
图1 堆栈式自编码器结构
Fig.1 Structure of SAE
摘要 针对变压器故障数据的稀缺性及数据分布中存在的长尾现象,导致故障诊断准确率低的问题,该文提出一种基于变权属性矩阵的变压器零样本故障诊断技术。首先,采用改进的高效通道注意力网络-堆栈式自编码器(IECANet-SAE)网络构建特征提取模块,自适应地提取油中气体数据的关键特征信息;其次,利用基于潜在狄利克雷分布的主题建模方法构建变权属性矩阵;最后,提出基于神经网络的朴素贝叶斯(NNB)方法学习已知故障特征信息与属性矩阵的空间映射关系,建立零样本故障诊断模型并依靠模型实现未知故障类型诊断。应用IEC TC 10故障数据库及典型故障数据对所提方法加以验证。试验结果表明,所提出的方法具有更好的诊断效果,且在零样本条件下故障诊断平均准确率高达83%,平均诊断时间达0.18 s。
关键词:零样本学习 特征提取 故障诊断 变权属性矩阵
变压器作为输变电网络的枢纽设备,可实现不同电压等级之间的电力传输,其安全稳定运行是保障电力系统正常运行的必要基础。在各种工况条件的长期作用下,变压器内部会发生绝缘老化、裂解等现象,严重时会导致变压器故障,危及整个电力系统的安全稳定运行,同时造成巨大的经济损失[1]。因此,准确、及时地诊断变压器的故障,对于确保电力系统的安全和稳定运行具有重要的意义。
目前,对于油浸式变压器而言,油中溶解气体分析(Dissolved Gas Analysis, DGA)方法是一种有效的诊断方法。传统的DGA方法主要包括气体成分分析法[2]和气体含量比值法[3-4]。气体成分分析法是通过分析变压器内部气体中的特征气体成分来判断变压器故障,但其只能定性描述,难以定量分析。气体含量比值法是通过建立不同气体成分的比值与变压器故障类型之间的关联性,从而确定变压器内部故障类型。这类方法丰富了气体特征量的个数,在一定程度上提升了故障诊断精度,但该方法的边界区存在一定的模糊性。随着人工智能技术的快速发展,基于数据驱动的故障诊断方法也在不断发展和创新,如神经网络[5-7]、支持向量机[8-10]、深度学习[11-12]等。文献[13]通过分析变压器油中气体数据特征,提出一种基于多层深度神经网络(Deep Neural Networks, DNN)的电力变压器故障识别算法,相对于单层网络模型具有较高的诊断准确率。文献[14]采用自适应极限学习机(Self-Adaptive Extreme Learning Machine, SA-ELM)方法构建变压器故障识别模型,克服了人工智能算法训练速度慢、超参数难以选择等问题。文献[15]提出了一种基于深度置信网络和极限学习机的变压器故障诊断方法,保证了故障识别精度,同时提高了模型收敛速度及泛化能力。综上所述,基于数据驱动的故障诊断方法在故障识别能力和诊断准确度等方面都具有较大的优势,但上述算法性能的实现往往需要依靠大量的样本数据。而在实际工程应用中,变压器故障属于小概率事件,收集到的故障信息有限,难以覆盖所有可能的故障情况,易造成故障样本信息的缺失,这属于零样本问题。因此,上述方法难以正确识别故障类型。
零样本学习(Zero-Shot Learning, ZSL)方法是一种旨在利用训练集和辅助信息对模型进行训练,并在测试阶段利用模型的测试类辅助信息对模型进行补足,实现零样本条件下测试集的分类。C. H. Lampert等[16]首次提出了ZSL方法,并给出了基于物体属性的直接属性预测(Direct Attribute Prediction, DAP)方法,解决了没有交集的测试集和训练集的分类。此外,C. H. Lampert等[17]提出了间接属性预测(Indirect Attribute Prediction, IAP)方法学习属性之间的关系来实现分类任务。Gong Ping等[18]提出了一种基于多任务混合的属性关系和属性特定特征的零样本分类方法,通过对图片或视频的属性关系和属性特定特征的描述实现对不同类别的分类。Shen Fengli等[19]建立了一种基于语义相似度监督的自编码器模型,提升了分类任务中零样本学习方法的准确度。然而,上述文献中关于ZSL方法的研究对象均为图像、视频或者物品,其属性矩阵基于“形状”或“颜色”等语义信息构成。但是这类属性信息并不适用于工程中零样本故障诊断问题,因此,需要更具有代表性的属性矩阵来辅助零样本故障诊断技术的实现。
目前,零样本故障诊断的研究主要在轴承故障诊断方面。文献[20]提出一种基于零样本学习的轴承复合故障诊断模型,将单个故障和复合故障的语义特征嵌入到故障数据的视觉空间中,利用信号特征与复合故障语义之间的距离来识别未知复合故障类别。文献[21]提出一种基于收缩自动编码器的零样本学习故障诊断方法,能够在未知工作负载下诊断相关但不同工作负载下的故障。文献[22]提出一种基于语义信息的多变量时间序列早期故障分类方法,该方法利用传感器生成多路时间序列数据,通过语义信息实现对未知故障的分类。文献[23]提出一种两阶段零样本故障识别方法来解决类别不平衡问题,利用新型特征生成网络获取样本的潜在分布特征,实现无训练样本下的故障检测。虽然ZSL方法在轴承故障诊断方面具有一定的可靠性和优越性,但在变压器故障诊断方面鲜有研究。同时变压器油中溶解气体含量分布的长尾效应引起故障样本信息缺失增加了变压器准确诊断的难度。
在ZSL故障诊断过程中数据特征提取对于提高故障诊断性能具有重要作用。面对复杂非线性数据时,文献[24]采用卷积神经网络增强模型非线性表达能力,降低了数据维度,但易陷入局部最优和过拟合。文献[25]采用无监督学习的自编码器作为特征提取方法,其泛化性强,但提取的特征数据复杂、粗糙,易导致特征数据冗余,造成故障数据的误表示。文献[26]采用主成分分析方法提取主要特征,其计算方法简单且易于实现,但对异常值敏感易导致主成分特征偏离真实情况。数据特征提取过程能够剔除无效信息,提升故障识别精度和收敛速度,但上述方法均未考虑到样本数据特征之间的权重问题。注意力机制是一种灵活、高效的机制,能够有效地改进特征提取中的不足之处,并被广泛应用于各类机器学习中。注意力机制的核心思想是通过增加空间注意力通道使得网络获得性能增益,以低权重去除不相关信息,且不断调整权重,降低模型复杂度的同时保持性能。其通过一维卷积实现局部跨通道交互,提取通道间的相关性,能够有效解决上述特征提取存在的问题。
此外,在ZSL故障诊断中,辅助信息用于实现训练集和测试集之间数据特征共享,是实现零样本故障诊断的关键。文献[27]中依据故障细粒度属性描述,采用手工标注的方法获取零样本故障诊断任务的辅助信息。由于属性描述属于类级别,无需专家知识即可获取,因此克服了未知故障需要收集大量样本的难处。但随着属性个数的增加,在一定程度上增加了人工成本。而文本学习方法采用主题模型[28]、Word2Vec[29]和TF-IDF词向量化[30]等处理工具,更加有效地学习样本数据中的准确辅助信息,提高零样本学习的可靠性。
