每个像素的明亮程度。该矩阵的尺寸与输入图像相同,每个元素表示输入图像中对应像素的明亮程度的权重,曝光良好的像素对应权重矩阵中权重值大,曝光不足的像素分配的权重值小。权重矩阵计算方式为
为通道c的原图像;r为曝光率。权重矩阵用于评估输入图像中每个像素的明亮程度。该矩阵的尺寸与输入图像相同,每个元素表示输入图像中对应像素的明亮程度的权重,曝光良好的像素对应权重矩阵中权重值大,曝光不足的像素分配的权重值小。权重矩阵计算方式为
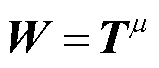 (8)
(8)
式中,T为场景亮度图;μ为增强强度控制参数,本实验中取μ=0.4。T通过求解方程式(9)得到。
 (9)
(9)
式中,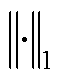 和
和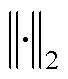 分别为L1和L2范数,对T求导数时分别在其水平和垂直方向上求导;Γ为亮度矩阵,由原图像中各像素的RGB色彩通道上的最大值组成;λ为置信度,本文中取λ=0.5;Θ为加权矩阵,表达式为
分别为L1和L2范数,对T求导数时分别在其水平和垂直方向上求导;Γ为亮度矩阵,由原图像中各像素的RGB色彩通道上的最大值组成;λ为置信度,本文中取λ=0.5;Θ为加权矩阵,表达式为
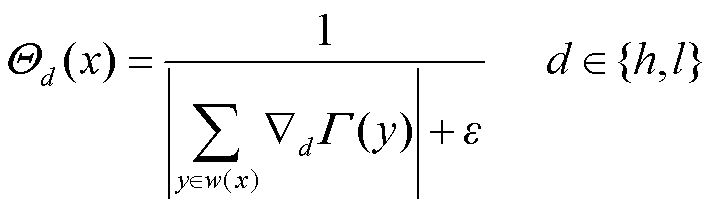 (10)
(10)
式中,h和l分别代表图像水平与垂直方向;w(x)为以像素x为中心的窗口;ε取0.001以避免分母为0。

图7 不同暗光处理算法的对比
Fig.7 Comparison of different dark light processing algorithms
对该输入图像P,r的取值需使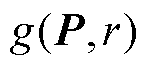 的交叉熵最大,且
的交叉熵最大,且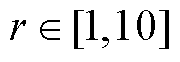 。
。
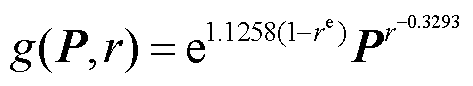 (11)
(11)
经过上述处理,得到图像如图7c所示。原图像中低亮度部分被充分暗化,模拟了暗光环境下部分区域亮度值更低的情况。但处理后仍有大部分区域亮度值未明显降低,而实际暗光条件下拍摄得到的图像整体亮度值均应降低。所以本文需对经上述步骤处理得到的图像再进行处理,降低其各通道数值,使其亮度整体下降,以达到在图像整体亮度较低的同时,不同部位亮度降低程度不同的效果,处理结果如图7d所示。
在雾霾天气下,无人机携带摄像头或固定机位摄像头拍摄的输电线路图片,可能会受到雾霾遮挡和低可见度的影响,使得目标受遮挡、成像不清晰、图像色彩变化,进而干扰目标识别算法对缺陷的识别效果。为测试目标识别算法在雾霾天气下的识别效果,需生成一组雾霾天气下的输电线路缺陷图片。
常用的图像雾化算法主要有三种。①处理图像的RGB色彩通道,使图像的灰度值发生变化。然而如图8b所示,这种方法的缺点是整个图像会均匀变灰,无法很好地模拟实际雾气的分布情况。②基于标准光学模型,以图像某一点为中心进行合成雾扩散,距离中心越远,合成雾浓度越低。如图8c所示,该方法可以模拟雾气的不均匀分布,但其分布方式单一,且无法模拟雾天能见度降低的情况。③基于深度信息合成雾。此方法结合了图像的深度信息和光学模型,在远距离和中心处模拟浓雾,而在近距离处模拟淡雾。这种方法可以同时模拟雾气的不均匀分布和可见度情况。然而,此方法需要获取图像的深度信息,需使用双目相机对目标进行拍摄,才可通过左右视图的视差获取图像深度信息。因此,此方法适用条件要求较高,在现场应用中无法总能得到满足。

图8 雾霾环境下图像
Fig.8 Image in fog and haze environment
