 阈值仅考虑误判率的弊端,提出
阈值仅考虑误判率的弊端,提出 阈值计算方法,综合考虑误判率和漏判率对异常数据辨识的影响,可判断出同期线损数据集合中是否存在异常数据;在此基础上,建立同期线损异常数据辨识模型,进一步判断异常数据的位置;最后以甘肃实际运行数据为例进行仿真,验证该文所提异常数据辨识方法的有效性。
阈值计算方法,综合考虑误判率和漏判率对异常数据辨识的影响,可判断出同期线损数据集合中是否存在异常数据;在此基础上,建立同期线损异常数据辨识模型,进一步判断异常数据的位置;最后以甘肃实际运行数据为例进行仿真,验证该文所提异常数据辨识方法的有效性。摘要 针对目前同期线损系统接入数据海量,异常数据难以辨识的问题,提出了基于“秩和”近似相等特性的同期线损异常数据辨识方法。首先引入“秩和”差异理论,分析无异常数据情况下,同期线损与理论线损差异电量的“秩和”近似相等特性;然后分析存在异常数据时的“秩和”差异特征。基于此,改进传统阈值仅考虑误判率的弊端,提出阈值计算方法,综合考虑误判率和漏判率对异常数据辨识的影响,可判断出同期线损数据集合中是否存在异常数据;在此基础上,建立同期线损异常数据辨识模型,进一步判断异常数据的位置;最后以甘肃实际运行数据为例进行仿真,验证该文所提异常数据辨识方法的有效性。
关键词:同期线损 异常数据辨识 “秩和”近似相等特性 阈值
近些年,国家电网公司大力推行一体化电量与线损管理系统(同期线损系统)建设[1-2],致力于提高电网公司线损管理水平。然而,实际运行发现,同期线损值较理论线损基值差异较大,究其原因,主要是由于供售统计不同期以及存在异常数据引起的[3]。针对前者,文献[4]提出基于功率或电量预测的同期化方法,已取得较好的同期化效果。但由于同期线损系统的数据主要来自于六大业务系统(包括PMS2.0、调度OMS/SCADA系统、营销业务应用系统、电能量信息采集系统、用电信息采集系统、电网GIS系统)融合的海量数据平台,具体数据来源难以考证;且在数据采集、数据传输环节中均存在数据丢失、错误等情况,故有效辨识同期线损中的异常数据十分困难[5-6],严重影响线损指标考核达标率,不利于线损管理。因此,同期线损系统异常数据辨识对于线损指标考核以及优化电网经济运行具有重要意义。
目前针对异常数据辨识已有一定研究,但多集中于电力系统运行状态数据或负荷数据的异常辨识。在电力系统状态异常数据辨识方面,文献[7]提出一种基于低秩模型的电力数据异常辨识算法,将系统观测数据分解为低秩部分和稀疏部分,用低秩部分表达无异常的观测,用稀疏部分表达异常数据。文献[8-9]系统地介绍了电力系统状态估计中异常数据的潮流追踪法、残差辨识方法等。随着新能源的接入,文献[10]分析了风机异常状态数据辨识。在负荷异常数据辨识方面,文献[11]从母线数据本身出发,首先分析了母线数据的低秩特性,然后建立了一种基于低秩矩阵分解的母线坏数据辨识与修复的模型,并给出了基于阈值迭代法(Iterative Thresholding, IT)的模型求解方法,可有效辨识并修复母线负荷坏数据。文献[12]提出基于改进模糊C均值(Fuzzy C-Means, FCM)聚类算法的不良负荷数据辨识及修复方法,可提高负荷异常数据的辨识效率。然而上述方法均是针对电力系统具体应用场景提出的异常数据辨识方法,将其直接运用至同期线损系统异常数据辨识时,辨识效果不佳,误判率和漏判率均较高。
随着理论线损快速计算方法的发展,通过理论线损与同期线损对比分析进行异常数据辨识成为可能。文献[13-14]基于实时负荷情况,将原网络分解为若干个等效网络,提高理论线损计算速度。文献[15]采用改进最近邻聚类方法对相似运行断面进行聚类,可快速计算理论线损值。文献[16-17]引入粒子群算法和支持向量机等智能算法,也大大地提高了理论线损计算速度。
在此基础上,本文研究发现,同期线损与理论线损差值序列具有“秩和”近似相等特性,当同期系统中存在异常数据,可利用上述“秩和”近似相等特性进行异常数据辨识,误判率和漏判率均显著得到降低,辨识效果较好。
理论线损与同期线损的差异对比需要大量历史线损数据,但理论线损计算得到的是线损功率数据,同期线损得到的是线损电量数据,在进行差异数据分析时,需要转换为同一量纲。以15min时间尺度进行理论线损计算,有
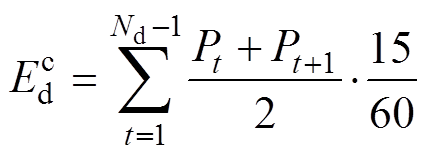 (1)
(1)式中, 为同期日线损电量;
为同期日线损电量;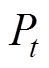 为时刻t的理论线损功率;
为时刻t的理论线损功率;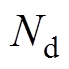 为差异对比的时间间隔,对于日线损,
为差异对比的时间间隔,对于日线损,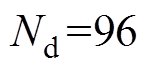 。
。
直接运用转换得到的数据序列进行对比辨识,在正常无异常的情况下也存在较大的转换误差,见表1。
表1 数据转换误差
Tab.1 Data conversion error
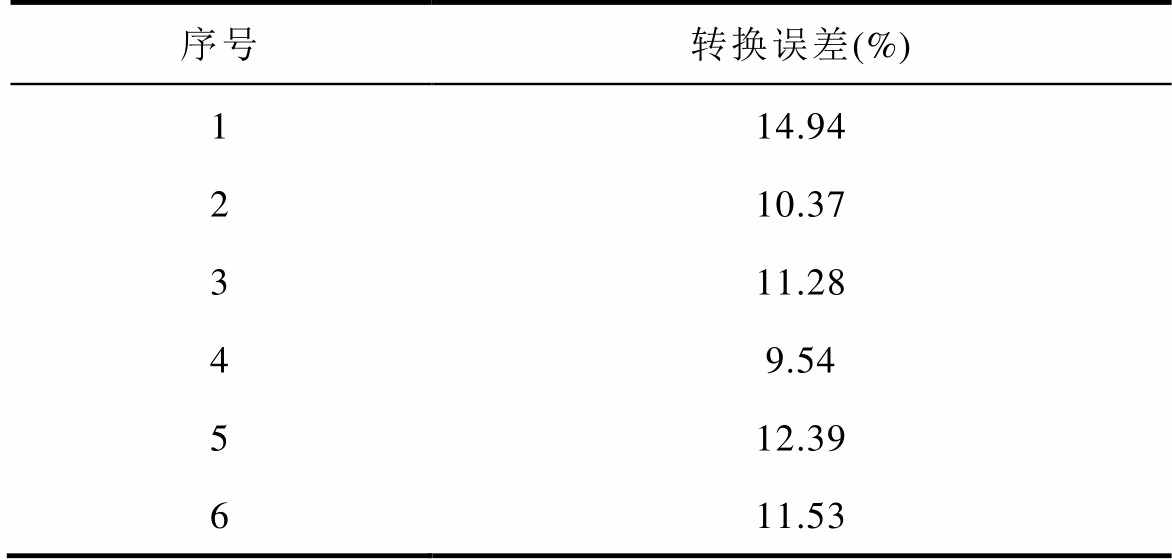
序号转换误差(%) 114.94 210.37 311.28 49.54 512.39 611.53
由表1可知,转换误差最小为9.54%,说明正常无异常数据情况下,同期线损与理论线损的差异也较大,不利于异常数据的辨识。本文引入“秩和”差异理论,通过对同期线损与理论线损电量差异序列编秩,可降低数据转换对辨识结果的影响。
在进行“秩和”特性分析之前,先介绍“秩和”的概念。
秩:设Y为一总体,将一容量为n的样本观察值按自小到大的次序编号排列为
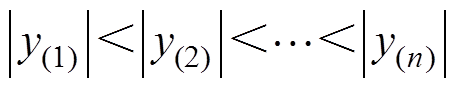 (2)
(2)式中,称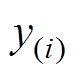 的足标i为的秩,
的足标i为的秩,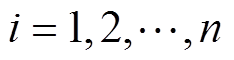 ,若为负,则秩也冠以负号。
,若为负,则秩也冠以负号。
根据秩的定义,的秩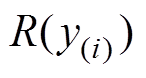 可表示为
可表示为
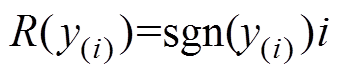 (3)
(3)式中,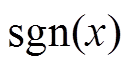 为符号函数,其计算公式为
