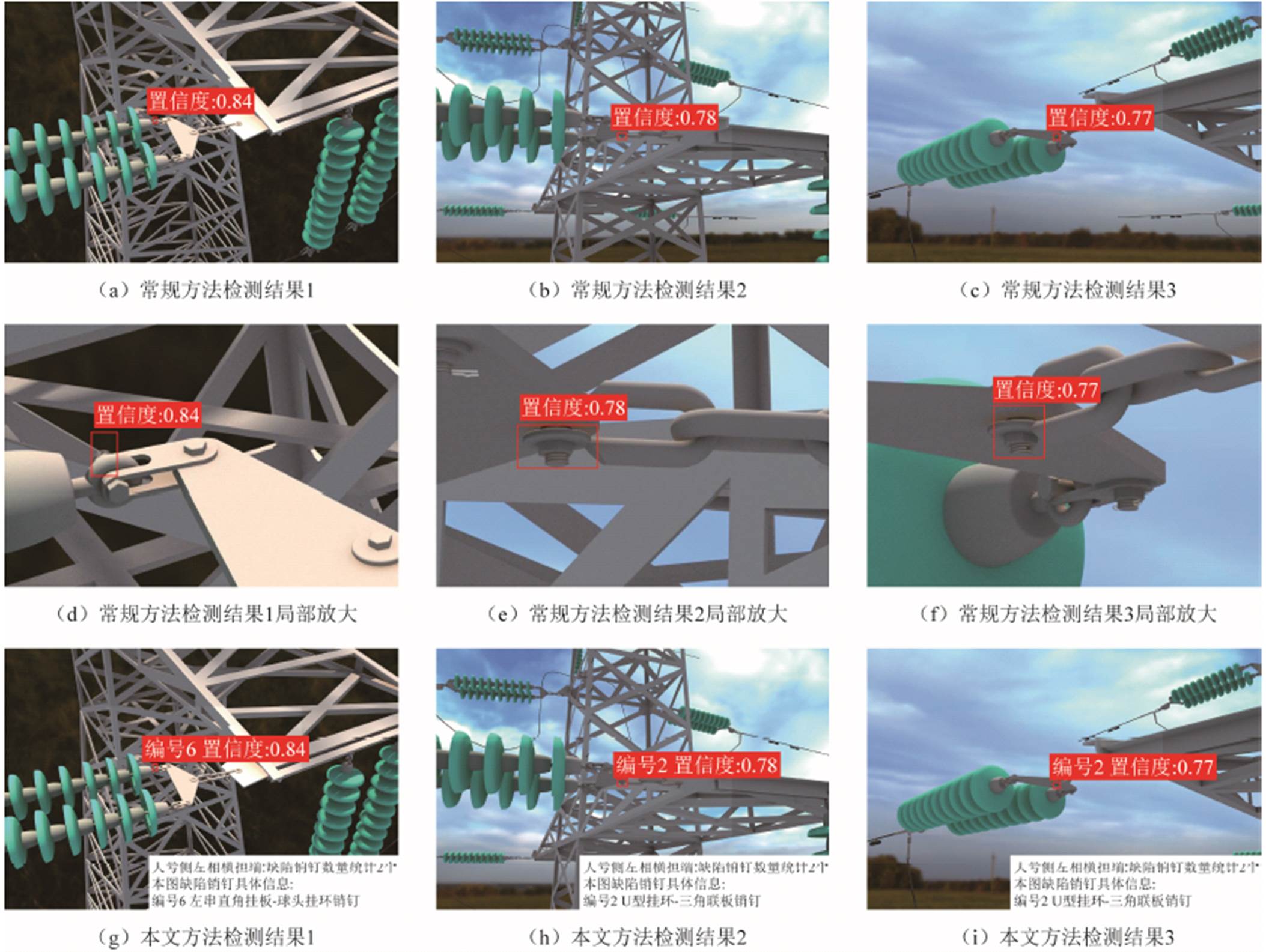
图1 常规缺陷销钉检测方法不足及本文方法优势
Fig.1 The shortage of conventional defect pin detection methods and the advantage of this method
摘要 近年来,基于深度学习的缺陷销钉检测技术在电力杆塔巡检中得到广泛应用。但是该技术只能在图像空间对缺陷销钉进行定位,无法准确给出缺陷销钉在实际电力杆塔中对应销钉的唯一编号。针对该问题,该文提出一种融合深度学习与三维重投影的缺陷销钉唯一性识别方法。首先通过构建巡检电力杆塔系统的三维模型,进行电力杆塔系统中部件模型的编号获取,以及部件模型三维空间包围盒顶点和中心点坐标的计算;其次,利用YOLOv5模型在图像空间对销钉及上下文相关目标进行检测;再次,通过该文提出的融合结构约束的相机位姿估计算法对航拍图像的相机位姿进行估计;最后,将三维电力杆塔系统中的销钉包围盒按相机位姿进行重投影与销钉检测框进行匹配度计算,在图像空间中输出带有具体编号的销钉检测框。在YOLOv5模型输出的销钉检测框基础上进行销钉唯一性识别,利用仿真数据进行实验得到的唯一性识别正确率为100%,利用实拍数据进行实验得到的唯一性识别正确率为93.3%,验证了该文提出的销钉唯一性识别方法的有效性。通过对缺陷销钉进行唯一性识别,可以减少人工对故障图像的二次审核工作量,并准确地统计缺陷销钉的数量及具体位置信息,为后续故障维修及故障相关性分析等精细化管理提供支持。
关键词:电力巡检 销钉检测 相机位姿估计 唯一性识别
销钉是输电线路中的重要紧固件,起到固定螺母的作用,一旦出现故障,可能造成大面积停电等安全问题。随着深度学习在目标检测领域的发展[1-5],在图像空间中自动并准确定位缺陷销钉成为可能。文献[6]针对销钉体积小的特点,对特征金字塔算法做出了改进,增强对底层语义信息和位置信息的提取能力。文献[7]对SSD网络结构进行改进,增强特征层信息提取能力。文献[8]提出一种两阶段网络检测模型,通过先裁剪、再识别策略对非带销螺栓进行过滤。文献[9]考虑螺栓周围的背景信息,提出一种基于上下文信息和多尺度特征融合的深度神经网络。文献[10]提出一种双注意力机制方法,增强螺栓区域精细特征,增大螺栓与背景特征差异。
以上常规基于深度学习的缺陷销钉检测技术主要通过改进特征提取网络、融合多尺度特征等技术手段来提高缺陷销钉检测精度,其检测结果只能在图像空间中对缺陷销钉进行定位,而无法自动确定缺陷销钉对应实际电力杆塔系统中的编号,对于缺陷的具体位置仍需人工判断。且无人机在巡检过程中,为获取清晰完整的航拍图像,通常会对同一部位进行多角度拍摄,就可能造成缺陷销钉的重复标注,给人工二次审查带来不便。图1给出了对同一巡检部位的多角度拍摄图像,采用常规目标检测方法与本文方法对缺陷销钉检测结果的对比情况。常规方法只在图像空间对缺陷销钉进行定位并给出置信度,本文方法在常规目标检测方法输出结果的基础上,给出了检测目标的编号,并自动统计该巡检部位缺陷销钉数量及具体位置信息。
也有部分学者对基于航拍的故障定位进行研究,如文献[11-13],研究方法为在已知无人机GPS、位姿信息的条件下,根据故障位置的像素坐标,经坐标系转换求解故障点的大地坐标。然而受无人机数据采集精度等因素影响导致求解结果不精确。还有学者利用三维目标检测技术研究电力巡检中目标的空间定位问题,如文献[14-15],其目的是为了提高变电站场景中人员安全管控水平。三维目标检测技术通过传感器获取额外的深度信息以回归目标的3D包络框,其侧重于对目标空间位置、尺寸信息、方向角等三维形态信息的感知。目前航拍巡检图像主要成像方式为单目相机成像,图像本身不包含相机位姿信息及深度信息,以上研究均难以直接解决单目图像中目标的准确空间定位问题。
图1 常规缺陷销钉检测方法不足及本文方法优势
Fig.1 The shortage of conventional defect pin detection methods and the advantage of this method
对此,本文提出一种融合深度学习和三维重投影的航拍图像销钉唯一性识别方法,其本质是对二维目标检测任务的延伸。本文方法在已知巡检部位名称的条件下,仅依据三维模型中少量的空间特征点,根据二维图像空间目标检测任务结果,计算图像拍摄时的相机位姿。通过将带编号的三维空间销钉包围盒重投影至二维图像上与销钉检测框进行匹配,得到图像空间中销钉在三维电力杆塔系统中的编号。最终根据编号与位置的对应关系对该部位的缺陷销钉数量及具体位置信息进行统计,在图像空间输出缺陷销钉的唯一性识别结果。对航拍图像缺陷销钉的唯一性识别,有利于运维人员对同一巡检部位多张缺陷图像中多次标注的同一缺陷进行快速辨别,提高运维人员对缺陷图像的二次核查效率,为后续故障维修及故障部件的相关性分析等精细化管理提供支持。
本文提出的融合深度学习与三维重投影的销钉唯一性识别方法基本流程分为销钉唯一性识别预处理、基于上下文相关目标的图像空间特征提取、融合结构约束的航拍图像相机位姿估计以及图像空间销钉唯一性编号确定四个子流程。图2给出了本文方法的详细框架。
