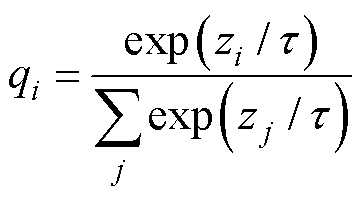 (1)
(1)
摘要 当前,基于深度学习的局部放电识别方法缺乏在模型训练后继续学习新增多样性数据样本的方案。为此,该文提出一种结合知识蒸馏和图神经网络(GNN)的局部放电增量识别方法:通过回放少量局部放电旧数据,实现原始模型与新模型间的先验知识共享,以避免知识遗忘;利用先验知识辅助新模型学习局部放电新数据、提升泛化能力;为适应新增数据规模的不确定性,新模型采用与GNN相结合的方式构建,可以协同学习放电特征以及各类放电间丰富的关联信息,弥补有限样本的信息不足。实验结果表明,该方法能够渐进地学习陆续新增的局部放电数据,且不受新数据规模的制约,增量学习后模型对新数据的识别率提升近18%;模型更新所需的计算资源更少,相较于重新训练,显存和内存占用分别下降67.9%和72.7%;具有较好的可推广性,对基于AlexNet、ResNet等网络的局部放电识别模型均能够实现增量式更新。
关键词:局部放电 深度学习 增量学习 知识蒸馏 图神经网络
局部放电(简称局放)是电力变压器等高压输变电设备绝缘缺陷的先兆和表现,准确地识别放电类型对于掌握设备绝缘状况具有重要意义[1]。传统机器学习方法虽然极大地推动了局放模式识别的发展[2-3],然而这类识别方法的输入特征量依赖人为手工设计,存在一定的主观性,还可能遗漏某些关键特征。
深度学习作为一种新型机器学习方法,能够自适应地挖掘各类型样本的可分性表征,已成为当前局放诊断研究的主流[4]。Duan Lian等[5]直接将局放脉冲的一维时域序列作为稀疏自编码器(Sparse Autoencoder, SAE)的输入,实现了“端到端”的特征提取与类型识别;张重远等[6]和SongHui等[7]采用卷积神经网络(Convolutional Neural Network, CNN)分别对放电脉冲时频谱和脉冲序列相位图谱进行识别,识别能力优于典型的传统机器学习方法;也有部分学者利用AlexNet[8]、ResNet[9]和MobileNet[10]等大规模CNN架构捕获更深层次的局放特征,相较于浅层CNN,识别率和泛化能力进一步得到提高。
上述基于深度网络的局放识别模型具有三个显著特点:①以海量、多样化的训练数据为基础;②假设训练与测试数据满足独立同分布;③一次性学习当前所有数据后,学习过程终止。然而,随着变压器运行年限的增加以及传感器的增设,更加多样性的局放数据逐渐出现,在数据分布上表现出与原有数据的差异,从而导致原始模型失准。传统做法是将新数据和历史数据混合后重新训练,但重复学习大规模历史数据带来了极大的计算资源浪费。而且,随着新一代电力智能终端在电力设备上的应用,诊断模型逐渐趋于边缘终端侧部署,而资源受限的边缘终端难以支持模型通过重新训练的方式实现自我更新维护。因此,通过模型修正逐步增强面向新数据的泛化能力,成为一种更为高效的解决手段[11],但在局放诊断领域中目前未见相关报道。
增量学习是渐进式修正模型的有效方法,无需重新训练,可以在记忆旧知识的同时(无需完整地保留旧数据)持续学习新增数据,以适应数据分布随时间的变化[12]。知识蒸馏(Knowledge Distillation, KD)是当前增量学习研究的热点,主要由原始模型(也称教师网络)和新模型(也称学生网络)组成。在增量任务中,原始模型为采用大规模旧数据训练稳定的神经网络;新模型一般与前者结构一致,致力于高效地转化和利用原始模型已学的知识来完成新知识的学习,并尽可能地避免遗忘前期所学。Li Zhizhong等[13]提出了无遗忘学习(Learning without Forgetting, LwF),无需保留旧数据,通过在微调学习新数据的同时约束新模型和原始模型的预测相接近,克服了对历史知识的灾难性遗忘;S. A. Rebuffi等[14]和F. M. Castro等[15]采用回放部分代表性旧数据的方式向新模型传递先验知识,并利用先验知识指导新数据的学习,可以实现“温故而知新”。以上方法虽然在充足的新数据下较为有效,但并不适合于小样本的增量学习[16],而且现场的新增局放数据很可能数量不足且类别不平衡,所以难以直接应用于局放识别模型的增量更新。
小样本任务的难点在于样本有限、可利用的信息不足,此时样本间的关联关系变得十分重要。新兴的图神经网络(Graph Neural Network, GNN)是一种有效的关系学习网络,在小样本任务中得到了广泛关注[17-18]。GNN的输入为多个节点及其连接构成的图数据,节点可以是随机组合的多个样本,使得图数据具有多样性的特点[17]。GNN能够融合样本特征和样本间的关联关系进而挖掘潜在的相关信息,相较传统网络可以弥补有限样本的信息不足。
综上所述,本文提出了一种结合知识蒸馏和GNN的局部放电增量识别方法。首先,采用旧局放数据集训练一神经网络作为原始模型;然后,根据知识蒸馏原理,利用少量代表性旧数据在增量更新中迁移先验知识,并进一步指导新数据的学习;最后,考虑到新增局放数量少、类别不平衡的特点,采用GNN进行改进。结果表明,该方法无需重新训练,能够高效地学习持续新增的多样性局放数据;在不同规模的新数据集下均具有较好的效果;计算资源占用低,有利于实现边缘智能终端上模型的部署与维护。
