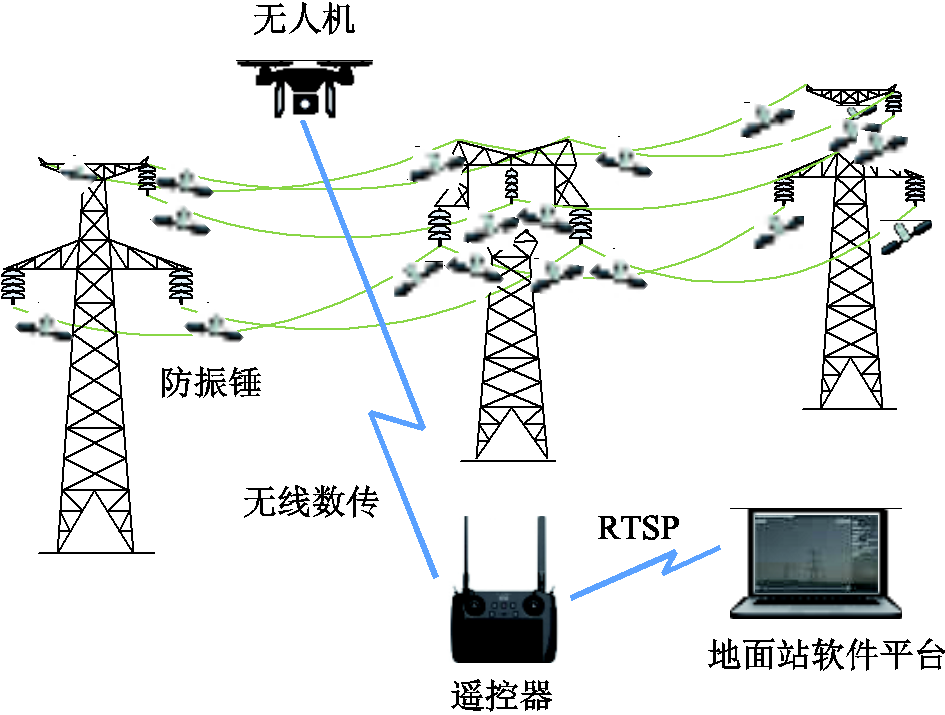
图1 系统整体框架
Fig.1 The overall structure of the system
摘要 作为输电线路中的重要金具部件,防振锤的缺陷将对输电线路构成严重威胁。针对由于防振锤缺陷样本数量稀少、背景复杂、区域形状尺寸不一造成的防振锤缺陷识别能力不足的问题,提出一种基于多尺度卷积注意力机制的防振锤缺陷检测方法。首先,通过统计不同缺陷的防振锤尺寸,设计适应不同类别的多尺度卷积注意力机制,使网络重点关注图像中的防振锤区域;其次,引入结构重参数化方法,以将网络中的多分支结构无损失地转换为单分支结构,在提高网络检测性能的同时维持检测速度在较高水平;最后,以渐进式特征金字塔网络结构(AFPN)为基础,融合更多的浅层网络,提高了网络检测防振锤小目标的能力。实际收集的防振锤缺陷数据集实验结果表明,设计的检测方法可显著提升防振锤缺陷检测的性能,检测精度mAP0.5达到了91.9%,在TITAN XP平台下检测速度达60.88帧/s,可为输电线路防振锤智能化巡检提供参考。
关键词:防振锤 深度学习 注意力机制 实时缺陷检测
防振锤作为输电线路中一种重要的金具,用来吸收或削弱风传递到架空输电导线的动能,以切断导线振动能量的补给线,从而降低架空输电导线的振动损坏[1-2]。然而,由于防振锤长时间暴露在自然环境下,极易产生金属裂纹、螺栓松动等问题,进而引发防振锤缺损、变形、倒置的形态结构缺陷,导致防振锤无法切实有效地发挥防振作用[3]。例如,2017年5月,工作人员在锡西—东苏220 kV输电线路巡检过程中,发现部分防振锤出现锤头缺损及锈蚀缺陷,在对防振锤进行消缺更换作业时发现85%以上的导线在该位置出现了不同程度的断股情况。若不能及时发现并消除防振锤缺陷,极有可能导致输电导线微风振动与舞动,进而严重威胁电力系统的安全稳定运行。
目前,国内电力巡检的主要方式可以分为人工巡检与无人机巡检。传统的人工巡检方式依靠巡检人员对电力设备进行逐一巡查,存在线路盲区、巡检效率低、人力成本高等弊端[4]。相比之下,无人机凭借其体积小、成本低、灵活性高等优势已被广泛应用在电网中,通过搭载光学摄像机、红外热成像仪等装置能尽早地识别与检测导线、绝缘子、金具等设备缺陷。
虽然无人机极大地方便了线路巡检工作,但也产生了海量的图像数据,在后续图像处理上仍需要人工对海量图像进行观察与查缺,且长时间的工作容易引起工作人员的疲劳,使查缺准确度降低。深度学习技术凭借其强大的特征表达能力,以及端到端的网络结构,完美契合了对海量图像自动缺陷检测的需求,既能节约人力成本,也避免了误检漏检的情况[5]。
基于深度学习的目标检测网络可以分为基于回归的一阶段网络,如SSD(single shot multibox detector)[6]、YOLO(you only look once)系列[7-11]等,以及基于区域的二阶段网络,如快速区域卷积神经网络(Faster Region based Convolutional Neural Network, Faster R-CNN)[12]、级联区域卷积神经网络(Cascade Region based Convolutional Neural Network, Cascade R-CNN)[13]等。文献[14]基于多尺度窗口和区域注意力残差网络(Multiscale Window Region Attention Residual Network, MWRA-ResNet),可以识别无线电力终端身份,有效增强电力系统的无线通信安全。文献[15]提出一种基于YOLOv5网络的弱监督和分段迁移学习的方法,用于识别输电线路中的不同覆冰类型。文献[16]通过通道注意机制和空间注意机制改进了YOLOv5网络,对输电线路上的鸟巢进行检测与识别。文献[17]改进了EfficientDet,并对数据集进行增强,检测电网元件本体及其缺陷。文献[18]改进掩膜区域卷积神经网络(Mask Region based Convolutional Neural Network, Mask R-CNN),实现了绝缘子的自爆检测。文献[19]采用残差注意力网络提出了一种基于多尺度特征融合的网络(Multi-Scale Defect Detection Network, MSD2Net),用于绝缘子的缺陷检测。文献[20]将SSD算法应用于电力设备红外成像单目测距,可得到电力设备的类型及距离。文献[21]使用区域建议网络获得绝缘子候选区域,再利用Adaboost分类器实现了绝缘子缺陷的检测。文献[22]改进YOLOX网络,对雾天情况下的绝缘子进行了定位识别。相较于其他电力设备,专门针对防振锤缺陷检测的网络研究相对较少,但也获得了一些成果。文献[23]将并行混合注意力(Parallel Mixed Attention, PMA)模块引入并集成到YOLOv4网络中,有效地降低了防振锤的漏检率,但是网络推理速度较慢。文献[24]在Faster R-CNN中引入KL(Kullback-Leibler)散度和形状约束,提升了防振锤定位框的精度,但无法识别缺陷。文献[25]改进Faster R-CNN算法,构建多设备缺陷检测模型,将防振锤的各种缺损归为一类,整体的精度仅为83.23%。
基于此,本文提出了一种基于多尺度卷积注意力机制的防振锤缺陷检测网络RCA-YOLOv8(RepConv, Conv-A and AFPN YOLOv8)。首先,根据防振锤在图像中的不同尺度,设计了适用于防振锤尺度的多尺度卷积注意力(Convolutional Attention, Conv-A)模块,使网络更好地关注图像中的重点区域;然后,通过结构重参数化方法[26],将网络中的多分支结构转换为单分支结构,在保证网络因多分支结构获得高检测精度的同时,使网络具有单分支结构优秀的推理速度;最后,基于渐进式特征金字塔网络结构(Asymptotic Feature Pyramid Network, AFPN)[27]搭建了AFPN small(AFPNs),融合更多浅层特征,以检测图像中的防振锤小目标。实验结果表明,本文方法可显著提升输电线路防振锤的缺陷检测精度和检测速度。