本文首先进行销钉唯一性识别的预处理,通过构建巡检电力杆塔的三维模型,获取部件的三维空间包围盒信息及编号。
然后利用深度学习目标检测网络对销钉及上下文相关目标进行检测,销钉及上下文相关目标示意图如图3所示。由于本文只对图像空间中目标巡检部位内的销钉进行唯一性识别,因此对目标巡检部位内销钉所属的上下文环境进行定义。将多个金具相互连接以实现某种功能的整体结构定义为金具目标群。并将金具目标群作为销钉上下文相关目标,分为横担端及导线端,分别用于绝缘子串与杆塔以及绝缘子串与导线的连接。此外,销钉上下文相关目标还包括特定金具如三角联板等。YOLOv5[16]模型计算速度快且预置多尺度先验框,因此本文采用YOLOv5模型作为图像特征提取网络,对销钉及上下文相关目标的多尺度目标进行识别。
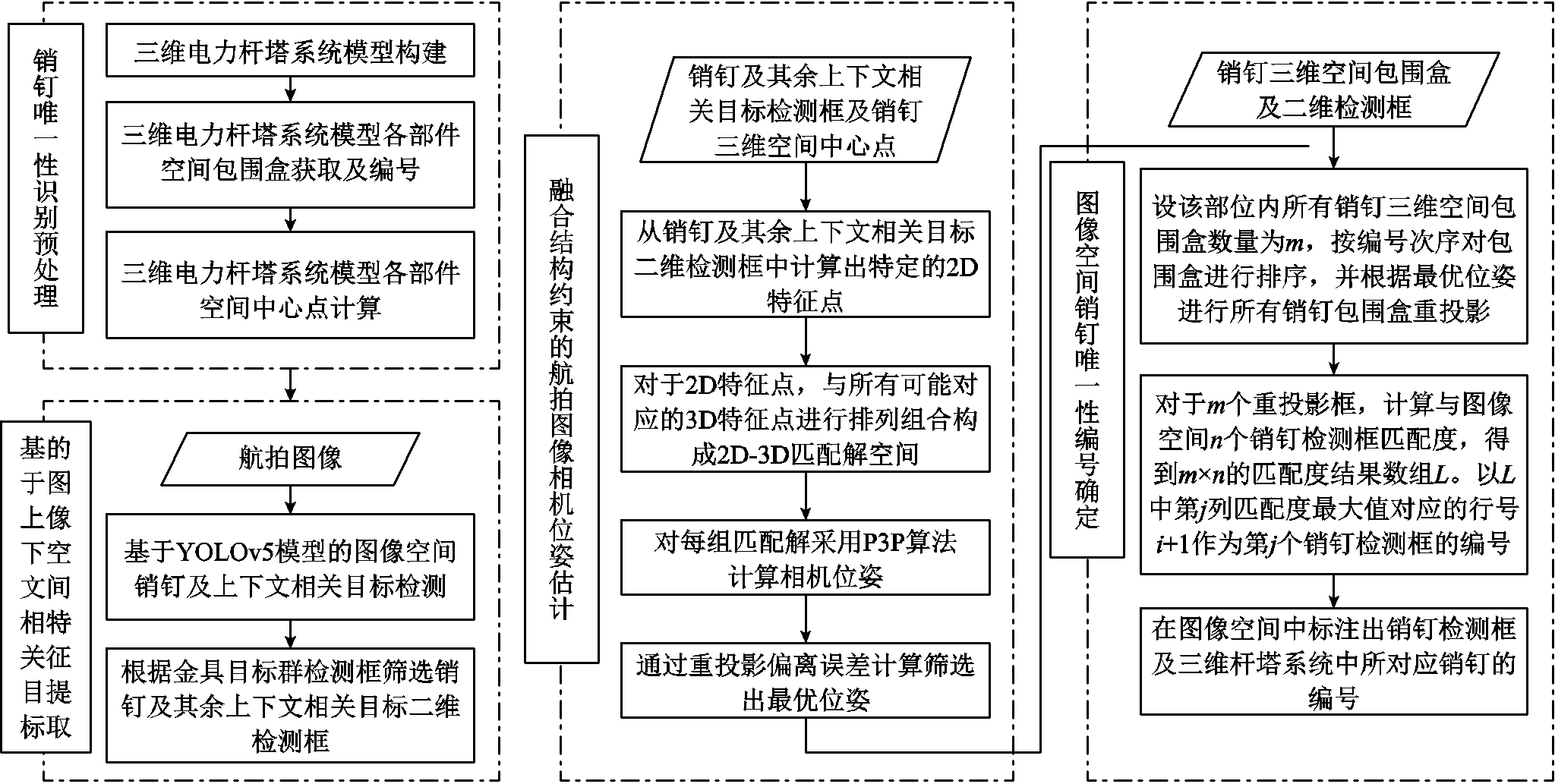
图2 融合深度学习与三维重投影的销钉唯一性识别详细框架
Fig.2 A detailed framework for pin uniqueness dentification integrates deep learning and 3D reprojection

图3 销钉上下文相关目标示意图
Fig.3 Pins and context sensitive targets
根据三维空间包围盒信息获取结果,以及图像空间目标检测结果,利用本文提出的融合结构约束的相机位姿估计算法对图像的相机位姿进行计算。将带编号的销钉三维空间包围盒按照相机位姿重投影至二维图像空间,与销钉检测框进行匹配度计算,最终在图像中输出销钉检测结果及编号。
理想相机成像模型[17]是一种平面透视投影模型,该模型描述了三维空间中的点到相机图像中的点的关系。对于世界坐标系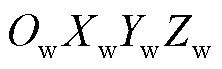 中任意一点
中任意一点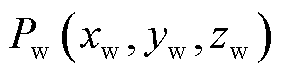 ,经旋转矩阵R、平移矩阵T变换到相机坐标系
,经旋转矩阵R、平移矩阵T变换到相机坐标系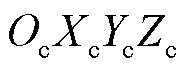 得到
得到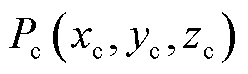 ,再经相机坐标系、图像坐标系
,再经相机坐标系、图像坐标系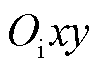 以及像素坐标系
以及像素坐标系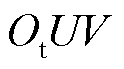 之间的转换关系,得到二维像素点
之间的转换关系,得到二维像素点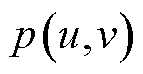 。坐标系之间转换关系为
。坐标系之间转换关系为
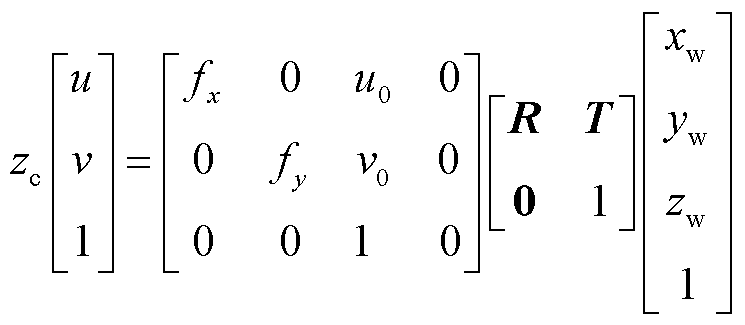 (1)
(1)
本文采用基于视觉的相机位姿估计方法[18],即PnP(Perspective-n-Point)算法:在相机内参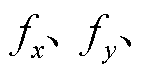
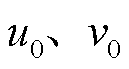 已知的情况下,利用n个3D特征点和对应的2D特征点来估计相机位姿参数(R, T)。
已知的情况下,利用n个3D特征点和对应的2D特征点来估计相机位姿参数(R, T)。
PnP算法准确求解的关键条件是n对2D-3D特征点的对应匹配。n值越大,2D-3D特征点匹配计算量越大。因此,本文取n=3,即P3P算法。P3P算法利用三对2D-3D匹配特征点计算位姿,但可能有多解的情况,通常还需利用第4对匹配特征点验证最优解。为实现2D-3D特征点的自动对应,本文以目标的二维像素中心点和三维空间中心点形成点对点约束,利用穷举法构建匹配解空间,根据空间点的结构约束计算重投影偏离误差验证最优位姿。
2.2.1 基于上下文相关目标的2D-3D特征点匹配
为减小以目标图像空间和三维空间中心点作为对应特征点对精度的影响,本文选取计算特征点的目标为体积小、占据像素少的销钉及螺栓头部。为解决2D-3D特征点的对应问题,首先选定4个目标检测框计算中心点作为2D特征点,根据类别将每个2D特征点与可能的3D特征点逐个匹配,以全排列组合方式得到所有2D-3D特征点匹配结果,构成解空间Z。为提高算法运行效率,通过检测特定的上下文金具目标,优先选取与之存在相交的销钉、螺栓头部目标,将3D特征点的选择范围由全局缩减为特定金具的临近范围内。
2.2.2 基于P3P算法的相机位姿计算
遍历解空间Z,利用P3P算法对每组2D-3D特征点匹配解进行相机位姿计算。对于2D-3D特征点全部对应正确的匹配解计算出的位姿才是最优位姿。
2.2.3 基于位姿重投影的偏离误差计算
设解空间Z中第k个2D-3D匹配解位姿计算结果为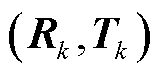 ,三维空间销钉中心点集合为
,三维空间销钉中心点集合为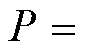