知识蒸馏本质上是一种高效的知识迁移方法,能够通过最小化新模型与原始模型的软标签输出以迁移前期所学的先验知识[19]。通常,神经网络的输出是采用0和1标注的硬标签,忽略了除正确类别下的其他相关信息,而软标签的标注数值在0~1之间,既可以表明类别属性,又蕴含了不同类别间的隐含信息[20]。软标签的标注数值计算式为
(1)
式中,zi为网络模型的logit输出;τ为参数,当τ =1时,式(1)与softmax函数等价,τ越大,qi分布越平缓。
基于知识蒸馏的增量学习原理如图1所示,通过对少部分代表性旧数据的重复访问来共享和高效利用先验知识,辅助实现面向新增数据的模型自我更新,而无需重复学习全部旧数据。
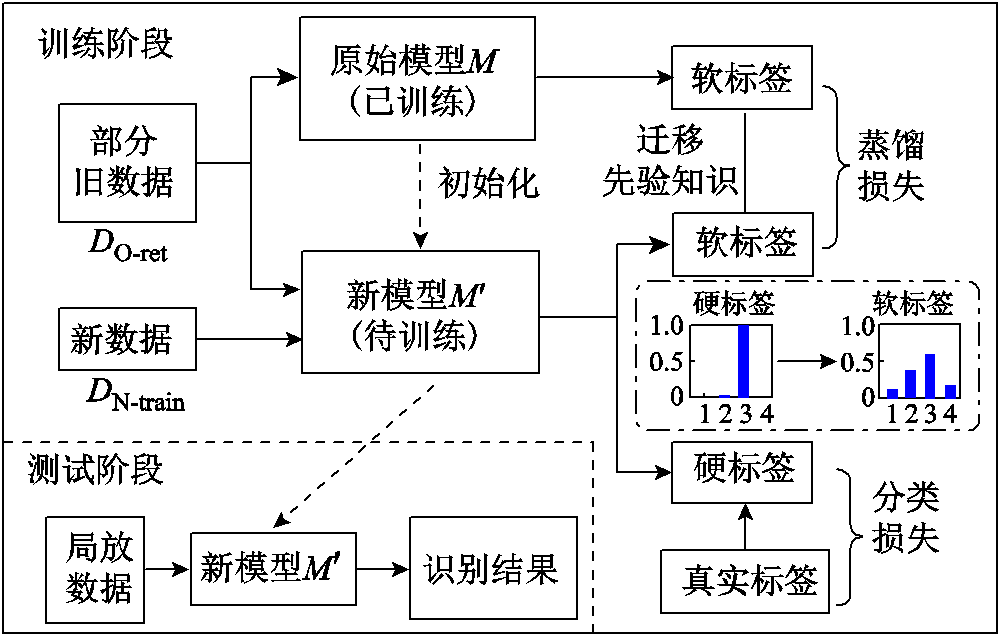
图1 基于知识蒸馏的增量学习原理
Fig.1 Schematic diagram of incremental learning framework based on knowledge distillation
原始模型M是基于旧数据集DO-train训练稳定的深度网络,新模型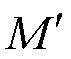 一般与M的结构一致,并借助M进行初始化。在训练阶段,仅进行参数更新,首先通过约束M和对代表性旧数据DO-ret的软标签输出相接近(即蒸馏损失LDistill)来迁移先验知识,以保护前期所学;在先验知识的指导下,致力于缩小新数据DN-train和DO-ret的硬标签输出与真实标签之间的差异(即分类损失LClass)来修正模型参数,以适应新增数据并进一步巩固前期所学,而无需重新训练模型,计算效率更高、计算资源占用更小;最终,替代M用于接下来的测试。
一般与M的结构一致,并借助M进行初始化。在训练阶段,仅进行参数更新,首先通过约束M和对代表性旧数据DO-ret的软标签输出相接近(即蒸馏损失LDistill)来迁移先验知识,以保护前期所学;在先验知识的指导下,致力于缩小新数据DN-train和DO-ret的硬标签输出与真实标签之间的差异(即分类损失LClass)来修正模型参数,以适应新增数据并进一步巩固前期所学,而无需重新训练模型,计算效率更高、计算资源占用更小;最终,替代M用于接下来的测试。
依据上述原理,知识蒸馏的总损失函数可表述为LDistill和LClass的加权,即
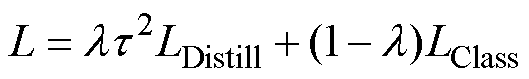 (2)
(2)
式中,LDistill和LClass分别采用Kullback-Leibler(KL)散度和交叉熵函数进行计算;λ为平衡参数,λ∈(0, 1),控制着新模型在新、旧数据上的性能平衡;LDistill乘以τ2使得梯度下降过程中两部分损失的相对贡献不随τ而改变,本文中取τ=4。
图数据是由多个节点及其连接边组成的不规则数据结构,直接定义了图中数据间的关系[21]。假设F个节点的图数据为V∈RF×d(d为节点特征维度),全图中各节点间的连接关系采用邻接矩阵A∈RF×F表示。通常,若节点相邻,则Ai,j=1;不相邻则为0。但如此计算的邻接矩阵仅能表达节点间的相邻性,无法表征关联关系的强弱。受消息传递机制的启发,S. Kearnes等[22]提出了一种神经网络化的自适应邻接矩阵计算方法,认为节点i、j之间的Ai,j取决于两节点的当前状态vi(k)和vj(k),即
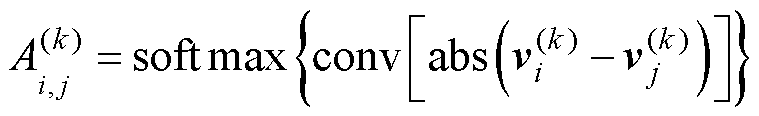 (3)
(3)
式中,abs(·)为绝对值函数;conv(·)表示卷积层;经softmax函数归一化后得到Ai,j∈[0, 1]。
图神经网络(GNN)是针对图数据而设计的新型网络架构,其原理如图2所示。GNN的核心思想是,根据邻接矩阵A学习一特征映射实现邻域节点聚合和节点特征更新[23]。设V(k)为当前的图数据特征,任意节点i的状态更新均是当前节点特征vi(k)及其邻居节点共同作用的结果,即
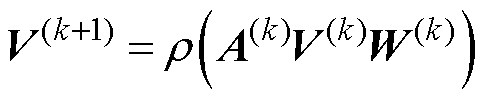 (4)
(4)
式中,A(k)V(k)表示各节点间的信息交互;W(k)为可学习的权重,用于加强网络拟合能力;ρ(·)为激活函数。由于GNN存在过平滑问题[23],一般以1~2层为宜。通过多轮的状态更新,GNN从图数据中发掘数据间潜在的关联信息,表现出优异的关联性建模能力。
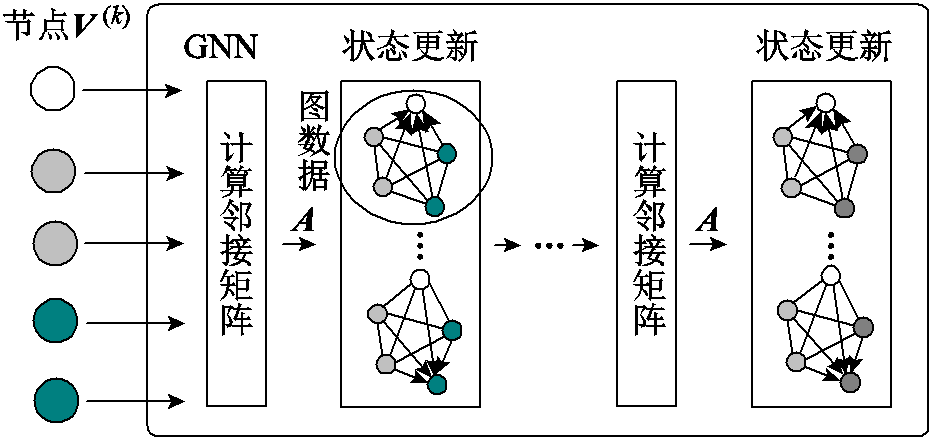
图2 GNN原理
Fig.2 Schematic diagram of GNN
在少样本场景中,特征信息的匮乏使得样本间的关联信息对于提升网络性能至关重要。V. Garcia等[17]将GNN引入少样本任务中,每个样本作为图数据中的一个节点,节点随机组合的多样性可以增加图数据的多样性,有利于扩充和平衡少样本任务,且加之对特征信息和关联信息的协同挖掘,更进一步弥补了少样本场景的信息不足。目前,GNN已成为解决少样本问题的有效手段之一[18]。