防振锤智能缺陷检测系统整体框架如图1所示,由无人机巡检系统和地面站软件平台组成。无人机巡检系统经无线数传与RTSP(real-time stream protocol)将输电线路视频流传送至地面站,地面站利用内嵌的RCA-YOLOv8网络对视频流进行检测。当检测到防振锤缺陷时,软件平台会显示、记录并上传防振锤缺陷位置及类型等信息,供运维人员调阅查看,避免产生海量图像。
图1 系统整体框架
Fig.1 The overall structure of the system
无人机巡检系统采用模块化设计,系统硬件主要包括视频采集模块、通信模块和飞行动力模块。视频采集模块选用ZR10三轴云台摄像机,拍摄图像与录制视频最大分辨率均为2 560×1 440,录制视频帧速率为30帧/s;通信模块选用接收机与遥控器进行无线数传,建立通信链路;飞行动力模块由Pixhawk 6C飞行控制器和YH X4120II无刷直流电机等组成,控制无人机的飞行姿态,确保其灵活性与可靠性,无人机持续飞行时间超过30 min。
地面站软件平台支持两种方式的输入:①接收RTSP视频流进行实时检测;②将拍摄的视频和图像储存在无人机的存储卡中,待巡线结束后,将存储卡从无人机中拔出,并将信息拷贝到便携式计算机上进行离线检测,但此方式的实时性较差。
系统采用RTSP接收巡检视频流的目的在于实时分析防振锤缺陷。该协议无法传输单张图像,但是视频流中每秒都包含了30张图像,可以逐帧批量分析,提高防振锤缺陷检测的实时性。
防振锤形状类似于条形,对无人机拍摄的防振锤图像进行分析可发现,不同的拍摄距离、角度以及防振锤的不同缺陷,会使防振锤在图像中呈现不同的尺寸,这就要求主干网络可以提取到不同尺度的特征。同时,为使本文提出的网络与防振锤现实参量相关联,本文设计了专用于防振锤形状的条状卷积,提取图像中不同尺寸的防振锤特征。
条状卷积的形状由防振锤的长宽比确定。图像中防振锤的长宽比与现实防振锤的长宽比差异较大,因此本文通过分析所有图像的标注文件,获取文件中每个防振锤的标注坐标,计算出长宽比,绘制成散点图如图2所示。
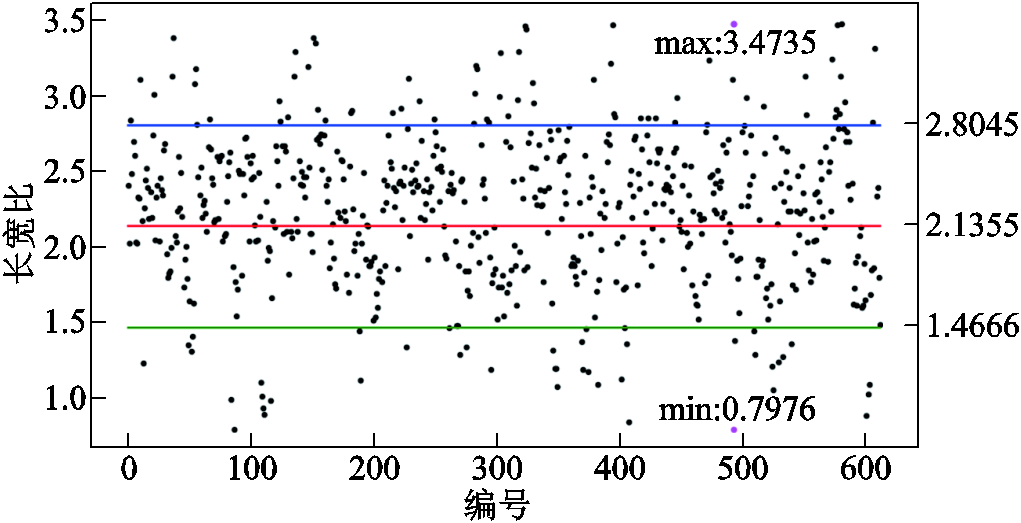
图2 图像中防振锤长宽比散点图
Fig.2 Scatter plot of aspect ratios of dampers in images
从图2中可以看出,数据分散程度大,最大值max为3.473 5,最小值min为0.797 6,故本文确定三个不同形状的条状卷积以适应大多数情况。选取的三个长宽比值分别为mid=(max+min)/2、(max+mid)/2、(min+mid)/2。由于卷积核大小不为小数,故选择3×7、3×5、3×9三个尺寸的条状卷积进行多尺度特征提取。
无人机以不同的视角拍摄防振锤,包括正视视角、俯仰视角及侧视视角,本文针对防振锤的变形、缺损、倒置、正常四个类别进行检测。其中,正视视角拍摄图像中的防振锤尺寸与防振锤的类别相关联,正常与倒置对应较大的3×9卷积核,变形与缺损分别对应中间的3×7与较小的3×5卷积核;俯仰视角会导致图像中防振锤区域宽度降低,尺寸变大,于是各类防振锤对应3×9和3×7卷积核;最后,侧视视角与俯仰视角相反,对应3×7和3×5卷积核。因此,本文通过数据集确定的三个尺寸的条状卷积在无人机拍摄的防振锤数据集上具有通用性。
基于上述的条状卷积,本文设计了Conv-A模块,以获得防振锤多尺度特征,其结构如图3所示。图3中,Xinput为输入特征矩阵;Conv为标准卷积;K为卷积核大小;特征矩阵的维数为H×W×C,其中H为高度,W为宽度,C为通道数。
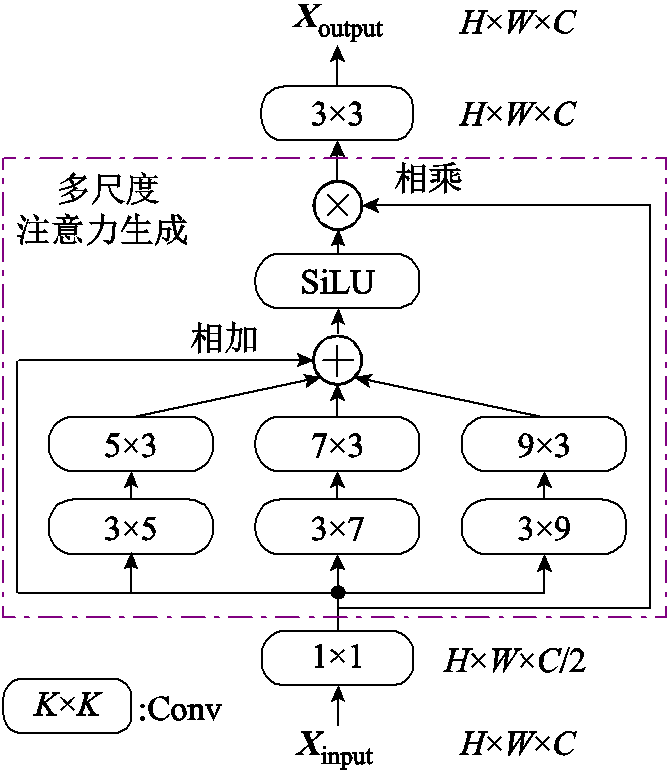
图3 Conv-A模块结构
Fig.3 Conv-A module structure
多尺度注意力生成阶段使用上述三种形状的条状卷积与残差结构,一对条状卷积与普通卷积等价,使用条状卷积能更好地提取图像中防振锤的特征,并且条状卷积处理速度更快。Conv-A模块的1×1卷积将通道数减半,减少注意力生成的计算开销;1×1卷积的输出结果分别经过三组条状卷积与残差结构后相加,将不同尺度提取到的特征进行融合,特征图通道数仍然为C/2,条状卷积采用分组的方式进行卷积,避免增加过量参数;使用激活函数SiLU对融合特征进行非线性处理,完成多尺度卷积注意力的生成;再与原始特征图相乘,将注意力嵌入;最后3×3卷积将通道数恢复为输入通道数C。输入Xinput通过Conv-A模块嵌入多尺度注意力,并且输出通道数等于输入通道数。
深度学习网络由不同的结构或模块组成,每个结构中包含了不同的参数,每个结构与其参数是一一对应的。网络中的多分支结构和残差结构可以帮助网络提取更多的特征,从而提升网络的性能,但也相对降低了网络的推理速度;单分支结构只能提取到单一的特征,推理速度却比多分支结构快。因此,可以在网络训练时采用多分支结构,在网络预测时将多分支结构重参数化为单分支结构,在保证高检测精度的同时提升网络的推理速度。本文使用RepConv卷积结构替换RCA-YOLOv8网络中的3×3卷积,同时将结构重参数化思想运用在Conv-A模块中,将多尺度注意力生成阶段的卷积合并,共同提升RCA-YOLOv8网络的推理速度。
RepConv卷积的训练与推理阶段的结构如图4所示。图4中左侧为结构变化过程,右侧为参数变化过程。训练结构为3×3、1×1卷积和残差结构加批量归一化(Batch Normalization, BN)层组成的多分支结构,经过重参数化后转换为单分支的3×3卷积。图4右侧卷积核中,颜色块指该位置具有参数,白色块为0值。
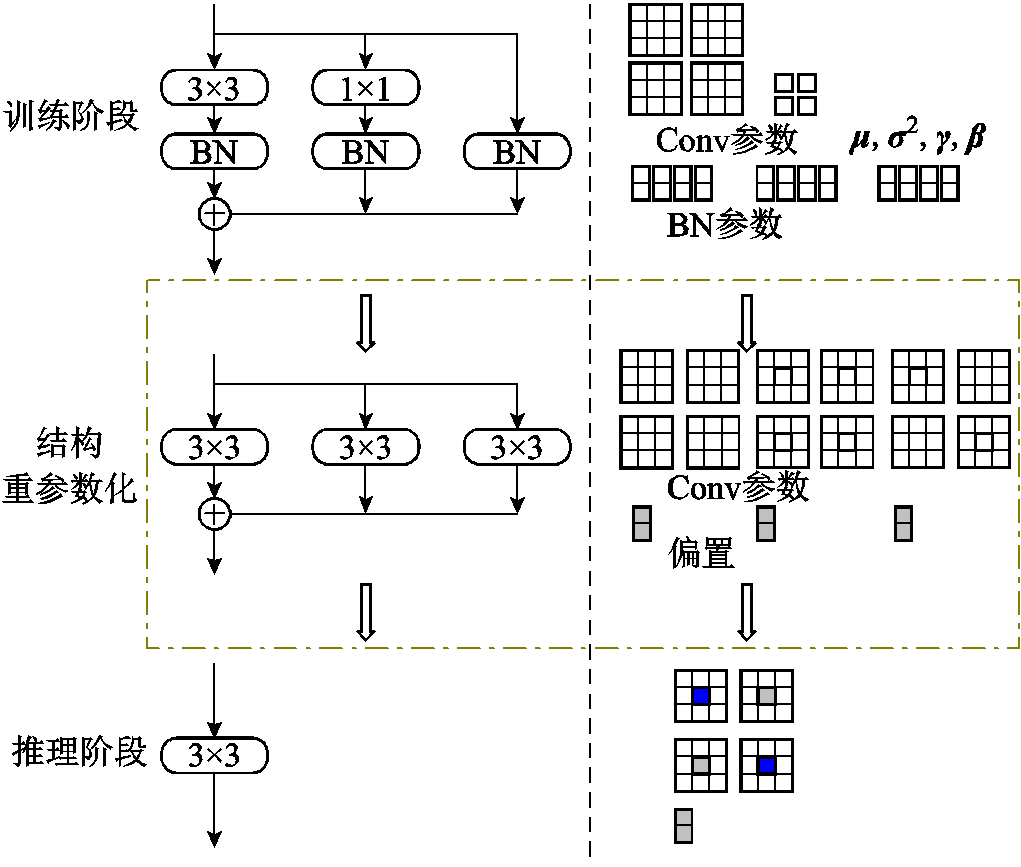
图4 RepConv模块结构
Fig.4 RepConv module structure
RepConv结构重参数化的具体步骤如下:
1)转换1×1卷积和残差结构至3×3卷积。在卷积转换的步骤中,原有的3×3卷积不作改变,1×1卷积可以通过在周围补0的操作转换为3×3卷积,残差结构可构造出四个卷积核,其中两个卷积核中心值为1,其余均为0。输入特征矩阵通过该四个卷积核处理后的输出与输入相同。
