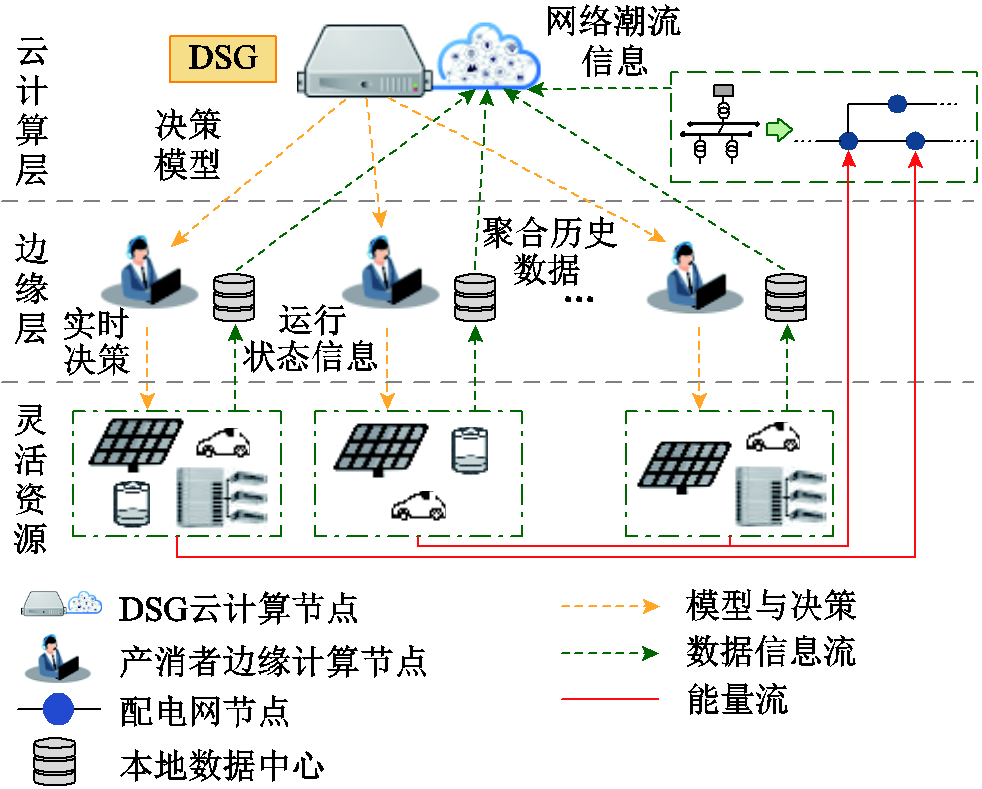
图1 基于边云协同的DSG层级优化调度框架
Fig.1 Framework of edge-cloud collaborative hierarchical optimization scheduling based on DSG
摘要 随着分布式资源配置容量与电力系统灵活性需求的不断提升,通过分布式智能电网(DSG)整合用户侧灵活资源并进行协同调度,对提升分布式电源就地消纳与配电系统实时供需平衡调节能力具有重要意义。考虑到DSG优化过程中的运行经济性、决策生成的实时性与能量网络安全性的需求,该文首先将DSG中灵活资源的优化调度过程描述为一个多智能体优化模型,并构建了基于边云协同的DSG系统层级优化调度框架;然后,建立了考虑产消者差异化特征的异构智能体交互环境模型,为兼顾异构产消者的设备运行要求与DSG系统的整体运行经济性和能量网络安全性,设计了考虑全局-局部奖励相结合的产消者智能体奖励方法;最后针对考虑异构智能体的离线训练任务提出了一种改进多智能体近端策略优化算法,并基于IEEE 33节点系统,利用该文所提方法对DSG系统实时优化调度过程中能量网络安全性、运行经济性与决策时效性的提升作用进行了验证。
关键词:分布式智能电网 灵活资源 边云协同 深度强化学习 网络安全约束
随着能源市场的深化改革与低碳清洁能源的发展,未来配电系统中将出现海量、异质、分散的灵活资源,以及对其进行整合并具备管理自身发电、用电与储电能力的产消者[1]。分布式电源渗透率的不断提升对配电系统的双向潮流适应能力与新能源接纳能力提出了更高要求。同时,产消者兼具电能生产与消费者的双重身份,市场价格引导下的经济用电策略很可能导致产消者在某时段的集中放电或用电,随之造成配电网末端电压升高、反向负荷尖峰,引发网络阻塞等能量网络运行安全问题[2-3]。
为推动清洁能源项目的发展,同时降低集中式清洁能源发电的输配电边际成本,中央财经委员会提出了发展以就地开发就地消纳为核心理念的分布式智能电网(Distributed Smart Grid, DSG)的新要求。相较于微电网与增量配电网,DSG所覆盖的资源调节范围更广、灵活性更高,具有高度的自治、自愈能力与平衡、协同、互动等特征[4]。考虑通过DSG形成产消者-灵活资源的层级协同优化框架,在保证能量网络运行安全的前提下实现对灵活资源的快速调度决策,对提升配电系统的实时供需平衡调节能力与运行安全性具有重要意义。
现有针对提升配电系统运行安全性的灵活资源优化调度研究中,依据能量管理方式主要可以分为集中式直接功率控制与间接功率调整方法两类[5-6]。文献[7]主要针对有源配电网中多线路过载问题提出了基于聚合商优选分级的集中式能量协同管理方法,能够在消除线路过载风险的同时保证系统的运行经济性。文献[8]同样通过综合能源运营商依据网络与灵活资源的运行状态对能量进行统一调度管理,以缓解配电网阻塞问题。直接功率控制的优势在于集中式求解更易实现全局最优,但灵活资源数量众多、分散度较高,高维决策变量易给实时调度中心带来较大的计算负担。因此有学者提出基于多主体间价格信息迭代的间接功率调整方案,通过分布式求解的方式分摊算力,进而提升整体求解效率。文献[9-10]分别针对日前与实时阶段,提出通过调整各交易时段配电网节点边际电价的分布式计算方法引导产消者制定满足配电网安全约束的功率决策。而文献[11-12]同样针对实时阻塞问题,在近实时市场中通过产消者与上层运营商之间的价格信息迭代实现有功功率的调整。基于分布式计算的间接功率调整方法可以有效缓解调度中心的解算压力,但序贯型迭代方法依赖于各主体的顺次优化与主体间的信息传递,除灵活资源与网络潮流约束模型本身的非凸与非线性问题外,参与主体的增多也会造成较大的实时通信开销。
相较于传统数学规划方法,深度强化学习具有较强的自适应学习能力,更易于处理具有较强非线性与随机性的优化问题[13-14]。文献[15-16]基于深度强化学习方法训练适应灵活资源调度的在线决策模型,利用所训练模型由输入到输出的直接映射关系,实现相同场景下的长时间快速重复应用。但随着灵活资源设备数量的增加,单智能体的模型结构在高维决策变量输入时将面临训练速度缓慢的“维数灾”问题。因此文献[17]提出基于集中训练-分布执行框架,以各产消者主体对应于强化学习中的智能体,将规模化灵活资源的协同优化问题描述为一个多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning, MADRL)模型。文献[18-19]则在此框架下进一步提出了基于边云协同的配电网-灵活资源层级调度框架,在执行阶段依托本地局域网络,通过边端决策单元完成灵活资源设备的状态信息采集与决策指令下达,降低实时在线调度过程的通信开销。然而,上述研究均未考虑能量网络安全约束对灵活资源设备运行策略的影响,同时现有研究中多将产消者描述为同构智能体模型,未考虑产消者在灵活资源设备结构与数量等方面的差异化特征,较少对异构产消者智能体的环境模型、奖励设计与训练方法等问题进行讨论。
基于上述问题,为兼顾含分布式电源与灵活资源的DSG系统协同优化调度过程中的决策时效性、经济性与能量网络运行安全性,本文首先基于边云协同思想,构建了考虑能量网络安全约束的灵活资源-产消者-DSG层级优化调度框架;其次,建立了考虑产消者差异化特征的异构智能体交互环境模型,为兼顾异构产消者的设备运行要求与DSG系统的整体运行经济性与能量网络安全性,设计了考虑局部-全局奖励相结合的产消者智能体奖励方法;再次,为适应异构智能体环境的离线训练需求,提出了一种改进多智能体近端策略优化算法;最后,在IEEE 33节点系统中对DSG系统的离线训练过程与在线决策效果进行了分析,验证了本文所提方法对DSG系统实时优化调度过程中能量网络安全性、运行经济性与决策时效性的提升作用。
作为突破传统电力系统自上而下垂直一体化管控的重要手段,DSG提出的目的在于通过数字化技术对含中小型产消者在内的灵活资源进行挖掘、调度与利用,实现分布式发电的就地消纳与本地实时供需平衡。同时考虑到灵活资源的海量、分散特性,在对其进行实时能量管理与协同优化时,需要对含高维决策变量与连续状态空间的灵活资源模型进行处理并求解,集中式优化方法将面临较高的解算压力与通信复杂度。因此,本文在现有研究基础上将基于MADRL方法的边云协同框架扩展至考虑能量网络约束的灵活资源协同优化调度问题中,构建了考虑灵活资源-产消者-DSG的层级优化调度框架,如图1所示。在底层资源配置上,考虑以光伏发电(Photovoltaic, PV)作为分布式电源,以电动汽车(Electric Vehicle, EV)、建筑物暖通空调(Heating Ventilation Air Conditioning, HVAC)与储能(Energy Storage System, ESS)作为可调节灵活资源。
图1 基于边云协同的DSG层级优化调度框架
Fig.1 Framework of edge-cloud collaborative hierarchical optimization scheduling based on DSG
在整体调度控制框架中,由DSG代表群体产消者利益并参与能量市场交易,同时作为底层灵活资源与上级电网之间的沟通桥梁,其优化调度目标为在保证配电网运行安全性的前提下使产消者收益最大化。同时,考虑将实际掌控并拥有灵活资源设备的产消者对应于强化学习中的智能体,基于MADRL方法将DSG系统协同优化问题描述为一个多智能体协同训练任务,并考虑在DSG系统中设置包含不同类型与数量灵活资源的异构产消者智能体。框架顶层以DSG作为云端计算中心,主要负责为多智能体系统在模型训练阶段提供包含设备运行状态、配电网潮流信息等历史数据与全局状态信息的集中式交互环境,各智能体则依据环境提供的观测信息与奖励探索最优策略,同时在训练结束后负责将模型分割并抄送至由产消者能量管理单元形成的边缘侧计算中心。
在离线训练阶段:首先由位于边缘侧的产消者服务器对其下各设备的历史时序运行状态数据抄送至DSG云端服务器;然后云端服务器对来自多方主体的数据信息进行整合并作为模型的训练数据集,在考虑网络运行安全约束的前提下,以各产消者用电成本最低为目标对协同优化调度模型进行训练;最后,训练完成后保存并抄送产消者智能体策略网络模型至边缘侧服务器。
在实时调度阶段:产消者能量管理单元通过本地局域网络获取其下灵活资源设备的实时运行状态信息,将维度与结构保持与训练过程一致的状态信息输入本地决策模型,通过策略网络快速映射至实时调度决策,实现相同场景下的重复多次在线应用。