本文将知识蒸馏思想引入局部放电模式识别领域,提出了一种持续学习多样性新数据的局部放电增量识别方法。同时,考虑到电力变压器的结构复杂性和放电缺陷的随机性,一段时间内积累的新局放数据很可能数量不足且类别不平衡,故采用GNN对知识蒸馏框架进行改进,以改善少样本场景下的增量识别性能。结合知识蒸馏和GNN的局部放电增量识别方法流程如图3所示,主要步骤如下:
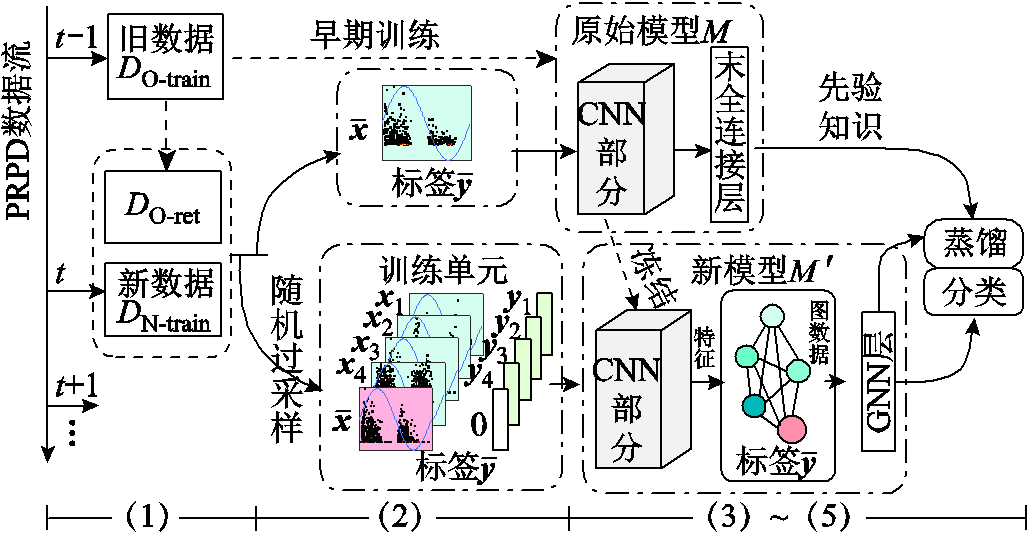
图3 结合知识蒸馏和GNN的局部放电增量识别方法
Fig.3 Incremental partial discharge recognition method combining knowledge distillation with GNN
(1)从旧训练集DO-train随机保留部分数据构建代表性旧数据集DO-ret,并对t时段内新增的局放数据的放电相位分布(Phase Resolved Partial Discharge, PRPD)图谱进行预处理形成新数据集DN-train。
(2)从DO-ret中抽取不同类型的PRPD样本x1~x4,并采样待测样本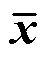 ,构成一个训练单元(标签为
,构成一个训练单元(标签为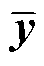 );假设模型的批量大小为K,其中K/2的样本源自DO-ret,另K/2的待测样本从DN-train中随机过采样,使得每训练批次中的待测样本类别平衡。
);假设模型的批量大小为K,其中K/2的样本源自DO-ret,另K/2的待测样本从DN-train中随机过采样,使得每训练批次中的待测样本类别平衡。
(3)将前期采用DO-train训练的局放识别模型作为原始模型M,利用模型M构建新模型,并冻结CNN部分,继而采用随机初始化的GNN层替代末全连接层作为的输出层以保持探索能力。
(4)利用模型M对取自DO-ret的进行知识蒸馏,将输出的软标签作为先验知识辅助模型的增量训练。
(5)增量训练中,模型的CNN部分自主提取各局放样本的PRPD特征,并与对应属性信息的one-hot编码(的one-hot编码采用零向量0)共同构成节点特征;各节点两两连接形成图数据;最后利用GNN层挖掘新、旧数据的域间共性和域内差异,输出待测样本的诊断结果。
PRPD图谱表征了局部放电数据按照相位统计的放电脉冲幅值和脉冲个数的分布特征,蕴含了绝缘缺陷的内在信息,在局部放电检测中得到了广泛的应用。为获得深度网络训练所需的PRPD数据集,本文以油浸式变压器为研究对象,针对常见的油中尖端放电、油中沿面放电、油中气隙放电和油中悬浮放电等缺陷,设计了如图4所示的A和B两套人工放电模型,图中数值单位均为mm。为了产生两组具有数据分布差异的数据集,两套放电模型主要存在以下区别:①A组的尖端放电模型模拟油纸绝缘附近的尖端放电,B组则仅考虑尖端在油中的放电行为;②两组沿面放电均采用球-板电极模拟,但两球电极直径分别为24 mm和2 mm;③A组中的气隙模拟绝缘纸包封气泡的情况,B组模拟油中气泡放电的场景;④两组悬浮放电的配件存在差异,分别为铜块和垫片。
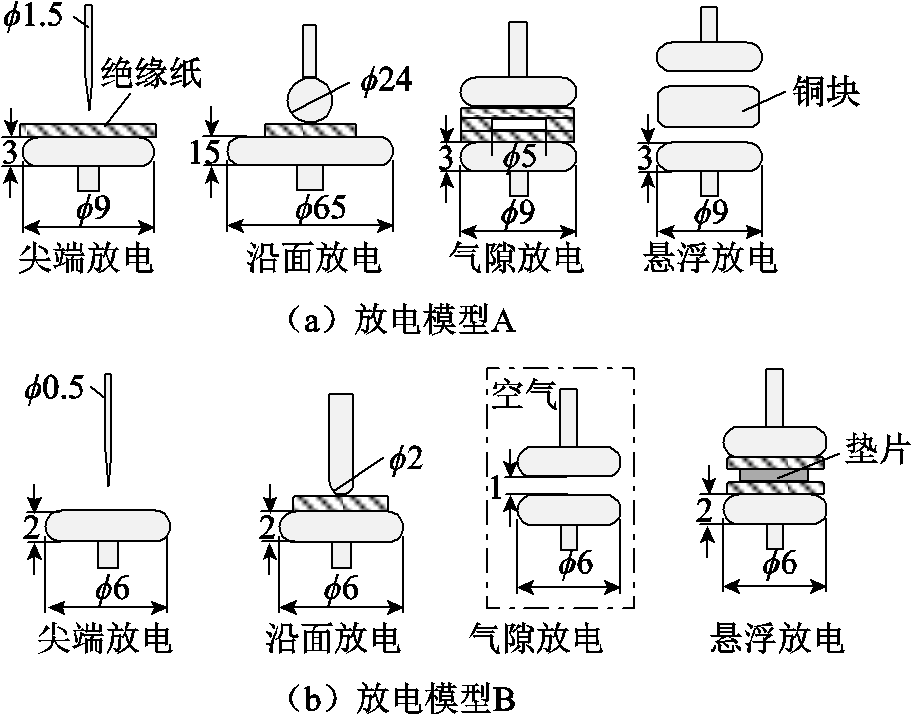
图4 人工放电模型
Fig.4 Artificial discharge model
实验使用高频电流法从放电支路的接地端捕获局部放电信号,实验原理如图5所示。实验时,示波器的采样率为20 MS/s,采样带宽为1~10 MHz。在8~25 kV阶升电压下,分别对两套放电模型下的四种典型缺陷进行测试,每采集2 s的局放信号(即100个工频周期)形成一个PRPD图谱。为了方便神经网络直接处理PRPD图谱,将其压缩为128×128的二维矩阵形式,即放电相位0°~360°和放电量0~qmax分别被离散为128个等区间,矩阵中的值为相位和幅值处于对应区间的放电次数,并按照“最大-最小值”进行线性归一化处理。各放电缺陷的PRPD图谱如图6所示,不同类型的PRPD图谱在相位分布、脉冲分散度、放电次数等方面存在较明显的差异,有利于实现放电类型的模式识别;从两组放电模型采集的同一类型局放既存在共性,又兼具差异,表现出一定的多样性。因此,两组数据可分别模拟早期采集的局放旧数据和新增的多样性数据。

图5 局部放电实验原理
Fig.5 Schematic diagram of PD test platforms
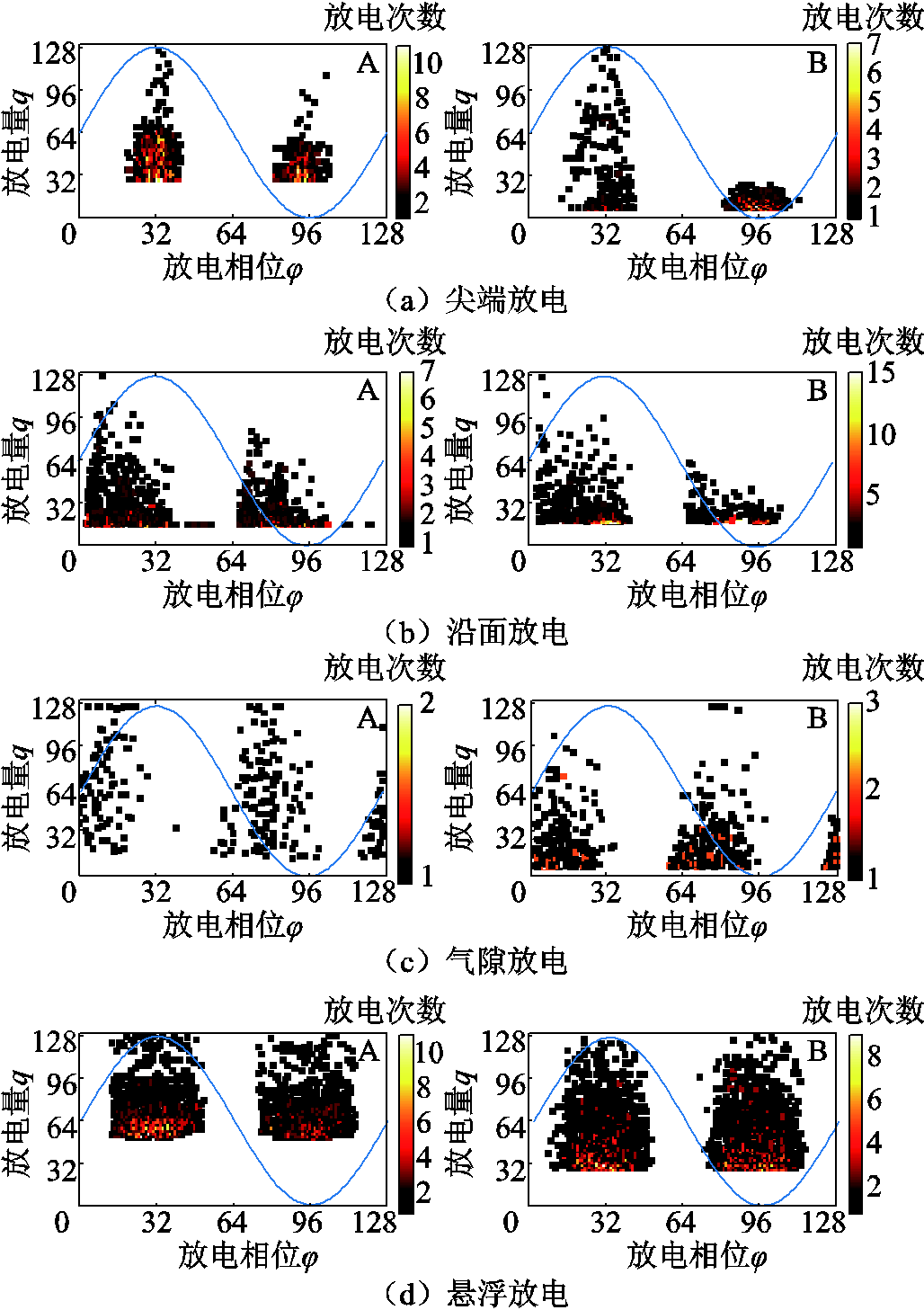
图6 局部放电信号的时频谱图
Fig.6 Time-frequency spectra of PD signals