综上所述,为了解决零样本条件下变压器故障诊断准确率不高的问题,本文提出了基于变权属性矩阵的变压器零样本故障诊断方法。采用改进的高效通道注意力网络-堆栈式自编码器(Improved Efficient Channel Attention Network-Stacked Autoencoder, IECANet-SAE)网络对油中气体数据进行重要特征提取,减少数据冗余信息;构建基于故障描述的变权属性矩阵,增强已知故障和未知故障之间数据特征共享;利用基于神经网络的朴素贝叶斯(Neural Naive Bayes, NNB)算法学习主要特征数据与属性矩阵之间的空间映射关系并诊断故障类型,实现零样本故障诊断。最后,对比不同模型、不同数据集的试验结果,相较于其他方法,本文所提方法的诊断效果更好、诊断速度更快。
堆栈式自编码器(Stacked Autoencoder, SAE)是一种基于神经网络的无监督学习方法,主要用于特征提取和降维。它由多层自编码器组成,每一层自编码器由多个隐含层组成,结构如图1所示。编码器的作用是将输入数据从高维度向低维度进行非线性转换,并在此过程中去除数据中的冗余信息,获取网络训练后的低维特征表达。解码器则是将编码器的输出进行反向转换,以重建原始数据。
图1 堆栈式自编码器结构
Fig.1 Structure of SAE
假设自编码的输入为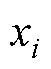 ,编码器和解码器公式为
,编码器和解码器公式为
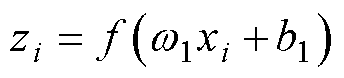 (1)
(1)
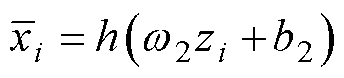 (2)
(2)
式中,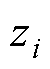 为中间变量;
为中间变量;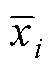 为重构数据;
为重构数据;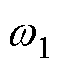 和
和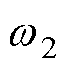 分别为编码器和解码器的权重;
分别为编码器和解码器的权重;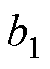 和
和 分别为编码器和解码器的偏置;
分别为编码器和解码器的偏置;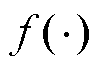 和
和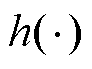 分别为编码器和解码器的激活函数。
分别为编码器和解码器的激活函数。
在SAE训练过程中,通过编码和解码两个阶段完成。编码阶段,首先将输入数据通过训练将隐含层的输出映射为低维度的特征向量;其次把上一层网络的输出作为当前网络的输入,并传递到下一个隐含层进行相同的处理;最后编码器将输入数据转换为一个低维度的特征向量,表示为编码器的输出。
解码阶段是采用反向传播算法进行训练,其实现过程与编码过程类似,且解码器的输入是编码器的输出。解码过程从编码器的输出开始,通过激活函数将隐含层的输出映射为高维度的特征向量。然后将特征向量传递到下一个隐藏层进行相同的处理。最后解码器将编码器的输出转换为原始数据,表示为解码器的输出。
在训练过程中,编码器和解码器的参数通过反向传播算法进行更新,以方均最小化误差作为重构损失函数,有
 (3)
(3)
式中,N为样本个数。
损失函数通过计算输入数据与解码器输出数据之间的差异来衡量重构能力。通过不断迭代训练,模型可以逐步学习到数据中的有效特征,并提高重构精度。
IECANet-SAE网络由卷积神经网络(Convo- lutional Neural Network, CNN)和高效通道注意力网络(Efficient Channel Attention Network, ECANet)构成,实现更加高效和准确的特征提取。CNN是一种用于处理网格结构数据的深度学习模型,主要由卷积层、池化层和全连接层组成。其中,卷积层是卷积神经网络的核心部分,能够通过卷积操作提取输入数据中的局部信息。ECANet是一种基于权重比分布的注意力机制,其旨在学习通道间的注意力权重,聚焦于局部信息,通过引入自适应一维卷积充分融合通道中的局部信息,降低网络的复杂度,同时避免降维过程中的信息丢失。综合利用CNN和ECANet的特征表达能力,提取更加丰富、准确的特征,IECANet-SAE网络结构如图2所示。
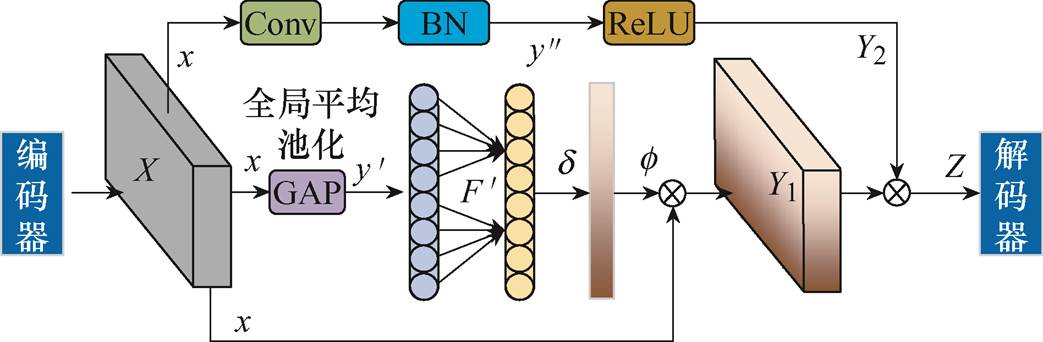
图2 IECANet-SAE网络结构
Fig.2 Structure of IECANet-SAE network
具体流程如下:
(1)将编码器输出数据
 作为输入数据,利用卷积运算从输入的信息中提取特征进行池化、归一化、全连接等处理获得输出值
作为输入数据,利用卷积运算从输入的信息中提取特征进行池化、归一化、全连接等处理获得输出值 为
为
 (4)
(4)
式中,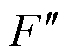 为卷积运算;
为卷积运算; 为3×3的卷积核;
为3×3的卷积核; 为偏置。
为偏置。
在卷积操作之后,采用ReLU函数作为激活函数对输出值进行非线性变换,增加网络的表达能力。
 (5)
(5)
式中, 为激活函数。
为激活函数。
(2)利用全局平均池化(Global Average Pooling,GAP)对大小为H×W×C的输入数据 进行降维分析,并在通道中进行一维卷积融合局部重要信息,使用Sigmoid激活函数生成通道权重信息,并与原输入数据相乘得到中间特征数据。
进行降维分析,并在通道中进行一维卷积融合局部重要信息,使用Sigmoid激活函数生成通道权重信息,并与原输入数据相乘得到中间特征数据。
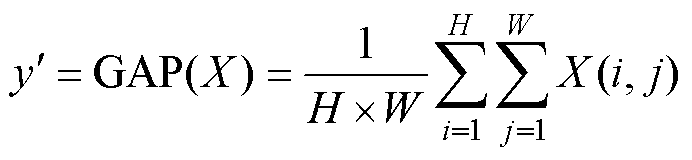 (6)
(6)
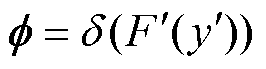 (7)
(7)
 (8)
(8)
式中,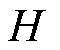 、
、 分别为数据的高度和宽度;
分别为数据的高度和宽度;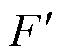 为卷积运算;
为卷积运算;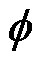 为权重向量;
为权重向量;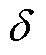 为Sigmoid激活函数;
为Sigmoid激活函数;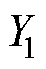 为特征提取结果。
为特征提取结果。
在一维卷积操作的过程中,卷积核 由通道数C的函数自适应决定,两者之间的关系为
由通道数C的函数自适应决定,两者之间的关系为
