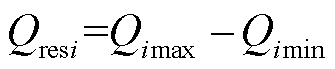 (1)
(1)
摘要 针对电网无功储备需求计算复杂度高、耗时长的问题,提出一种基于残差图卷积深度网络考虑冗余样本特征削减的电网无功储备需求快速计算方法。该文首先,给出一种基于深度学习的电网无功储备需求快速计算框架,采用残差图卷积深度神经网络(GCNII)对电网无功储备需求计算进行建模;其次,为克服传统相似性计算方法在拓扑属性样本度量问题上的局限,提出一种双尺度相似性度量方法,基于矩阵奇异值序列的余弦距离实现对拓扑结构样本的相似性度量;最后,提出一种冗余样本削减策略,基于双尺度相似性度量方法,结合改进谱聚类算法实现对样本集合的分层聚类,并通过样本局部密度分析,实现在维持数据集特征多样性的情况下,对冗余样本进行有效削减,提升模型训练效率。所提算例采用IEEE标准节点系统进行仿真,计算结果表明,该方法能够实现在模型计算精度基本不变的情况下大幅提升模型训练效率。
关键词:残差图卷积神经网络 无功储备需求计算 样本削减策略 矩阵奇异值序列 双尺度相似性
无功储备对于维持电网的电压稳定起到了至关重要的作用[1-2]。随着国家“双碳”目标的提出,可再生能源的并网规模正不断扩大,新能源的随机波动性给电力系统的安全运行带来巨大挑战[3-4]。
在无功储备分析计算领域,文献[5]围绕交直流互联系统受端电网,提出一种基于轨迹灵敏度的无功储备优化方法,为故障下的电力系统稳定运行提供支撑;文献[6]针对高比例新能源接入背景下的无功储备优化问题,提出了一种计及故障集的区域无功储备多目标优化方法,降低系统的运行风险,提高了故障下电力系统的电压安全水平;文献[7]提出一种维持最低电压稳定裕度条件下的无功备用容量优化模型,提高了系统无功储备能力;文献[8]给出了基于电压稳定的无功备用容量计算方法,并在此基础上构建了一种多目标无功储备优化模型,提高了系统的无功备用容量。以上文献均对无功储备优化计算进行了深入研究并取得了较好的效果,但以上方法的计算复杂度较高,随着电网规模的日益扩大,无功储备需求计算的时间成本进一步加剧。考虑到近年来可再生能源并网规模的激增,新能源出力的不确定性使得电网无功储备需求计算周期缩短,正逐渐从离线计算向在线评估转变,这对无功储备需求计算的实时性提出了更高的要求,因此,如何提升电网无功储备需求的计算速度,已成为能否实现其在线快速评估的关键。
近年来,由于人工智能、大数据、云计算等技术的快速发展,以及数据采集与监控系统、数值天气预报系统等平台的搭建[9],以深度学习为代表的依赖数据训练学习的机器学习方法在电力系统领域的应用奠定了基础。目前,越来越多的研究正在将深度学习技术与电力系统传统问题相结合。例如在负荷预测领域,文献[10]提出一种基于卷积神经网络(Convolutional Neural Networks, CNN)和门控循环单元(Gatedrecurrent Unit, GRU)的混合神经网络,与传统使用单模型的预测方法[11]相比,融合模型能够更加充分地挖掘负荷数据和特征之间的联系,提高了模型预测精度;文献[12]在双模型的基础上采用聚类经验模态分解降低了负荷序列的随机性和非稳定性,进一步提高了预测精度。在电力系统稳定评估领域,文献[13]提出一种基于双生成器对抗神经网络的暂态稳定评估方法,较好地解决了因样本多样性不足、抗干扰性差而导致评估算法的分类性能不佳的问题。
以上文献将人工智能技术应用于电力系统领域的相关问题,并取得了较好的成效。然而,上述文献所提出的模型和方法,虽然在处理欧式数据上有良好的表现,但其对于含有拓扑信息的非欧空间数据样本的处理能力则相对较弱[14]。考虑到电网是一个严格的拓扑网络,因此,无功储备需求计算本质上是非欧式空间下的信息传播问题。受到卷积神经网络的启发,J. Bruna等[15]在2013年提出了第一个图卷积神经网络,该算法能够计及拓扑信息有效挖掘节点之间的关联性,所以在非欧式空间的图数据计算上展现出优异的性能。目前,图网络模型已经在交通预测[16-17]、化学分子结构预测[18]、图像识别与分类[19-20]以及电力系统等众多领域有所应用,如文献[21-22]分别将消息传递图神经网络和图注意力模型(Graph Attention Network, GAT)应用于电网暂态稳定评估和配电网故障定位,成功地解决了传统网络无法适应电网拓扑变化所带来的模型性能降低的问题;文献[23]将图卷积神经网络(Graph Convolutional Neural Network, GCN)模型与谱图论结合应用于直流电网节点电压快速估计中,验证了GCN较传统机器学习算法有着更好的估计稳定性和鲁棒性。
深度学习技术的应用虽然可以在很大程度上提高模型的计算速度,但深度学习建模的过程则需要海量样本数据进行训练,训练数据集中的冗余样本不仅容易导致模型出现过拟合的情况,而且会使模型训练耗费更多时间。针对这一问题,近年来研究人员进行了初步探索,文献[24]采用核主成分分析(Kernel Principal Components Analysis, KPCA)降低模型输入变量维度,实现模型训练复杂度的降低,在一定程度上提高了模型的训练效率;文献[25]则从样本特征与标签的相关性角度去考虑,采用灰色关联分析法选取与目标值强相关的特征量作为网络输入,并通过具有最优压缩率的降维策略提取关键特征,既避免了模型出现过拟合的现象,也提高了模型的学习效率。但是通过降维来提高模型训练效率的方法仍难以从本质上解决模型训练耗时的问题,影响模型训练效率的关键因素还是样本的规模。因此,如何在确保模型精度基本不变的前提下,通过缩减训练样本,实现模型的高效训练,是值得深入研究的问题。
通过对以上文献的深入研读和分析,针对无功储备需求计算复杂度高耗时长的问题,考虑引入深度学习技术,构建残差图卷积深度网络对无功储备需求计算进行拟合,并通过特征提取策略进行冗余样本的削减,提升模型训练效率。基于这一思想,本文首先给出一种基于深度学习算法的无功储备需求快速计算框架,采用残差图卷积深度网络(Graph Convolutional Neural Networks with Initial Residuals And Identity Mappings, GCNII)进行无功储备需求建模;其次,为解决拓扑属性样本的相似性比对问题,提出一种双尺度相似性度量方法;最后,为提高模型训练效率,结合改进谱聚类和样本局部密度分析,提出一种基于双尺度相似性度量的样本削减策略,最终实现在保证模型计算精度的同时大幅提升训练效率。
算例选用IEEE标准节点进行仿真分析,首先对GCNII和已有深度学习算法进行比较分析,验证了其在无功储备需求计算上的性能优势;其次,为进一步说明本文所提样本缩减方法的有效性,采用缩减后样本和原始样本分别进行模型训练,对比分析模型计算结果和训练耗时情况,仿真结果表明本文所提样本缩减策略能够实现在模型计算精度基本不变的情况下,大幅减少模型训练时间,提升模型训练效率;最后采用不同规模的IEEE系统算例进一步对本文提出的方法进行适应性验证,结果表明本文方法适用不同规模的电力系统网络,鲁棒性较强。
为了确保电网有充足的无功储备来维持故障下系统的电压稳定性,需要对电网运行断面进行给定故障集的扫描分析(故障集通常包含:N-1/N-2扫描和给定故障等),以确定无功源无功出力的临界值,并以此计算出电网无功储备的需求,从而保证电网有充足的无功储备量以维持给定故障集下的电压稳定。
首先,计算稳态场景下无功源无功储备需求,即
(1)
式中,Qresi为无功源i的无功储备需求值;Qimax为故障典型场景下无功源i无功出力最大值;Qimin为正常运行方式下无功源i的无功出力最小值。
其次,通过对运行断面进行故障(本文采用N-1)扫描以确定各无功源的临界出力情况,并利用式(2)计算无功源故障场景集下最大无功出力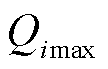 。
。
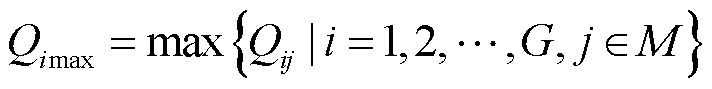 (2)
(2)
式中,为无功源i在故障场景下最大无功出力;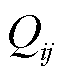 为无功源i在故障场景j下的无功出力;M为故障场景集。
为无功源i在故障场景j下的无功出力;M为故障场景集。