生成式对抗网络(Generative Adversarial Networks, GAN)由I. Goodfellows等学者于2014年首次提出[29],由相互博弈的生成器和判别器组成,该模型在风格迁移领域对风格图片的纹理特征抓取能力十分强大。Zhu Junyan等在2017年提出Cycle GAN[30],可实现非配对的两个域图像无监督风格迁移,大大扩展了生成式对抗网络的适用条件。其模型由两组生成器、判别器构成,该算法的核心思想是利用两个生成器和两个判别器进行对抗训练。其中一个生成器用于将源领域内的样本数据转换成目标领域内的样本数据;另一个生成器则用于将目标领域内的样本数据转换回源领域内的数据。同时,两个判别器分别用于判断生成器的输出结果是否真实或逼真。
为学习到自然环境中雾霾天气条件下的图像特征,本文使用爬虫技术爬取雾霾天气条件下的自然风光图像与非雾霾天气条件下的自然风光图像,分别组成输入Cycle GAN的两个域图像。对Cycle GAN进行训练使其学习雾霾天气条件下的图像特征。该数据集包括雾天条件下的图像913张,非雾天条件下的图像962张。本文使用的Cycle GAN结构如图9所示。对Cycle GAN训练500轮次,得到雾霾天气图像生成器(图9中A→B生成器)权重,使用该权重对输电线路图片进行生成操作,所得到的模拟雾霾天气下的线路缺陷如图8d所示。
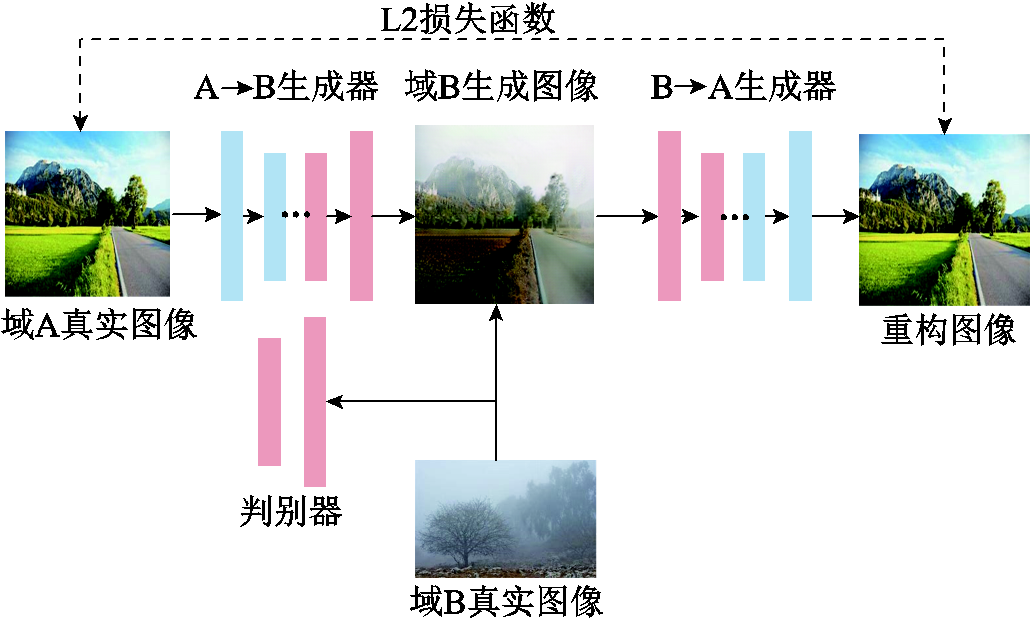
图9 Cycle GAN结构
Fig.9 Cycle GAN structure
对输电线路进行拍摄时,有时会因为对焦问题或相机抖动导致成像模糊,减少图像的细节信息,进而影响目标识别网络的缺陷识别效果。为测试识别算法在成像模糊图片中识别线路缺陷的能力,需生成一组模糊成像的输电线路缺陷图像。在本文中使用均值滤波(Mean Filtering)对输电线路缺陷图片进行处理,降低图像细节以生成成像模糊的测试集。均值滤波是一种计算机视觉算法中的图像处理方法,该方法本质上是一种对图像的卷积操作,其卷积函数为
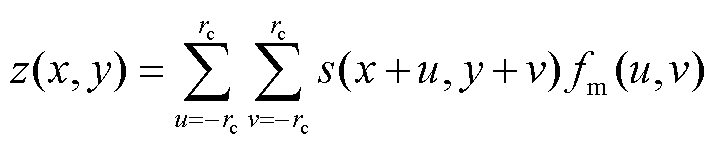 (12)
(12)
式中,(x, y)为二维图像像素点的坐标;z(x, y)为该像素被处理后的像素值;rc为卷积核半径;s(x, y)为该像素点原来的像素值;fm(u, v)为卷积核在(u, v)上的权重值,fm函数通常也称作滤波函数,均值滤波的滤波函数表示为
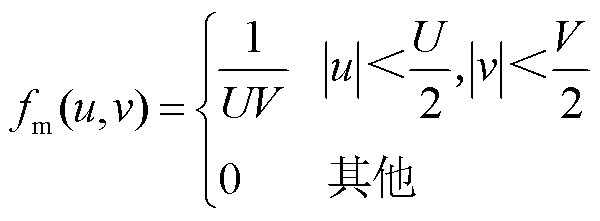 (13)
(13)
本文中设置邻域范围U=10, V=10。使用均值滤波对原始测试集中输电线路缺陷图片进行处理,得到成像模糊效果如图10所示。

图10 成像模糊图像
Fig.10 Imaging blurry images
对正常环境下测试数据集进行处理可得到暗光环境、雾霾环境以及成像模糊情况下的测试数据集。为有效验证本文提出算法对不同环境下图像识别效果的鲁棒性,测试集需要与正常环境下的数据集具有不同的图像特征分布。本节基于图像的颜色特征与纹理特征,对测试集图像特征分布进行分析验证。
颜色直方图表示每个色彩范围包含的图像像素个数,通常用来衡量图像的颜色特征。在计算时首先将各个数据集内图像灰度化,按式(14)将图像色彩量化到[0, 256]区间内得到色彩强度S,再累计数据集中各色彩强度像素数量得到该数据集颜色直方图。
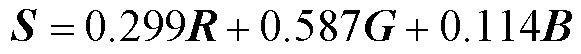 (14)
(14)
式中,R、G、B分别为各色彩通道的强度。
不同测试数据集颜色直方图拟合折线图如图11所示。可见不同数据集颜色分布不同,暗光环境下图像色彩偏暗;在雾霾环境测试集中,因有雾霾存在,图像颜色分布相对正常环境下更为均匀;而成像模糊情况下与正常环境颜色分布相接近。
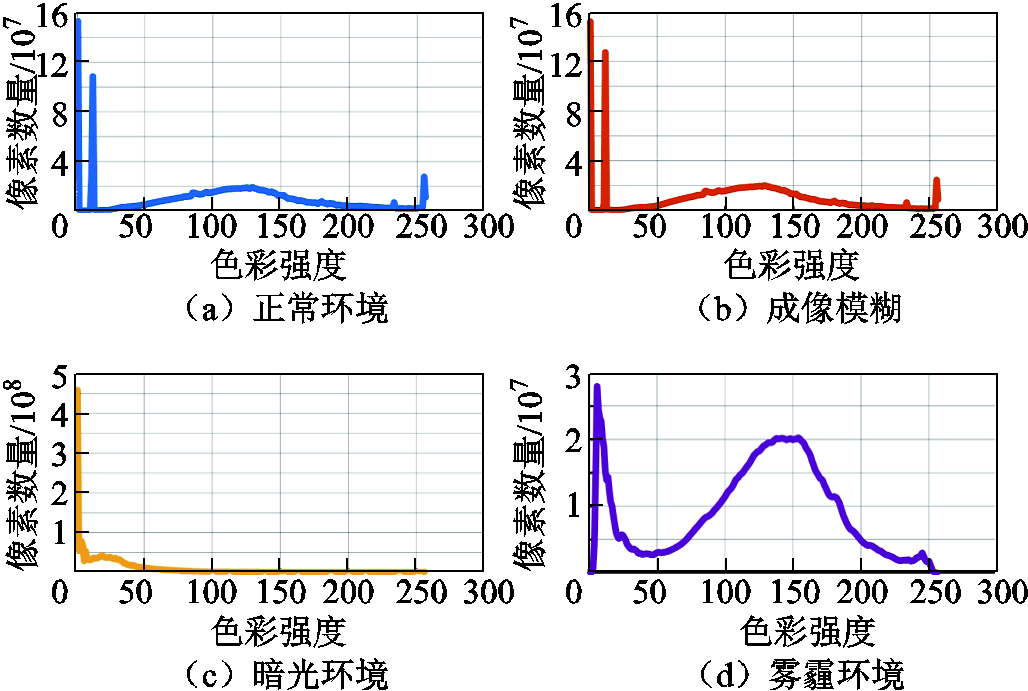
图11 不同测试数据集颜色直方图拟合折线图
Fig.11 Color histogram fitting line chart for different test datasets
灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM)是用于描述图像纹理特征的一种统计方法。它通过分析图像中像素灰度级别之间的空间关系来揭示图像纹理的特征,可在不依赖图像颜色和亮度的条件下表征图像在间隔、方向、变化幅度等方面的综合信息[31]。计算灰度共生矩阵时首先需将图像灰度化;而后遍历图像中的每个像素,检查当前像素和其相邻像素之间的灰度级别对是否与所选的灰度级别对匹配,此过程中本文选择对比方向为90°;如果匹配成功,将对应位置的共生矩阵元素加一;重复上述步骤直到完全遍历整个图像;最后将共生矩阵进行归一化。各图像纹理特点可通过对应灰度共生矩阵的统计量得出,常用的统计量有对比度(Contrast)、能量(Energy)、相关性(Correlation)和熵(Entropy)。其中,对比度描述了图像中灰度级别对之间的对比度或差异程度;相关性描述了图像中灰度级别对之间的线性相关性;能量描述了图像中灰度级别对的分布均匀程度;熵描述了图像中灰度级别对的不确定性或复杂度。四者均为对各图像纹理特征的统计描述,本文从中选择相关性、能量和熵作为描述图像纹理的指标,对各个数据集中的图像按式(15)进行计算,并绘制散点图如图12所示。
 (15)
(15)
式中,Cij为灰度共生矩阵中第i行、第j列的元素;μx、μy、σx、σy分别为灰度共生矩阵在水平和垂直方向的均值和标准差。

图12 不同测试集灰度共生矩阵统计特征分布
Fig.12 Statistical feature distribution of grayscale co-occurrence matrices of different test sets
由图12中可看出,各数据集特征分布不同。其中,正常环境数据集中因为图像来源不同,各图像特征分布较为分散;雾霾环境数据集因雾霾存在导致各图像纹理较为接近,散点分布集中。
基于对各数据集各图像颜色特征与纹理特征的分析,各测试数据集图像特征分布不同,且各自特征符合实际情况下该环境特点。
本文实验平台的操作系统为Ubuntu 22.04,硬件配置为Intel Xeon Processor X5650处理器,GeForce RTX 1080Ti显卡。驱动环境为CUDA 11.3,算法基于MMDetection[32]与MMYOLO[33]算法库实现。训练时的超参数设置为:批大小为8,最大训练轮数为300;优化器采用带动量的SGD优化器,动量值为0.937,学习率设置为0.01。
本文任务为提高缺陷识别算法的鲁棒性,需要在不利条件下客观地评价各算法的缺陷识别效果。优秀的评价指标能够准确地反映识别算法能否灵敏、准确地检测目标位置,并区分目标种类。本文选用平均精度均值(mean Average Precision, mAP)作为评价指标,mAP越高,表明算法在查准与查全两个方面均表现越好。首先,每个类别分别计算其高于交并比阈值的预测框的查准率(Precision, P)和查全率(Recall, R),二者表达式分别为
 (16)
(16)
并由查准率和查全率计算结果构成P-R曲线。其次,对于每一个类别,计算其平均精度(Average Precision, AP),即P-R曲线下方的面积。最后,对所有类别的AP值取平均,得到最终的mAP值。
为验证本文方法中各个部分的作用,本文以YOLOv8算法为基准算法(Baseline),在基准算法上逐步累积使用添加Transformer注意力机制、添加Dyhead和改进CSPLayer方法,分别进行训练和测试。使用数据集中的训练集分别对各个算法按照4.1节中的实验设置进行训练,并选取最优训练轮次产生的权重文件作为该算法的训练结果。使用原始测试集与第3节形成的各种不利环境测试集对各个算法进行测试,当交并比阈值取为0.75时,测试结果见表1~表4,表中Ö代表使用该改进方法。
表1 正常环境测试集下消融实验结果
Tab.1 Ablation experiments results of normal environment test dataset

序号基准算法Transformer注意力机制Dyhead改进CSPLayerAPmAP 鸟巢垃圾气球风筝 1Ö0.7670.8690.7840.7730.798 25 2ÖÖ0.7900.8640.7920.7510.799 25 3ÖÖ0.8100.8670.7870.7530.804 25 4ÖÖÖ0.8280.8740.8010.7710.818 50 5ÖÖÖÖ0.8230.9010.8650.7880.844 25
表2 暗光测试集下消融实验结果
