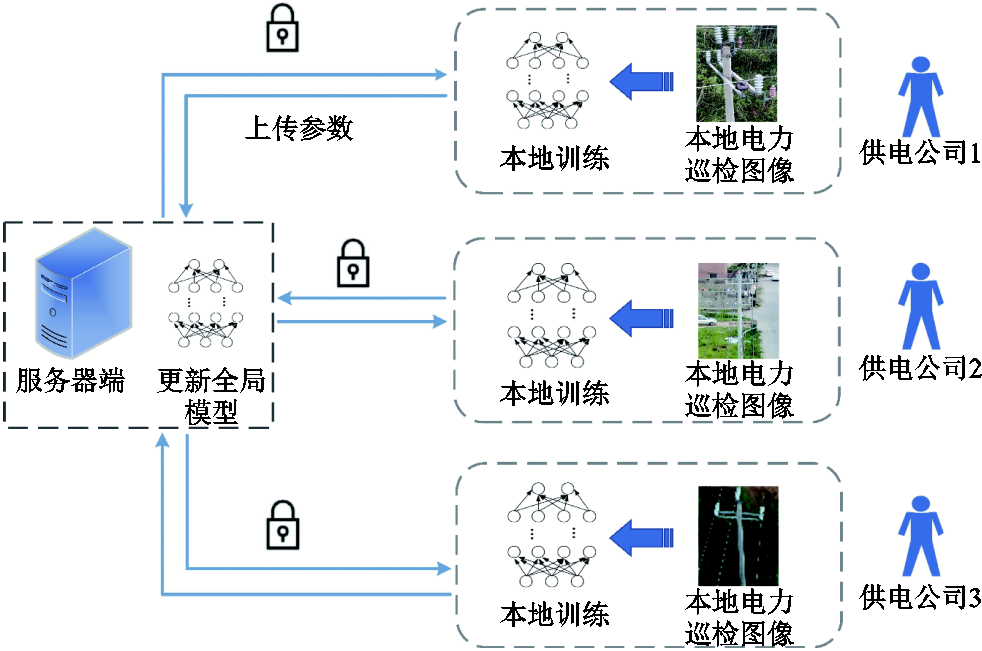
图1 面向电力巡检图像目标检测的联邦学习流程
Fig.1 The federated learning process for object detection of power inspection images
摘要 基于深度学习的目标检测算法能够高效处理电力巡检图像,及时发现故障隐患。然而,由于数据整合困难及数据隐私保护等原因,单个电力公司或第三方机构可能不足以训练出高性能模型。为解决这一问题并激励更多参与方加入面向电力巡检图像目标检测的联邦学习,该文构建了基于模型公平和基于收益公平的电力巡检图像目标检测联邦激励机制。基于模型公平的激励机制适用于所有参与方都是数据拥有方的情况,通过贡献评估分配不同性能的模型;基于收益公平的激励机制针对同时存在数据拥有方和数据需求方的模式,数据拥有方获得相应的收益,而数据需求方获得高性能模型。实验结果显示,在这两种激励机制中,公平性相关系数分别可达到0.96和1。这表明所提出的激励机制可有效地提升公平性,并能够激励更多的参与方加入到面向电力巡检图像目标检测的联邦学习中。
关键词:电力巡检 目标检测 联邦学习 激励机制 公平性
为了确保电力系统的安全稳定运行,电力公司需要开展常态化的电力巡检以确定电力线路和设备的运行状态,避免导致人身和财产损失的重大电力事故[1-5]。然而,来自单个电力公司采集的数据其数量和类型有限,电力巡检图像数据以“数据孤岛”的形式存在于各个电力公司中,将全部数据整合在一起可行性差、效率低,无法通过数据驱动的深度学习方法训练得到高性能模型[6-7]。此外,由于数据隐私规定,电力公司收集的电力巡检图像数据不允许与他人共享,限制了研究学者和第三方机构获取相关数据,难以构建和改进面向电力巡检图像处理的深度学习模型[8]。
联邦学习作为一种新兴的分布式技术,能够在保护数据隐私的前提下,通过参与方之间的协同构建高性能模型,因此可以高效地应用在电力巡检视觉任务中[9-10]。在传统的联邦学习中,最终分发给各个参与方的是一个具有相同性能的全局模型(即不同参与方获得了相同的回报),并未考虑不同参与方对联邦的贡献差异。但是在真实场景中,不同参与方提供的电力巡检图像数据的数量、质量、成本代价等是不同的,对于最终目标检测模型训练结果的贡献也是不同的。如果参与联邦学习的参与方不能得到公平合理的回报,会引起部分参与方不愿意加入电力巡检图像目标检测的联邦训练中,无法保证参与联邦学习的参与方数量,导致联邦训练无法继续或训练效果不佳。因此,在面向电力巡检图像目标检测的联邦学习中,为了激励更多的电力公司愿意加入到联邦机制中,提供高质量的电力巡检图像数据,从而进一步提升联邦学习的效果,构建一套公平合理的激励机制必不可少。
联邦学习的激励机制主要包括参与方贡献度衡量和收益分配两方面的设计[11]。目前,在针对参与方贡献度衡量的研究中,Wang Guan等[12]使用删除诊断和影响函数来衡量不同参与方的数据质量和贡献度。A. Richardson等[13]在此基础上提出了一种提高激励机制实用性的方法,通过计算影响函数的近似结果,保证近似结果与真实结果的误差在可承受范围内,并以此提高评估速度。除此之外,Kang Jiawen等[14]使用参与联邦学习的设备的CPU频率、CPU使用轮数和本地模型迭代次数等属性计算设备的资源消耗,作为贡献度的衡量指标。在收益分配方案中,Zhang Jingfeng等[15]提出了分层公平联邦学习框架(Hierarchically Fair Federated Learning, HFFL),根据贡献度的大小划分参与方等级,通过给予贡献度较多的参与方更高的等级以及分配更高性能模型的方式,确保参与方之间的公平性。不同于为每个等级分配相同性能的模型,Lyu Lingjuan等[16]提出了公平和隐私保护深度学习(Fair and Privacy-Preserving Deep Learning, FPPDL)框架,每个客户端通过参与方之间的相互评估获得信誉,并基于自己的贡献获得不同性能的模型。文献[17]则根据各参与方本地模型训练的精度计算得到信誉值,并根据信誉值的大小下载对应数量的梯度值作为收益回报,更新自己的本地模型。Yu Han等[18]提出了一种联邦学习激励机制(Federated Learning Incentive, FLI),该机制从各个参与方的贡献度、成本和遗憾三种维度进行了量化,并综合以上三种公平指标确定最终的收益分配值。
目前,基于联邦学习的激励机制研究还不够完善,缺乏在实际数据场景中的应用。在面向电力巡检图像目标检测的联邦学习中,还没有针对其在实际场景中的激励机制设计。因此,研究面向电力巡检图像目标检测的联邦学习激励机制,对于保证该联邦机制长久稳定运行具有重要意义。
基于以上分析,本文提出了面向电力巡检图像目标检测任务的联邦激励机制。主要贡献包括:①针对参与方全部为数据拥有方的模式,提出了基于模型公平的电力巡检图像目标检测激励机制。在该机制下,参与方基于各自的贡献度获得不同性能的模型。②针对同时存在数据拥有方和数据需求方的模式,提出了基于收益公平的电力巡检图像目标检测激励机制。在该机制下,数据拥有方通过贡献电力巡检图像数据获得一定的收益;数据需求方缺乏数据,通过一定的资金成本投入获得高性能的电力巡检图像目标检测模型。最后,通过实验证明了两种激励机制的有效性,本文所提联邦激励机制可提升基于联邦学习的电力巡检图像目标检测任务的公平性。
联邦学习作为一种分布式机器学习方法,允许多个参与方协作训练机器学习模型,而无需共享他们的数据。每个参与方利用本地数据集训练模型,将更新的模型权重上传至服务器进行参数聚合和更新。同时,可以通过加密手段(如差分隐私[19]和同态加密[20]方法)在模型参数传递的过程中对信息进行保护。在联邦学习训练期间,各个参与方在协同构建全局模型的同时,始终将自己的数据集保留在本地,很好地满足了数据隐私保护的要求。