最后,在获取电网中各无功源无功储备需求后,通过式(3)计算电网无功储备需求[6]。
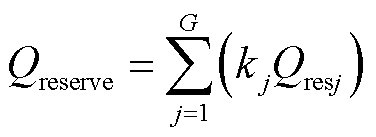 (3)
(3)
式中,Qreserve为电网无功储备需求;kj为无功源j在正常运行方式下中对主导节点的无功电压控制灵敏度[26]。
电网无功储备需求计算的流程如图1所示。
以上无功储备需求计算的耗时主要集中在故障扫描部分,以N-1故障扫描为例,单次扫描的时间通常由节点规模决定,随着节点规模的增加,其计算的时长将大幅增长。因此,为了提高无功储备需求计算的效率,实现无功储备需求的在线计算,需要给出一种快速计算方法。
深度学习技术因其强大的数据分析、预测、分类能力,近年来在建模和优化领域取得了较为瞩目的成果[27],尤其适合预测和优化问题。而无功储备需求计算是典型的预测回归问题,同时因其具有非欧式空间下的信息传播特性,使其电网的拓扑连接特性不可忽视。因此,本文选用对拓扑结构处理能力较强的图神经网络作为基础模型,构建无功储备需求快速计算框架,提高模型计算精度。
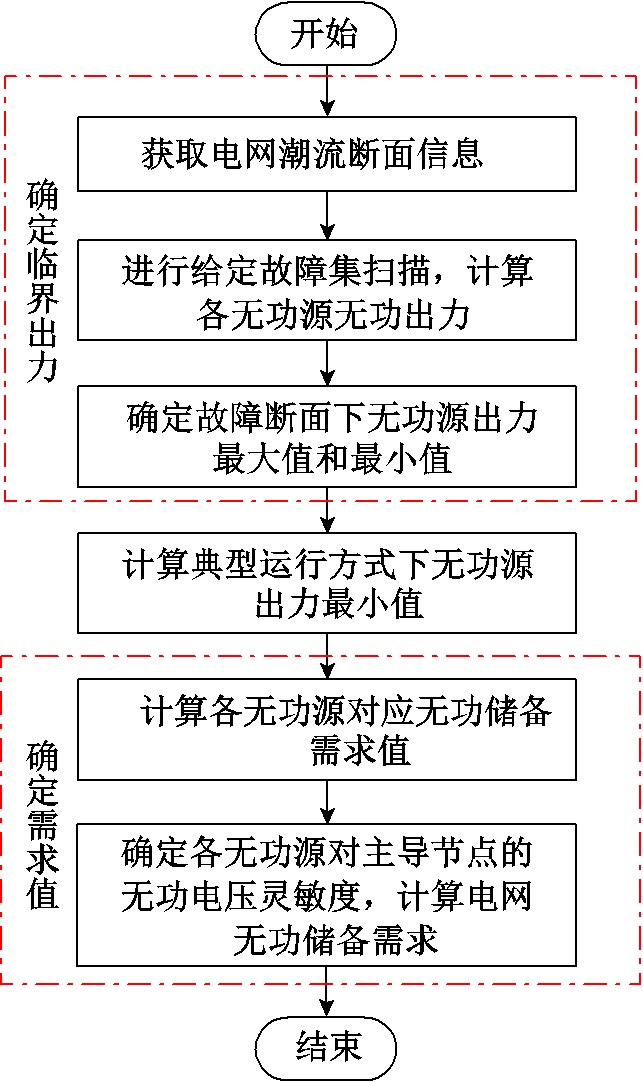
图1 电网无功储备需求计算
Fig.1 Reactive power reserve demand calculation
无功储备需求计算模型结构如图2所示。从图2中可以看出其核心由两部分构成:拓扑特征提取模块和特征映射模块。拓扑特征提取模块充分利用图卷积网络层的拓扑信息提取能力,实现对特征数据的信息聚合;而特征映射模块则是通过在图卷积层后部嵌入深度神经网络(Deep Neural Network, DNN),实现聚合后的特征量与标签数据的非线性变换。
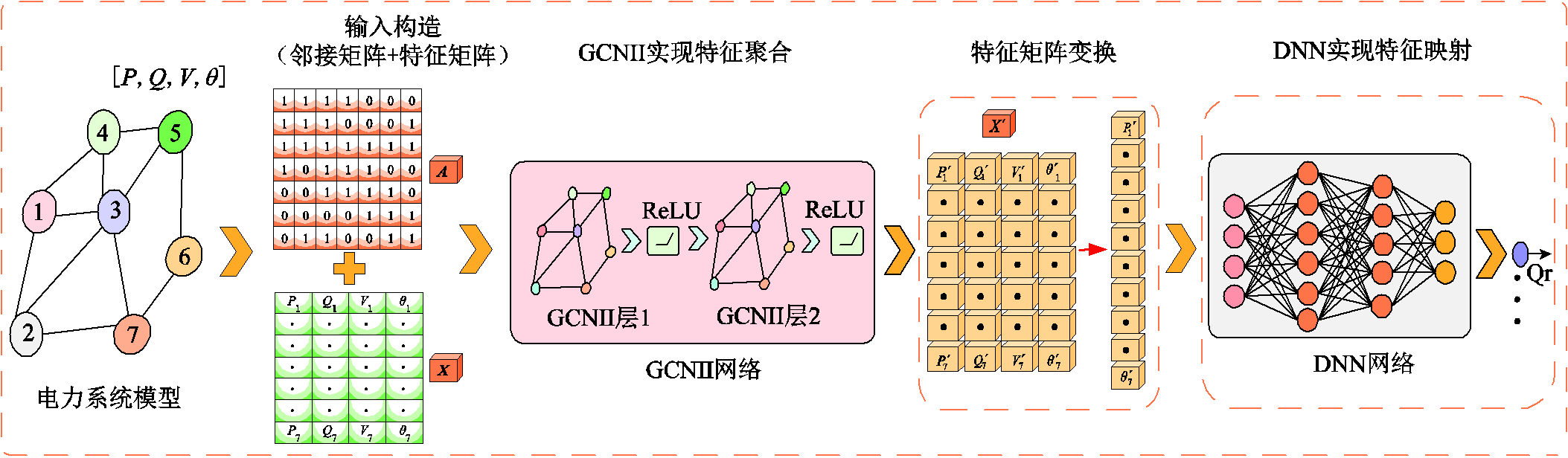
图2 无功储备需求计算模型结构示意图
Fig.2 Structure diagram of reactive power reserve demand calculation model
在详细介绍网络前,首先给出两个定义:
定义1:拓扑矩阵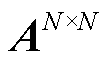 。非欧式空间的图数据
。非欧式空间的图数据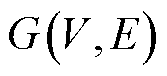 由节点和边所构,
由节点和边所构, 代表节点集合,
代表节点集合,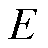 代表边集合。本文中,图中的节点代表电网中的母线节点,边代表连接各母线节点的输电线路。一般地,利用邻接矩阵A来表示电网各母线节点之间的连接关系。
代表边集合。本文中,图中的节点代表电网中的母线节点,边代表连接各母线节点的输电线路。一般地,利用邻接矩阵A来表示电网各母线节点之间的连接关系。
定义2:特征矩阵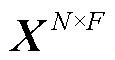 。将电网各母线节点功率等数据作为节点的特征属性,其中
。将电网各母线节点功率等数据作为节点的特征属性,其中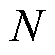 表示电网中母线节点的数量,
表示电网中母线节点的数量,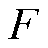 表示各母线节点所带有的特征信息数量,节点的属性特征可以是母线节点的注入无功功率、注入有功功率、节点电压以及相角信息。
表示各母线节点所带有的特征信息数量,节点的属性特征可以是母线节点的注入无功功率、注入有功功率、节点电压以及相角信息。
图神经网络通过消息传递的方式聚合电网拓扑连接信息和各母线节点信息,实现对特征信息的挖掘,从而较好地处理非欧式空间的回归问题[14]。具体特征聚合过程示意图如图3所示。
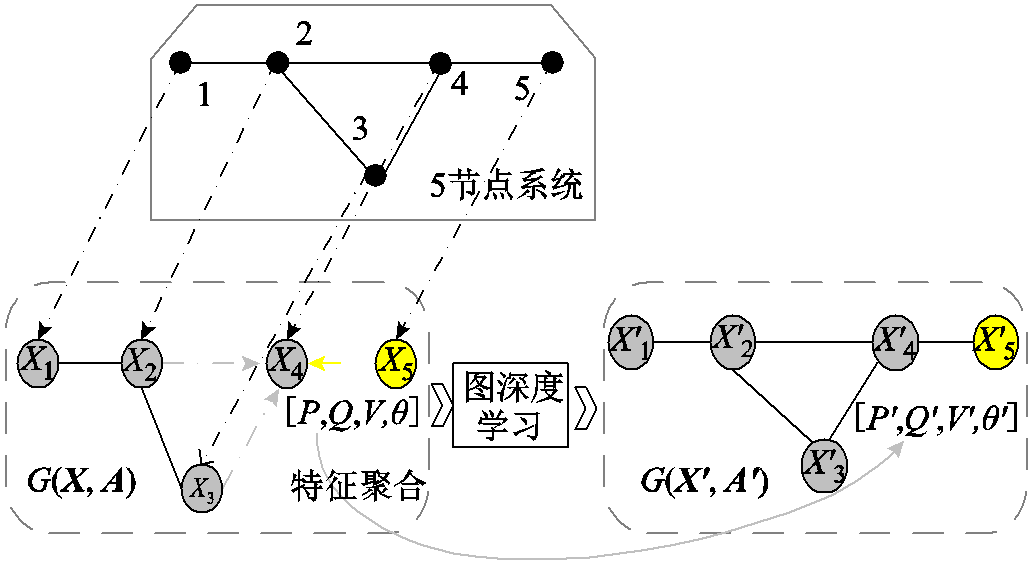
图3 特征聚合过程示意图
Fig.3 Schematic diagram of feature aggregation process
图神经网络可利用拓扑节点间的连接,通过某种信息传递的方式挖掘图中节点间的互信息。与传统模型相比,因其具有局部连接和参数共享的性质,使其拥有更加优良的性能表现,是目前应用最为广泛的深度学习技术之一。
图卷积神经网络是在CNN的基础上发展而来。CNN仅能利用规则矩阵空间上的数值信息,对于具有复杂拓扑结构的电力系统网络来说,CNN无法有效利用空间局部区域之间的关联信息。而GCN可以通过图上卷积算子实现对拓扑结构下节点的信息聚合[28],因此,使用图卷积神经网络来捕捉电力网络结构特征进行特征提取。对于图来说,首先需要定义图的拉普拉斯矩阵L=D-A,并通过式(4)计算规范化后的图拉普拉斯矩阵[29]。
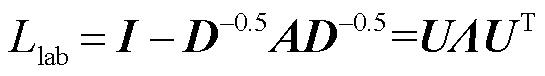 (4)
(4)
式中,I为单位矩阵,U、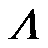 分别对应
分别对应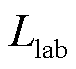 的特征向量矩阵及特征值对角阵;D为邻接矩阵A对应的度矩阵。
的特征向量矩阵及特征值对角阵;D为邻接矩阵A对应的度矩阵。
为了解决传统谱卷积在处理图时计算量较大的问题,H. David等[30]利用K阶切比雪夫多项式逼近滤波器实现对局部图进行卷积操作,公式变换为
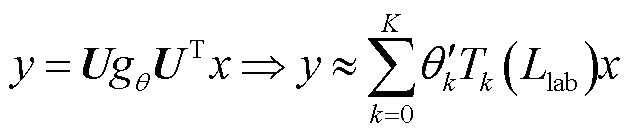 (5)
(5)
式中,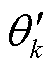 为切比雪夫系数;
为切比雪夫系数;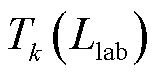 为切比雪夫多项式。
为切比雪夫多项式。
T. N. Kipf等[31]为了进一步简化卷积运算,通过限制K=1且令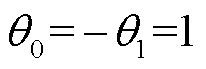 来进一步逼近最大特征值,将式(5)改写为
来进一步逼近最大特征值,将式(5)改写为
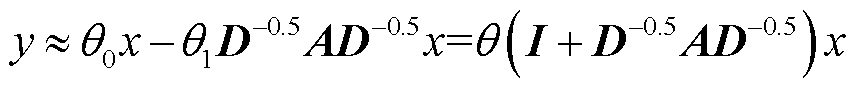 (6)
(6)
最终,将式(6)进行归一化处理获得图卷积神经网络(Graph Convolutional Network, GCN)层的矩阵表达形式为
 (7)
(7)
式中,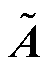 为增加自连接的邻接矩阵;
为增加自连接的邻接矩阵;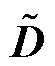 为对应度矩阵;
为对应度矩阵;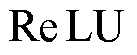 为激活函数;
为激活函数;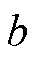 为偏置;
为偏置;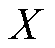 为特征信息;W为权重矩阵。
为特征信息;W为权重矩阵。
图卷积神经网络虽然能够有效地学习非欧式空间数据,但其网络本身存在一定局限性:传统GCN的结构往往只能够采用浅层设计,导致模型无法从高阶邻居中获取特征信息从而限制了模型性能的提升,这也在一定程度上降低了模型的拟合能力。文献[32]尝试采用堆叠多层网络的方式去提取高阶邻居信息,反而导致模型的准确性降低。这种现象被称为过度平滑,即随着网络层数的增加,GCN中节点的特征信息会倾向于收敛到某一特定值,导致模型的学习能力下降。
为了解决深层图卷积神经网络出现过度平滑的问题,Chen Ming等[33]提出了一个应用初始残差(initial residual connection)和身份映射(identity mapping)的变体图卷积神经网络模型GCNII,其在每一层,利用初始残差从输入层构建一个跳跃连接并通过恒等映射在权值矩阵中添加一个单位阵,在有效缓解模型过度平滑的同时,也提高了模型的性能。GCNII网络层的数学表达式为
 (8)
(8)
式中,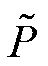 为图卷积矩阵的重正则化,