基于前述所建立的DSG系统层级优化调度框架,本节构建了云端集中训练过程中的产消者智能体交互环境模型。针对DSG系统优化调度中的能量网络运行安全问题,考虑选取线路传输容量与节点电压约束作为能量网络运行安全约束条件。
考虑到现实生产场景中产消者所拥有并掌控的灵活资源设备在类型结构与数量方面的差异性,基于产消者灵活资源设备的运行特性构建了异构智能体交互环境模型,并对异构智能体的局部动作、观测空间进行了描述。同时提出通过全局-局部奖励相结合的奖励设计方法引导智能体进行策略更新,以保证异构智能体在追求自身奖励最大化的同时兼顾DSG系统的整体优化与协同训练目标。
在MADRL的训练过程中,需要异构智能体与环境不断交互并进行策略更新。因此本节内容主要基于DSG系统中底层灵活资源设备的运行特性,对马尔科夫决策过程中各类灵活资源设备的局部动作与观测空间进行了描述。
2.1.1 EV设备特性与局部环境模型
对于具有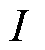 辆可调度EV的产消者
辆可调度EV的产消者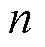 而言,在对其建立局部交互环境模型时,除EV充电过程中的自身运行特性外,还需要重点关注调度周期内EV的入网时间
而言,在对其建立局部交互环境模型时,除EV充电过程中的自身运行特性外,还需要重点关注调度周期内EV的入网时间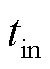 、离网时间
、离网时间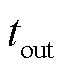 与用户能量需求及用户期望充电容量达成率。
与用户能量需求及用户期望充电容量达成率。
因此,在本文研究中考虑由外生数据驱动获取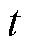 时刻在网EV集合
时刻在网EV集合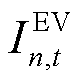 ,同时,在中剔除已满足能量需求的车辆,形成时刻待充电的
,同时,在中剔除已满足能量需求的车辆,形成时刻待充电的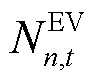 辆EV集合
辆EV集合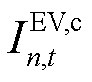 ,并通过缩放时刻EV的功率可行域边界构建其局部动作空间
,并通过缩放时刻EV的功率可行域边界构建其局部动作空间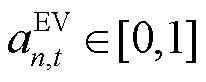 ,有
,有
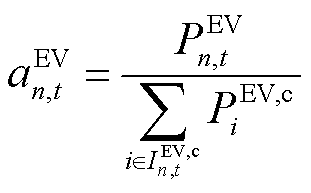 (1)
(1)
式中,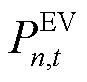 为智能体在时刻的所决策的EV总体充电功率,
为智能体在时刻的所决策的EV总体充电功率,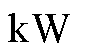 ;
;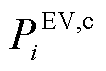 为第
为第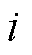 辆EV的最大充电功率,。
辆EV的最大充电功率,。
在收到智能体在时刻的策略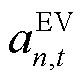 后,由EV设备局部环境将中EV的SOC状态
后,由EV设备局部环境将中EV的SOC状态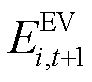 与剩余能量需求
与剩余能量需求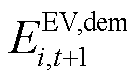 更新至
更新至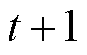 时刻,有
时刻,有
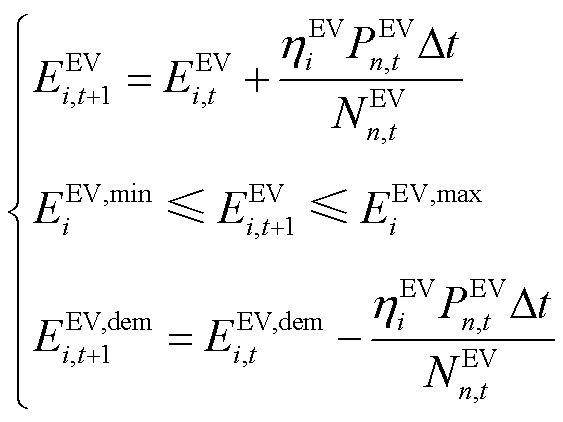 (2)
(2)
式中,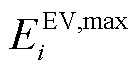 、
、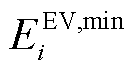 分别为EV的容量上、下界,
分别为EV的容量上、下界, ;
;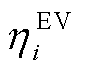 为EV充电过程中的电能转换效率;Dt为DSG系统调度区间。
为EV充电过程中的电能转换效率;Dt为DSG系统调度区间。
同时,依据车辆入/离网信息及时刻各车辆的剩余能量需求,将待充电EV集合更新为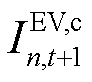 。此外,如果中包含在时刻离网且仍有剩余能量需求(
。此外,如果中包含在时刻离网且仍有剩余能量需求(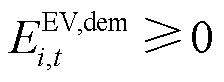 , t+1=tout)的
, t+1=tout)的![]() 辆EV设备,则对局部观测空间中的充电需求未响应容量
辆EV设备,则对局部观测空间中的充电需求未响应容量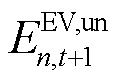 进行更新,有
进行更新,有
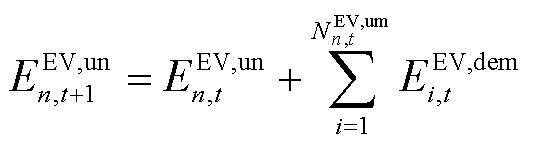 (3)
(3)
因此,对于具有辆可调度EV的产消者智能体而言,其局部观测空间可以表示为
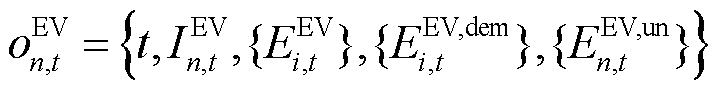 (4)
(4)
2.1.2 HVAC特性与局部环境模型
作为需求侧重要的灵活性资源,智能楼宇可以通过对HVAC的制冷器出风温度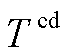 与各区域的冷风流量
与各区域的冷风流量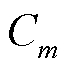 (
(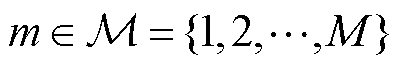 )进行控制,在保证用户室内环境温度舒适度的前提下实现HVAC功率的实时动态调整[20]。
)进行控制,在保证用户室内环境温度舒适度的前提下实现HVAC功率的实时动态调整[20]。
因此,对于产消者中第j栋具有M个独立温控区域的智能楼宇HVAC而言,其局部动作空间可以表示为
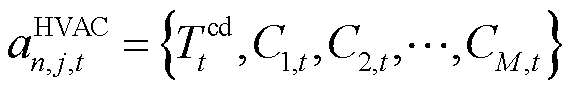 (5)
(5)
而该HVAC的整体功率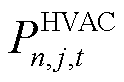 、第
、第 区域送冷量
区域送冷量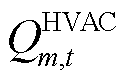 与决策变量之间的关系可表示为
与决策变量之间的关系可表示为
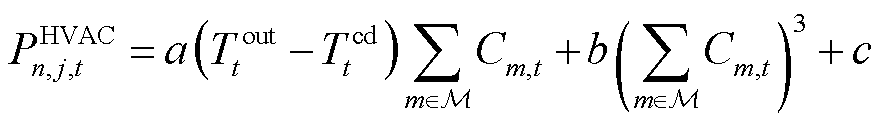 (6)
(6)
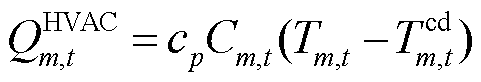 (7)
(7)
式(7)中第一项为HVAC制冷器功率,后两项为各温控区域可变风量送风扇功率;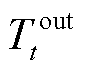 为时刻室外温度,℃;
为时刻室外温度,℃;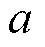 、
、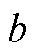 、
、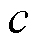 均为HVAC设备运行参数;
均为HVAC设备运行参数;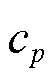 为空气比定压热容,
为空气比定压热容,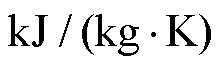 ;
;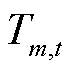 为第区域在时刻的室内温度,℃。本文研究中参考文献[21]中方法,利用带外生变量的自回归模型对室内温度的动态变化过程进行描述为
为第区域在时刻的室内温度,℃。本文研究中参考文献[21]中方法,利用带外生变量的自回归模型对室内温度的动态变化过程进行描述为
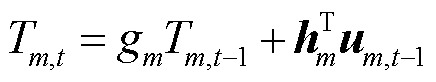 (8)
(8)
式中,um,t为包含外生变量的输入向量,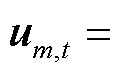
