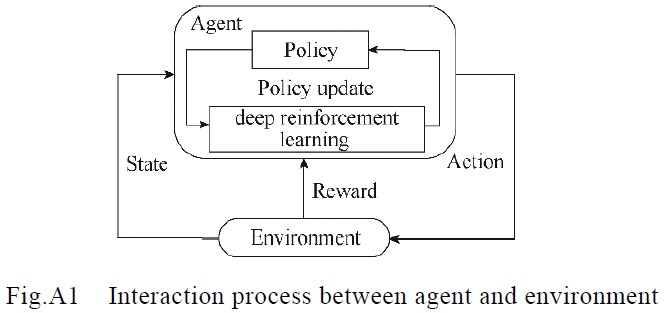
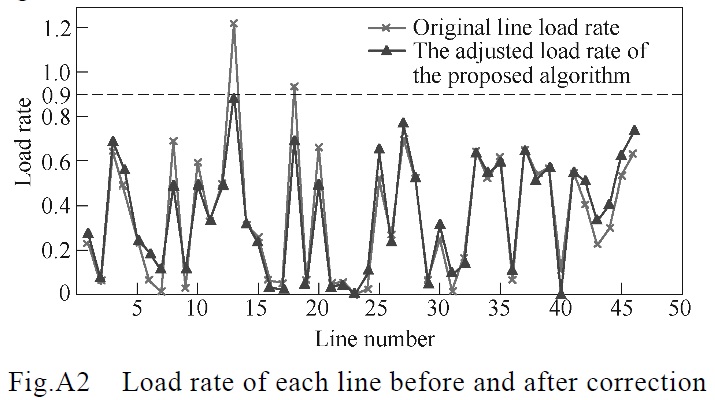
| [1] 林涛, 毕如玉, 陈汝斯, 等. 基于二阶锥规划的计及多种快速控制手段的综合安全校正策略[J]. 电工技术学报, 2020, 35(1): 167-178.
Lin Tao, Bi Ruyu, Chen Rusi, et al.Comprehensive security correction strategy based on second-order cone programming considering multiple fast control measures[J]. Transactions of China Electrotechnical Society, 2020, 35(1): 167-178.
[2] 刘瑶, 彭书涛, 张志华, 等. 基于抽样盲数的线路N-1静态安全评估[J]. 电力系统保护与控制, 2019, 47(7): 106-112.
Liu Yao, Peng Shutao, Zhang Zhihua, et al.Static security assessment according to N-1 criterion for transmission lines based on sampled-blind-number[J]. Power System Protection and Control, 2019, 47(7): 106-112.
[3] 陈中, 朱政光, 严俊, 等. 基于交直流混联系统静态安全域安全校正控制后的优化调度[J]. 电力自动化设备, 2021, 41(4): 139-147, 169.
Chen Zhong, Zhu Zhengguang, Yan Jun, et al.Optimal dispatch after security correction control based on steady-state security region of AC/DC hybrid system[J]. Electric Power Automation Equip-ment, 2021, 41(4): 139-147, 169.
[4] 孙淑琴, 颜文丽, 吴晨悦, 等. 基于原-对偶内点法的输电断面有功安全校正控制方法[J]. 电力系统保护与控制, 2021, 49(7): 75-85.
Sun Shuqin, Yan Wenli, Wu Chenyue, et al.Active power flow safety correction control method of transmission sections based on a primal-dual interior point method[J]. Power System Protection and Control, 2021, 49(7): 75-85.
[5] 王艳松, 卢志强, 李强, 等. 基于源-荷协同的电网静态安全校正最优控制算法[J]. 电力系统保护与控制, 2019, 47(20): 73-80.
Wang Yansong, Lu Zhiqiang, Li Qiang, et al.Optimal control algorithm for static safety correction of power grid based on source-load coordination[J]. Power System Protection and Control, 2019, 47(20): 73-80.
[6] Wang Qin, McCalley J D, Zheng Tongxin, et al. Solving corrective risk-based security-constrained optimal power flow with Lagrangian relaxation and Benders decomposition[J]. International Journal of Electrical Power & Energy Systems, 2016, 75: 255-264.
[7] 刘阳, 夏添, 汪旸. 区域电网内多输电断面有功协同控制策略在线生成方法[J]. 电力自动化设备, 2020, 40(7): 204-210.
Liu Yang, Xia Tian, Wang Yang.On-line generation method of active power coordinated control strategy for multiple transmission sections in regional power grid[J]. Electric Power Automation Equipment, 2020, 40(7): 204-210.
[8] Wang Chenlu, Feng Changyou, Zeng Yuan, et al.Improved correction strategy for power flow control based on multi-machine sensitivity analysis[J]. IEEE Access, 8: 82391-82403.
[9] 邓佑满, 黎辉, 张伯明, 洪军, 雷健生. 电力系统有功安全校正策略的反向等量配对调整法[J]. 电力系统自动化, 1999, 23(18): 5-8.