为图卷积矩阵的重正则化,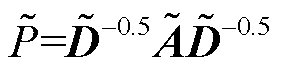 ;
;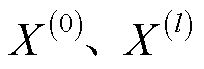 分别为输入层特征和第
分别为输入层特征和第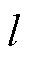 层特征;In为单位矩阵;
层特征;In为单位矩阵;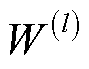 为第层的权值;
为第层的权值;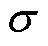 为激活函数;
为激活函数;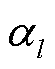 为第层每个节点所含原始输入特征的权重;
为第层每个节点所含原始输入特征的权重;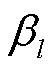 的设置降低了权重矩阵的衰减速率。
的设置降低了权重矩阵的衰减速率。
针对传统无功储备需求计算复杂度高且耗时长的问题,本文利用残差图卷积神经网络进行无功储备需求建模,并在此基础上提出一种考虑双尺度相似性的样本削减策略,实现在维持数据特征多样性的情况下,对冗余数据进行削减以提升模型的训练效率。电网无功储备需求快速计算框架如图4所示。
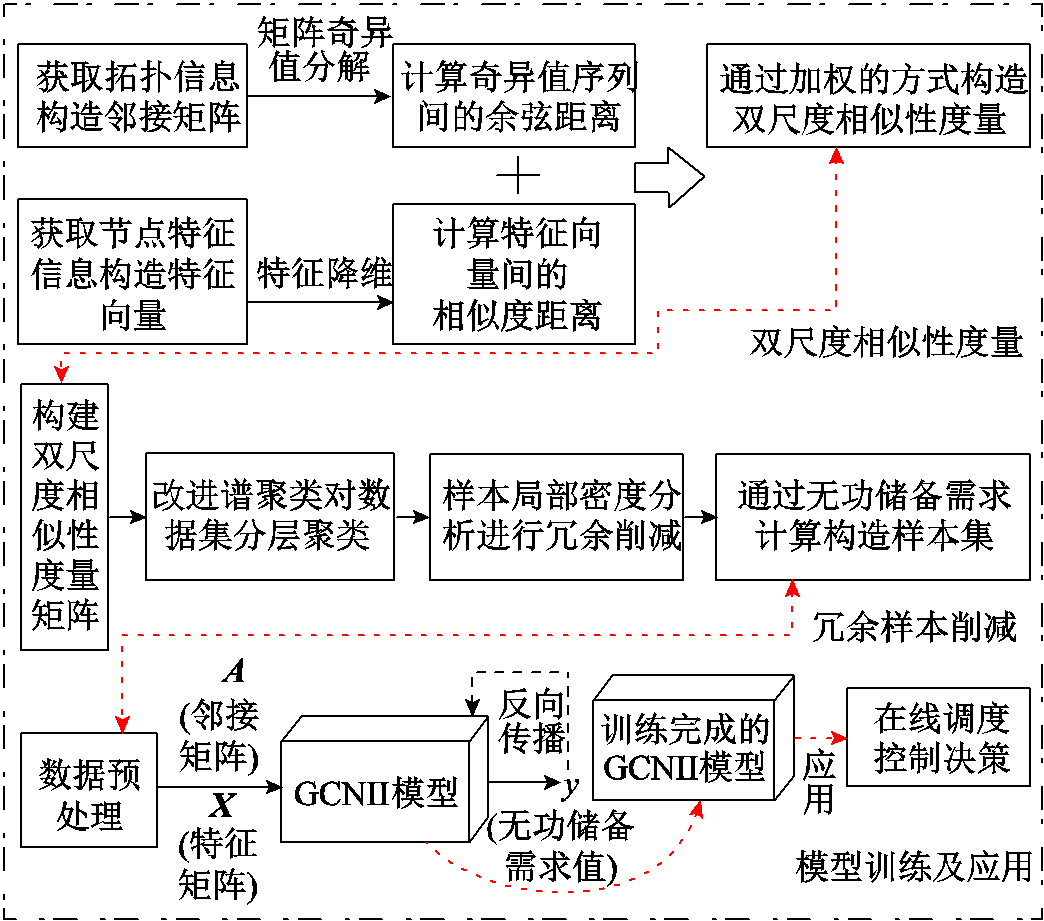
图4 电网无功储备需求快速计算框架
Fig.4 Framework for fast calculation of power grid reactive power reserve demand
1)获取历史断面信息,将断面整体发电和负荷水平在80%~120%之间进行均匀波动,构造样本集。
2)对所构造新断面进行数据清洗,通过潮流计算排查潮流不收敛的断面。
3)根据电网数据带有拓扑特征的性质,构建一种基于拓扑矩阵奇异值序列的双尺度相似度量方法,对带拓扑属性的样本数据集合进行相似性分析。
4)采用改进谱聚类算法对样本集进行分层聚类,深度挖掘样本的空间分布特性,并进行样本局部密度分析,削减冗余数据。
5)获取经削减处理后的样本进行数据集划分,以实现对模型的训练和测试。
采用深度学习建模技术虽能够极大地减少无功储备需求计算时间,实现在线计算,但模型自身训练需要海量的历史样本常导致模型训练耗时长,在线更新速度慢等问题。因此,如何实现在维持模型计算精度基本不变的情况下,大幅提高模型训练效率,对降低模型训练时间成本,提高模型在线更新速度等方面都有着重要意义。针对以上问题,本节提出基于双尺度相似性度量的样本削减策略实现对样本集进行冗余削减,提高模型的训练效率,基于双尺度相似性分析的样本削减流程如图5所示。
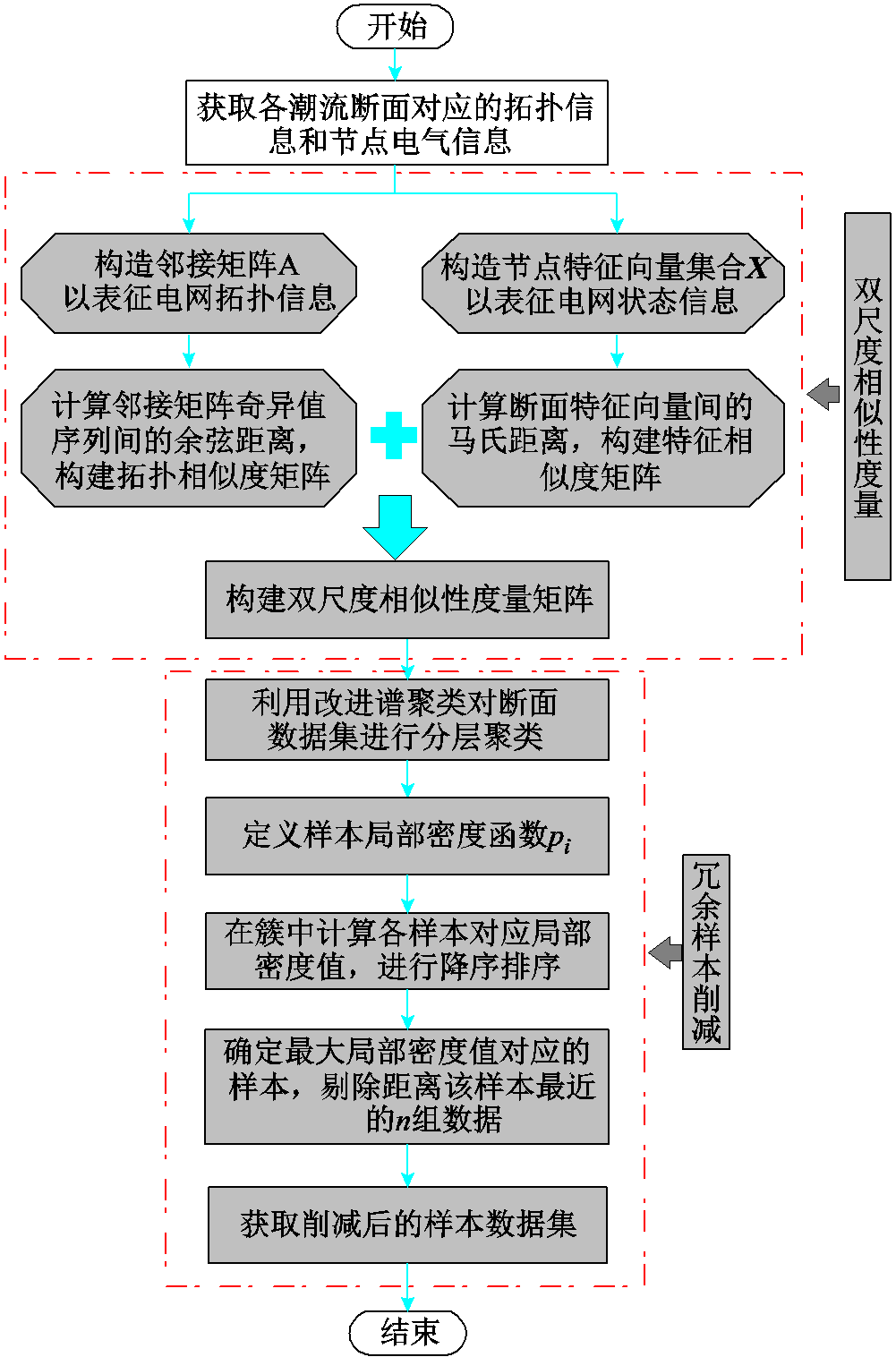
图5 基于双尺度相似性分析的样本削减流程
Fig.5 Sample reduction flow chart based on two-scale similarity analysis
主要步骤如下:
1)获取潮流断面对应的拓扑连接信息和节点电气信息,构造样本集合。
2)分别计算样本的拓扑相似度矩阵和节点特征相似度矩阵,并计算双尺度相似性。
3)利用双尺度相似性度量方法构造相似度矩阵以表征样本间相似程度。
4)采用基于双尺度相似矩阵的改进谱聚类算法对样本集合进行分层聚类,深度挖掘样本分布情况。
5)获取聚类结果,并构建局部密度函数,计算样本集合各样本对应的局部密度值。
6)对样本局部密度值进行排序,对分布较密集的数据样本进行削减。
传统度量方法大多采用单一尺度的数值距离进行相似程度的衡量[34],但本文中的电网样本具有拓扑特性,导致传统度量方法难以有效地衡量拓扑信息之间的相似程度。因此,如何构建拓扑属性样本间的相似性度量方法,成为样本削减首要解决的关键问题。本节提出一种基于双尺度相似性的拓扑样本度量方法,用以衡量拓扑样本间的相似程度。
3.1.1 基于拓扑信息的相似性度量方法
在实际电网运行中,由于线路检修、优化运行等原因常造成网络拓扑发生变化,而拓扑信息的变化对断面潮流的影响不可忽略。因此,为了能准确的分析电网样本间的相似度,需将断面样本抽象为由节点和支路构成的拓扑结构图(用邻接矩阵来表示),再通过矩阵奇异值分解获取拓扑矩阵对应的奇异值序列[35](矩阵奇异值序列能够涵盖电网拓扑主要结构特征)。
基于以上分析,本节采用奇异值序列间的余弦距离表征断面间拓扑相似度。具体计算步骤如下:
1)获取断面信息,根据电网网络下的节点以及线路信息构造邻接矩阵A。
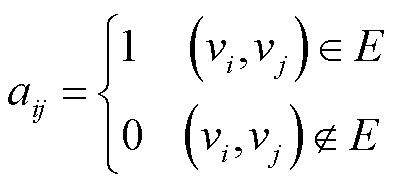 (9)
(9)
式中, 代表连接结点
代表连接结点 和
和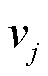 的边;为无向图中边的集合。
的边;为无向图中边的集合。
2)对所生成的邻接矩阵进行奇异值分解;假定邻接矩阵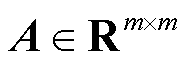 ,则存在m×m的正交阵U和m×m的正交阵V,使得
,则存在m×m的正交阵U和m×m的正交阵V,使得
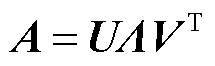 (10)
(10)
式中,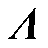 为m×m的对角矩阵,m为母线节点的数量。
为m×m的对角矩阵,m为母线节点的数量。
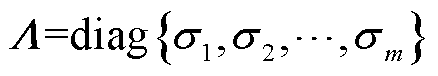 (11)
(11)
式中,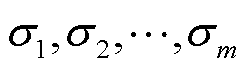 为矩阵A的奇异值序列。奇异值包含了矩阵的核心信息,因此具有描述矩阵特征的能力。
为矩阵A的奇异值序列。奇异值包含了矩阵的核心信息,因此具有描述矩阵特征的能力。
3)对奇异值序列进行排序,截取前k个较大的奇异值构成断面拓扑特征的表征向量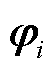 。
。
4)确定各断面拓扑对应的奇异值向量,通过余弦距离计算向量之间的相似度距离记为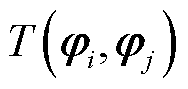 ,具体计算公式为
,具体计算公式为
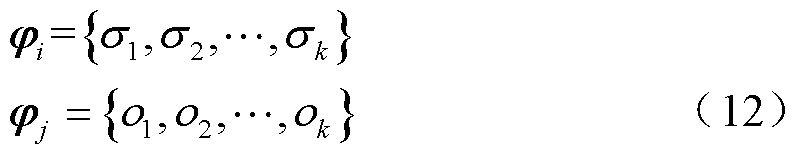
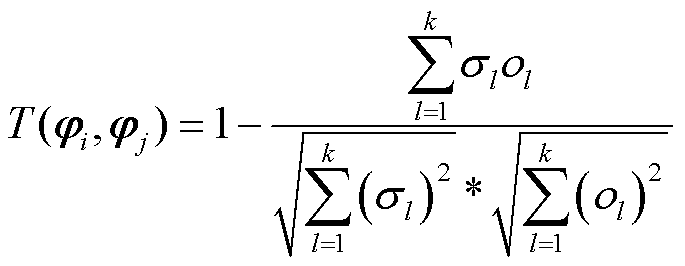 (13)
(13)
式中,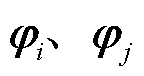 分别为第i个和第j个断面拓扑所对应的奇异值序列;
分别为第i个和第j个断面拓扑所对应的奇异值序列; 为奇异值序列
为奇异值序列 的第
的第 个元素;
个元素; 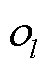 为奇异值序列
为奇异值序列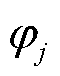 的第个元素;*代表元素相乘;
的第个元素;*代表元素相乘;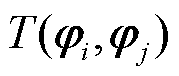 为两个序列向量之间的余弦距离即断面间拓扑相似度。
为两个序列向量之间的余弦距离即断面间拓扑相似度。
3.1.2 基于节点特征信息的相似性度量方法
3.1.1节从拓扑角度分析了断面样本的相似度处理方法,但仅通过拓扑特征衡量两个断面样本间的相似度,难以反映电网样本的全貌(例如:运行特性)。因此,还需构建样本运行数据特征的相似度比对方法。
本节给出一种基于节点特征信息的相似性度量方法。考虑到样本运行数据特征的计算复杂度会随样本节点特征维度的增加而大幅增长,因此,在实际应用时还需要对节点特征进行降维,从而提高计算效率,采用KPCA对各断面样本节点特征信息所构成的高维数据进行降维,利用降维后的数据进行特征相似度分析,既能保留原数据的全局特征[36]也能降低相似度距离的计算复杂度。具体计算步骤如下:
1)选定断面下各母线节点的特征信息(注入有功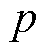 ,注入无功
,注入无功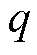 ,电压