2)融合BN层与卷积层,从卷积加BN层的结构转换为带偏置的卷积结构。设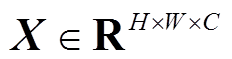 为输入张量。BN层的计算式为
为输入张量。BN层的计算式为
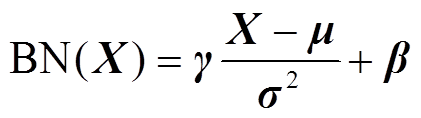 (1)
(1)
式中,μ为样本均值;σ2为样本方差;γ、β为可学习的参数。无偏置的卷积的计算式为
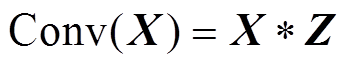 (2)
(2)
式中,Z为卷积核的参数。输入张量X经过卷积层和BN层的处理可以表示为
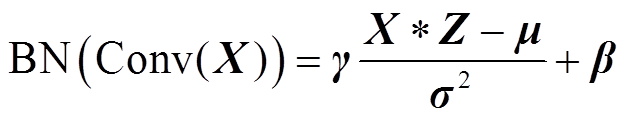 (3)
(3)
式(3)可转换为
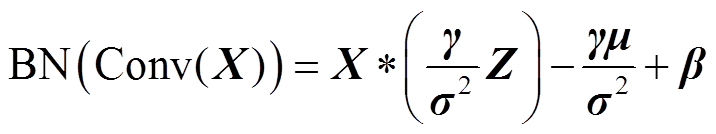 (4)
(4)
基于式(4),令
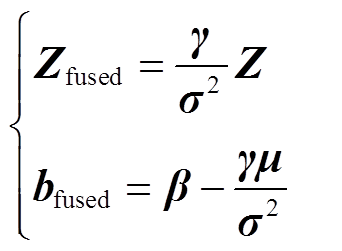 (5)
(5)
式中,Zfused和bfused分别为融合后的卷积核参数与偏置。最终卷积和BN层融合的结果为
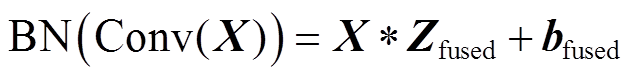 (6)
(6)
通过上述融合方法,可以将步骤1)中的3×3卷积层与BN层融合,减少网络的参数量。
3)分别融合卷积层与偏置,将3个3×3卷积核及其3个偏置对应叠加,得到单个3×3卷积核及其偏置。
设三组3×3卷积的卷积核参数和偏置分别为Z1、Z2、Z3和b1、b2、b3,输入张量通过三组3×3卷积及其偏置处理后的输出张量 可以表示为
可以表示为
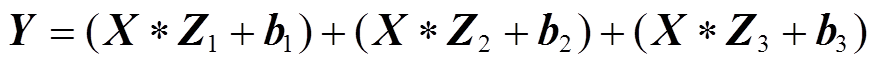 (7)
(7)
同时,式(7)等价于
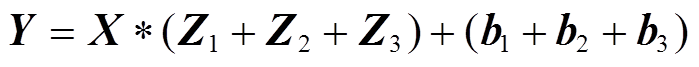 (8)
(8)
基于上述计算,最终将训练阶段的RepConv多分支结构,通过结构重参数化转换为单分支的卷积结构。另外,将Conv-A模块的多尺度注意力生成阶段经由上述的原理进行结构重参数化,过程如图5所示。
首先,分别将三个尺度的两个条状卷积融合为单个方形卷积;其次,将三个尺度的单个卷积与残差结构分别转换为9×9卷积,与最大的卷积核尺寸一致;最后,将四组9×9卷积融合为一个9×9卷积。多尺度注意力生成阶段中不包含BN层,因此仅需将卷积进行融合,经过结构重参数化的Conv-A模块可以大幅减少参数量,在保证网络能关注于防振锤区域、维持检测高性能的同时提升网络的推理速度。
本文基于YOLOv8的特征提取结构设计了Conv-A Block结构,作为主干网络中的特征提取结构。Conv-A Block结构是一个高效的多分支网络结构,通过控制最短和最长的梯度路径,使网络能够融合尽可能多的特征,并且具有更强的鲁棒性。通过RepConv和Conv-A注意力机制提取多尺度特征,从而高效地获取更多的防振锤特征。Conv-A Block结构如图6所示,共有3个分支。首先,使用卷积与拆分,将Conv输出的通道数为C的特征图,拆分为两个通道为C/2的特征图,降低计算量;其次,对其中一个划分的特征图使用两组RepConv和Conv-A结构提取特征;再次,将另一个划分后不做更改的特征图与两个Conv-A的输出拼接,得到通道数为3C/2的特征图;最后,通过通道数为C的Conv模块后得到通道数与输入一致的输出特征图。
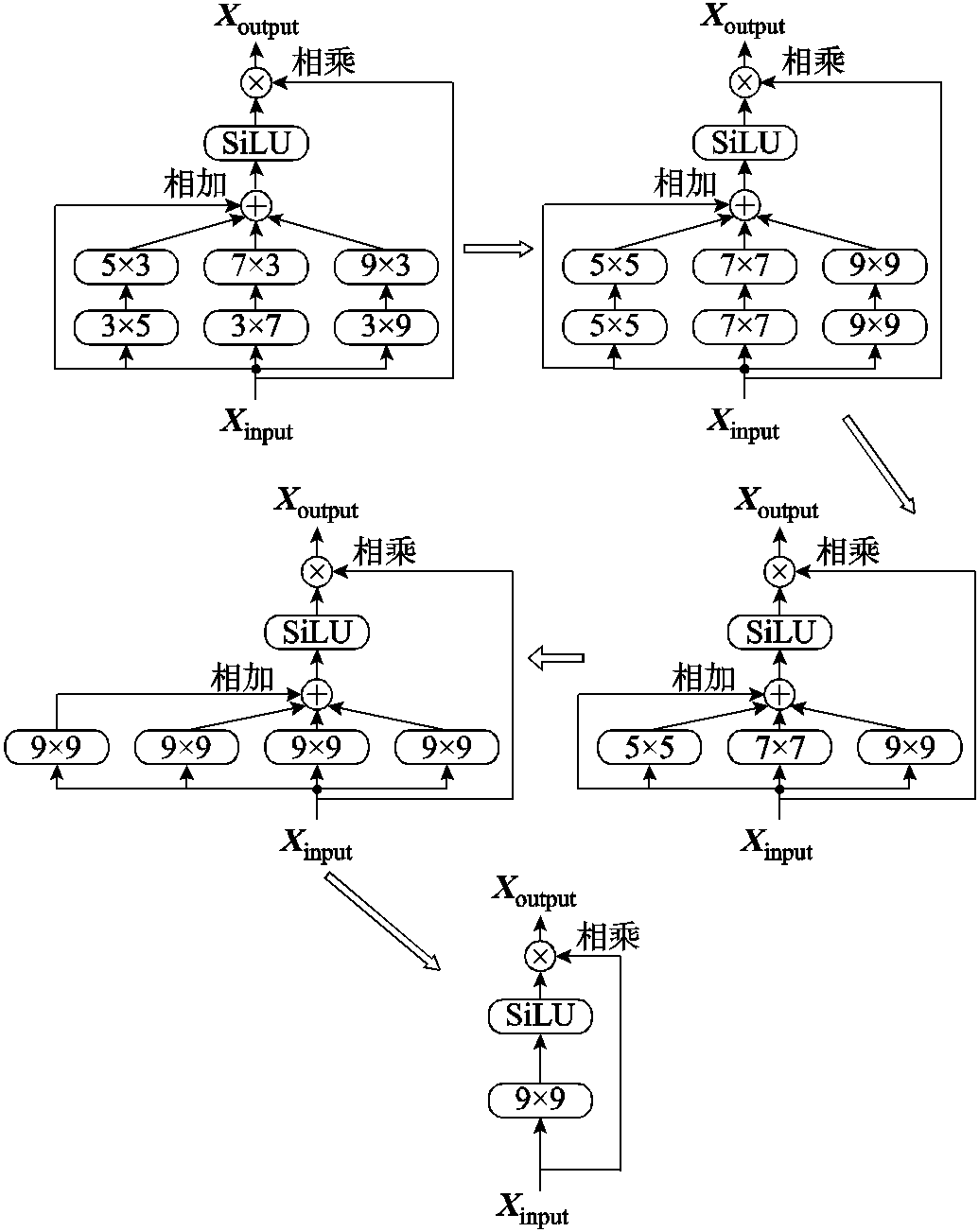
图5 Conv-A模块结构重参数化
Fig.5 Conv-A module structural re-parameterization
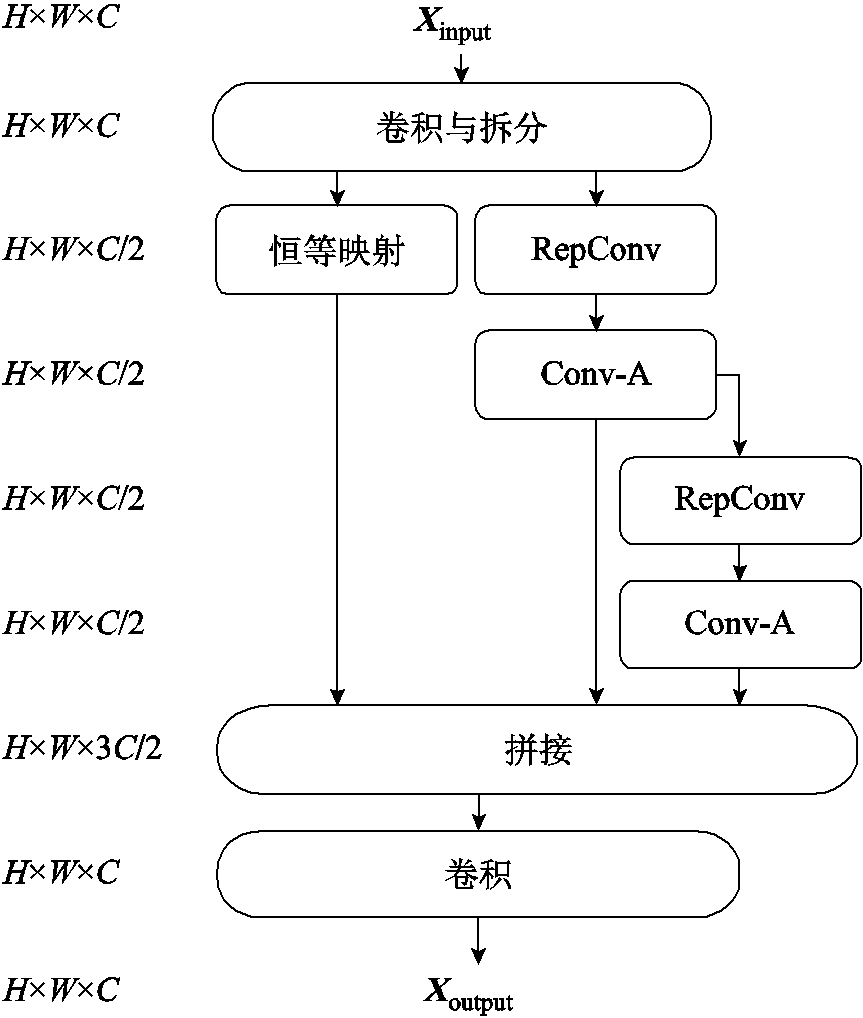
图6 Conv-A Block模块结构
Fig.6 Conv-A Block module structure
在RCA-YOLOv8主干网络中,共有C1~C5五个阶段的特征提取。C1仅使用RepConv,将输入特征图矩阵尺寸减半,通道数升至32;C2~C5阶段由RepConv和Conv-A Block组成,其中C2、C5阶段的Conv-A Block使用两组RepConv和Conv-A拼接,C3、C4阶段使用四组拼接。RepConv负责特征图下采样与升维,Conv-A Block进行特征提取,每个阶段的特征图尺寸和通道数较上一阶段分别减半和倍增,最终C5阶段的特征图尺寸为输入的1/32,通道数为512。
由于防振锤自身尺寸较小,在无人机拍摄的输电线路可见光图像中有一定数量的防振锤呈现为小目标,并且较为密集,这就需要网络的特征融合阶段可以更多地整合小目标的信息,避免防振锤本体及其缺陷的漏检。AFPN使用自适应空间特征融合(Adaptively Spatial Feature Fusion, ASFF)[28]逐步融合相邻层次中的特征信息,避免非相邻层次间的较大语义差距。AFPN与路径聚合网络(Path Aggregation Network, PANet)一致对YOLOv8的后三个阶段进行特征融合。本文在AFPN的基础上,进一步融合浅层网络构造了AFPN Small(AFPNs)结构,如图7所示。
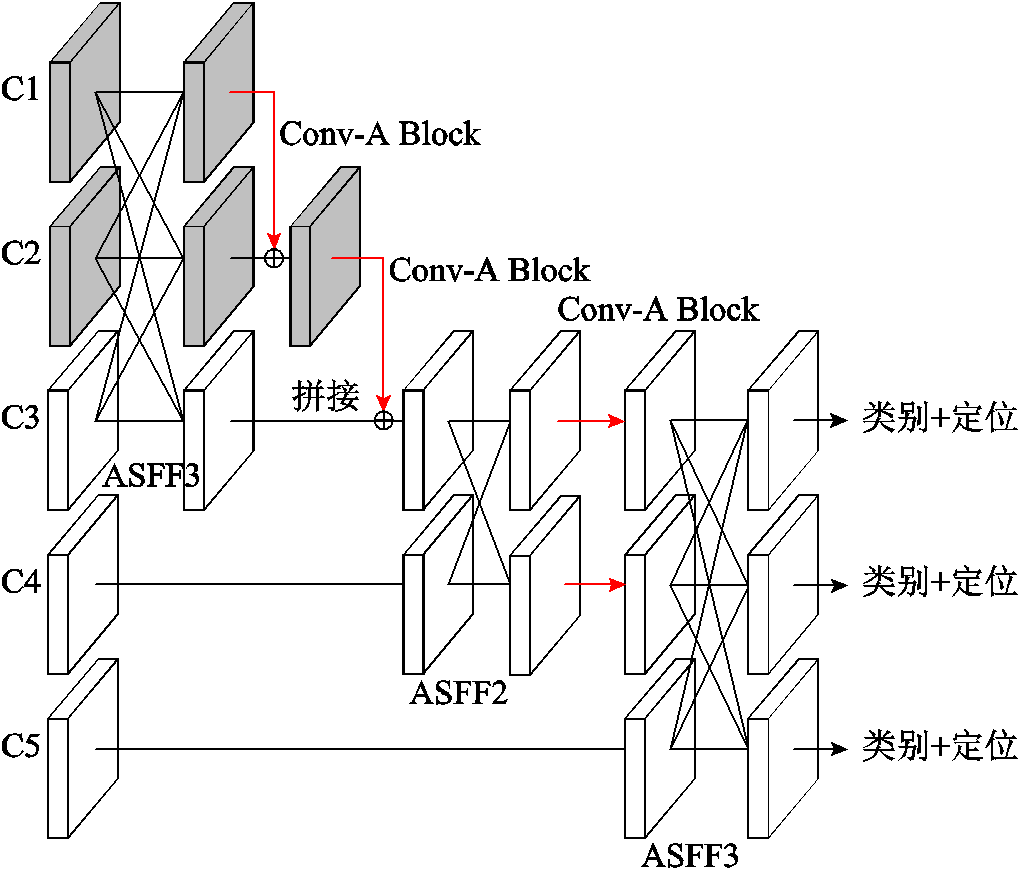
图7 AFPNs的结构
Fig.7 AFPNs structure
浅层阶段C1~C2中包含了部分小目标的信息,因此将C1~C2阶段的特征同样进行融合操作,可以帮助网络关注到防振锤小目标的信息。AFPNs采用渐进式结构,从浅层网络逐步融合深层网络,防止特征信息在传输和交互过程中丢失或退化。AFPNs首先使用ASFF与自上而下结构将C1~C2阶段的特征融合至C3阶段,在自上而下的结构中使用Conv-A Block再次整合特征;然后C3与C4通过ASFF的处理,分别经过Conv-A Block的整合后,与C5再使用ASFF结构进行处理;最后输出三个特征图进行预测。