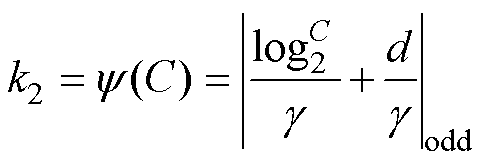 (9)
(9)
式中,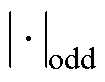 为选择最接近的奇数;本文设置
为选择最接近的奇数;本文设置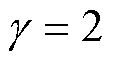 ,
, ,用于改变通道数
,用于改变通道数 和卷积核大小之间的比例。
和卷积核大小之间的比例。
(3)将两通道特征提取结果相加,综合利用卷积神经网络和ECANet的特征表示能力,进一步提升模型的性能,同时作为解码层的输入数据,从而实现编码-解码的过程。
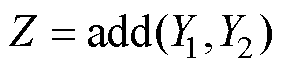 (10)
(10)
将IECANet-SAE应用在油中气体特征提取中,挖掘数据集之间的相关性并为不同气体特征数据设定不同的权重比值,以此更好地提取气体数据与故障类别之间的高价值信息,从而降低信息损失度,提高诊断精度。
本文提出了基于变权属性矩阵的变压器零样本故障诊断技术,旨在解决油中气体数据缺失而导致故障诊断困难的问题。
油浸式变压器中以绝缘油作为冷却和绝缘介质,其主要由烷类、烃类、烯类、炔类等组成。当变压器设备发生故障时,如火花放电、高温过热等,变压器油中的物质在发热和放电的过程中通过化学反应生成H2、CH4、C2H2、C2H4、C2H6等气体。根据《变压器油中溶解气体分析和判断导则》[2],建立油中气体特征比值组合与变压器的故障类型的联系,将油浸式变压器中的故障分为五大类:低能放电、高能放电、局部放电、中低温过热和高温过热。由于受外界环境、不同运行工况以及变压器的使用寿命的影响,不同的故障类型产生的油中气体含量、种类各有差异。
大量的研究表明,特征气体、特征气体比值与故障类型存在较强的相关性。由于气体数据数值差距大、特征量个数较少,因此传统分析方法中仅由H2、CH4、C2H2、C2H4、C2H6气体作为特征量进行分析,难以准确反映气体数据与故障类别对应关系。通过大量研究文献总结出五种特征气体和五种气体比值作为气体特征,具体见表1。表中,TCH为总烃,即所有烃类气体总和。
表1 气体特征
Tab.1 Characteristics of gas

编 号气体特征 1H2 2CH4 3C2H4 4C2H6 5C2H2 6H2/TCH 7CH4/TCH 8C2H4/TCH 9C2H6/TCH 10C2H2/TCH
为了充分保留特征气体之间的个体差异性,增强样本的代表性,提高变压器故障诊断精度,对表1中的气体特征数据按照式(11)进行标准化处理,进一步采用IECANet-SAE网络提取数据中的主要特征。
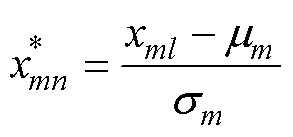 (11)
(11)
式中,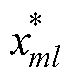 为第
为第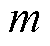 个故障气体特征的第l个标准化后数据;
个故障气体特征的第l个标准化后数据;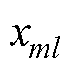 为第个故障气体特征的第l个数值;
为第个故障气体特征的第l个数值; 和
和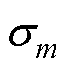 分别为第个故障气体特征的均值、标准差。
分别为第个故障气体特征的均值、标准差。
采用IECANet-SAE网络提取变压器油中气体数据的主要特征。通过卷积层和池化层对输入数据进行降维处理,提取局部特征和上下文关联信息。同时引入自适应一维卷积网络学习通道注意力权重,对油中气体数据进行权重计算与分配,并与原数据进行卷积计算,保留主要特征。综合利用两者提取的特征向量,实现油中气体数据重要特征提取。
变压器故障属性矩阵是一种有效的辅助信息,建立故障信息与故障标签之间的联系,增强各类故障之间数据特征的共享。采用基于潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)的主题建模方法构建变权属性矩阵,过程示意图如图3所示。
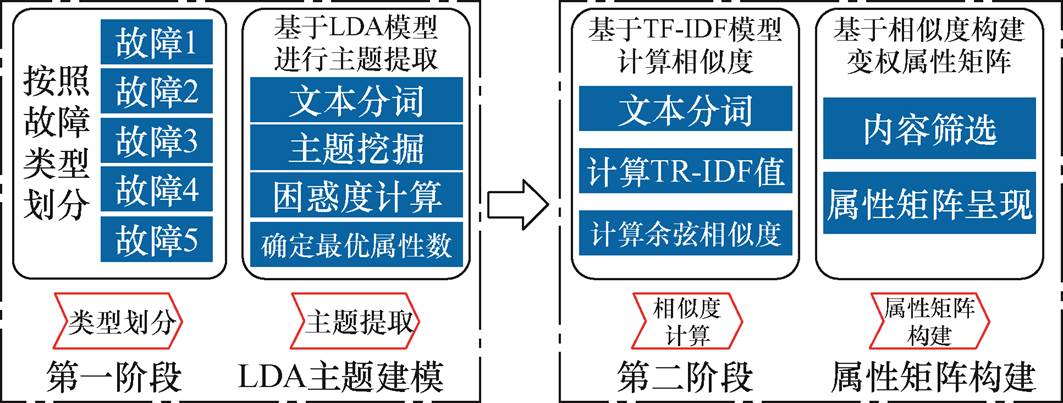
图3 故障属性矩阵构建示意图
Fig.3 Construction diagram of fault attribute matrix
第一阶段是故障类型划分和主题提取。首先将收集到的故障描述按照故障类型进行划分,其中每类变压器故障的特征来源于《电网设备状态检测技术应用典型案例(2011~2013年)》、《变压器类设备典型故障案例汇编(2006~2010年)》等文献[30-31],部分故障特征描述见表2。完成阶段划分后,采用LDA模型对故障描述进行分词,并利用Log_Perplexity方法计算不同主题下的困惑度,确定最优故障属性个数及不同属性的权重,实现故障重要属性提取。
第二阶段是故障属性矩阵构建。采用TF-IDF模型将文本转换为TF-IDF矩阵,并对各向量采用式(12)计算余弦相似度,判断向量之间的相似性。通过相似度高低判断不同故障同一属性之间的匹配程度,采用矩阵的形式实现可视化表达。假定所有属性都具有二进制值,使得训练类的属性表示为 。其中,
。其中,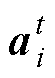 表示第
表示第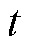 种故障第
种故障第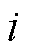 个属性描述特征。依据故障类别是否拥有变压器故障属性,得到一个与之对应的15维的二值故障属性矩阵,如图4所示,具体的故障属性信息见表3。故障属性矩阵表示为:
个属性描述特征。依据故障类别是否拥有变压器故障属性,得到一个与之对应的15维的二值故障属性矩阵,如图4所示,具体的故障属性信息见表3。故障属性矩阵表示为: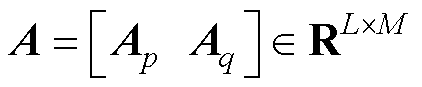 ,其中,
,其中,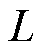 为故障种类数,且
为故障种类数,且 ,
,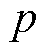 和
和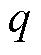 表示训练集和测试集中故障种类数,
表示训练集和测试集中故障种类数,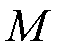 为故障属性的个数。
为故障属性的个数。
表2 部分故障特征描述
Tab.2 Description of partial fault features

故障类型故障描述 低能放电裸金属悬浮放电 低能放电低压侧短路低压绕组损坏 高能放电相间短路导致绕组损坏 高能放电短路导致绕组损坏 局部放电电容屏蔽绝缘故障 局部放电套管内部放电性故障 中低温过热磁屏蔽短路过热 中低温过热铁心局部过热故障 高温过热线圈金属压环过热 高温过热低压绕组股间短路过热