Tab.2 Ablation experiment results of the dark light test dataset

序号基准算法Transformer注意力机制Dyhead改进CSPLayerAPmAP 鸟巢垃圾气球风筝 1Ö0.5600.8040.6830.7640.702 75 2ÖÖ0.6160.8340.7010.7030.713 50
(续)

序号基准算法Transformer注意力机制Dyhead改进CSPLayerAPmAP 鸟巢垃圾气球风筝 3ÖÖ0.5960.8420.6300.7400.702 00 4ÖÖÖ0.6130.8380.6800.7300.715 25 5ÖÖÖÖ0.6150.8270.7230.7570.730 50
表3 雾霾测试集下消融实验结果
Tab.3 Ablation experiment results of fog and haze test dataset

序号基准算法Transformer注意力机制Dyhead改进CSPLayerAPmAP 鸟巢垃圾气球风筝 1Ö0.3670.5260.3520.4280.418 25 2ÖÖ0.3870.5560.3820.4380.440 75 3ÖÖ0.3750.5310.3790.4420.431 75 4ÖÖÖ0.4280.5290.4170.4430.454 25 5ÖÖÖÖ0.4600.5430.4960.5440.510 75
表4 成像模糊测试集下消融实验结果
Tab.4 Ablation experiment results of imaging fuzz test dataset

序号基准算法Transformer注意力机制Dyhead改进CSPLayerAPmAP 鸟巢垃圾气球风筝 1Ö0.6930.7300.7200.7000.710 75 2ÖÖ0.7910.8410.8930.7120.809 25 3ÖÖ0.7820.8130.8420.7200.789 25 4ÖÖÖ0.8020.8550.8420.7670.816 50 5ÖÖÖÖ0.8110.8780.8500.7460.821 25
如表1所示,在正常环境下,通过各改进方法的累加,mAP值逐步提高,检测效果逐步改善,mAP相对改进前提高0.046。在暗光环境下,如表2所示,各算法识别精度相比正常环境均降低,使用本文提出的改进方法后,mAP相对YOLOv8算法提高了0.027 75。实验结果证明了本文提出的方法提高了算法对暗光环境的适应能力。在雾霾环境下的图像特征与正常环境下的图像特征区别较大,识别算法mAP下降极大,如表3所示,基准算法的mAP仅有0.418 25,而使用本文所提出的改进方法后,mAP提高了0.092 5。使用改进CSPLayer对算法识别效果提升贡献最大,取消该方法后,mAP值降低0.056 5。通过使用大卷积核与高效通道注意力机制能够更好地获取全局信息,进而提高了算法对雾霾环境的适应能力。如表4所示,在成像模糊环境下,基准算法YOLOv8精度相对正常环境下出现了0.087 5的下降,而ER-YOLO算法精度下降值较低。各改进方法中添加Transformer 注意力模块对算法总体识别效果的提升最为显著,相对使用前mAP提升了0.098 5,因此,通过在骨干网络中添加Transformer残差注意力机制能够提升算法对成像模糊环境的适应性。各测试环境中,经过本文方法改进后的mAP值相对基准算法mAP值平均提升了约0.069。
为进一步验证本文所提出改进方法提升深度学习网络对缺陷特征的学习能力,本文采用特征图可视化方法对网络注意力集中位置进行可视化分析。热力图中权重越高的区域表示原始图片中该区域对网络的响应越高、贡献越大。
各网络颈部输出的热力图如图13所示。图13a为YOLOv8网络颈部网络输出热力图,图中网络所关注区域较分散,线路缺陷(鸟巢)区域虽相对其周围区域权重较高但相对全图并未有足够的权重。图13b为使用Transformer注意力机制后网络颈部输出的热力图,可见注意力向杆塔整体集中,线路缺陷获得更多注意力。图13c为使用Transformer注意力机制与多重注意力机制检测头方法后颈部网络输出热力图,图中线路缺陷区域对网络共享最大,且可以观察到注意力沿鸟巢形状分布,说明多重注意力机制检测头同空间注意力的可变形卷积方法作用明显。图13d为本文ER-YOLO算法颈部网络输出热力图,图中高权重范围相比图13c更集中于缺陷本体。