最终,放电模型A、B分别形成2 400个(600个/类)和800个(200个/类)PRPD图谱,依次从两组数据集中随机、分层地抽取400个作为各自的测试集,其余作为对应的训练集(DO-train和DN-train)。其中,DO-train用于训练原始的局部放电识别模型,DN-train是增量学习阶段需要学习的新数据。此外,从旧训练集DO-train中随机保留20%的旧样本记为DO-ret,用作增量学习中的辅助信息,避免学习新局放知识的同时产生灾难性遗忘。
原始模型M选择局部放电研究中常见的AlexNet构建(共8个网络层),新模型的CNN部分与M的前7层一致,且利用M进行初始化并冻结权重参数,之后添加GNN层进行关联性建模,具体结构与参数设置见表1。GNN层采用5个1×1卷积自适应地计算邻接矩阵A,即式(3);“聚合+全连接层”表示对节点状态的更新,即式(4);由于局放图数据的节点少、结构简单,经实验确定,仅一个GNN层即可获得优异的增量性能。同时,为了提高训练的稳定性,在各卷积层后添加批量归一化(Batch Normalization, BN)层使输出均衡一致。
表1 网络结构与参数设置
Tab.1 Network structure and parameter setting

模型类型层数通道卷积核(步长)激活函数 原始模型卷积层+BN层+最大值池化5643×3(2)ReLU 全连接层2256, 64—ReLU 全连接层14—Softmax GNN层卷积层+BN层4641×1(1)LeakyReLU 卷积层111×1(1)Softmax 聚合+全连接层14—Softmax
网络模型基于Pytorch框架实现,计算硬件平台为NVIDIA GTX1650 GPU(4G)和8G RAM。实验中,M和的优化求解器均为Adam,两者的学习率分别为1×10-3和1×10-4,矩估计因子β1、β2为0.9和0.999。每次迭代,两模型投入的样本批量大小分别为80和16,经300次迭代训练可收敛稳定。
在知识蒸馏中,如何利用新、旧训练样本是构建损失函数时需要着重考虑的问题。根据数据利用方式的不同,可将常见的损失函数分为四类:L1,无需保留旧数据,蒸馏和分类损失均仅采用新数据DN-train构建[13];L2,采用少量代表性旧数据DO-ret构建蒸馏损失,分类损失中仅考虑新数据[14];L3,蒸馏损失与L2一致,分类损失同时考虑对新、旧数据的分类要求[15];L4,两部分损失均采用新、旧数据构建。为了考察各损失函数对增量性能的影响,分别在L1~L4下进行增量训练(λ通过遍历寻优确定),各函数下的训练数据集及识别率见表2。
表2 不同损失函数下的识别率提升效果对比
Tab.2 Comparison of the improvement of recognition rate among different loss functions

损失函数训练数据集识别率(%) LDistillLClass新数据旧数据 M—DO-train80.2599.25 L1DN-trainDN-train+10.25-22.75 L2DO-retDN-train+16.00-1.50 L3DO-retDO-ret+DN-train+17.750 L4DO-ret+DN-trainDO-ret+DN-train+10.75-1.00
注:表中“+”“-”分别代表以原始模型M为参照,应用各损失函数时识别率的提升和下降。
表2率先给出了原始模型M的识别情况,在旧数据集上的测试识别率为99.25%,但受新、旧数据非独立同分布的影响,新数据上的识别率仅为80.25%。以M作为参照,采用L1增量训练的在新数据上提升了10.25%,但对旧数据降低了22.75%,即严重地遗忘了前期所学;利用L2增量训练后,对新数据的识别率提升了16.00%,且因旧数据DO-ret实现了新、旧模型间的知识共享,在旧数据上仅下降了1.50%,有效缓解了知识遗忘问题;L3展现出了最优的增量性能,对新数据的识别率提升了17.75%,且在旧数据的识别能力与M保持一致;与L3相比,L4虽然进一步地增加新数据来迁移M中的先验知识,但M对新数据预测所产生的错误经验将对增量训练产生误导,所以性能有所下降。总的来看,L3更适合增量训练局部放电识别模型。
在损失函数中,λ参数与蒸馏和分类两部分的平衡密切相关,影响着对新知识和前期所学知识的整合能力。图7展示了不同λ值下的识别率变化,随着λ的增大,通过知识蒸馏而迁移的先验知识逐渐增加,对旧数据的认知能力持续提升且基本恢复到M的水平;对于新数据,的识别率呈现先减后增的趋势,在0.2~0.4之间趋于平稳,但随着λ的进一步增大,增量训练中对分类任务的关注度降低,新增数据无法得到有效学习,故识别率逐渐下降。最终,选定λ=0.2进行之后的分析。
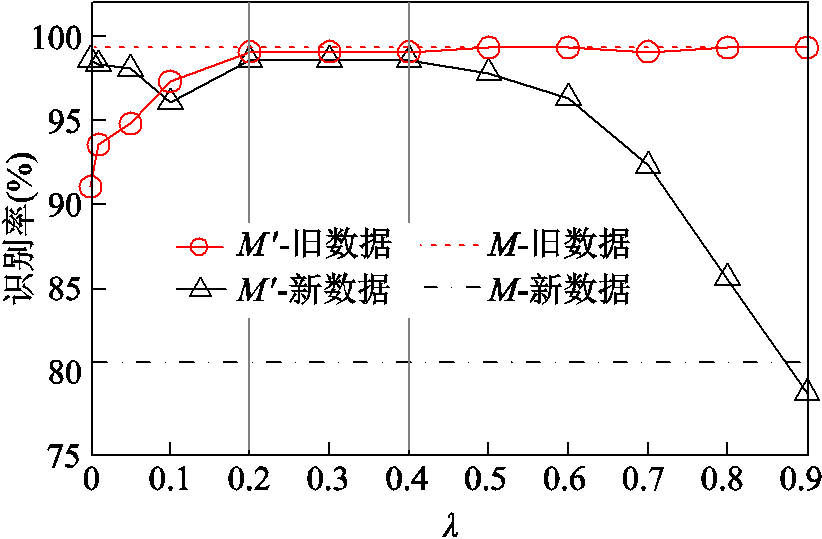
图7 不同λ参数下的增量效果对比
Fig.7 Comparison of incremental effects with different λ