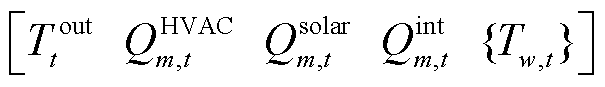 ,其中
,其中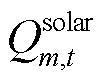 与
与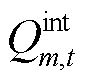 分别为第区域t时刻的太阳辐射热增益与内部热增益,
分别为第区域t时刻的太阳辐射热增益与内部热增益,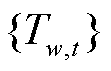 为t时刻除第区域外其他区域温度集合(
为t时刻除第区域外其他区域温度集合(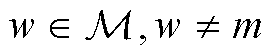 );
);![]() 和
和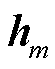 为自回归模型的内生参数。由此可得产消者中HVAC设备局部观测空间
为自回归模型的内生参数。由此可得产消者中HVAC设备局部观测空间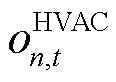 为
为
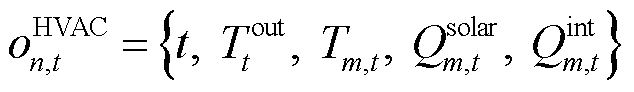 (9)
(9)
2.1.3 ESS设备特性与局部环境模型
ESS可以对系统的实时功率平衡起到重要的调节作用。因此对于ESS设备而言,其在时刻的充放电功率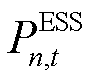 即为智能体所输出的局部动作决策:
即为智能体所输出的局部动作决策: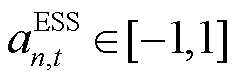 ,其中,
,其中,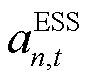 为正表示ESS充电,为负则表示ESS处于放电状态。
为正表示ESS充电,为负则表示ESS处于放电状态。
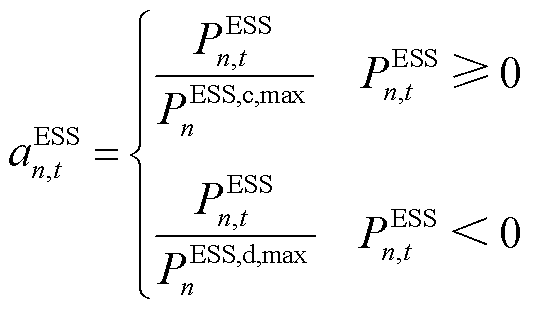 (10)
(10)
式中,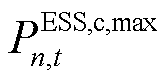 、
、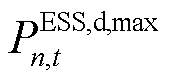 分别为智能体中ESS设备的充、放电功率边界,。而ESS在运行中的局部观测空间
分别为智能体中ESS设备的充、放电功率边界,。而ESS在运行中的局部观测空间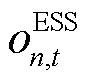 则应包括当前时刻与荷电状态
则应包括当前时刻与荷电状态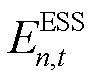 :
: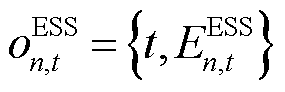 ,其中受ESS设备物理容量限制,智能体与环境交互并将时刻状态更新至
,其中受ESS设备物理容量限制,智能体与环境交互并将时刻状态更新至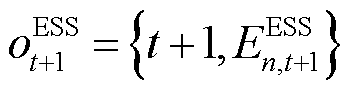 ,有
,有
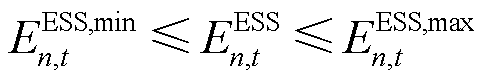 (11)
(11)
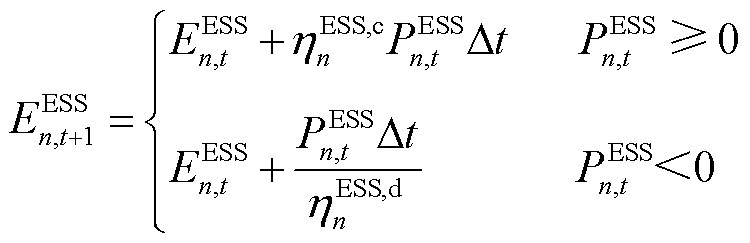 (12)
(12)
式中,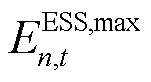 、
、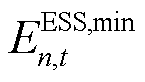 分别为ESS的容量上、下界,;
分别为ESS的容量上、下界,;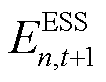 为时刻ESS的荷电状态,;
为时刻ESS的荷电状态,;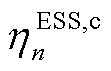 、
、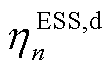 分别为ESS充、放电过程中的电能转换效率。
分别为ESS充、放电过程中的电能转换效率。
为便于对各产消者灵活资源构成进行通用化描述,引入0-1变量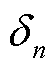 以表示灵活资源的存在性。同时,为保证DSG中分布式新能源的就地消纳率,考虑将分布式PV的历史出力情况
以表示灵活资源的存在性。同时,为保证DSG中分布式新能源的就地消纳率,考虑将分布式PV的历史出力情况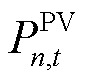 通过外生数据的形式将环境观测量
通过外生数据的形式将环境观测量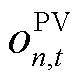 添加至产消者的观测空间中,因此,时刻智能体在配电网节点中的总功率需求可以表示为
添加至产消者的观测空间中,因此,时刻智能体在配电网节点中的总功率需求可以表示为
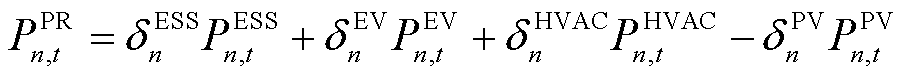 (13)
(13)
同时,基于前述所建立的灵活资源设备局部交互环境模型,通过对灵活资源设备的局部观测与动作空间的拼接与封装即可生成各异构产消者智能体的输入观测空间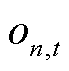 与输出动作空间
与输出动作空间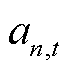 ,有
,有
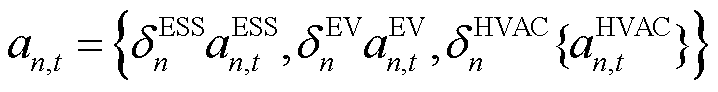 (14)
(14)
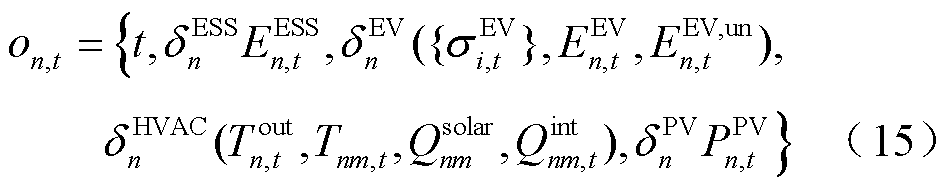
在强化学习的标准范式中,通常对优化问题的目标函数与部分约束条件以奖励的形式进行转换,并驱动智能体向累计折扣奖励最大化的方向不断学习[22]。各异构智能体的局部奖励函数与产消者的设备结构相关,需要重点关注HVAC和EV用户的满意度评价与ESS设备的运行成本。
针对EV与HVAC用户满意度的需求未达成部分,考虑将其以罚函数的形式向智能体添加奖励修正项。选取时刻EV设备局部观测空间中充电需求未响应容量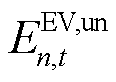 与HVAC设备局部观测空间中区域室温作为用户满意度评价指标。在交互环境为智能体更新观测信息的同时,向智能体提供数值为负的奖励修正项
与HVAC设备局部观测空间中区域室温作为用户满意度评价指标。在交互环境为智能体更新观测信息的同时,向智能体提供数值为负的奖励修正项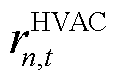 与
与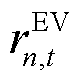 ,有
,有
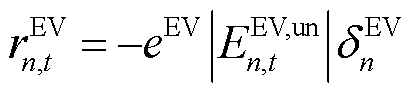 (16)
(16)
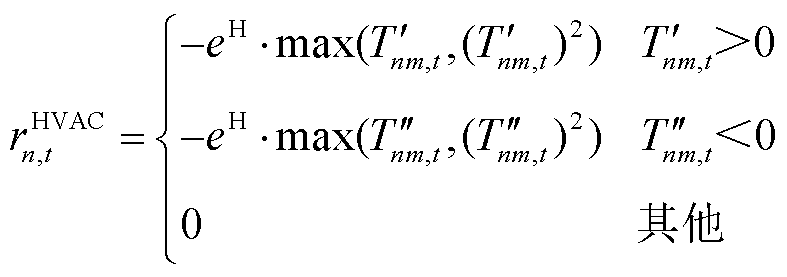 (17)
(17)
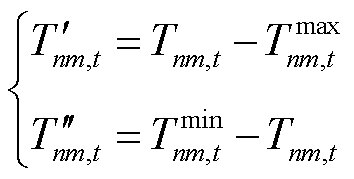 (18)
(18)
式中,![]() 与
与![]() 分别为EV用户充电需求未响应容量与超出HVAC用户舒适温度需求部分的奖励修正系数;
分别为EV用户充电需求未响应容量与超出HVAC用户舒适温度需求部分的奖励修正系数;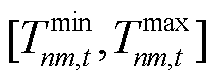 为HVAC用户的舒适温度区间;
为HVAC用户的舒适温度区间;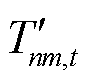 与
与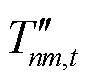 为引入的过程变量,用以标记室内温度与用户舒适温度间的差值。
为引入的过程变量,用以标记室内温度与用户舒适温度间的差值。
同时,考虑到含ESS设备的产消者在自身能量平衡调节中的电池损耗与维护折旧成本,基于等效成本系数对ESS运行成本进行计算[23],并向含ESS设备的产消者添加局部奖励函数,有
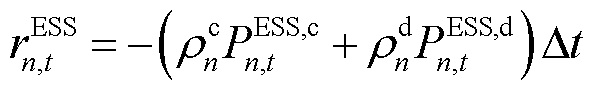 (19)
(19)
式中,![]() 与
与![]() 分别为产消者内ESS设备的充电与放电运行成本系数;
分别为产消者内ESS设备的充电与放电运行成本系数;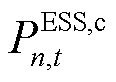 与
与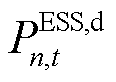 分别为ESS设备的充电与放电功率(