面向电力巡检图像目标检测的联邦学习流程如图1所示[21]。服务器端首先初始化全局模型参数,然后将初始全局模型参数分发给客户端。每个客户端基于接收到的全局模型参数,使用本地数据集更新本地模型,更新后的本地模型参数将被发送到服务器端进行参数聚合。服务器聚合来自客户端的本地更新参数,并用平均模型替换全局模型,然后将更新的全局模型参数发送回客户端进行新一轮的训练。
图1 面向电力巡检图像目标检测的联邦学习流程
Fig.1 The federated learning process for object detection of power inspection images
激励就是通过适当的形式激发、引导个体做某些特定行为。激励是所有经济活动的核心,可分为积极激励和消极激励。前者旨在通过承诺奖励来激励他人;而后者则通过惩罚个人来避免恶意行为。
联邦学习在实际应用场景中势必存在各方的利益交换,数据作为一种特殊形态的资产,需要被合理地定价,并给予各个参与方相应的激励。如果参与联邦学习的参与方不能得到公平合理的回报,那么在实际场景中就很难保证参与联邦学习的参与方的数量。因此,构建一套合理的分配机制,不仅可以保证联邦学习机制长久稳定运行,还能激励更多的机构参与到联邦学习中,提高联邦学习的效果,保证数据市场长久发展[22-26]。
在面向电力巡检图像目标检测的联邦学习中,为了激励更多的参与方加入联邦机制中,进一步提升联邦学习的效果,构建一套公平合理的激励机制必不可少。本节首先研究针对参与方本地电力巡检图像数据贡献度的衡量方法,然后在此基础上,分别研究基于模型公平和基于收益公平的电力巡检图像目标检测联邦激励机制。
2.1.1 直接评估法
直接评估法即根据客户端拥有数据的数量、类别量等因素,计算各个客户端的贡献度[27]。在评估中,可以分为单维度和多维度两种贡献衡量方法。
在单维度贡献衡量方法中,若客户端i拥有的数据量为Di,其贡献度Ci表示为
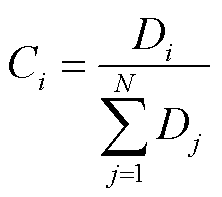 (1)
(1)
式中,N为参与联邦学习的客户端数量。
若客户端i拥有的数据类别量为vi,则其贡献度Ci表示为
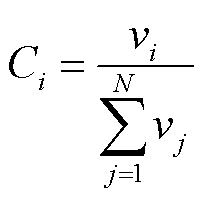 (2)
(2)
在多维度贡献衡量方法中,若客户端i拥有的数据量为Di,类别量为vi,其贡献度Ci表示为
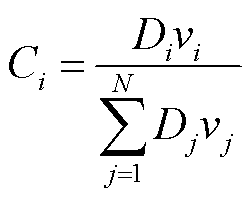 (3)
(3)
2.1.2 边际效用评估法
边际效用评估法即根据客户端可以产生的效益来计算贡献度。在基于客户端单方训练的贡献度衡量中,客户端i基于自己本地的电力巡检图像数据集训练得到模型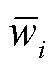 ,根据模型的性能可以获得客户端i单方训练的效益
,根据模型的性能可以获得客户端i单方训练的效益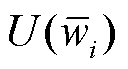 ,从而计算得到客户端i在联邦学习中的贡献度Ci为
,从而计算得到客户端i在联邦学习中的贡献度Ci为
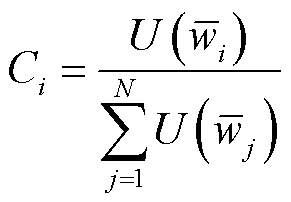 (4)
(4)
如果考虑动态轮次的变化,那么客户端i在第t轮联邦学习中的贡献度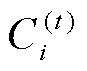 为
为
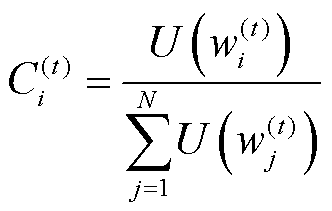 (5)
(5)
在基于影响函数的贡献度衡量中,客户端i的贡献度即为客户端加入联邦学习所带来的效用增益,可以表示为
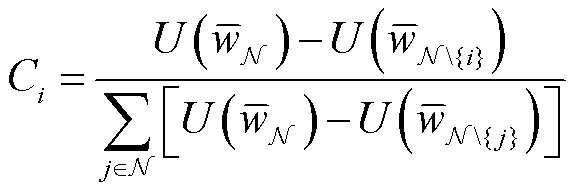 (6)
(6)
式中, 为所有N个客户端的集合;
为所有N个客户端的集合;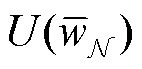 为所有N个客户端都参与联邦学习训练得到的模型 所带来的效益;
为所有N个客户端都参与联邦学习训练得到的模型 所带来的效益;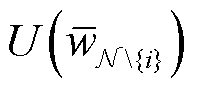 为除了客户端i以外的客户端都参与联邦学习训练得到的模型
为除了客户端i以外的客户端都参与联邦学习训练得到的模型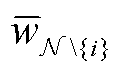 所带来的效益。
所带来的效益。
基于模型公平的联邦激励机制主要针对参与方全部为数据拥有方的模式。参与方在本地各自拥有部分电力巡检图像数据集,通过联邦激励机制,融合多方数据信息,协同训练出更优的电力巡检图像目标检测模型,并根据各自的贡献度得到不同性能的模型。
2.2.1 模型参数更新值分配方法
在服务器端聚合得到全局模型后,各个参与方将根据各自的贡献度得到模型的全部或部分参数更新值。在全局模型参数更新值分配的过程中采用最大值方法,即将模型的参数更新值按照从大到小的顺序排列,并按照各参与方的贡献度占比,分配给他们相应数量的模型参数更新值,用于各自本地模型的更新。全局模型参数分配方法如图2所示,假设参与方2相比参与方1计算得到的贡献度更高,根据他们的贡献度占比,分别获取相应数量的模型参数更新值,用于自己本地模型的更新。可以看到,参与方2能够比参与方1下载更多数量的全局模型参数更新值,从而更新得到性能更优的本地模型。
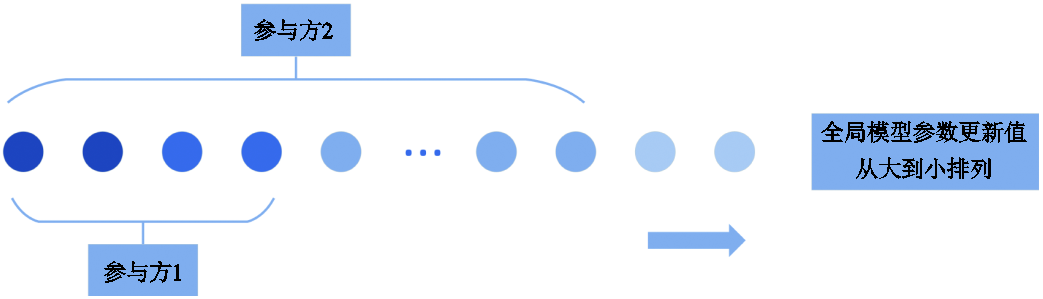
图2 全局模型参数分配方法
Fig.2 Global model paramter allocation method
2.2.2 算法流程
基于模型公平的联邦学习激励机制如图3所示。参与方使用本地电力巡检图像进行训练后,上传参数至服务器端进行贡献度评估。
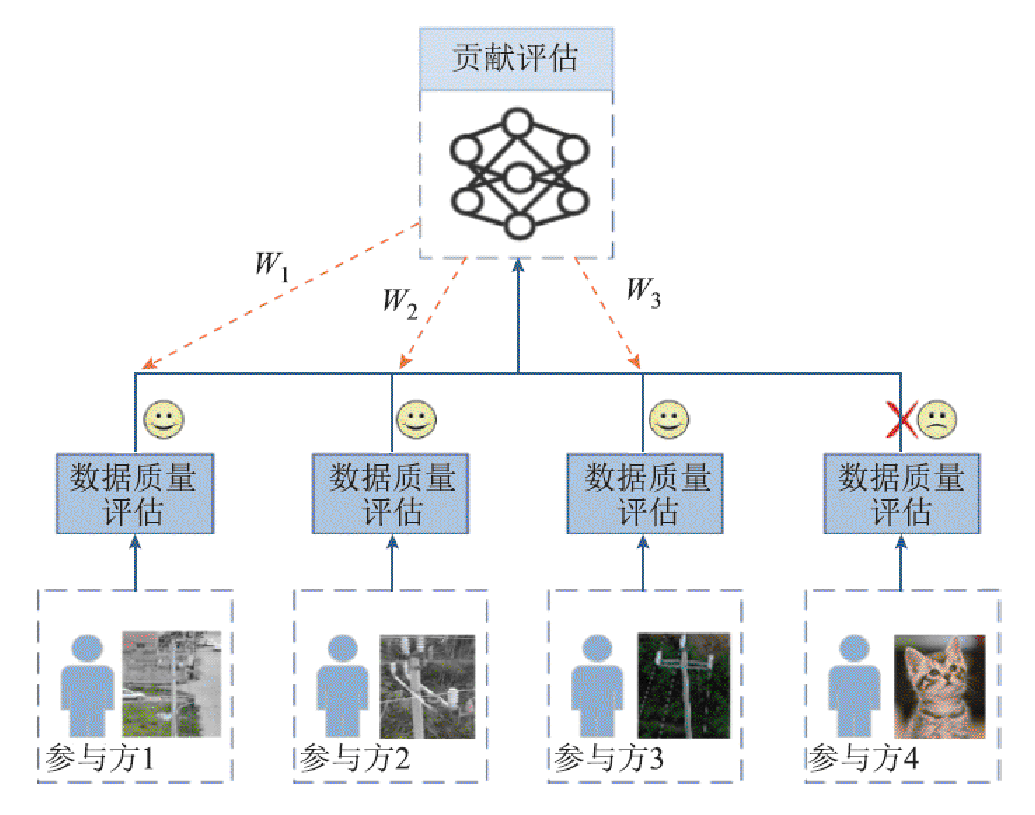
图3 基于模型公平的联邦学习激励机制
Fig.3 Model fairness incentive mechanism