图13 不同网络颈部输出热力图
Fig.13 Heat maps of different network necks
为验证本文算法在真实环境中的实用性,收集了真实环境中暗光、雾霾、成像模糊情况下的线路缺陷,利用本文算法进行检测与定位,其部分结果如图14所示。由图14可见,本文提出的ER-YOLO算法在真实环境中的跨环境检测效果优秀,且在背景复杂、目标尺寸较小情况下仍能较好地检测出线路缺陷,证明了本文算法跨环境检测的实际效果。

图14 真实环境下算法检测效果
Fig.14 Detection result in real environment
为进一步验证本文方法的性能,将本算法与其他缺陷识别算法进行对比实验。在同样的训练设置下,将本文提出的ER-YOLO算法及其他目标检测算法——全卷积单阶段(Fully Convolutional One-Stage, FCOS)目标检测算法[34]、快速区域卷积神经网络(Faster Region-Convolutional Neural Network, Faster R-CNN)[14]、融合IoU预测和概率锚点分配(Probabilistic Anchor Assignment, PAA)的目标检测算法[35]进行训练。分别使用原始测试集和第3节形成的不利环境测试集对训练后的各个算法进行测试,并进行定性与定量分析。不同算法在暗光(左)、雾霾(中)、成像模糊环境(右)下的部分检测结果如图15所示,FCOS算法在成像模糊环境以及PAA算法在雾霾环境中出现了误检情况;Faster R-CNN算法在雾霾环境下出现错误分类情况;FCOS算法在暗光环境与雾霾环境出现漏检现象;而本文算法对相同目标均检测、分类准确,且在各算法均准确识别出缺陷时,本文算法置信度最高。综上所述,本文算法在跨环境识别中鲁棒性较强,可适应检测环境的变化。为进一步确定算法的性能,使用各算法模型权重分别计算其在各测试集中交并比阈值为0.75时的mAP值,实验结果见表5。


图15 不同算法检测效果
Fig.15 Detection results of different algorithms
表5 不同算法对比实验结果
Tab.5 Comparison of the experimental results using different algorithms
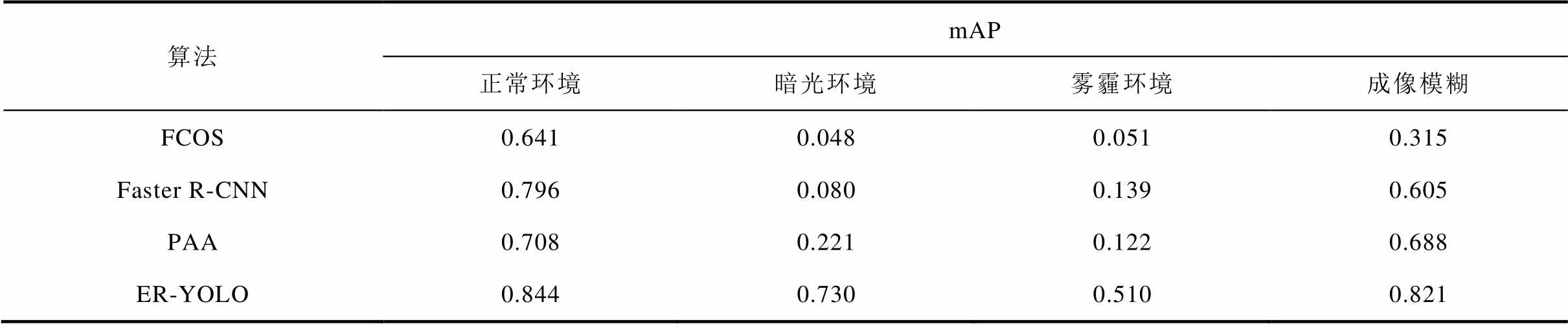
算法mAP 正常环境暗光环境雾霾环境成像模糊 FCOS0.6410.0480.0510.315 Faster R-CNN0.7960.0800.1390.605 PAA0.7080.2210.1220.688 ER-YOLO0.8440.7300.5100.821
在正常环境测试集中,本文提出算法的mAP最高,其他算法也表现良好,mAP值均大于0.64。但在跨环境测试集中,其他算法mAP值出现近乎断崖式下降,例如在暗光与雾霾环境数据集中,mAP值均不足0.3。而本算法在跨环境测试集中的识别效果有明显的优势,特别是在暗光环境与雾霾环境下优势最为显著,其mAP最低值也不低于0.510,远高于其他算法mAP值。对比实验结果表明,本文方法在各测试环境中mAP值平均为0.726,本文方法的跨环境识别鲁棒性强于所对比的其他目标检测方法。
本文为提高输电线路缺陷智能检测算法在不同环境条件下的鲁棒性,克服现有智能检测算法在不同环境下识别性能下降的问题,满足输电线路缺陷检测任务对算法泛化性的需求,提出了ER-YOLO算法,并探索了跨环境虚拟数据集生成方法。本文主要贡献及结论如下:
1)本文基于广义注意力理论将Transformer注意力机制作为注意力残差块并联到骨干网络中,提升了算法长距离建模能力与不同层次的特征融合能力。使用大卷积核逐通道可分离卷积与高效通道注意力模块(ER-YOLO中CSPLayer层),有效地获取了物体特征,减少无关环境的影响。使用Dyhead结构提高了算法对尺度、空间位置和多任务的感知能力,将有限计算资源集中到缺陷本体特征。改进后算法在各环境下的mAP值相对改进前平均提升了0.069,证明了改进方法的有效性。