本文数据集中图像为某供电公司无人机采集的现场图像,共计469张。由于网络训练需要大量图像,本文使用数据增强的方法避免网络出现过拟合。数据集设有变形、缺损、倒置、正常四个目标检测种类,对应标签名分别为Deformation、Damage、Inversion、Normal。为切合实际工程应用,本文充分考虑现场实际应用,选取了不同情况下采集的防振锤图像,数据集部分图像及描述如图8和表1所示。

图8 不同情况下采集的防振锤现场图像
Fig.8 Site images of damper collected under different conditions
表1 数据集图像情况描述
Tab.1 The dataset image description

图像问题图号缺陷种类描述 正常拍摄(a)(b)正常、倒置图(a)远焦多目标,图(b)近焦少目标 拍摄角度(c)(g)正常非正视角度拍摄 光照剧烈(d)(h)正常、缺损光照过强导致防振锤整体虚化,特征不明显
(续)

图像问题图号缺陷种类描述 光照太弱(e)正常、变形防振锤区域与背景融为一体 二维遮挡(f)(g)(h)正常、变形、缺损遮挡导致防振锤部分特征丢失 环境复杂(h)正常、缺损雾天拍摄 图像模糊(i)正常无人机相机因风造成抖动
此外,当前深度学习网络在电力行业应用中普遍存在训练样本匮乏、样本类别不平衡、小目标检测困难等问题[29],现阶段的图像扩充方式也仅限于先对图像进行扩充,再通过手动标注数据集来扩充样本。然而手动标注数据集耗时费力,因此本文提出了一种新的数据集自动扩充方法,可以由少量带标注的图像自动完成图像及标注的扩充,免去了扩充图像的标注时间。同时,在使用无人机进行线路巡检时,可能存在因线路环境复杂或者无人机需要与线路保持安全距离而无法近距离拍摄的问题,这些都会使视频中的防振锤呈现为小目标,为此本文的扩充方法添加了尺度变化。一方面,缩小目标可以增加小目标的训练数量;另一方面,将小目标扩大也扩充了正常大小目标的训练量。
具体扩充方法分为以下三个步骤:
1)制作数据集。使用Labelme软件标注原始数据集,按照7:2:1的比例划分为训练集、验证集、测试集,得到标注文件。
2)图像扩充。包括非尺度变换模拟不同拍摄背景和尺度变换模拟不同的拍摄距离。图像非尺度变换包括y轴翻转、添加高斯噪声、添加椒盐噪声、调整亮度。图像尺度变换包括扩大目标与缩小目标,在输入端通过数据增强的方法提升网络对小目标的检测能力。图像扩充时引入随机因子,避免原始图像大量重复,并缓解数据集类别不平衡的问题。
3)更新标注文件。现有的数据集扩充方法仅对图像进行扩充,再手动标注信息,本文根据图像扩充过程中目标框的坐标位置变化,自动更新标注信息。更新标注坐标的具体方法可分为非尺度变换与尺度变换。
(1)非尺度变换更新方法。设原始目标框左上角及右下角坐标分别为(m1, n1)、(m2, n2),则y轴翻转操作后新坐标的计算式为
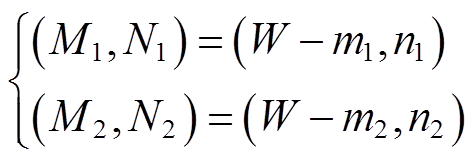 (9)
(9)
式中,(M1, N1)、(M2, N2)为翻转后坐标。除y轴翻转外的非尺度变换,由于没有改变标注点位置,只需要更改相应文件名,即可生成新的标注信息。
(2)尺度变换更新方法。对于尺度变换,为了保证防振锤的形状不发生畸变,需要变换后图像的宽高比与原图一致。同时,在原图上直接进行随机裁剪可能会丢失目标,因此本文采用在目标框周围进行随机填充的方式等效随机裁剪。扩大与缩小目标的过程如图9所示。
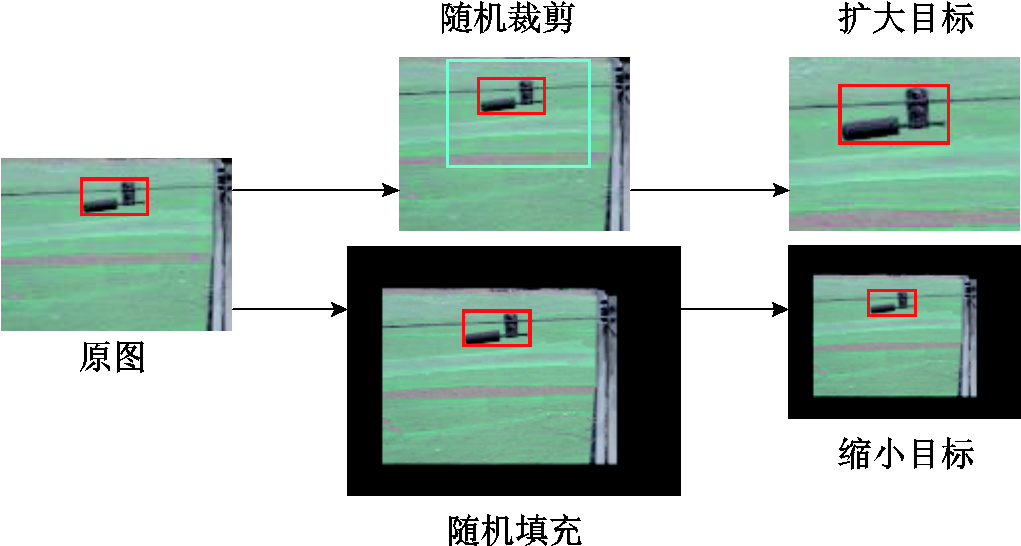
图9 图像尺度变换过程
Fig.9 Image scale transformation process diagram
设在目标框或原图上、下、左、右填充的值分别为y1、y2、x1、x2,其中y1、y2、x1随机生成以保证随机性,x2按照式(10)进行计算。
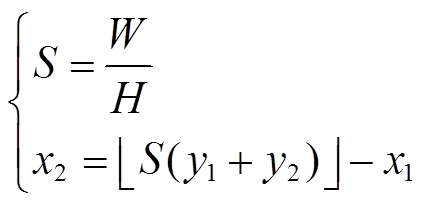 (10)
(10)
式中,S为图像的宽高比;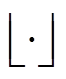 为向下取整运算。设T为变换比,(e1, f1)、(e2, f2)为原始坐标,(E1, F1)、(E2, F2)为尺度变换后坐标,扩大与缩小后的目标框坐标更新方法分别为
为向下取整运算。设T为变换比,(e1, f1)、(e2, f2)为原始坐标,(E1, F1)、(E2, F2)为尺度变换后坐标,扩大与缩小后的目标框坐标更新方法分别为
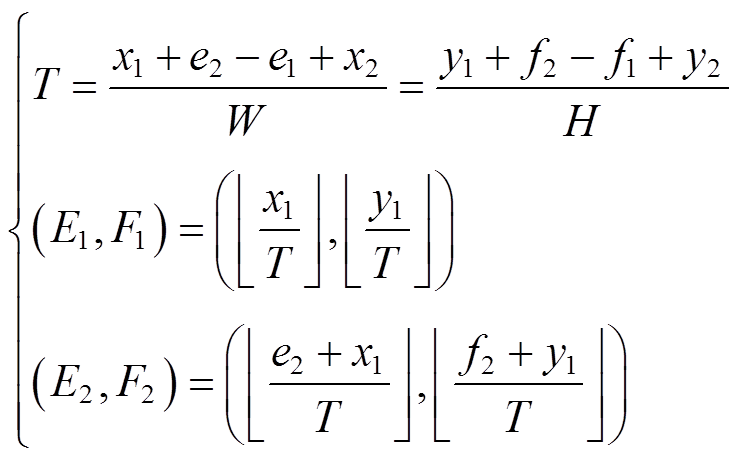 (11)
(11)
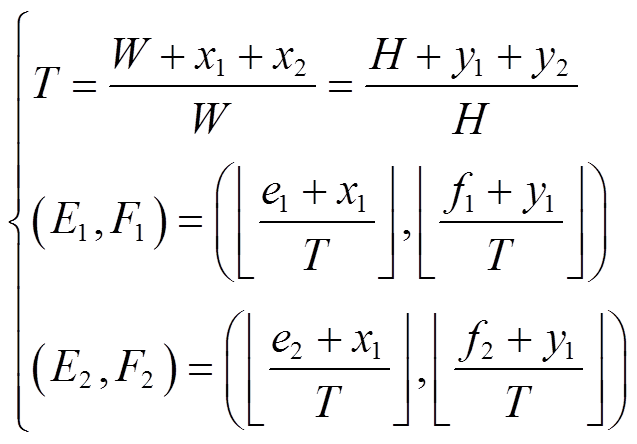 (12)
(12)
若式(10)中x2、式(11)、式(12)中新坐标出现小数则均采取向下取整,由此产生的误差相对于图像尺寸可以忽略。在数据集扩充过程中引入了随机因子,以达到正常与缺陷类别样本的平衡。
本文提出的数据集扩充方法可以在短时间内将少量带标注的图像进行大量扩充,并且扩充的新图像无需再进行人工标注,可以直接进行训练,节省大量标注时间,提高网络的准确度、泛化性。数据集自动化扩充后共有4 690幅图像,数据集格式为COCO2017。数据集增强前后种类标签数见表2。
表2 数据集种类标签数
Tab.2 The number of dataset type labels
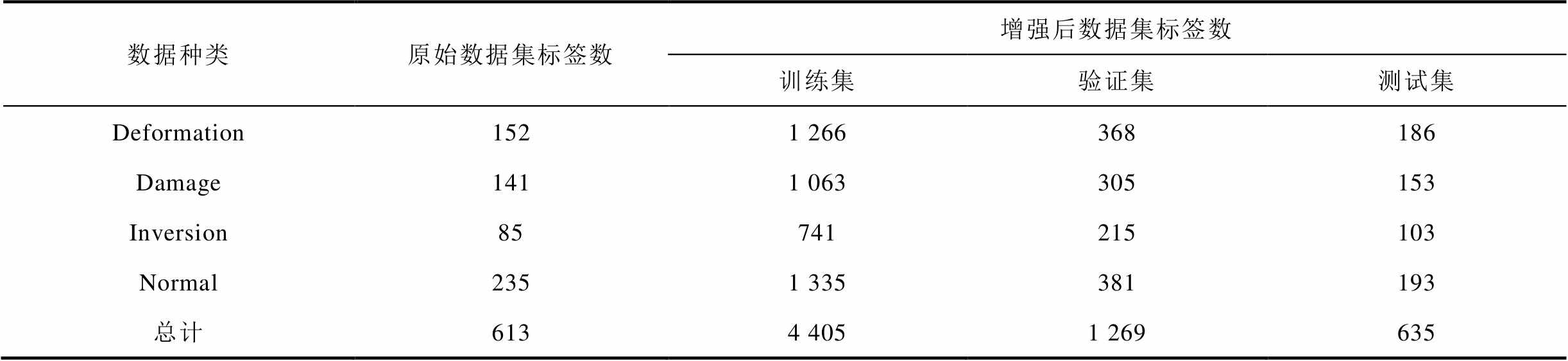
数据种类原始数据集标签数增强后数据集标签数 训练集验证集测试集 Deformation1521 266368186 Damage1411 063305153 Inversion85741215103 Normal2351 335381193 总计6134 4051 269635
实验在Ubuntu16.04系统下运行,服务器CPU为Inter i7-6850k、内存为64 GB,网络在两块显存为12 GB的TITAN XP显卡上训练并预测。Python版本为3.8,PyTorch版本为1.7.0,并采用Pycharm2021.1.3软件运行程序。
本文将RAC-YOLOv8网络训练图像尺寸统一为1 280×960;训练过程中,每轮所选取的样本数batch_size设置为16;选用SGD优化器,初始学习率为0.001;训练轮次为300轮,训练时间约为9 h。