 ,二维图像空间销钉检测框中心点集合为
,二维图像空间销钉检测框中心点集合为 。为验证最优位姿,首先将P中所有的3D特征点按
。为验证最优位姿,首先将P中所有的3D特征点按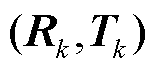 进行重投影,然后计算
进行重投影,然后计算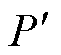 中所有的2D特征点与最近邻的重投影点的像素距离,像素距离之和作为的重投影偏离误差,计算公式为
中所有的2D特征点与最近邻的重投影点的像素距离,像素距离之和作为的重投影偏离误差,计算公式为
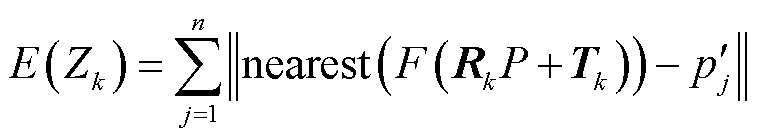 (2)
(2)
式中,F(∙)为相机坐标系下3D特征点到2D像素点的投影变换;nearest(∙)表示选取与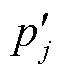 像素距离最小的重投影点。最终选取重投影偏离误差最小的相机位姿(R,T)作为最优位姿。
像素距离最小的重投影点。最终选取重投影偏离误差最小的相机位姿(R,T)作为最优位姿。
本文将电力杆塔及杆塔上的绝缘子串定义为电力杆塔系统。根据三维电力杆塔系统模型,获取巡检部位内销钉三维空间包围盒,由1~m进行编号。按最优位姿重投影至二维空间,计算重投影点最小外接矩形作为包围盒重投影框,设重投影框集合为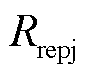 。
。
1)设航拍图像中,经金具目标群检测框筛选后的销钉检测框集合为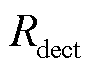 ,数量为n。
,数量为n。
2)在目标检测领域中,通常利用交并比(Intersection over Union, IoU)计算目标边界框的定位精度。本文利用IoU计算重投影框与检测框的匹配度。设重投影框集合为,第i个销钉检测框与第j个重投影框IoU计算公式如式(3)所示,其中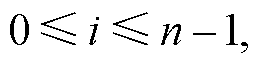
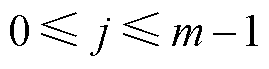 。
。
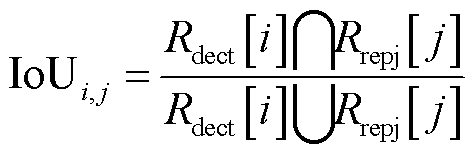 (3)
(3)
3)设m个重投影框与n个销钉检测框经IoU计算得到二维结果数组L,由于中重投影框索引编号起始位置为0,因此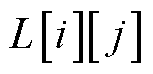 表示编号为i+1的销钉包围盒重投影框与第j个销钉检测框的匹配度。对于第j个销钉检测框,比较L中第j列的最大值,其对应的行索引值i+1即为三维电力杆塔系统中对应销钉的编号。若最大值为0,则销钉检测框匹配失败。
表示编号为i+1的销钉包围盒重投影框与第j个销钉检测框的匹配度。对于第j个销钉检测框,比较L中第j列的最大值,其对应的行索引值i+1即为三维电力杆塔系统中对应销钉的编号。若最大值为0,则销钉检测框匹配失败。
经销钉包围盒重投影框与检测框匹配度计算,得到销钉检测框在三维电力杆塔系统中该巡检部位内对应销钉的编号,与销钉检测框一并在图像空间中进行可视化输出。
由于在实际环境中,无人机拍摄角度都会受到一定限制,难以获得多角度的杆塔巡检图像以及精准的相机位姿。为了获取相机位姿丰富的数据集,本文提出一种多角度相机位姿的图像生成方法以及目标标注框自动生成算法。
根据某110 kV干字型电力杆塔远距离航拍图片,结合相关规范资料,在仿真环境中构建电力杆塔系统三维模型。以杆塔底部中心点为原点,杆塔小号侧方向为x轴正方向,竖直向上为z轴正方向构建右手坐标系。通过对模型增加材质、光照、背景贴图等元素模拟真实电力杆塔场景,设置摄像机对杆塔系统进行拍摄模拟无人机巡检,如图4所示。

图4 110 kV干字型三维电力杆塔系统模型构建
Fig.4 Construction of 3D model of 110 kV gan-shaped power tower system
4.2.1 多角度相机位置生成
本文以拍摄目标位置为基准位置,通过修改相机位置获取多角度位姿。设拍摄目标三维空间点坐标为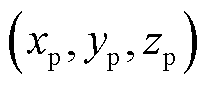 ,设置坐标偏移量Δx, Δy, Δz,叠加得到相机位置坐标
,设置坐标偏移量Δx, Δy, Δz,叠加得到相机位置坐标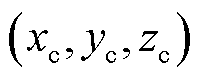 ,偏移量计算公式为
,偏移量计算公式为
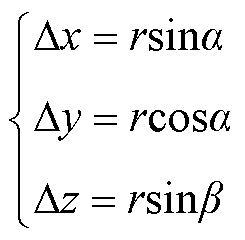 (4)
(4)
式中,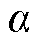 、
、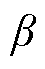 为以等间隔增加的角度值。假设无人机拍摄时从杆塔外侧向里侧进行拍摄且存在一定角度限制,则、存在上下界。所有相机位置坐标点分布近似为以拍摄目标坐标(xp, yp, zp)为轴线中点,r为半径的柱面区域。