2)经过消融实验与对比实验验证,本文提出的ER-YOLO算法实现了在使用正常环境数据集进行训练的情况下,在其他不利环境中的识别精度依然维持良好水平的预期效果,各环境中本算法mAP平均值为0.726,证明了本算法的跨环境识别鲁棒性。
3)本文通过曝光融合复合亮度调节方法、对抗生成网络、均值滤波方法,基于正常环境下测试集分别生成了暗光环境、雾霾环境与成像模糊情况下的虚拟测试数据集。通过观察对比以及图像特征实验验证,本文使用的图像生成方法能较好地模拟现实中上述环境中的成像情况,且各环境图像特征分布差异合理,解决了因图像采集困难导致的可用于验证算法鲁棒性的数据集稀少的问题。未来可面向其他种类缺陷开展跨环境缺陷识别研究,同时探索其他有效的多环境虚拟数据集生成方法。
参考文献
[1] Nguyen V N, Jenssen R, Roverso D. Automatic autonomous vision-based power line inspection: a review of current status and the potential role of deep learning[J]. International Journal of Electrical Power & Energy Systems, 2018, 99: 107-120.
[2] 胡晨龙, 裴少通, 刘云鹏, 等. 基于LEE-YOLOv7的输电线路边缘端实时缺陷检测方法[J/OL]. 高电压技术, 2023: 1-14[2023-12-09]. https://doi.org/10. 13336/j.1003-6520.hve.20230945. Hu Chenlong, Pei Shaotong, Liu Yunpeng, et al. Real-time defect detection method for transmission line edge end based on LEE-YOLOv7[J/OL]. High Voltage Engineering, 2023: 1-14[2023-12-09]. https:// doi.org/10.13336/j.1003-6520.hve.20230945.
[3] 周宇, 徐波, 宋爱国, 等. 基于改进文本检测识别的绝缘子串异常定位和判别方法[J]. 高电压技术, 2021, 47(11): 3819-3826. Zhou Yu, Xu Bo, Song Aiguo, et al. Anomaly location and discrimination method of insulator string based on improved text detection and recognition[J]. High Voltage Engineering, 2021, 47(11): 3819-3826.
[4] 李斌, 屈璐瑶, 朱新山, 等. 基于多尺度特征融合的绝缘子缺陷检测[J]. 电工技术学报, 2023, 38(1): 60-70. Li Bin, Qu Luyao, Zhu Xinshan, et al. Insulator defect detection based on multi-scale feature fusion[J]. Transactions of China Electrotechnical Society, 2023, 38(1): 60-70.
[5] 苟军年, 杜愫愫, 刘力. 基于改进掩膜区域卷积神经网络的输电线路绝缘子自爆检测[J]. 电工技术学报, 2023, 38(1): 47-59. Gou Junnian, Du Susu, Liu Li. Transmission line insulator self-explosion detection based on improved mask region-convolutional neural network[J]. Tran-sactions of China Electrotechnical Society, 2023, 38(1): 47-59.