基于模型公平的电力巡检图像目标检测联邦激励算法分为服务器端和客户端,采用原始联邦平均(Federal Average, FedAvg)算法[28]作为联邦训练过程的基本框架。算法流程分别见表1和表2。服务器端初始化全局模型参数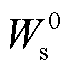 并发送给各客户端,客户端k通过本地训练后,计算得到模型参数的更新值
并发送给各客户端,客户端k通过本地训练后,计算得到模型参数的更新值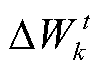 并发送给服务器端进行聚合。之后,服务器端通过聚合方法得到模型参数更新值
并发送给服务器端进行聚合。之后,服务器端通过聚合方法得到模型参数更新值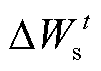 ,并根据各客户端的贡献度Ck,分配对应数量Mk的模型参数更新值
,并根据各客户端的贡献度Ck,分配对应数量Mk的模型参数更新值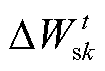 给客户端k。最终,客户端k基于分配得到的模型参数更新值进行本地模型更新,得到本地模型
给客户端k。最终,客户端k基于分配得到的模型参数更新值进行本地模型更新,得到本地模型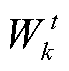 。为了更加清晰地描述联邦激励机制的流程,表1和表2中省略了数据加密和解密的相关步骤。
。为了更加清晰地描述联邦激励机制的流程,表1和表2中省略了数据加密和解密的相关步骤。
表1 基于模型公平的电力巡检图像目标检测算法:服务器端
Tab.1 The object detection algorithm for power inspection images based on model fairness: Server side

输入:通信轮数T,客户端数量K,模型初始权重。 过程:1:初始化目标检测全局模型参数2:Fort = 1,…, Tdo3: For客户端k = 1,…, Kdo4: 接收每个客户端本地训练后的模型参数更新值以及每个客户端的本地训练数据量5: End For6: 根据各参与方上传的模型参数更新值,聚合得到:

7: 8: 利用贡献度衡量方法计算得到各个参与方的贡献度Ck9: 根据贡献度,计算得到参与方k分配得到的模型参数更新值的数量:10: 11:根据聚合梯度分配方式,将对应数量Mk的参数更新值发送给客户端k12:End For结束过程 输出:聚合模型参数更新值以及各个客户端k分配得到的模型参数更新值。
表2 基于模型公平的电力巡检图像目标检测算法:客户端
Tab.2 The object detection algorithm for power inspection images based on model fairness: Client side

输入:通信轮数T,客户端k上轮本地模型参数,本地数据集Dk,各客户端k分配得到的梯度。 过程:1:Fort = 1,…, Tdo2: For每个客户端k:3: 计算当前每个客户端k的本地电力巡检图像数据集大小4: 在本地数据集上训练后得到本轮模型参数,并计算得到模型参数的更新值5: 发送本地训练数据量和模型参数更新值给服务器端6: 下载分配得到的模型更新值7: 结合更新值获得本轮最终更新后的模型8: End For9:End For结束过程 输出:客户端k的本地训练数据量,模型参数更新值以及更新后的模型参数。
在基于收益公平的联邦激励机制中,既存在数据提供方,又存在数据需求方。数据提供方拥有一定数量和质量的电力巡检图像数据,但不需要获得目标检测模型。数据需求方缺乏电力巡检图像数据,但需要得到相关的目标检测模型。结合联邦学习激励机制(FLI)[18],基于数据提供方的成本代价、数据质量以及基于时间序列的期望损失共同建模得到公平的收益分配方法,以此构建基于收益公平的电力巡检图像目标检测联邦激励机制。
2.3.1 公平性建模
根据FLI模型[18],设在基于通信轮次0≤t<T的时间序列中参与方i的贡献度由变量qi(t)表示,ci(t)表示参与方i将数量为Di(t)的数据贡献给联邦所需要的代价,ui(t)表示数据提供方i在通信轮次t获得的收益回报,将参与方i目前已经收到的和其应该收到的收益之间的差值定义为期望损失Yi(t),则t+1轮的期望损失表示为
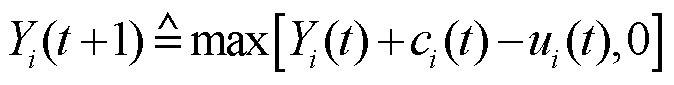 (7)
(7)
当数据需求方由于预算限制难以一次性付清ui(t)时,数据需求方需要基于当前预算B(t),根据各参与方的期望损失和等待全额收益的时间计算其在当前支付预算中所占的份额,以多个轮次分期支付的方式向数据提供方支付收益。因此,以时间队列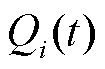 表示时间期望损失,则t+1轮的时间期望损失表达式为
表示时间期望损失,则t+1轮的时间期望损失表达式为
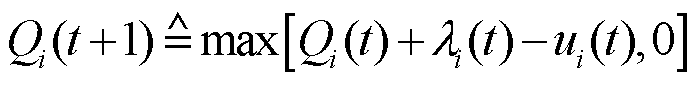 (8)
(8)
其中,λi(t)定义为
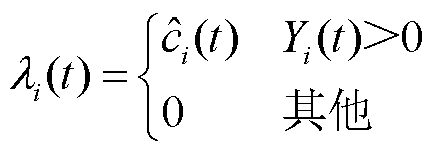 (9)
(9)
当Yi(t)>0时,即此时数据提供方获取的收益不及成本,时间队列就会增加,增量是参与方i为联邦系统过去提供数据的平均成本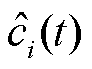 。当联邦系统向参与方i支付收益时,Yi(t)和队列都会以同样的规模减小。这样不仅可以确保参与方因提供的数据贡献而得到收益,还会因为等待的时长获得更多的回报。
。当联邦系统向参与方i支付收益时,Yi(t)和队列都会以同样的规模减小。这样不仅可以确保参与方因提供的数据贡献而得到收益,还会因为等待的时长获得更多的回报。
为了激励参与方持续加入到联邦学习中,联邦机制需要确保参与方能够被公平对待,主要需要保证以下三个公平性标准[18]。
1)贡献公平性:参与方i的收益回报应该与其对联邦的贡献qi(t)正相关。
2)期望损失分配公平性:参与方之间的期望损失和时间期望损失应该尽可能小。