为了直观地展示本文方法增量式融合新、旧局放特征的能力,首先采用t-分布式随机领域嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)算法对M和的末层特征输出进行可视化,结果如图8所示。图8a中,原始模型M能够将旧数据中同类局放的特征聚集成簇,不同类型的群簇相互分离,但由于新、旧数据间分布差异的存在,新数据的各类型特征点群交叉重叠、分类效果不佳。增量训练后(见图8b),新、旧数据集中同类放电的特征相互融合,且各自聚集成群,即本文提出的增量方法能够在特征层面缩小非同分布数据集间的概率分布差异。

图8 模型增量训练前、后的特征可视化
Fig.8 Feature visualization before and after incremental training
进一步地,在测试集上统计模型M和对各类局放信号的混淆情况。模型增量训练前、后的混淆矩阵如图9所示。从图9a和图9b可以看出,原始模型M对旧数据的识别率较高,平均可达99.25%,但对数据分布不一致的新数据呈现出严重的模式混淆,大部分沿面放电无法正确预测,识别率仅为48%,对尖端放电的识别率也仅为84%。经增量训练,如图9c和图9d所示,对新数据集的混淆情况明显改善,四类放电上均可实现96%以上的识别率。实验结果表明,该增量学习方法可以赋予局放识别模型自我更新能力,能够在不过多损失历史知识的前提下,渐进式地学习陆续出现的多样性局放数据、逐步提高泛化能力。
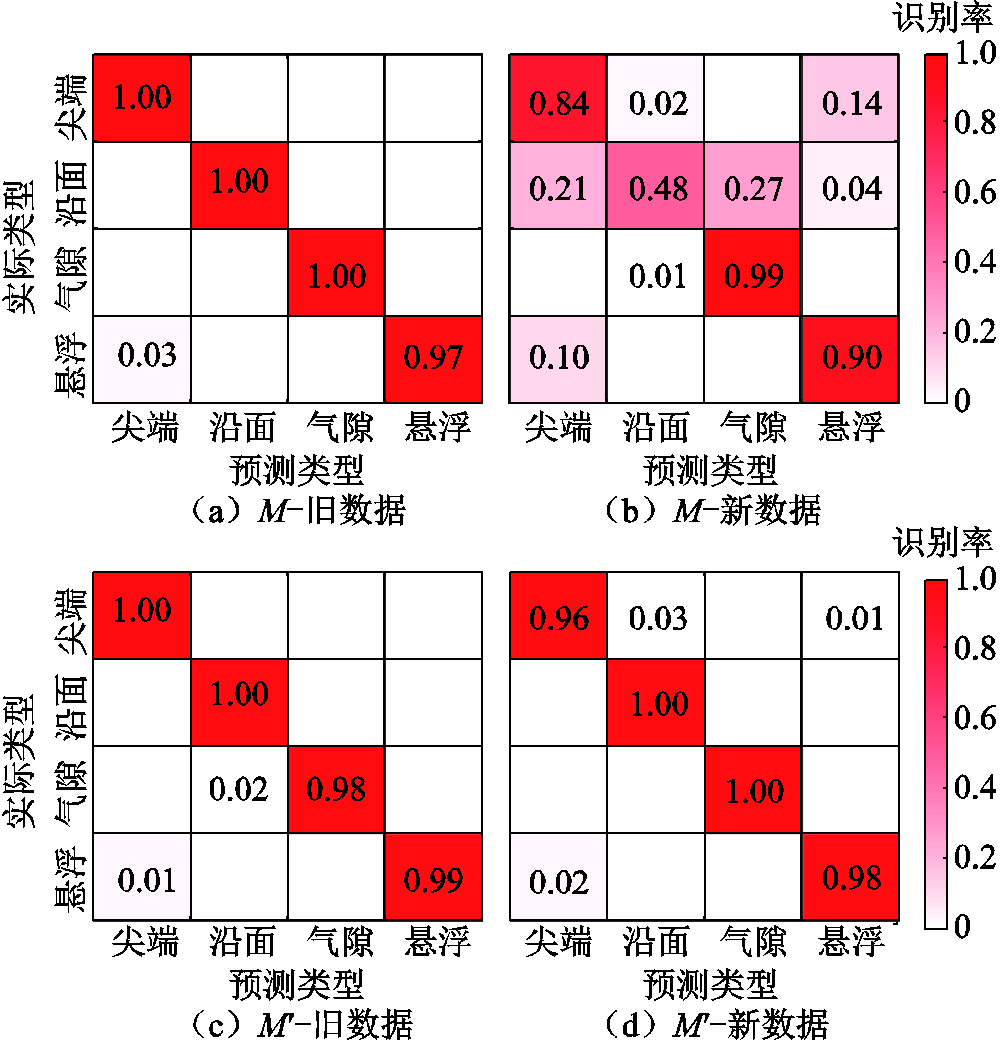
图9 模型增量训练前、后的混淆矩阵
Fig.9 Confusion matrices before and after incremental training
面对新增的局放数据,传统做法是将新数据与大规模旧数据联合后重新训练模型,称为联合训练。此外,微调、LwF[13]和常规知识蒸馏(简称常规KD)[15]等也常见于增量学习领域。微调通过较小的学习率(本处取1×10-5)调整网络参数来学习新数据;LwF指采用3.2节中L1构建的知识蒸馏法;常规KD指采用L3的知识蒸馏法,即本文方法未经GNN改进的版本。为了体现本文方法对变压器局部放电增量识别任务的优越性,本节将对各方法进行对比分析。四种对比方法均利用模型M初始化,批量大小为80,其他设置与本文方法一致。
3.5.1 少样本和类别不平衡场景
由于现场变压器不能长期带隐患运行,加之绝缘缺陷类型的随机性,新增的局放数据存在数量不足、类别不平衡的特点,因此需要评估增量方法对不同数据规模的适应性。首先,在类别平衡的情况下,分析新增数据数量对增量性能的影响。逐渐增加新训练集的样本量为40、80、200和400,对上述方法进行对比,结果如图10所示。

图10 不同新增样本数量下的增量性能
Fig.10 Incremental performance on varying new data size
图10中,在不同的新增样本数量下,微调和LwF的旧数据识别率均明显下降,即表现出对旧知识的灾难性遗忘,原因是微调过程缺乏对历史信息的约束,极易覆盖前期所学,而LwF的增量学习又高度依赖两数据集间的相似性[19],因此后文不再对二者进行对比分析;联合训练和常规KD保持了与原始模型M相似的旧数据识别能力,虽然缓解了遗忘问题,但由于传统深度网络对大规模数据的天然依赖,在新数据上,随着新增样本量的减少,二者的性能迅速下降;本文方法在常规KD的基础上增加GNN层,能够改善少样本下学习能力的不足,在新数据上的测试识别率相较常规KD分别提升了9.25%、3.5%、3.25%和2.75%。这主要是因为,本文方法将图数据作为一个训练样本,每个图数据由多个类型局放样本随机组合,能够在少样本场景下增强训练样本的多样性;进一步地,GNN自主学习各类型局放样本间的关联性以及新、旧局放数据间的相似性,三者协同地促进增量更新的进程。
接下来,考察新增数据的类别不平衡对增量性能的影响。从新训练集DN-train中随机抽取70个尖端放电、10个沿面放电、100个气隙放电和40个悬浮放电,构成类别不平衡训练集,选择图10中表现较优异的联合训练和常规KD与本文方法进行对比。训练过程中,每2次迭代进行1轮实时预测,迭代曲线如图11所示。随着训练的进行,三者的识别率逐渐趋于稳定,联合训练、常规KD和本文方法最终在新、旧数据上的平均识别率分别收敛于92.50%、92.25%和98.00%附近,本文方法的性能最佳。类别不平衡情况下的增量性能对比见表3。分析表3中详细的识别率对比可知,模型对旧数据的认知能力基本不受新增数据类别不平衡的影响,但在新数据的测试上,前两者对作为少数类的沿面放电识别率仅为60%左右,而本文方法利用随机过采样的方式构建图数据,可以保证每个训练批次中的各类图数据数量均等,对少数类放电的识别率提升至92%,缓解了绝缘缺陷随机性带来的新增局放数据的类别不平衡问题。
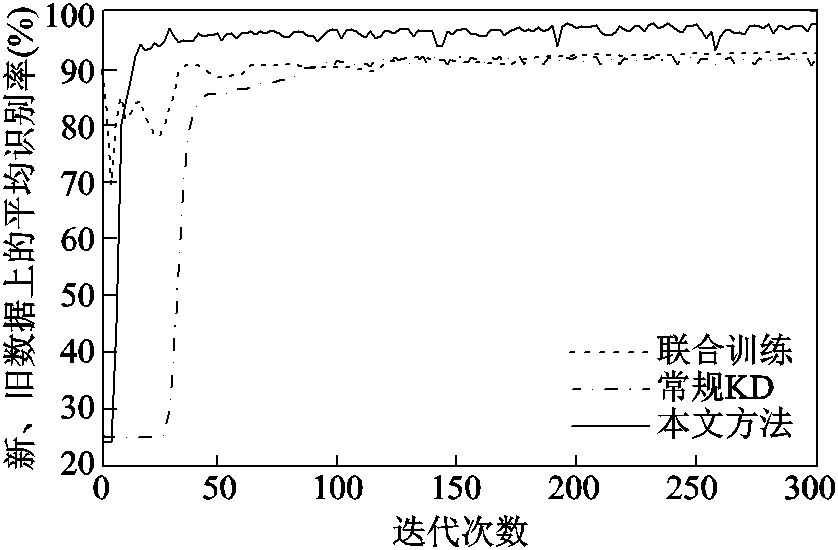
图11 不同方法的迭代曲线