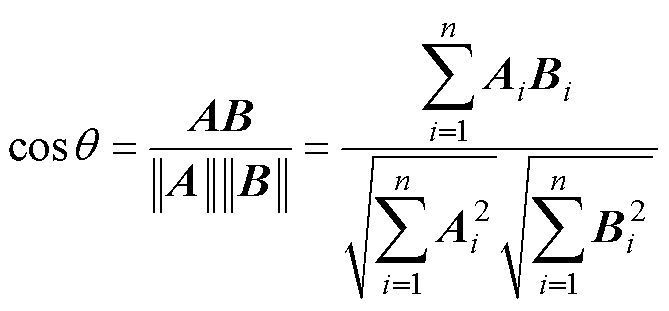 (12)
(12)
式中, 、
、 分别为向量A和B的各分量。
分别为向量A和B的各分量。

图4 故障属性矩阵
Fig.4 Matrix of fault attribute
表3 故障属性信息
Tab.3 Information of fault attribute

属 性属性描述 1号磁屏蔽故障 2号油道/油泵故障 3号围屏故障 4号绕组损坏 5号低压侧短路 6号分接开关故障 7号铁心局部短路 8号局部涡流 9号套管故障 10号绝缘受潮 11号异物引起悬浮放电 12号接触不良 13号绕组变形 14号雷击引起故障 15号铁心多点接地
零样本学习的本质是将已知样本集进行训练,得到一个 的映射关系,再将学习得到的
的映射关系,再将学习得到的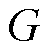 模型应用于未知样本集中,从而获取对应的故障标签。零样本学习中的对象分为两类:训练集
模型应用于未知样本集中,从而获取对应的故障标签。零样本学习中的对象分为两类:训练集 (又称为已知样本)和测试集
(又称为已知样本)和测试集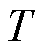 (又称为未知样本),且训练集和测试集彼此不相交,即
(又称为未知样本),且训练集和测试集彼此不相交,即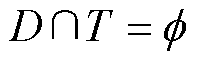 。训练集的样本表示为:
。训练集的样本表示为: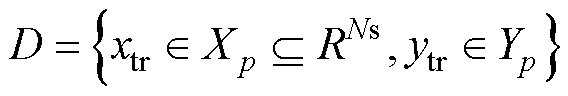 ,目标集的样本表示为:
,目标集的样本表示为: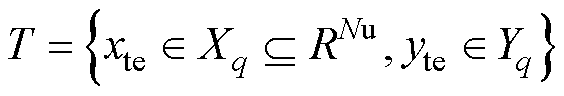 ,其中,
,其中,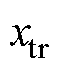 和
和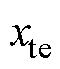 分别为训练集和测试集,
分别为训练集和测试集,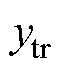 和
和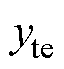 分别为训练集和测试集的故障标签。
分别为训练集和测试集的故障标签。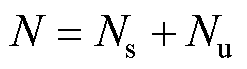 ,
, 和
和 分别为训练集、测试集个数。
分别为训练集、测试集个数。
由于零样本故障诊断的研究仍处于发展阶段,还未明确一致的定义,因此为了更清晰地阐述零样本故障诊断问题,本文对零样本故障诊断定义如下:
定义1:在故障诊断过程中,训练阶段采用已知故障样本数据作为输入数据进行训练,且在测试阶段中能够识别未知故障类型的过程,即认为该模型实现了零样本故障诊断。
零样本故障诊断技术的基本思想如图5所示。
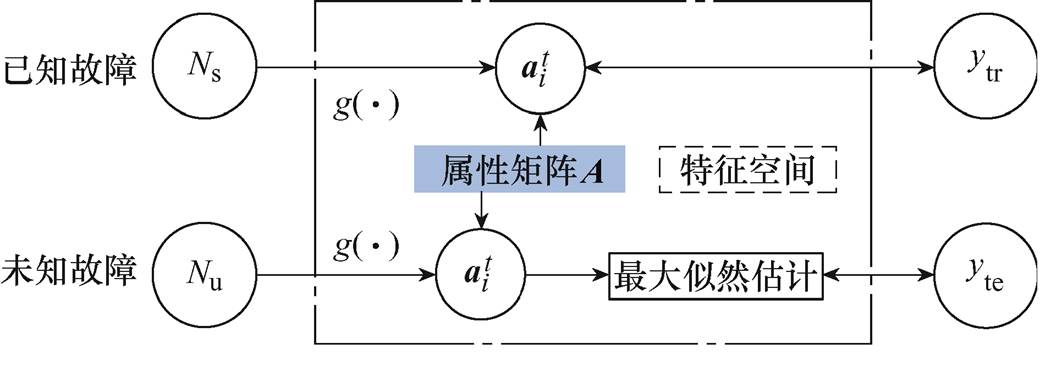
图5 零样本故障诊断过程示意图
Fig.5 Process diagram of zero-shot fault diagnosis
映射学习阶段:采用NNB算法获得故障属性矩阵中每一属性向量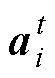 与已知故障样本数据在特征空间中的映射函数
与已知故障样本数据在特征空间中的映射函数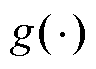 。
。
诊断阶段:使用将未知故障样本数映射到同一个特征空间中,得到对应属性向量。基于贝叶斯原理,采用最大似然估计公式获取第种故障最可能的故障类别,有
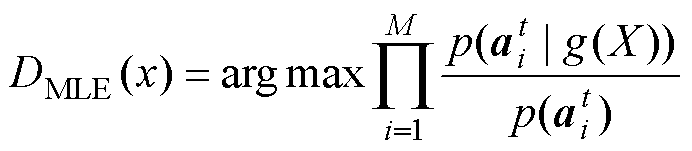 (13)
(13)
本文提出的ZSL变压器故障诊断模型包括数据处理、属性矩阵构建、数据特征提取和零样本故障诊断四个阶段。其中,零样本故障诊断部分又包括属性学习和故障识别过程。具体故障诊断流程如图6所示,步骤如下:
(1)数据处理。把变压器油中气体和气体比值作为样本数据集,并对数据集进行标准化处理,划分训练集和测试集。
(2)属性矩阵构建。根据变压器典型故障案例中故障特征描述信息,采用基于LDA的主题建模方法构建基于属性描述的变权属性矩阵A。
(3)数据特征提取。采用IECANet-SAE网络提取油中气体数据主要特征,充分保留各个数据的差异性和重要信息。
(4)零样本故障诊断。零样本故障诊断由属性映射学习和故障识别两部分构成。利用NNB算法学习重要特征信息与属性矩阵之间的映射关系,并获得未知样本的故障属性向量。通过计算未知故障向量和与之对应的故障属性之间的相似度,选取最相似的标签作为诊断结果,实现零样本故障诊断,同时建立诊断结果评价指标。
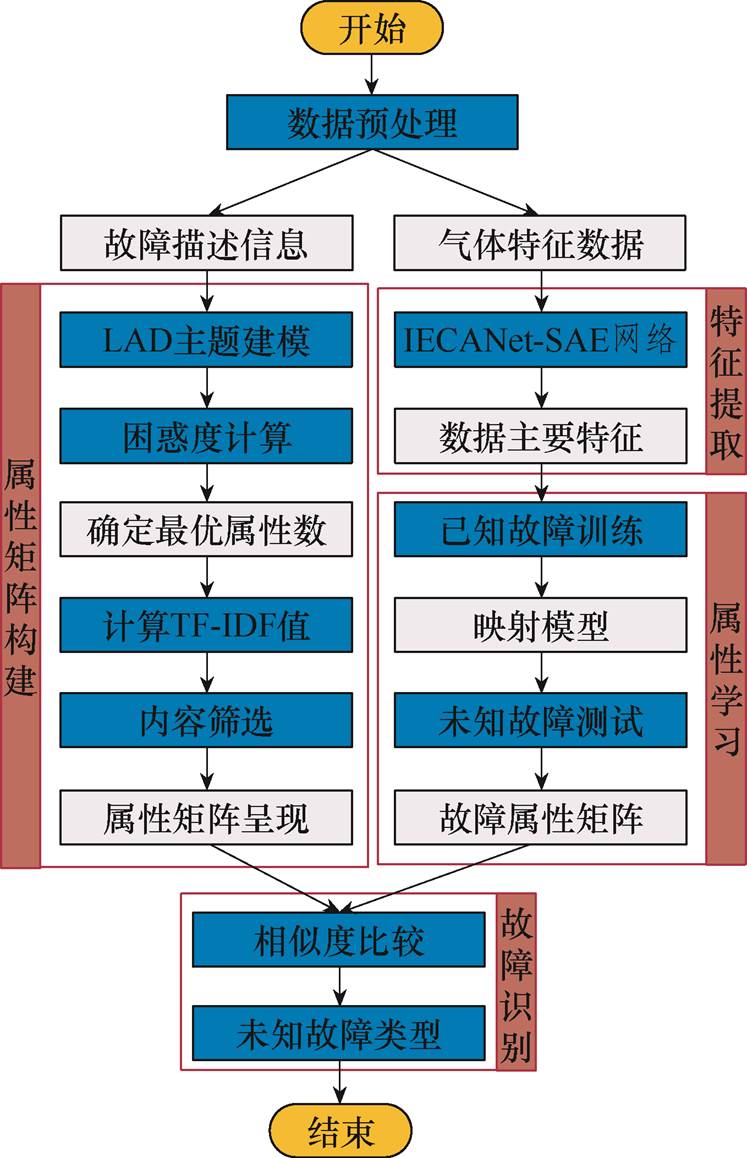
图6 ZSL故障诊断流程
Fig.6 Flow chart of ZSL fault diagnosis
为了验证本文提出方法的性能和有效性,使用Python语言在Tensorflow 2.2学习框架上运行代码。计算机使用Intel(R) Core(TM) i5-8400 CPU @ 2.80 GHz处理器及16GB内存硬件配置。
本文所选用的油中溶解气体数据来源于IEC TC 10故障数据库及已公开发表的相关权威的文献资料[30-31],共计990组。故障样本分布情况及编号见表4,部分故障样本数据见表5。
表4 故障样本数据分布
Tab.4 Distribution of fault sample data

编 号故障类型样本数量 F1 (Fault1)低能放电196 F2 (Fault2)高能放电231 F3 (Fault3)局部放电129 F4 (Fault4)中低温过热195 F5 (Fault5)高温过热239
表5 部分故障样本数据
Tab.5 Partial fault sample data

样本编号样本体积分数/(μL/L)故障类型 H2CH4C2H6C2H4C2H2 165.220.03.98.125.1F1 267.88.91.912.736.2F1 3475.3195.832.6187.3221.2F2 4531.0111.922.7122.5169.0F2 583.345.318.136.50.3F3 685.97.04.52.60.0F3 733.029.09.012.00.0F4 846.9161.694.1193.60.6F4 9165.6241.061.3514.513.5F5 10164.0244.0103497.08.3F5