为符号函数,其计算公式为
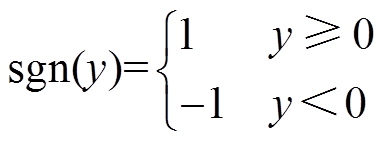 (4)
(4)
现设从理论线损数据集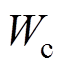 和同期线损数据集
和同期线损数据集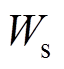 中分别抽取容量均为n的样本,形成集合。
中分别抽取容量均为n的样本,形成集合。
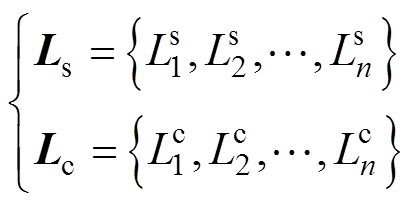 (5)
(5)不妨设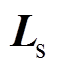 与
与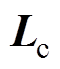 中元素差值的平均值为
中元素差值的平均值为 ,令
,令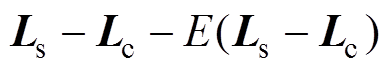 ,得到差异序列集合为
,得到差异序列集合为
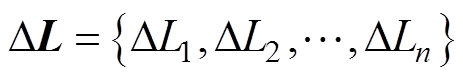 (6)
(6)
则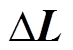 中的元素应均匀、随机地分布在0的邻域内。对中的元素按绝对值从小到大排序,得到新的编号,不妨设
中的元素应均匀、随机地分布在0的邻域内。对中的元素按绝对值从小到大排序,得到新的编号,不妨设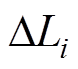 对应的新编号为
对应的新编号为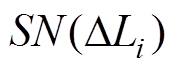 ,则 秩为
,则 秩为
 (7)
(7)根据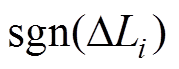 的正负,将各元素的秩
的正负,将各元素的秩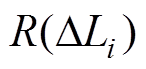 划分为正秩集合
划分为正秩集合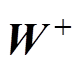 和负秩集合
和负秩集合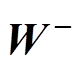 ,有
,有
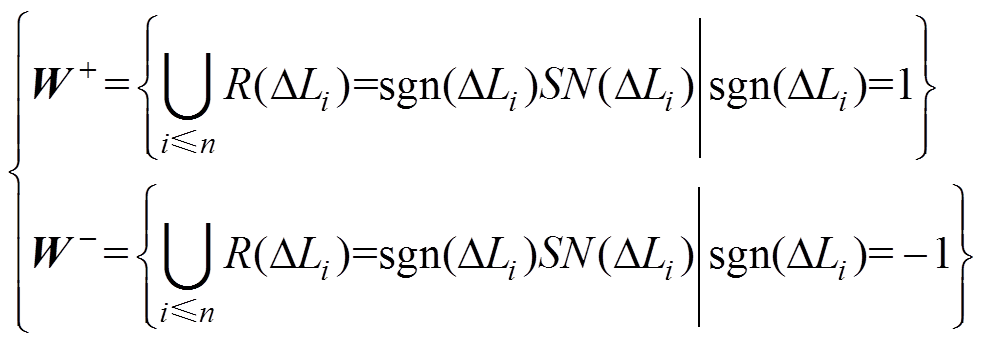 (8)
(8)
中的元素和称为正“秩和”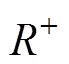 ,中的元素和称为负“秩和”
,中的元素和称为负“秩和” ,计算公式为
,计算公式为
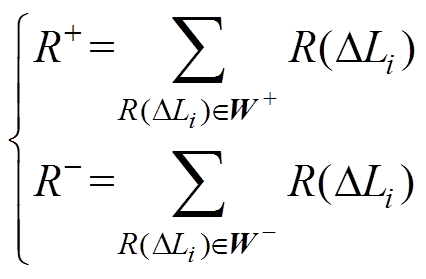 (9)
(9)
如果同期线损系统数据质量较高,则其统计得到的同期线损电量与理论线损电量的差值应随机地、分散地分布在零附近的邻域内,故差值序列的秩值应均匀地分布在[-n, +n]之间,差值的总体分布应是对称的,故根据式(9)求取的正负“秩和”相差不应悬殊,即正“秩和”与负“秩和”绝对值的 近似相等,即
近似相等,即
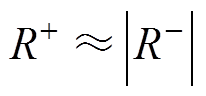 (10)
(10)反映了差异电量序列的“秩和”近似相等特性。
以某线路为例,给出该条线路连续5个时间段(每个时间段为29天,即n=29)的“秩和”差异特性,见表2。
表2 “秩和”近似相等特性
Tab.2 “Rank sum” approximate equality characteristic
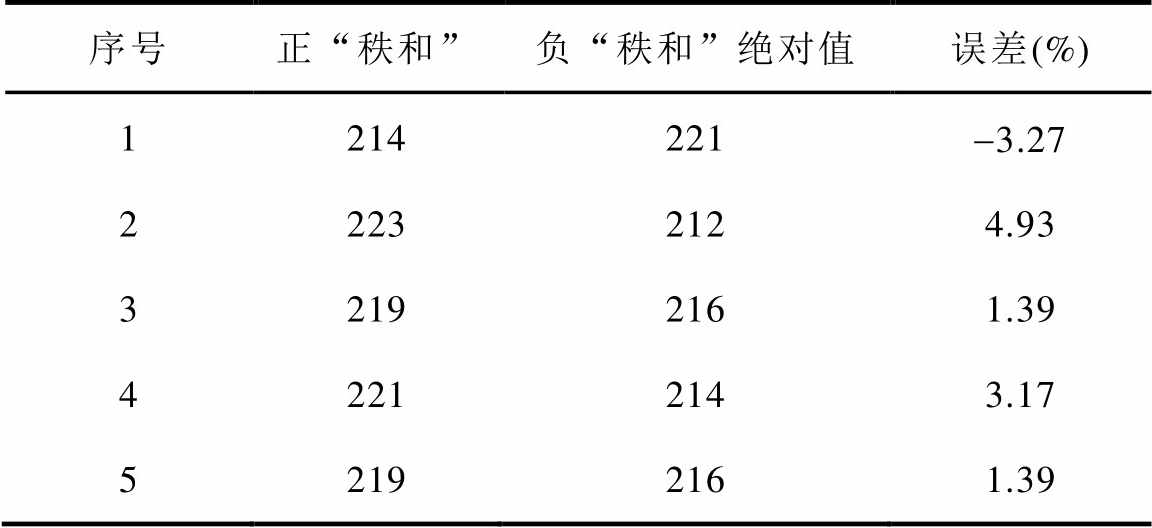
序号正“秩和”负“秩和”绝对值误差(%) 1214221-3.27 22232124.93 32192161.39 42212143.17 52192161.39
由表2可知,当数据中不包含异常数据时,正“秩和”及负“秩和”的绝对值近似相等,误差最大不超过5%,基本不受转换误差的影响。这是由于在求取同期线损与理论线损差值序列时,减去了差值平均值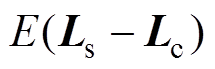 ,使得中的元素均匀随机地分布在0的邻域内;并且根据编秩过程可知,只要中正元素和负元素的个数近似相等,则正“秩和”及负“秩和”也近似相等,数据转换误差通过差值平均值得以消除,其误差大小不会影响该性质,即通过差异序列编秩可以消除数据转换误差对异常数据辨识的影响。
,使得中的元素均匀随机地分布在0的邻域内;并且根据编秩过程可知,只要中正元素和负元素的个数近似相等,则正“秩和”及负“秩和”也近似相等,数据转换误差通过差值平均值得以消除,其误差大小不会影响该性质,即通过差异序列编秩可以消除数据转换误差对异常数据辨识的影响。
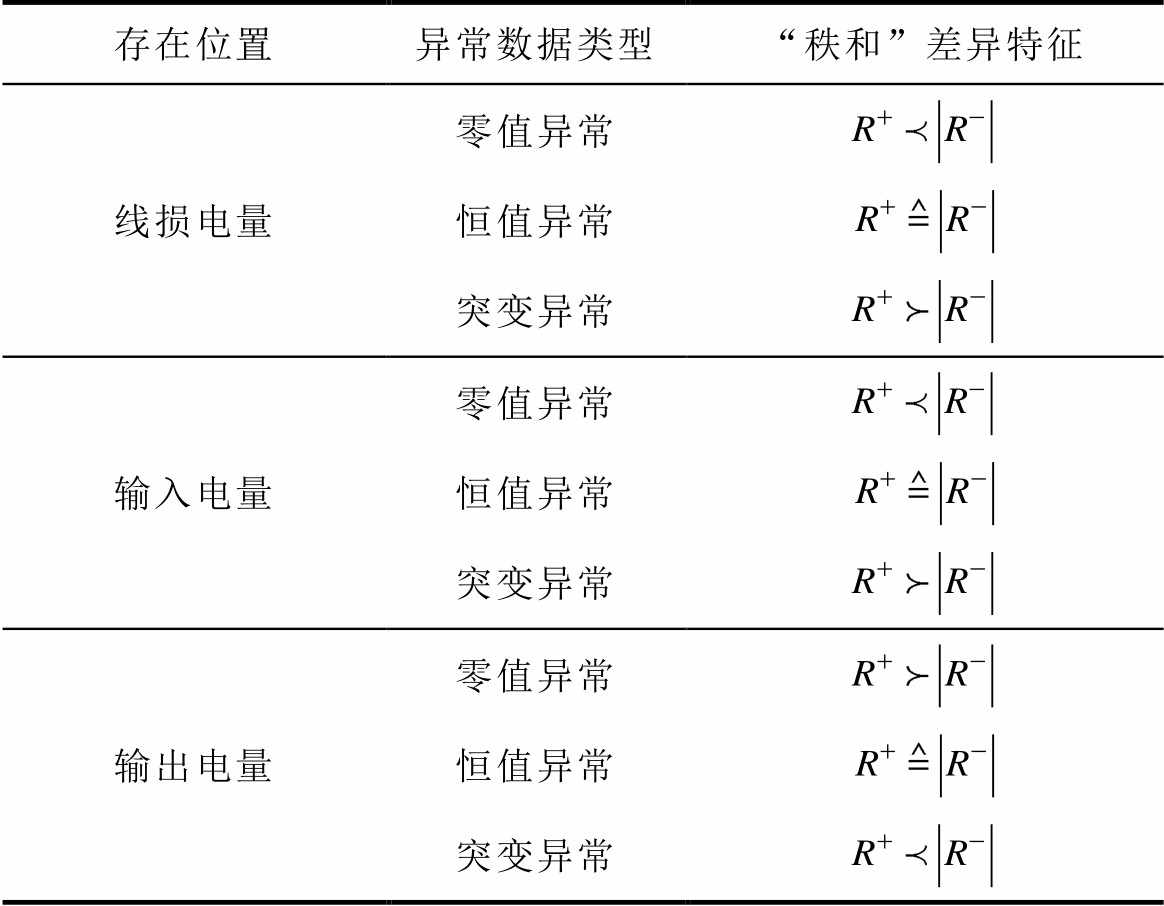
当数据中存在异常数据时,将会破坏上述“秩和”近似相等特性,呈现出新的差异特征,具体见表3。
以线损电量为例,对表3进行解释说明:
(1)当同期线损电量中存在零值异常数据时,会造成同期线损电量减少,理论线损电量不变,则同期线损与理论线损的差值电量为负的样本增加,负“秩和”增加,故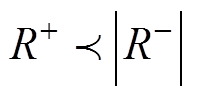 。
。
(2)当线损电量中存在恒值异常数据时,由于异常数据与实际数据偏差正负不能确定,故正负“秩和”的相对关系不确定,但同期线损电量与理论线损电量差值增加,会破坏近似相等特性,故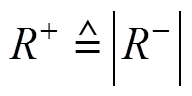 。
。
表3 “秩和”差异特征
Tab.3 “Rank sum” difference characteristics
存在位置异常数据类型“秩和”差异特征 线损电量零值异常 恒值异常 突变异常 输入电量零值异常 恒值异常 突变异常 输出电量零值异常 恒值异常 突变异常
注: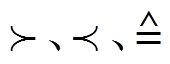 在本文中分别表示明显大于、明显小于、明显不等于。
在本文中分别表示明显大于、明显小于、明显不等于。
(3)当线损电量中存在突变异常数据(一般为异常增大)时,会造成同期线损电量显著增加,理论线损电量不变,则同期线损与理论线损的差值电量为正的样本增加,正“秩和”增加,故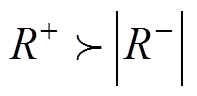 。