Fig.11 Iteration curves of different methods
表3 类别不平衡情况下的增量性能对比
Tab.3 Incremental performance with category imbalance

方法数据识别率(%) 尖端沿面气隙悬浮平均 联合训练旧99100999297.50 新91631009687.50 常规KD旧9997999898.25 新9365988986.25 本文方法旧100991009799.00 新10092999797.00
3.5.2 计算资源占用
在深度模型的服役周期内需要及时地利用新出现数据更新、维护模型,因此减少增量训练中的计算资源占用具有重要意义,特别是对于在资源受限的边缘侧部署和维护的应用场景中尤为重要。不同方法的存储空间和计算资源占用见表4,统计给出了浮点运算数、数据存储空间和显存占用等指标。浮点运算数表示模型前向传播的计算量大小,结果表明各方法所训练模型在测试环节具有相同的测试计算复杂度;数据存储空间指存储训练样本所需的内存空间,由于基于知识蒸馏的方法仅保留和回放少部分旧样本,所需的内存空间仅为联合训练的27.3%;显存占用表示增量训练中对计算资源(GPU)的消耗,在每批次样本量相等的条件下,本文方法仅占用0.9 GB显存,相较联合训练和常规KD分别减少了67.9%和18.2%,有利于降低模型部署的硬件要求、实现模型的边缘终端侧部署与本地更新。
表4 不同方法的存储空间和计算资源占用
Tab.4 Memory footprint and computing resource usage under different methods

方法浮点运算数数据存储空间/MB显存占用/GB 联合训练2.81×10835.22.8 常规KD2.81×1089.61.1 本文方法2.81×1089.60.9
由以上分析可以看出,本文方法既能适应新增局放规模的不确定性,又无需占用大量内存和计算资源来存储和重复学习大规模旧数据,仅轻微地损失精度,获得了泛化能力的提升和计算资源消耗的大幅降低,验证了其对局放增量识别任务的优越性。
除AlexNet网络外,LeNet5[5]、ResNet18[9]和MobileNet-V2[10]也常被用于局部放电的类型识别。为了验证本文方法在不同局部放电识别模型上的可推广性,依次对训练稳定的上述三种深度卷积框架进行增量更新。方便起见,各模型的卷积层通道数均为64,网络次末层的64维输出作为节点特征构建图数据,新模型均采用一层GNN,其他设置与3.2节一致。在3.5节所述的类别不平衡训练集下,不同深度神经网络的增量学习结果见表5。
表5 对不同局部放电识别模型的增量学习
Tab.5 Incremental learning for different PD models

框架数据识别率(%) 增量前增量后变化 LeNet旧98.0095.25 -2.75 新71.5092.75 +21.25 AlexNet旧99.2599.00-0.25 新80.2597.00+16.75 ResNet18旧99.2599.25 0 新83.5098.50+15.00 MobileNet-V2旧99.2598.00-1.25 新80.5096.50+16.50
从表5可以看出,多种常见的局部放电识别模型经本文方法增量更新后,对新数据均可达到90%以上的识别率,相较于增量更新前提升显著,而且仅轻微损失旧知识,在旧数据上的测试识别率下降均在3%以内。由此可见,本文提出的深度增量学习不受识别模型的网络结构限制,对常见的局放识别深度模型均表现出优异的增量效果,验证了该方法的可推广性。
针对现有基于深度学习的局部放电诊断模型不能进一步学习现场新增数据的问题,本文提出了一种结合知识蒸馏和图神经网络的局部放电增量识别方法,主要工作与结论如下:
1)将知识蒸馏法引入局部放电模式识别中,建立了具有自更新能力的深度识别模型,可以在继承原始模型识别能力的同时,学习陆续到达监测平台的新局放数据,逐渐提升泛化能力。
2)为了适应新增局放数据规模的不确定性,进一步引入图神经网络进行改进。该方法通过随机组合多个类型局放样本构建图数据,增加了训练样本的多样性,又能够挖掘不同类型样本间的关联性,弥补了有限样本的信息不足。
3)与增量前相比,对新数据的识别率提升了约18%,且在旧数据上与原始模型一致;在少样本和类别不平衡场景下,识别效果优于联合训练和常规KD,所需的硬件资源更少,显存占用分别下降了67.9%和18.2%,数据存储空间占用也仅为联合训练的27.3%(即下降72.7%),使得边缘智能终端上的模型部署及本地更新成为可能。
4)该方法对基于LeNet5、AlexNet、ResNet、MobileNet-V2等典型网络训练的局部放电识别模型均可实现增量式更新,表现出较好的可推广性。
参考文献