由于不同故障类型产生的油中气体含量和种类存在差异,而气体数据的数值差距较大,特征量较少,难以准确反映气体数据与故障类别对应关系。以高温过热故障为例,图7展示了故障中各类气体含量分布。从图中可以看出,气体数据分布呈现“长尾效应”,其中“头部”数据的气体含量大,而“尾部”数据的气体含量小,因而在试验中往往会忽略“头部”数据,增加了故障诊断的难度。
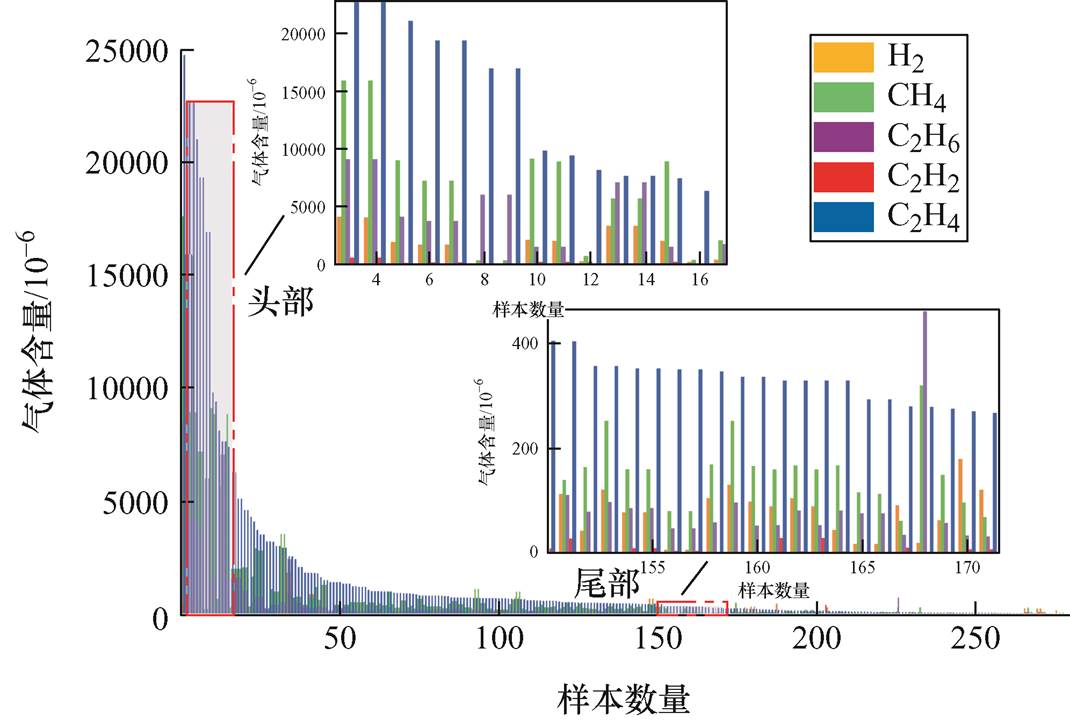
图7 高温过热故障中各类气体含量分布
Fig.7 Distribution of various gas content in high temperature overheating faults
因此,对表1中的十类气体特征数据进行标准化处理,并根据零样本学习的原则对故障样本数据集进行划分,在五类故障数据中随机抽取三种故障作为训练样本,剩余故障作为测试样本,数据集的训练故障和目标故障划分情况见表6。
表6 故障样本数据集划分
Tab.6 Division of fault sample data set

数据集训练故障目标故障 T1F2, F3, F4F1, F5 T2F1, F3, F5F2, F4 T3F2, F4, F5F1, F3 T4F1, F3, F4F2, F5
为了更加有效地评价所提零样本故障诊断模型的性能,采用精准率(Pre)、召回率(Rec)和准确率(Acc)作为评价指标,如式(14)~式(16)所示。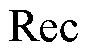 是评价诊断结果的完整性,
是评价诊断结果的完整性, 是对变压器故障诊断结果评定的综合指标,其指数越高代表故障诊断精度越高。
是对变压器故障诊断结果评定的综合指标,其指数越高代表故障诊断精度越高。
 (14)
(14)
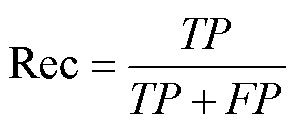 (15)
(15)
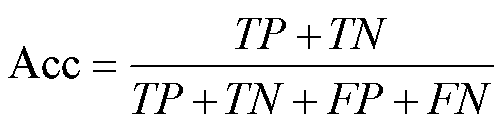 (16)
(16)
式中,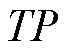 为正样本被正确识别的数量;
为正样本被正确识别的数量; 为误报的负样本数量;
为误报的负样本数量;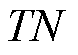 为负样本被正确识别的数量;
为负样本被正确识别的数量;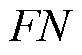 为漏报的正样本数量。
为漏报的正样本数量。
属性映射学习是实现零样本故障诊断的基础,属性映射学习的结果影响着零样本故障诊断的性能。为了更好地评估属性学习的效果,采用子集准确率( )[32]作为评价指标来评估该方法的性能,如式(17)所示。表示预测的标签组与真实标签组完全一致时,正确个数占所有个数的百分比。
)[32]作为评价指标来评估该方法的性能,如式(17)所示。表示预测的标签组与真实标签组完全一致时,正确个数占所有个数的百分比。
 (17)
(17)
式中,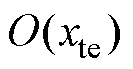 为测试集属性映射学习标签;为测试集真实数据标签。
为测试集属性映射学习标签;为测试集真实数据标签。
3.3.1 特征提取结果分析
本文采用IECANet-SAE网络作为特征提取网络来提取数据中的重要信息,并通过数据的重构结果来评估模型的有效性。在特征提取时,将数据集按照7 3划分为测试集和验证集,提取每类特征气体中的前三个重要特征。设置SAE和IECANet-SAE网络对比试验,其准确率如图8所示。由对比结果可知,IECANet-SAE特征提取模型的重构误差仅为0.05%,准确率高达97%以上,且高于SAE特征提取结果。这表明IECANet-SAE网络能够充分提取重要特征信息,即能够较好地表示数据信息。
3划分为测试集和验证集,提取每类特征气体中的前三个重要特征。设置SAE和IECANet-SAE网络对比试验,其准确率如图8所示。由对比结果可知,IECANet-SAE特征提取模型的重构误差仅为0.05%,准确率高达97%以上,且高于SAE特征提取结果。这表明IECANet-SAE网络能够充分提取重要特征信息,即能够较好地表示数据信息。
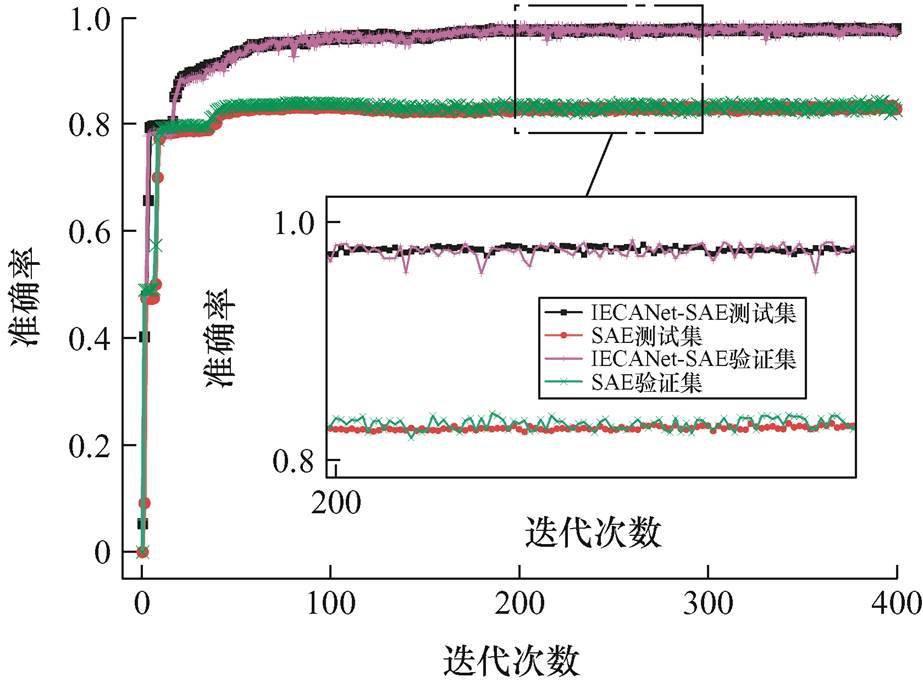
图8 不同特征提取方法下数据重构的准确率
Fig.8 Accuracy of data reconstruction in different feature extraction methods
此外,使用t-SNE方法将提取的多维特征降维后投影到二维空间中进行可视化分析,从投射结果的分离效果来说明特征提取方法的有效性。特征降维可视化后的结果如图9所示,其中水平和垂直坐标分别表示成分占比最大的两个特征。
从图9a中可见,SAE方法对于变压器不同故障气体特征数据的区分度较差,五类故障类型均出现重叠现象。而IECANet-SAE网络特征提取结果的可分性较佳,从图9b可见具有明显的分界线。因此,与SAE方法相比较,IECANet-SAE网络特征提取效果更佳。
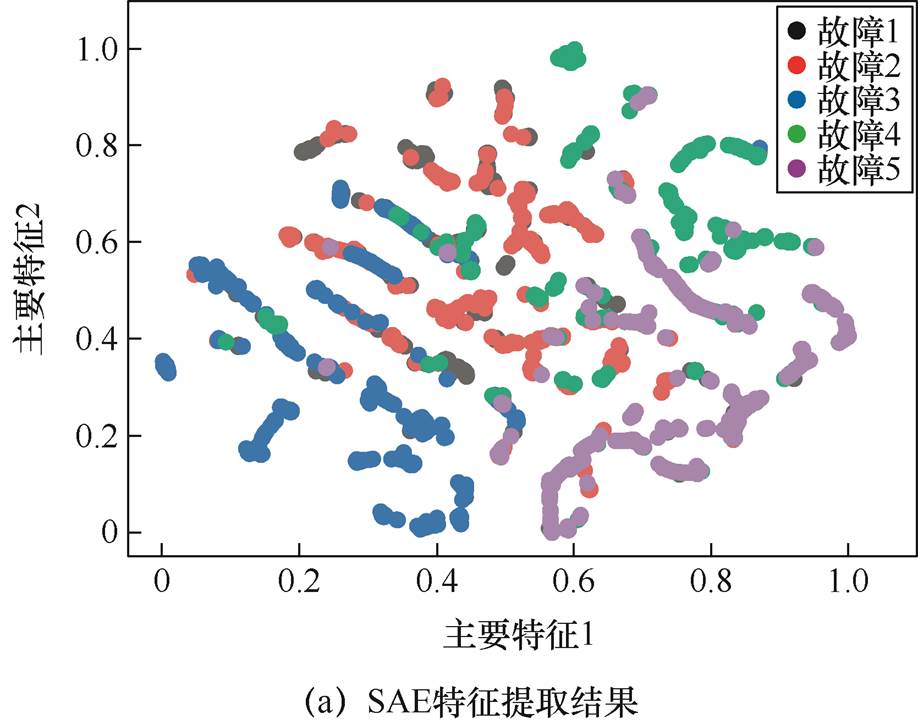
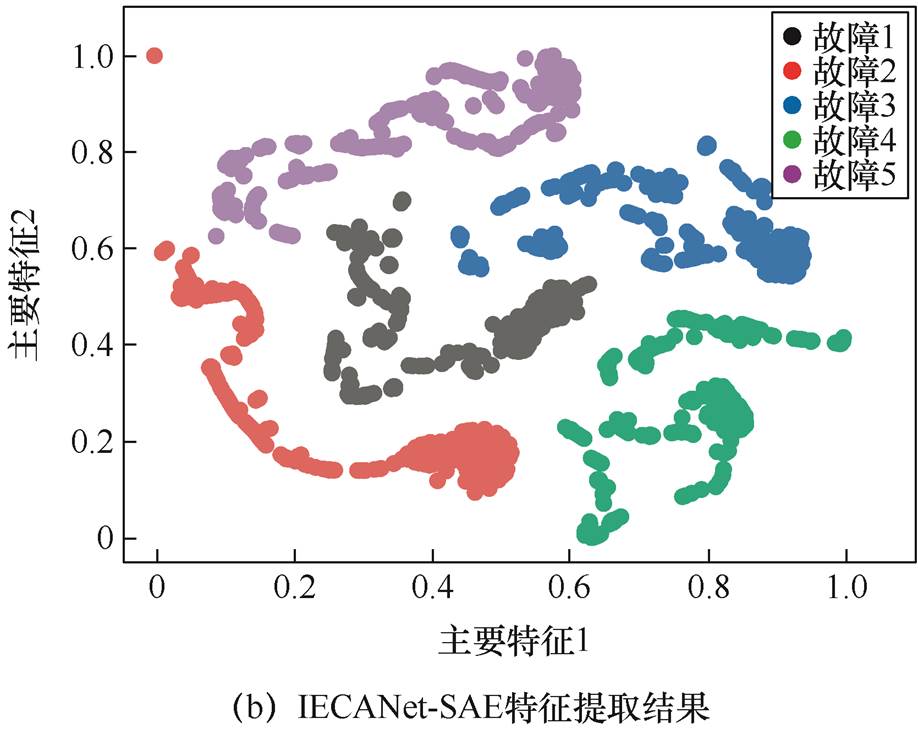
图9 不同方法特征提取结果对比
Fig.9 Comparison of feature extraction results of different methods
3.3.2 属性学习结果分析对比
属性学习的准确性是评估零样本故障诊断性能的重要评价指标。依据表6中的数据集划分情况,使用属性映射学习网络学习各数据集中的各个属性,各属性的平均学习准确率如图10所示。

图10 不同数据集下属性学习准确率
Fig.10 Accuracy of attribute learning in different data sets
通过对比图10中四个数据集的学习准确率,可知大多数属性的学习效果比50%的随机准确率高,其中属性映射学习网络对数据集T4的准确率可达90%及以上。由于不同故障类别之间属性信息存在差异性以及故障信息不足等原因,导致数据集T2和T3中个别属性学习准确率较低。对比原数据直接属性学习和特征提取后的属性学习平均准确率的结果,如图11所示。考虑到试验结果的公平性,保持NNB中的参数不变。由图11中可知,采用原数据进行属性学习的准确率普遍较低;采用SAE特征提取后的属性学习结果略高于原数据的学习结果;而采用IECANet-SAE网络保留了原数据中的重要信息,大大提高了属性学习准确率,且高于其他两种方法。因此,本文所提的属性映射学习方法能够有效映射数据与故障属性之间的关系。
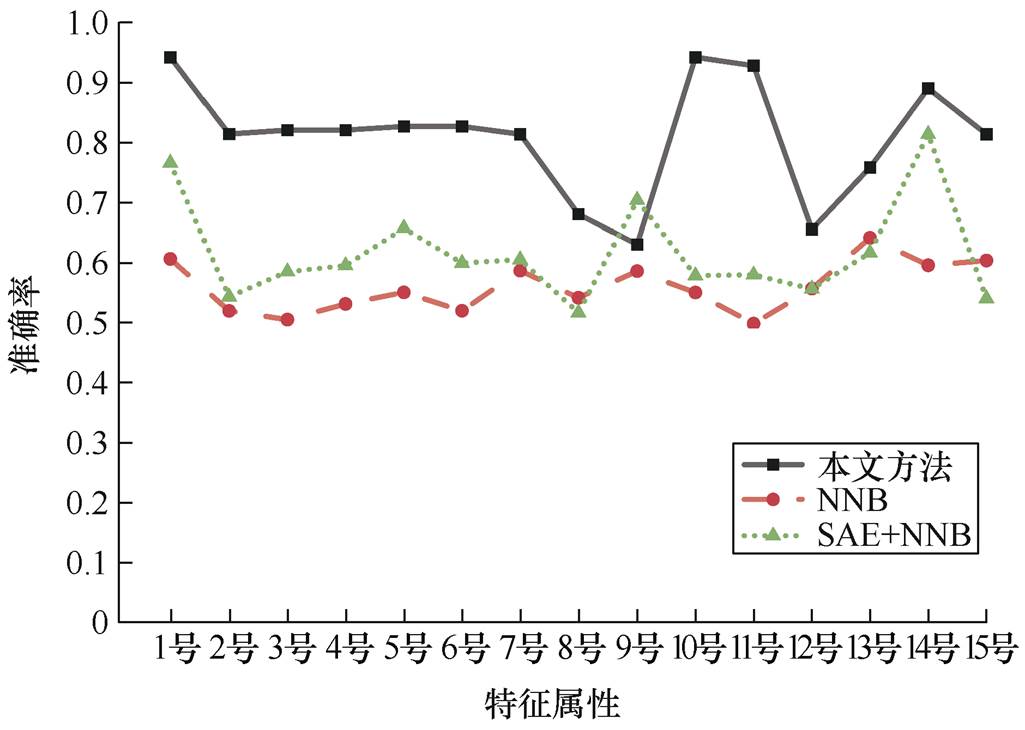
图11 不同分析方法下属性学习平均准确率
Fig.11 Average accuracy of attribute learning in different analysis methods