分别为ESS设备的充电与放电功率(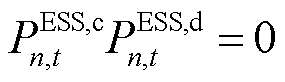 ),。因此,各异构智能体的局部奖励函数
),。因此,各异构智能体的局部奖励函数![]() 可以表示为
可以表示为
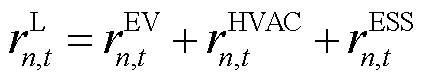 (20)
(20)
在本文研究中,考虑DSG系统的整体协同优化目标为在保证能量网络运行安全的前提下,最小化系统整体用电成本。同时基于异构智能体交互环境模型中对各异构智能体动作决策至各产消者在能量网络节点中总功率需求映射的描述,考虑能量网络安全约束的DSG系统整体优化目标表示为
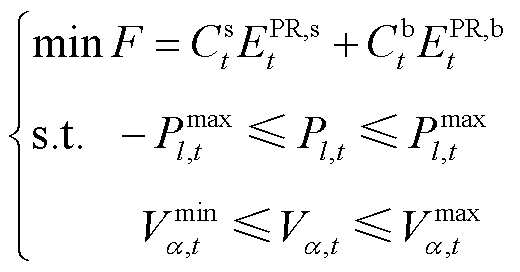 (21)
(21)
式中,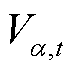 为时刻配电网节点
为时刻配电网节点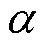 的电压;
的电压;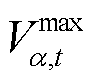 与
与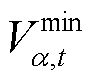 分别为节点的电压上限与下限;
分别为节点的电压上限与下限;![]() 为时刻配电网线路
为时刻配电网线路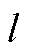 的传输功率;
的传输功率;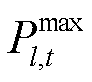 为线路的传输功率上限;
为线路的传输功率上限;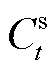 与
与![]() 分别为时刻的配电网售电价格与上网电价,元/();
分别为时刻的配电网售电价格与上网电价,元/();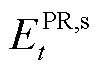 与
与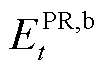 分别为时刻DSG系统的总体购入能量与总上网容量,,在不考虑产消者间能量交易行为的前提下,可以表示为
分别为时刻DSG系统的总体购入能量与总上网容量,,在不考虑产消者间能量交易行为的前提下,可以表示为
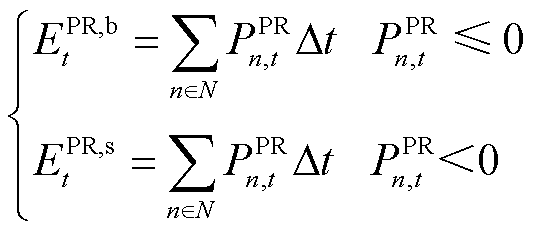 (22)
(22)
除节点电压约束(式(21))与线路传输容量约束外,还需要考虑配电网系统的节点功率平衡[24],系统节点功率平衡方程为
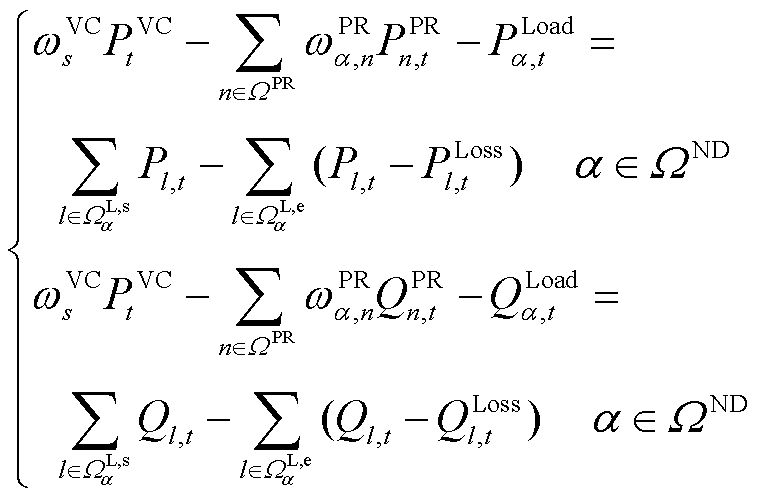 (23)
(23)
式中, 、
、 、
、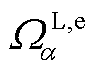 与
与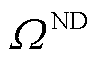 分别为所有产消者、以节点为首端的线路、以节点为末端的线路与配电网中所有节点的集合;
分别为所有产消者、以节点为首端的线路、以节点为末端的线路与配电网中所有节点的集合;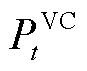 与
与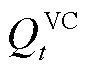 分别为变电站接入的有功功率与无功功率;
分别为变电站接入的有功功率与无功功率;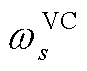 与
与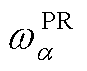 分别为网络拓扑关联矩阵的相应元素,用以标识配电网变电站与产消者的接入节点位置,即当产消者在节点接入时=1,否则为0;
分别为网络拓扑关联矩阵的相应元素,用以标识配电网变电站与产消者的接入节点位置,即当产消者在节点接入时=1,否则为0;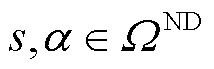 ;
;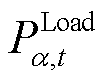 与
与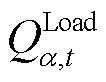 分别为接入节点的固定负荷的有功功率与无功功率;
分别为接入节点的固定负荷的有功功率与无功功率;![]() 与
与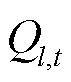 分别为线路的有功功率与无功功率;
分别为线路的有功功率与无功功率;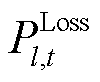 与
与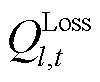 分别为线路
分别为线路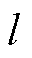 的有功网损和无功网损。
的有功网损和无功网损。
同时考虑将DSG系统整体优化目标以奖励函数与奖励修正项的形式转换为MADRL训练过程中各异构智能体的全局奖励,以DSG系统整体收益,即负的用电成本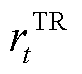 为系统用电成本奖励;而对于节点电压约束与线路传输容量约束,与局部奖励中用户满意度约束的方式相同,以罚函数的形式向全部智能体添加奖励修正项
为系统用电成本奖励;而对于节点电压约束与线路传输容量约束,与局部奖励中用户满意度约束的方式相同,以罚函数的形式向全部智能体添加奖励修正项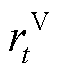 与
与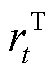 ,有
,有
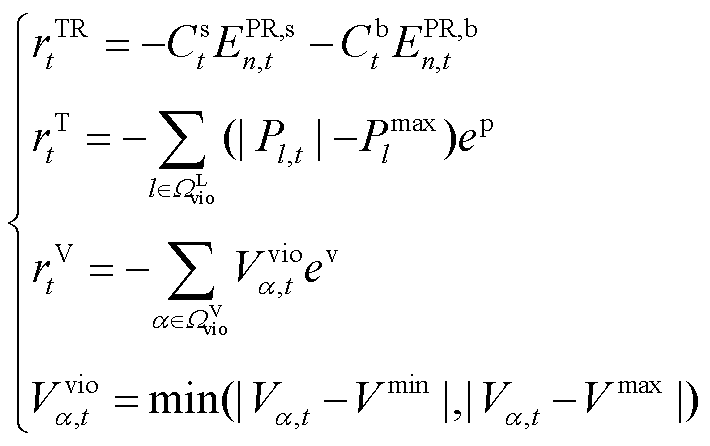 (24)
(24)
式中,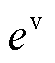 与
与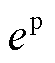 分别为限制节点电压范围与线路传输容量的奖励修正系数;
分别为限制节点电压范围与线路传输容量的奖励修正系数;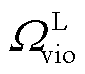 为配电网中出现传输功率越限的线路集合;
为配电网中出现传输功率越限的线路集合;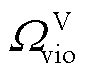 为配电网中出现电压越限的节点集合。因此,交互环境所提供的全局奖励
为配电网中出现电压越限的节点集合。因此,交互环境所提供的全局奖励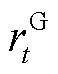 与异构产消者智能体最终获得的奖励
与异构产消者智能体最终获得的奖励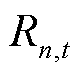 可以表示为
可以表示为
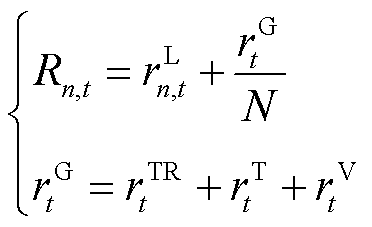 (25)
(25)
在DSG系统层级优化调度框架的离线训练阶段,需要对含高维连续动作与状态空间的模型进行处理。在现有MADRL方法中,多智能体近端策略优化(Multi-Agent Proximal Policy Optimization, MAPPO)算法具有较强的连续状态空间处理能力,且因其具有较强的环境适应性与训练稳定性而被应用于众多领域的研究任务中[25]。因此本文研究中考虑基于MAPPO算法对计及能量网络运行安全的DSG系统协同优化任务进行离线训练。
现有MAPPO算法基于执行器-评判器(Actor-Critic)架构,主要应用于同构的多智能体协同训练场景。在奖励机制与网络结构设计上,需要全部智能体共享一个全局的奖励函数,并通过训练一个全局的Critic网络来集中学习全部环境状态到所有智能体动作间的映射关系。基于全局Critic网络进行训练的优势在于可以消除在同步策略更新中,单一智能体策略改变所带来的环境不稳定。但全局Critic网络的输入维度也会随着智能体数量的增加而呈指数增长[26],在共享全局奖励下Critic网络只能对全部智能体的联合状态-动作对的相对优势进行评估,智能体无法判断自身观测-动作对系统整体的影响,易导致智能体无效探索的增加,进而引发信用分配问题[27]。
因此,本文在考虑能量网络安全约束的DSG系统协同优化场景下对MAPPO算法进行了适用性改进。考虑到在产消者异构环境下,各智能体Actor网络在输入观测空间与输出动作空间的维度上存在差异,为在适应异构性需求的前提下降低全局Critic网络的训练复杂度,对各智能体建立了独立的Actor与Critic网络。同时,为保证独立网络下的改进MAPPO算法收敛性,引入了智能体策略随机顺序更新方法[28-29]。