[1] 李泽, 王辉, 钱勇, 等. 基于加速鲁棒特征的含噪局部放电模式识别[J]. 电工技术学报, 2022, 37(3): 775-785. Li Ze, Wang Hui, Qian Yong, et al. Pattern recognition of partial discharge in the presence of noise based on speeded up robust features[J]. Transactions of China Electrotechnical Society, 2022, 37(3): 775-785.
[2] 邓冉, 朱永利, 刘雪纯, 等. 基于变量预测-谷本相似度方法的局部放电中未知类型信号识别[J]. 电工技术学报, 2020, 35(14): 3105-3115. Deng Ran, Zhu Yongli, Liu Xuechun, et al. Pattern recognition of unknown types in partial discharge signals based on variable predictive model and tanimoto[J]. Transactions of China Electrotechnical Society, 2020, 35(14): 3105-3115.
[3] 宋思蒙, 钱勇, 王辉, 等. 基于方向梯度直方图属性空间的局部放电模式识别改进算法[J]. 电工技术学报, 2021, 36(10): 2153-2160. Song Simeng, Qian Yong, Wang Hui, et al. Improved algorithm for partial discharge pattern recognition based on histogram of oriented gradient attribute space[J]. Transactions of China Electrotechnical Society, 2021, 36(10): 2153-2160.
[4] Lu Shibo, Chai Hua, Sahoo A, et al. Condition monitoring based on partial discharge diagnostics using machine learning methods: a comprehensive state-of-the-art review[J]. IEEE Transactions on Dielectrics and Electrical Insulation, 2020, 27(6): 1861-1888.
[5] Duan Lian, Hu Jun, Zhao Gen, et al. Identification of partial discharge defects based on deep learning method[J]. IEEE Transactions on Power Delivery, 2019, 34(4): 1557-1568.
[6] 张重远, 岳浩天, 王博闻, 等. 基于相似矩阵盲源分离与卷积神经网络的局部放电超声信号深度学习模式识别方法[J]. 电网技术, 2019, 43(6): 1900-1907. Zhang Zhongyuan, Yue Haotian, Wang Bowen, et al. Pattern recognition of partial discharge ultrasonic signal based on similar matrix BSS and deep learning CNN[J]. Power System Technology, 2019, 43(6): 1900-1907.
[7] Song Hui, Dai Jiejie, Sheng Gehao, et al. GIS partial discharge pattern recognition via deep convolutional neural network under complex data source[J]. IEEE Transactions on Dielectrics and Electrical Insulation, 2018, 25(2): 678-685.
[8] 朱煜峰, 许永鹏, 陈孝信, 等. 基于卷积神经网络的直流XLPE电缆局部放电模式识别技术[J]. 电工技术学报, 2020, 35(3): 659-668. Zhu Yufeng, Xu Yongpeng, Chen Xiaoxin, et al. Pattern recognition of partial discharges in DC XLPE cables based on convolutional neural network[J]. Transactions of China Electrotechnical Society, 2020, 35(3): 659-668.