为以等间隔增加的角度值。假设无人机拍摄时从杆塔外侧向里侧进行拍摄且存在一定角度限制,则、存在上下界。所有相机位置坐标点分布近似为以拍摄目标坐标(xp, yp, zp)为轴线中点,r为半径的柱面区域。
4.2.2 基于相对位置的位姿转换
1)水平角、俯仰角计算
在本文研究中,忽略无人机相机滚转角控制,利用式(5)计算水平角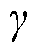 、俯仰角
、俯仰角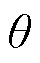 。并在生成仿真图像时以“巡检部位名称+水平角+俯仰角”进行图像文件命名。
。并在生成仿真图像时以“巡检部位名称+水平角+俯仰角”进行图像文件命名。
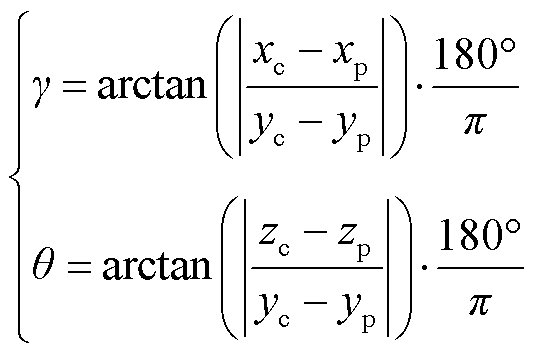 (5)
(5)
2)相机位姿计算
(1)相机坐标系单位向量计算
设相机坐标系单位向量分别为Xe、Ye、Ze,由于相机坐标系z轴由光心指向目标,根据式(6)计算Ze,再根据正交原则计算Xe、Ye。
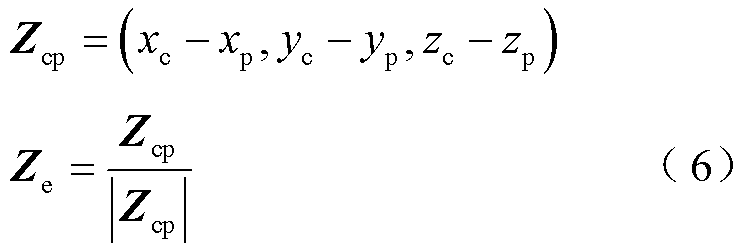
(2)旋转矩阵R计算
根据R的几何意义,R中的第i个行向量,表示相机坐标系中第i个坐标轴的单位向量在世界坐标系中的坐标,由此得到旋转矩阵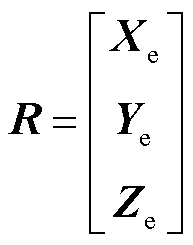 。
。
(3)平移矩阵T计算
根据T的几何意义,T表示世界坐标系原点在摄像机坐标系的坐标。易知-RTT为相机坐标系原点在世界坐标系坐标,由式(7)计算平移矩阵。
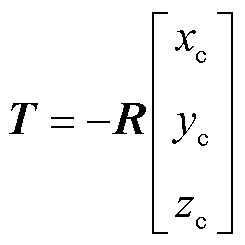 (7)
(7)
4.2.3 基于投影的仿真图像生成
由多角度相机位置转换得到相机位姿集合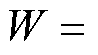
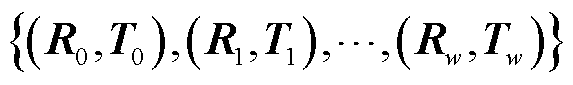 。根据相机成像原理,通过投影得到多角度杆塔巡检仿真图像,如图5所示。仿真图像不仅具有多角度成像特征,背景贴图天空、草地等环境因素也随位姿而发生变化,符合实际成像特点。
。根据相机成像原理,通过投影得到多角度杆塔巡检仿真图像,如图5所示。仿真图像不仅具有多角度成像特征,背景贴图天空、草地等环境因素也随位姿而发生变化,符合实际成像特点。

图5 多角度电力杆塔巡检仿真图像
Fig.5 Multi-angle power tower simulated inspection images
对于多角度投影生成的大量仿真图像,采用人工标注的方式进行多尺度目标标注费时费力且容易出错。本文提出了基于遮挡判别的目标包围盒重投影的自动标注算法,步骤如下。
4.3.1 检测目标空间包围盒计算
根据三维电力杆塔系统模型,计算金具目标群内待检测目标三维空间包围盒。金具目标群包围盒通过其部件的三维空间包围盒进行计算。
4.3.2 基于包围盒重投影的目标标注框生成
对于每张仿真图像,设其投影位姿为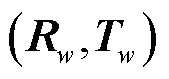 ,图像中待检测目标集合为S,第i个待检测目标Si三维空间包围盒顶点集为
,图像中待检测目标集合为S,第i个待检测目标Si三维空间包围盒顶点集为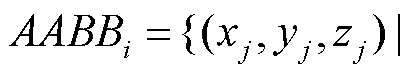
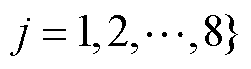 。将包围盒顶点集
。将包围盒顶点集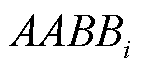 按位姿重投影至二维图像得到包围盒重投影点集合
按位姿重投影至二维图像得到包围盒重投影点集合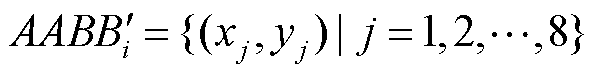 ,计算最小外接矩形框,作为待检测目标Si的重投影标注框。
,计算最小外接矩形框,作为待检测目标Si的重投影标注框。
4.3.3 基于包围盒可见性判别遮挡目标标注框去除
考虑到小尺度目标销钉和螺栓头部,其因体积小可能在投影时被遮挡,利用包围盒重投影的标注框生成方法会得到错误的标注结果。因此,增加对小尺度目标的包围盒可见性判别,进行目标标注框的保留与去除,算法步骤如下。
1)三维电力杆塔系统模型处理
构建具有类别区分色的销钉和螺栓头部三维空间包围盒模型,导入三维电力杆塔系统模型中。将三维电力杆塔系统模型中其余金具模型设置属性为投影不可见,但保留对销钉及螺栓头部包围盒模型的遮挡效果。
2)着色包围盒重投影及颜色识别
将销钉和螺栓头部着色包围盒模型按仿真图像位姿投影生成图像。利用图像处理技术将图像RGB颜色空间转换为HSV(hue, saturation, value)颜色空间,对图像中彩色区域进行识别,每个颜色区域代表一个目标,得到两种类别对应颜色的区域轮廓集合。分别遍历两种类别颜色对应的区域轮廓集合,计算轮廓区域的最小外接矩形,得到区域轮廓框。
3)不可见目标标注框去除
分别遍历销钉和螺栓头部重投影标注框集合,利用IoU计算每个标注框与对应类别的所有区域轮廓框相交程度,设最大值为IoUmax。若IoUmax小于给定阈值d,说明可见性不强,去除该重投影标注框,否则保留。