具体而言,在本文所提出的改进MAPPO算法中,需要在训练开始阶段,对各智能体的策略网络参数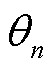 与价值网络参数
与价值网络参数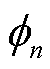 进行初始化,并设置相应的折扣奖励因子
进行初始化,并设置相应的折扣奖励因子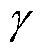 、网络学习率
、网络学习率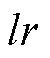 代理目标剪裁比
代理目标剪裁比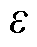 及经验回放池容量
及经验回放池容量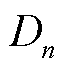 等模型训练超参数。各智能体利用初始策略
等模型训练超参数。各智能体利用初始策略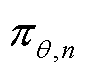 与环境进行交互。同时在训练开始阶段,对各智能体进行编码,并在每一次策略迭代中都利用编码随机生成一个更新顺序。
与环境进行交互。同时在训练开始阶段,对各智能体进行编码,并在每一次策略迭代中都利用编码随机生成一个更新顺序。
按照生成的随机顺序对智能体进行顺序更新,在对当前智能体的策略进行更新时,仅智能体与环境交互并获得新的观测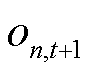 与奖励,同时将每一步与环境交互所产生的轨迹
与奖励,同时将每一步与环境交互所产生的轨迹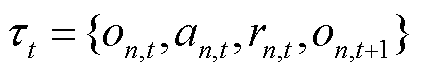 存入经验回放池中,联合策略空间
存入经验回放池中,联合策略空间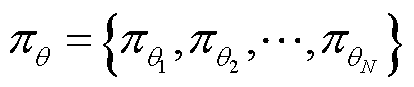 中其余智能体固定当前策略不变。当轨迹经验满足经验回放池大小时,将经验回放池中的轨迹输入智能体对应的价值网络中,并计算其广义优势估计函数
中其余智能体固定当前策略不变。当轨迹经验满足经验回放池大小时,将经验回放池中的轨迹输入智能体对应的价值网络中,并计算其广义优势估计函数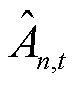 ,有
,有
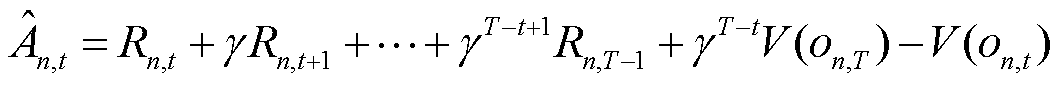 (26)
(26)
在前述建立的异构智能体交互环境模型中,奖励函数中包含了局部奖励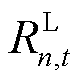 与全局奖励
与全局奖励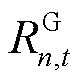 两部分,同时由于在智能体与环境进行交互过程中,联合策略空间中其余智能体策略固定不变。因此通过优势函数
两部分,同时由于在智能体与环境进行交互过程中,联合策略空间中其余智能体策略固定不变。因此通过优势函数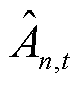 的计算,智能体既可以由中的局部奖励的变化获取设备运行功率控制策略的相对优势,也可以基于全局奖励,对在考虑其余智能体策略的情况下自身策略的改变对全局回报的影响进行准确评估。
的计算,智能体既可以由中的局部奖励的变化获取设备运行功率控制策略的相对优势,也可以基于全局奖励,对在考虑其余智能体策略的情况下自身策略的改变对全局回报的影响进行准确评估。
同时利用Adam优化器采用梯度上升的方式对策略网络参数进行更新。在限制新旧策略间差异的同时为使策略更具探索性,本文算法中采用剪裁代理目标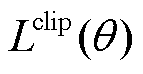 与策略熵共同组成策略网络更新目标
与策略熵共同组成策略网络更新目标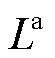 ,有
,有
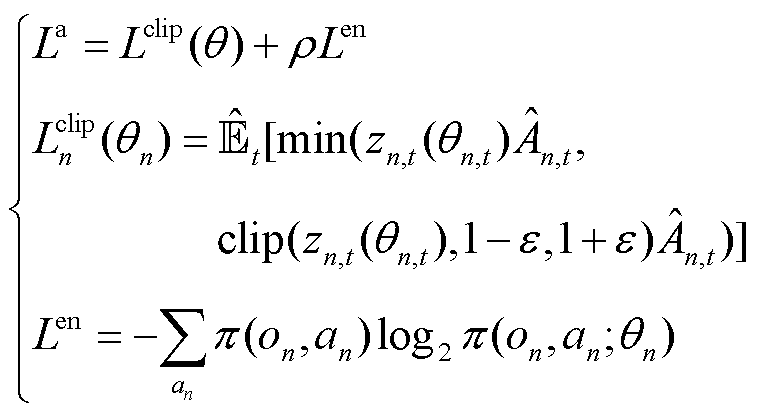 (27)
(27)
式中,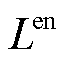 为策略
为策略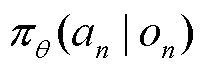 的熵正则化项;
的熵正则化项;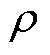 为熵正则化项权重;
为熵正则化项权重;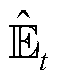 为t时刻的期望估计;clip为裁剪限制;
为t时刻的期望估计;clip为裁剪限制;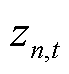 为将当前经验轨迹中所采集到的观测
为将当前经验轨迹中所采集到的观测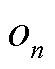 分别输入以
分别输入以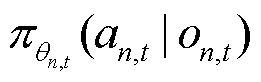 为当前策略和以
为当前策略和以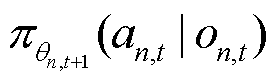 为目标策略的策略网络中,并利用观测-动作对计算当前策略相对于目标策略的重要性采样比率,有
为目标策略的策略网络中,并利用观测-动作对计算当前策略相对于目标策略的重要性采样比率,有
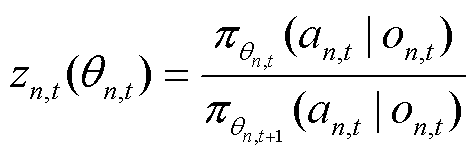 (28)
(28)
策略网络参数更新完成后,以状态价值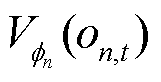 的方均误差作为损失函数,并利用梯度下降更新价值网络参数。
的方均误差作为损失函数,并利用梯度下降更新价值网络参数。
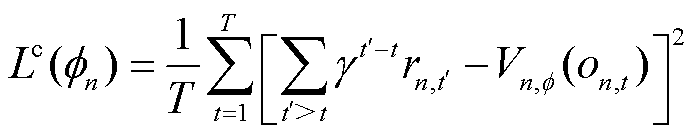 (29)
(29)
在完成当前选定智能体的策略更新后,按照本轮迭代更新初始选定的策略更新顺序,重复式(26)~式(29)的智能体策略更新过程,对随机顺序中下一个智能体进行策略更新。
在智能体策略的顺序更新中,由于每次迭代只有一个智能体与环境交互并进行策略更新策略,联合策略空间中其余智能体的策略保持不变,因此价值网络可以通过奖励变化明确的计算出每个智能体的局部贡献,当前智能体可以在考虑其余智能体策略固定不变的情况下更新至局部最优策略,保证了联合策略的单调改进性与全局优势 的累加性。
的累加性。
同时,随机训练总回合数的增加,采用随机的更新顺序可以保证每个可能的智能体排列顺序逐渐稳定在一个正的被抽样概率上,以保证不同智能体具有较为平等的优先更新机会,进而保证系统整体的联合策略能够近似收敛到Nash均衡点[29]。改进MAPPO算法伪代码如附录所示。在离线训练完成后将抄送模型至各边端服务器,而各产消者智能体将依据灵活资源设备的实时运行状态信息及本地策略网络制定实时功率调度决策。
为验证本文所提方法在考虑能量网络约束的DSG系统协同优化调度问题中的有效性,考虑基于IEEE 33节点系统进行了仿真分析。参考OPSD开源数据集[30]中灵活资源设备与分布式发电信息作为训练数据集,同时考虑实时运行中的功率平衡需求,以24 h为一个调度周期,设置每15 min为一个调度区间,电价信息如附图1所示,灵活资源设备运行参数见附表1。
考虑设置配电网系统整体有功负荷水平维持在3 MW左右,设置参与DSG协同优化调度的产消者数量为17,包含共计565辆EV与21组具有相同温控区域结构的智能楼宇五区温控HVAC设备(M=5);设置配电网系统电压安全范围为[0.95(pu), 1.05(pu)];线路0-23的最大安全传输功率为2.5 MW;线路24-31的最大安全传输功率为0.45 MW。算例仿真环境为8-core 3.80 GHz Intel(R) i7-10700K处理器,64 GB RAM,软件配置为Python3.8.16,PyTorch1.10.0,同时通过在异构智能体的封装环境中调用Panda Power2.11.1软件包对配电网潮流进行计算。
本文首先对基于边云协同的DSG系统离线训练过程进行了分析,为保证模型的训练效果,利用随机搜索方法[31]对控制网络模型的超参数组合进行选取,超参数随机搜索空间与随机搜索过程如附图2、附图3所示,最终选定的离线训练超参数见附表2。同时为验证本文所提出的全局-局部奖励设计方法与改进MAPPO算法的有效性,设置参照训练方案如下。