3.3.3 不同方法诊断性能对比分析
通过属性映射学习网络获得未知故障样本对应的属性矩阵向量后,通过计算各个样本属性矩阵向量与原属性矩阵之间的相似度,最终确定未知故障的类型。对比四个数据集中本文所提方法与其他故障诊断方法的性能对比结果,见表7。
据查阅文献可知,目前基于数据驱动的故障诊断模型在没有样本训练的前提条件下难以实现故障诊断。因此,DNN[13]和SA-ELM[14]在各个数据集下的诊断结果为0,同时表明了这类方法不适用于零样本条件下的故障诊断。而采用零样本学习的故障诊断方法具有一定的成效。DAP和IAP是由C. H. Lampert[16-17]等提出的用于图像识别任务的方法,主要依赖于诸如“颜色”或“形状”等属性特征来构建辅助信息。但是,在变压器故障诊断领域中难以获取这类信息。因此,采用本文所构建属性描述信息矩阵作为辅助信息进行零样本故障诊断。其中,DAP方法是将属性矩阵嵌于已知故障标签与未知故障标签之间,直接从已知故障样本信息中学习属性映射关系来识别未知故障样本标签,识别准确率较低,平均准确度仅为0.57。IAP方法是在训练已知故障中引入中间层,通过学习属性信息间接预测未知故障的属性信息,其准确率为0.64,比DAP方法略高。上述两种方法是直接从原始数据进行分析,而本文所提的方法使用IECANet- SAE网络对重要特征进行提取,保留原数据的特征信息。相比仅使用SAE特征提取的方法,本文所提的故障诊断结果具有较高的准确率、召回率和精准率。平均准确率达0.83,召回率达0.80,精准率达0.86,且所有结果均高于其他三种方法。
为了更加清晰地展示本文所提方法在零样本条件下的故障诊断效果,绘制四类数据集故障诊断结果的混淆矩阵如图12所示,横坐标表示故障诊断类别,纵坐标表示故障真实类别。对比四类数据集结果可知,故障类别1、2和5的正确识别率较佳,最高可达0.97。由于T2和T3数据集中个别属性学习准确率较低,以及故障类别3和4与其他故障之间的属性相关性较低等多种因素,导致故障类别3和4的正确识别率低于其他几类故障。
表7 不同方法诊断性能对比
Tab.7 Comparison of diagnostic performance of different methods

数据集评价指标DNNSA-ELMDAPIAPSAE-NNBIECANet-SAE+NNB T1Acc000.583 20.667 40.768 10.880 6 Rec000.733 30.870 10.920 30.961 8 Pre000.561 00.619 10.702 70.823 6 T2Acc000.602 50.655 60.744 50.804 2 Rec000.219 40.537 10.650 20.681 2 Pre000.991 10.707 90.798 20.886 8 T3Acc000.562 50.610 80.713 20.754 7 Rec000.128 10.233 30.675 60.575 2 Pre000.985 80.990 60.731 10.911 9 T4Acc000.513 80.645 10.773 40.873 4 Rec000.990 10.501 50.862 50.976 6 Pre000.507 10.706 90.735 40.802 1 平均值Acc000.565 50.644 70.749 80.828 2 Rec000.517 70.535 50.777 20.798 7 Pre000.761 30.756 10.741 90.856 1

图12 不同数据集诊断结果的混淆矩阵
Fig.12 Confusion matrix of diagnostic results for different data sets
表8展示了在不同数据集下各种零样本诊断方法故障的诊断时间。DAP和IAP方法是对原始数据进行分析,因此数据量较大、计算时间略长。而SAE-NNB和IECANet-SAE+NNB方法保留了数据中部分重要特征,在一定程度上减少了计算时间。由表8可知,本文所提方法诊断时间大约0.18 s,略快于其他方法。综上所述,本文所提方法在零样本条件下进行变压器故障诊断是可行的,且具有较高的准确率和效率。
表8 不同方法诊断时间对比
Tab.8 Comparison of diagnostic time of different methods

数据集DAP/sIAP/sSAE-NNB/sIECANet-SAE+NNB/s T12.171 2±0.041.842 5±0.050.189 4±0.010.178 5±0 T22.073 4±0.091.927 4±0.020.224 3±0.020.177 5±0 T32.271 5±0.101.855 0±0.110.214 5±00.173 5±0.01 T41.970 7±0.091.725 7±0.040.194 5±0.010.186 5±0.01
针对零样本条件下故障诊断准确率低的问题,本文以变压器油中气体为研究对象,提出了基于变权属性矩阵的零样本变压器故障诊断方法,通过属性矩阵构建、特征提取和零样本故障诊断,实现已知故障到未知故障的零样本故障诊断,准确识别变压器未知故障类型。主要研究结果如下:
1)使用基于LDA主题建模方法,计算文本相似度,构建故障信息描述的变权属性矩阵,有效增强故障信息与故障样本标签之间的关联性,解决了样本缺失导致诊断精度低的问题。
2)通过IECANet-SAE网络提取油中气体数据的主要特征,相比于SAE方法,具有良好的故障特征气体分离效果,有助于提高变压器故障诊断性能。
3)采用NNB算法构建重要特征数据与故障属性矩阵之间的映射关系,同时获得未知故障的矩阵向量。通过计算矩阵向量与属性矩阵之间的相似度,高效且准确地识别未知故障类型。诊断结果的平均准确度可达0.83,诊断时间达0.18 s。
综上所述,基于变权属性矩阵的变压器零样本故障诊断方法能在样本信息缺失的条件下实现零样本故障诊断,准确度较高且计算速度快。但是变压器故障信息不足及故障类型之间的相关度对变压器的准确诊断有一定的影响,因此,深度挖掘故障信息是下一步亟须解决的问题。
参考文献
[1] 刘云鹏, 许自强, 李刚, 等. 人工智能驱动的数据分析技术在电力变压器状态检修中的应用综述[J]. 高电压技术, 2019, 45(2): 337-348.
Liu Yunpeng, Xu Ziqiang, Li Gang, et al. Review on applications of artificial intelligence driven data analysis technology in condition based maintenance of power transformers[J]. High Voltage Engineering, 2019, 45(2): 337-348.