本文以典型带三角联板的耐张水平绝缘子串为实验对象。为充分验证本文提出的销钉唯一性识别方法的有效性,考虑到正常销钉和缺陷销钉在检测结果的相似性,本文在正常仿真数据集上进行了多角度位姿估计以及编号确定的验证实验,并在正常实拍数据集上进行了编号确定的验证实验。
5.1.1 实验流程
仿真实验按图2融合深度学习与三维重投影的销钉唯一性识别详细框架进行。在本文研究对象的金具组成中,三角联板是巡检部位内的共有金具,且邻域内销钉及三角联板上的螺栓头部数量可以满足位姿计算条件。因此本文以三角联板作为相机位姿估计中的特定目标金具,且仅需识别三角联板上的螺栓头部,并采取“螺栓头部优先,销钉补充”作为小尺度目标检测框选取策略。本文使用的P3P算法见文献[19]。
5.1.2 实验设置
本文采用第4节所描述的三维电力杆塔系统模型进行实验,根据本文提出的多角度仿真图像生成方法及自动标注技术,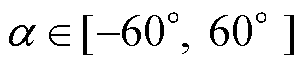 ,间隔10°取值;
,间隔10°取值;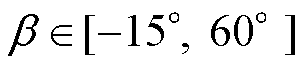 ,间隔15°取值;拍摄左相和右相绝缘子时r设为3 m,拍摄中相时r设为5 m;自动标注遮挡判定阈值d=0.5。对三维电力杆塔系统模型12个巡检部位生成分辨率大小为5 472×3 648的共计870张仿真巡检图像,将各个部位按8:1:1进行随机划分并组合,构建仿真图像数据集,其中训练集704张,验证集88张,测试集78张。
,间隔15°取值;拍摄左相和右相绝缘子时r设为3 m,拍摄中相时r设为5 m;自动标注遮挡判定阈值d=0.5。对三维电力杆塔系统模型12个巡检部位生成分辨率大小为5 472×3 648的共计870张仿真巡检图像,将各个部位按8:1:1进行随机划分并组合,构建仿真图像数据集,其中训练集704张,验证集88张,测试集78张。
在硬件配置为NVIDA GeForce GTX 2080Ti, 43 GB内存,Ubuntu操作系统,Pytorch深度学习框架的远程服务器上进行YOLOv5模型的多尺度目标检测训练和测试。训练时设置BatchSize大小为2,迭代次数为100Epoch,采用模拟余弦退火曲线调整学习率。设置阈值ε=0.6,对小于该阈值的检测框进行滤除。
将训练后的YOLOv5模型部署在CPU型号为AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz,GPU型号为NVIDIA GeForce RTX 3050 Laptop GPU的计算机上对测试集图像进行销钉唯一性识别实验。
5.1.3 评价指标
1)精确率、召回率、AP、mAP
精确率、召回率、AP、mAP是目标检测算法常用评价指标,AP是指每个类别的平均精确度,mAP则为所有类别AP的平均值。其中精确率、召回率、AP用来评价目标检测算法对每类目标的分类性能,mAP为各类AP的均值用于评价目标检测算法整体的分类性能。
2)水平角误差 、俯仰角误差
、俯仰角误差![]()
根据相机最优位姿计算水平角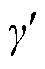 、俯仰角
、俯仰角![]() ,由式(8)计算、
,由式(8)计算、![]() 。
。
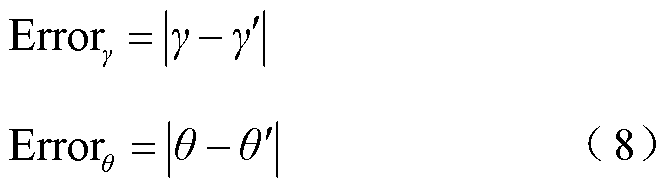
3)唯一性识别正确率
本文在YOLOv5模型输出的检测框基础上进行销钉唯一性识别正确率计算。设金具目标群检测框内销钉检测框总数为Nall,最终输出的销钉检测框编号与实际对应销钉编号一致的为唯一性识别正确销钉,设其总数为![]() 。销钉唯一性识别正确率
。销钉唯一性识别正确率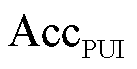 计算公式为
计算公式为
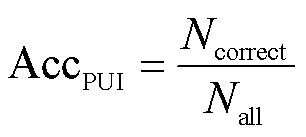 (9)
(9)
5.1.4 正常销钉数据集实验结果及分析
1)YOLOv5模型检测结果及分析
本文在测试集78张图像上进行销钉唯一性实验,YOLOv5模型检测结果见表1。mAP结果为0.958,说明多尺度目标检测效果整体较好。
表1 基于YOLOv5模型仿真图像目标检测结果
Tab.1 Object detection results of simulated image based on YOLOv5 model

类别名称精确率召回率AP 横担端0.8910.9290.916 导线端0.9741.00.995 三角联板0.8580.9630.963 三角联板上螺栓头部0.9340.9490.961 销钉0.9130.9380.954
以小号侧右相导线端某仿真图像检测结果为例,如图6所示。首先利用金具目标群检测框,筛选出在其内部的销钉及上下文相关目标。利用三角联板检测框,得到相交的3个螺栓头部检测框以及1个销钉检测框,计算2D特征点。结合三维空间中心点坐标,经排列组合构成2D-3D特征点匹配解空间,大小为3×2×1×5=30,其中3×2×1为三角联板上螺栓头部的组合数,5为三角联板邻域内的销钉数量。对解空间中每组2D-3D特征点利用P3P算法计算相机位姿得到位姿集合。根据2个2D特征点和6个3D特征点计算重投影偏离误差,进行最优位姿的筛选。