3)期望公平性:尽量减少参与方的期望损失和时间期望损失随时间推移而产生的波动。
基于公平性标准1,参与方提供的贡献qi(t)与得到的收益ui(t)应该呈正相关。因此,目标函数U为
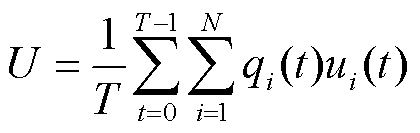 (10)
(10)
其中,需最大化U以满足公平性标准1。
基于公平性标准2,目标函数应该考虑参与方之间的期望损失(Yi(t)和Qi(t))程度以及分布情况。因此,目标函数L(t)为
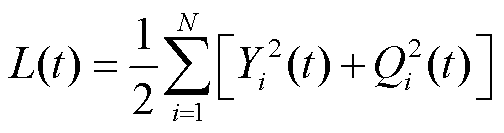 (11)
(11)
其中,需最小化L(t)以满足公平性标准2。
随着通信轮次的增加,参与方的期望损失偏移为
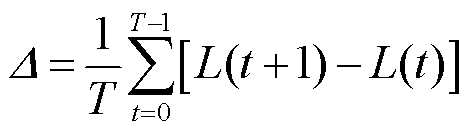 (12)
(12)
期望损失偏移量Δ融合了数据提供方之间期望损失的分布,以及期望损失随时间的变化。因此,最小化Δ可以同时满足公平性标准2和3。
综合考虑上述公平性标准,可知联邦的总体目标函数为最大化目标U以及最小化目标Δ,即最大化总体目标函数f,表示为
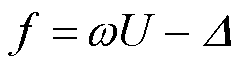 (13)
(13)
式中,ω为正则化系数,用于控制两个目标之间的权重。
基于对总目标函数f的优化,数据提供方i在第t轮获得的收益ui(t)为
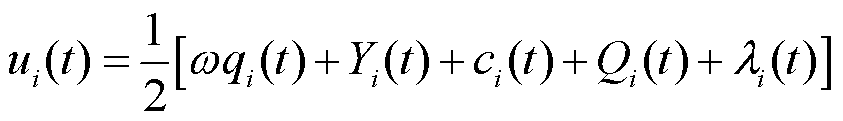 (14)
(14)
2.3.2 算法流程
基于上述公平性建模,设计面向电力巡检图像目标检测的联邦收益分配流程如图4所示,算法流程见表3。与前述2.2.2节类似,表3省略了数据加密和解密的过程。

图4 面向电力巡检图像目标检测的联邦收益分配流程
Fig.4 The federated revenue allocation process for object detection of power inspection images
表3 面向电力巡检图像目标检测的联邦收益分配算法
Tab.3 The federated revenue allocation algorithm for object detection of power inspection images

输入:正则化系数ω,预算B(t),来自第t轮参与联邦学习的电力巡检图像数据提供者的Yi(t)和Qi(t),其中Yi(0)=0,Qi(0)=0。 过程:1:初始化收益值2:For参与方i = 1 to Ndo:3: If 参与方i提供的数据数量Di(t)>0:4: 计算参与方i的成本代价ci(t)5: 计算参与方i的贡献度qi(t)6: Else:7: 设置参与方i的成本代价ci(t)=08: End If9: If Yi(t)>0:10: 11:Else:12: 13: End If14:计算参与方i的收益值ui(t):15: 16:计算收益累加值S(t):17: 18:End For19:For参与方i = 1 to Ndo:20: 计算最终基于预算B(t)得到的本轮收益:21: 22: 更新Yi(t)和Qi(t)的值:23: 24: 25:End For26:结束过程 输出:
为了验证上述两种联邦激励机制的有效性,本文基于作者所在实验室构建的无人机电力杆塔巡检图像数据集[29]开展相关实验研究。该数据集共有5 048张电力巡检图片,包含山区、城市、平原等多个场景。训练集和测试集的占比分别约为80%和20%。
同时,为了考虑不同客户端之间数据集的非独立同分布特性对联邦学习的影响,本文首先按照特征倾斜、数量倾斜、混合倾斜三种情况对数据集进行了划分[30]。表4展示了特征倾斜分布情况下的数据划分方式;图5为基于Dirichlet分布的数量倾斜数据划分方式;表5为基于混合倾斜分布的数据划分。
表4 基于特征倾斜分布的数据集划分
Tab.4 Dataset partition based on feature skew

参与方特征倾斜(场景数=1)特征倾斜(场景数=3) 1城市城市、山区、平原 2山区平原、村庄、树林 3平原城市、山区、村庄 4村庄城市、村庄、树林 5树林山区、平原、树林
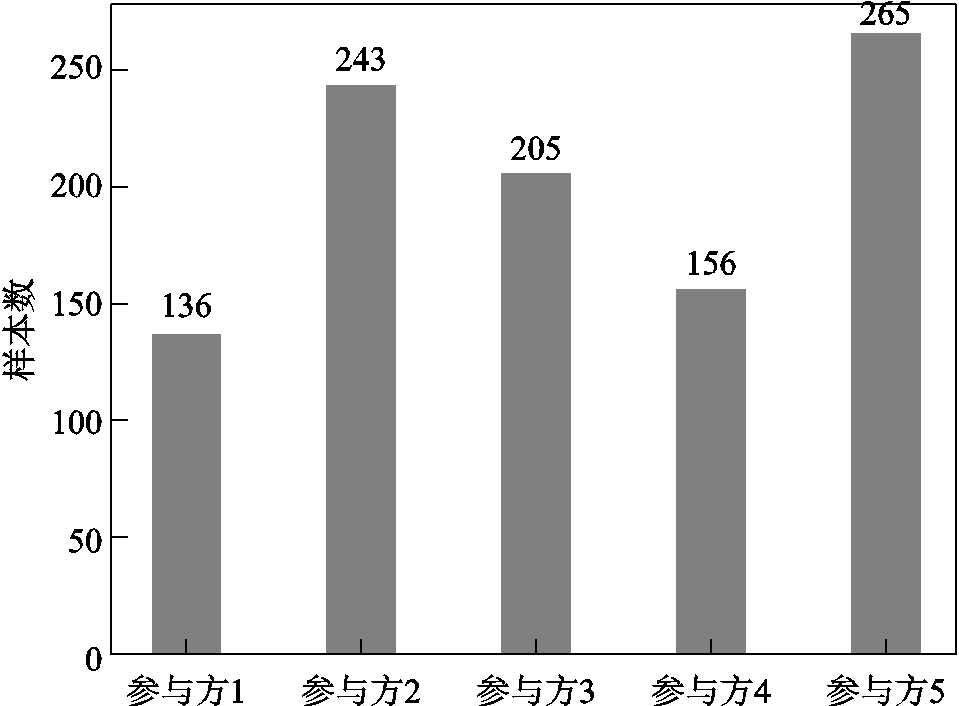
图5 基于数量倾斜的数据集划分(Dirichlet分布中的浓度参数α=5)
Fig.5 Dataset partition based on quantity skew (Dirichlet distribution with concentration parameter α=5)
表5 基于混合倾斜的数据集划分
Tab.5 Dataset partition based on mixed skew

参与方图像数量场景 1685城市(685) 21 215城市(123)、山区(808)、平原(284) 31 030平原(524)、村庄(506) 4785村庄(302)、树林(483) 5325树林(325) 总计4 040城市(808)、山区(808)、平原(808)、村庄(808)、树林(808)
本文实验均在GPU服务器上开展,其中电力巡检图像目标检测全局模型采用YOLO系列的轻量级预训练模型YOLOv5s。为了聚焦对激励机制的研究,所有参与方均使用同一模型。所有算法均基于深度学习框架PyTorch实现。
在模型评估方面,本文选择全类平均精度(mean Average Precision, mAP)作为评估目标检测模型性能的指标,它是对模型预测结果和真实标注之间匹配程度的综合评估。计算mAP时,首先计算每个类别的平均精度(Average Precision, AP),再将所有类别的AP求平均得到mAP。计算AP时,首先按照得分从高到低排序;其次根据不同的阈值计算出对应的精度和召回率;最后将精度和召回率绘制成曲线,对曲线下的面积求和,即可得到AP值。在本文实验中,交并比(Intersection over Union, IoU)的阈值选择为0.5。此外,由于目标检测模型的训练过程会有所振荡,为了排除噪声的影响,以便更好地进行实验分析与对比,本文参照惯例对实验部分呈现的数据曲线进行了一定程度的平滑处理。