[6] 宋立业, 刘帅, 王凯, 等. 基于改进EfficientDet的电网元件及缺陷识别方法[J]. 电工技术学报, 2022, 37(9): 2241-2251. Song Liye, Liu Shuai, Wang Kai, et al. Identification method of power grid components and defects based on improved EfficientDet[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2241-2251.
[7] 仲林林, 胡霞, 刘柯妤. 基于改进生成对抗网络的无人机电力杆塔巡检图像异常检测[J]. 电工技术学报, 2022, 37(9): 2230-2240, 2262. Zhong Linlin, Hu Xia, Liu Keyu. Power tower anomaly detection from unmanned aerial vehicles inspection images based on improved generative adversarial network[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2230-2240, 2262.
[8] 游越, 伊力哈木·亚尔买买提. 基于改进YOLOv5在电力巡检中的目标检测算法研究[J]. 高压电器, 2023, 59(2): 89-96. You Yue, Yilihamu Yaermaimaiti. Research on target detection algorithm based on improved YOLOv5 in power partrol inspection[J]. High Voltage Apparatus, 2023, 59(2): 89-96.
[9] 郑含博, 胡思佳, 梁炎燊, 等. 基于YOLO-2MCS的输电线路走廊隐患目标检测方法[J/OL]. 电工技术学报, 2023: 1-12[2023-12-09]. https://doi.org/10. 19595/j.cnki.1000-6753.tces.230666. Zheng Hanbo, Hu Sijiao, Liang Yanshen, et al. A hidden danger object detection method for trans-mission linecorridor based on YOLO-2MCS[J/OL]. Transactions of China Electrotechnical Society, 2023: 1-12[2023-12-09]. https://doi.org/10.19595/j.cnki.1000- 6753.tces.230666.
[10] 张芯睿, 赵清华, 王雷, 等. 基于Mask R-CNN的雾天场景目标检测[J]. 电光与控制, 2022, 29(12): 83-88. Zhang Xinrui, Zhao Qinghua, Wang Lei, et al. Target detection in foggy scene based on Mask R-CNN[J]. Electronics Optics & Control, 2022, 29(12): 83-88.
[11] 郭克友, 王苏东, 李雪, 等. 基于Dim env-YOLO算法的昏暗场景车辆多目标检测[J]. 计算机工程, 2023, 49(3): 312-320. Guo Keyou, Wang Sudong, Li Xue, et al. Multi-target detection of vehicles in dim scenes based on Dim env-YOLO algorithm[J]. Computer Engineering, 2023, 49(3): 312-320.
[12] 翟永杰, 杨珂, 王乾铭, 等. 基于混合样本迁移学习的盘型绝缘子缺陷检测[J]. 中国电机工程学报, 2023, 43(7): 2867-2876. Zhai Yongjie, Yang Ke, Wang Qianming, et al. Disc insulator defect detection based on mixed sample transfer learning[J]. Proceedings of the CSEE, 2023, 43(7): 2867-2876.
[13] 刘庆臻, 刘亚东, 严英杰, 等. 基于域随机化的绝缘子缺损数据自动生成与评价方法[J/OL]. 高电压技术, 2023: 1-13[2023-12-09]. DOI:10.13336/j.1003-6520.hve.20231241. Liu QingZhen, Liu Yadong, Yan jieing, et al. Automatic generation and evaluation method of insulator broken defect data based on domain randomization[J/OL]. High Voltage Engineering, 2023: 1-13[2023-12-09]. DOI:10.13336/j.1003-6520. hve.20231241.
[14] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 779-788.
[15] Feng Chengjian, Zhong Yujie, Gao Yu, et al. TOOD: task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 2021: 3490-3499.
[16] Zheng Zhaohui, Wang Ping, Ren Dongwei, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics, 2022, 52(8): 8574-8586.
[17] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 2017: 6000-6010.
[18] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision – ECCV 2020, Glasgow, UK, 2020: 213-229.
[19] Dai Zihang, Yang Zhilin, Yang Yiming, et al. Transformer-XL: attentive language models beyond a fixed-length context[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 2978-2988.
[20] Zhu Xizhou, Cheng Dazhi, Zhang Zheng, et al. An empirical study of spatial attention mechanisms in deep networks[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 6687-6696.
[21] Liu Zhuang, Mao Hanzi, Wu Chaoyuan, et al. A ConvNet for the 2020s[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022: 11966-11976.
[22] Ding Xiaohan, Zhang Xiangyu, Han Jungong, et al. Scaling up your kernels to 31x31: revisiting large kernel design in CNNs[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022: 11953-11965.
[23] Lü Chengqi, Zhang Wenwei, Huang Haian, et al. RTMDet: an empirical study of designing real-time object detectors[J/OL]. ArXiv, 2022: 1-15[2023-12-09]. https://doi.org/10.48550/arXiv.2212.07784.
[24] Chollet F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 1800-1807.
[25] Wang Qilong, Wu Banggu, Zhu Pengfei, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020: 11531-11539.
[26] Dai Xiyang, Chen Yinpeng, Xiao Bin, et al. Dynamic head: unifying object detection heads with attentions[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 7369-7378.
[27] Chen Yinpeng, Dai Xiyang, Liu Mengchen, et al. Dynamic ReLU[C]//European Conference on Computer Vision – ECCV 2020, Glasgow, UK, 2020: 351-367.