[9] Gao Angran, Zhu Yongli, Cai Weihao, et al. Pattern recognition of partial discharge based on VMD-CWD spectrum and optimized CNN with cross-layer feature fusion[J]. IEEE Access, 2020, 8: 151296-151306.
[10] Wang Yanxin, Yan Jing, Sun Qifeng, et al. A MobileNets convolutional neural network for GIS partial discharge pattern recognition in the ubiquitous power internet of things context: optimization, comparison, and application[J]. IEEE Access, 2019, 7: 150226-150236.
[11] 汤奕, 崔晗, 党杰. 基于继承思想的时变性电力系统暂态稳定预测[J]. 中国电机工程学报, 2021, 41(15): 5107-5119. Tang Yi, Cui Han, Dang Jie. Transient stability prediction of time-varying power systems based on inheritance[J]. Proceedings of the CSEE, 2021, 41(15): 5107-5119.
[12] 范兴明, 王超, 张鑫, 等. 基于增量学习相关向量机的锂离子电池SOC预测方法[J]. 电工技术学报, 2019, 34(13): 2700-2708. Fan Xingming, Wang Chao, Zhang Xin, et al. A prediction method of Li-ion batteries SOC based on incremental learning relevance vector machine[J]. Transactions of China Electrotechnical Society, 2019, 34(13): 2700-2708.
[13] Li Zhizhong, Hoiem D. Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935-2947.
[14] Rebuffi S A, Kolesnikov A, Sperl G, et al. iCaRL: incremental classifier and representation learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 5533-5542.
[15] Castro F M, Marín-Jiménez M J, Guil N, et al. End-to-end incremental learning[C]//Computer Vision - ECCV 2018, Munich, Germany, 2018: 241-257.
[16] Cheraghian A, Rahman S, Fang Pengfei, et al. Semantic-aware knowledge distillation for few-shot class-incremental learning[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 2534-2543.
[17] Garcia V, Bruna J. Few-shot learning with graph neural networks[C]//6th International Conference on Learning Representations, Vancouver, Canada, 2018: 1-13.
[18] Kim J, Kim T, Kim S, et al. Edge-labeling graph neural network for few-shot learning[C]//2019 IEEE/ CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2020: 11-20.
[19] Parisi G I, Kemker R, Part J L, et al. Continual lifelong learning with neural networks: a review[J]. Neural Networks, 2019, 113: 54-71.
[20] 赵振兵, 金超熊, 戚银城, 等. 基于动态监督知识蒸馏的输电线路螺栓缺陷图像分类[J]. 高电压技术, 2021, 47(2): 406-414. Zhao Zhenbing, Jin Chaoxiong, Qi Yincheng, et al. Image classification of transmission line bolt defects based on dynamic supervision knowledge distillation[J]. High Voltage Engineering, 2021, 47(2): 406-414.
[21] 刘广一, 戴仁昶, 路轶, 等. 基于图计算的能量管理系统实时网络分析应用研发[J]. 电工技术学报, 2020, 35(11): 2339-2348. Liu Guangyi, Dai Renchang, Lu Yi, et al. Graph computing based power network analysis applications[J]. Transactions of China Electrotechnical Society, 2020, 35(11): 2339-2348.
[22] Kearnes S, McCloskey K, Berndl M, et al. Molecular graph convolutions: moving beyond fingerprints[J]. Journal of Computer-Aided Molecular Design, 2016, 30(8): 595-608.
[23] Zhou Xiang, Shen Fumin, Liu Li, et al. Graph convolutional network hashing[J]. IEEE Transactions on Cybernetics, 2020, 50(4): 1460-1472.
Abstract Partial discharge (PD) is the primary hidden danger threatening the insulation safety of high-voltage power equipment. Typically, there is some correlation between discharge type and insulation damage, so that by identifying the PD types, a large number of insulation faults can be predicted or detected in a timely manner. Recently, deep learning (DL) technology has been gradually applied in PD, showing excellent performance in PD pattern recognition. However, its learning process terminates after learning all the current data at once, which means that those PD recognition models cannot be gradually trained on the new PD data collected later. To address it, an incremental learning method combining knowledge distillation and graph neural network (GNN) for PD recognition is proposed in this paper, which can gradually expand the generalization ability of the original recognition model.
Firstly, a deep neural network (DNN) is trained as the original model M with the old PD data set. Then, according to the knowledge distillation theory, the prior knowledge from M is transferred to avoid forgetting in the process of incremental training by replaying a small amount of old PD data, and meanwhile, the new PD data can be learned with the prior knowledge assistance, which improves the generalization ability of the M. Finally, to adapt to the uncertainty of the new data size, it adopts the GNN layers to extract the abundant correlation information among various types of PD data, making up for the information shortage of limited samples. In this way, the DL-based PD model learns the continuously increasing PD data efficiently without retraining on all the old PD data and achieves better incremental recognition with different set sizes of the new data.
The experimental results show that with sufficient new PD data, the proposed incremental PD recognition method increases the accuracy by roughly 18%. In contrast to the traditional knowledge distillation, the proposed method with GNN increases the recognition accuracy by 2.75% to 9.25% on several new datasets with fewer samples, and reduces the adverse effects of unbalanced categories that are normally caused by the randomness of insulation defects. Moreover, the method has excellent generalization properties and is also effective on the incremental updates of other PD recognition models such as AlexNet, ResNet or MobileNet based models. More significantly, it requires less computational resources than retraining, reducing its GPU and RAM footprint by 67.9% and 72.7%, respectively.
The following conclusions can be drawn from the experiments analysis: (1) By introducing the knowledge distillation theory, the DL-based PD recognition model can inherit the recognition ability of original PD model as well as learn the new PD data gradually arriving at the monitoring platform, which is beneficial to improve the generalization ability of PD models. (2) The added GNN builds the graph data by randomly combining multiple types of PD samples, which increases the diversity of training samples. Therefore, it is appropriate to apply GNN to incrementally learn limited samples or imbalanced datasets in categories. (3) Compared to retrain model, this method requires less hardware resources in incremental training, making the deployment and local maintenance of the DL-based PD recognition models possible. (4) Furthermore, the proposed method is a universal incremental method so that it is effective on numerous common PD recognition models based on classical DNNs.
keywords:Partial discharge, deep learning, incremental learning, knowledge distillation, graph neural network
河北省自然科学基金(F2022502002)、国家自然科学基金(51677072)和特高压工程技术(昆明、广州)国家工程实验室开放基金资助项目。
收稿日期 2022-02-27
改稿日期 2022-03-24
DOI:10.19595/j.cnki.1000-6753.tces.220285
中图分类号:TM85
张 翼 男,1994年生,博士研究生,研究方向为输变电设备在线监测与故障诊断。E-mail:pw_zhangyi@163.com(通信作者)
朱永利 男,1963年生,教授,博士生导师,研究方向为电力设备大数据分析与智能电网。E-mail:yonglipw@163.com
(编辑 李冰)