实验中分别对各个网络计算精确度P、召回率R、平均精确度均值mAP0.5与mAP0.5:0.95,mAP0.5为交并比(Intersection over Union, IOU)设置为0.5时计算得到的mAP;mAP0.5:0.95为IOU从0.5到0.95,步长为0.05时计算得到的mAP。参数量Params、帧率FPS,并进行定量分析对比网络性能。本文网络嵌入地面站软件平台,对实时性要求高,因此FPS也是评价本文网络的一项重要指标。
精确度P和召回率R的计算式分别为
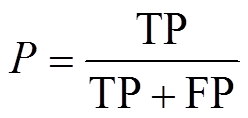 (13)
(13)
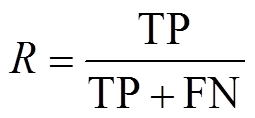 (14)
(14)
式中,TP(truth positive)为预测正确的正样本数量;FP(false positive)为负样本被预测正确的数量;FN(false negative)为正样本被预测错误的数量。由P和R可绘制P-R曲线,通过计算曲线下面积可得各类别的平均精确度(Average Precision, AP),再进行平均后得到平均精确度均值mAP,表示为
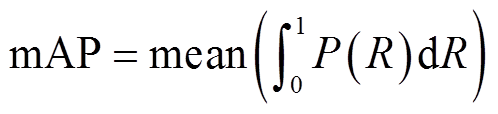 (15)
(15)
式中,mean(·)表示计算均值。
Params表示网络具有的参数量,由网络中所有模块参数量加和得到。各个网络参数量的计算与输入图像的尺寸无关。
FPS指网络平均每秒的检测帧数,数值越大表示网络推理速度越快。
本文提出的RCA-YOLOv8防振锤检测网络为单阶段的无锚框检测网络,为了验证其优越性,将其与先进的目标检测网络进行对比,包括双阶段检测网络Faster R-CNN、Cascade R-CNN,单阶段检测网络SSD、YOLOv5、YOLOv8,单阶段的轻量型检测网络EfficientDet[30]和单阶段无锚框网络FreeAnchor[31]。不同网络对比实验结果见表3,训练过程中轮数与mAP0.5变化曲线如图10所示。
表3 不同网络对比实验结果
Tab.3 The results of differents network comparative experiments
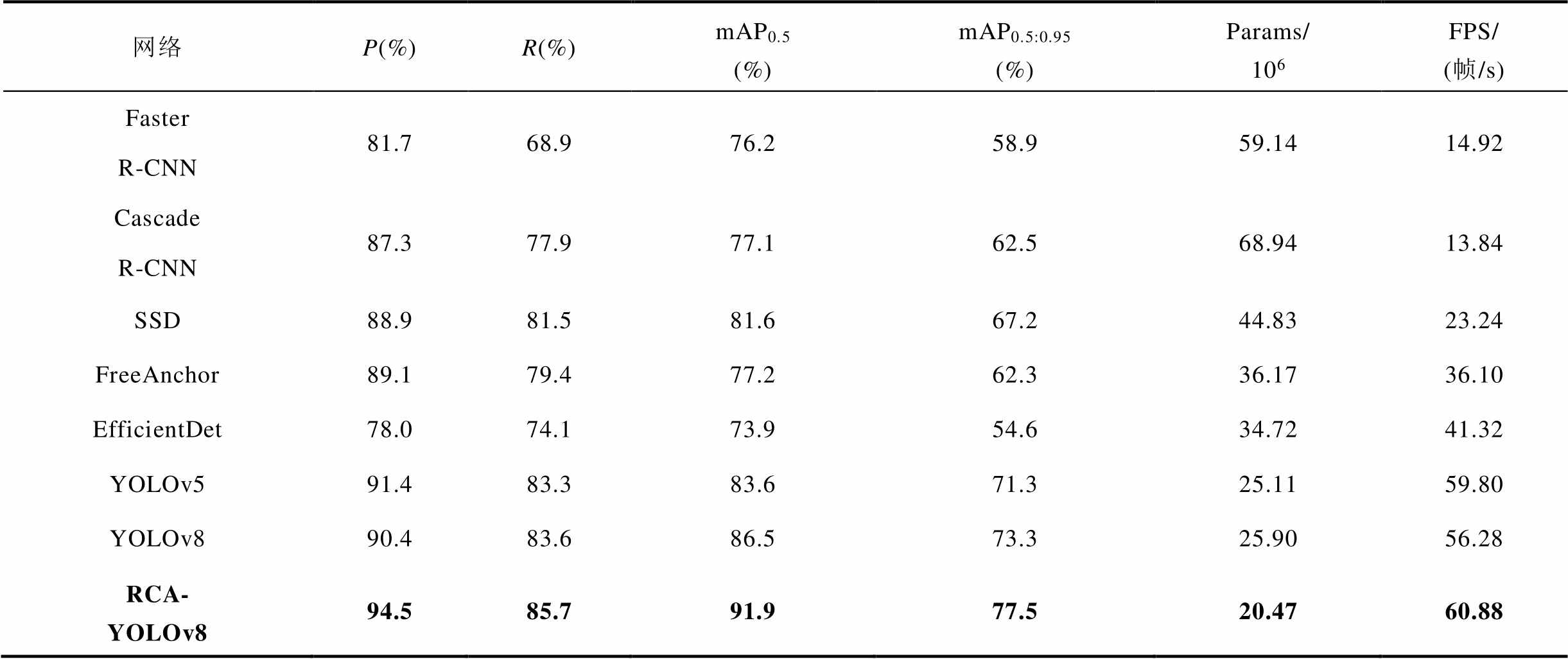
网络P(%)R(%)mAP0.5(%)mAP0.5:0.95 (%)Params/ 106FPS/(帧/s) FasterR-CNN81.768.976.258.959.1414.92 CascadeR-CNN87.377.977.162.568.9413.84 SSD88.981.581.667.244.8323.24 FreeAnchor89.179.477.262.336.1736.10 EfficientDet78.074.173.954.634.7241.32 YOLOv591.483.383.671.325.1159.80 YOLOv890.483.686.573.325.9056.28 RCA-YOLOv894.585.791.977.520.4760.88
从对比结果可以看出,与经典目标检测网络相比,RAC-YOLOv8网络的平均精确度与检测速度均最高,模型参数量也最少。两阶段目标检测网络Faster R-CNN与Cascade R-CNN的mAP0.5值均较低,这是因为其使用特征金字塔(Feature Pyramid Networks, FPN)结构导致低层网络上的位置信息大量丢失,同时两阶段检测模式的网络检测速度缓慢,Faster R-CNN网络的FPS仅为14.92帧/s,难以满足实时缺陷检测的需求。SSD、YOLOv5、YOLOv8网络与RAC-YOLOv8网络均为单阶段目标检测网络,直接由特征图回归目标位置与类别,检测速度大幅提升。相较于YOLOv8网络,RAC-YOLOv8网络的参数量下降了5.43×106,速度提升了4.60帧/s。YOLOv5网络参数量为25.11×106,FPS为59.80帧/s,而RAC-YOLOv8网络参数量仅为20.47×106,FPS也取得了最优值60.88帧/s。与单阶段轻量型EfficientDet和无锚框FreeAnchor相比,RAC-YOLOv8网络参数量更少,检测速度也更快。此外,RAC-YOLOv8网络使用独特的多尺度注意力与渐进式特征融合结构,mAP0.5和mAP0.5:0.95也较其他网络取得了最高值91.9%和77.5%。从图10中也可以看出,RAC-YOLOv8最终取得的mAP0.5相较于YOLOv8网络提升了5.4%。
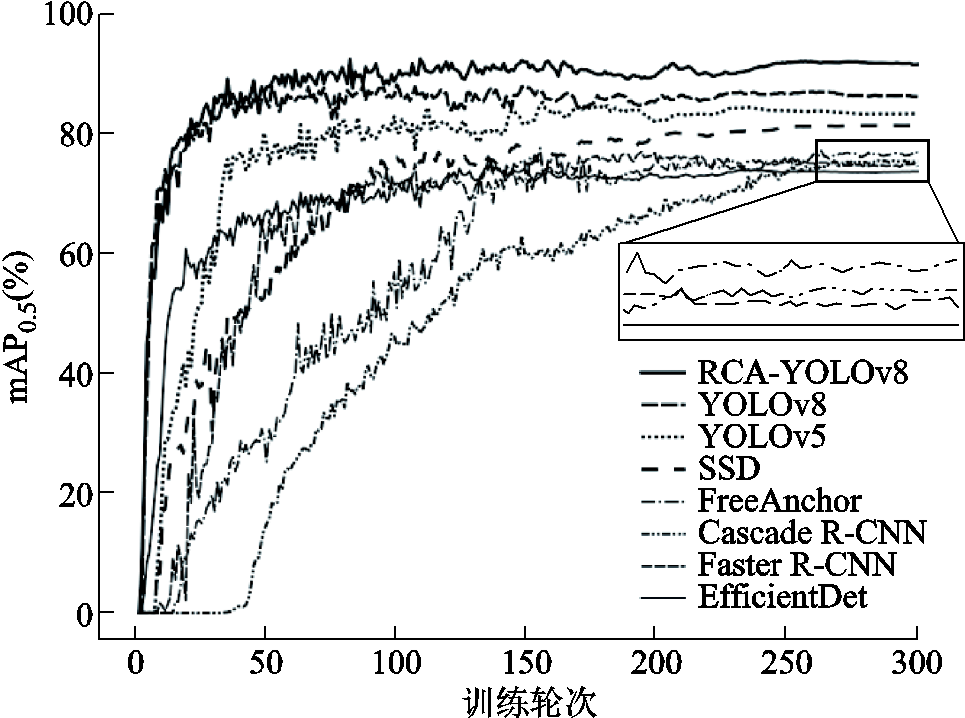
图10 不同网络的mAP0.5曲线
Fig.10 mAP0.5 curves of different networks
RCA-YOLOv8网络与Cascade R-CNN、FreeAnchor、EfficientDet、YOLOv8网络在测试集上的可视化结果如图11所示。
在A、B、C、D四组实验中,RAC-YOLOv8网络的置信度最高,预测框更加精准,综合表现最佳。EfficientDet网络在A组实验中将Deformation类的防振锤误检为正常防振锤,其他网络均准确检测出。同样在A组中,左侧的Deformation类防振锤被杆塔遮挡,导致部分特征丢失,仅YOLOv8网络与RCA-YOLOv8网络识别到该防振锤,并且RCA-YOLOv8网络的置信度91%高于YOLOv8网络的89%。但在C组中,YOLOv8网络也出现了漏检情况。Cascade R-CNN、FreeAnchor、EfficientDet网络的漏检情况同样发生在B组和C组中,漏检的防振锤在图像中均呈现为小目标,说明在防振锤小目标检测方面,RCA-YOLOv8网络取得了最好的效果,这得益于其中的Conv-A与ASFFs结构,使RCA-YOLOv8网络能更好地提取并融合小目标的特征。在实际的线路巡检工作中,漏检可能会导致严重的事故。在定位准确性方面,RCA-YOLOv8网络可以更好地贴近防振锤的边界,防振锤区域没有超出定位框,同时定位框内包含的背景区域更少,进一步证明RCA-YOLOv8网络具有较强的识别与定位性能。