在基于模型公平的联邦激励机制实验中,本文使用特征倾斜(每个参与方拥有的场景数为1)的电力杆塔巡检图像数据集,并采用基于边际效用的评估策略,分别比较了基于单方训练、动态通信轮次以及影响函数的贡献度衡量方法。
3.3.1 基于单方训练的贡献度衡量实验
在基于单方训练最高模型精度的贡献度衡量实验中,各个参与方使用自己本地的电力巡检图像数据集进行模型的训练直至收敛。当参与方j单方训练收敛后,使用目标检测模型的最高mAP值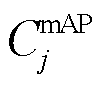 作为参与方的贡献度衡量因素,并进行归一化,使得贡献度的总和为1,即
作为参与方的贡献度衡量因素,并进行归一化,使得贡献度的总和为1,即
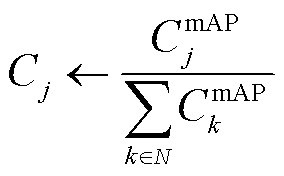 (15)
(15)
根据式(15)可得到各个参与方的贡献度Cj见表6。然后利用聚合梯度分配方法,使得联邦学习的参与方在每个通信轮次都能够得到与贡献度大小相匹配的模型参数更新值,用于本地模型参数的更新。
表6 参与方单方训练的最高mAP值
Tab.6 The highest mAP value for unilateral training of participants

单方训练参与方最高mAP值贡献度 10.5130.188 20.5680.208 30.6180.227 40.6040.222 50.4240.155
随着通信轮数的增加,各个参与方根据得到的模型参数更新值进行本地模型更新后,模型在测试集上的性能曲线(本地迭代次数epoch=3)如图6所示。由于贡献度的计算基于单方训练的最高mAP值,具有一定的波动和偶然性,因此参与方4在贡献度略低于参与方3的情况下,得到较高性能的模型是合理的。总体而言,表6中贡献度较高的参与方,最终得到的本地模型性能也普遍较高,能够保证一定的公平性。
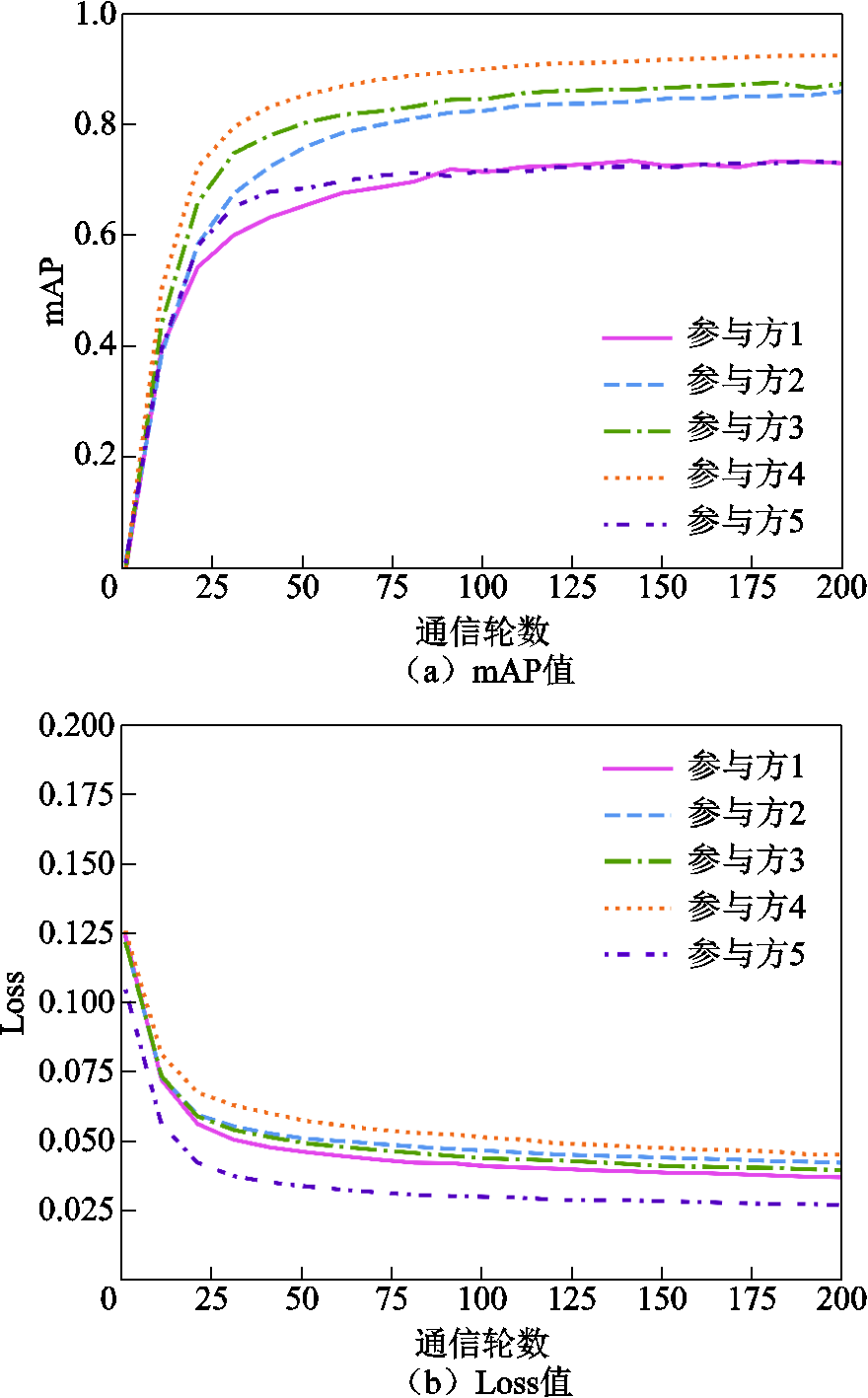
图6 不同参与方模型的mAP与Loss值对比(epoch=3)
Fig.6 Comparison of mAP and Loss values for different participant models (epoch=3)
图7为参与方本地迭代次数epoch增加到5时的实验结果。随着本地epoch的增加,模型的收敛速度也会加快。然而,由于每个参与方得到的模型参数更新值与贡献度相关,个别参与方(参与方1)会由于后期分配得到的模型参数更新值而出现过拟合现象,从而导致模型性能下降。但是如图8所示,当本地模型利用本地数据集进行训练后,可以缓解过拟合的现象,模型性能也能够恢复到原来的水平。因此,在这种情况下,参与方1可以选择通过本地训练恢复性能或及时终止联邦学习的训练,保存最佳性能的模型为本地模型。
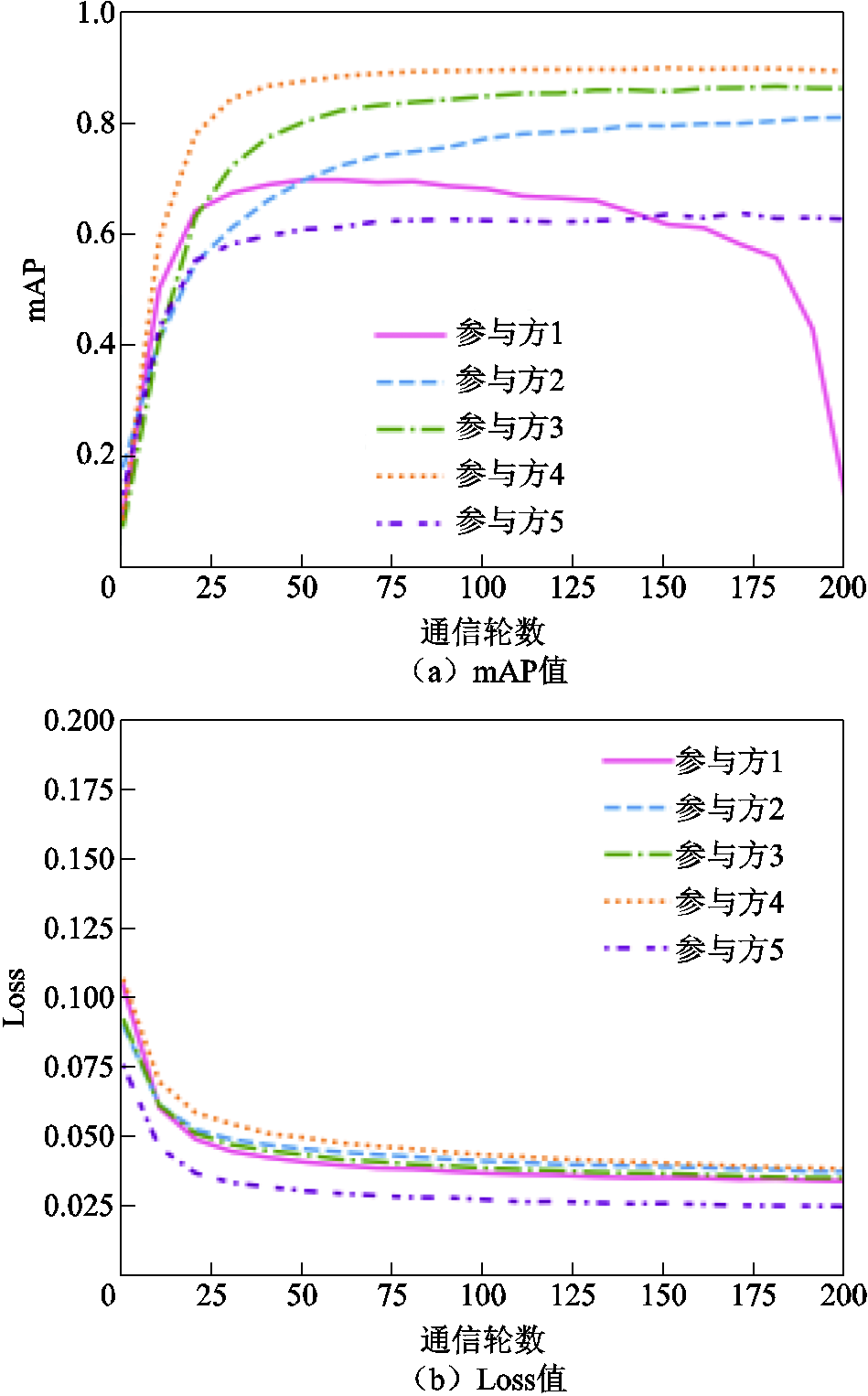
图7 不同参与方模型的mAP与Loss值对比(epoch=5)
Fig.7 Comparison of mAP and Loss values for different participant models (epoch=5)
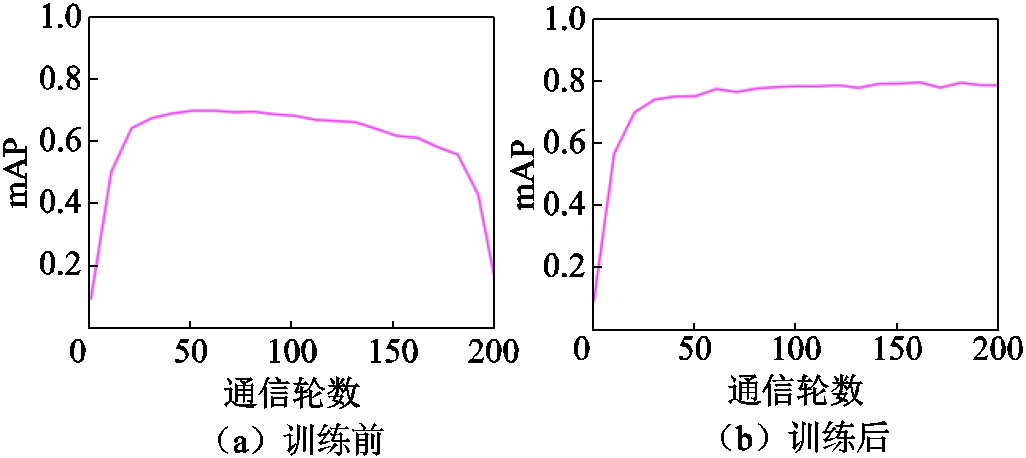
图8 参与方1本地训练前后模型mAP值对比
Fig.8 Comparison of mAP values of client1’s model before and after local training
图9对比了各个参与方通过基于模型公平的联邦训练后得到的模型与各自单方训练的模型性能。实验结果表明,在模型公平的前提下,各个参与方仍然能够得到高于单方训练性能的模型,证明了基于模型公平的联邦训练的有效性。这种激励机制不仅保证了参与方之间的公平性,也使得各参与方加入联邦训练是值得的,能够激励更多参与方加入到基于模型公平的电力巡检图像目标检测联邦训练中。
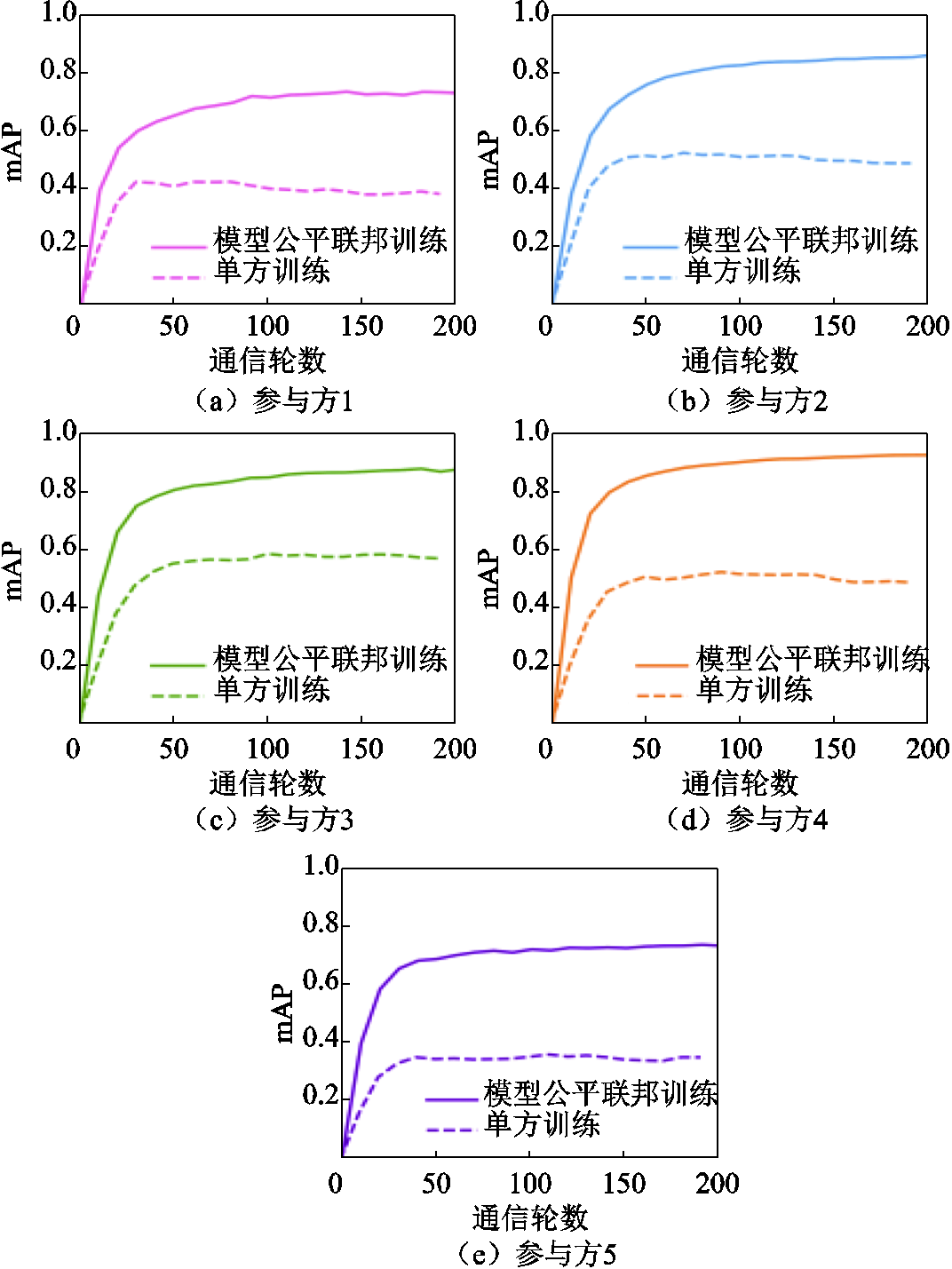
图9 基于贡献度衡量的模型公平联邦训练与单方训练结果对比
Fig.9 Comparison of model-fairness federated training based on contribution measurement and unilateral training
3.3.2 基于动态通信轮次的贡献度衡量实验
在基于动态通信轮次变化的模型精度贡献度衡量实验中,每一轮都根据各个参与方的模型精度,动态调整其贡献值。为了防止由于振荡和偶然情况造成贡献度的计算过度依赖某一轮的模型性能而出现较大偏差,在计算贡献度时,将本轮次的贡献度Cj与上一轮的历史贡献度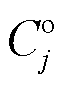 进行加权后,得到最终的贡献度Cj。同时,使用双曲正弦函数sinh增加各参与方之间的贡献区分度。
进行加权后,得到最终的贡献度Cj。同时,使用双曲正弦函数sinh增加各参与方之间的贡献区分度。
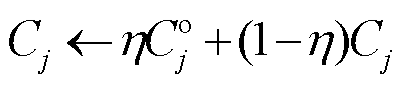 (16)
(16)
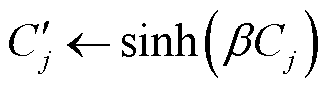 (17)
(17)
式中,η为历史贡献度与本轮贡献度的权衡因子,在本文实验中取值为0.5; 为控制区分度的参数,其值越大,区分度越高,在本文实验中,取值为5。最后通过归一化更新各个参与方本轮的贡献度
为控制区分度的参数,其值越大,区分度越高,在本文实验中,取值为5。最后通过归一化更新各个参与方本轮的贡献度 。
。
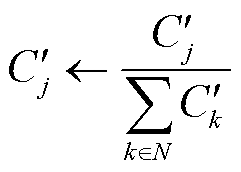 (18)
(18)