。
从上述分析可知,当同期线损系统中不存在异常数据时,满足,但当同期线损系统中存在异常数据时,会破坏该“秩和”近似相等特性,因此可以利用该特性进行同期线损异常数据辨识。
根据上述分析可知,只要设置合适的阈值,判定统计量和统计量是否近似相等可有效辨识异常数据,即通过判定式(10)是否成立即可。
根据上述线损电量差异序列的编秩过程可知, ,故
,故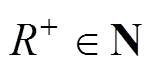 ,
,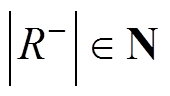 。其中,
。其中,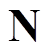 为自然数集合。
为自然数集合。
因此,推导可得
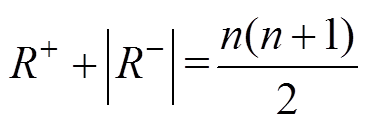 (11)
(11)式中,n为样本容量。
由于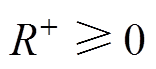 ,
,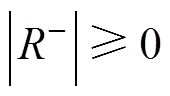 ,故
,故
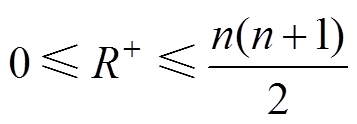 (12)
(12)所以,、当中的一个确定后,另一个随之而定。这样只考虑统计量即可。
假设同期线损系统中不存在异常数据,由“秩和”近似相等特性可知,正“秩和”的值不应取靠近式(12)两端的值。特殊的,对于大量样本计算得到正“秩和”应处于式(12)中间,即
 (13)
(13)因而,对于给定的样本,当计算得到的正“秩和”过分大或过分小,偏离式(13)较远时,均认为同期线损与理论线损差异过大,样本中存在异常数据。根据以上分析,判断式(10)是否成立转换成判断式(13)是否成立。
不妨设定的上、下阈值为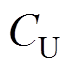 和
和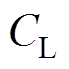 ,当且仅当满足正“秩和”的观察值满足
,当且仅当满足正“秩和”的观察值满足
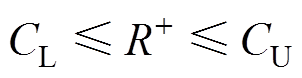 (14)
(14)则认为式(13)成立,即同期线损系统数据质量良好,无异常数据。
进行异常数据辨识的关键就是确定上述两个阈值。
 阈值计算
阈值计算传统阈值仅考虑第一类错误概率,即数据序列中没有异常数据但辨识为异常数据的误判概率,当该误判概率值确定后,即可以根据统计量的概率密度函数确定阈值。为了方便说明,不妨建立两个假设: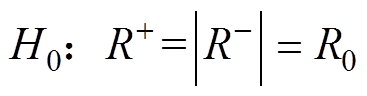 ;
;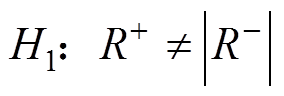 。其中,
。其中,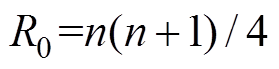 。
。
设当H0为真时,的概率密度分布函数为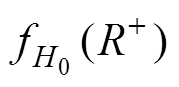 ,即样本中不存在异常数据时,的概率密度分布函数为,该概率密度函数根据历史数据计算,与n有关。由文献[18]可知,为对称分布函数,其示意图如图1所示。
,即样本中不存在异常数据时,的概率密度分布函数为,该概率密度函数根据历史数据计算,与n有关。由文献[18]可知,为对称分布函数,其示意图如图1所示。
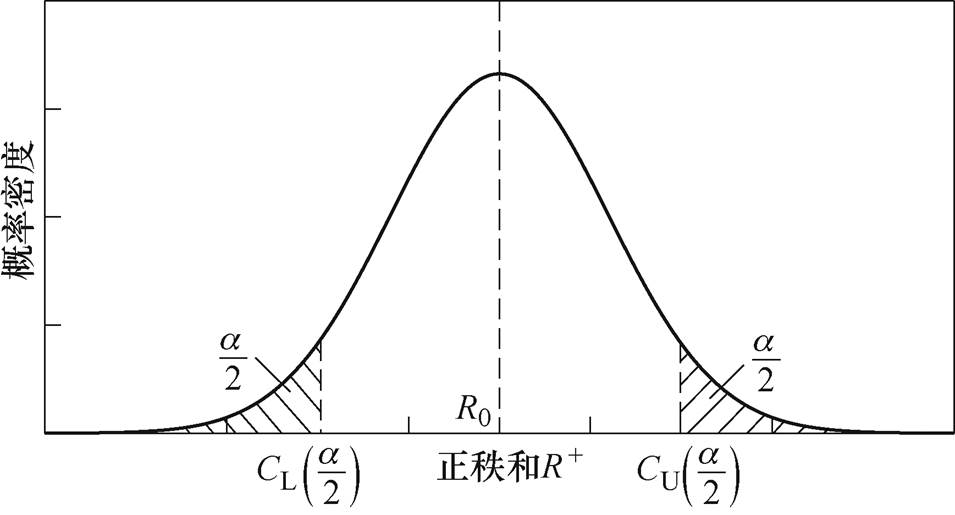
图1  阈值示意图
阈值示意图
Fig.1 Schematic diagram of threshold
则误判概率为
 (15)
(15)令双边误判概率均为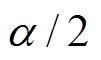 ,可得
,可得
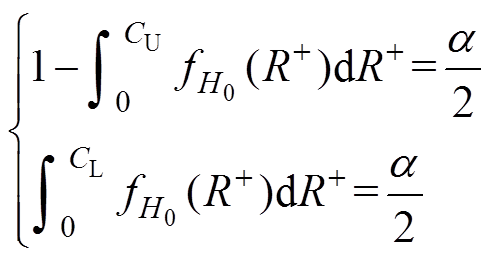 (16)
(16)
由此可得阈值为
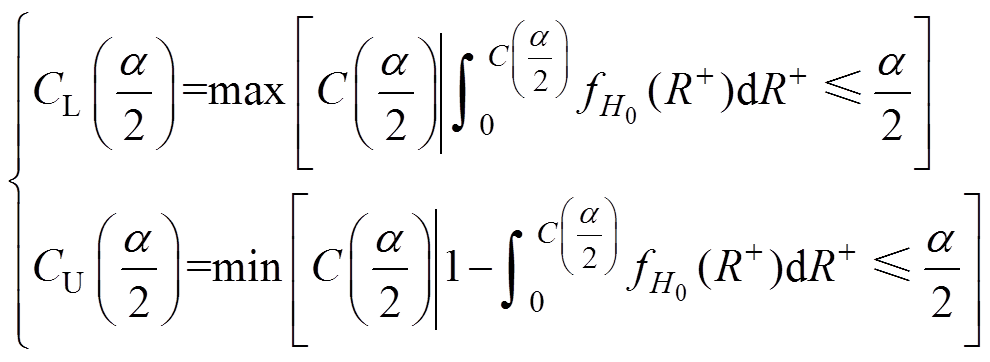 (17)
(17)上述阈值仅考虑第一类错误概率,即数据序列中没有异常数据但辨识出异常数据的误判概率;然而,实际也存在数据中存在异常数据却辨识不出的情况,因此,还需要考虑第二类错误漏判概率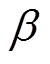 。
。
 阈值计算
阈值计算设当H0为假时,的概率密度分布函数为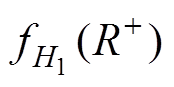 ,即样本中存在异常数据时的概率密度分布函数为。由文献[18]可知,为偏态双峰对称分布函数,多数情况下远离
,即样本中存在异常数据时的概率密度分布函数为。由文献[18]可知,为偏态双峰对称分布函数,多数情况下远离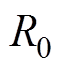 ,b 阈值示意图如图2所示。
,b 阈值示意图如图2所示。
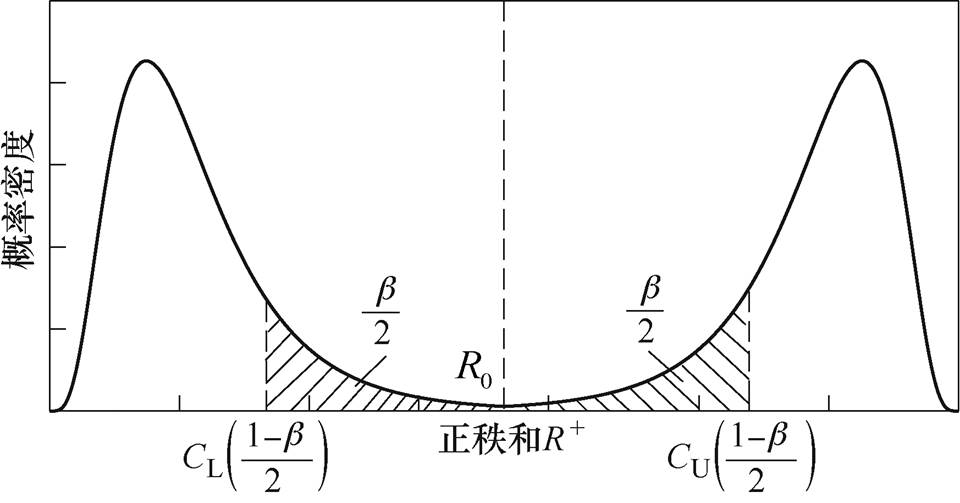
图2  阈值示意图
阈值示意图
Fig.2 Schematic diagram of threshold
漏判概率为
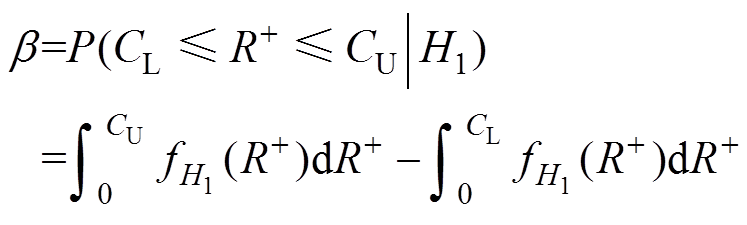 (18)
(18)令双边误判概率均为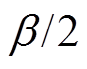 ,可得
,可得
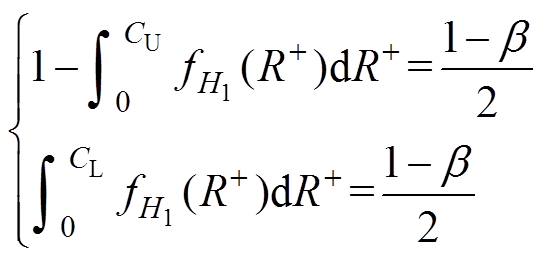 (19)
(19)
由此可得阈值为
 (20)
(20)综合考虑阈值和阈值的阈值确定如图3和图4所示。
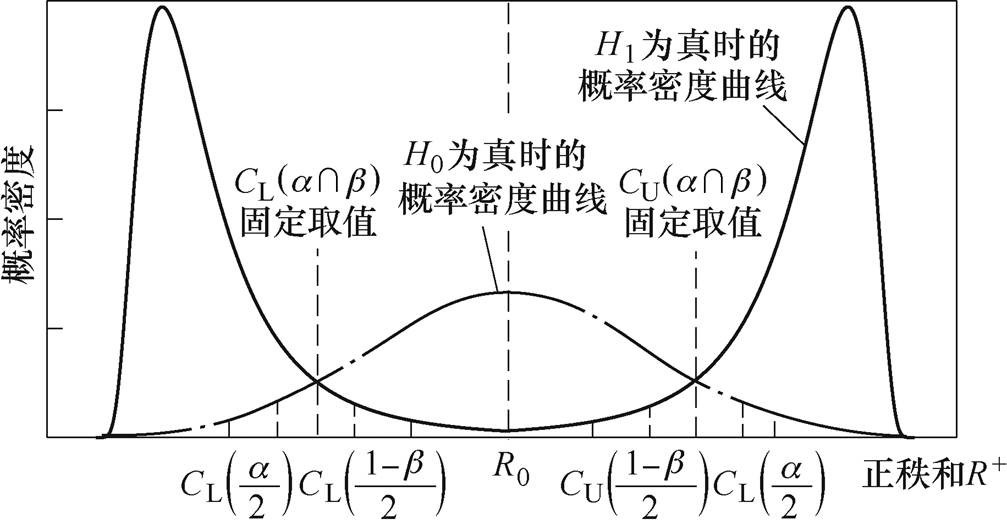
图3  阈值(
阈值( )
)
Fig.3 Schematic diagram of threshold ()

图4  阈值(
阈值(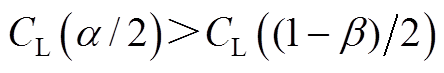 )
)
Fig.4 Schematic diagram of threshold ()
由图3和图4可知,由于阈值的对称性,阈值和阈值的大小关系存在三种情况(本文均以阈值下限值说明大小关系),不同情况下的阈值结果不同,下面分别进行讨论。