图11 不同网络的可视化结果
Fig.11 Visualization results of different networks
RCA-YOLOv8由几个不同的模块组成,为了进一步验证RCA-YOLOv8网络中各个模块的有效性,选取了不同阶段的网络作为对比。第一组为不同注意力机制的比较;第二组验证Conv-A Block和结构重参数化的有效性;第三组为不同特征融合阶段Neck网络的对比,以探究AFPNs结构在防振锤小目标识别方面的贡献。
3.4.1 Conv-A卷积注意力机制消融实验
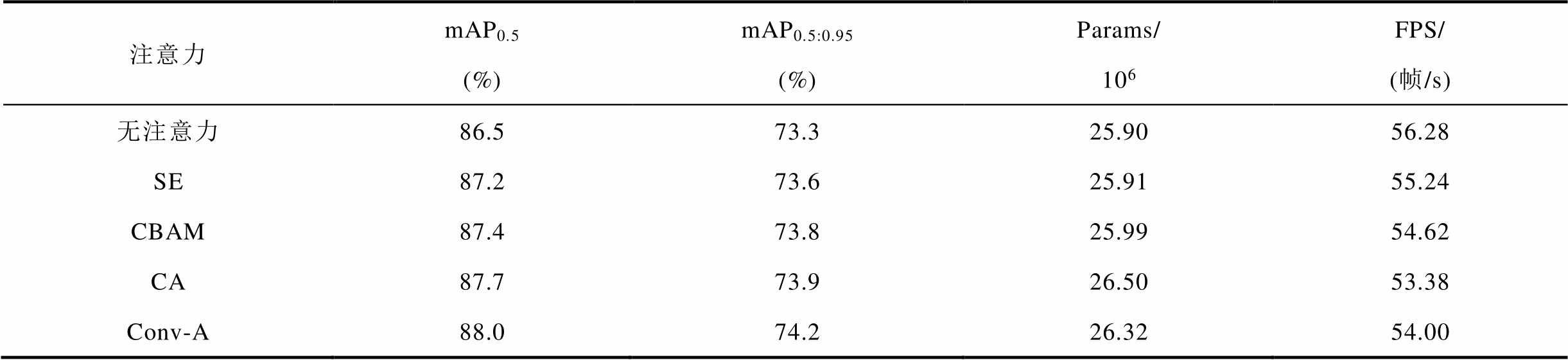
网络中的自注意力机制可以帮助目标检测网络忽略无关信息关注重点信息。Grad-CAM[32]使用类激活图技术,可以在视觉上对网络进行可视化解释。因此,为了对比不同注意力机制以及探究多尺度卷积注意力Conv-A对RCA-YOLOv8网络的贡献,本文分别使用压缩和激励网络[33](Squeeze-and-Excitation, SE)、卷积块注意力模块[34](Convolutional Block Attention Module, CBAM)、协调注意力[35](Coordinate Attention, CA)在网络的相同位置替换Conv-A,并对主干网络最后一层使用Grad-CAM可视化体现不同注意力机制的有效性。Grad-CAM可视化结果如图12所示,不同注意力机制的对比结果见表4。

图12 Grad-CAM可视化结果
Fig.12 Grad-CAM visualization results
表4 不同注意力机制的对比结果
Tab.4 Comparative results of different attention outcomes
注意力mAP0.5(%)mAP0.5:0.95(%)Params/ 106FPS/ (帧/s) 无注意力86.573.325.9056.28 SE87.273.625.9155.24 CBAM87.473.825.9954.62 CA87.773.926.5053.38 Conv-A88.074.226.3254.00
图12中,无注意力表示在网络中相应的位置不添加自注意力机制,使用RepConv代替。可以看出,网络在不添加自注意力时,图像中的背景有较多区域被激活,但网络关注的重点,即深色区域仍在防振锤目标上。在C组与D组中,图像中的防振锤大目标被网络重点关注,但没有完整地提取小目标特征,导致防振锤小目标区域颜色较浅。通过纵向对比可以看出,本文提出的多尺度卷积注意力机制Conv-A可以更好地提取防振锤的特征,使网络重点关注该区域,并且在背景中被激活的区域最少,体现了Conv-A在提取防振锤特征时的优越性,以及对RCA-YOLOv8网络性能的提升做出的贡献。
从表4中可以看出,Conv-A结构取得了最佳的mAP0.5和mAP0.5:0.95值,与GradCam可视化结果一致,并且可以很好地平衡精度与参数、速度之间的关系。
3.4.2 Conv-A Block和结构重参数化消融实验
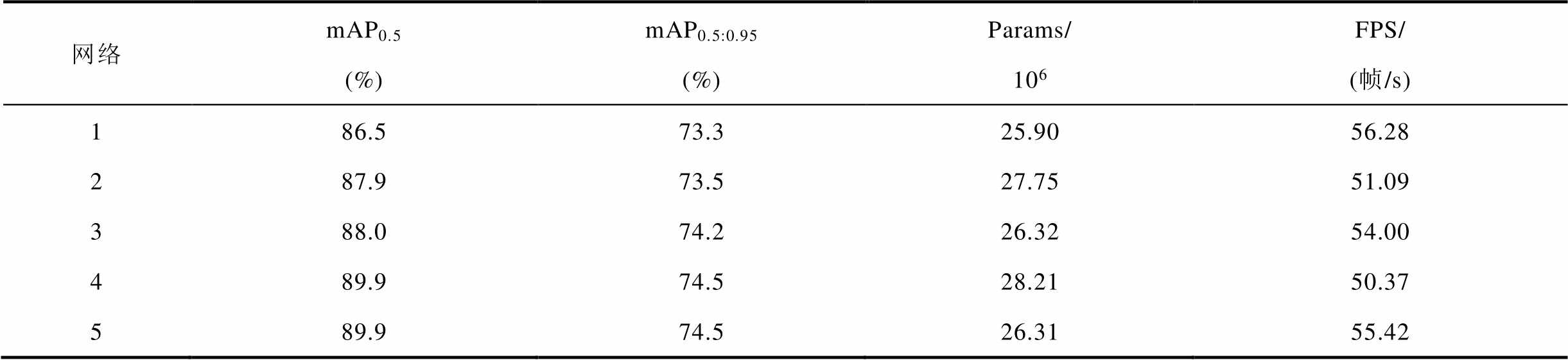
结构重参数化方法可以将网络中对提升性能有帮助的RepConv和Conv-A的多分支结构转换为推理速度较快的单分支结构,并保留多分支的性能。在RCA-YOLOv8网络训练时,所有的3×3卷积均被替换为RepConv,推理时利用结构重参数化方法处理RepConv和Conv-A,将其均转换为单分支结构。结构重参数化阶段不同网络的对比结果见表5。表5中,网络1为YOLOv8原始网络;网络2为YOLOv8+RepConv,将YOLOv8网络中3×3卷积替换为RepConv;网络3为YOLOv8+Conv-A,在YOLOv8网络的特征提取阶段使用Conv-A注意力结构,但不使用RepConv;网络4为YOLOv8+ RepConv+Conv-A(RC-YOLOv8)网络,即同时使用RepConv和Conv-A结构;网络5为对网络4进行结构重参数化后的网络。在各网络训练时,Neck结构均采用YOLOv8的PANet结构。
表5 结构重参数化阶段不同网络的对比结果
Tab.5 Comparative results of different networks in the stage of structural re-parameterization
网络mAP0.5(%)mAP0.5:0.95(%)Params/ 106FPS/ (帧/s) 186.573.325.9056.28 287.973.527.7551.09 388.074.226.3254.00 489.974.528.2150.37 589.974.526.3155.42
通过对比表5中网络1和网络2、3、4可以看出,RepConv和Conv-A的多分支结构有助于提升网络的检测性能,但也伴随着参数的上升和推理速度的下降,相比之下,Conv-A可以以更小的计算代价获取更高的检测性能。对比网络4和5,经过结构重参数后mAP0.5和mAP0.5:0.95均没有发生变化,参数量下降了1.9×106,推理速度上升了5.05帧/s。最后对比网络1和5,mAP0.5和mAP0.5:0.95分别上升了3.4%和1.2%,然而参数量和推理速度变化非常小。由此可以看出,多分支结构和结构重参数化可以以非常小的代价实现网络检测能力的提升。
3.4.3 ASPNs结构消融实验
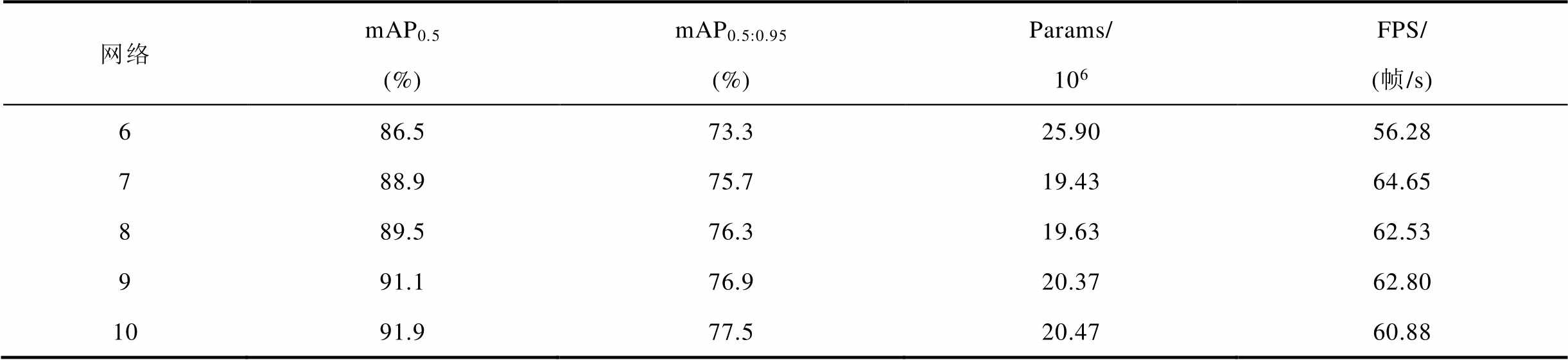
Neck网络将不同层次的特征进行聚合,分别检测图像中的大、中、小目标,但小目标的检测在网络中通常是不易的。本文对比了使用PANet进行特征融合的YOLOv8网络、YOLOv8 + AFPN网络、YOLOv8 + AFPNs网络、RC-YOLOv8+AFPN网络、RC-YOLOv8+AFPNs(RCA-YOLOv8)网络,并分别指代为网络6~10,评价指标见表6,训练过程中的mAP0.5和mAP0.5:0.95变化曲线如图13所示,图中各网络按指标由高到低排序。此外,图14展示了网络9和10在检测防振锤小目标时的可视化结果。