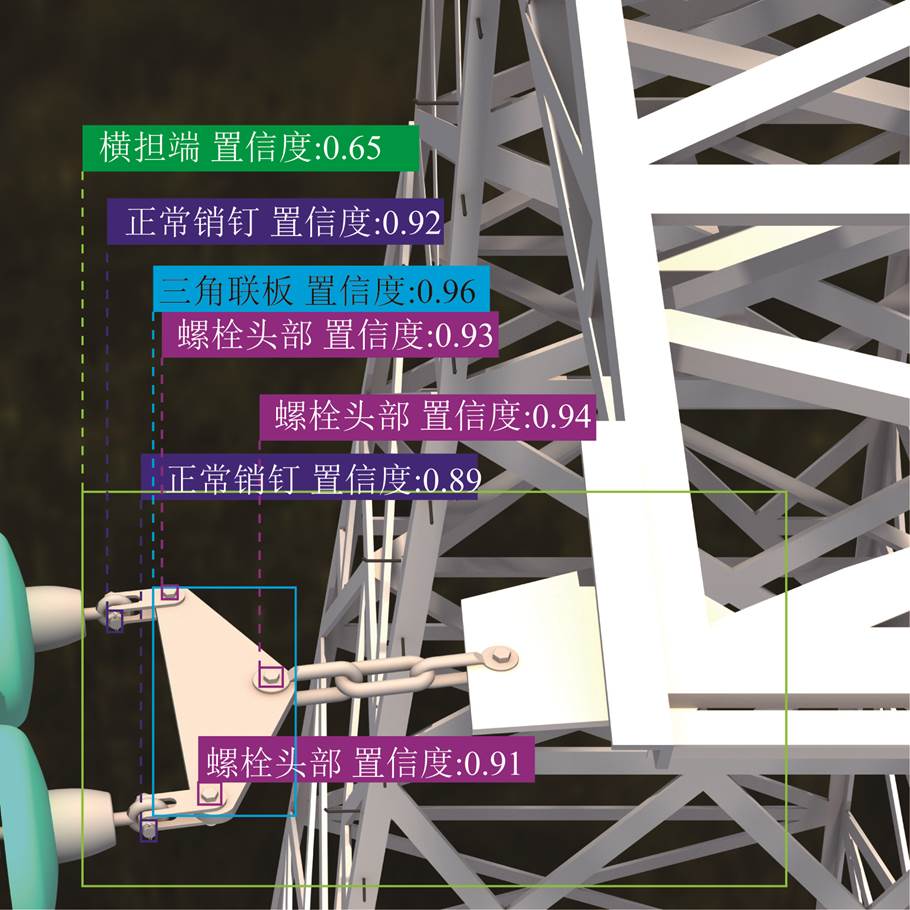
图6 仿真图像多尺度目标检测结果
Fig.6 Multi-scale target detection results of simulated images
2)唯一性识别结果
在测试集78张图片中,有4张图片因位姿较为极端不满足位姿计算条件,其余74张图片经本文所提的融合结构约束的相机位姿估计算法得到水平角平均误差为0.57°,俯仰角平均误差为0.74°,销钉唯一性正确识别率为100%。说明在基于YOLOv5模型得到的销钉检测框基础上,对销钉进行编号确定,其结果与巡检部位内编号全部一致。
3)算法运行效率分析
表2展示了在5.1.2节的实验环境下,对测试集仿真图像进行唯一性识别计算的分步平均运行时间,步骤之间是连续并自动完成的。可以看出,本文研究方法在常规目标检测方法基础上增加的唯一性识别步骤运行时间占总时长的2.54%,几乎可以忽略不计。
表2 销钉唯一性识别框架分步运行时间对比
Tab.2 Pin uniqueness identification framework step-by-step runtime

步骤名称平均运行时间/ms 基于YOLOv5网络目标检测方法514.3 融合结构约束的图像位姿估计13.1 包围盒重投影0.31 重投影框与销钉检测框匹配0.01
5.1.5 缺陷销钉数据集实验结果
本文构造缺陷销钉仿真数据集按上述流程进行唯一性识别实验,图7分别为对小号侧右相导线端和大号侧左相横担端多角度缺陷销钉仿真图像唯一性识别结果。其中小号侧右相导线端3张图像中均标注出同一脱销销钉,大号侧左相横担端有2张图像对2个缺陷销钉进行重复标注。利用本文的销钉唯一性识别方法,可以将同一部位多张图像中同一缺陷销钉对应起来,并自动统计出该巡检部位缺陷销钉的数量以及具体的位置信息。
5.2.1 实验设置
为验证本文所提方法的实际可行性,本文利用110 kV干字型耐张杆塔无人机航拍图像进行正常销钉编号确定实验,图像分辨率大小为4 864×3 648。本文从实拍图像中筛选出由相同类别金具组成的横担端和导线端拍摄图像共计50张作为测试集,并根据金具目标群结构组成和绝缘子串延伸方向的一致性将其分为四类:横担端1、横担端2、导线端1、导线端2,每类看作对同一巡检部位从不同位姿角度进行拍摄得到的图像集。其余图像随机划分成训练集145张,验证集40张,采用手工标注方式对待检测目标进行打标。
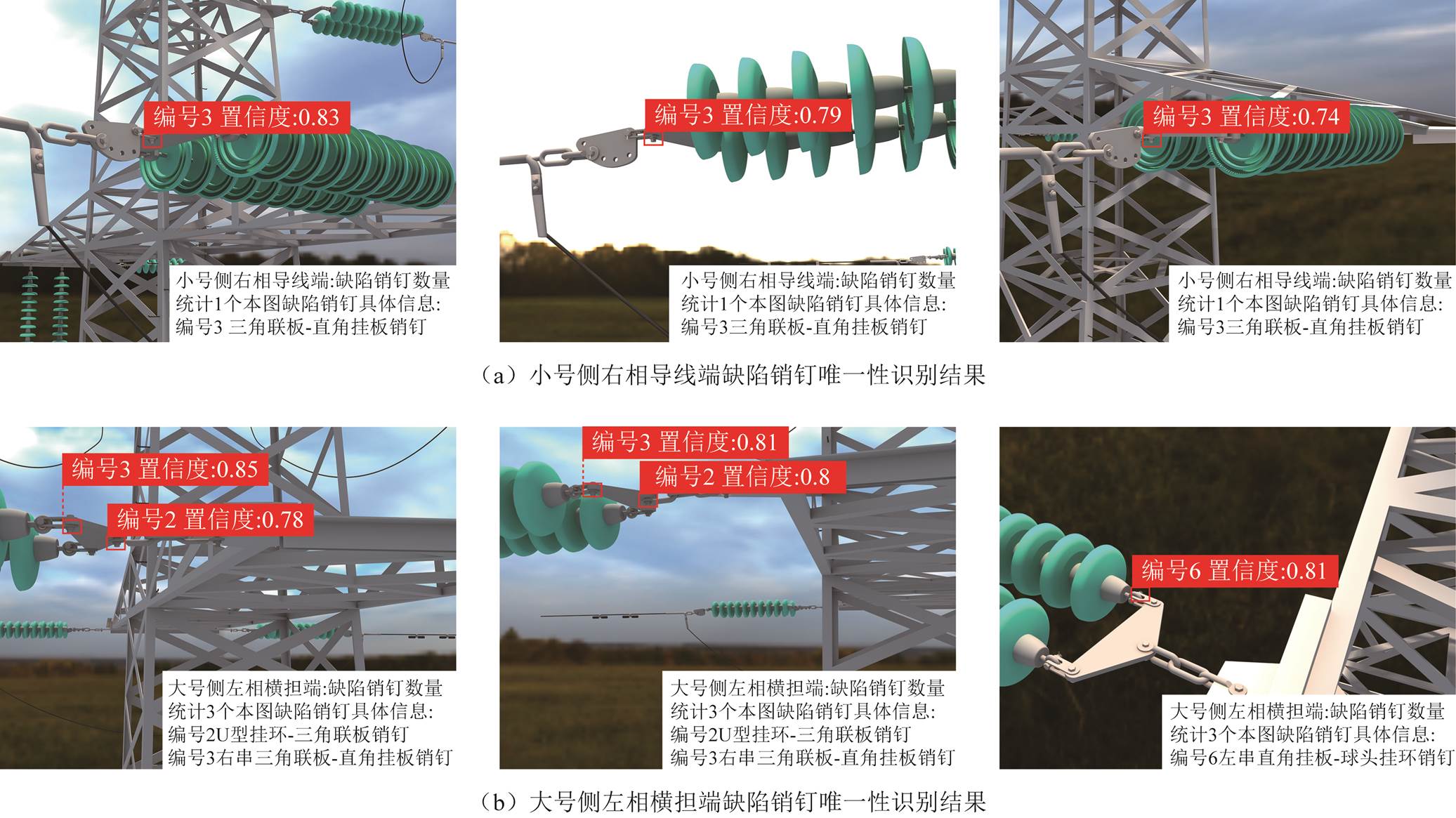
图7 仿真缺陷销钉图像唯一性识别结果
Fig.7 Defective pin uniqueness identification results of simulated images
本文借鉴迁移学习[20]的方法对实拍图像进行训练,以仿真实验的训练结果作为YOLOv5模型初始参数,然后在实拍图像数据集继续训练。
由于未获取完整的杆塔信息,不同于仿真实验研究建立以杆塔底部中心点为原点的世界坐标系,在实拍图像上进行实验时,根据图样等规范资料构建金具串三维模型获取各部件包围盒顶点、中心点坐标及编号信息。
5.2.2 YOLOv5模型检测结果及分析
基于YOLOv5模型的实拍图像目标检测结果见表3。根据表3结果,在实拍图像上采用YOLOv5模型进行多尺度目标检测结果依然较好,mAP值为0.987。
表3 基于YOLOv5模型的实拍图像目标检测结果
Tab.3 Object detection results of real images based on YOLOv5 model

类别名称精确率召回率AP 横担端1.00.8910.995 导线端0.9650.9580.992 三角联板0.9751.00.991 三角联板上螺栓头部0.9260.9650.973 销钉0.9460.9510.984
5.2.3 实拍图像销钉唯一性识别结果
唯一性识别结果见表4。由表4结果可知,本文所提的融合深度学习与三维重投影的销钉唯一性识别框架有效地解决了实拍图像中销钉编号的确定问题,mAP值为93.3%。
表4 实拍图像销钉唯一性识别结果
Tab.4 Pin uniqueness identification results of the real image

巡检部位数量/张Ncorrect/个Nall/个AccPUI(%) 横担端113525594.5 横担端213545893.1 导线端11211011992.4 导线端21211011893.2
在电力杆塔系统具体施工时,实际目标三维空间点与三维模型建模参数存在一定偏差,本文提出的算法在绝大多数情况依然具有一定鲁棒性,能得到正确的销钉编号识别结果。部分实际航拍图像的销钉唯一性识别结果如图8所示。


图8 实拍图像销钉唯一性识别结果
Fig.8 Pin uniqueness identification results for real images