(1)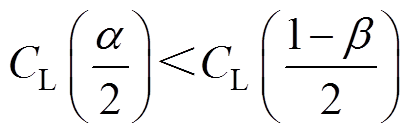 情况。此种情况下,根据图3可知,当阈值取值较小,偏向阈值时,异常数据检测的误判率随之减小,但漏判概率会随之增加,即未能检测出的异常数据数目增加;当阈值取值较大,偏向阈值时,异常数据检测的漏判率随之减小,但误判概率会随之增加,即会将更多的正确数据误判为异常数据。若阈值小于阈值(或大于阈值),会引起漏判率(或者误判率)显著增加,严重不合格,因此无论阈值取何值,均难以同时满足误判率和漏判率的要求。此时,阈值需要折衷,选取阈值和阈值的加权平均值,有
情况。此种情况下,根据图3可知,当阈值取值较小,偏向阈值时,异常数据检测的误判率随之减小,但漏判概率会随之增加,即未能检测出的异常数据数目增加;当阈值取值较大,偏向阈值时,异常数据检测的漏判率随之减小,但误判概率会随之增加,即会将更多的正确数据误判为异常数据。若阈值小于阈值(或大于阈值),会引起漏判率(或者误判率)显著增加,严重不合格,因此无论阈值取何值,均难以同时满足误判率和漏判率的要求。此时,阈值需要折衷,选取阈值和阈值的加权平均值,有
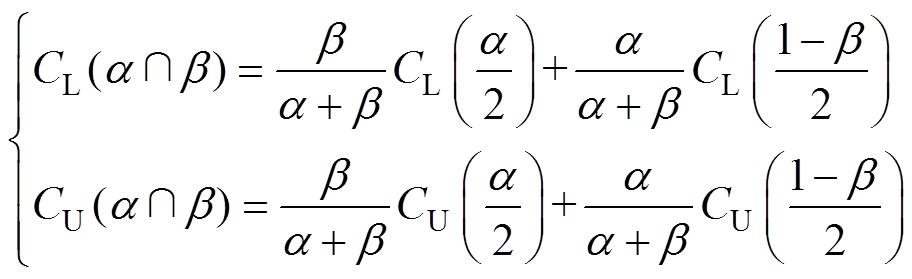 (21)
(21)当实际要求尽可能地保留正常数据,即要求误判概率更小时,式(21)的阈值更偏向阈值;反之,若实际要求尽可能地剔除异常数据,即要求漏判概率更小时,式(21)的 阈值更偏向
阈值更偏向 阈值。
阈值。
(2) 情况。此种情况下,由图4可知,当阈值较大,趋近
情况。此种情况下,由图4可知,当阈值较大,趋近 阈值时,会使得漏判概率减小;当阈值取阈值较小,趋近阈值时,也会使得误判概率减小,只要阈值处于阈值和阈值之间,均满足要求,故阈值为
阈值时,会使得漏判概率减小;当阈值取阈值较小,趋近阈值时,也会使得误判概率减小,只要阈值处于阈值和阈值之间,均满足要求,故阈值为
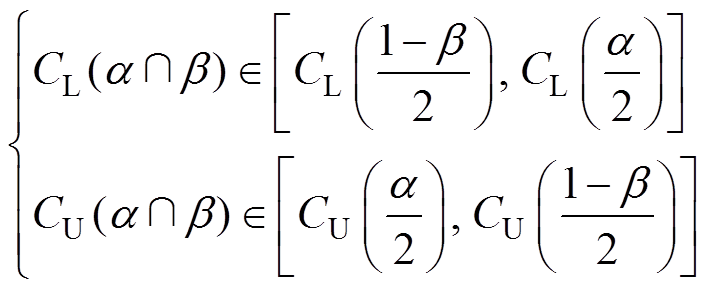 (22)
(22)(3)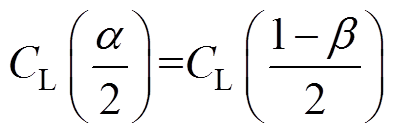 情况。此种情况下,阈值和阈值均恰好满足要求,可取值为阈值(或阈值,两者相等),若阈值小于该值,则会造成漏判率不合格,若阈值大于该值,则会造成误判率不合格,故阈值为
情况。此种情况下,阈值和阈值均恰好满足要求,可取值为阈值(或阈值,两者相等),若阈值小于该值,则会造成漏判率不合格,若阈值大于该值,则会造成误判率不合格,故阈值为
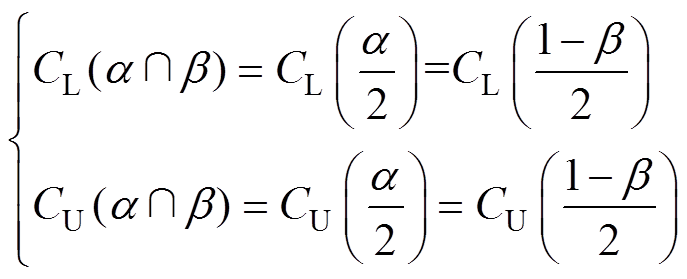 (23)
(23)
由上述分析可知,计算阈值最关键的一步是确定两个分布函数: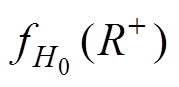 和
和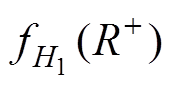 ,这两个分布函数确定后,阈值便可以根据式(21)~式(23)进行计算。对于同一个区域,由于其表计、通信等因素引起数据异常的本质特性是一致的,故可以认为同一区域的和是确定的,进而同一区域的阈值也是确定的,不会随着待辨识样本的变化而变化。
,这两个分布函数确定后,阈值便可以根据式(21)~式(23)进行计算。对于同一个区域,由于其表计、通信等因素引起数据异常的本质特性是一致的,故可以认为同一区域的和是确定的,进而同一区域的阈值也是确定的,不会随着待辨识样本的变化而变化。
经过第3节介绍,可以通过式(21)~式(23)所示的阈值判断样本中是否含有异常数据,下面将进一步判断异常数据的位置。
通常情况下,已知样本中是否存在异常数据的判据,通过二分法,不断拆分样本分别判断,最终便可以得到异常数据位置。然而,面对海量同期线损异常数据,会进行多次阈值判断,计算量较大,为此本文在第3节阈值计算的基础上,建立同期线损异常数据辨识模型。具体如下:
不妨设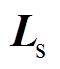 为待检测的同期线损电量样本,将其分解成
为待检测的同期线损电量样本,将其分解成
 (24)
(24)式中,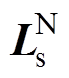 为同期线损电量正常数据构成的集合,异常数据位置元素置0;
为同期线损电量正常数据构成的集合,异常数据位置元素置0;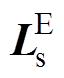 为同期线损电量异常数据构成的集合,正常数据位置元素置0,两个数据集合的维度与相同,均为列矩阵。
为同期线损电量异常数据构成的集合,正常数据位置元素置0,两个数据集合的维度与相同,均为列矩阵。
通过求解即可完成同期线损异常数据辨识。
由于中不含异常数据,对其进行阈值判断时,其正“秩和”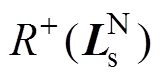 一定处于该区域异常数据的阈值范围内,故有
一定处于该区域异常数据的阈值范围内,故有
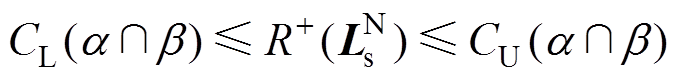 (25)
(25)同理,由于中存在异常数据,对其进行阈值判断时,其正“秩和”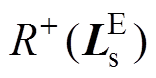 一定处于该区域异常数据的阈值范围外,故有
一定处于该区域异常数据的阈值范围外,故有
 (26)
(26)
不难发现,满足式(25)和式(26)的矩阵分解组合有很多种,只要中不含有异常数据,即使只包含部分的正常数据,也可满足要求。因此,在求解、过程中,为了辨识出所有的异常数据,只要使得在满足式(25)和式(26)的基础上,中的非零元素数量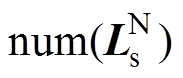 最大,即可使得全部的正常数据分解至,异常数据分解至,故异常数据辨识模型转换为优化模型:
最大,即可使得全部的正常数据分解至,异常数据分解至,故异常数据辨识模型转换为优化模型:
(1)优化目标:的非零元素数量最大,有
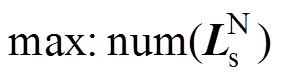 (27)
(27)(2)约束条件:①满足分解规则约束,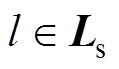 等价于
等价于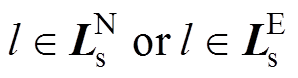 ;②满足的阈值约束,如式(25)所示;③满足的阈值约束,如式(26)所示。
;②满足的阈值约束,如式(25)所示;③满足的阈值约束,如式(26)所示。