表6 不同Neck网络的对比结果
Tab.6 Comparison results of different Neck networks
网络mAP0.5(%)mAP0.5:0.95(%)Params/ 106FPS/ (帧/s) 686.573.325.9056.28 788.975.719.4364.65 889.576.319.6362.53 991.176.920.3762.80 1091.977.520.4760.88
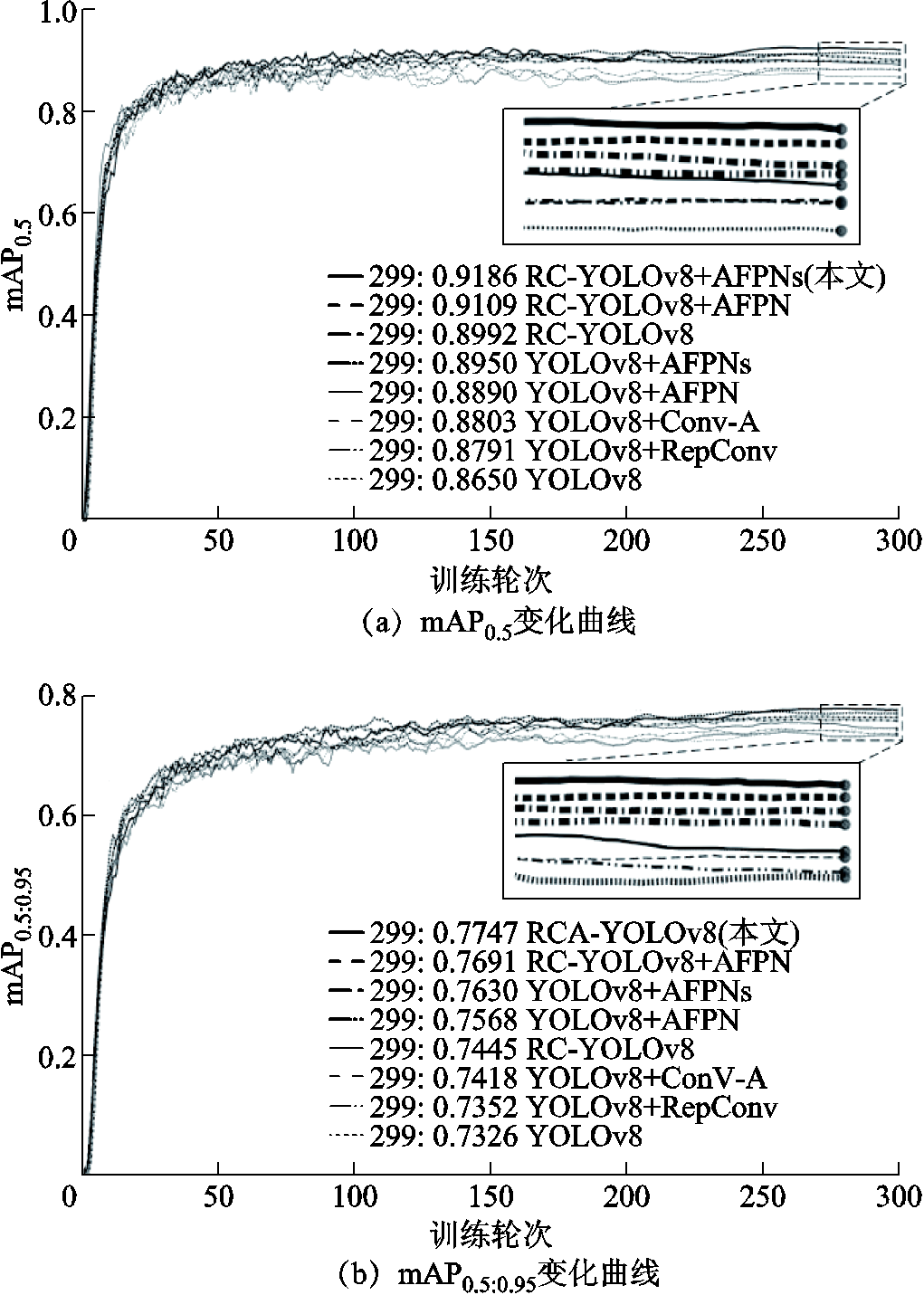
图13 训练过程中mAP0.5和mAP0.5:0.95变化曲线
Fig.13 mAP0.5 and mAP0.5:0.95 variation curves during training

图14 防振锤小目标检测对比结果
Fig.14 Comparison results of detection for dampers small object
由表6可以看出,AFPN和AFPNs相较于PANet结构具有显著的优势。对比网络6和网络7、8,在推理速度方面,使用AFPN结构的网络7相较于网络6提升了8.37帧/s,同时mAP0.5:0.95提高了2.4%,验证了渐进式特征融合结构在解决图像中特征冲突方面的有效性。在AFPN的基础上,AFPNs又将更多的浅层特征融合,使得mAP0.5:0.95再次提升了0.6%,推理速度仅下降2.12帧/s。图13也直观地展现了RCA-YOLOv8网络在mAP0.5和mAP0.5:0.95上取得的优秀成绩。最终,本文的RCA-YOLOv8的mAP0.5和mAP0.5:0.95分别为91.9%和77.5%,参数量为20.47×106、推理速度为60.88帧/s。
最后,从图14中可以看出,虽然RC-YOLOv8+ AFPN网络可以识别到防振锤小目标,但是对于密集的小目标,往往在两个防振锤区域只出现了一个检测框。而本文构建的AFPNs结构,对密集目标仍具有良好的识别性能,可以将其全部检测出,但是由于小目标自身特征量远远小于大目标的特征量,在定位框的精准度方面与大目标的定位框仍有差距。在图14中可以看出,密集小目标区域的检测框相对包含了较多的背景,未来将针对该不足继续开展研究,缩小网络检测小目标与较大目标的性能差距。
综上所述,本文提出的RCA-YOLOv8网络具有更加准确、快速的检测性能,能够满足防振锤缺陷实时检测任务的需求。
本文设计的防振锤智能缺陷检测系统实物如图15所示。

图15 防振锤智能缺陷检测系统实物
Fig.15 Physical diagram of intelligent defect detection system for damper
将RCA-YOLOv8网络嵌入地面站软件平台,并在110 kV输电线路上进行现场测试验证。测试使用的无人机云台摄像机录制帧率为30帧/s。图16a、图16b为现场巡检案例中地面站软件平台界面图。

图16 RCA-YOLOv8网络现场测试案例
Fig.16 RCA-YOLOv8 network field test case
案例1和案例2中,地面站软件平台通过嵌入的RCA-YOLOv8网络分别识别到4处Damage类缺陷和3个正常防振锤,且识别到的防振锤目标均为小目标,置信度在92%以上。
案例1中RTSP传输速率稳定在30帧/s,地面站软件平台显示的帧率也为30帧/s。当由于网络问题导致RTSP传输速率降低时,当前秒内传输帧数小于30,地面站软件平台将当前秒的全部检测完成后,会继续按帧序处理视频流,因此案例2中出现FPS大于30帧/s的情况。
由以上两个案例可以看出,本文提出的RCA-YOLOv8网络可以实现防振锤实时缺陷检测。
针对现阶段输电线路无人机巡检防振锤缺陷成本高、实时性差的问题,本文提出了满足实时性缺陷检测的RCA-YOLOv8网络,并设计了基于无人机与深度学习的防振锤缺陷检测系统。该网络通过多尺度卷积注意力机制、结构重参数化和渐进式特征融合结构提取整合防振锤的特征,进而快速准确地检测到图像中不同尺寸的防振锤。本文通过对比实验与消融实验证明了该方法的有效性。通过输电线路实际测试分析,可以得出以下结论:
1)多尺度卷积注意力机制Conv-A以非常小的计算成本使网络关注图像中的防振锤区域,忽略背景区域,从而提升网络的检测精度。因此,Conv-A非常适用于提取具有多尺度特点的防振锤特征。
2)相比单分支结构,多分支结构能帮助网络提取更多的特征,但推理速度却不如单分支结构。通过结构重参数化方式,可以在网络训练时使用多分支结构,推理时转换为单分支结构,并且保持检测性能不变,对网络平衡检测精度与速度做出显著的贡献。
3)通过改进渐进式特征融合结构,使更多的浅层特征被利用,同时解决了图像中防振锤大、中、小目标的特征冲突问题,使得网络具备了检测小目标的能力。实验结果表明,RCA-YOLOv8网络具有优秀的防振锤缺陷检测能力,防振锤的检测精度mAP0.5达到了91.9%,TITAN XP平台下的检测速度达60.88帧/s。在现场测试中表现优异,可以应用于输电线路防振锤缺陷的实时检测中。
本文将现场应用与算法研究相结合,共同提升了输电线路巡检工作中防振锤缺陷检测的效率。现阶段本文方法仅局限于对防振锤本体及缺损、变形、倒置结构缺陷的实时检测,未来将持续改进和优化检测网络,增加防振锤的锈蚀、移位等缺陷的检测研究,进一步为实现无人机智能化巡检提供参考。
参考文献
[1] 赵拥华, 张鹏, 段意, 等. FD型防振锤的动力特性研究[J]. 电力科学与工程, 2021, 37(5): 73-78. Zhao Yonghua, Zhang Peng, Duan Yi, et al. Research on dynamic characteristics of FD anti-vibration hammer[J]. Electric Power Science and Engineering, 2021, 37(5): 73-78.