[2] 国家能源局. DL/T 722-2014 变压器油中溶解气体分析和判断导则[S]. 北京: 中国电力出版社, 2015.
[3] Taha I B M, Hoballah A, Ghoneim S S M. Optimal ratio limits of Rogers' four-ratios and IEC 60599 code methods using particle swarm optimization fuzzy-logic approach[J]. IEEE Transactions on Dielectrics and Electrical Insulation, 2020, 27(1): 222-230.
[4] Souahlia S, Bacha K, Chaari A. MLP neural network-based decision for power transformers fault diagnosis using an improved combination of Rogers and Doernenburg ratios DGA[J]. International Journal of Electrical Power & Energy Systems, 2012, 43(1): 1346-1353.
[5] Xing Zhikai, He Yigang. Multi-modal information analysis for fault diagnosis with time-series data from power transformer[J]. International Journal of Electrical Power & Energy Systems, 2023, 144: 108567.
[6] 杜厚贤, 刘昊, 雷龙武, 等. 基于振动信号多特征值的电力变压器故障检测研究[J]. 电工技术学报, 2023, 38(1): 83-94.
Du Houxian, Liu Hao, Lei Longwu, et al. Power transformer fault detection based on multi-eigenvalues of vibration signal[J]. Transactions of China Electrotechnical Society, 2023, 38(1): 83-94.
[7] 李典阳, 张育杰, 冯健, 等. 变压器故障样本多维诊断及结果可信度分析[J]. 电工技术学报, 2022, 37(3): 667-675.
Li Dianyang, Zhang Yujie, Feng Jian, et al. Multi-dimensional diagnosis of transformer fault sample and credibility analysis[J]. Transactions of China Electrotechnical Society, 2022, 37(3): 667-675.
[8] Hong Cui, Qiu Shida, Gao Wei. Fault diagnosis of distribution transformers by combining EEMDAN and GCN[J]. Journal of Electronic Measurement and Instrumentation, 2022, 36(12): 86-96.
[9] 赵莉华, 徐立, 刘艳, 等. 基于点对称变换与图像匹配的变压器机械故障诊断方法[J]. 电工技术学报, 2021, 36(17): 3614-3626.
Zhao Lihua, Xu Li, Liu Yan, et al. Transformer mechanical fault diagnosis method based on symmetrized dot patter and image matching[J]. Transactions of China Electrotechnical Society, 2021, 36(17): 3614-3626.
[10] Xu Yaosong, Bao Liming, Guan Zhifeng, et al. Research on transformer fault diagnosis based on IPPA optimized PNN[J]. Journal of Electronic Measurement and Instrumentation, 2022, 36(10): 138-145.
[11] 张立石, 梁得亮, 刘桦, 等. 基于小波变换与逻辑斯蒂回归的混合式配电变压器故障辨识[J]. 电工技术学报, 2021, 36(增刊2): 467-476.
Zhang Lishi, Liang Deliang, Liu Hua, et al. Fault identification of hybrid distribution transformer based on wavelet transform and logistic regression[J]. Transactions of China Electrotechnical Society, 2021, 36(S2): 467-476.
[12] 葛磊蛟, 廖文龙, 王煜森, 等. 数据不足条件下基于改进自动编码器的变压器故障数据增强方法[J]. 电工技术学报, 2021, 36(增刊1): 84-94.
Ge Leijiao, Liao Wenlong, Wang Yusen, et al. Data augmentation method for transformer fault based on improved auto-encoder under the condition of insufficient data[J]. Transactions of China Electrotechnical Society, 2021, 36(S1): 84-94.
[13] 曲岳晗, 赵洪山, 马利波, 等. 多深度神经网络综合的电力变压器故障识别方法[J]. 中国电机工程学报, 2021, 41(23): 8223-8231.
Qu Yuehan, Zhao Hongshan, Ma Libo, et al. Multi-depth neural network synthesis method for power transformer fault identification[J]. Proceedings of the CSEE, 2021, 41(23): 8223-8231.
[14] 吴杰康, 覃炜梅, 梁浩浩, 等. 基于自适应极限学习机的变压器故障识别方法[J]. 电力自动化设备, 2019, 39(10): 181-186.