方案一:利用本文所提改进MAPPO算法进行离线训练,同时考虑能量网络安全约束对DSG系统整体优化调度过程的影响。
方案二:同样利用改进MAPPO算法进行训练,但不考虑能量网络安全约束,仅考虑DSG系统的整体运行经济性。
方案三:利用MAPPO算法基于全局Critic网络进行训练,并以![]() 作为共享的全局奖励函数,各智能体Actor网络相互独立且无参数共享。
作为共享的全局奖励函数,各智能体Actor网络相互独立且无参数共享。
方案四:作为算法参照,考虑将优势执行器-评判器(Advantage Actor-Critic, A2C)算法扩展至多智能体系统中,基于独立网络与同步策略更新对各异构智能体系统进行训练。
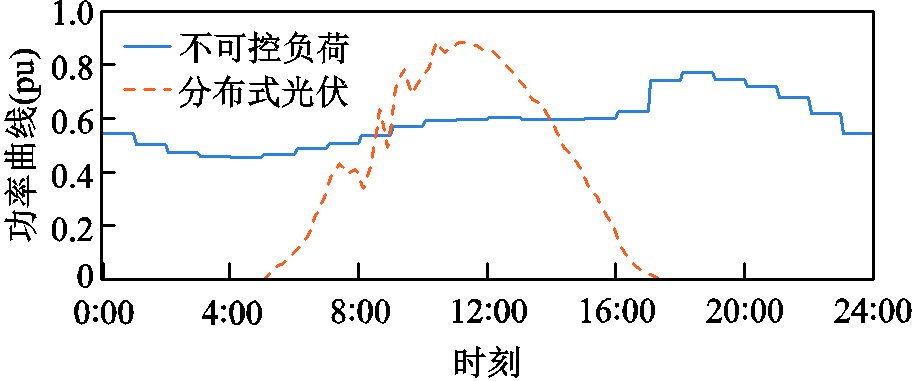
上述方案均选取每回合训练的平均累计折扣奖励值作为算法收敛性的评估指标,各方案下DSG系统的离线训练过程如图2所示。
由图2可知,在400个回合的训练中,基于MAPPO算法的三种训练方案都能收敛到一个较为稳定的结果,其中方案一中的全局-局部奖励相结合的奖励设计方式与智能体策略的随机顺序更新方法有效地保证了训练过程中的环境状态稳定性,也验证了本文所提改进MAPPO算法的收敛性。同时,对各方案的每回合平均训练时长与算法收敛时所需的训练回合数进行对比,结果见表1。
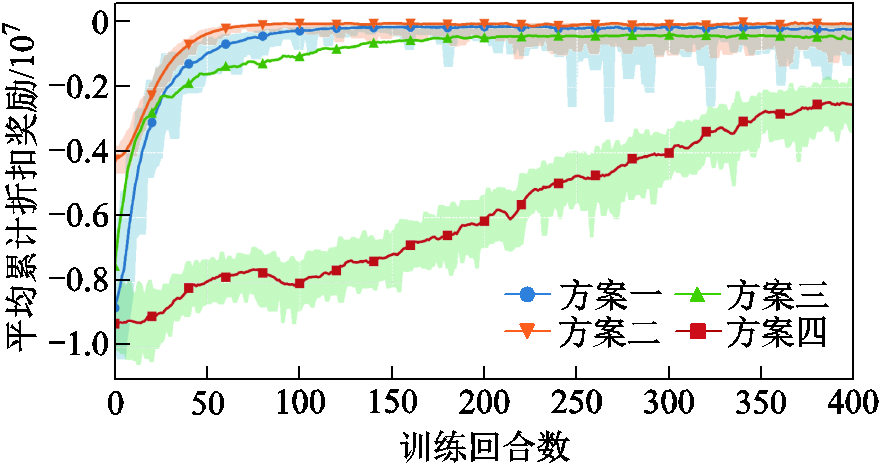
图2 各方案下DSG系统离线训练过程
Fig.2 DSG system offline training process under different solutions
表1 各方案训练时长与训练回合数对比
Tab.1 Comparison of training time and number of training rounds under different solutions

方案收敛所需回合数每回合平均训练时长/s 一14092.62 二9078.35 三20088.59 四—81.71
首先对比训练方案一与训练方案二。由于训练方案一中需要考虑能量网络运行安全性对DSG系统优化调度过程的影响,因而训练方案一在全局策略寻优过程中所需的训练回合数更多,同时训练方案二无需在交互环境中对网络潮流进行计算,因而每回合的平均训练时间更短。
其次,在本文所提出的改进MAPPO算法中,策略随机顺序更新方法与全局-局部奖励机制可以提升智能体在联合策略下对自身策略优势的评估准确性,能够在一定程度上避免智能体策略的无效探索与信用分配问题。因而相比于训练方案三,基于改进MAPPO算法的训练方案一所需的收敛回合数更少。但由于在智能体策略的随机顺序更新中,需要各异构智能体与环境依次进行交互,因而增加了网络潮流的计算负担,虽然独立价值网络的设计可以降低状态空间的输入维度并对价值网络训练效率起到一定的提升作用,但在最终的每回合平均训练时间上训练方案一略长于训练方案三。
最后,在完全独立的多智能体系统训练中,环境状态的非稳定性将导致训练效率的下降,因而训练方案四未能在400个训练回合中达到收敛。同时由于缺少剪裁代理目标等限制智能体策略更新幅度的方法导致策略波动性较大。因此,综合训练时间与收敛回合数对离线训练效率进行考虑,本文所提改进MAPPO算法在异构产消者智能体的离线训练任务中更具优势。
为验证本文所提DSG系统协同优化调度方法对能量网络运行安全性的提升作用,在实时调度阶段应用训练方案一与方案二中所得离线训练模型对DSG系统进行在线决策,并对DSG系统的整体运行经济性、能量网络安全性与灵活资源设备的调度策略进行分析。
实时调度当日系统固定负荷与PV出力情况如附图4所示,两种训练方案下各时段系统节点电压与线路传输功率情况如附图5~附图8所示。系统整体运行成本与能量网络运行安全情况见表2。对表2进行分析可知,考虑能量网络运行安全性的DSG系统实时优化调度方法相较于方案二中的经济优化调度模式在系统整体运行成本上提高了8.73%。同时对比能量网络运行安全情况可知,本文所提方法能够有效提升DSG系统的能量网络运行安全性。
表2 系统整体运行成本与能量网络运行安全情况
Tab.2 Comparison of overall system operating cost and energy network operating security status under different solutions
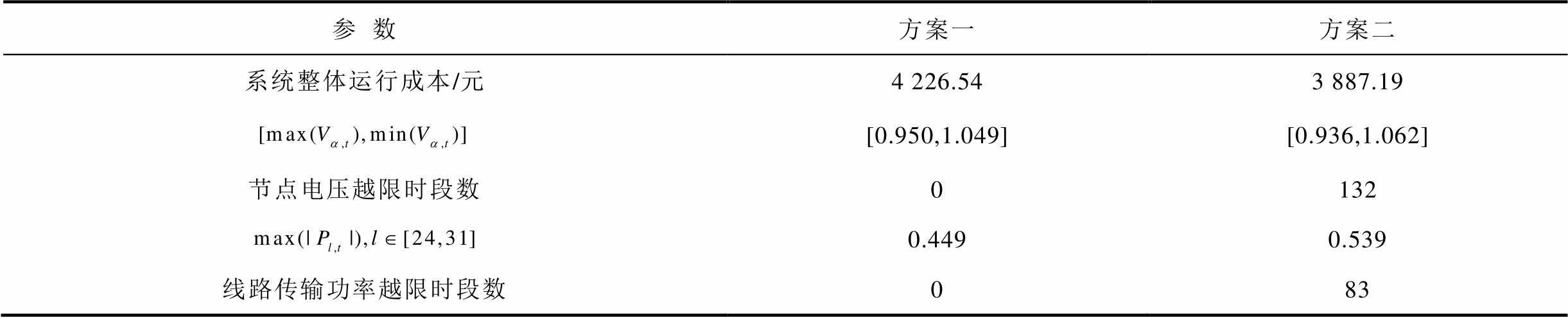
参数方案一方案二 系统整体运行成本/元4 226.543 887.19 [0.950,1.049][0.936,1.062] 节点电压越限时段数0132 0.4490.539 线路传输功率越限时段数083
考虑到在配电系统中,任意节点的功率变化都会引起整个系统网络潮流与电压分布情况的改变。为便于比对分析,选取33节点系统中最长支路末端的17号节点与潮流承载能力较弱的24-31号线路,对DSG系统的局部安全性与灵活资源设备的实时能量管理策略进行分析。首先对比考虑能量网络运行安全约束前后节点17与线路24的各时段电压与传输功率情况,如图3所示。
通过对图3分析可知,由于在DSG系统中配置有相对充裕的PV资源,因而在午间PV出力较高时段易出现反向负荷尖峰问题。同时相较于仅考虑DSG系统运行经济性的优化调度方案,方案一中线路24的传输功率与节点17的电压值均能保持在安全限额范围内,也验证了如式(24)所示的能量网络安全约束奖励修正方法能够对DSG系统协同调度过程中的电压与线路传输功率越限问题起到较好的抑制作用。同时考虑对DSG系统实时优化调度中灵活资源设备的局部能量管理策略进行分析,以24-31号线路为例,分布于该支路上的灵活资源设备聚合功率情况如图4所示。
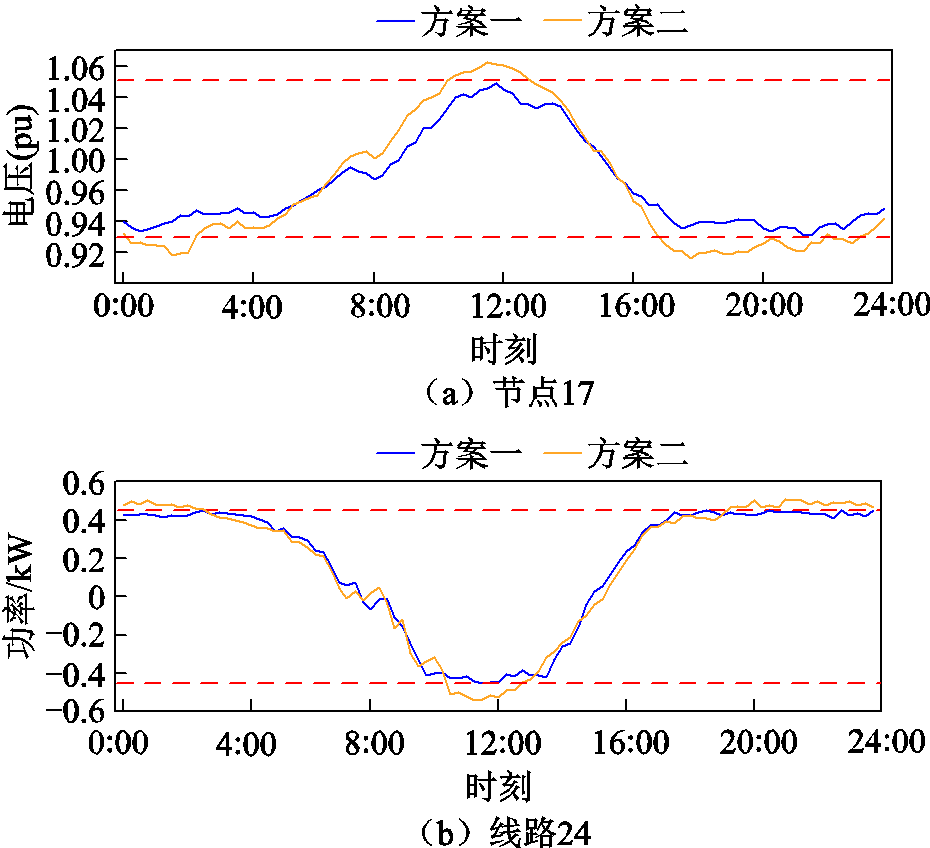
图3 两种方案下节点17的实时电压与线路24的实时传输功率情况
Fig.3 Real-time voltage of node 17 and real-time transmission power of line 24 under two solutions
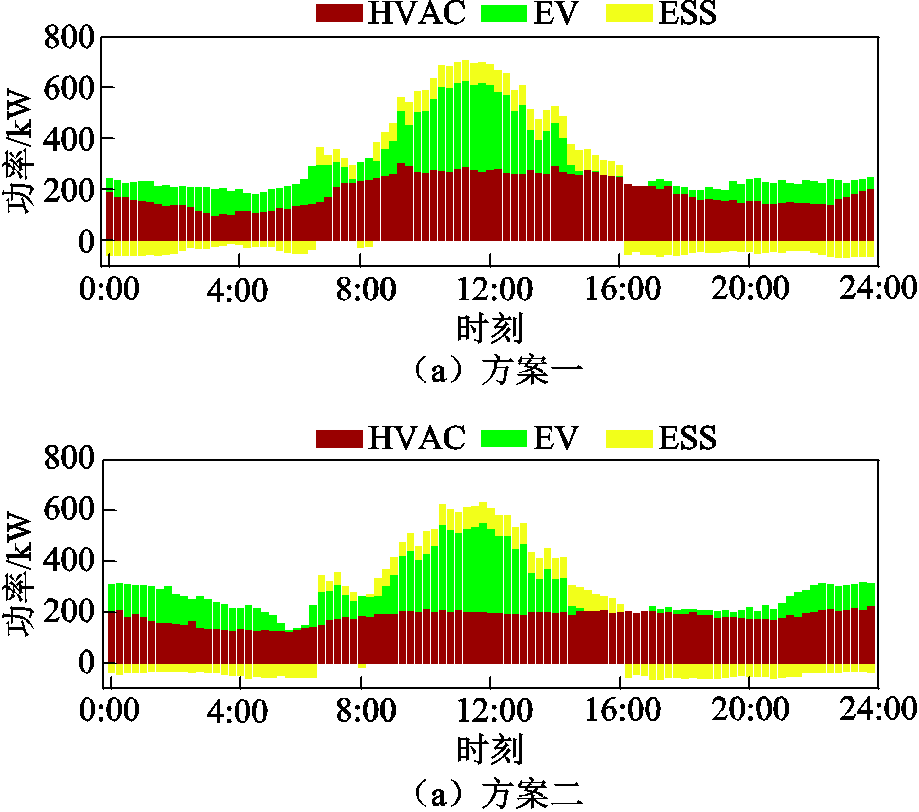
图4 两种方案下线路24-31上灵活资源设备的聚合功率情况对比
Fig.4 Comparison of aggregated power of flexible resources on line 24-31 under two solutions
在产消者智能体对灵活资源设备的实时能量管理策略方面,通过对比如图4所示的考虑能量网络运行安全前后线路24-32上灵活资源设备的聚合功率可知,在方案二中仅考虑系统运行经济性的优化调度策略下,ESS设备主要用以平衡PV出力较低时段的产消者用电需求,HVAC设备的实时调度策略以在满足用户舒适需求的前提下降低运行功耗为主,而EV设备则通过在满足用户在网时间约束与出行能量需求的前提下,将充电行为尽量安排在PV出力较高或售电价格较低的时间段内以降低产消者用电成本。
而在考虑能量网络安全约束的调度策略中,为保证节点电压与线路传输功率维持在安全限额范围内,由于在午间PV出力较高时EV与ESS设备的调节能力较弱,因此智能体主要通过提升该时段HVAC设备运行功率来抑制反向负荷尖峰问题;而在夜间负荷较为集中时,主要通过将部分EV充电负荷转移至售电价格相对较高的时段,并由ESS设备向网络输送更多电能以支撑系统节点电压。同时在考虑能量网络安全约束的灵活资源设备实时能量策略中,HVAC设备各区域的实时温度(如图5所示)与EV期望充电量均能满足用户舒适性需求,也验证了如式(16)、式(17)中所示的考虑用户满意度的局部奖励修正方法的有效性。
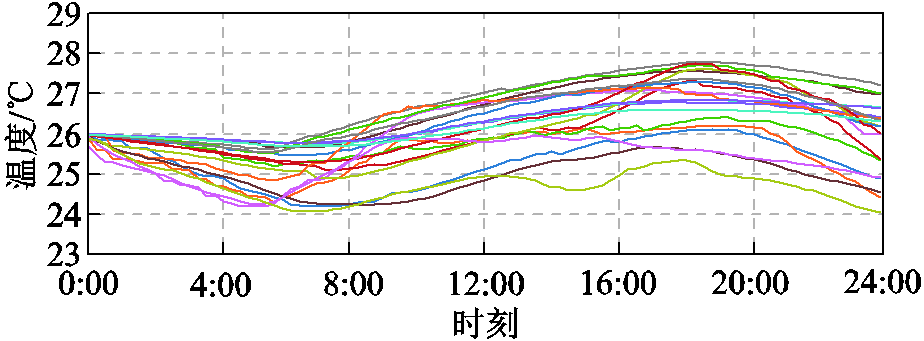
图5 HVAC设备各温控区域的实时温度
Fig.5 Real-time temperature of different thermal zones of HVAC equipment
为进一步验证本文所提DSG系统协同优化调度方法所得实时功率调度决策的运行经济性、能量网络安全性与决策时效性,考虑增加方案四和方案五两种优化调度方案与本文所提方法进行对比。
方案四:采用集中式数学规划方法,在Python 3.8环境中通过Pyomo工具箱调用IPOPT求解器对含非线性潮流模型[32]的DSG系统实时优化问题进行求解。