常规基于深度学习的图像空间缺陷销钉检测算法无法自动确定检测目标的唯一性编号,对于巡检部位内多张图像多次标注同一缺陷的需经人工二次辨别后才能统计出准确的缺陷数量及位置。针对该问题,本文提出一种销钉唯一性识别方法。通过对实拍图像进行验证,其唯一性识别正确率为93.3%。本文贡献总结如下:
1)本文提出一种融合深度学习与三维重投影的销钉唯一性识别方法。首先构建三维电力杆塔系统模型获取部件包围盒顶点、中心点坐标以及编号;然后利用常规目标检测网络对图像空间销钉及上下文相关目标进行检测,再根据本文提出的融合结构约束的位姿估计算法对相机位姿进行估计;最后将带编号的销钉包围盒按位姿进行重投影,与销钉检测框进行匹配,在图像空间输出销钉检测结果以及编号。
2)本文研究方法不仅有利于运维人员对巡检部位内多张图像多次标注的同一缺陷进行快速辨别,提高运维人员对缺陷图像二次审查效率,还能根据编号与位置的对应关系自动统计出该巡检部位中准确的缺陷销钉数量与具体位置信息,为后续故障维修及故障相关性分析等精细化管理操作提供指导。
3)本文提出的相机位姿估计算法在一定程度上依赖多目标检测精度和三维空间点计算的准确性,未来将进一步优化算法,使得在计算相机位姿时算法鲁棒性更强。此外本文主要针对销钉做唯一性识别研究,未来将考虑对其他金具的唯一性识别进行研究。
参考文献
[1] 郑含博, 李金恒, 刘洋, 等. 基于改进YOLOv3的电力设备红外目标检测模型[J]. 电工技术学报, 2021, 36(7): 1389-1398.
Zheng Hanbo, Li Jinheng, Liu Yang, et al. Infrared object detection model for power equipment based on improved YOLOv3[J]. Transactions of China Electrotechnical Society, 2021, 36(7): 1389-1398.
[2] 王卓, 王玉静, 王庆岩, 等. 基于协同深度学习的二阶段绝缘子故障检测方法[J]. 电工技术学报, 2021, 36(17): 3594-3604.
Wang Zhuo, Wang Yujing, Wang Qingyan, et al. Two stage insulator fault detection method based on collaborative deep learning[J]. Transactions of China Electrotechnical Society, 2021, 36(17): 3594-3604.
[3] 徐建军, 黄立达, 闫丽梅, 等. 基于层次多任务深度学习的绝缘子自爆缺陷检测[J]. 电工技术学报, 2021, 36(7): 1407-1415.
Xu Jianjun, Huang Lida, Yan Limei, et al. Insulator self-explosion defect detection based on hierarchical multi-task deep learning[J]. Transactions of China Electrotechnical Society, 2021, 36(7): 1407-1415.
[4] 宋立业, 刘帅, 王凯, 等. 基于改进EfficientDet的电网元件及缺陷识别方法[J]. 电工技术学报, 2022, 37(9): 2241-2251.
Song Liye, Liu Shuai, Wang Kai, et al. Identification method of power grid components and defects based on improved EfficientDet[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2241-2251.
[5] 王建, 吴昊, 张博, 等. 不平衡样本下基于迁移学习-AlexNet的输电线路故障辨识方法[J]. 电力系统自动化, 2022, 46(22): 182-191.
Wang Jian, Wu Hao, Zhang Bo, et al. Fault identificationmethod for transmission line based on transfer learning-AlexNet with imbalanced samples[J]. Automation of Electric Power Systems, 2022, 46(22): 182-191.
[6] 李雪峰, 刘海莹, 刘高华, 等. 基于深度学习的输电线路销钉缺陷检测[J]. 电网技术, 2021, 45(8): 2988-2995.
Li Xuefeng, Liu Haiying, Liu Gaohua, et al. Transmission line pin defect detection based on deep learning[J]. Power System Technology, 2021, 45(8): 2988-2995.