[28] Ying Zhenqiang, Li Ge, Gao Wen. A bio-inspired multi-exposure fusion framework for low-light image enhancement[J/OL]. ArXiv, 2017: 1-10[2023-12-09]. https://doi.org/10.48550/arXiv.1711.00591.
[29] Goodfellow I, Pouget-Abadie, Mirza M, et al. Generative adversarial networks[J/OL]. ArXiv, 2014: 1406.2661vl. https://doi.org/10.48550/arXiv.1406.2661.
[30] Zhu Junyan, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2242-2251.
[31] 赵书涛, 王紫薇, 陈志华, 等. 有载分接开关GLCM纹理特征及改进随机森林算法的故障诊断方法[J]. 高电压技术, 2022, 48(9): 3593-3601. Zhao Shutao, Wang Ziwei, Chen Zhihua, et al. GLCM texture features of on-load tap changer and fault diagnosis method based on im-proved random forest algorithm[J]. High Voltage Engineering, 2022, 48(9): 3593-3601.
[32] Chen Kai, Wang Jiaqi, Pang Jiangmiao, et al. MMDetection: open MMLab detection toolbox and benchmark[J/OL]. ArXiv, 2019: 1-13[2023-12-09]. https://doi.org/10.48550/arXiv.1906.07155.
[33] MMYOLO: OpenMMLab YOLO series toolbox and benchmark[EB/OL].(2023-08-15)[2023-12-09]. https:// github.com/open-mmlab/mmyolo.
[34] Tian Zhi, Shen Chunhua, Chen Hao, et al. FCOS: fully convolutional one-stage object detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 9626-9635.
[35] Kim K, Lee H S. Probabilistic anchor assignment with IoU prediction for object detection[C]//European Conference on Computer Vision–ECCV 2020, Glasgow, UK, 2020: 355-371.
Abstract The defect detection algorithm for power transmission lines based on deep learning heavily relies on the dataset used. The learned features of line defects and image features are highly correlated with the feature distribution of the dataset used. Currently, most datasets used to train defect detection algorithms are captured in a single environment, leading to the specific defect recognition algorithm performing well only in a particular environment. However, its generalization ability is inadequate in different shooting environments, such as low light, haze, and blur, resulting in poor algorithm robustness. To improve the robustness of the intelligent defect detection algorithm for power transmission lines in different environmental conditions and overcome the issue of decreased recognition performance in different environments, this paper proposes the cross-environment robust YOLO algorithm (ER-YOLO).
Firstly, based on the you only look once v8 (YOLOv8) algorithm, ER-YOLO enhances the algorithm's long-distance modeling capability by employing the Transformer attention mechanism based on the generalized attention theory. Secondly, ER-YOLO improves the path aggregation network (PANet) in the YOLOv8 algorithm by increasing the convolutional kernel size and introducing an efficient attention mechanism in the cross stage partial layer (CSPLayer), enhancing the network's object detection capability. Finally, ER-YOLO uses a multiple attention mechanism detection head network to strengthen the algorithm's multi-scale, spatial location, and multi-task perception capabilities, enabling the network to focus on crucial target information.
Additionally, to validate the cross-environment detection performance of the defect recognition algorithm, a certain number of corresponding datasets of power transmission line defects in different environments are required. However, due to environmental and practical engineering constraints, collecting a large number of datasets in specific environments is challenging. To address the issue of the test dataset, this paper proposes common methods for generating adverse environment data for power transmission line defect recognition. High-fidelity test datasets were generated based on normal environment data. The paper explores methods for simulating adverse environments, including dark light environment simulation using exposure fusion algorithms and brightness reduction methods, haze environment simulation using Cycle GAN networks, and imaging blur environment simulation using mean filtering methods. The effectiveness of each method was evaluated and compared with other methods, providing conditions for testing the robustness of defect recognition algorithms across different environments.
Through ablation experiments and comparative analysis, ER-YOLO demonstrated higher defect recognition accuracy and robustness in cross-environment testing. The average mAP value under various test datasets was 0.726, showing an improvement of 0.069 compared to the previous version. The algorithm's effectiveness was further validated in real environments. This study proposes a defect recognition method for power transmission lines across shooting environments, exhibiting excellent performance in cross-environment recognition. It also explores methods for generating cross-environment images, providing insights for future virtual dataset generation techniques. Future research directions may focus on cross-environment defect recognition studies for other types of defects and explore other effective methods for generating multi-environment virtual datasets.
keywords:Power transmission lines, defect detection, deep learning, dataset generation
DOI: 10.19595/j.cnki.1000-6753.tces.232073
中图分类号:TM755;TP39
中央高校基本科研业务费资助项目(2020MS093)。
收稿日期 2023-12-13
改稿日期 2024-01-09
裴少通 男,1990年生,讲师,硕士生导师,研究方向为电气设备的智能故障检测与诊断技术。E-mail:peishaotong@ncepu.com(通信作者)
张行远 男,1999年生,硕士研究生,研究方向为电气设备的智能故障检测与诊断技术。E-mail:zhanghay163@163.com
(编辑 李 冰)