,电压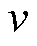 ,相角
,相角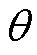 )构成输入向量
)构成输入向量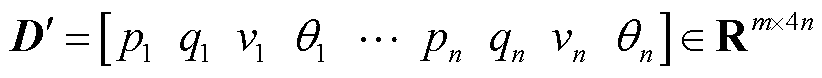 ,m为断面数量,n为母线节点个数。
,m为断面数量,n为母线节点个数。
2)对输入变量中所包含数据进行z-score标准化处理。z-score标准化计算公式为
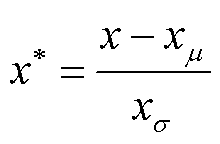 (14)
(14)
式中,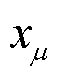 为输入向量所含数据的均值;
为输入向量所含数据的均值;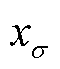 为输入向量所含数据的方差。
为输入向量所含数据的方差。
3)确定核函数,本文采用学习能力强且稳定性较高的高斯径向基核函数(Radial Basis Function, RBF),函数公式为
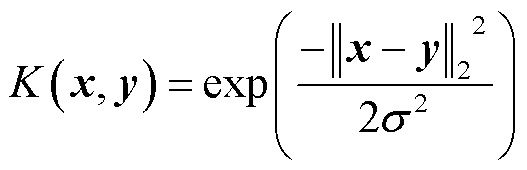 (15)
(15)
式中,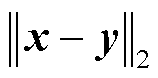 表示向量的L2-范式;σ为常数,表示高斯函数的覆盖宽度。
表示向量的L2-范式;σ为常数,表示高斯函数的覆盖宽度。
4)根据式(16)在特征空间对映射数据进行中心化处理,获取聚集度更高的核矩阵。
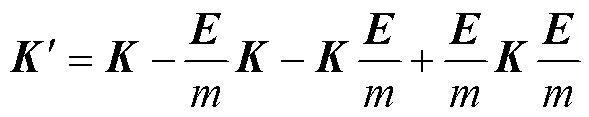 (16)
(16)
式中,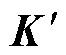 为聚集度更高的核矩阵;E为m×m的单位矩阵;K为核矩阵。
为聚集度更高的核矩阵;E为m×m的单位矩阵;K为核矩阵。
5)求取矩阵的特征值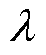 和特征向量w,根据式(17)选取贡献率前M个特征值为主元,从而获取数据样本的非线性主成分。
和特征向量w,根据式(17)选取贡献率前M个特征值为主元,从而获取数据样本的非线性主成分。
 (17)
(17)
式中,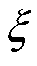 为特征值贡献率。
为特征值贡献率。
6)将降维后的数据构成m×k的特征矩阵X。
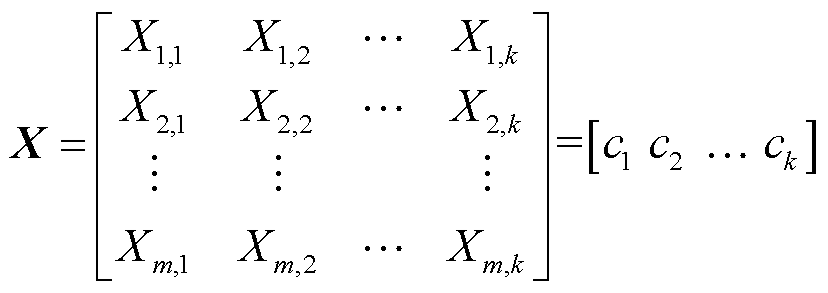 (18)
(18)
式中,m为断面数量;k为各断面特征压缩后的维度。
7)计算整个特征样本集合的协方差矩阵S。
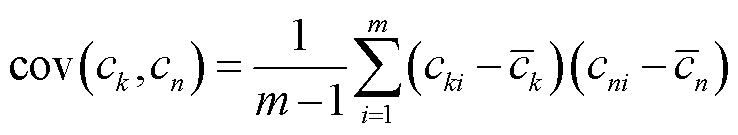 (19)
(19)
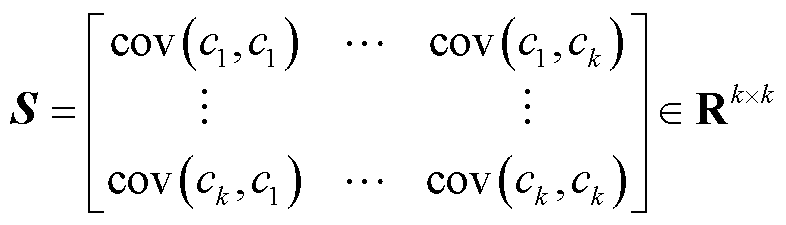 (20)
(20)
8)最后利用马氏距离计算断面间的特征相似度,计算公式为
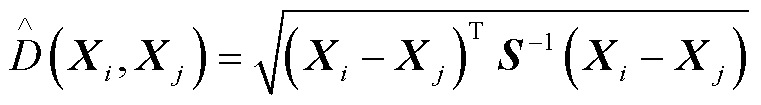 (21)
(21)
式中,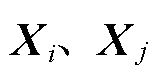 分别为第i个和第j个断面对应的母线特征向量;S为特征样本间的相关性。
分别为第i个和第j个断面对应的母线特征向量;S为特征样本间的相关性。
3.1.3 双尺度相似性度量方法
3.1.1节和3.1.2节分别从拓扑和节点特征两个角度给出了相似度量的方法,但断面样本的相似性需要综合拓扑相似程度和节点特征相似程度,因此,比较两个断面样本间的相似度还需要通过加权的方式构造双尺度相似度量方法。
考虑双尺度相似性的样本间综合距离计算如图6所示。
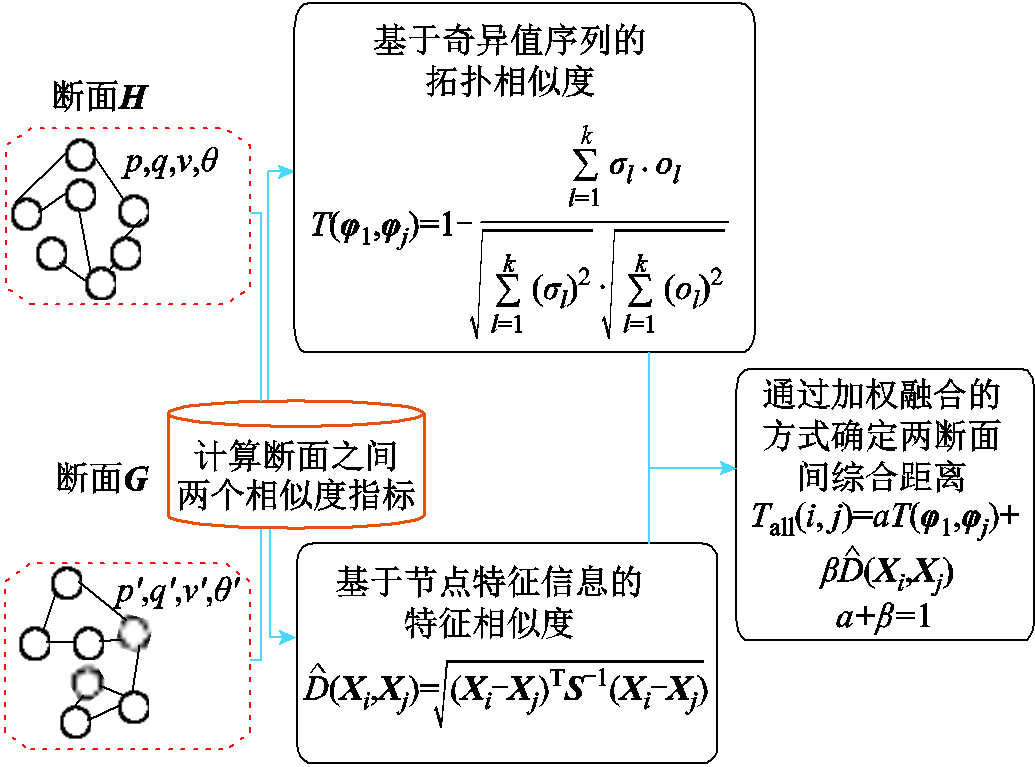
图6 考虑双尺度相似性的样本间综合距离计算
Fig.6 Comprehensive distance calculation between samples considering two-scale similarity
主要计算步骤如下:
1)获取潮流断面对应的拓扑连接信息和节点电气信息,分别构造拓扑连接矩阵和节点特征向量。
2)通过矩阵奇异值分解获取拓扑邻接矩阵对应的奇异值序列,并计算奇异值序列间的余弦距离以衡量拓扑间相似性。
3)采用核主成分分析对节点特征向量集合进行降维,计算降维后节点特征向量间的马氏距离以衡量节点特征相似度。
4)通过加权融合的方式构造考虑拓扑相似性的样本间综合相似距离计算方式,描述为
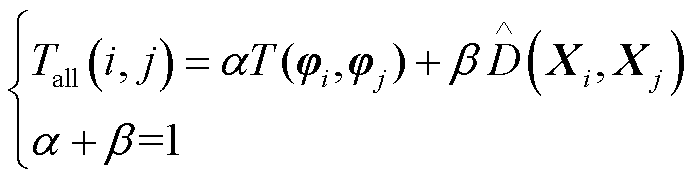 (22)
(22)
式中,α、β为可根据程序调整的加权系数,本文中将α、β分别设置为0.5;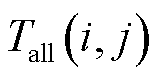 为第
为第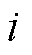 和第
和第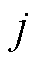 个断面间的综合距离;为拓扑矩阵奇异值序列间的余弦距离;
个断面间的综合距离;为拓扑矩阵奇异值序列间的余弦距离;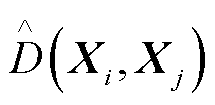 为母线节点间电气信息的马氏距离。
为母线节点间电气信息的马氏距离。
3.1节通过构建双尺度相似性度量方式,解决了拓扑属性样本的相似度量问题。本节在此基础上,进一步研究利用双尺度相似性进行冗余样本的削减。通过改进谱聚类算法,深度挖掘断面样本的空间分布特性,并通过分析样本集的局部密度特征,实现对较密集样本的冗余削减。
3.2.1 基于双尺度相似度量矩阵的改进谱聚类算法
传统谱聚类算法多采用单一距离进行相似性度量[37],无法兼顾本文样本的拓扑相似性和节点特征相似性。因此,本节采用双尺度相似方法来改进传统谱聚类的相似矩阵,实现对带拓扑属性样本的有效分类。主要步骤如下:
1)利用式(23)构造双尺度相似度量矩阵T。
 (23)
(23)
2)根据相似度矩阵T,采用高斯核函数构造邻接矩阵W。
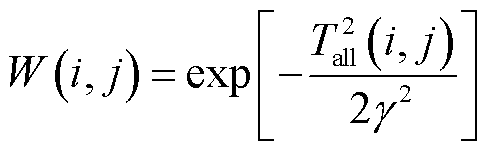 (24)
(24)
式中,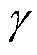 为尺度参数。
为尺度参数。
3)计算邻接矩阵W的归一化拉普拉斯矩阵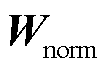 ,并进行矩阵特征分解计算获取特征值,同时选取p个最大特征值所对应的m维特征向量
,并进行矩阵特征分解计算获取特征值,同时选取p个最大特征值所对应的m维特征向量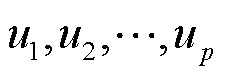 。
。
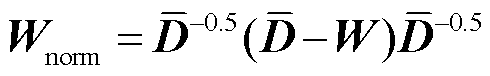 (25)
(25)
式中,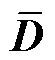 为对角矩阵,其元素
为对角矩阵,其元素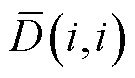 为矩阵W第i行元素之和。
为矩阵W第i行元素之和。
4)构造一个m×p的特征矩阵F,F的各列分别为,并利用式(26)对矩阵每一行进行标准化处理。
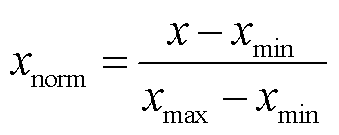 (26)
(26)
式中,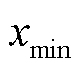 、
、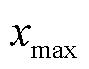 分别为该维数据的最小值、最大值;
分别为该维数据的最小值、最大值;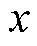 为数据初始值;
为数据初始值;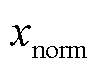 为归一化后的数据值。
为归一化后的数据值。
5)将矩阵F的每一行作为一个样本点,对这些样本点进行K-means聚类[38],获取s簇聚类结果,有
 (27)
(27)
式中, 为第s簇的断面集合;为簇中断面样本的数量。
为第s簇的断面集合;为簇中断面样本的数量。