通过分析可知,上述辨识模型的本质是将中的元素分配至集合和集合中的优化过程,为了方便求解,本文引入0-1变量矩阵x作为优化变量,对上述模型进行变形。具体如下:
不妨设
 (28)
(28)式中,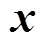 为列矩阵,其维度与相同,且元素为0-1变量;
为列矩阵,其维度与相同,且元素为0-1变量; 为矩阵的数组乘法。
为矩阵的数组乘法。
结合式(24)和式(28)可得
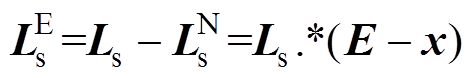 (29)
(29)式中,E为元素均为1的列矩阵,其维度与相同。则通过优化0~1变量矩阵x,即可实现中元素分配。中的元素数量可表示为x中所有元素的和,即
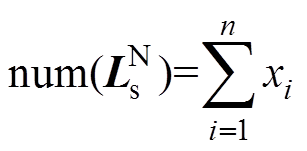 (30)
(30)式中,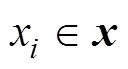 ,为x中的元素;n为中元素的数量。故同期线损异常数据辨识模型可改写为
,为x中的元素;n为中元素的数量。故同期线损异常数据辨识模型可改写为
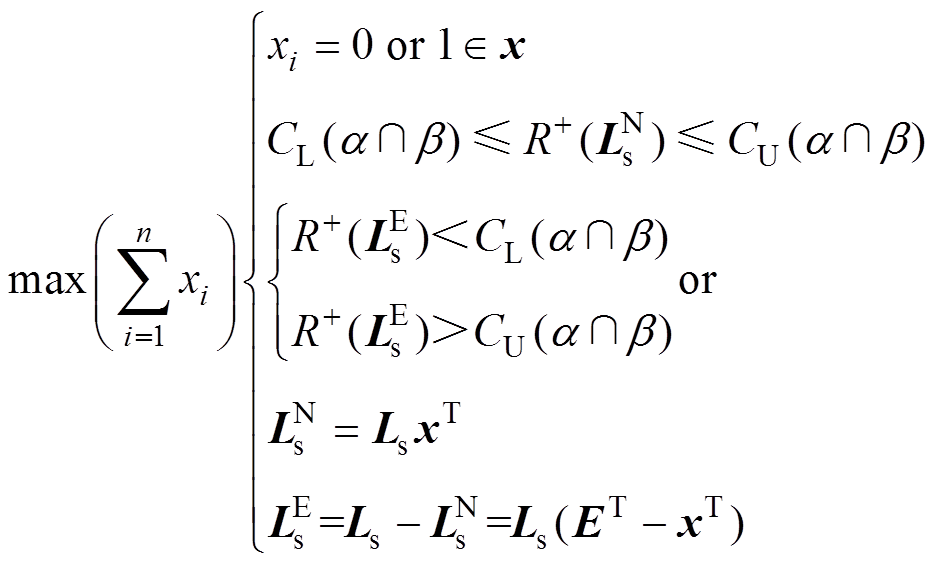 (31)
(31)
由第3节分析可知,由于阈值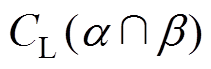 、
、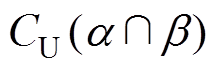 均为定值,且正“秩和”、的计算也都是线性的,因此式(31)所示的模型是最简单的0~1优化模型,采用lingo软件可轻易求解,不再赘述。
均为定值,且正“秩和”、的计算也都是线性的,因此式(31)所示的模型是最简单的0~1优化模型,采用lingo软件可轻易求解,不再赘述。
通过4.1节可以判定出异常数据的位置,但无法确定是该位置的理论线损异常还是同期线损数据异常,需要进一步定位。本文采用相邻数据检测方法,将4.1节得到的差异较大位置及相邻位置的数据筛选出来,形成理论线损疑似集合Lec和同期线损疑似集合Les,然后针对常见的三种异常数据类型(连续恒定、零值异常和突变异常),采用式(32)~式(34)分别对两个集合Lec、Les进行单独相邻检测[20],即可定位异常数据。
(1)连续恒定常数异常检测。当数据序列满足式(32)时,则认为数据连续恒定。
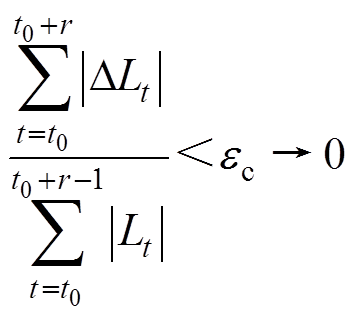 (32)
(32)式中,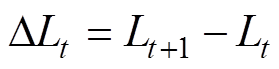 为相邻时刻的线损电量差值;r为判定连续相同的数据个数,一般取5;
为相邻时刻的线损电量差值;r为判定连续相同的数据个数,一般取5;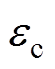 为连续恒定常数判定阈值。
为连续恒定常数判定阈值。
(2)零值异常数据检测。当数据序列中的数据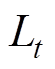 满足式(33)时,则认为数据零值异常。
满足式(33)时,则认为数据零值异常。
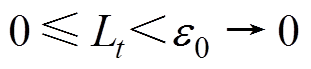 (33)
(33)式中,为零值异常判定阈值。
(3)突变异常数据检测。当数据序列满足式(34)时,则认为存在突变异常数据。
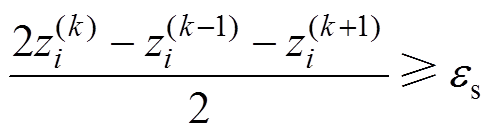 (34)
(34)式中,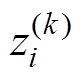 为序列中第k个数据;
为序列中第k个数据; 为突变异常判定阈值。
为突变异常判定阈值。
通过上述分析可知,本文提出的同期线损异常数据辨识方法流程如图5所示。
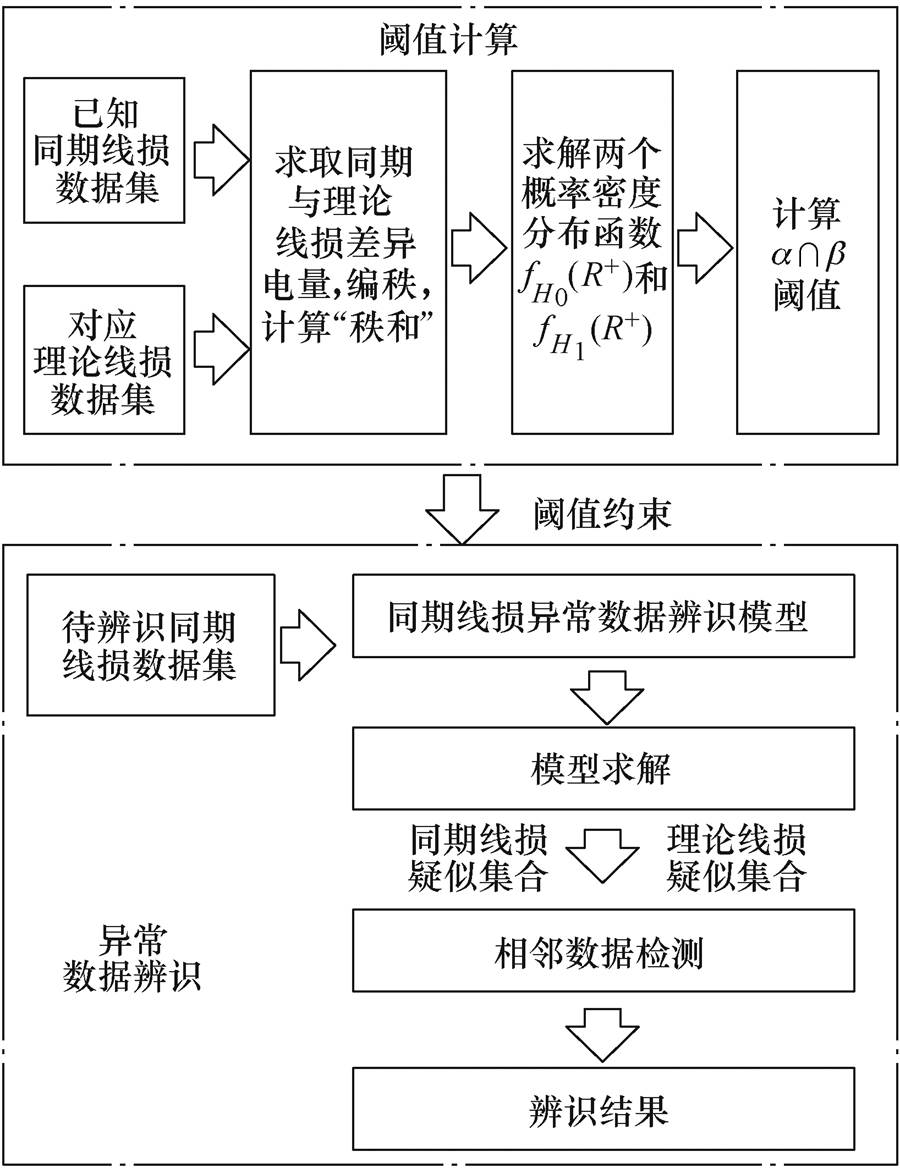
图5 同期线损异常数据辨识流程
Fig.5 Identification process of line loss abnormal data
由图5可知,本文所提辨识方法主要包含三个部分,具体如下:
(1)计算同期线损阈值,为异常数据辨识模型提供约束基准,其包含三小步:①根据已知同期线损数据集计算相应的理论线损数据集,计算两者的差异电量,并对差异电量序列进行编秩,计算正秩和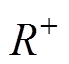 和负秩和
和负秩和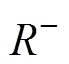 ;②根据历史数据计算H0为真时,的概率密度分布函数,以及H1为真时,的概率密度分布函数;③按照式(21)、式(22)或式(23)计算阈值。
;②根据历史数据计算H0为真时,的概率密度分布函数,以及H1为真时,的概率密度分布函数;③按照式(21)、式(22)或式(23)计算阈值。
(2)根据同期线损异常数据模型判定异常数据位置(不区分理论线损和同期线损)。①首先以步骤(1)得到的阈值作为式(31)的约束,建立同期线损异常数据辨识模型;②将待辨识的同期线损数据集合代入同期线损异常数据辨识模型中,对其求解,可得同期线损异常数据辨识结果,给出异常数据位置集合。
(3)根据相邻检测判定是理论线损还是同期线损中存在异常数据。①将步骤(2)得到的异常数据位置及相邻位置的数据筛选出来,形成理论线损疑似集合Lec和同期线损疑似集合Les;②根据式(32)~式(34)对两个疑似集合进行相邻数据检测,最终获得理论线损和同期线损的异常数据集合。
通过上述方法可以判断哪些同期数据为异常数据,进而为同期线损异常数据修复奠定基础。
该算例以甘肃同期线损系统数据为例进行仿真。选取其中330kV输电线路(包含双回线,总计227条)日线损电量数据进行异常数据辨识,采集时间段为2017年1月1日~2018年12月31日,每条输电线路均具有730个数据点,总计165 710个数据点。将上述样本数据划分为样本数据和测试数据两部分,样本数据包含200条输电线路数据,测试数据包含27条输电线路数据。具体数据划分情况见表4。
表4 数据划分
Tab.4 Data division

样本数据测试数据 146 00019 710
样本数据用于统计两个概率密度函数并计算秩和差异阈值,测试数据用于验证本文所提同期线损异常数据辨识的正确性。
5.2.1 阈值计算分析