Deng Youman, Li Hui, Zhang Boming, et al.Adjust-ment of equal and opposite quantities in pair s for strategy of active power security correction of power systems[J]. Automation of Electric Power Systems, 1999, 23(18): 5-8.
[10] 顾雪平, 张尚, 王涛, 等. 安全域视角下的有功安全校正优化控制方法[J]. 电力系统自动化, 2017, 41(18): 17-24.
Gu Xueping, Zhang Shang, Wang Tao, et al.Opti-mization control strategy for active power correction from perspective of security region[J]. Automation of Electric Power Systems, 2017, 41(18): 17-24.
[11] 陈中, 朱政光, 严俊. 基于安全距离灵敏度的交直流混联系统安全校正策略[J]. 电力自动化设备, 2019, 39(9): 144-150, 165.
Chen Zhong, Zhu Zhengguang, Yan Jun.Security correction strategy of AC/DC hybrid system based on security distance sensitivity[J]. Electric Power Auto-mation Equipment, 2019, 39(9): 144-150, 165.
[12] 徐正清, 肖艳炜, 李群山, 等. 基于灵敏度及粒子群算法的输电断面功率越限控制方法对比研究[J]. 电力系统保护与控制, 2020, 48(15): 177-186.
Xu Zhengqing, Xiao Yanwei, Li Qunshan, et al.Comparative study based on sensitivity and particle swarm optimization algorithm for power flow over-limit control method of transmission section[J]. Power System Protection and Control, 2020, 48(15): 177-186.
[13] 孙国强, 张恪, 卫志农, 等. 基于深度学习的含统一潮流控制器的电力系统快速安全校正[J]. 电力系统自动化, 2020, 44(19): 119-127.
Sun Guoqiang, Zhang Ke, Wei Zhinong, et al.Deep learning based fast security correction of power system with unified power flow controller[J]. Auto-mation of Electric Power Systems, 2020, 44(19): 119-127.
[14] Mnih V, Kavukcuoglu K, Silver D, et al.Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[15] 李永刚, 王月, 吴滨源. 基于双重Q学习的动态风速预测模型[J]. 电工技术学报, 2022, 37(7): 1810-1819.
Li Yonggang, Wang Yue, Wu Binyuan.Dynamic wind speed prediction model based on double Q learning[J]. Transactions of China Electrotechnical Society, 2022, 37(7): 1810-1819.
[16] 梁煜东, 陈峦, 张国洲, 等. 基于深度强化学习的多能互补发电系统负荷频率控制策略[J]. 电工技术学报, 2022, 37(7): 1768-1779.
Liang Yudong, Chen Luan, Zhang Guozhou, et al.Load frequency control strategy of hybrid power generation system: a deep reinforcement learning— based approach[J]. Transactions of China Electro-technical Society, 2022, 37(7): 1768-1779.
[17] 赵冬梅, 陶然, 马泰屹, 等. 基于多智能体深度确定策略梯度算法的有功-无功协调调度模型[J]. 电工技术学报, 2021, 36(9): 1914-1925.
Zhao Dongmei, Tao Ran, Ma Taiyi, et al.Active and reactive power coordinated dispatching based on multi-agent deep deterministic policy gradient algorithm[J]. Transactions of China Electrotechnical Society, 2021, 36(9): 1914-1925.
[19] Mocanu E, Mocanu D C, Nguyen P H, et al.On-line building energy optimization using deep reinforce-ment learning[J]. IEEE Transactions on Smart Grid, 2019, 10(4): 3698-3708.
[20] 李嘉文, 余涛, 张孝顺, 等. 基于改进深度确定性梯度算法的AGC发电功率指令分配方法[J]. 中国电机工程学报, 2021, 41(21): 7198-7211.
Li Jiawen, Yu Tao, Zhang Xiaoshun, et al.AGC power generation command allocation method based on improved deep deterministic policy gradient algorithm[J]. Proceedings of the CSEE, 2021, 41(21): 7198-7211.
[21] 叶宇剑, 袁泉, 汤奕, 等. 抑制柔性负荷过响应的微网分散式调控参数优化[J]. 中国电机工程学报, 2022, 42(5): 1748-1759.
Ye Yujian, Yuan Quan, Tang Yi, et al.Decentralized coordination parameters optimization in microgrids mitigating demand response synchronization effect of flexible loads[J]. Proceedings of the CSEE, 2022, 42(5): 1748-1759.
[22] 孙伟卿, 王承民, 张焰, 等. 电力系统运行均匀性分析与评估[J]. 电工技术学报, 2014, 29(4): 173-180.
Sun Weiqing, Wang Chengmin, Zhang Yan, et al.Analysis and evaluation on power system operation homogeneity[J]. Transactions of China Electro-technical Society, 2014, 29(4): 173-180. |