3.2.2 基于局部密度分析的样本削减策略
3.2.1节给出了断面样本集合的聚类结果,本节对各聚类集合做进一步分析,通过对各分类集合中不均匀样本的局部密度特征进行计算,降低样本密集区域的冗余度,最终在集合特征近似不变的基础上实现冗余样本削减,提高模型训练效率。图7给出了削减后样本分布示意图,从图中可以看出经过样本削减后,原本密集的数据集变得稀疏,且优化后的数据集合仍然能够较好地模拟原始样本集的分布空间。
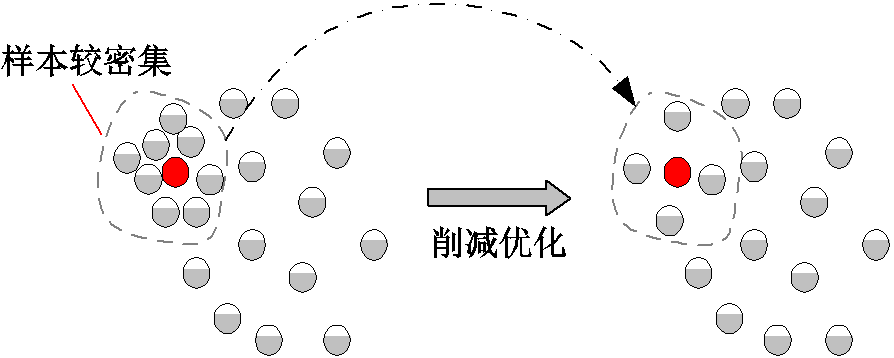
图7 削减后样本分布示意图
Fig.7 Schematic diagram of sample distribution after reduction
具体的计算步骤如下:
1)以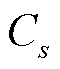 类为例,采用式(13)和式(21)构造双尺度相似度量矩阵T,T中存放类中
类为例,采用式(13)和式(21)构造双尺度相似度量矩阵T,T中存放类中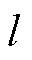 个断面间的综合距离。
个断面间的综合距离。
2)选取相似度矩阵每行前k个较小的距离元素(不包括对角元素)所对应的断面样本,构成最邻近样本集合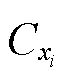 ,表示类中距离
,表示类中距离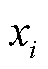 最近的k个断面样本。
最近的k个断面样本。
3)定义样本局部密度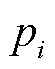 ,用于描述样本周围空间中数据的密集程度,计算公式为
,用于描述样本周围空间中数据的密集程度,计算公式为
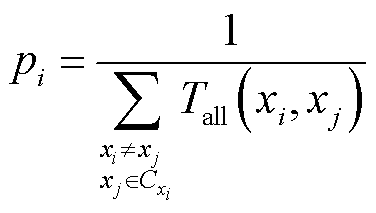 (28)
(28)
4)设置局部密度阈值 。为避免样本集出现过度删除的情况,并保证集合样本的特征近似不变,本文采用原始集合中各样本的局部密度和的均值作为判断阈值,从而实现对断面样本削减过程的控制。
。为避免样本集出现过度删除的情况,并保证集合样本的特征近似不变,本文采用原始集合中各样本的局部密度和的均值作为判断阈值,从而实现对断面样本削减过程的控制。
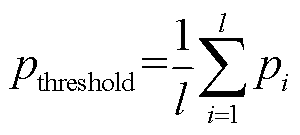 (29)
(29)
式中,l为类中原始样本的数量。
5)将计算出的局部密度值按降序排序获取数组P,并提取最大局部密度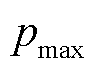 所对应的断面编号。
所对应的断面编号。
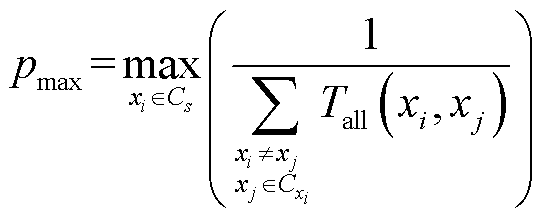 (30)
(30)
6)根据所确定的断面编号,在样本数据集中寻找对应断面样本,剔除与该断面综合距离最小的前n个断面。
7)对剩余的断面样本重新进行局部密度计算,选取最大密度值进行判断,若最大密度小于或等于密度阈值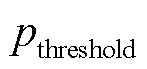 ,则结束本次计算;反之,执行步骤5),直到满足判断依据为止。
,则结束本次计算;反之,执行步骤5),直到满足判断依据为止。
为验证本文提出的无功储备需求快速计算框架的有效性和合理性,采用IEEE标准节点系统数据进行算例仿真。通过对标准IEEE系统的整体发电和负荷水平在80%~120%之间进行均匀波动构造样本集。算例所用模型均采用Facebook公司发布的深度学习框架 Pytorch1.7.0搭建;编写的语言为 python3.8.4;所用计算机配置为Intel(R) Core(TM) i7-9750HCPU @2.60GHz,内存16G。
为了使样本集合的分布更均匀,在样本生成的过程中对数据集的整体发电和负荷水平进行均匀分挡随机波动:将IEEE标准系统断面数据的整体发电和负荷水平在80%~120%之间均匀分成10挡,在每挡上再对各发电和负荷加上对应挡位5%以内的随机波动值。基于上述发电负荷变化情况进行样本生成,并通过潮流计算对断面有效性进行验证,剔除无法收敛的部分样本,最后,通过电网无功储备需求计算得到模型目标输入值。
本节对提出模型的泛化能力进行分析,分别采用100组训练集样本和测试集样本进行量化对比分析,图8给出了GCNII模型在训练集和测试集上的计算结果。图中真实值为采用数值计算方法得到的电网实际无功储备需求值;计算值为采用深度学习模型计算得到的无功储备需求值。
从图8中可以看出,模型在训练集和测试集上的计算结果均能较好地贴近目标值,这表明本文所提模型具有较强的泛化能力。图8c进一步给出了模型在不同数据集合上的计算误差分布情况,从图中可以明显看出,无论训练集还是测试集,GCNII模型的误差均集中分布在0值附近,训练集上的最大分布频率接近0.14,这也说明了模型在训练集上的计算结果更加贴近真实值。
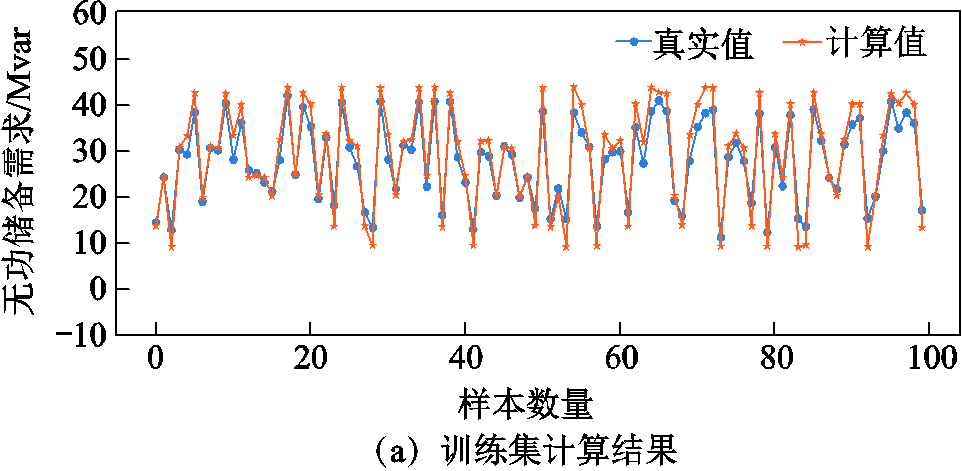
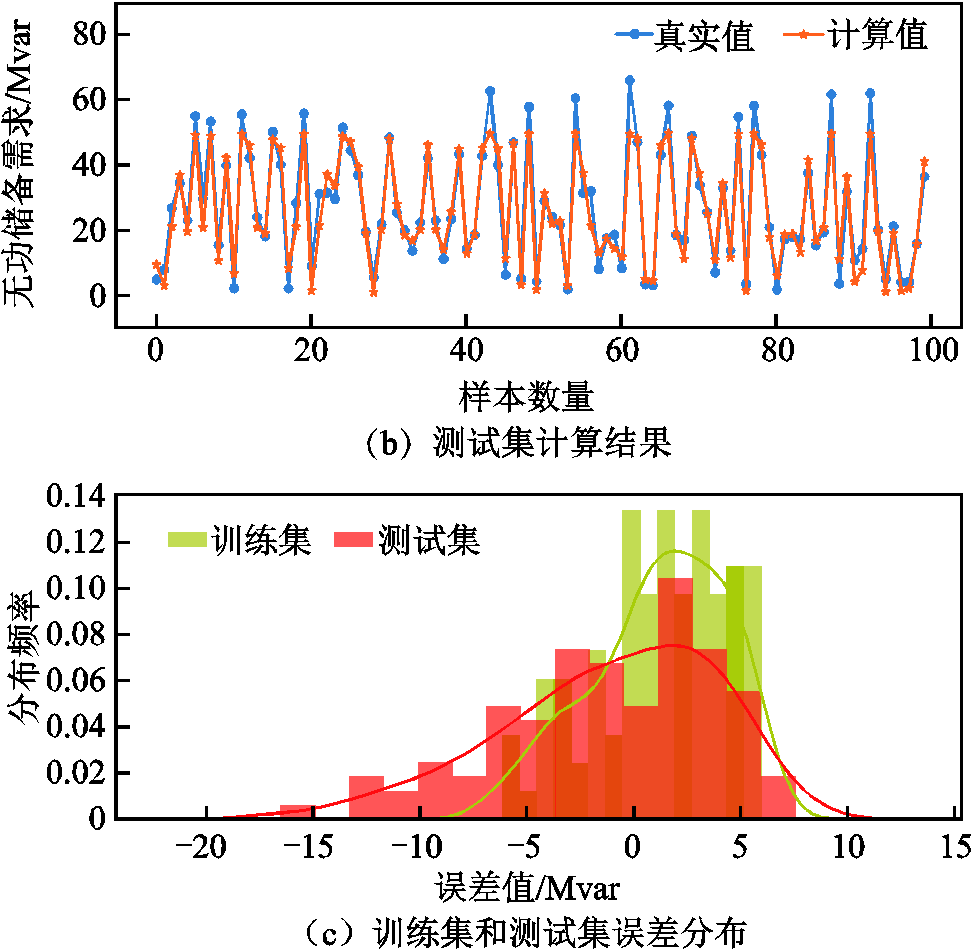
图8 训练集和测试集计算结果对比分析
Fig.8 Comparison and analysis of calculation results of training set and test set
训练集与测试集的评价量化对比见表1。可以看出,训练集的MSE值和MAE值均小于测试集,其中MAE值相差1.2,而MSE值则相差14.821,这反映了在测试集上误差分布更加分散,结合图8b也可以看出测试集还存在着误差较大的样本点,这也说明了模型在测试集上的误差波动较训练集要更大。
表1 训练集与测试集的评价量化对比
Tab.1 Quantitative comparison of evaluation between training set and test set

分类MAEMSE 训练集2.81210.977 测试集4.01225.798
4.2节对GCNII模型的泛化能力进行了验证,本节进一步验证GCNII模型对处理过度平滑问题的能力。分别采用GCNII和GCN搭建2层、4层、6层、8层和16层模型,并在相同的数据集上进行无功储备需求计算,对比分析各模型的计算结果。
不同层网络模型计算结果分析如图9所示,其中在两层网络结构下出现GCN模型计算精度优于GCNII的情况,这是因为浅层结构下GCN模型的图卷积矩阵较GCNII能够更有效地提取特征,从而取得较好的计算精度[17,39]。而随着网络层数的增加,传统GCN的特征将收敛至某一个值而造成信息丢失,导致模型计算精度下降[33,40],从图9f中可以明显看出,随着网路层数的增加,GCN模型计算结果的平均绝对误差呈现递增趋势,而GCNII模型计算结果的平均绝对误差则会逐渐减小,并稳定在2左右,这说明GCNII模型随着网络层数的变化仍能够较好拟合数据特征,同时随着层数增加GCNII计算结果较GCN更加够贴近真实值。
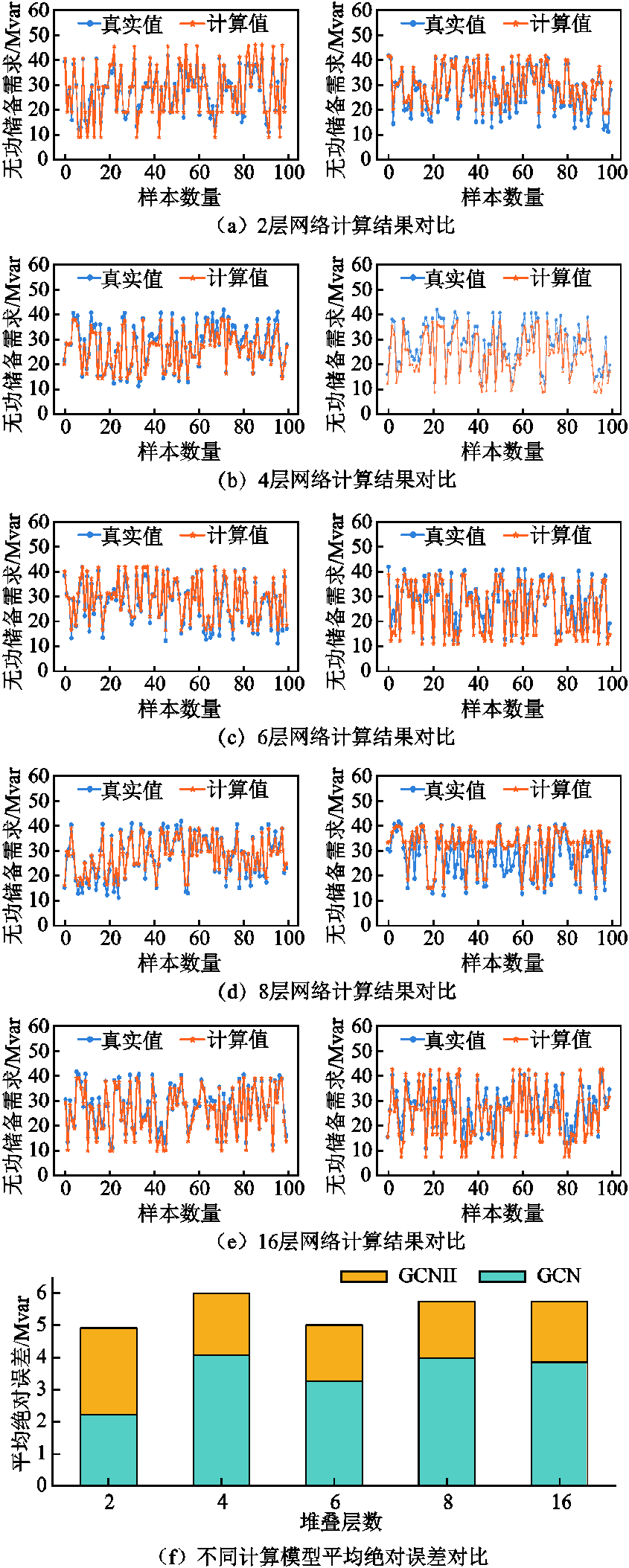
图9 不同层网络模型计算结果分析
Fig.9 Analysis of computing results of different layer network models
为了进一步分析网络层数的增加对不同模型稳定性的影响,采用小提琴图和箱线图来分析两种模型计算结果的绝对误差分布情况。不同模型绝对误差分布如图10所示。小提琴图给出了绝对误差分布情况,箱线图则展示了绝对误差的均值、中位数以及上下四分位数的情况。
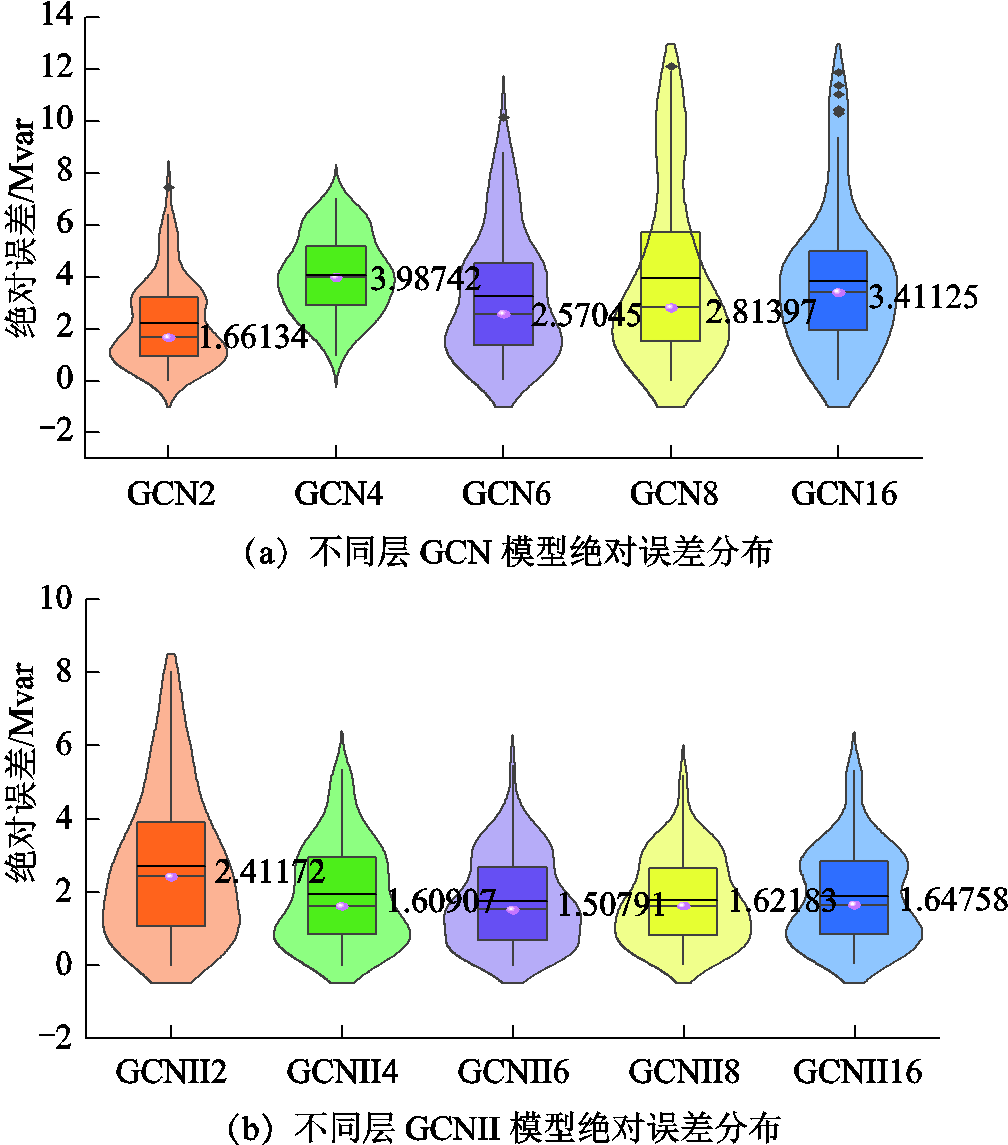
图10 不同模型绝对误差分布
Fig.10 Absolute error distribution of different models
从图10a可以看出,随着堆叠GCN层数的变化,模型计算结果的误差分布也呈现较大波动。其中,2、4、6、8和16层GCN层所构成的计算模型的绝对误差中位数分别为1.66、3.99、2.57、2.81、3.41;从误差分布情况上看,随着层数的增加,预测误差的分布范围将逐步增大,甚至出现部分计算结果的绝对误差超过10,这说明随着层数的增加,GCN模型计算精度逐渐下降。