为了获取样本数据的两个概率密度函数和,需要首先将样本数据划分成多个小样本,并判定小样本数据的标记(是否存在异常数据),经过大数据分析和多源数据校核[21](耗时较长),可得样本数据标记见表5。
表5 样本数据标记
Tab.5 Sample data division
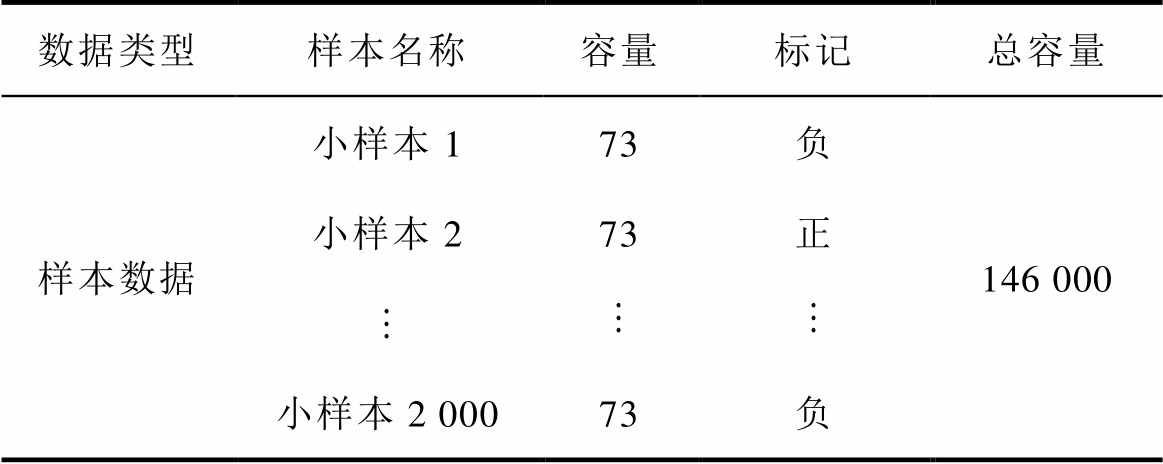
数据类型样本名称容量标记总容量 样本数据小样本173负146 000 小样本273正 小样本2 00073负
注:“正”表示小样本中不含异常数据;“负”表示小样本中包含异常数据。
经过统计,2 000个小样本中,标记为正的样本为856个,标记为负的样本为1 144个。统计可得和的概率密度函数,如图6所示。
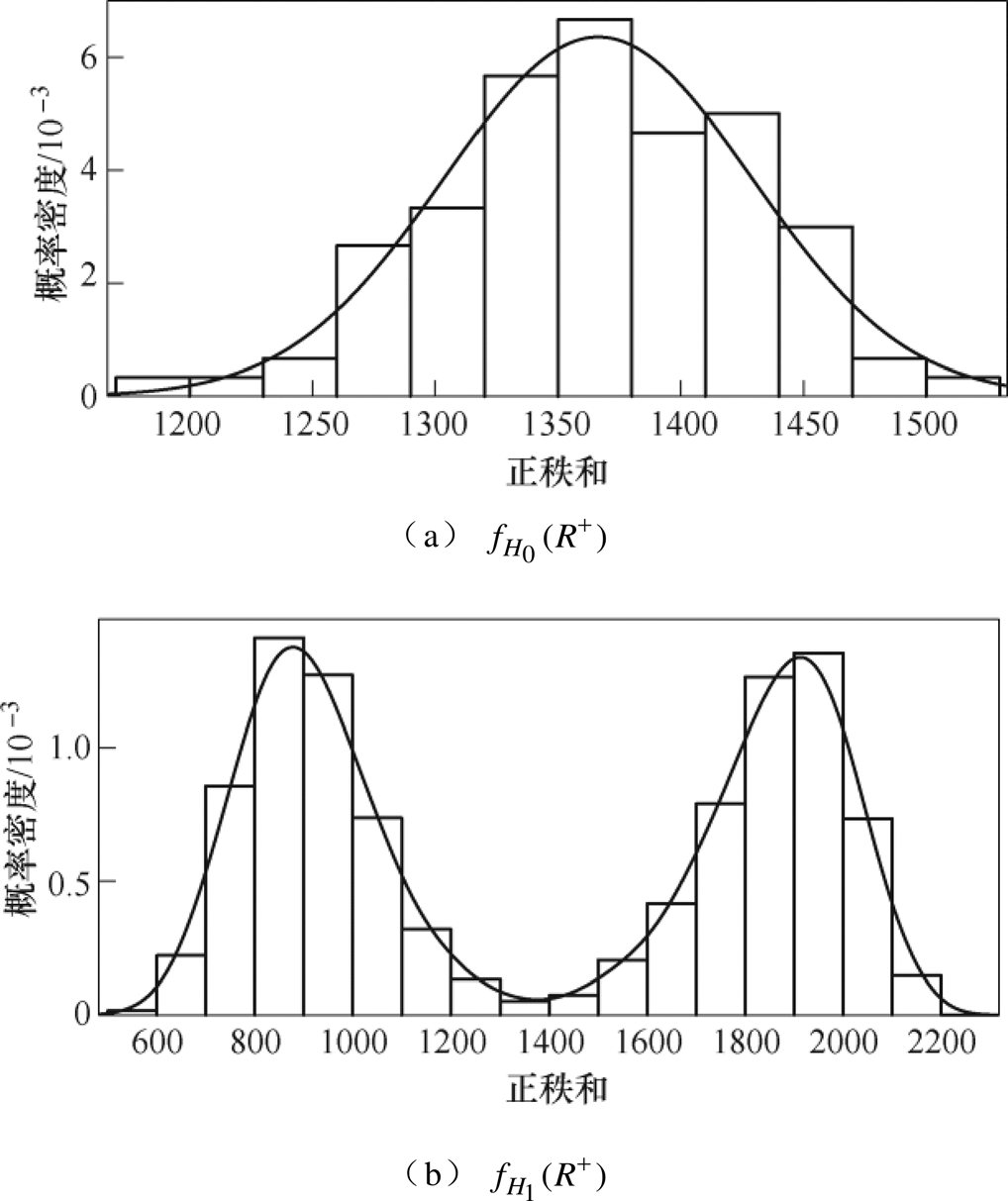
图6 概率分布函数
Fig.6 Schematic diagram of probability distribution function
由文献[18]可知,取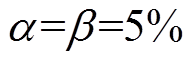 ,根据式(17)、式(20)分别计算阈值、阈值,见表6。
,根据式(17)、式(20)分别计算阈值、阈值,见表6。
表6 a 阈值和b 阈值
Tab.6 Threshold  and threshold
and threshold 

阈值阈值 1 2501 130 1 4901 610
根据表6,由于,根据式(22)可知,阈值可以取阈值和阈值之间的任意值,本文取两者的中间值,见表7。
表7 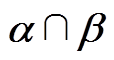 阈值
阈值
Tab.7 Threshold 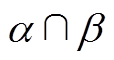

阈值 1 1901 550
5.2.2 不同类型异常数据辨识结果分析
1)样本实际异常数据确定
在进行辨识结果分析前,首先需要确定哪些数据为异常数据,并以此为标准分析本文各异常数据辨识效果。逻辑判断应是异常数据权威的判定方法,即利用电网的冗余结构,根据电网基本定律-基尔霍夫定律进行判断,逻辑判断如图7所示。图中,功率流入A点为正,流出A点为负。
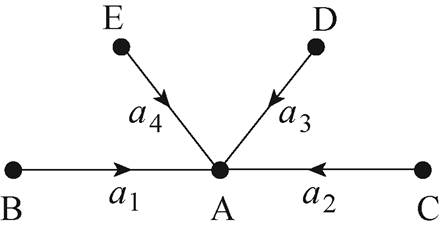
图7 逻辑判断示意图
Fig.7 Logic judgment diagram
若A点功率不满足基尔霍夫定律,说明a1、a2、a3、a4中有异常数据,此时,分别对B、C、D、E点分别进行基尔霍夫验证,下面分两种情况进行讨论:①只有一点不符合基尔霍夫(如B点),其余均满足基尔霍夫定律,则可以判定数据a1有误; ②若存在两点及以上不符合基尔霍夫(如D、E点),尚无法判断a3、a4哪个异常,此时需要以D点和E点为中心进行拓扑展开,判断D、E点的相邻点是否满足基尔霍夫,直至某个点的相邻点中只有一个点不符合基尔霍夫的情况,则可按照①判断异常数据,然后进行反推,判断a3、a4的异常情况。
显然,采用上述逻辑判断得到的数据异常是最准确的,但十分耗时,用于同期线损系统海量的数据判断不可行,只能用于小样本分析。
2)辨识结果分析
将上述阈值代入式(32)所示的辨识模型,即可辨识出不同类型的异常数据位置。同时,为了方便分析,将所提方法与传统残差法和间歇统计法进行比较。
传统残差辨识[22]的辨识公式为
 (35)
(35)式中, 为标准化残差辨识门槛值;
为标准化残差辨识门槛值; 为量测j的标准化残差。
为量测j的标准化残差。
 (36)
(36)
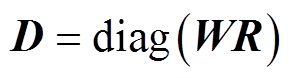 (37)
(37)式中,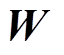 为残差灵敏度矩阵。
为残差灵敏度矩阵。
残差辨识的门槛值在运行中需要人工调整,对于维护较差的系统,门槛值调整的高一些,否则数据过多会失掉可辨识性;对于维护良好的系统,门槛值调整的低一些,以免漏掉不良数据。通过对残差法阈值的反复调试,得到最佳(误判率和漏判率均较低)的阈值为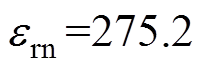 ,以此阈值进行辨识。
,以此阈值进行辨识。
间歇统计法[23]的辨识公式为
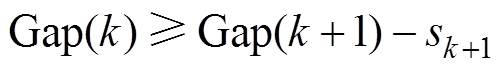 (38)
(38)其中
 (39)
(39)
式中,Gap(k)为间隙值;sk为标准差;Dk为聚类内部各数据点的欧式距离之和;K为聚类个数; 为第k类样本点个数;
为第k类样本点个数;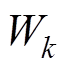 为聚类离散度,上标*表示参考数据;B为参考数据集个数;
为聚类离散度,上标*表示参考数据;B为参考数据集个数;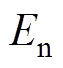 为数据期望。通过间隙统计法可以确定最优聚类的个数,如果最优聚类为1,则表示所有数据为正常数据,否则认为存在异常数据,具有最小平均值的聚类被认为是正常数据的聚类,其余的都被认为是不良数据组成的聚类。
为数据期望。通过间隙统计法可以确定最优聚类的个数,如果最优聚类为1,则表示所有数据为正常数据,否则认为存在异常数据,具有最小平均值的聚类被认为是正常数据的聚类,其余的都被认为是不良数据组成的聚类。
(1)零值异常数据辨识结果分析。采用本文方法、残差辨识法和间歇统计法对测试区数据进行辨识,得到辨识结果如图8所示。由图8可知,对于零值异常数据具有较好的辨识效果,可以全部辨识出来,这是由于零值会显著改变“秩和”和“残差”,使其远离正常“秩和”范围和“残差”范围,超出阈值。
(2)恒值异常数据辨识结果分析。同样,对测试区数据进行恒值异常数据辨识,得到辨识结果如图9所示。由图9可知,残差辨识方法和间歇辨识方法均检测到两处恒值异常数据;而本文辨识方法仅为一处。通过逻辑判断可知,第一处的实际运行情况就是线损电量连续几天近似相等,属于正常数据;而第二处为电量数据实际异常,因此残差辨识和间歇辨识均出现误判现象,而本文所提秩和辨识方法可有效将其辨识出来,说明该方法的有效性。
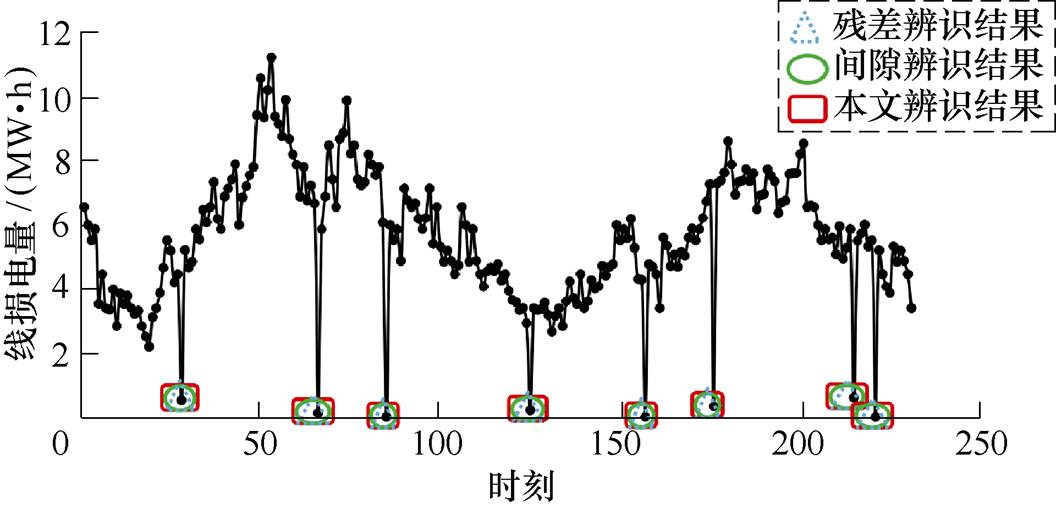
图8 零值异常数据辨识结果
Fig.8 Identification results of zero value abnormal data