方案五:同样采用集中式优化方法,并通过粒子群算法进行求解。
系统整体运行成本与能量网络运行安全情况见表3。由于本文所建立的DSG系统协同场景规模较大,集中式优化方法需要对含高维决策变量的优化模型进行求解,因此粒子群算法存在求解困难,易陷入局部最优解的问题,同时与本文所提方法及数学规划方法相比,其所得调度结果无法保证能量网络的运行安全性。
表3 系统整体运行成本与能量网络运行安全情况
Tab.3 Comparison of overall system operating cost and energy network operating security status

方案一方案四方案五 整体运行成本/元4 226.544 244.714 360.52 实时功率决策速度/s0.0569.53133.85 能量网络运行安全性√√× 通信需求本地通信公共网络公共网络
在系统整体运行成本方面,本文所提方法相较于方案四与方案五分别降低了0.43%与3.07%。而在决策获取的时效性方面,由于本文所提方法能够通过策略网络快速映射至实时调度决策,因此仅需0.056 s的平均实时决策时间,同时本文方法在实时决策阶段可以依靠本地网络通信实现DSG系统的协同优化调度,不存在传统集中式优化方法中通信复杂度较高的问题,因此相较于数学规划与粒子群算法,本文方法在决策时效性方面更具优势。
本文针对需求侧灵活资源的实时能量管理与协同优化问题,为在满足灵活资源用户舒适性需求及考虑产消者差异化特征的同时,制定兼顾能量网络安全性、运行经济性与决策时效性的优化调度方案,提出了考虑网络安全约束的分布式智能电网边云协同优化调度方法,主要结论如下:
1)构建了基于边云协同的DSG系统层级优化调度框架,相较于传统集中式优化调度方案能够在实时调度阶段更快速地获取决策方案,提升了DSG系统的功率调度决策时效性。
2)提出了全局与局部奖励相结合的异构智能体奖励机制,能够实现在满足用户需求舒适性的同时,兼顾考虑能量网络运行安全性与经济性的DSG系统整体优化与协同训练目标。
3)为考虑产消者差异化特征,提出了适应异构智能体训练任务的改进MAPPO算法,并通过基于随机顺序的智能体策略异步更新方法,在为各智能体保留了独立决策空间的同时,保证了异构智能体系统协同训练过程中的环境状态稳定性。
此外,在现有分时电价与上网电价机制下,灵活资源产消者的获益空间有限,因此基于当前研究工作,后续将针对提升灵活资源产消者收益的实时交易机制与方案展开进一步研究。
附 录
1. 改进MAPPO算法伪代码
本文所提出的改进MAPPO算法伪代码如下。

改进MAPPO算法: 1输入:智能体数量、小批量样本大小、训练回合数及每回合步长 2初始化:各智能体策略与价值网络参数与、经验池大小 3for do 4 运行初始联合策略 5 对智能体进行编码并形成随机更新顺序 6 for智能体 in do 7 固定中其余智能体策略不变 8 智能体与环境交互并生成经验轨迹 9 当满足大小时候从经验池中抽取小批量样本 10 利用式(26)计算当前智能体优势 11 计算重要性采样比率 12 利用式(27)、式(29)更新参数与 13 end for 14end for
2. 算例参数设置
附图1 购售电价信息
App.Fig.1 Electricity purchase and sale price information
附表1 灵活资源设备运行参数
App.Tab.1 Operating parameters of flexible resources
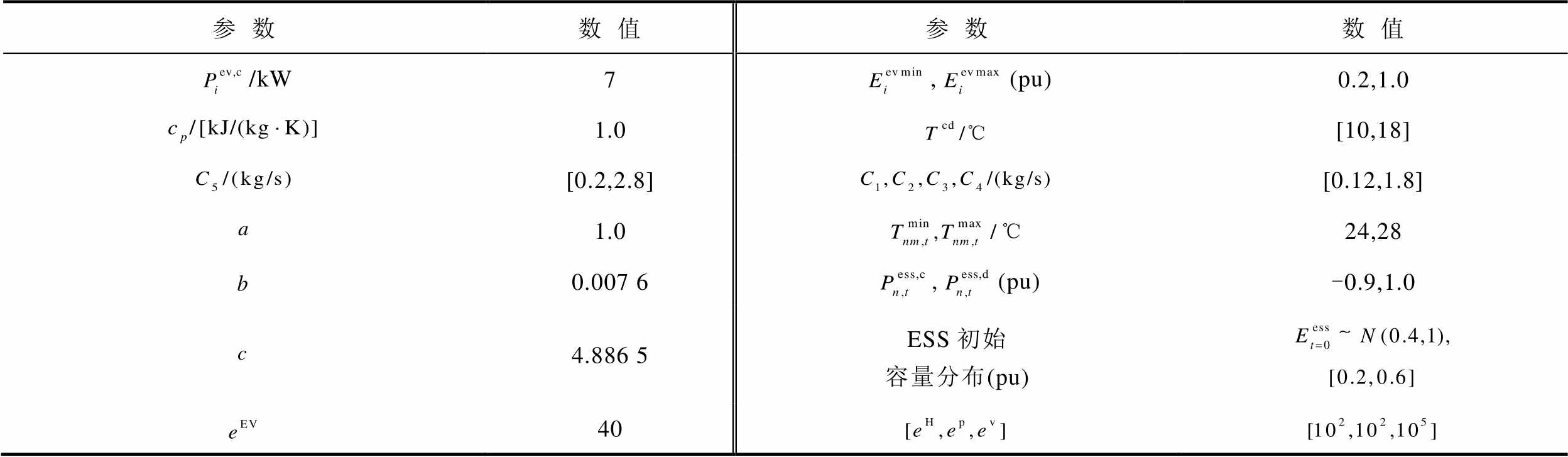
参数数值参数数值 /kW7,(pu)0.2,1.0 1.0[10,18] [0.2,2.8][0.12,1.8] 1.024,28 0.007 6,(pu)-0.9,1.0 4.886 5ESS初始容量分布(pu) 40
附图2 超参数随机搜索空间
App.Fig.2 Hyperparameter random search space
附图3 超参数随机搜索结果
App.Fig.3 Hyperparameter random search results
附表2 离线训练超参数
App.Tab.2 Hyperparameters for offline training

超参数数值 奖励折扣因子0.953 4 网络学习率0.000 065 样本批量768 代理目标剪裁比0.2 网络优化器ADAM 激活函数ReLU 经验回放池大小960 并行CPU数量8
附图4 实时决策日固定负荷曲线与光伏出力情况
App.Fig.4 Daily fixed load curve and PV generation on real-time decision day
3. 系统资源配置与不同方案下线路传输功率及节点电压情况
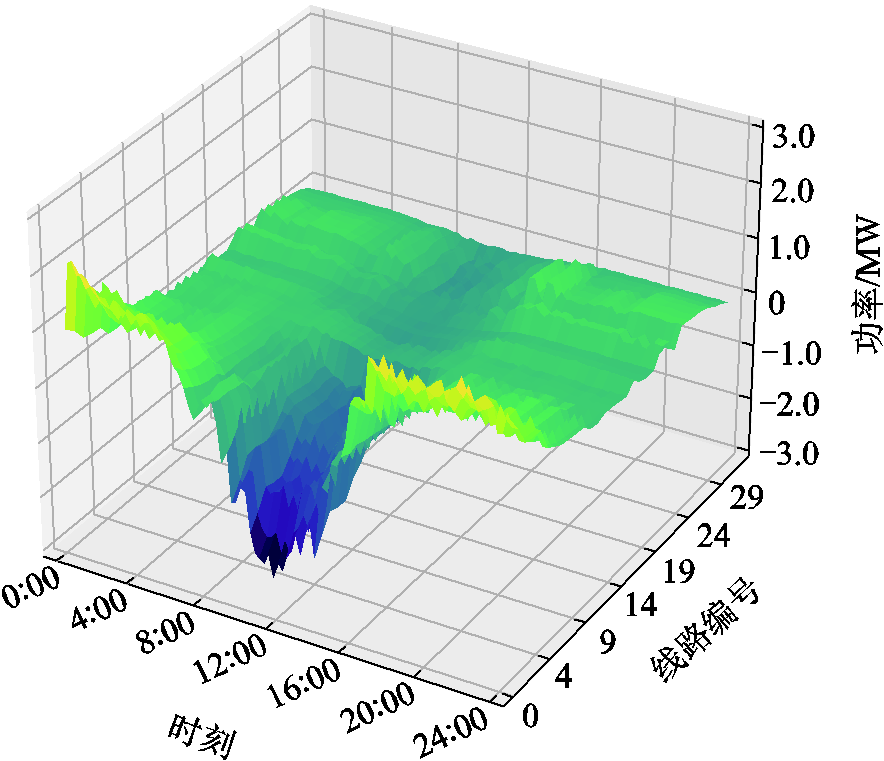
附图5 方案一中各时段线路传输功率情况
App.Fig.5 Line transmission power under solution one during different time periods
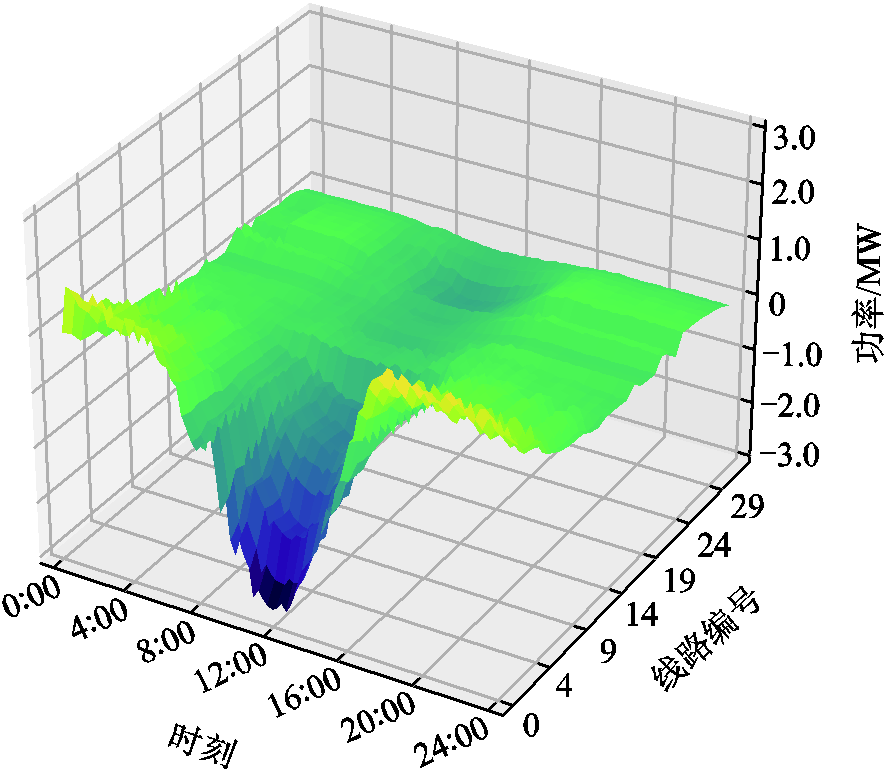
附图6 方案二中各时段线路传输功率情况
App.Fig.6 Line transmission power under solution two during different time periods
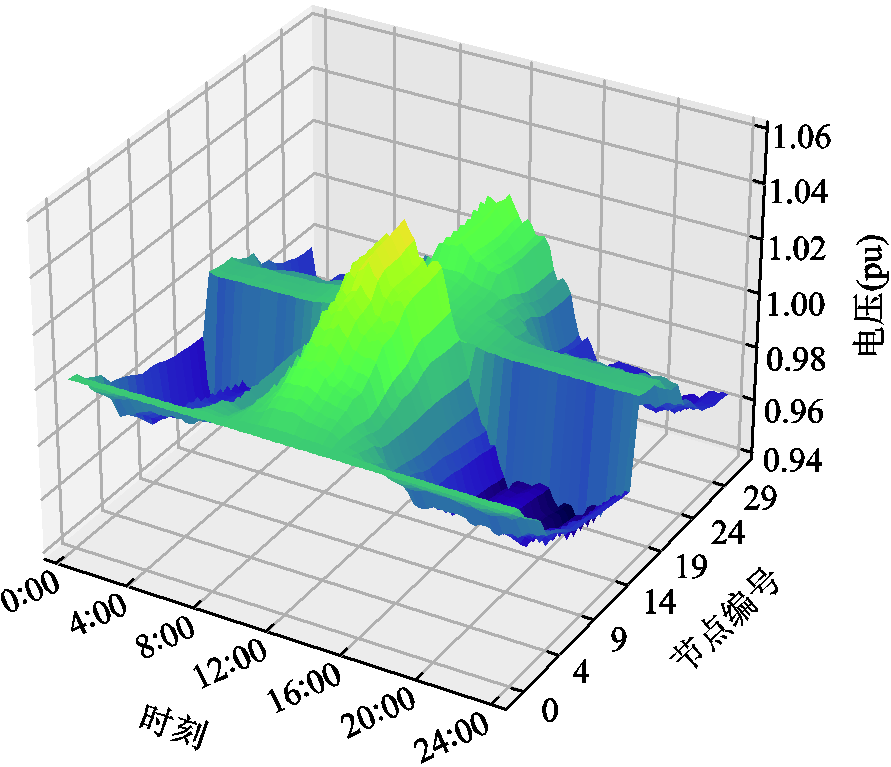
附图7 方案一中各时段系统电压情况
App.Fig.7 System voltage under solution one during different time periods
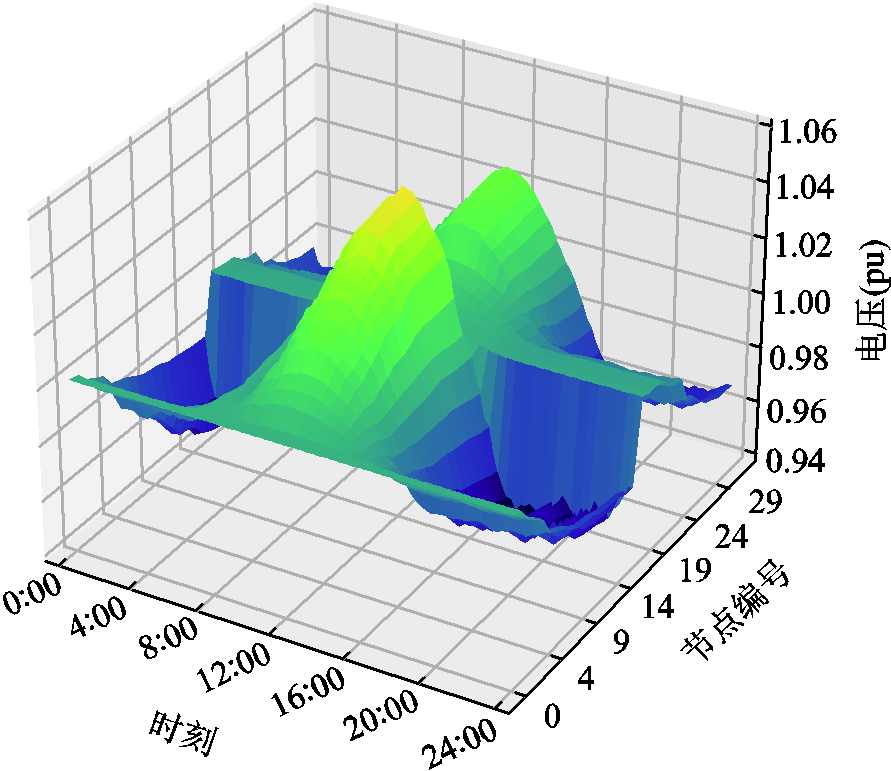
附图8 方案二中各时段系统电压情况
App.Fig.8 System voltage under solution two during different time periods
参考文献
[1] 孙毅, 李飞, 胡亚杰, 等. 计及条件风险价值和综合需求响应的产消者能量共享激励策略[J]. 电工技术学报, 2023, 38(9): 2448-2463.
Sun Yi, Li Fei, Hu Yajie, et al. Energy sharing incentive strategy of prosumers considering conditional value at risk and integrated demand response[J]. Transactions of China Electrotechnical Society, 2023, 38(9): 2448-2463.
[2] 胡俊杰, 李阳, 吴界辰, 等. 基于配网节点电价的产消者日前优化调度[J]. 电网技术, 2019, 43(8): 2770-2780.
Hu Junjie, Li Yang, Wu Jiechen, et al. A day-ahead optimization scheduling method for prosumer based on iterative distribution locational marginal price[J]. Power System Technology, 2019, 43(8): 2770-2780.
[3] 李勇, 凌锋, 乔学博, 等. 基于网侧资源协调的自储能柔性互联配电系统日前-日内优化[J]. 电工技术学报, 2023, 39(3): 758-773.
Li Yong, Ling Feng, Qiao Xuebo, et al. Day-ahead and intra-day optimization of flexible interconnected distribution system with self-energy storage based on the grid-side resource coordination[J]. Transactions of China Electrotechnical Society, 2023, 39(3): 758-773.
[4] 赵紫原. 分布式智能电网护航能源安全: 专访中国工程院院士、天津大学教授余贻鑫[J]. 中国电力企业管理, 2022(25): 10-13.