图10b则反映了层数变化对GCNII模型的影响,从图中可以看出:2、4、6、8及16层GCNII层所构成的计算模型的绝对误差中位数分别约为2.41、1.61、1.51、1.62、1.65,GCNII模型绝对误差平均值相较于GCN模型减少了1.128。进一步分析误差分布,可以看出不同层数的GCNII模型绝对误差均集中分布在中位数附近,绝对误差均小于10,且随着层数的增加,绝对误差分布呈现较稳定的状态,集中分布在0~5之间,这说明随着网络层数增加,GCNII模型仍然具有良好计算精度。
为了进一步验证GCNII模型在处理过度平滑问题上的优势,采用方均误差(MSE)和平均绝对误差(MAE)两个指标对各模型的计算结果进行量化评估。
不同层的网络模型评估量化对比见表2。从表2中可以看出,GCN模型随层数的增加,各指标均出现了较大的波动,其中2层GCN和8层GCN的MSE差值达到了19.505,说明深层的GCN模型计算精度较浅层网络更低。而相对应的GCNII模型则表现出较好的稳定性,其中MSE最大差值也仅为6.848。同时从表2中也可以看出,除了在2层网络的情况下,GCN计算结果略优于GCNII模型,在4、6、8、16层情况下,GCNII的三项指标均优于GCN模型,其中,在8层网络时GCNII模型取得了较好的效果,MSE、MAE较GCN模型分别降低了22.529、2.213,这说明在深层网络的情况下GCNII的计算精度明显优于GCN模型的。
表2 不同层的网络模型评估量化对比
Tab.2 Quantitative comparison of network model evaluation at different layers

参数GCN_2GCNII_2GCN_4GCNII_4GCN_6GCNII_6GCN_8GCNII_8GCN_16GCNII_16 MSE7.44111.26518.8185.56516.3464.49326.9464.41722.5945.214 MAE2.2142.7004.0721.9253.2611.7433.9721.7593.8541.885
为了进一步验证本文模型的优越性,将CNN和支持向量回归(Support Vector Regression, SVR)作为比较对象,对比分析各模型在无功储备需求计算上的性能差异。不同计算模型的计算结果如图11所示。
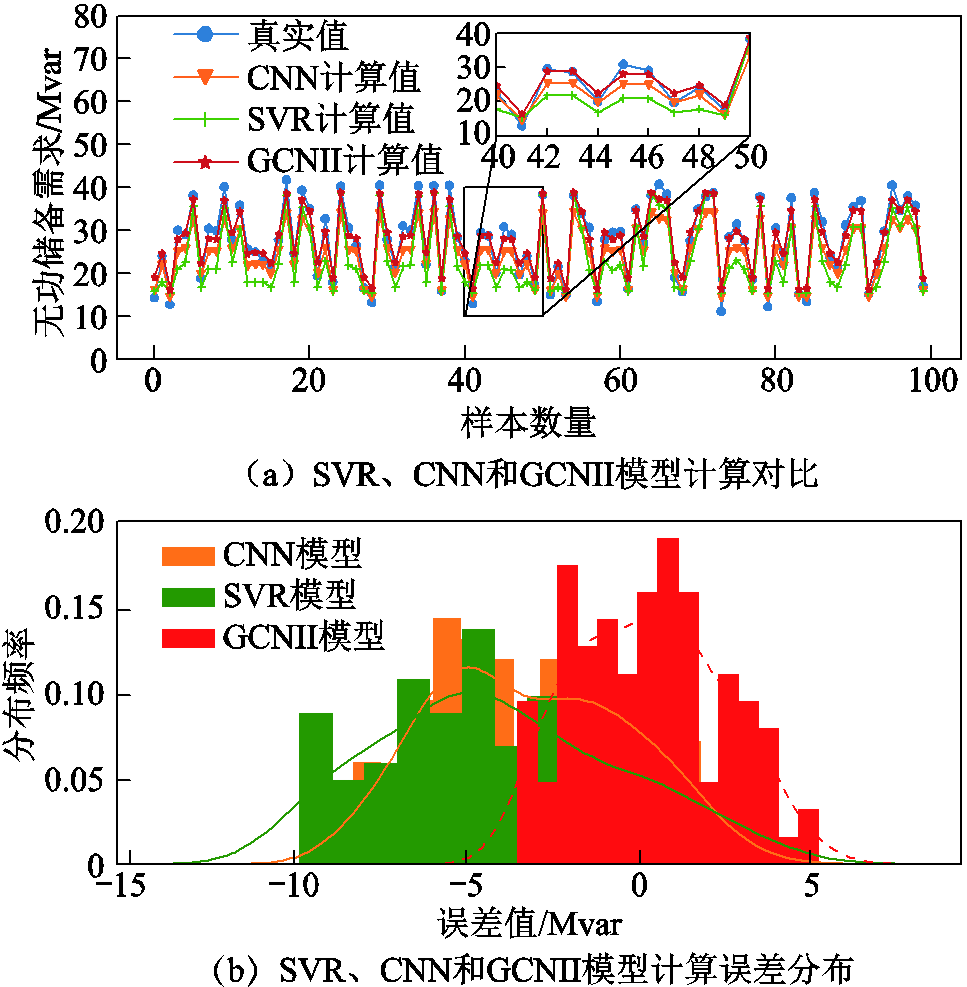
图11 不同计算模型的计算结果
Fig.11 Calculation results of different calculation models
图11a给出了不同网络模型计算结果的曲线图。从图中可以看出,总体上不同网络模型均能够较好地拟合真实值,但是从局部放大图中可以发现红色虚线更加接近真实值(即GCNII网络的计算结果更贴近真实值)。
图11b则从各模型计算结果的误差分布角度进行性能分析。从图中可以明显看出,SVR和CNN的误差分布均集中在-5附近,而GCNII模型误差分布则集中在0附近,说明了GCNII的计算结果更加贴近真实值。
通过三个量化评估指标进一步对模型性能进行分析,训练集与测试集的评价量化对比见表3。从表3中可以看出GCNII模型计算结果都显著低于SVR模型和CNN模型,且GCNII模型的MAE值较CNN、SVR模型分别降低了1.777、2.779,说明在无功储备需求计算任务上GCNII模型具有较好的计算精度,这与图11b的分析结果一致。
表3 不同计算模型的评估量化对比
Tab.3 Comparison of quantitative evaluation of different computational models

模型MSEMAE SVR28.3314.538 CNN17.6803.536 GCNII4.4171.759
4.5.1 样本削减方法有效性验证
为了验证所提样本削减方法能否有效提高模型训练效率,在IEEE 39节点系统上,分别采用GCN和GCNII进行40次迭代训练(均采用4层结构),对削减前后样本集合的计算结果和训练耗时进行对比分析(原始数据集规模为2 400,削减后数据集规模约为1 837,样本集规模缩小近23%)。
不同数据集上GCN模型评估量化对比见表4。从表4中可以看出,虽然采用削减样本集训练的模型精度略低于原始数样本集,但各指标间相差很小,其中MAE值仅改变了0.176,误差变化率约为5.05%。模型计算结果的误差分布情况如图12所示。从图12中可以看出,不同数据集训练的GCN模型计算结果均能够贴近真实数据,模型偏差值均集中分布在0~5之间,这也说明利用削减样本所训练的模型仍具有较好的拟合精度;在模型训练耗时方面,可以明显发现利用削减后的数据集训练模型仅需要耗费828.335 s,训练时间减少了近194s,训练效率提升了约19.0%。
表4 不同数据集上GCN模型评估量化对比
Tab.4 Quantitative comparison of GCN model evaluations on different data sets

样本MSEMAE训练时间/s 原始样本18.1883.4871 022.562 削减样本20.4763.663828.335
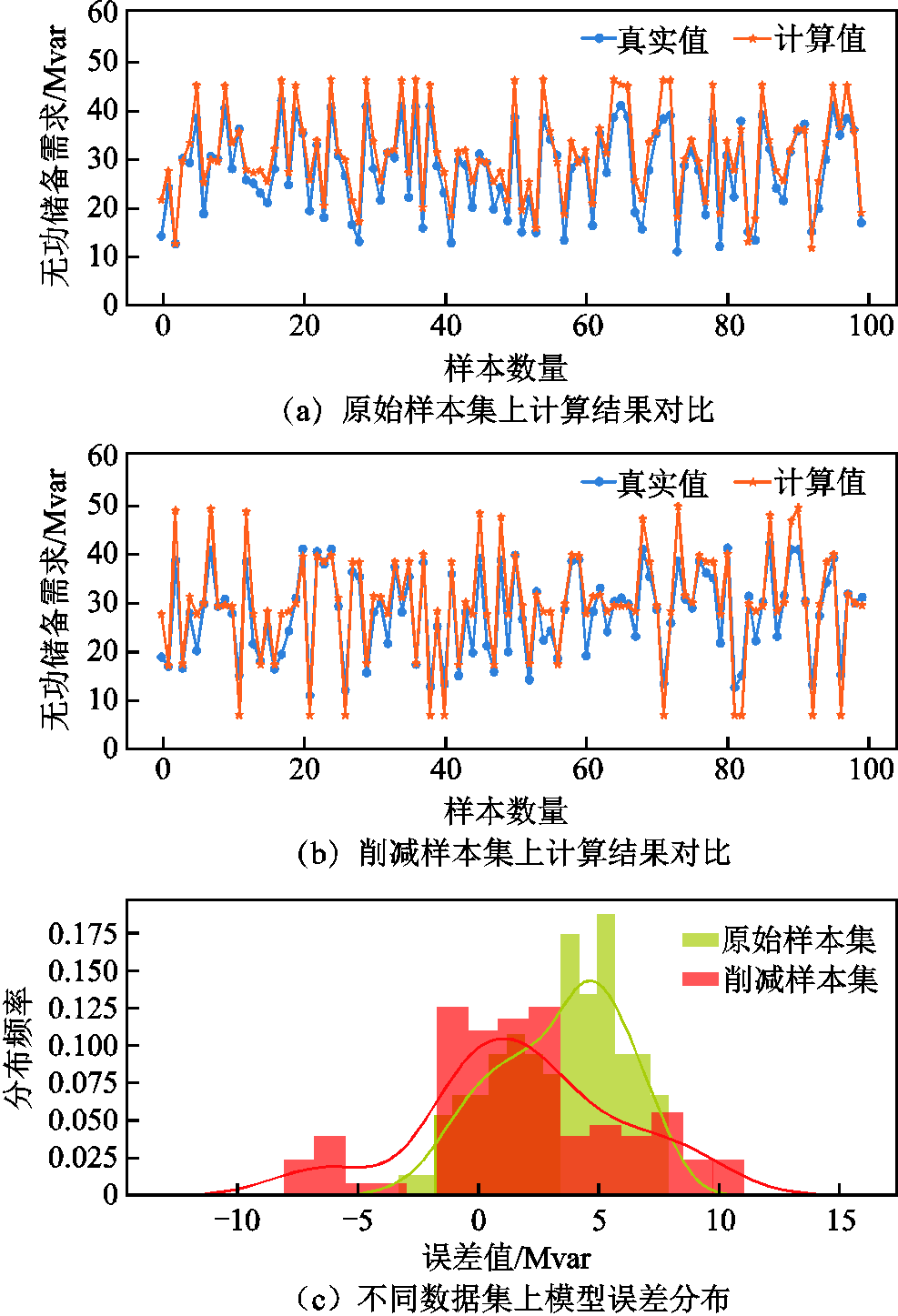
图12 不同数据集上GCN模型计算结果分析
Fig.12 Analysis of GCN model calculation results on different data sets
图13和表5分别给出了GCNII模型计算结果分布图和量化评估指标值,从误差分布情况可以看出,两种数据集训练的模型计算结果误差分布基本是重合的,均集中分布在2~3左右,这说明不同数据集训练的模型均能够较好的拟合真实值。
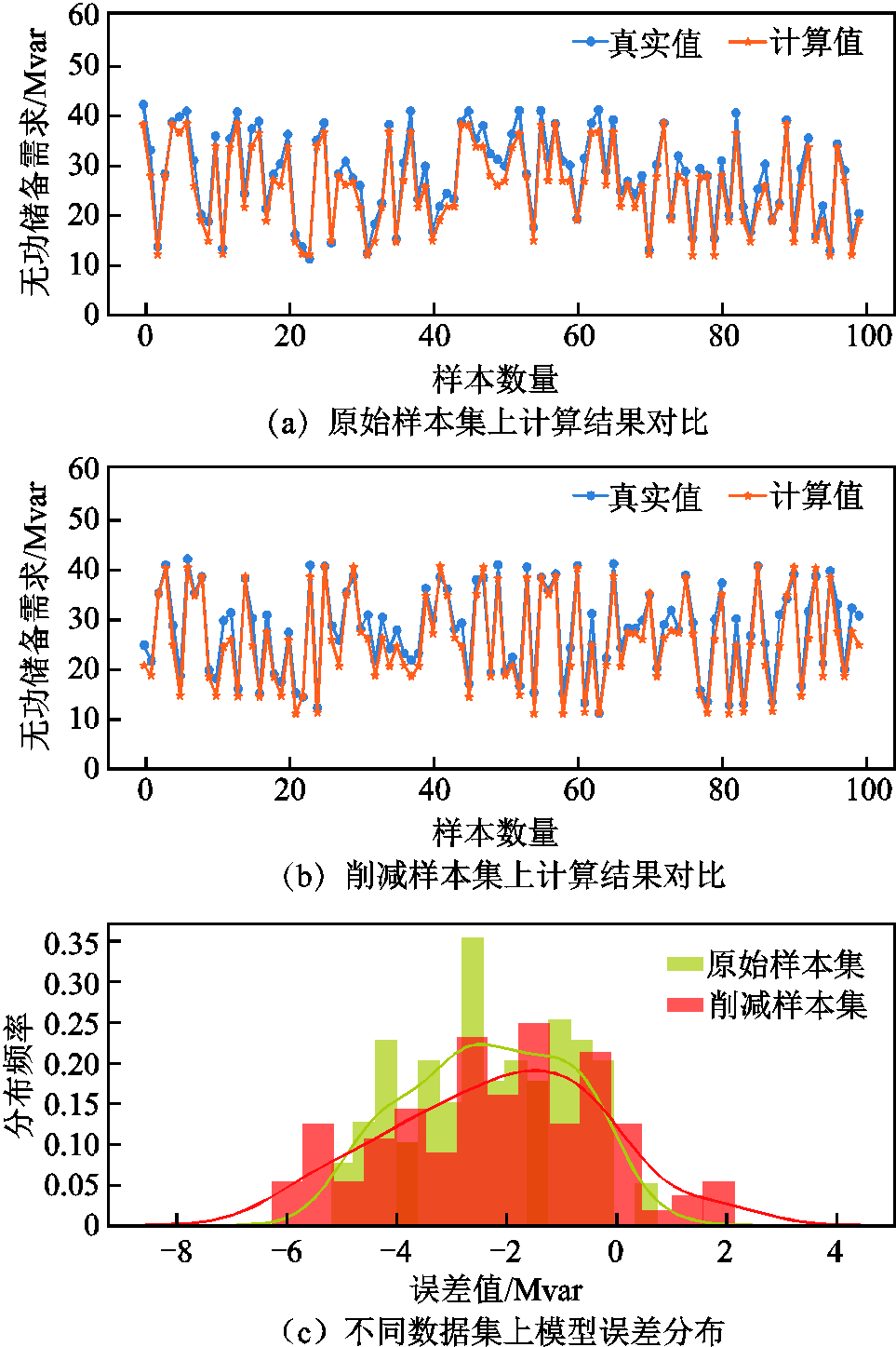
图13 不同数据集上GCNII模型计算结果分析
Fig.13 Analysis of GCNII model calculation results on different data sets
表5 不同数据集上GCNII模型评估量化对比
Tab.5 Quantitative comparison of GCNII model evaluations on different data sets

样本MSEMAE训练时间/s 原始样本7.3132.3121031.894 削减样本8.2972.365830.661
从模型计算结果误差指标上看,削减样本集所训练模型MAE值相比原始集合增加了0.053,误差变化率仅为2.29%,这说明了优化样本集所训练模型仍然能够较好的拟合真实值;从模型训练效率角度来看,样本削减后模型的训练耗时仅为830.661 s,与采用原始数据集合的模型训练耗时相比,训练时间减少了近201 s,效率提升了约19.5%。
分析削减前后的样本集对GCN和GCNII模型的影响,可以发现采用削减样本集均能使不同模型的训练耗时大幅降低15%以上,且各模型计算结果的MAE变化均控制在5%以内,这说明本文所使用的样本削减策略能够适应不同图深度学习模型的,且能在保证模型计算精度近似不变的情况下,实现训练效率的大幅提升。
通过不同训练集的测试,可以发现无论采用哪种集合进行模型训练,GCNII的计算结果都是最贴近真实值,这也进一步验证GCNII模型的优势。
同时为验证原始样本集合规模变化对削减策略的影响,在IEEE 39节点系统上重新生成5 000组数据构成原始样本集,经过削减后,样本集规模约为2 561,样本集规模减小了近48%,在40次迭代后记录计算结果。表6给出了GCNII模型在不同数据集上的计算结果和训练耗时情况。从表6中可以明显看出,模型的各项误差指标相差较小,其中MAE值仅相差0.022,误差变化率约为1.39%,从模型训练耗时角度看,利用削减后样本训练模型的耗时相较原始数据减少了约827 s,训练速率加快了约35.4%。
表6 39节点系统上GCNII模型评估量化对比
Tab.6 Quantitative comparison of GCNII model evaluation on 39 node system

样本MSEMAE训练时间/s 原始样本5.6631.5782 336.864 削减样本5.9821.6001 509.196