基于参与方本地3次迭代训练后的模型mAP值计算各参与方的贡献度,并得到相应数量的模型参数更新值用于局部模型的更新,更新后模型的mAP与Loss曲线如图10所示。同时,通过增加参与方本地epoch数为5,在基于动态模型精度的贡献度衡量方法下,联邦模型的收敛速度会加快,各个参与方之间分配得到的模型精度区分度也会增大,如图11所示。同样地,联邦训练后期参与方1出现了一定程度的过拟合现象,这同样可以通过本地训练恢复到之前的性能或选择提前退出联邦训练。
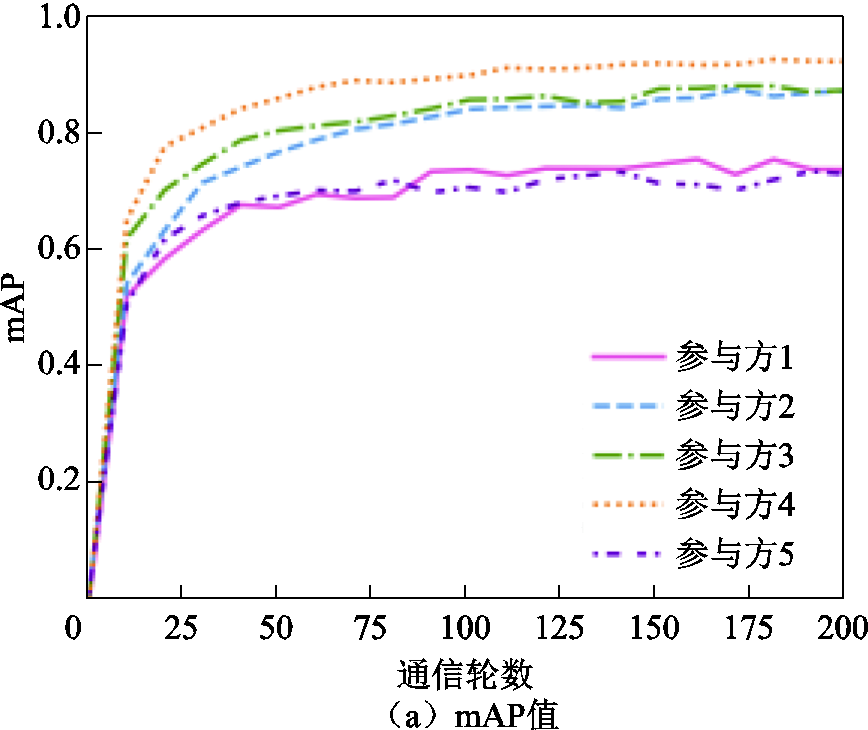
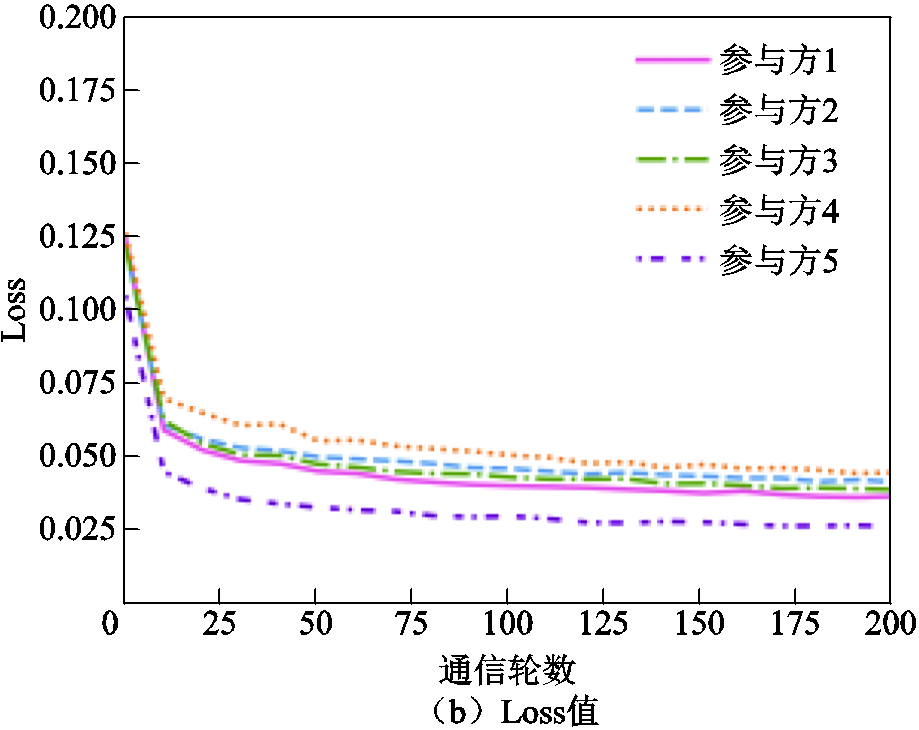
图10 基于动态精度的不同参与方模型mAP与Loss值对比(epoch=3)
Fig.10 Comparison of mAP and Loss values for different participant models based on dynamic accuracy (epoch=3)
3.3.3 基于影响函数的贡献度衡量实验
表7分别给出了五个参与方分别不加入联邦学习时,其他四个参与方协同进行联邦训练得到的模型精度。同时结合五个参与方共同参加联邦学习时的模型精度,通过影响函数公式计算得到各个参与方的贡献度。
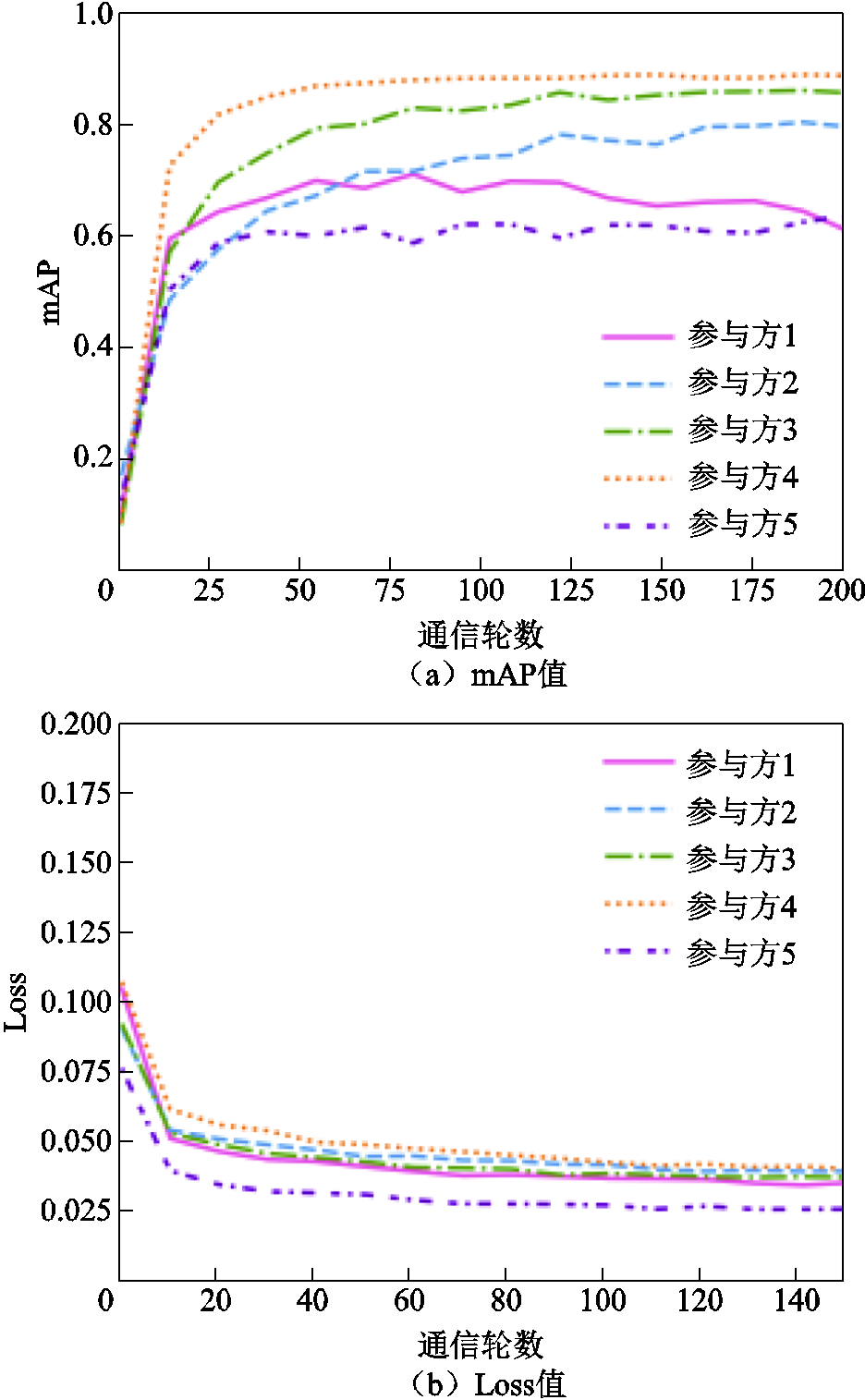
图11 基于动态精度的不同参与方模型mAP与Loss值对比(epoch=5)
Fig.11 Comparison of mAP and Loss values for different participant models based on dynamic accuracy (epoch=5)
表7 基于影响函数的参与方贡献度
Tab.7 Comparison of clients’ contribution based on influence function
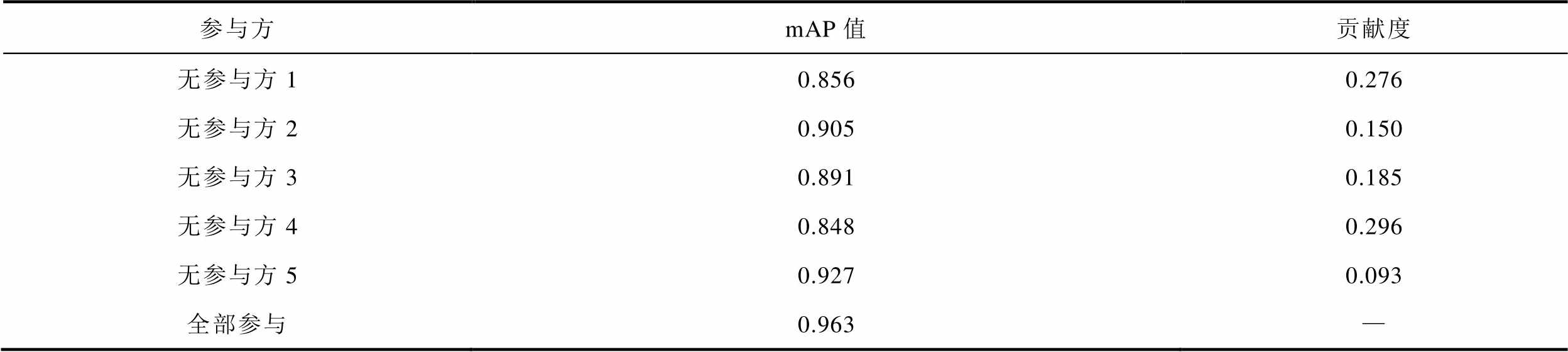
参与方mAP值贡献度 无参与方10.8560.276 无参与方20.9050.150 无参与方30.8910.185 无参与方40.8480.296 无参与方50.9270.093 全部参与0.963—
根据影响函数衡量的贡献度,各参与方得到相应数量的模型参数更新值用于本地模型更新。参与方更新得到的模型性能如图12所示(参与方本地epoch=3)。实验数据表明,各参与方得到的模型性能与基于影响函数衡量的贡献度总体呈正相关。但是,个别参与方(如参与方1)在基于影响函数衡量方法中得到较高的贡献度后,通过参数分配得到的模型性能并不与贡献值大小相匹配。这可能是因为在基于影响函数的贡献度衡量方法中,参与方1的加入对于总体联邦模型精度的提升有更大的帮助,能够提供其他参与方较为缺少的稀缺场景电力巡检图像数据。但是参与方1基于自己的数据集在本地进行训练的模型不能获得较高的测试精度,模型的泛化性较差,因此最终模型精度不高。由此也可以看出,在数据特征倾斜分布情况下,基于模型精度的贡献度衡量方式相比基于影响函数的衡量方式更适用于电力巡检图像目标检测任务。
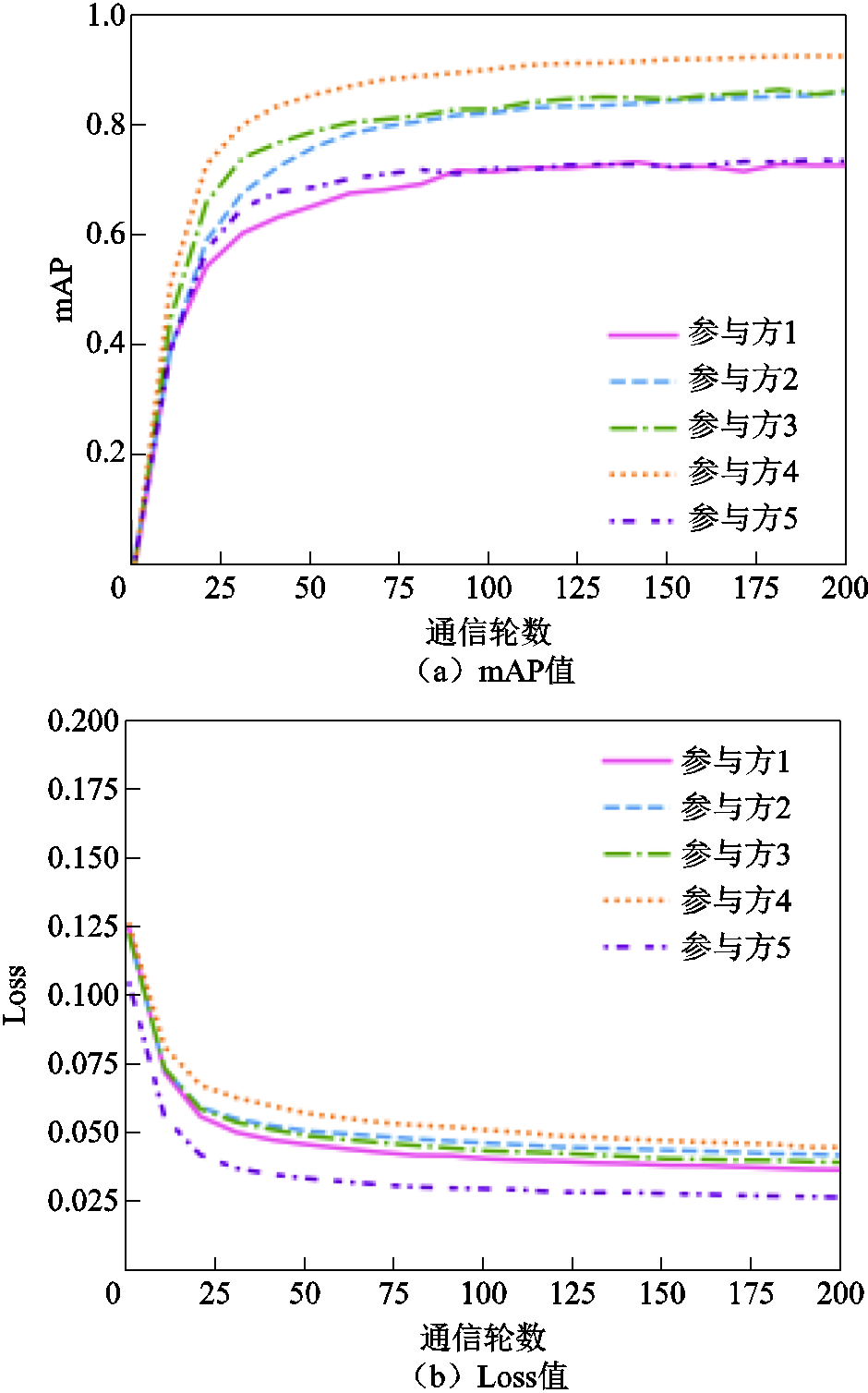
图12 基于影响函数的参与方模型mAP与Loss值对比
Fig.12 Comparison of mAP and Loss values in participant model based on influence function
3.3.4 不同贡献度衡量方法的对比
表8给出了基于不同贡献度衡量方法训练得到的模型最高mAP值,本地epoch数均保持为3。通过实验数据可知,基于不同贡献度衡量方法,各个参与方最终获得的本地模型能够达到的最高精度基本持平。且无论基于哪种衡量方法,基于模型公平的联邦激励机制都能够获得高于参与方单方训练的结果,可以在保证公平性的前提下,带来模型性能的提升。
表8 基于不同贡献度衡量方法的模型最高mAP
Tab.8 The highest mAP of models based on different contribution measurement methods

参与方单方训练静态模型动态模型影响函数 10.5130.7530.7570.750 20.5680.8970.8990.894 30.6180.9040.8970.899 40.6040.9340.9300.930 50.4240.7540.7460.754
同时,实验对比了基于不同贡献度衡量方法的模型公平激励机制的公平性。分别通过计算皮尔逊相关系数[31]、斯皮尔曼相关系数以及肯德尔秩相关系数[32]进行了公平性的对比,结果见表9。由表9可知,相较于其他两种贡献度衡量方法,基于动态模型精度的贡献度衡量方法得到的公平系数最高,皮尔逊相关系数为0.96;基于影响函数的模型衡量方法公平性系数最低。可见,在面向电力巡检图像目标检测的特征倾斜数据分布下,使用动态模型精度进行贡献度衡量,能够保证更高的公平性。
表9 基于不同贡献度衡量方法的公平性相关系数
Tab.9 Fairness correlation coefficients based on different contribution measurement methods

公平性衡量静态模型动态模型影响函数 皮尔逊相关系数0.870.960.29 斯皮尔曼相关系数0.800.900.40 肯德尔秩相关系数0.600.800.40
在基于收益公平的联邦激励机制实验中,本文使用数量倾斜和混合倾斜电力杆塔巡检图像数据集。其中,在数量倾斜的图像数据集划分中,Dirichlet分布的浓度参数取值为5。在参与方的成本衡量中采用直接评估法,考虑了参与方i本地电力杆塔巡检图像数据集的大小Di以及拥有的电力杆塔巡检图像场景数si,通过加权系数γ得到参与方i的成本ci,表示为
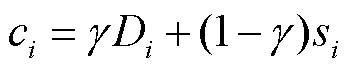 (19)
(19)