图9 恒值异常数据辨识结果
Fig.9 Identification results of constant value abnormal data
(3)突变异常辨识结果分析。对突变异常数据的辨识结果如图10所示。由图可知,本文秩和辨识方法可以有效辨识将突变异常数据,基本无漏判;残差辨识方法出现了两处数据误判;间隙辨识方法则出现了三处数据误判。说明了所提方法对于突变异常数据的辨识精度优于其他两种方法。
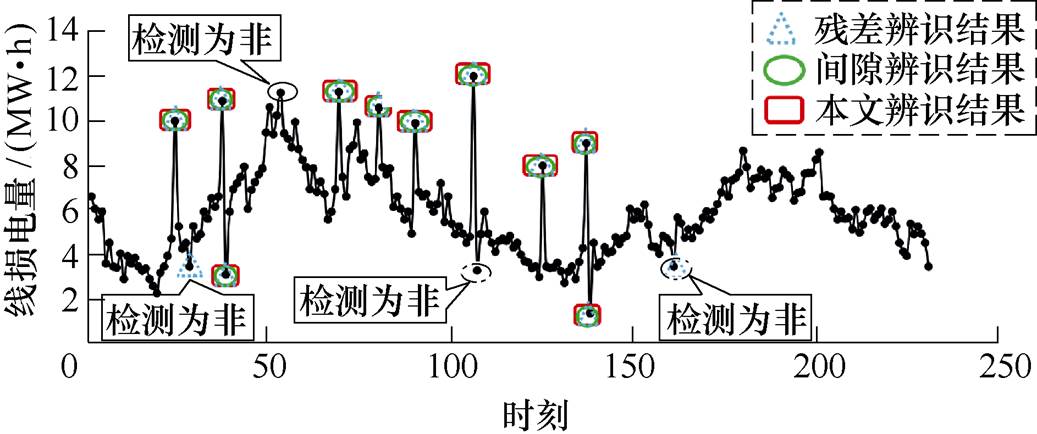
图10 突变异常数据辨识结果
Fig.10 Identification results of abrupt abnormal data
为了进一步量化分析本文所提辨识方法的辨识优势,通过大量数据辨识结果对比所提方法与传统残差辨识法、间歇统计法和阈值法的误判率和漏判率,结果见表8。
表8 辨识结果对比
Tab.8 Comparison of identification results
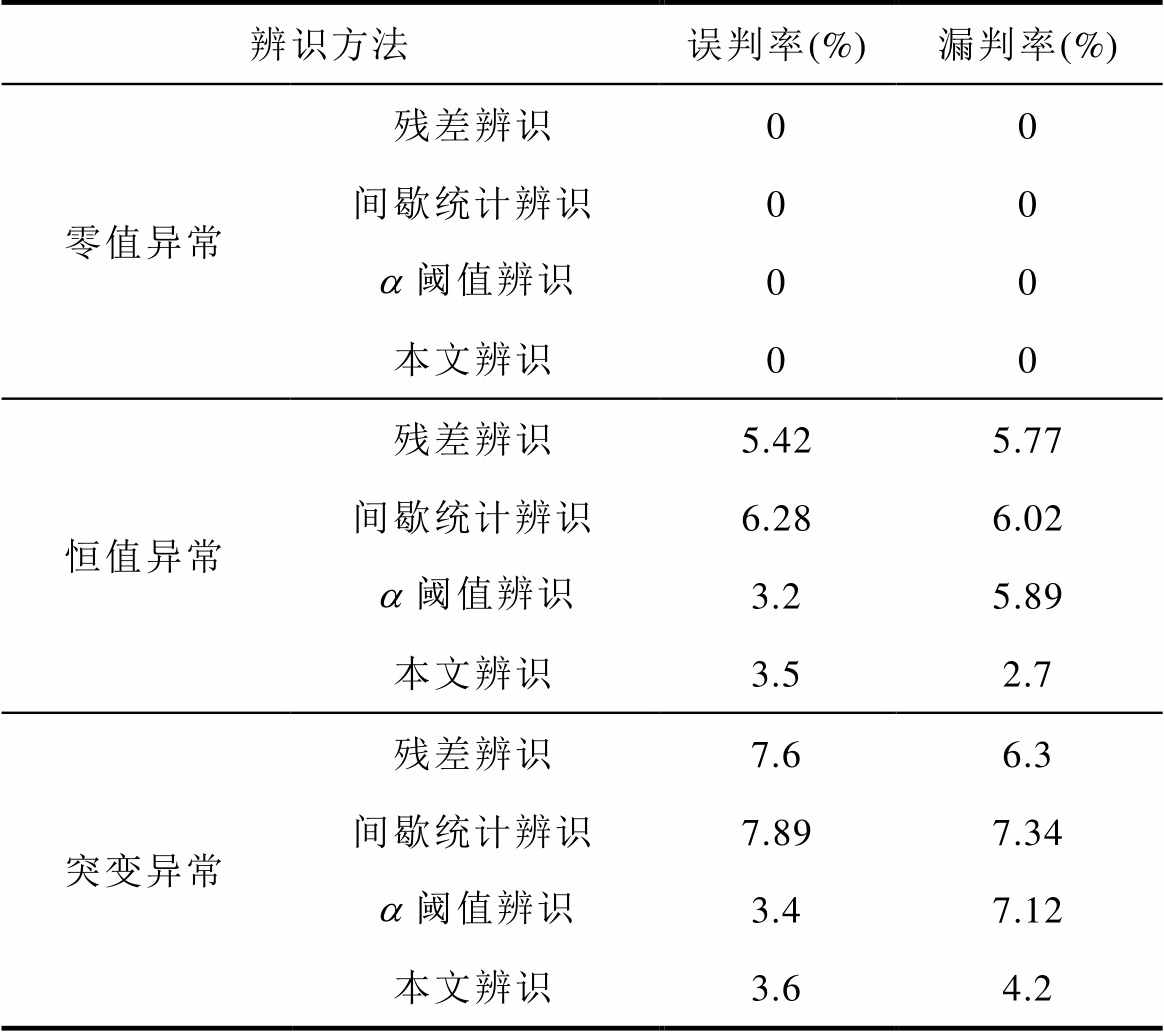
辨识方法误判率(%)漏判率(%) 零值异常残差辨识00 间歇统计辨识00 阈值辨识00 本文辨识00 恒值异常残差辨识5.425.77 间歇统计辨识6.286.02 阈值辨识3.25.89 本文辨识3.52.7 突变异常残差辨识7.66.3 间歇统计辨识7.897.34 阈值辨识3.47.12 本文辨识3.64.2
由表8可知,对于零值异常数据,四个方法均能获得较好的辨识效果,但对于恒值异常数据和突变异常数据,由于本文秩和辨识方法利用了理论线损对比数据,辨识效果更佳。并且从与阈值辨识法的比较看出,所提方法能在保证误判率满足要求的同时有效降低漏判率,相对更优。
同时,对三种辨识方法进行辨识总时长的比较,见表9。
表9 辨识总时长对比
Tab.9 Identification time comparison

辨识方法辨识总时长/ms 间歇统计辨识235 传统残差辨识126 阈值辨识21 本文辨识32
由表9可知,本文辨识方法具有较短的辨识总时长32ms,比传统残差辨识和间歇统计辨识耗时短,说明了所提方法具有更低的算法复杂度,能有效提高辨识的速度;虽然相对阈值辨识法的耗时有所增加,但增加不大,辨识精度却有明显改善,因此,综合辨识精度和辨识时间两方面,本文所提方法具有很好的实用性。
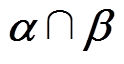 阈值取值对异常数据辨识的影响分析
阈值取值对异常数据辨识的影响分析由5.2节分析可知,由于,阈值可以取阈值和阈值之间的任意值,即阈值下限的取值范围为[1 130, 1 250],上限的取值范围为[1 490, 1 610]。下面以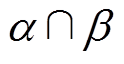 阈值取值不同设置5个案例,分析阈值变化对异常数据(以突变异常为例)辨识的影响,结果见表10。
阈值取值不同设置5个案例,分析阈值变化对异常数据(以突变异常为例)辨识的影响,结果见表10。
表10 阈值取值不同的对比
Tab.10 Comparison of different threshold values

阈值误判率(%)漏判率(%) 方案一1 1302.94.9 1 610 方案二1 1603.34.5 1 580 方案三1 1903.64.2 1 550 方案四1 2203.73.5 1 520 方案五1 2504.02.7 1 490
由表10可知,当阈值变大时,误判率会降低,漏判率升高;反之,误判率会升高,漏判率降低。但是从整体来看,误判率和漏判率均不会超出5%,符合辨识要求。
为了证明本文方法的可扩展性,以甘肃天水配电网为例,选取35kV线路日线损电量数据进行异常数据辨识,采集时间段为2017年1月1日~2018年12月31日,线路共69条,共计50 370个数据点。将所有数据按照相同方式划分为样本数据和测试数据,见表11。
表11 数据划分
Tab.11 Data division

样本数据测试数据 43 8006 570
分别采用本文方法、残差辨识方法、 阈值辨识法和间歇辨识方法进行异常数据辨识,辨识结果对比见表12。由表12可知,对配电同期线损数据,综合考虑辨识误判率和漏判率,本文所提辨识方法相对于传统残差辨识和间歇辨识依然优势明显,说明本文方法具有良好的适用性。
阈值辨识法和间歇辨识方法进行异常数据辨识,辨识结果对比见表12。由表12可知,对配电同期线损数据,综合考虑辨识误判率和漏判率,本文所提辨识方法相对于传统残差辨识和间歇辨识依然优势明显,说明本文方法具有良好的适用性。
同期线损系统异常数据辨识对于电力系统经济运行以及合理规划具有重要意义。本文提出基于“秩和”近似相等特性的同期线损异常数据深度辨识方法,一方面发掘出理论线损与同期线损数据差异的“秩和”近似相等特性,充分利用了理论线损数据信息,相对传统残差辨识方法可以取得更好的辨识效果;另一方面,该方法改进了传统只考虑误判率的阈值计算方法,提出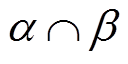 阈值计算方法,可使得异常数据辨识的误判率和漏判率均控制在一定范围内。经过仿真证明,本文所提异常数据辨识方法对不同类型异常数据均具有较好的辨识效果。
阈值计算方法,可使得异常数据辨识的误判率和漏判率均控制在一定范围内。经过仿真证明,本文所提异常数据辨识方法对不同类型异常数据均具有较好的辨识效果。
表12 辨识结果
Tab.12 Identification results
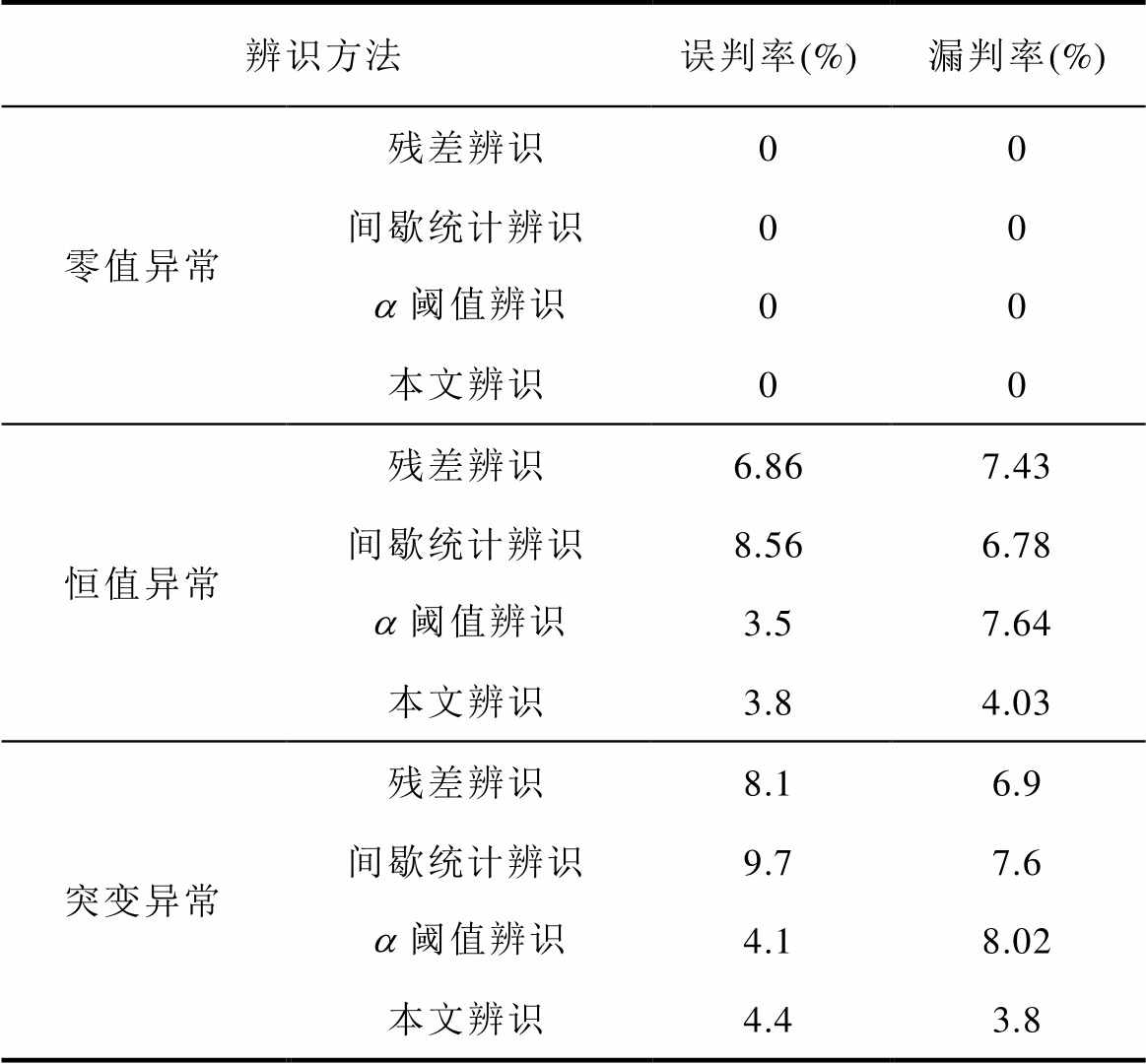
辨识方法误判率(%)漏判率(%) 零值异常残差辨识00 间歇统计辨识00 阈值辨识00 本文辨识00 恒值异常残差辨识6.867.43 间歇统计辨识8.566.78 阈值辨识3.57.64 本文辨识3.84.03 突变异常残差辨识8.16.9 间歇统计辨识9.77.6 阈值辨识4.18.02 本文辨识4.43.8
经过大量数据辨识实例发现,有些问题本文辨识方法依然没能解决,如对于差值边界点(同期线损与理论线损的差值序列的最大值和最小值)发生异常时,辨识效果仍然不佳,有待于进一步研究。
参考文献
[1] 张勤, 马玮, 付锦, 等. 中压配电网规划态线损计算方法[J]. 电气技术, 2018, 19(2): 42-45.