综合上述在不同规模原始数据集上的仿真结果可以直观地看出,随着原始样本集规模的增加,削减策略对模型训练耗时的影响更加显著,如在原始样本规模为2 400的情况下,经过对样本集合的削减,模型训练耗时减少了约19.5%,而在原始样本规模为5 000的情况下,通过对样本集合的削减,模型训练耗时减少了约35.4%,说明数据集规模的增加会导致冗余样本的数量出现较大的涨幅,此时利用本文提出的削减方法能够更加有效地降低数据集的规模,进一步减少模型训练耗时。
4.5.2 不同规模节点系统上削减策略适应性分析
为了验证本文所提方法的普适性,除IEEE 39节点外,在IEEE 57和IEEE 118节点系统上也进行了仿真计算。采用相同的样本生成策略,获得规模为3 800的原始训练样本集,削减后训练样本规模约为2 816,样本集规模缩小近26%,40次迭代后,GCNII模型计算结果如图14所示。
从图14中可以看出,两种训练集得到的模型均能够较好地拟合数据,从误差分布情况上看,不同训练集下模型计算结果的偏差均集中在0附近,且整体误差分布几乎重合。模型计算结果量化评估指标见表7。从表7中可以看出模型的各项误差指标相差不大,其中MAE值仅相差0.074,误差变化率约为3.42%。在模型训练耗时方面,利用削减后样本训练模型的耗时相较原始数据减少了约529 s,效率提升了约23.1%。
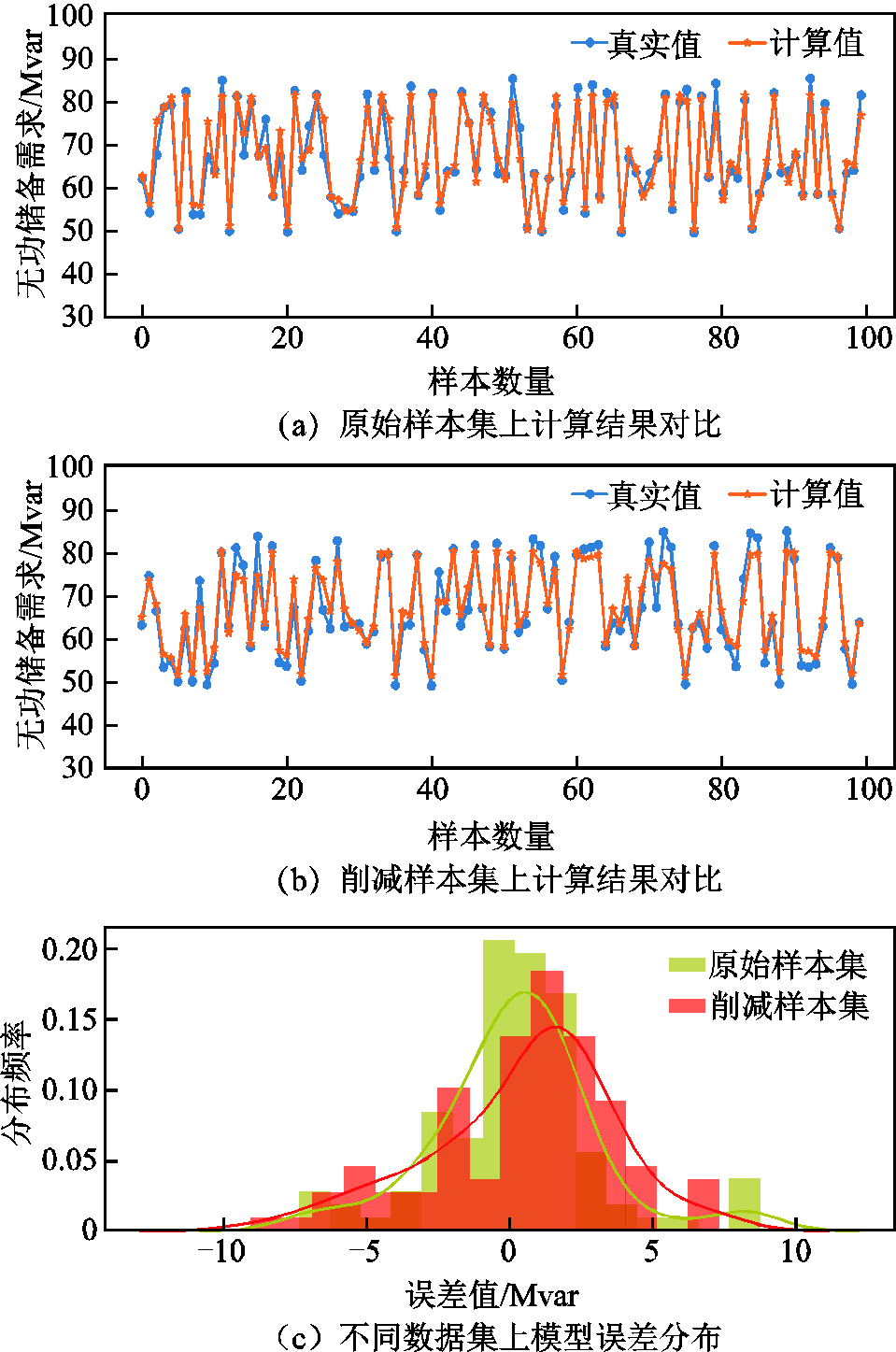
图14 57节点系统上计算结果分析
Fig.14 Analysis of calculation results on 57 nodes
表7 57节点系统上GCNII模型评估量化对比
Tab.7 Quantitative comparison of GCNII model evaluation on 57 node system

样本MSEMAE训练时间/s 原始样本8.5262.1632 295.717 削减样本9.2482.2371 766.500
118节点上模型计算结果误差分布如图15所示。从图15中可以看出两种训练集下的模型均能够较好地拟合数据,且模型计算偏差均集中分布在0附近。模型计算结果量化评估指标见表8。从表8中能更加直观地看出,模型的各项误差指标相差较小,其中MAE值仅相差0.118,误差变化率约为5.01%,说明采用削减后样本集训练的模型仍然具有较好的计算精度。在模型训练耗时方面,利用削减后样本训练模型的耗时相较原始数据减少了约652s,效率提升了约23.6%。
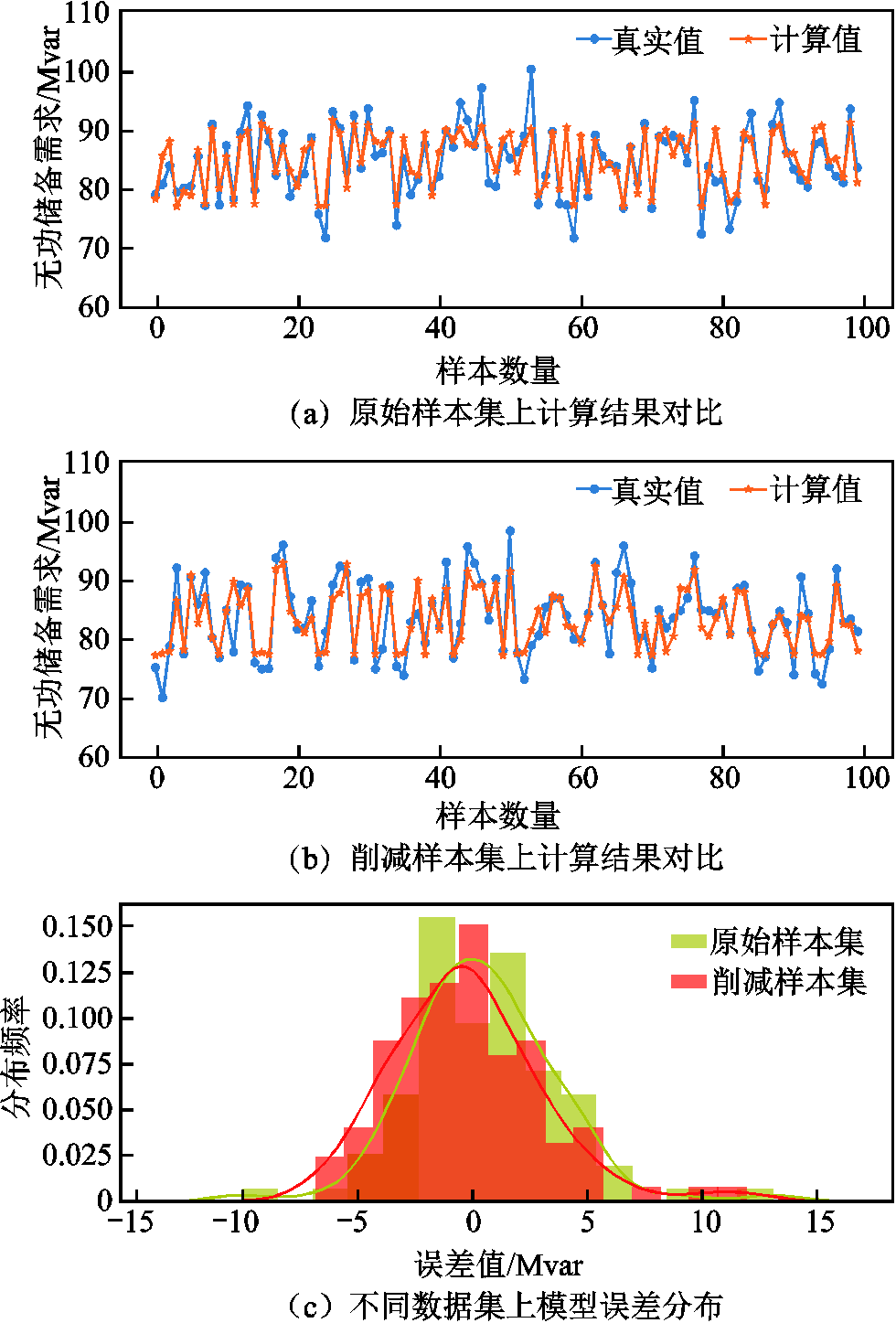
图15 118节点系统上计算结果分析
Fig.15 Analysis of calculation results on 118 nodes
表8 118节点系统上GCNII模型评估量化对比
Tab.8 Quantitative comparison of GCNII model evaluation on 118 node system

样本MSEMAE训练时间/s 原始样本9.9472.3542 767.383 削减样本10.6462.4722 114.886
通过对不同节点规模系统上的仿真结果进行分析,可以明显看出,在IEEE 57、IEEE 118节点系统上利用削减后样本集进行模型训练的耗时分别减少了约592 s、652 s,相较于利用原始数据集进行模型训练,训练效率分别提升了约23.1%、23.6%。从模型计算误差角度分析,可以看出在不同节点系统上,采用原始样本集和削减样本集所训练模型的计算结果对应MAE的差值分别为0.074、0.118,均控制在一个较小的范围内,说明了样本削减策略对不同节点规模系统具有良好的适应性,均能够通过对样本集中冗余数据的削减,实现在保证模型计算精度的情况下,有效降低了模型的训练耗时,进一步加快了电网无功储备需求的计算速度。
本文提出一种基于深度学习模型的电网无功储备需求快速计算框架,将样本削减策略与深度学习技术相结合,实现了电网无功储备需求的快速计算,主要结论如下:
1)本文提出基于残差图卷积神经网络的电网无功储备需求快速计算框架,实现无功储备需求的在线计算。GCNII模型相比传统机器学习模型具有更高的计算精度,其平均绝对误差(MAE)较CNN、SVR模型分别降低了1.777、2.779,表明该模型在无功储备需求计算任务中优势明显。
2)本文提出了基于双尺度相似性度量的冗余样本削减策略。仿真结果表明,采用该策略可使模型训练效率提高15%以上,且计算结果的MAE低于5%,能实现在确保模型计算精度基本不变的情况下,大幅提高模型训练效率。
3)通过设置不同规模的原始样本数据集进行仿真计算分析,发现随着初始样本规模的变大,模型的训练效率得到显著提升,这说明提出的样本削减策略在大样本集合中的优势更明显。在不同节点规模系统的仿真结果表明,本文提出的方法能够有效地提高不同节点规模的模型训练效率,表明所提方法具有较好的普适性。
本文将深度学习技术应用于电网无功储备需求计算,并就拓扑样本的相似性比对和削减方法进行了初步探索。后续将就电网运行状态变化对模型拟合精度的影响进行深入研究,进一步增强模型在复杂运行方式下的拟合精度。
参考文献
[1] 吴浩, 郭瑞鹏, 甘德强, 等. 发电机有效无功储备的分析和计算[J]. 电力系统自动化, 2011, 35(15): 13-17, 39.
Wu Hao, Guo Ruipeng, Gan Deqiang, et al. Analysis and computation of effective reactive power reserve of generators[J]. Automation of Electric Power Systems, 2011, 35(15): 13-17, 39.
[2] 赵晋泉, 居俐洁, 罗卫华, 等. 计及分区动态无功储备的无功电压控制模型与方法[J]. 电力自动化设备, 2015, 35(5): 100-105.
Zhao Jinquan, Ju Lijie, Luo Weihua, et al. Reactive voltage control model and method considering partitioned dynamic reactive power reserve[J]. Electric Power Automation Equipment, 2015, 35(5): 100-105.
[3] 亢丽君, 王蓓蓓, 薛必克, 等. 计及爬坡场景覆盖的高比例新能源电网平衡策略研究[J]. 电工技术学报, 2022, 37(13): 3275-3288.
Kang Lijun, Wang Beibei, Xue Bike, et al. Research on the balance strategy for power grid with high proportion renewable energy considering the ramping scenario coverage[J]. Transactions of China Electrotechnical Society, 2022, 37(13): 3275-3288.
[4] 柯德平, 冯帅帅, 刘福锁, 等. 新能源发电调控参与的送端电网直流闭锁紧急频率控制策略快速优化[J]. 电工技术学报, 2022, 37(5): 1204-1218.
Ke Deping, Feng Shuaishuai, Liu Fusuo, et al. Rapid optimization for emergent frequency control strategy with the power regulation of renewable energy during the loss of DC connection[J]. Transactions of China Electrotechnical Society, 2022, 37(5): 1204-1218.
[5] 齐子杰, 陈天华, 王彬, 等. 基于多阶轨迹灵敏度的交直流混联受端电网无功储备优化方法[J]. 电力科学与技术学报, 2022, 37(1): 74-81.