式中,γ为贡献度计算中电力杆塔巡检图像数据数量和场景数的权衡因子,本文取值为0.7,表示给予各参与方本地图像数据集规模更多的权重,即考虑更多的数据数量造成的成本代价。最后,对各个参与方的成本进行归一化得到最终各参与方的成本代价。
图13展示了各个参与方在基于数量倾斜的数据异质分布下(本地epoch=3),期望损失Y和时间期望损失Q随时间(即通信轮数)的变化。由于在实验设置中,数据需求方的预算不足以支付每轮参与方的总收益,因此期望损失和时间期望损失随着通信轮次的增加而不断增大,且时间期望损失的变化趋势与期望损失基本一致。其中,由于参与方5成本较低,产生的期望损失较小,并且能够及时在下一轮中得到收益的弥补,因此时间期望损失趋近于0。
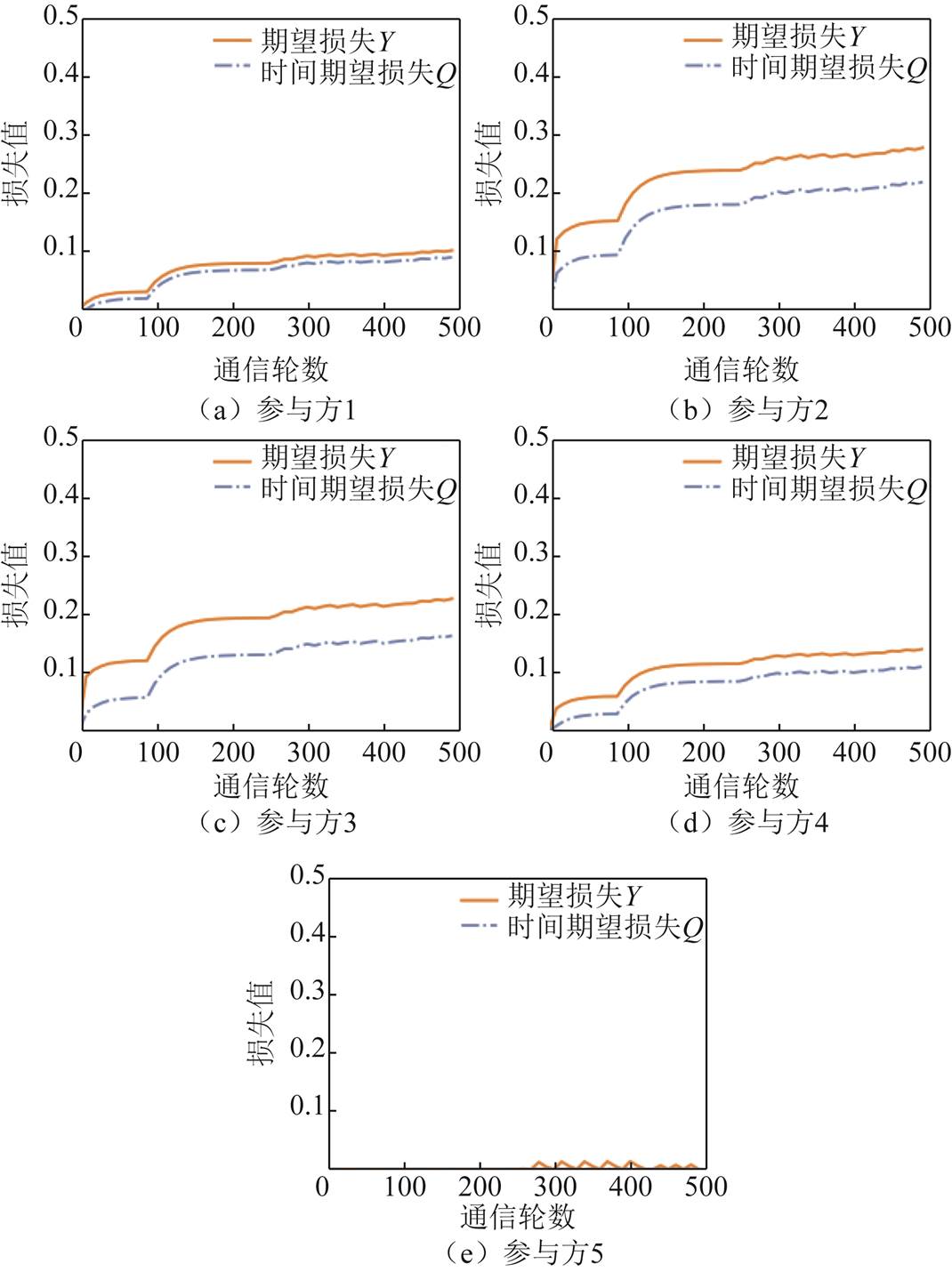
图13 基于数量倾斜的数据异质分布的参与方期望损失和时间期望损失的变化趋势
Fig.13 Trends in expected losses and expected temporal losses for participants based on the quantity skew data heterogeneity
电力巡检图像数量倾斜分布情况下,各参与方的成本与贡献度以及收益随通信轮次的趋势变化如图14所示。实验结果表明,参与方的成本与贡献度之和越高,对应的收益也越高,验证了基于收益公平的联邦激励机制的有效性,且能够在保证电力巡检图像目标检测联邦模型精度的前提下,满足公平性的要求。
各参与方在基于混合倾斜的数据异质分布下(本地epoch=3),期望损失Y和时间期望损失Q随时间的变化如图15所示,二者趋势基本一致。参与方1的期望损失与时间期望损失之间差距很小,因此曲线近乎重合。参与方5同样由于产生的期望损失较小,能够及时得到收益的弥补,因此时间期望损失趋近于0。
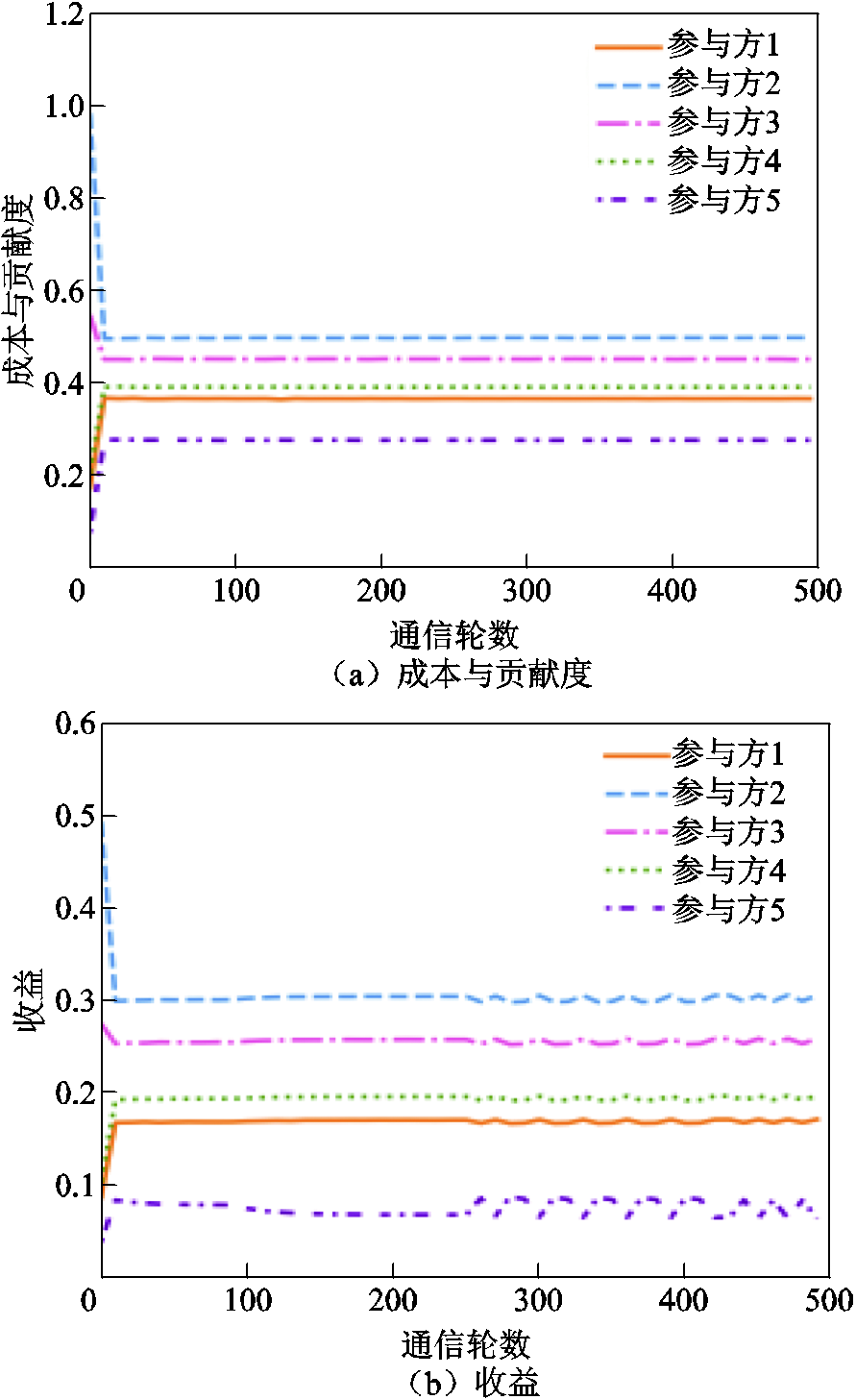
图14 基于数量倾斜的数据异质分布的参与方成本与贡献度和收益的变化趋势
Fig.14 Trends in cost contribution and revenue for participants based on the quantity skew data heterogeneity
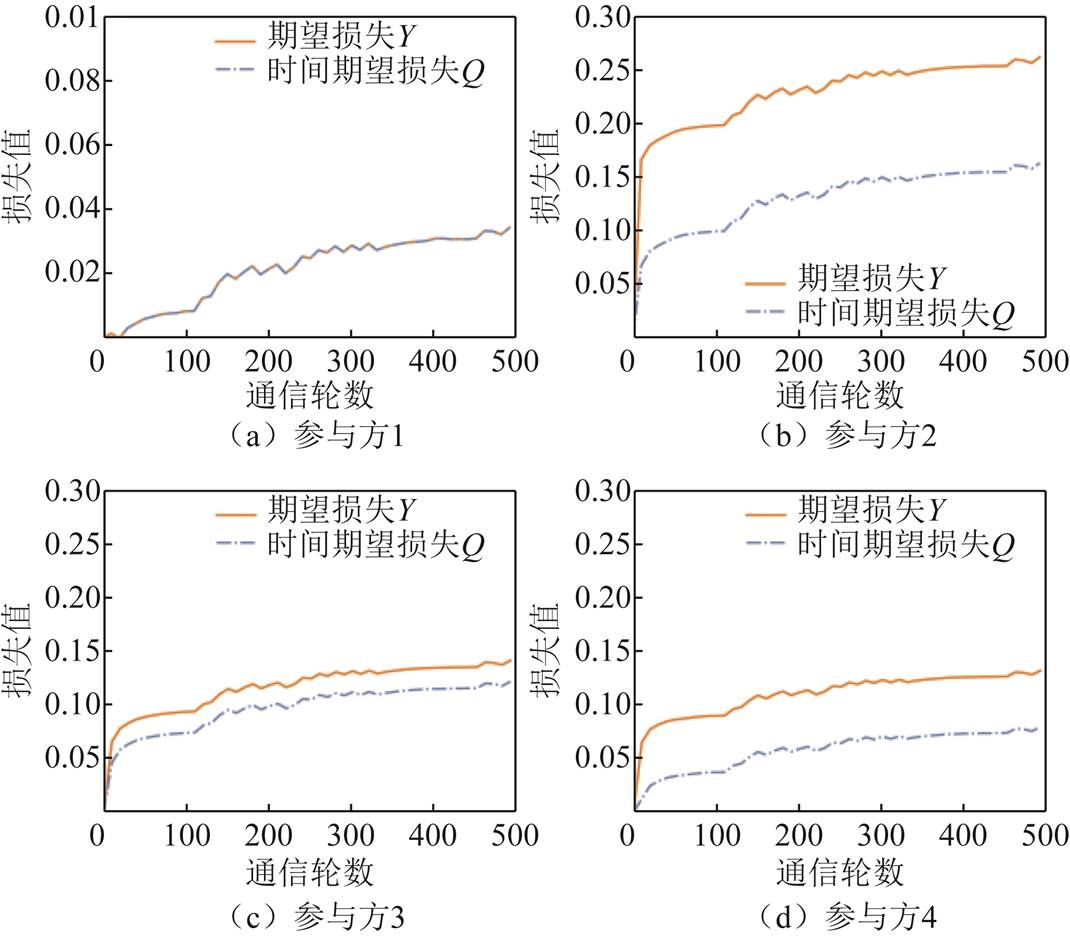
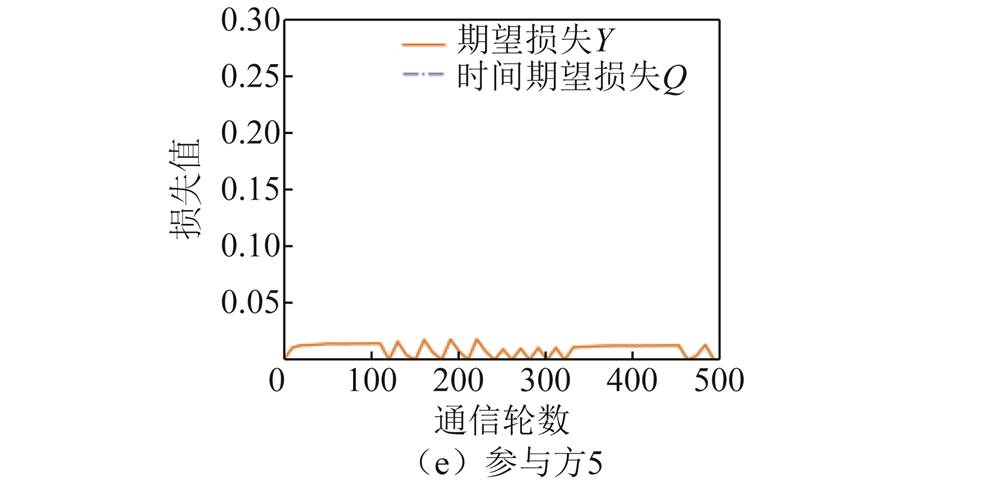
图15 基于混合倾斜的数据异质分布的参与方期望损失和时间期望损失的变化趋势
Fig.15 Trends in expected losses and expected temporal losses for participants based on the mixed skew data heterogeneity
类似地,在混合倾斜异质分布情况下,各参与方的成本与贡献度和收益随通信轮数的变化如图16所示,可见其趋势保持一致,同样证明了基于收益公平的联邦激励机制可以在保证模型性能的前提下,满足公平性要求,从而能够激励更多参与方加入到面向电力巡检图像目标检测的联邦学习机制中。
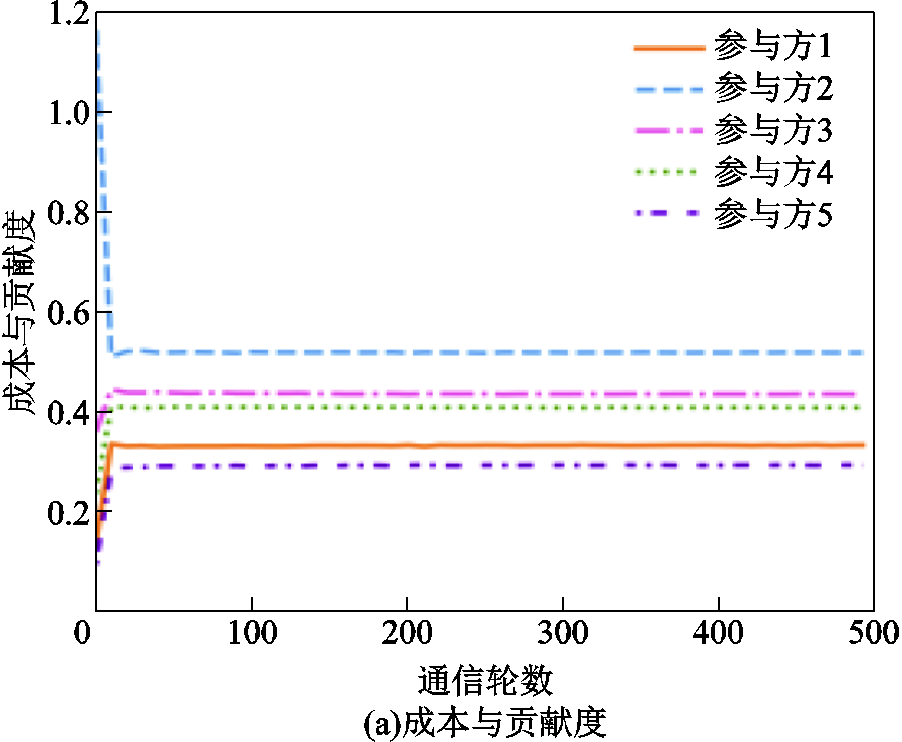
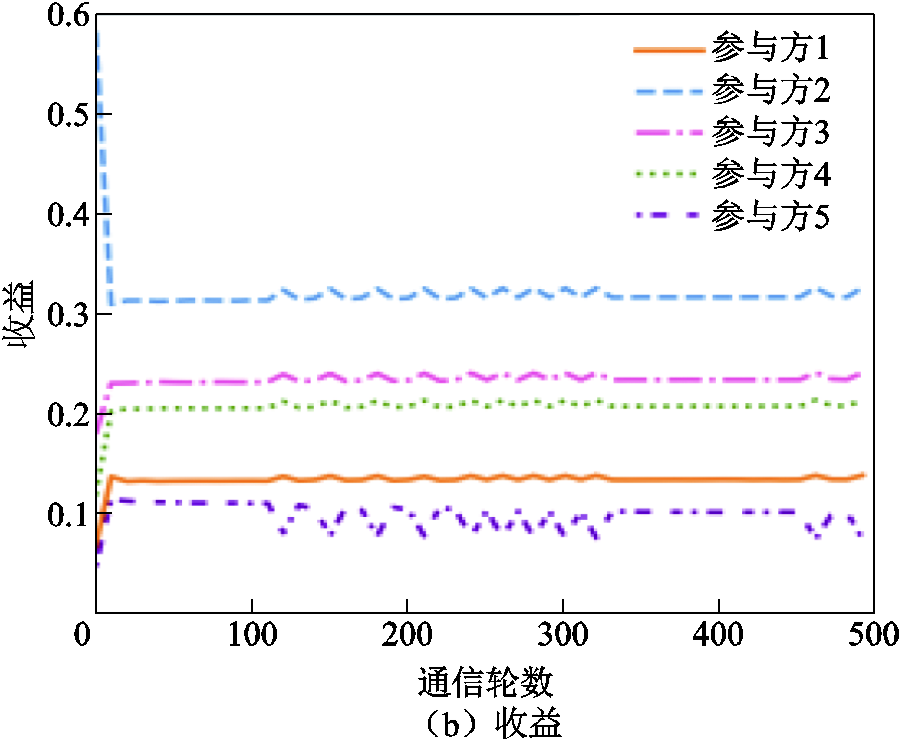
图16 基于混合倾斜异质数据异质分布的参与方成本与贡献度和收益的变化趋势
Fig.16 Trends in cost contribution and revenue for participants based on the mixed skew data heterogeneity
数量倾斜与混合倾斜数据异质分布下,各参与方的收益与各自贡献度之间关系的散点图如图17所示。横坐标表示各参与方的成本与贡献度,纵坐标表示分配得到的收益。可以看到,二者之间呈正相关关系。在数量倾斜和混合倾斜数据分布以及不同本地epoch数情况下,收益与成本贡献之间的皮尔逊相关系数见表10,可见整体近似为1,呈现强正相关关系。这表明在基于收益公平的联邦机制下能够实现电力巡检图像目标检测任务中各参与方之间的公平性。
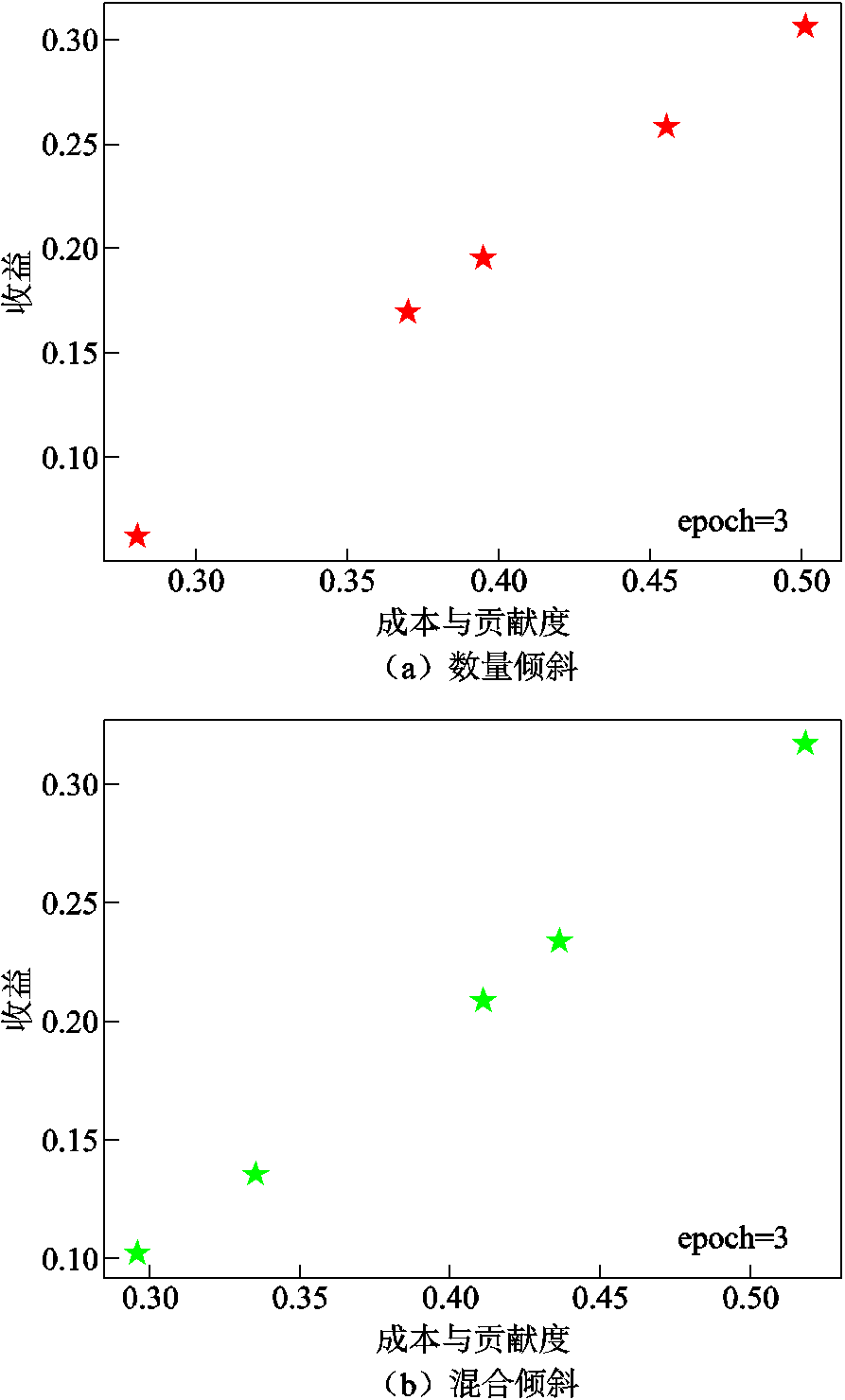
图17 收益与成本贡献度的散点图
Fig.17 Scatter plot of relation between revenue and cost contribution
表10 收益与成本贡献之间的皮尔逊相关系数
Tab.10 Pearson correlation coefficient between revenue and cost contribution

数据集epoch=1epoch=3 数量倾斜0.9990.999 混合倾斜1.0001.000
本文针对电力巡检图像目标检测联邦学习中存在的不公平性问题,分别构建了基于模型公平和收益公平的电力巡检图像目标检测联邦激励机制。在基于模型公平的联邦激励中,参与方作为数据提供方,获得不同性能的电力巡检图像目标检测模型。在基于收益公平的联邦激励中,既有数据提供方又有数据需求方,通过综合考虑成本、贡献度以及期望损失建模,数据提供方可得到与贡献相匹配的收益,数据需求方获得高性能模型。
实验结果表明,在基于模型公平的激励机制中,公平性相关系数最高可以达到0.96;在基于收益公平的联邦激励机制公平性度量中,相关系数可以达到1。以上两种联邦激励机制均能够在保证模型精度的前提下,提升面向电力巡检图像目标检测联邦训练的公平性,从而吸引更多参与方加入到联邦学习中。
应当指出的是,虽然本文以电力目标检测为主要应用场景,但本文所提出的激励机制可适用于包括图像分类、目标检测、异常检测在内的各类电力视觉任务,具有一定的通用性。此外,本文在贡献度衡量中考虑的指标较为单一,未来工作中可进一步考虑多重指标特征,从而更加全面地衡量不同参与方的成本和贡献。
参考文献
[1] 郭敬东, 陈彬, 王仁书, 等. 基于YOLO的无人机电力线路杆塔巡检图像实时检测[J]. 中国电力, 2019, 52(7): 17-23.