Zhang Qin, Ma Wei, Fu Jin, et al. Line loss calcu- lation for middle voltage distribution network planning[J]. Electrical Engineering, 2018, 19(2): 42-45.
[2] 李滨, 严康, 罗发, 等. 最优标杆在市级电网企业线损精益管理中的综合应用[J]. 电力系统自动化, 2018, 42(23): 184-192.
Li Bin, Yan Kang, Luo Fa, et al. Comprehensive application of optimal benchmarking in line loss lean management of city-level power grid enterprises[J]. Automation of Electric Power Systems, 2018, 42(23): 184-192.
[3] 崔赛. 供电企业同期线损分析与指标体系管理研究[D]. 北京: 华北电力大学, 2017.
[4] 冷华, 陈鸿琳, 李欣然, 等. 基于功率或电量预测的智能配电网统计线损同期化方法[J]. 电力系统保护与控制, 2016, 44(18): 108-114.
Leng Hua, Chen Honglin, Li Xinran, et al. A method for synchronous line loss statistics of distribution network based on load or electricity consumption forecasting[J]. Power System Protection and Control, 2016, 44(18): 108-114.
[5] 史雷, 赵滨滨, 徐晓萌, 等. 基于分层节点识别策略的中低压配电网同期线损优化系统的研究[J]. 电测与仪表, 2019, 56(24): 39-45.
Shi Lei, Zhao Binbin, Xu Xiaomeng, at al. Design and implementation of the synchronous line loss optimization system of medium and low voltage distribution network based on hierarchical node identification strategy[J]. Electrical Measurement & Instrumentation, 2019, 56(24): 39-45.
[6] 杨霁, 曾现均, 姚龙, 等. 基于大数据挖掘的异常用电监测研究[J]. 自动化与仪器仪表, 2019(8): 219-222.
Yang Ji, Zeng Xianjun, Yao Long, et al. Research on abnormal electricity monitoring based on large data mining[J]. Automation & Instrumentation, 2019(8): 219-222.
[7] 李永攀, 门锟, 吴俊阳. 基于低秩模型的电力状态数据异常检测[J]. 计算机工程与应用, 2019, 55(16): 255-258, 264.
Li Yongpan, Men Kun, Wu Junyang. Low-rank representation for outliers detection in power state estimation[J]. Computer Engineering and Applications, 2019, 55(16): 255-258, 264.
[8] 陈文超. 状态估计不良数据的潮流追踪与动态辨识方法研究[D]. 重庆: 重庆大学, 2017.
[9] 赵霞, 叶晓斌, 杨仑, 等. 网省两级AGC机组协调调度的二层规划模型[J]. 电工技术学报, 2018, 33(20): 4876-4887.
Zhao Xia, Ye Xiaobin, Yang Lun, et al. A bi-level programming model for coordinated dispatch of AGC units in regional and provincial power grids[J]. Transactions of China Electrotechnical Society, 2018, 33(20): 4876-4887.
[10] 沈小军, 付雪姣, 周冲成, 等. 风电机组风速-功率异常运行数据特征及清洗方法[J]. 电工技术学报, 2018, 33(14): 3353-3361.
Shen Xiaojun, Fu Xuejiao, Zhou Chongcheng, et al. Characteristics of outliers in wind speed-power operation data of wind turbines and its cleaning method[J]. Transactions of China Electrotechnical Society, 2018, 33(14): 3353-3361.
[11] 王毅, 李鼎睿, 康重庆. 低秩矩阵分解在母线坏数据辨识与修复中的应用[J]. 电网技术, 2017, 41(6): 1972-1979.
Wang Yi, Li Dingrui, Kang Chongqing. Application of low-rank matrix factorization in bad data identification and recovering for bus load[J]. Power System Technology, 2017, 41(6): 1972-1979.
[12] 胡启安. 基于改进FCM算法的不良负荷数据辨识及修复方法[D]. 天津: 天津大学, 2017.
[13] 陈得治, 郭志忠. 基于负荷获取和匹配潮流方法的配电网理论线损计算[J]. 电网技术, 2005, 29(1): 80-84.
Chen Dezhi, Guo Zhizhong. Theoretical line loss calculation of distribution network based on load acquisition and matching power flow method[J]. Power System Technology, 2005, 29(1): 80-84.
[14] 张恺凯, 杨秀媛, 卜从容, 等. 基于负荷实测的配电网理论线损分析及降损对策[J]. 中国电机工程学报, 2013, 33(增刊1): 92-97.
Zhang Kaikai, Yang Xiuyuan, Bu Congrong, et al. Theoretical analysis on distribution network loss based on load measurement and countermeasures to reduce the loss[J]. Proceedings of the CSEE, 2013, 33(S1): 92-97.
[15] 李学平, 刘怡然, 卢志刚, 等. 基于聚类的阶段理论线损快速计算与分析[J]. 电工技术学报, 2015, 30(12): 367-376.
Li Xueping, Liu Yiran, Lu Zhigang, et al. Phase theoretical line loss calculation and analysis based on clustering theory[J]. Transactions of China Electro- technical Society, 2015, 30(12): 367-376.
[16] 徐茹枝, 王宇飞. 粒子群优化的支持向量回归机计算配电网理论线损方法[J]. 电力自动化设备, 2012, 32(5): 86-89, 93.
Xu Ruzhi, Wang Yufei. Steady-state power flow control by generator regulation[J]. Electric Power Automation Equipment, 2012, 32(5): 86-89, 93.
[17] 彭宇文, 刘克文. 基于改进核心向量机的配电网理论线损计算方法[J]. 中国电机工程学报, 2011, 31(34): 120-126.
Peng Yuwen, Liu Kewen. A distribution network theoretical line loss calculation method based on improved core vector machine[J]. Proceedings of the CSEE, 2011, 31(34): 120-126.
[18] 李晓莉, 张雅文. 概率论与数理统计[M]. 北京: 高等教育出版社, 2014.
[19] 吴润泽, 包正睿, 王文韬, 等. Hadoop架构下基于模式匹配的短期电力负荷预测方法[J]. 电工技术学报, 2018, 33(7): 1542-1551.
Wu Runze, Bao Zhengrui, Wang Wentao, et al. Short-term power load forecasting method based on pattern matching in Hadoop framework[J]. Transa- ctions of China Electrotechnical Society, 2018, 33(7): 1542-1551.
[20] 李扬, 李京, 陈亮, 等. 复杂噪声条件下基于抗差容积卡尔曼滤波的发电机动态状态估计[J]. 电工技术学报, 2019, 34(17): 3651-3660.
Li Yang, Li Jing, Chen Liang, et al. Dynamic state estimation of synchronous machines based on robust cubature Kalman filter under complex measurement noise conditions[J]. Transactions of China Electro- technical Society, 2019, 34(17): 3651-3660.
[21] 李建宁, 马小丽, 颜华敏, 等. 基于无线通信和大数据技术的低压台区同期线损异常诊断系统[J]. 电力与能源, 2019, 40(1): 36-40.
Li Jianning, Ma Xiaoli, Yan Huamin, et al. Anomaly diagnosis system for low-voltage area line loss based on wireless communication and big data techno- logy[J]. Power & Energy, 2019, 40(1): 36-40.
[22] 肖润龙, 王刚, 李子梦, 等. 中压直流输电直流区域配电综合电力系统静态状态估计方法研究[J]. 电工技术学报, 2018, 33(13): 3023-3033.
Xiao Runlong, Wang Gang, Li Zimeng, et al. Static estimation of the integrated power system with medium voltage DC and DC zonal distribution system[J]. Transactions of China Electrotechnical Society, 2018, 33(13): 3023-3033.
[23] 吴军基, 杨伟, 葛成, 等. 基于GSA的肘形判据用于电力系统不良数据辨识[J]. 中国电机工程学报, 2006, 26(22): 23-28.
Wu Junji, Yang Wei, Ge Cheng, et al. Application of GSA-based elbow judgment on bad-data detection of power system[J]. Proceedings of the CSEE, 2006, 26(22): 23-28.
Abnormal Data Identification of Synchronous Line Loss Based on the Approximate Equality of Rank Sum
Abstract Aiming at the problem that abnormal data of synchronous line loss is difficult to identify because of the huge amount of data, a new method based on the characteristics of the approximate equality of "rank sum" was proposed to identify the abnormal data. Firstly, the "rank sum" difference theory was introduced to analyze the difference of the "rank sum" between the synchronous line loss and the theoretical line loss in the same period. Then, based on the traditional a threshold, a new threshold calculation method was proposed only considering misjudgment rate. The threshold could consider the influence of misjudgment rate and missed judgment rate simultaneously, which helps to judge whether the data set contains abnormal data. On this basis, the identification model of abnormal data was established to further judge the location of the abnormal data. Finally, taking actual operation data of Gansu grid as an example, simulation was carried out to verify the effectiveness of the abnormal data identification method proposed in this paper.
keywords:Synchronous line loss, abnormal data identification, approximate similarity of rank sum, threshold
中图分类号:TM73
DOI: 10.19595/j.cnki.1000-6753.tces.191353
国家电网公司科技项目(SGGSKY00DJJS1800083)、国家自然科学基金项目(51377053)和中央高校基本科研专项基金项目(2019QN115)资助。
收稿日期2019-10-16
改稿日期 2020-03-10
王方雨 男,1992年生,博士,研究方向为电力系统线损数据评估与治理、电力系统安全分析等。E-mail: 18001201352@163.com(通信作者)
刘文颖 女,1955年生,教授,博士生导师,研究方向为电力系统运行分析与控制、电力系统线损数据分析等。E-mail: liuwenyingls@sina.com
(编辑 崔文静)