[7] 李瑞生, 张彦龙, 翟登辉, 等. 基于改进SSD的输电线路销钉缺陷检测[J]. 高电压技术, 2021, 47(11): 3795-3802.
Li Ruisheng, Zhang Yanlong, Zhai Denghui, et al. Pin defect detection of transmission line based on improved SSD[J]. High Voltage Engineering, 2021, 47(11): 3795-3802.
[8] 王红星, 翟学锋, 陈玉权, 等. 基于改进Cascade R-CNN的两阶段销钉缺陷检测模型[J]. 科学技术与工程, 2021, 21(15): 6373-6379.
Wang Hongxing, Zhai Xuefeng, Chen Yuquan, et al. Two-stage pin defect detection model based on improved cascade R-CNN[J]. Science Technology and Engineering, 2021, 21(15): 6373-6379.
[9] Jiao Runhai, Liu Yanzhi, He Hui, et al. A deep learning model for small-size defective components detection in power transmission tower[J]. IEEE Transactions on Power Delivery, 2022, 37(4): 2551-2561.
[10] 戚银城, 武学良, 赵振兵, 等. 嵌入双注意力机制的Faster R-CNN航拍输电线路螺栓缺陷检测[J]. 中国图象图形学报, 2021, 26(11): 2594-2604.
Qi Yincheng, Wu Xueliang, Zhao Zhenbing, et al. Bolt defect detection for aerial transmission lines using Faster R-CNN with an embedded dual attention mechanism[J]. Journal of Image and Graphics, 2021, 26(11): 2594-2604.
[11] 文师华. 输电线路防振锤复位机器人目标识别及定位方法研究[D]. 沈阳: 沈阳航空航天大学, 2020.
[12] 胡国雄. 输电线路航拍图像目标检测算法研究[D]. 南京: 南京航空航天大学, 2019.
[13] 陈鑫. 基于无人机航拍的电力线故障定位算法研究[D]. 青岛: 山东科技大学, 2018.
[14] 高伟, 何搏洋, 张婷, 等. 基于注意力机制的变电站作业场景三维目标检测[J]. 激光与光电子学进展, 2022, 59(22): 165-173.
Gao Wei, He Boyang, Zhang Ting, et al. Three-dimensional object detection in substation operation scene based on attention mechanism[J]. Laser & Optoelectronics Progress, 2022, 59(22): 165-173.
[15] 张婷, 张兴忠, 王慧民, 等. 基于图神经网络的变电站场景三维目标检测[J]. 计算机工程与应用, 2023, 59(9): 329-336.
Zhang Ting, Zhang Xingzhong, Wang Huimin, et al. 3D object detection in substation scene based on graph neural network[J]. Computer Engineering and Applications, 2023, 59(9): 329-336.
[16] Glenn J, Alex S, Jirka B. YOLOv5[CP/OL]. (2022-02-22). [2023-03-25]. https://github.com/ultralytics/yolov5
[17] 周佳乐, 朱兵, 吴芝路. 融合二维图像和三维点云的相机位姿估计[J]. 光学精密工程, 2022, 30(22): 2901-2912.
Zhou Jiale, Zhu Bing, Wu Zhilu. Camera pose estimation based on 2D image and 3D point cloud fusion[J]. Optics and Precision Engineering, 2022, 30(22): 2901-2912.
[18] 王平, 付辉, 徐贵力. 基于旋转搜索的相机位姿估计和对应点匹配[J]. 航空学报, 2023, 44(2): 296-307.
Wang Ping, Fu Hui, Xu Guili. Camera pose estimation and corresponding points matching based on rotation search[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(2): 296-307.
[19] Ke Tong, Roumeliotis S I. An efficient algebraic solution to the perspective-three-point problem[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 4618-4626.
[20] 仲林林, 胡霞, 刘柯妤. 基于改进生成对抗网络的无人机电力杆塔巡检图像异常检测[J]. 电工技术学报, 2022, 37(9): 2230-2240, 2262.
Zhong Linlin, Hu Xia, Liu Keyu. Power tower anomaly detection from unmanned aerial vehicles inspection images based on improved generative adversarial network[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2230-2240, 2262.
Abstract With the development of artificial intelligence technology, defect pin detection technology based on deep learning has been widely applied in the field of power tower inspection. However, this technology can only locate the defect pin in the image space, but cannot provide a unique number for the defect pin in the actual power tower, and cannot automatically determine the actual position of the defect pin. Moreover, for multi-angle images of the same part, the defect pin detection algorithm using depth learning may repeatedly label the same defect pin, which may cause repeated statistics of defect pins.
To address this issue, this paper proposes a pin uniqueness identification method that integrates deep learning and 3D reprojection, which is essentially an extension of the 2D object detection task. Firstly, a three-dimensional model of the inspection power tower system is constructed to obtain vertices and center points of the components 3D space bounding box, and unique number of the components in the power tower system. Then, the YOLOv5 model is used to detect pins and contextual sensitive targets in the image space. The contextual targets include a group of large-scale hardware, a mesoscale specific hardware, and a small-scale bolt head. Filter detection results that are not within the inspection area by using the hardware target group bounding box. Then use the camera pose estimation algorithm that integrates structural constraints proposed in this article to estimate the camera pose of the image. Use the center points of the pins and bolt heads 2D bounding boxes as 2D feature points, and the center point of the pins and bolt heads 3D space bounding boxes as 3D feature point to form point-to-point constraints. Use P3P algorithm for camera pose estimation. For the unknown 2D-3D correspondence, four 2D feature points are selected by using the specific hardware bounding box, and the matching solution space of 2D-3D feature points is constructed by enumeration method. Calculate the camera pose for each solution separately, and use the deviation error of reprojection to choose the optimal pose. Finally, the numbered pin 3D space bounding box will be reprojected according to the optimal pose, and the matching degree will be calculated with the pin bounding box. The number of the reprojection box with the highest matching degree will be selected as the number of the pin bounding box, and the pin bounding box with unique number will be output in the image space.
In addition, the article also proposes a method for generating multi-pose simulation images and an label automatic generation technology based on occlusion detection, which is used to achieve automatic construction of simulation image datasets. The pin uniqueness identification accuracy of the evaluation index in this article is calculated based on the YOLOv5 model detection results. Experiments on simulated images gets 100% pin uniqueness identification accuracy, while experiments on real images gets 93.3%. By defect pin uniqueness identification, the bounding box with unique number of pins are output in the image space, and automatically count the total and specific position of defect pins in the inspection area based on the corresponding relationship between the number and position information, it helps inspection personnel quickly identify defect pins in multiple inspection images of the same inspection area, and provides assistance for refined management such as fault maintenance and fault correlation analysis.
keywords:Power inspection, pin detection, camera pose estimation, uniqueness identification
中图分类号:TP181; TM75
DOI: 10.19595/j.cnki.1000-6753.tces.230760
国家自然科学基金资助项目(62073133)。
收稿日期 2023-05-25
改稿日期 2023-07-14
阎光伟 1971年生,男,副教授,硕士生导师,研究方向为计算机图形/图像技术在电力系统中的应用等。
E-mail:yan_guang_wei@126.com(通信作者)
马颐琳 1999年生,女,硕士研究生,研究方向为计算机图形/图像技术在电力系统中的应用等。
E-mail:120212227125@ncepu.edu.cn
(编辑 赫 蕾)