Wu Jiekang, Qin Weimei, Liang Haohao, et al. Transformer fault identification method based on self-adaptive extreme learning machine[J]. Electric Power Automation Equipment, 2019, 39(10): 181- 186.
[15] 王艳, 李伟, 赵洪山, 等. 基于油中溶解气体分析的DBN-SSAELM变压器故障诊断方法[J]. 电力系统保护与控制, 2023, 51(4): 32-42.
Wang Yan, Li Wei, Zhao Hongshan, et al. Transformer DGA fault diagnosis method based on DBN-SSAELM[J]. Power System Protection and Control, 2023, 51(4): 32-42.
[16] Lampert C H, Nickisch H, Harmeling S. Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 2009: 951-958.
[17] Lampert C H, Nickisch H, Harmeling S. Attribute-based classification for zero-shot visual object categorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(3): 453-465.
[18] Gong Ping, Wang Xuesong, Cheng Yuhu, et al. Zero-shot classification based on multitask mixed attribute relations and attribute-specific features[J]. IEEE Transactions on Cognitive and Developmental Systems, 2020, 12(1): 73-83.
[19] Shen Fengli, Lu Zheming. A semantic similarity supervised autoencoder for zero-shot learning[J]. IEICE Transactions on Information and Systems, 2020, E103.D(6): 1419-1422.
[20] Xu Juan, Zhou Long, Zhao Weihua, et al. Zero-shot learning for compound fault diagnosis of bearings[J]. Expert Systems with Applications, 2022, 190: 116197.
[21] Gao Yiping, Gao Liang, Li Xinyu, et al. A zero-shot learning method for fault diagnosis under unknown working loads[J]. Journal of Intelligent Manufacturing, 2020, 31(4): 899-909.
[22] Gupta A, Gupta H P, Biswas B, et al. An unseen fault classification approach for smart appliances using ongoing multivariate time series[J]. IEEE Transactions on Industrial Informatics, 2021, 17(6): 3731-3738.
[23] Pan Tongyang, Chen Jinglong, Xie Jingsong, et al. Deep feature generating network: a new method for intelligent fault detection of mechanical systems under class imbalance[J]. IEEE Transactions on Industrial Informatics, 2021, 17(9): 6282-6293.
[24] 李恩文, 王力农, 宋斌, 等. 基于混沌序列的变压器油色谱数据并行聚类分析[J]. 电工技术学报, 2019, 34(24): 5104-5114.
Li Enwen, Wang Linong, Song Bin, et al. Parallel clustering analysis of dissolved gas analysis data based on chaotic sequences[J]. Transactions of China Electrotechnical Society, 2019, 34(24): 5104-5114.
[25] 杨志淳, 沈煜, 杨帆, 等. 考虑多元因素态势演变的配电变压器迁移学习故障诊断模型[J]. 电工技术学报, 2019, 34(7): 1505-1515.
Yang Zhichun, Shen Yu, Yang Fan, et al. A transfer learning fault diagnosis model of distribution transformer considering multi-factor situation evolution[J]. Transactions of China Electrotechnical Society, 2019, 34(7): 1505-1515.
[26] 姜雅男, 于永进, 李长云. 基于改进TOPSIS模型的绝缘纸机-热老化状态评估方法[J]. 电工技术学报, 2022, 37(6): 1572-1582.
Jiang Yanan, Yu Yongjin, Li Changyun. Evaluation method of insulation paper deterioration status with mechanical-thermal synergy based on improved TOPSIS model[J]. Transactions of China Electrotechnical Society, 2022, 37(6): 1572-1582.
[27] 李松, 舒世泰, 郝晓红, 等. 融合文本描述和层次类型的知识表示学习方法[J]. 浙江大学学报(工学版), 2023, 57(5): 911-920.
Li Song, Shu Shitai, Hao Xiaohong, et al. Knowledge representation learning method integrating textual description and hierarchical type[J]. Journal of Zhejiang University(Engineering Science), 2023, 57(5): 911-920.
[28] 席笑文, 郭颖, 宋欣娜, 等. 基于word2vec与LDA主题模型的技术相似性可视化研究[J]. 情报学报, 2021, 40(9): 974-983.
Xi Xiaowen, Guo Ying, Song Xinna, et al. Research on the technical similarity visualization based on word2vec and LDA topic model[J]. Journal of the China Society for Scientific and Technical Information, 2021, 40(9): 974-983.
[29] 石慧. 基于TF-IDF和机器学习的文本向量化与分类研究[D]. 武汉: 华中科技大学, 2022.
[30] 国家电网公司运维检修部. 电网设备状态检测技术应用典型案例: 2011~2013年[M]. 北京: 中国电力出版社, 2014.
[31] 国家电网公司运维检修部. 高压开关设备典型故障案例汇编: 2006~2010年[M]. 北京: 中国电力出版社, 2012.
[32] Ma Xin, Hu Yu, Wang Menghui, et al. Degradation state partition and compound fault diagnosis of rolling bearing based on personalized multilabel learning[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 3520711.
Abstract In actual engineering applications, transformer failure is a small probability event, so there is little fault data and low data quality, and the actual data distribution often exhibits a long tail effect. However, traditional data-driven fault diagnosis methods require a large amount of fault data for sample training, which leads to problems such as low model accuracy and model failure in the actual application of traditional supervised models. To address this type of problem, this article proposes a zero-shot fault diagnosis technology for transformers based on variable weight attribute matrix. The spatial mapping function between known fault attribute matrices and dissolved gas data is learned to achieve accurate identification of unknown faults.
Firstly, an improved efficient channel attention network-stack autoencoder (IECANet-SAE) network is used to construct a data feature extraction network. Among them, convolutional neural networks extract local important information from input data through convolutional operations, while efficient channel attention networks focus on important information by learning attention weights between channels. The use of feature extraction networks solves the problem of quality and quantity of fault sample data, while adaptively extracting key feature information from dissolved gas data. Secondly, based on the description information of transformer faults, a variable weight attribute matrix is constructed using a topic modeling method based on potential Dirichlet distribution. This includes fault type classification, topic word extraction, similarity calculation, and matrix construction. By enhancing the connection between fault labels and fault information through the fault attribute matrix, data sharing between known and unknown class faults can be achieved. Then, the neural network-based Naive Bayes (NNB) method is used to learn the mapping function between each attribute vector in the fault attribute matrix and the important feature information of known class faults in the feature space. Based on the mapping function, the unknown class feature information is mapped to the same feature space to obtain the corresponding attribute vector. Finally, based on Bayesian principle, the maximum likelihood estimation formula is used to obtain the most likely fault type for unknown class faults.
The proposed method was validated using the IEC TC 10 fault database and relevant authoritative literature that has been publicly published. From the accuracy of fault diagnosis results, it can be seen that data-driven fault diagnosis models are difficult to achieve fault diagnosis without sample training, so the diagnostic accuracy of this type of algorithm is 0. On the basis of the transformer fault attribute matrix proposed in this article, zero-shot fault diagnosis is achieved, which has a higher accuracy of up to 0.83 compared to direct attribute prediction (DAP) and indirect attribute prediction (IAP) methods. From the fault diagnosis time, it can be seen that the DAP and IAP methods analyze the original data, so the calculation time is slightly longer due to the large amount of data. The method in this article retains some important features in the data, reducing computational time to a certain extent. The diagnostic time is about 0.18 seconds, which is slightly faster than other methods.
The following conclusions can be drawn through experimental analysis: (1) The use of LDA based topic modeling method effectively enhances the correlation between fault information and fault sample labels, solving the problem of difficult fault diagnosis under the condition of no training samples. (2) Extracting the main features of dissolved gas data through the IECANet-SAE network has better fault feature separation performance compared to other methods, which helps to improve transformer fault diagnosis performance. (3) The NNB algorithm is used to construct the mapping relationship between important feature data and fault attribute matrix, efficiently and accurately identifying unknown fault types. The average accuracy and diagnostic time of the diagnostic results are superior to other methods.
keywords:Zero-shot learning, feature extraction, fault diagnosis, weighted attribute matrix
中图分类号:TM407
DOI: 10.19595/j.cnki.1000-6753.tces.231335
国家重点研发计划“储能与智能电网技术”专项“海上风电并网系统远程监测与故障诊断技术”资助项目(2023YFB2406900)。
收稿日期 2023-08-17
改稿日期 2023-09-07
雷蕾潇 女,1994年生,博士研究生,研究方向为变压器故障诊断。E-mail: leixiaolei@whu.edu.cn
何怡刚 男,1966年生,教授,博士生导师,研究方向为混合信号电路故障诊断、电子设备可靠性和通信信道建模与监测等。E-mail: yghe1221@whu.edu.cn(通信作者)
(编辑 崔文静)