Qi Zijie, Chen Tianhua, Wang Bin, et al. Reactive power reserve optimization method for AC/DC hybrid receiving network based on multi-order trajectory sensitivity[J]. Journal of Electric Power Science and Technology, 2022, 37(1): 74-81.
[6] 陈光宇, 吴文龙, 戴则梅, 等. 计及故障场景集的风光储混合系统区域无功储备多目标优化[J]. 电力系统自动化, 2022, 46(17): 194-204
Chen Guangyu, Wu Wenlong, Dai Zemei, et al. Multi-objective optimization of regional reactive power reserve in hybrid system with wind/photovoltaic/ energy storage considering fault scenario set[J]. Automation of Electric Power Systems, 2022, 46(17): 194-204
[7] Leonardi B, Ajjarapu V. An approach for real time voltage stability margin control via reactive power reserve sensitivities[J]. IEEE Transactions on Power Systems, 2013, 28(2): 615-625.
[8] 熊虎岗, 程浩忠, 徐敬友. 考虑提高系统无功备用容量的无功优化调度[J]. 电网技术, 2006, 30(23): 36-40.
Xiong Hugang, Cheng Haozhong, Xu Jingyou. Optimal dispatch of reactive power considering increase of system reactive power reserve[J]. Power System Technology, 2006, 30(23): 36-40.
[9] 苗长新, 李昊, 王霞, 等. 基于数据驱动和深度学习的超短期风电功率预测[J]. 电力系统自动化, 2021, 45(14): 22-29.
Miao Changxin, Li Hao, Wang Xia, et al. Data-driven and deep-learning-based ultra-short-term wind power prediction[J]. Automation of Electric Power Systems, 2021, 45(14): 22-29.
[10] 姚程文, 杨苹, 刘泽健. 基于CNN-GRU混合神经网络的负荷预测方法[J]. 电网技术, 2020, 44(9): 3416-3424.
Yao Chengwen, Yang Ping, Liu Zejian. Load forecasting method based on CNN-GRU hybrid neural network[J]. Power System Technology, 2020, 44(9): 3416-3424.
[11] 罗澍忻, 麻敏华, 蒋林, 等. 考虑多时间尺度数据的中长期负荷预测方法[J]. 中国电机工程学报, 2020, 40(增刊1): 11-19.
Luo Shuxin, Ma Minhua, Jiang Lin, et al. Medium and long-term load forecasting method considering multi-time scale data[J]. Proceedings of the CSEE, 2020, 40(S1): 11-19.
[12] 刘亚珲, 赵倩. 基于聚类经验模态分解的CNN-LSTM超短期电力负荷预测[J]. 电网技术, 2021, 45(11): 4444-4451.
Liu Yahui, Zhao Qian. Ultra-short-term power load forecasting based on cluster empirical mode decomposition of CNN-LSTM[J]. Power System Technology, 2021, 45(11): 4444-4451.
[13] 杨东升, 吉明佳, 周博文, 等. 基于双生成器生成对抗网络的电力系统暂态稳定评估方法[J]. 电网技术, 2021, 45(8): 2934-2945.
Yang Dongsheng, Ji Mingjia, Zhou Bowen, et al. Transient stability assessment of power system based on DGL-GAN[J]. Power System Technology, 2021, 45(8): 2934-2945.
[14] Wu Zonghan, Pan Shirui, Chen Fengwen, et al. A comprehensive survey on graph neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24.
[15] Bruna J, Zaremba W, Szlam A, et al. Spectral networks and locally connected networks on graphs[EB/OL]. 2013, arXiv: 1312.6203. https://arxiv. org/abs/1312.6203.
[16] Zhao Ling, Song Yujiao, Zhang Chao, et al. T-GCN: a temporal graph convolutional network for traffic prediction[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(9): 3848-3858.
[17] Cui Zhiyong, Henrickson K, Ke Ruimin, et al. Traffic graph convolutional recurrent neural network: a deep learning framework for network-scale traffic learning and forecasting[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(11): 4883-4894.
[18] Liu Yabo, Liu Yi, Yang Cheng. Modulation recognition with graph convolutional network[J]. IEEE Wireless Communications Letters, 2020, 9(5): 624-627.
[19] Ding Yun, Guo Yuanyuan, Chong Yanwen, et al. Global consistent graph convolutional network for hyperspectral image classification[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 1-16.
[20] Song Tengfei, Zheng Wenming, Song Peng, et al. EEG emotion recognition using dynamical graph convolutional neural networks[J]. IEEE Transactions on Affective Computing, 2020, 11(3): 532-541.
[21] 王铮澄, 周艳真, 郭庆来, 等. 考虑电力系统拓扑变化的消息传递图神经网络暂态稳定评估[J]. 中国电机工程学报, 2021, 41(7): 2341-2350.
Wang Zhengcheng, Zhou Yanzhen, Guo Qinglai, et al. Transient stability assessment of power system considering topological change: a message passing neural network-based approach[J]. Proceedings of the CSEE, 2021, 41(7): 2341-2350.
[22] 李佳玮, 王小君, 和敬涵, 等. 基于图注意力网络的配电网故障定位方法[J]. 电网技术, 2021, 45(6): 2113-2121.
Li Jiawei, Wang Xiaojun, He Jinghan, et al. Distribution network fault location based on graph attention network[J]. Power System Technology, 2021, 45(6): 2113-2121.
[23] 王渝红, 沈靖, 曾琦, 等. 基于谱图论和图卷积神经网络的直流电网节点电压估计研究[J]. 电网技术, 2022, 46(2): 521-532.
Wang Yuhong, Shen Jing, Zeng Qi, et al. Voltage estimation for DC grid nodes based on spectral theory and graph convolutional neural network[J]. Power System Technology, 2022, 46(2): 521-532.
[24] 陈光宇, 孙叶舟, 江海洋, 等. 基于DIndRNN-RVM深度融合模型的AGC指令执行效果精准辨识及置信评估研究[J]. 中国电机工程学报, 2022, 42(5): 1852-1867.
Chen Guangyu, Sun Yezhou, Jiang Haiyang, et al. Research on accurate identification and confidence evaluation of AGC command execution effect based on DIndRNN-RVM deep fusion model[J]. Proceedings of the CSEE, 2022, 42(5): 1852-1867.
[25] Jahangir H, Tayarani H, Baghali S, et al. A novel electricity price forecasting approach based on dimension reduction strategy and rough artificial neural networks[J]. IEEE Transactions on Industrial Informatics, 2020, 16(4): 2369-2381.
[26] 郑吉祥, 钟俊. 基于节点类型和分区耦合性的复杂网络无功电压快速分区方法[J]. 电网技术, 2020, 44(1): 223-230.
Zheng Jixiang, Zhong Jun. A complex network theory fast partition algorithm of reactive voltage based on node type and coupling of partitions[J]. Power System Technology, 2020, 44(1): 223-230.
[27] 张怡, 张恒旭, 李常刚, 等. 深度学习在电力系统频率分析与控制中的应用综述[J]. 中国电机工程学报, 2021, 41(10): 3392-3406, 3665.
Zhang Yi, Zhang Hengxu, Li Changgang, et al. Review on deep learning applications in power system frequency analysis and control[J]. Proceedings of the CSEE, 2021, 41(10): 3392-3406, 3665.
[28] 徐冰冰, 岑科廷, 黄俊杰, 等. 图卷积神经网络综述[J]. 计算机学报, 2020, 43(5): 755-780.
Xu Bingbing, Cen Keting, Huang Junjie, et al. A survey on graph convolutional neural network[J]. Chinese Journal of Computers, 2020, 43(5): 755-780.
[29] Mou Lichao, Lu Xiaoqiang, Li Xuelong, et al. Nonlocal graph convolutional networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(12): 8246-8257.
[30] David K, Hammond A,Pierre Vandergheynst B,et al. Wavelets on graphs via spectral graph theory[J]. Applied and Computational Harmonic Analysis, 2011, 30(2): 129-150.
[31] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[C]//ICLR, 2016, abs/1609.02907.
[32] 张翼, 朱永利. 图信号与图卷积网络相结合的局部放电模式识别方法[J]. 中国电机工程学报, 2021, 41(18): 6472-6481.
Zhang Yi, Zhu Yongli. A partial discharge pattern recognition method combining graph signal and graph convolutional network[J]. Proceedings of the CSEE, 2021, 41(18): 6472-6481.
[33] Chen Ming, Wei Zhewei, Huang Zengfeng, et al. Simple and deep graph convolutional networks[EB/ OL]. 2020, arXiv: 2007.02133. https://arxiv.org/abs/ 2007.02133.
[34] 徐胜蓝, 司曹明哲, 万灿, 等. 考虑双尺度相似性的负荷曲线集成谱聚类算法[J]. 电力系统自动化, 2020, 44(22): 152-160.
Xu Shenglan, Si Caomingzhe, Wan Can, et al. Ensemble spectral clustering algorithm for load profiles considering dual-scale similarities[J]. Automation of Electric Power Systems, 2020, 44(22): 152-160.
[35] 林君豪, 张焰, 赵腾, 等. 基于改进卷积神经网络拓扑特征挖掘的配电网结构坚强性评估方法[J]. 中国电机工程学报, 2019, 39(1): 84-96, 323.
Lin Junhao, Zhang Yan, Zhao Teng, et al. Structure strength assessment method of distribution network based on improved convolution neural network and network topology feature mining[J]. Proceedings of the CSEE, 2019, 39(1): 84-96, 323.
[36] 姜雅男, 于永进, 李长云. 基于改进TOPSIS模型的绝缘纸机-热老化状态评估方法[J]. 电工技术学报, 2022, 37(6): 1572-1582.
Jiang Yanan, Yu Yongjin, Li Changyun. Thermal aging state evaluation method of insulated paper machine based on improved TOPSIS model [J]. Transactions of China Electrotechnical Society, 2022, 37(6): 1572-1582.
[37] 林顺富, 田二伟, 符杨, 等. 基于信息熵分段聚合近似和谱聚类的负荷分类方法[J]. 中国电机工程学报, 2017, 37(8): 2242-2253.
Lin Shunfu, Tian Erwei, Fu Yang, et al. Power load classification method based on information entropy piecewise aggregate approximation and spectral clustering[J]. Proceedings of the CSEE, 2017, 37(8): 2242-2253.
[38] 王卓, 王玉静, 王庆岩, 等. 基于协同深度学习的二阶段绝缘子故障检测方法[J]. 电工技术学报, 2021, 36(17): 3594-3604.
Wang Zhuo, Wang Yujing, Wang Qingyan, et al. Two stage insulator fault detection method based on collaborative deep learning[J]. Transactions of China Electrotechnical Society, 2021, 36(17): 3594-3604.
[39] 陈立帆, 张琳琳, 宋辉, 等. 基于图卷积神经网络的输电线路自然灾害事故预测[J/OL]. 电网技术, 2022, DOI: 10.13335/j.1000-3673.pst.2021.2520.
Chen Lifan, Zhang Linlin, Song Hui, et al. Natural disaster accident prediction of transmission line based on graph convolution network[J/OL]. Power System Technology, 2022, DOI: 10.13335/j.1000-3673.pst. 2021.2520.
[40] Oono K, Suzuki T. Graph neural networks exponentially lose expressive power for node classification[EB/OL]. 2019, arXiv: 1905.10947. https://arxiv.org/abs/1905.10947.
Abstract Reactive power reserve plays a crucial role in maintaining voltage stability of power grid. Considering that the uncertainty of new energy output shortens the analysis period of reactive power reserve demand and gradually changes from offline calculation to online evaluation, traditional reactive power reserve demand analysis methods have the problems of high computational complexity and long time consumption. As a result, the calculation of reactive power reserve requirements cannot meet the requirements of online evaluation. To solve these problems, this paper proposes a fast calculation method of grid reactive power reserve demand based on residual graph convolution deep network considering redundant sample reduction. The sample reduction technology and deep learning technology are effectively combined to realize the fast calculation of grid reactive power reserve demand.
Firstly, a fast grid reactive power reserve calculation framework based on deep learning is proposed, and residual graph convolutional neural network (GCNII) is used to model the grid reactive power reserve demand calculation. Secondly, aiming at the limitation of traditional similarity calculation methods in topological attribute sample measurement, a two-scale similarity measurement method was constructed based on feature similarity measure and topological similarity measure. Thirdly, the improved spectral clustering algorithm and densitometric analysis method are combined to deeply mine the redundant data with high similarity and dense distribution in the sample set, and the redundant data are reduced, so as to greatly improve the model training efficiency while ensuring the accuracy of model calculation. Finally, the reduced data sets are used to train and test the deep learning model, and the reactive power reserve requirements of the power grid are rapidly calculated..
The simulation results on IEEE standard system show that the calculation results of the model on the training set and the test set are close to the target value, indicating that the residual graph convolution model has strong generalization ability. Secondly, by comparing the GCNII model with the GCN model at different depths, it can be found that the deep GCNII model has better calculation accuracy, which verifies that the GCNII model can effectively solve the excessive smoothing problem of the GCN model. Finally, the sample reduction strategy is used to effectively process the dataset, and the sample sets before and after the reduction are used to train and calculate the model respectively. It is verified that the sample reduction strategy can greatly improve the model training efficiency while ensuring the model calculation accuracy.
The following conclusions can be drawn from the simulation analysis: (1) Compared with the traditional machine learning model, the GCNII model has higher calculation accuracy, and its mean absolute error (MAE) is 1.777 and 2.779 lower than CNN and SVR models, respectively, indicating that the GCNII model has obvious advantages in reactive power reserve requirement calculation task. (2) The sample reduction strategy can improve the model training efficiency by more than 15%, and the mean absolute error (MAE) of the calculation results is less than 5%, which can greatly improve the model training efficiency while keeping the model calculation accuracy basically unchanged. (3) The simulation results in different node size systems show that the proposed method can effectively improve the model training efficiency of different node sizes, indicating that the proposed method has good universality.
keywords: Residual graph convolutional neural network, reactive power reserve demand calculation, sample reduction strategy, matrix singular value sequence, two scale similarity
中图分类号:TM734
DOI:10.19595/j.cnki.1000-6753.tces.221019
智能电网保护和运行控制国家重点实验室资助(SGNR0000KJJS2302148)。
收稿日期 2022-06-02
改稿日期 2022-09-06
陈光宇 男,1980年生,博士,副教授,硕士生导师,研究方向为电力系统运行与控制,优化调度,人工智能等。E-mail:cgyhhu@163.com(通信作者)
袁文辉 男,1997年生,硕士研究生,研究方向为电力系统运行控制,人工智能。E-mail:1272698676@qq.com
(编辑 赫蕾)