Zhao Ziyuan. Distributed smart grid escorts energy security—interview with yu Yixin, academician of China academy of engineering and professor of Tianjin university[J]. China Power Enterprise Management, 2022(25): 10-13.
[5] 陈心宜, 胡秦然, 石庆鑫, 等. 新型电力系统居民分布式资源管理综述[J]. 电力系统自动化, 2024, 48(5): 157-175.
Chen Xinyi, Hu Qinran, Shi Qingxin, et al. Review on residential distributed energy resource management in new power system[J]. Automation of Electric Power Systems, 2024, 48(5): 157-175.
[6] 王枭, 何怡刚, 马恒瑞, 等. 面向电网辅助服务的虚拟储能电厂分布式优化控制方法[J]. 电力系统自动化, 2022, 46(10): 181-188.
Wang Xiao, He Yigang, Ma Hengrui, et al. Distributed optimization control method of virtual energy storage plants for power grid ancillary services[J]. Automation of Electric Power Systems, 2022, 46(10): 181-188.
[7] 李振坤, 钱晋, 符杨, 等. 基于负荷聚合商优选分级的配电网多重阻塞管理[J]. 电力系统自动化, 2021, 45(19): 109-116.
Li Zhenkun, Qian Jin, Fu Yang, et al. Multiple congestion management for distribution network based on optimization classification of load aggregators[J]. Automation of Electric Power Systems, 2021, 45(19): 109-116.
[8] Hu Junjie, Liu Xuetao, Shahidehpour M, et al. Optimal operation of energy hubs with large-scale distributed energy resources for distribution network congestion management[J]. IEEE Transactions on Sustainable Energy, 2021, 12(3): 1755-1765.
[9] Hu Junjie, Yang Guangya, Bindner H W, et al. Application of network-constrained transactive control to electric vehicle charging for secure grid operation[J]. IEEE Transactions on Sustainable Energy, 2017, 8(2): 505-515.
[10] Hu Junjie, Yang Guangya, Ziras C, et al. Aggregator operation in the balancing market through network-constrained transactive energy[J]. IEEE Transactions on Power Systems, 2019, 34(5): 4071-4080.
[11] 兰威, 陈飞雄. 计及阻塞管理的虚拟电厂与配电网协同运行策略[J]. 电气技术, 2022, 23(6): 30-41.
Lan Wei, Chen Feixiong. Cooperative operation strategy of distribution network and virtual power plants considering congestion management[J]. Electrical Engineering, 2022, 23(6): 30-41.
[12] Shen Feifan, Wu Qiuwei, Huang Shaojun, et al. Two-tier demand response with flexible demand swap and transactive control for real-time congestion management in distribution networks[J]. International Journal of Electrical Power & Energy Systems, 2020, 114: 105399.
[13] 冯斌, 胡轶婕, 黄刚, 等. 基于深度强化学习的新型电力系统调度优化方法综述[J]. 电力系统自动化, 2023, 47(17): 187-199.
Feng Bin, Hu Yijie, Huang Gang, et al. Review on optimization methods for new power system dispatch based on deep reinforcement learning[J]. Automation of Electric Power Systems, 2023, 47(17): 187-199.
[14] 陈泽宇, 方志远, 杨瑞鑫, 等. 基于深度强化学习的混合动力汽车能量管理策略[J]. 电工技术学报, 2022, 37(23): 6157-6168.
Chen Zeyu, Fang Zhiyuan, Yang Ruixin, et al. Energy management strategy for hybrid electric vehicle based on the deep reinforcement learning method[J]. Transactions of China Electrotechnical Society, 2022, 37(23): 6157-6168.
[15] Kang H, Jung S, Kim H, et al. Multi-objective sizing and real-time scheduling of battery energy storage in energy-sharing community based on reinforcement learning[J]. Renewable and Sustainable Energy Reviews, 2023, 185: 113655.
[16] 陈明昊, 孙毅, 谢志远. 基于双层深度强化学习的园区综合能源系统多时间尺度优化管理[J]. 电工技术学报, 2023, 38(7): 1864-1881.
Chen Minghao, Sun Yi, Xie Zhiyuan. The multi-time-scale management optimization method for park integrated energy system based on the Bi-layer deep reinforcement learning[J]. Transactions of China Electrotechnical Society, 2023, 38(7): 1864-1881.
[17] 叶宇剑, 袁泉, 刘文雯, 等. 基于参数共享机制多智能体深度强化学习的社区能量管理协同优化[J]. 中国电机工程学报, 2022, 42(21): 7682-7695.
Ye Yujian, Yuan Quan, Liu Wenwen, et al. Parameter sharing empowered multi-agent deep reinforcement learning for coordinated management of energy communities[J]. Proceedings of the CSEE, 2022, 42(21): 7682-7695.
[18] Lin Lin, Guan Xin, Peng Yu, et al. Deep reinforcement learning for economic dispatch of virtual power plant in Internet of energy[J]. IEEE Internet of Things Journal, 2020, 7(7): 6288-6301.
[19] Fang Dawei, Guan Xin, Peng Yu, et al. Distributed deep reinforcement learning for renewable energy accommodation assessment with communication uncertainty in Internet of energy[J]. IEEE Internet of Things Journal, 2021, 8(10): 8557-8569.
[20] Kim D, Bae Y, Yun S, et al. A methodology for generating reduced-order models for large-scale buildings using the Krylov subspace method[J]. Journal of Building Performance Simulation, 2020, 13(4): 419-429.
[21] Chintala R H, Rasmussen B P. Automated multi-zone linear parametric black box modeling approach for building HVAC systems[C]//Proceedings of ASME 2015 Dynamic Systems and Control Conference, Columbus, Ohio, USA, 2015: 1-10.
[22] Silver D, Hubert T, Schrittwieser J, et al. A general reinforcement learning algorithm that Masters chess, shogi, and Go through self-play[J]. Science, 2018, 362(6419): 1140-1144.
[23] Ding Yifu, Morstyn T, McCulloch M D. Distributionally robust joint chance-constrained optimization for networked microgrids considering contingencies and renewable uncertainty[J]. IEEE Transactions on Smart Grid, 2022, 13(3): 2467-2478.
[24] Zhu Hao, Liu H J. Fast local voltage control under limited reactive power: optimality and stability analysis[J]. IEEE Transactions on Power Systems, 2016, 31(5): 3794-3803.
[25] Yu Chao, Velu A, Vinitsky E, et al. The surprising effectiveness of PPO in cooperative, multi-agent games[EB/OL]. 2021: arXiv: 2103.01955. https:// arxiv.org/abs/2103.01955.pdf
[26] Iqbal S, Sha Fei. Actor-attention-critic for multi-agent reinforcement learning[EB/OL]. 2018: arXiv: 1810.02912. https://arxiv.org/abs/1810.02912.pdf.
[27] Foerster J, Farquhar G, Afouras T, et al. Counterfactual multi-agent policy gradients[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 2974-2982.
[28] Kuba J G, Feng Xidong, Ding Shiyao, et al. Heterogeneous-agent mirror learning: a continuum of solutions to cooperative MARL[EB/OL]. 2022: arXiv: 2208.01682. https://arxiv.org/abs/2208.01682.pdf.
[29] Kuba J G, Chen Ruiqing, Wen Muning, et al. Trust region policy optimisation in multi-agent reinforcement learning[EB/OL]. 2021: arXiv: 2109.11251. https:// arxiv.org/abs/2109.11251.pdf.
[30] Wiese F, Schlecht I, Bunke W D, et al. Open Power System Data - Frictionless data for electricity system modelling[J]. Applied Energy, 2019, 236: 401-409.
[31] Liessner R, Schmitt J, Dietermann A, et al. Hyper-parameter optimization for deep reinforcement learning in vehicle energy management[C]//Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 2019: 134-144.
[32] 马庆, 邓长虹. 基于单/多智能体简化强化学习的电力系统无功电压控制方法[J]. 电工技术学报, 2024, 39(3): 1300-1312.
Ma Qing, Deng Changhong. Single/multi agent simplified deep reinforcement learning based volt-var control of power system[J]. Transactions of China Electrotechnical Society, 2024, 39(3): 1300-1312.
Network Security Constrained Distributed Smart Grid Edge-Cloud Collaborative Optimization Scheduling
Abstract With the increasing penetration of distributed generation and the growing demand for power system flexibility, issues like voltage rise at the edge of distribution networks and network congestion under bidirectional power flow are becoming more prominent. Integrating and coordinating flexible resources at the user side through Distributed Smart Grids (DSG) is significant for enhancing the accommodation of distributed generation and the real-time supply-demand balancing capability of distribution systems. Considering the large quantity and high dispersion of flexible resource devices and the distinct characteristics of different prosumers, traditional centralized optimization and dispatch schemes as well as distributed computing methods will face greater challenges in solving efficiency and decision delivery timeliness. Against this background, this paper aims to develop a DSG system collaborative optimization and dispatch method that takes into account operational economy, energy network security, and decision timeliness concurrently.
Firstly, mapping real-world prosumers who control and own flexible resources to intelligent agents in reinforcement learning, the optimization and dispatch of flexible resources in DSG is formulated as a multi-agent collaborative optimization model. The existing edge-cloud collaborative framework is extended to the optimization of flexible resources considering energy network security constraints, and a hierarchical optimization and dispatch framework of flexible resource-prosumer-DSG is established. Secondly, considering the differentiated characteristics of prosumers in aspects like types of flexible resource devices, photovoltaics (PV) is taken as distributed generation, and electric vehicles (EV), heating, ventilation and air conditioning (HVAC) of buildings, and energy storage systems (ESS) are taken as demand-side flexible resources. A heterogeneous intelligent agent interactive environment model is built based on the operational characteristics of different flexible resources. Meanwhile, to balance flexible resource operational requirements, overall economic efficiency and energy network security of the DSG system, user satisfaction evaluation of EV and HVAC operation and ESS operation cost are considered as local rewards, while system energy cost and energy network security evaluation are taken as global rewards, and a combined global-local reward mechanism for heterogeneous intelligent agents is proposed. Finally, to adapt to the collaborative training task of the heterogeneous intelligent agent system, an improved multi-agent proximal policy optimization (MAPPO) algorithm is proposed based on asynchronous update of agent policies in random order.
Case studies on the IEEE 33-node system are conducted for analysis. Firstly, the proposed improved MAPPO algorithm is compared with existing multi-agent collaborative training schemes in the offline training stage. Secondly, the differences in flexible resource prosumers' power decisions with and without considering energy network constraints are analyzed in the online dispatch stage. Finally, the proposed method is compared with traditional mathematical programming and particle swarm optimization methods regarding optimization performance in real-time dispatch. The main conclusions are: (1) The edge-cloud collaborative hierarchical optimization and dispatch framework for DSG systems is established, which can obtain dispatch decisions faster in real-time dispatch compared to traditional centralized optimization and thus improve the timeliness of DSG power dispatch decisions. (2) The combined global-local reward mechanism for heterogeneous intelligent agents can achieve overall DSG system optimization and collaborative training objectives of balancing user comfort, economic efficiency and energy network security. (3) The proposed improved MAPPO algorithm adapted for heterogeneous intelligent agent training can maintain independent decision spaces for each agent while ensuring environment state stability in collaborative training through asynchronous policy updates in random order.
keywords:Distributed smart grid, flexible resources, edge-cloud collaboration, deep reinforcement learning, network safety constrain
中图分类号:TM732
DOI:10.19595/j.cnki.1000-6753.tces.231352
国家自然科学基金面上项目(52177080)和北京市科技新星计划项目(Z201100006820106)资助。
收稿日期 2023-08-21
改稿日期 2023-10-27
潘玺安 男,1993年生,博士研究生,研究方向为新能源电力系统及微网。
E-mail:panxian@ncepu.edu.cn
胡俊杰 男,1986年生,教授,博士生导师,研究方向为新能源电力系统及微网等。
E-mail:junjiehu@ncepu.edu.cn(通信作者)
(编辑 赫 蕾)