Guo Jingdong, Chen Bin, Wang Renshu, et al. YOLO-based real-time detection of power line poles from unmanned aerial vehicle inspection vision[J]. Electric Power, 2019, 52(7): 17-23.
[2] 阎光伟, 马颐琳, 焦润海, 等. 航拍电力杆塔图像中销钉唯一性识别研究[J/OL]. 电工技术学报, 2023: 1-12[2023-09-11]. DOI:10.19595/j.cnki.1000-6753.tces. 230760.
Yan Guangwei, Ma Yilin, Jiao Runhai, et al. Research on pin uniqueness identification in aerial power tower images[J/OL]. Transactions of China Electrotechnical Society, 2023: 1-12[2023-09-11]. DOI:10.19595/j.cnki. 1000-6753.tces.230760.
[3] 宋立业, 刘帅, 王凯, 等. 基于改进EfficientDet的电网元件及缺陷识别方法[J]. 电工技术学报, 2022, 37(9): 2241-2251.
Song Liye, Liu Shuai, Wang Kai, et al. Identification method of power grid components and defects based on improved EfficientDet[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2241-2251.
[4] 苟军年, 杜愫愫, 刘力. 基于改进掩膜区域卷积神经网络的输电线路绝缘子自爆检测[J]. 电工技术学报, 2023, 38(1): 47-59.
Gou Junnian, Du Susu, Liu Li. Transmission line insulator self-explosion detection based on improved mask region-convolutional neural network[J]. Transactions of China Electrotechnical Society, 2023, 38(1): 47-59.
[5] 韩翔宇, 纽春萍, 何海龙, 等. 电磁式断路器状态监测与智能评估技术综述[J]. 电工技术学报, 2023, 38(8): 2191-2210.
Han Xiangyu, Niu Chunping, He Hailong, et al. Review of condition monitoring and intelligent assessment of electromagnetic circuit breaker[J]. Transactions of China Electrotechnical Society, 2023, 38(8): 2191-2210.
[6] Yang Qiang, Liu Yang, Chen Tianjian, et al. Federated machine learning: concept and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): 12.
[7] 郭方洪, 刘师硕, 吴祥, 等. 基于联邦学习的含不平衡样本数据电力变压器故障诊断[J]. 电力系统自动化, 2023, 47(10): 145-152.
Guo Fanghong, Liu Shishuo, Wu Xiang, et al. Federated learning based fault diagnosis of power transformer with unbalanced sample data[J]. Automation of Electric Power Systems, 2023, 47(10): 145-152.
[8] Buttarelli G. The EU GDPR as a clarion call for a new global digital gold standard[J]. International Data Privacy Law, 2016, 6(2): 77-78.
[9] Hard A, Rao K, Mathews R, et al. Federated learning for mobile keyboard prediction[J/OL]. ArXiv, 2019: 1811.03604v2. https://doi.org/10.48550/arXiv.1811. 03604.
[10] 梁天恺, 曾碧, 陈光. 联邦学习综述:概念、技术、应用与挑战[J]. 计算机应用, 2022, 42(12): 3651-3662.
Liang Tiankai, Zeng Bi, Chen Guang. Federated learning survey: concepts, technologies, applications and challenges[J]. Journal of Computer Applications, 2022, 42(12): 3651-3662.
[11] Ng K L, Chen Zichen, Liu Zelei, et al. A multi-player game for studying federated learning incentive schemes [C]//Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 2021: 5279-5281.
[12] Wang Guan, Dang C X, Zhou Ziye. Measure contribution of participants in federated learning [C]//2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 2019: 2597-2604.
[13] Richardson A, Filos-Ratsikas A, Faltings B. Rewarding high-quality data via influence functions [J/OL]. ArXiv, 2019: 1908. 11598. http://arxiv.org/ abs/1908.11598v1.
[14] Kang Jiawen, Xiong Zehui, Niyato D, et al. Incentive mechanism for reliable federated learning: a joint optimization approach to combining reputation and contract theory[J]. IEEE Internet of Things Journal, 2019, 6(6): 10700-10714.
[15] Zhang Jingfeng, Li Cheng, Robles-Kelly A, et al. Hierarchically fair federated learning[J/OL]. ArXiv, 2020: 1-16. https://doi.org/10.48550/arXiv.2004. 10386.
[16] Lyu Lingjuan, Yu Jiangshan, Nandakumar K, et al. Towards fair and privacy-preserving federated deep models[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(11): 2524-2541.
[17] Lyu Lingjuan, Xu Xinyi, Wang Qian, et al. Collaborative fairness in federated learning [M]//Yang Qiang, Fan Lixin, Yu Han. Federated Learning: Privacy and Incentive. Cham: Springer, 2020: 189-204.
[18] Yu Han, Liu Zelei, Liu Yang, et al. A fairness-aware incentive scheme for federated learning[C]// Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 2020: 393-399.
[19] Dwork C. Differential privacy: a survey of results [C]//The 5th International Conference on Theory and Applications of Models of Computation, Xi’an, China, 2008: 1-19.
[20] Rivest R L, Adleman L, Dertouzos M L. On data banks and privacy homomorphisms[M]//DeMillo R A, Lipton R J, Dobkin D P, et al. Foundations of Secure Computation. Amstertam: Academic Press, 1978: 169-180.
[21] Liu Keyu, Zhong Linlin. Object detection of UAV power line inspection images based on federated learning[C]//2022 IEEE 5th International Electrical and Energy Conference (CIEEC), Nanjing, China, 2022: 2372-2377.
[22] Zeng Rongfei, Zeng Chao, Wang Xingwei, et al. A comprehensive survey of incentive mechanism for federated learning[J/OL]. ArXiv, 2021: 2106.15406v1. https://doi.org/10.48550/arXiv.2106.15406.
[23] Zhan Yufeng, Zhang Jie, Hong Zicong, et al. A survey of incentive mechanism design for federated learning[J]. IEEE Transactions on Emerging Topics in Computing, 2022, 10(2): 1035-1044.
[24] Tang Ming, Wong V W S. An incentive mechanism for cross-silo federated learning: a public goods perspective[C]//IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 2021: 1-10.
[25] 梁文雅, 刘波, 林伟伟, 等. 联邦学习激励机制研究综述[J]. 计算机科学, 2022, 49(12): 46-52.
Liang Wenya, Liu Bo, Lin Weiwei, et al. Survey of incentive mechanism for federated learning[J]. Computer Science, 2022, 49(12): 46-52.
[26] 朱智韬, 司世景, 王健宗, 等. 联邦学习的公平性研究综述[J]. 大数据, 2024, 10(1): 62-85.
Zhu Zhitao, Si Shijing, Wang Jianzong, et al. A survey on the fairness of federated learning[J]. Big Data Research, 2024, 10(1): 62-85.
[27] Zhou Zirui, Chu Lingyang, Liu Changxin, et al. Towards fair federated learning[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 2021: 4100-4101.
[28] McMahan H B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[J/OL]. ArXiv, 2016: 1602. 05629v4. https://doi.org/10.48550/arXiv.1602.05629.
[29] 仲林林, 胡霞, 刘柯妤. 基于改进生成对抗网络的无人机电力杆塔巡检图像异常检测[J]. 电工技术学报, 2022, 37(9): 2230-2240, 2262.
Zhong Linlin, Hu Xia, Liu Keyu. Power tower anomaly detection from unmanned aerial vehicles inspection images based on improved generative adversarial network[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2230-2240, 2262.
[30] Li Qinbin, Diao Yiqun, Chen Quan, et al. Federated learning on non-IID data silos: an experimental study[C]//2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 2022: 965-978.
[31] Ratner B. The correlation coefficient: Its values range between +1/−1, or do they?[J]. Journal of Targeting, Measurement and Analysis for Marketing, 2009, 17(2): 139-142.
[32] Kendall M G. Rank Correlation Methods[M]. London: Charles Griffin, 1948.
Abstract In recent years, the automated inspection approaches have been widely used in power system, which is safer and more efficient than traditional manual inspection. In order to effectively process the large number of power inspection images generated by automated inspection machines, such as unmanned aerial vehicles (UAVs), the deep learning-based object detection technology is commonly used to timely detect potential faults. However, in practical applications, power lines are widely distributed, and the collected inspection images are not easily integrated. In addition, due to data privacy and restrictions from relevant laws and regulations, these inspection images cannot be shared with or provided to third-party organizations. The data exist as “data islands” scattered among various power companies. In this situation, a single power company has a limited amount and variety of inspection image data, making it difficult to obtain a robust object detection model with good generalization performance through traditional data-driven deep learning algorithms.
Federated learning (FL), as an emerging distributed technology, can be efficiently applied to visual tasks of power inspection by constructing a high-performance model through collaboration among participants while protecting data privacy. In traditional federated learning, the final distributed model to each participant is a global model with the same performance without considering the contribution differences by different participants, which means different participants receive the same model. However, in real scenarios, the quantity, quality, and cost of power inspection image data provided by different participants are really different, and their contributions to the training of global model are also different. If the participants in federal learning cannot receive fair and reasonable returns, it will cause some participants to be unwilling to participate in the federal training of object detection model for processing power inspection images, and cannot guarantee the number of participants in federal learning, resulting in the inability to continue federal training or poor training performance.
To address these challenges and incentivize more participants to join federated learning for object detection of power inspection images, this paper proposes two federated incentive mechanisms based on model fairness and revenue fairness, respectively. The model fairness incentive mechanism is designed for the scenarios where all participants are data owners, and it involves evaluating contributions to obtain models with varying performance levels. In this incentive mechanism, we use an evaluation strategy based on marginal benefit, and compare the contribution measurement methods based on unilateral training, dynamic accuracy, and impact function. The revenue fairness incentive mechanism targets the scenarios involving both data owners and data demanders, wherein data owners receive corresponding benefits, and data demanders obtain high-performance models. In this incentive mechanism, the fairness of the federated learning is modeled by evaluating contributions, expected losses, and expected temporal losses.
The above two incentive mechanisms are validated by the experiments on the homemade UAV power tower inspection image dataset. The three kinds of data heterogeneity are considered including feature skew, quantity skew and mixed skew. The results demonstrate that the fairness correlation coefficients in the two incentive mechanisms can reach 0.96 and 1, respectively. This indicates that the proposed incentive mechanisms can effectively enhance fairness and motivate more participants to engage in federated learning for object detection of power inspection images. Also, it is noted that although we use power object detection as the main application scenario in this work, the proposed incentive mechanism can be applied to various power vision tasks including image classification, object detection, and anomaly detection, and has a certain degree of generality.
keywords:Power inspection, object detection, federated learning, incentive mechanism, fairness
中图分类号:TM11
DOI: 10.19595/j.cnki.1000-6753.tces.231243
国家自然科学基金(92066106)、江苏省科协青年科技人才托举工程(2021031)和东南大学“至善青年学者”支持计划(中央高校基本科研业务费)(2242022R40022)资助项目。
收稿日期 2023-08-01
改稿日期 2023-09-04
仲林林 男,1990年生,副研究员,博士生导师,研究方向为高电压技术、放电等离子体技术、人工智能技术。
E-mail:linlin@seu.edu.cn(通信作者)
刘柯妤 女,1998年生,硕士研究生,研究方向为联邦学习与目标检测在电气领域的应用。
E-mail:lky@seu.edu.cn
(编辑 李 冰)