[2] 田毅, 伍逸群, 张烨, 等. 基于融合色差和神经网络的防震锤故障识别[J]. 计算机技术与发展, 2020, 30(8): 103-108. Tian Yi, Wu Yiqun, Zhang Ye, et al. Fault identification of damper defect based on fused chromatic aberration and neural network[J]. Computer Technology and Development, 2020, 30(8): 103-108.
[3] Huang Xinbo, Zhang Xiaoling, Zhang Ye, et al. A method of identifying rust status of dampers based on image processing[J]. IEEE Transactions on Instru-mentation and Measurement, 2020, 69(8): 5407-5417.
[4] 隋宇, 宁平凡, 牛萍娟, 等. 面向架空输电线路的挂载无人机电力巡检技术研究综述[J]. 电网技术, 2021, 45(9): 3636-3648. Sui Yu, Ning Pingfan, Niu Pingjuan, et al. Review on mounted UAV for transmission line inspection[J]. Power System Technology, 2021, 45(9): 3636-3648.
[5] 刘志颖, 缪希仁, 陈静, 等. 电力架空线路巡检可见光图像智能处理研究综述[J]. 电网技术, 2020, 44(3): 1057-1069. Liu Zhiying, Miao Xiren, Chen Jing, et al. Review of visible image intelligent processing for transmission line inspection[J]. Power System Technology, 2020, 44(3): 1057-1069.
[6] Liu Wei, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//14th European Conference on Computer Vision – ECCV 2016, Amsterdam, the Netherlands, 2016: 21-37.
[7] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 779-788.
[8] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017: 7263-7271.
[9] Redmon J, Farhadi A. YOLOv3: an incremental improvement[J/OL]. arXiv, 2018: 1804.02767. http:// doi.org/10.48550/arxiv.1804.02767.
[10] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[J/OL]. arXiv, 2020: 2004.10934. http://doi.org/10.48550/ arXiv. 2004.10934.
[11] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 2023: 7464-7475.
[12] Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[13] Cai Zhaowei, Vasconcelos N. Cascade R-CNN: delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, 2018: 6154-6162.
[14] 赵洪山, 孙京杰, 彭轶灏, 等. 基于多尺度窗口和区域注意力残差网络的无线电力终端身份识别方法[J]. 电工技术学报, 2023, 38(1): 107-116. Zhao Hongshan, Sun Jingjie, Peng Yihao, et al. Wireless power terminal identification method based on multiscale windowed deep residual network[J]. Transactions of China Electrotechnical Society, 2023, 38(1): 107-116.
[15] Hao Yanpeng, Liang Wei, Yang Lin, et al. Methods of image recognition of overhead power line insulators and ice types based on deep weakly-supervised and transfer learning[J]. IET Generation, Transmission & Distribution, 2022, 16(11): 2140-2153.
[16] 张焕龙, 齐企业, 张杰, 等. 基于改进YOLOv5的输电线路鸟巢检测方法研究[J]. 电力系统保护与控制, 2023, 51(2): 151-159. Zhang Huanlong, Qi Qiye, Zhang Jie, et al. Bird nest detection method for transmission lines based on improved YOLOv5[J]. Power System Protection and Control, 2023, 51(2): 151-159.
[17] 宋立业, 刘帅, 王凯, 等. 基于改进EfficientDet的电网元件及缺陷识别方法[J]. 电工技术学报, 2022, 37(9): 2241-2251. Song Liye, Liu Shuai, Wang Kai, et al. Identification method of power grid components and defects based on improved EfficientDet[J]. Transactions of China Electrotechnical Society, 2022, 37(9): 2241-2251.
[18] 苟军年, 杜愫愫, 刘力. 基于改进掩膜区域卷积神经网络的输电线路绝缘子自爆检测[J]. 电工技术学报, 2023, 38(1): 47-59. Gou Junnian, Du Susu, Liu Li. Transmission line insulator self-explosion detection based on improved mask region-convolutional neural network[J]. Tran-sactions of China Electrotechnical Society, 2023, 38(1): 47-59.
[19] 李斌, 屈璐瑶, 朱新山, 等. 基于多尺度特征融合的绝缘子缺陷检测[J]. 电工技术学报, 2023, 38(1): 60-70. Li Bin, Qu Luyao, Zhu Xinshan, et al. Insulator defect detection based on multi-scale feature fusion[J]. Transactions of China Electrotechnical Society, 2023, 38(1): 60-70.
[20] 杨帆, 王梦珺, 谭天, 等. 基于目标像素宽度识别的电力设备红外成像单目测距改进算法[J]. 电工技术学报, 2023, 38(8): 2244-2254. Yang Fan, Wang Mengjun, Tan Tian, et al. An improved monocular ranging method for infrared image of power equipment based on the pixel width recognition of objects[J]. Transactions of China Electrotechnical Society, 2023, 38(8): 2244-2254.
[21] 左国玉, 马蕾, 徐长福, 等. 基于跨连接卷积神经网络的绝缘子检测方法[J]. 电力系统自动化, 2019, 43(4): 101-106. Zuo Guoyu, Ma Lei, Xu Changfu, et al. Insulator detection method based on cross-connected convolutional neural network[J]. Automation of Electric Power Systems, 2019, 43(4): 101-106.
[22] 汤璐, 王淑青, 王年涛, 等. 基于改进YOLOX网络的雾天绝缘子缺陷检测[J]. 高压电器, 2024, 60(3): 223-228. Tang Lu, Wang Shuqing, Wang Niantao, et al. Insulator defect detection in foggy condition based on improved YOLOX network[J]. High Voltage Apparatus, 2024, 60(3): 223-228.
[23] Bao Wenxia, Ren Yangxun, Wang Nian, et al. Detection of abnormal vibration dampers on transmission lines in UAV remote sensing images with PMA-YOLO[J]. Remote Sensing, 2021, 13(20): 4134.
[24] 赵振兵, 李延旭, 甄珍, 等. 结合KL散度和形状约束的Faster R-CNN典型金具检测方法[J]. 高电压技术, 2020, 46(9): 3018-3026. Zhao Zhenbing, Li Yanxu, Zhen Zhen, et al. Typical fittings detection method with faster R-CNN combining KL divergence and shape constraints[J]. High Voltage Engineering, 2020, 46(9): 3018-3026.
[25] Liang Huagang, Zuo Chao, Wei Wangmin. Detection and evaluation method of transmission line defects based on deep learning[J]. IEEE Access, 2020, 8: 38448-38458.
[26] Ding Xiaohan, Zhang Xiangyu, Ma Ningning, et al. RepVGG: making VGG-style ConvNets great again[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 13733-13742.
[27] Yang Guoyu, Lei Jie, Zhu Zhikuan, et al. AFPN: asymptotic feature pyramid network for object detection[J/OL]. arXiv, 2023: 2306.15988. http://doi. org/10.48550/arXiv.2306.15988.
[28] Liu Songtao, Huang Di, Wang Yunhong. Learning spatial fusion for single-shot object detection[J/OL]. arXiv, 2019: 1911.09516. http://doi.org/10.48550/arXiv.1911.09516.
[29] 王建, 吴昊, 张博, 等. 不平衡样本下基于迁移学习-AlexNet的输电线路故障辨识方法[J]. 电力系统自动化, 2022, 46(22): 182-191. Wang Jian, Wu Hao, Zhang Bo, et al. Fault identification method for transmission line based on transfer learning-AlexNet with imbalanced samples[J]. Automation of Electric Power Systems, 2022, 46(22): 182-191.
[30] Tan Mingxing, Pang Ruoming, Le Q V. EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020: 10781-10790.
[31] Zhang Xiaosong, Wan Fang, Liu Chang, et al. Learning to match anchors for visual object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022: 44(6): 3096-3109.
[32] Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017: 618-626.
[33] Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, 2018: 7132-7141.
[34] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//15th European Conference on Computer Vision – ECCV 2018, Munich, Germany, 2018: 3-19.
[35] Hou Qibin, Zhou Daquan, Feng Jiashi. Coordinate attention for efficient mobile network design[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 13713-13722.
Abstract The presence of defective dampers in power transmission lines poses a significant risk to the secure and stable operation of the electrical grid. Advancing the intelligent development of damper inspections in transmission lines, a fast and accurate defect detection method holds paramount importance. Addressing the issue of insufficient damper defect recognition due to scarce defect samples, complex backgrounds, and varying regional dimensions, a novel damper defect detection network (RCA-YOLOv8) based on a multi-scale convolution attention mechanism was proposed.
Firstly, the diverse sizes of dampers in images are analyzed and a multi-scale convolution attention mechanism composed of three sets of bar-shaped convolutions is constructed to precisely capture features of different-sized dampers. Subsequently, a structural reparameterization method is utilized to convert the multi-branch structure in the network into a single-branch structure, enabling to maintain consistent inference speed with the single-branch structure while benefiting from the detection performance improvement brought by the multi-branch structure. In addition, based on the YOLOv8 feature extraction structure, a Conv Block structure containing Conv-A structure and structural reparameterization method was constructed to propose multi-scale features of dampers. Moreover, more shallow network features are integrated by using the AFPNs structure, resolving feature conflicts between large, medium, and small targets in the images, thereby enabling accurate detection of small damper targets and further enhancing detection performance. In this model, Conv-A is more able to focus on the dampers area in the image, reducing background interference, and structural reparameterization greatly reduces computational costs. AFPNs solve the problem of feature conflicts between large and small dampers in the image, thus achieving a low computational cost and high detection accuracy model.
For model experimentation, a dataset of damper defects in power transmission lines within substation scenes using image processing techniques is generated. To enhance dataset diversity and save annotation time, employ automatic data augmentation operations, including scale transformations, such as y-axis flipping, adding Gaussian noise, adding salt and pepper noise, adjusting brightness and non-scale transformations, such as size enlargement and reduction, along with automatically generated annotation files. Based on the dataset, the RCA-YOLOv8 network achieves an average precisionmAP0.5 of 91.9% and mAP0.5:0.95 of 77.5%. Compared with other advanced one-stage and two-stage object detection networks, RCA-YOLOv8 has better damper defect detection performance. The mAP values of RCA-YOLOv8 network increased by 5.4% and 4.2% respectively compared to the basic network YOLOv8, with an inference speed of 60.88 frames per second under TITAN XP platform. It can be concluded that the proposed RCA-YOLOv8 network can rapidly and effectively detect dampers and their defects in power transmission lines.
The following conclusions can be drawn from the simulation analysis: (1) The network based on the multi-scale convolution attention mechanism can focus on crucial regions in the images, suppressing background regions' feature representations to obtain more relevant information. (2) Structural reparameterization successfully converts the multi-branch structure into a single-branch structure without any loss, striking a balance between detection accuracy and speed. (3) AFPNs with progressive feature fusion from different levels enable the network to achieve more precise detection of small damper targets.
keywords: Damper, deep learning, attention mechanism, real-time defect detection
DOI: 10.19595/j.cnki.1000-6753.tces.231155
中图分类号:TM755
国家自然科学基金(52307182)、西安市科技计划(22GXFW0038)、陕西省科学技术协会青年人才托举计划(20220133)、金属成形技术与重型装备全国重点实验室开放课题(S2208100.W03)和西安工程大学博士科研启动基金(BS202125)资助项目。
收稿日期 2023-07-19
改稿日期 2023-08-10
张 烨 女,1988年生,副教授,硕士生导师,研究方向为人工智能技术在输电线路中的应用。E-mail:zhangye@xpu.edu.cn
黄新波 男,1975年生,教授,博士生导师,研究方向为输电线路在线监测与故障诊断。E-mail:huangxb1975@163.com(通信作者)
(编辑 李 冰)